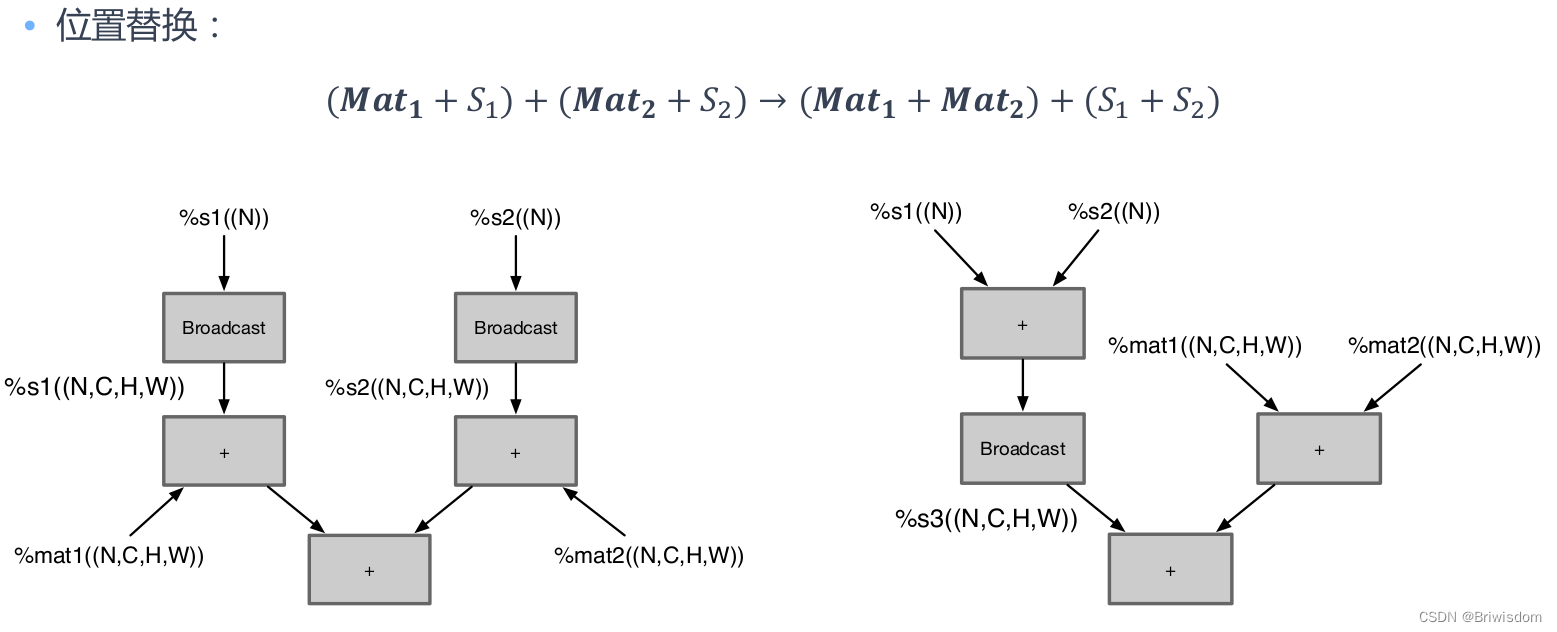
5.8更新几个比较坑的点
- 首先如果你的模型太大(>5GB),那么需要使用下面的命令声明一下,否则无法push
$ huggingface-cli lfs-enable-largefiles ./path/to/your/repo
- 假如使用VScode提交,那么需要注意,在最后push时需要在VScode顶端区域两次输入用户名和token,否则会一直卡在这个步骤。

前言
Huggingface transformers是一个非常棒的NLP项目,它用pytorch实现了几乎所有的主流预训练模型供研究者学习交流。同时,该项目允许用户上传自定义的预训练模型进行发布。这里简要记录一下上传流程。
注册
要发布自定义模型,首先我们需要注册一个账号。注册链接为:https://huggingface.co/join 。在填写完个人信息后,需要进入邮箱进行验证激活即可完成注册。(注意:最近Huggingface的网站好像不是很稳定,我再注册时经常遇到网站报错500或502,后面等了一段时间再试就可以了,如果有同样问题的同学可以等一段时间再来注册。)
安装git lfs
git lfs是git对大文件系统的支持。我是Linux系统,并且有root用户,所以安装git lfs过程比较简单。相关命令如下:
$curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
$sudo apt-get install git-lfs
$git lfs install
安装并登录huggingface-cli
安装命令如下,首先使用pip安装这个包。然后使用huggingface-cli login命令进行登录,登录过程中需要输入用户的Access Tokens。这里需要先到网站页面上进行设置然后复制过来进行登录。
$pip install huggingface_hub
$(picard) jxqi@han-server-01:~/text2sql/huggingface_model/sparc/t5-3b$ huggingface-cli login_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|To login, `huggingface_hub` now requires a token generated from https://huggingface.co/settings/token.(Deprecated, will be removed in v0.3.0) To login with username and password instead, interrupt with Ctrl+C.Token:
Login successful
Your token has been saved to /home/jxqi/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the defaultgit config --global credential.helper store
(picard) jxqi@han-server-01:~/text2sql/huggingface_model/sparc/t5-3b$
最后,使用huggingface-cli repo create model_name来创建自己的模型repo。
$huggingface-cli repo create model_name
上传与提交模型
创建好repo后,首先需要git clone到本地。
$git lfs install
$git clone https://huggingface.co/username/model_name
之后,使用cp命令,将自己已经训练好保存的模型文件夹中的内容复制到这个repo中。注意:这里的模型文件夹是指通过transformers的官方接口保存的模型文件夹,比如可以使用model.save_pretrained()或者trainer训练过程中自动保存的checkpoint文件夹。
添加完成后,进行git repo的正常上传即可。具体步骤如下:
$git add .
