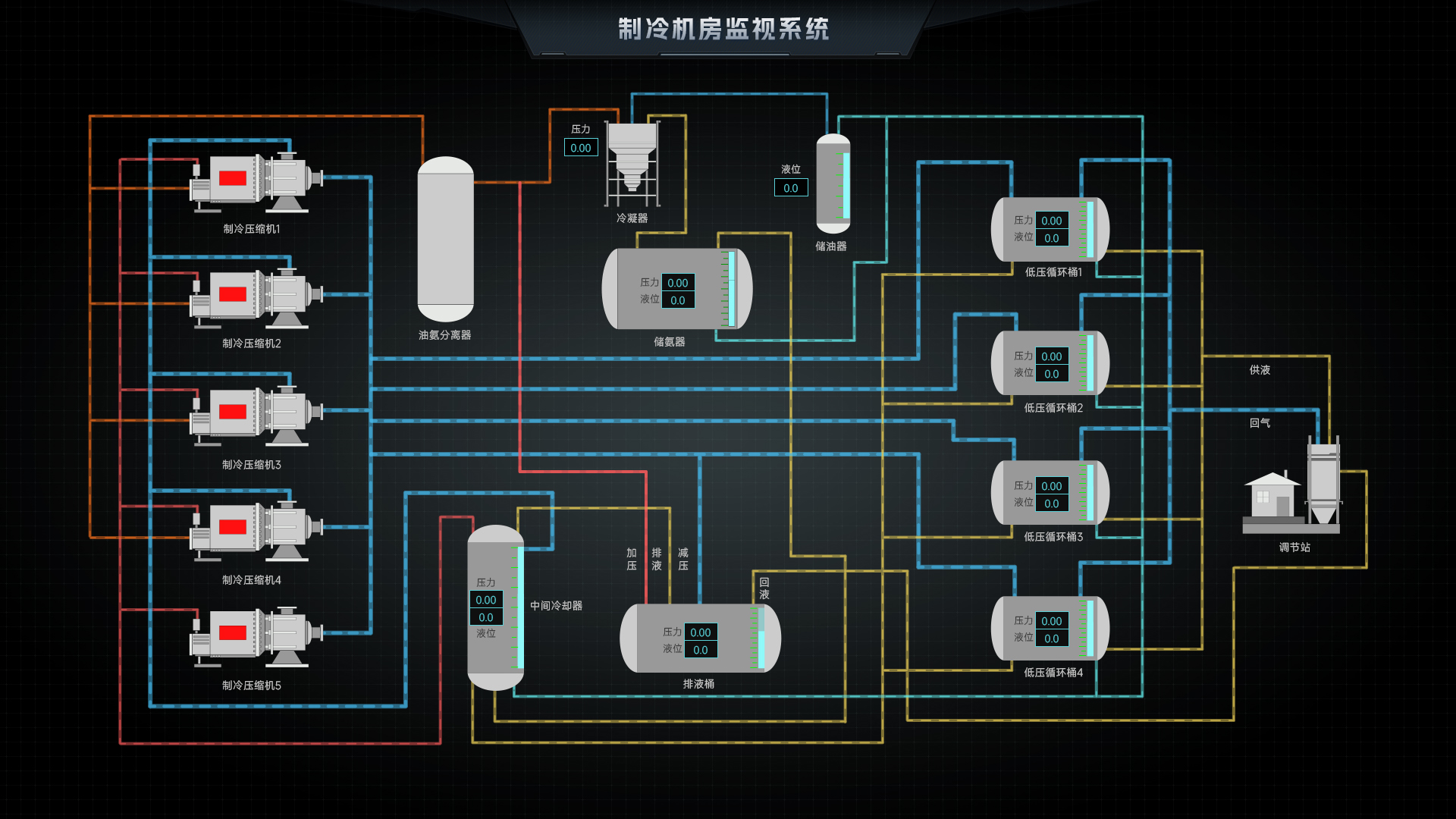
简述
生成对抗网络(Generative Adversarial Networks,简称GAN)是一种深度学习模型,由Ian Goodfellow于2014年提出。它的主要目标是生成与真实数据分布相似的新数据。GAN在许多领域都取得了显著的成功,如图像生成、图像到图像的转换、文本生成等。

此外,GAN模型还衍生出了多种变体,如CGAN、LAPGAN、DCGAN、InfoGan、LSGAN、WGAN和CycleGAN等,这些变体在生成器或判别器结构上进行了一系列创新,提高了GAN的性能和应用范围,下面将用DCGAN进行示例。
基本思想
通过同时训练两个神经网络——生成器(Generator)和判别器(Discriminator)来实现生成任务。生成器的目标是生成足够真实的数据以欺骗判别器,而判别器的目标是区分输入数据是真实数据还是生成器生成的伪造数据。这两个网络相互竞争,不断提高各自的性能,最终达到一个动态平衡。
基本结构
-
生成器(Generator):生成器是一个神经网络,它接收一个随机噪声向量作为输入,并将其映射到数据空间。生成器的目标是生成与真实数据分布相似的新数据。在训练过程中,生成器会不断改进其参数,以便生成的数据能够欺骗判别器。
-
判别器(Discriminator):判别器也是一个神经网络,它接收来自真实数据集和生成器生成的数据作为输入。判别器的目标是区分输入数据是真实数据还是生成器生成的伪造数据。在训练过程中,判别器会不断改进其参数,以便更准确地识别出真实数据和生成数据。
-
损失函数(Loss Function):GAN使用对抗损失(Adversarial Loss)作为损失函数。对于生成器,损失函数是判别器将生成数据识别为真实数据的概率。对于判别器,损失函数是正确识别真实数据和生成数据的概率。通过最小化生成器的损失函数和最大化判别器的损失函数,可以实现生成器和判别器的优化。
-
训练过程(Training Process):在训练过程中,生成器和判别器交替进行更新。首先,固定生成器的参数,训练判别器以更好地区分真实数据和生成数据。然后,固定判别器的参数,训练生成器以生成更真实的数据。这个过程反复进行,直到达到动态平衡。
示例
GAN的应用非常广泛,涵盖了图像生成、图像修复、图像增强、风格迁移、超分辨率、文本生成、语音生成等领域。下面就以keras实现深度卷积生成对抗 (DCGAN) 生成手写数字的图像进行示例。
1、导入所需库、加载MNIST数据集
import numpy as np
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam#加载MNIST数据集
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train / 127.5 - 1.0
X_train = np.expand_dims(X_train, axis=3)
2、定义生成器
# 定义生成器
def build_generator():model = Sequential()#全连接层,输入维度为100,输出维度为128*7*7,激活函数为relumodel.add(Dense(128 * 7 * 7, activation="relu", input_dim=100))#改变形状,将输入数据调整为(7, 7, 128)的形状model.add(Reshape((7, 7, 