.
专栏:数据结构|Linux|C语言
路漫漫其修远兮,吾将上下而求索
文章目录
- 前言
- 归并排序(递归)
- 动图:
- 代码实现
- 以下是代码详细讲解:
- 归并排序非递归
- 代码实现
- 以下是代码详细讲解:
- 计数排序
- 代码实现
- 以下是代码详细讲解:
- 时间复杂度和空间复杂度
- 完整代码
- 总结
前言
本文将深入介绍归并排序和计数排序这两种经典的排序算法,分别从递归和非递归的角度,以及对于整数排序的特殊情况,展开讨论它们的原理和实现。
归并排序(递归)
动图:
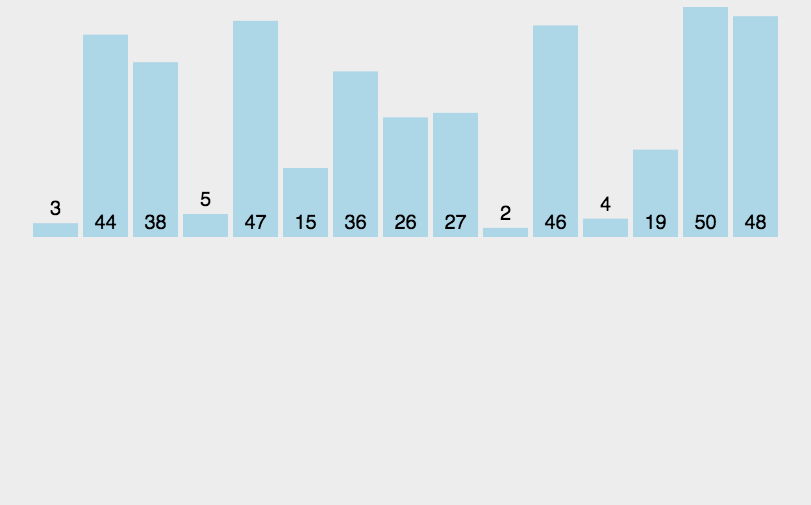
归并排序是一种分治算法,它将一个数组分为两个子数组,分别对这两个子数组进行排序,然后合并这两个有序子数组,得到一个完全有序的数组。以下是递归实现的归并排序的C代码:
代码实现
void _MergeSort(int* a, int begin, int end, int* tmp)// 归并排序实现(递归)
{// 基准情况:如果开始位置大于等于结束位置,表示当前数组已经有序或为空,直接返回if (begin >= end)return;// 计算中间位置 midint mid = (begin + end) / 2;// 递归对左半部分进行归并排序_MergeSort(a, begin, mid, tmp);// 递归对右半部分进行归并排序_MergeSort(a, mid + 1, end, tmp);// 合并两个有序数组,将结果保存在临时数组 tmp 中int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin;// 比较左右两个部分的元素,将较小的元素放入 tmp 数组while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}// 处理剩余的元素,如果左半部分还有剩余,将其复制到 tmp 中while (begin1 <= end1){tmp[i++] = a[begin1++];}// 如果右半部分还有剩余,将其复制到 tmp 中while (begin2 <= end2){tmp[i++] = a[begin2++];}// 将排序好的部分复制回原数组 amemcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}void MergeSort(int* a, int n)// 归并排序
{// 为临时数组 tmp 分配内存int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}// 调用递归排序函数_MergeSort(a, 0, n - 1, tmp);// 释放临时数组内存free(tmp);
}以下是代码详细讲解:
基准情况检查: 如果开始位置
begin大于等于结束位置end,表示当前数组已经有序或为空,直接返回,作为递归的终止条件。
计算中间位置
mid: 根据开始位置和结束位置计算中间位置。
递归排序左右部分: 递归调用
_MergeSort函数,对左半部分和右半部分进行归并排序。
合并两个有序数组: 创建两个索引
begin1/end1和begin2/end2分别表示左半部分和右半部分的范围。创建一个索引 i 表示当前合并位置。通过比较左右两部分的元素,将较小的元素放入临时数组tmp中,然后将剩余的元素复制到tmp中。
复制回原数组: 将排序好的部分复制回原数组
a。
释放临时数组内存: 最终释放用于合并的临时数组的内存。
通过递归地将数组划分为更小的部分,然后合并有序部分,最终完成整个数组的排序。这有助于理解每个步骤的具体实现。
归并排序非递归
为了避免递归调用的开销,我们还提供了归并排序的非递归版本。这种实现方式使用迭代的方式进行归并,通过不断扩大合并的范围,最终完成整个数组的排序。
代码实现
void MergeSortNonR(int* a, int n)// 归并排序(非递归)
{// 为临时数组 tmp 分配内存int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");exit(-1);}// 初始 gap 为 1,不断扩大 gap 直到数组全部有序int gap = 1;while (gap < n){// 对数组进行多轮归并for (int i = 0; i < n; i += 2 * gap){// 确定左右两部分的起始和结束位置int begin1 = i;int end1 = i + gap - 1;int begin2 = i + gap;int end2 = i + 2 * gap - 1;// 处理边界情况,防止数组越界if (end1 >= n || begin2 >= n)break;if (end2 >= n)end2 = n - 1;// 