$git commit -m "commit from $USER"
$git push
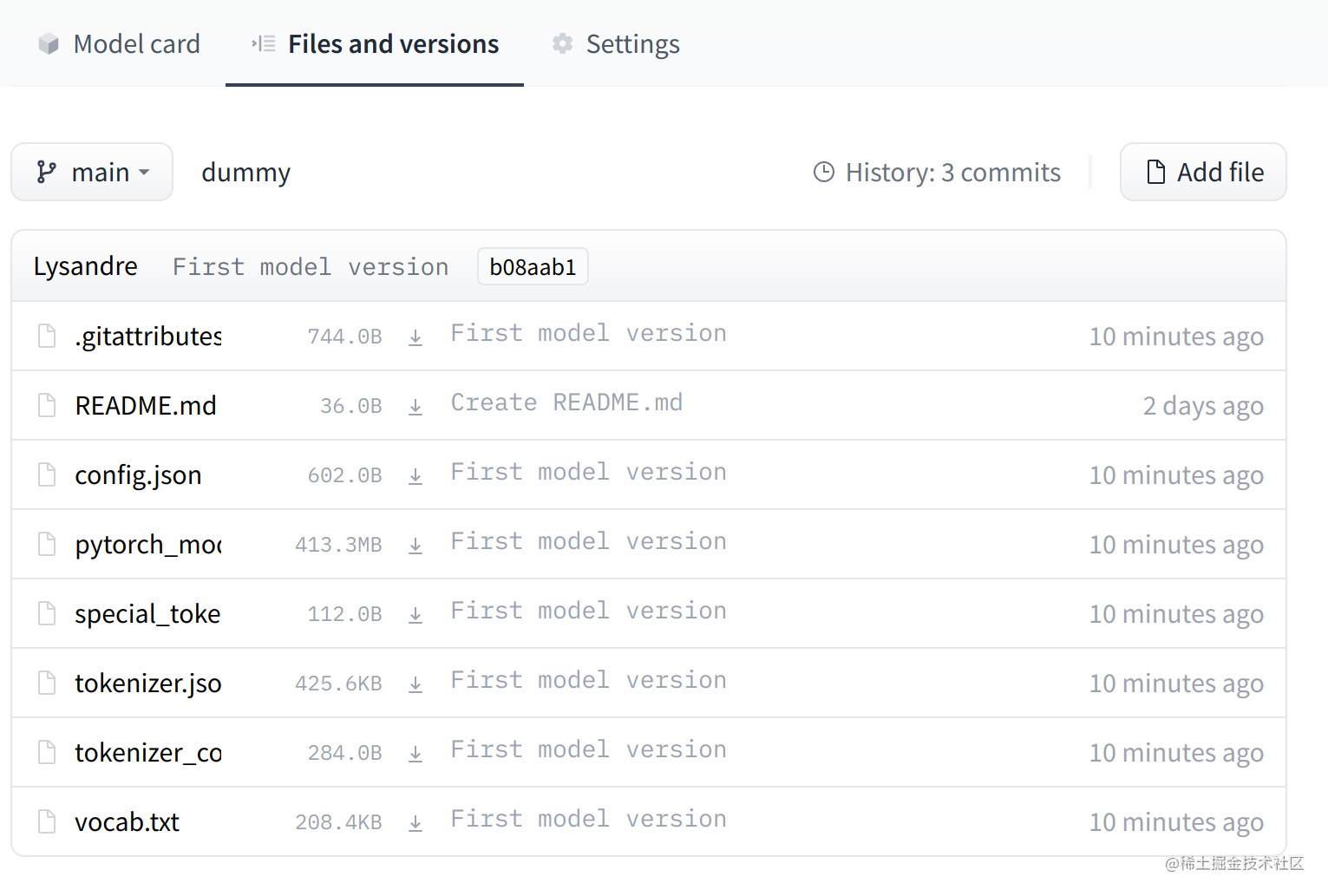
之后,在网页上打开模型的详情页面就可以看到我们模型保存的文件详细信息。
使用模型
最后,在使用模型时,我们可以很方便的在python代码中通过.from_pretrained方法来获取到模型和分词器:
tokenizer = AutoTokenizer.from_pretrained("username/model_name")
model = AutoModel.from_pretrained("username/model_name")
参考
- Adding your model to the Hugging Face Hub, https://huggingface.co/docs/hub/adding-a-model
- Welcome,https://huggingface.co/welcome
- 三句指令急速安装 Git LFS, https://zhuanlan.zhihu.com/p/73885257