128)))#上采样2D,将数据空间尺寸扩大2倍model.add(UpSampling2D())#卷积层,卷积核大小为3,填充方式为samemodel.add(Conv2D(128, kernel_size=3, padding="same"))#批量归一化,动量参数为0.8model.add(BatchNormalization(momentum=0.8))#激活函数,使用relumodel.add(Activation("relu"))#上采样2D,将数据空间尺寸扩大2倍model.add(UpSampling2D())#卷积层,卷积核大小为3,填充方式为samemodel.add(Conv2D(64, kernel_size=3, padding="same"))#批量归一化,动量参数为0.8model.add(BatchNormalization(momentum=0.8))#激活函数,使用relumodel.add(Activation("relu"))#卷积层,卷积核大小为3,填充方式为samemodel.add(Conv2D(1, kernel_size=3, padding="same"))#激活函数,使用tanhmodel.add(Activation("tanh"))return model3、定义判别器
#定义判别器
def build_discriminator():#创建一个Sequential模型model = Sequential()#添加卷积层,使用32个3x3的卷积核,步长为2,输入形状为(28, 28, 1),填充方式为"same"model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=(28, 28, 1), padding="same"))#添加LeakyReLU激活函数,alpha值为0.2model.add(LeakyReLU(alpha=0.2))#添加Dropout层,丢弃率为0.25model.add(Dropout(0.25))#添加卷积层,使用64个3x3的卷积核,步长为2,填充方式为"same"model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))#添加ZeroPadding2D层,对输入进行填充,填充量为((0, 1), (0, 1))model.add(ZeroPadding2D(padding=((0, 1), (0, 1))))#添加BatchNormalization层,动量为0.8model.add(BatchNormalization(momentum=0.8))#添加LeakyReLU激活函数,alpha值为0.2model.add(LeakyReLU(alpha=0.2))#添加Dropout层,丢弃率为0.25model.add(Dropout(0.25))#添加卷积层,使用128个3x3的卷积核,步长为2,填充方式为"same"model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))#添加BatchNormalization层,动量为0.8model.add(BatchNormalization(momentum=0.8))#添加LeakyReLU激活函数,alpha值为0.2model.add(LeakyReLU(alpha=0.2))#添加Dropout层,丢弃率为0.25model.add(Dropout(0.25))#添加Flatten层,将多维输入一维化model.add(Flatten())#添加全连接层,输出维度为1,激活函数为sigmoidmodel.add(Dense(1, activation='sigmoid'))return model
4、构建并编译模型
def build_combined():#构建生成器模型generator = build_generator()#构建判别器模型discriminator = build_discriminator()#设置判别器的训练不可用discriminator.trainable = False#定义输入层,输入维度为100z = Input(shape=(100,))#通过生成器生成图像img = generator(z)#通过判别器判断图像的真实性valid = discriminator(img)#构建组合模型combined = Model(z, valid)#编译组合模型,使用二元交叉熵损失函数和Adam优化器,评估指标为准确率combined.compile(loss='binary_crossentropy', optimizer=Adam())return combined5、训练模型
#定义训练的迭代次数
epochs = 10000
#定义每次训练使用的样本数量
batch_size = 32
#定义每隔多少个迭代保存一次生成的图片
sample_interval = 1000#进行指定次数的训练迭代
for epoch in range(epochs):#随机选择一批训练数据idx = np.random.randint(0, X_train.shape[0], batch_size)imgs = X_train[idx]#生成噪声数据noise = np.random.normal(0, 1, (batch_size, 100))#使用生成器生成一批图片gen_imgs = generator.predict(noise)#训练判别器,计算真实图片的损失d_loss_real = discriminator.train_on_batch(imgs, np.ones((batch_size, 1)))#训练判别器,计算生成图片的损失d_loss_fake = discriminator.train_on_batch(gen_imgs, np.zeros((batch_size, 1)))#计算判别器的总损失d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)#生成新的噪声数据noise = np.random.normal(0, 1, (batch_size, 100))#训练生成器,计算生成图片的损失g_loss = combined.train_on_batch(noise, np.ones((batch_size, 1)))#打印当前迭代次数、判别器损失和生成器损失print("Epoch: {}, D loss: {}, G loss: {}".format(epoch + 1, d_loss, g_loss))#每隔一定次数保存生成的图片if epoch % sample_interval == 0:print("Saving generated images...")save_images(gen_imgs)训练GAN模型时,需要注意平衡生成器和判别器之间的训练过程,以及选择合适的损失函数和优化器,GAN的训练过程可能不稳定,需要调整超参数和网络结构来获得更好的生成效果。




![[C++]priority_queue——优先级队列(含模拟实现)](https://img-blog.csdnimg.cn/direct/5e6525931fcc48498cd91e64aab9f095.png)