合并两部分有序数组,将结果保存在临时数组 tmp 中int j = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}// 处理剩余的元素,如果左半部分还有剩余,将其复制到 tmp 中while (begin1 <= end1){tmp[j++] = a[begin1++];}// 如果右半部分还有剩余,将其复制到 tmp 中while (begin2 <= end2){tmp[j++] = a[begin2++];}// 将排序好的部分复制回原数组 amemcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}// 每轮归并后,将 gap 扩大为原来的两倍gap *= 2;}// 释放临时数组内存free(tmp);
}
以下是代码详细讲解:
为临时数组分配内存: 创建一个临时数组 tmp 用于在归并过程中存储中间结果。
初始化 gap: 初始时,gap 设置为 1。
外层循环(gap 循环): 外层循环通过不断扩大 gap 的大小,直到 gap 大于等于数组长度 n。
内层循环(归并循环): 内层循环对整个数组进行多轮归并。每一轮归并根据当前的 gap 对数组进行分段,然后对相邻的两个段进行归并。
确定左右两部分的起始和结束位置: 根据当前的 gap,确定左半部分 [begin1, end1] 和右半部分 [begin2, end2] 的范围。
处理边界情况: 防止数组越界,检查左右两部分的结束位置是否超出数组长度,进行相应的调整。
归并两部分: 类似递归版本的归并排序,合并两部分有序数组,并将结果存储在临时数组 tmp 中。
复制回原数组: 将排序好的部分复制回原数组 a。
扩大 gap: 每一轮归并后,将 gap 扩大为原来的两倍。
释放临时数组内存: 最终释放用于归并的临时数组的内存。
这个非递归版本的归并排序通过迭代的方式实现了归并过程,避免了递归调用的开销。
计数排序
计数排序是一种非比较性的排序算法,适用于一定范围内的整数排序。以下是计数排序的C代码:
代码实现
void CountSort(int* a, int n)//计数排序
{// 寻找数组中的最小值和最大值int min = a[0];int max = a[0];for (int i = 0; i < n; i++){if (a[i] > max){max = a[i];}if (a[i] < min){min = a[i];}}// 计算数值范围int range = max - min + 1;// 为计数数组分配内存,并初始化为 0int* count = (int*)calloc(range, sizeof(int));if (count == NULL){printf("calloc fail\n");return;}// 统计每个元素出现的次数for (int i = 0; i < n; i++){count[a[i] - min]++;}// 根据计数数组重建原数组int i = 0;for (int j = 0; j < range; j++){while (count[j]--){a[i++] = j + min;}}// 释放计数数组内存free(count);
}
计数排序适用于元素范围相对较小的情况,具有线性时间复杂度,是一种高效的排序算法。
以下是代码详细讲解:
寻找最小值和最大值: 遍历数组,找到其中的最小值和最大值,以确定数值范围。
计算数值范围: 计算数组中元素的范围,即
max - min + 1。
分配计数数组内存: 使用
calloc分配一个计数数组count,其大小为数值范围,初始值全部为 0。
统计每个元素的出现次数: 遍历数组,对于每个元素,通过
a[i] - min将其映射到计数数组中的位置,并将对应位置的计数值加一。
根据计数数组重建原数组: 遍历计数数组,根据计数值的多少,将元素的值从小到大重建到原数组
a中。
释放计数数组内存: 释放用于存储计数数组的内存。
计数排序是一种非比较性的排序算法,适用于一定范围内的整数排序。在元素范围相对较小的情况下,计数排序具有线性时间复杂度,是一种非常高效的排序算法。
时间复杂度和空间复杂度
| 算法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 归并排序 | O(n log n) | O(n) |
| 计数排序 | O(n + k) | O(k) |
完整代码
可以来我的github参观参观,看完整代码
路径点击这里–>所有排序练习
总结
通过深入了解归并排序和计数排序这两种排序算法的原理和实现,我们可以更好地理解它们的优劣势以及适用场景。选择合适的排序算法对于提高程序的效率和性能至关重要。希望本文的介绍能够为读者提供有益的知识,启发对排序算法的深入思考。
![[java基础揉碎]do..while循环控制](https://img-blog.csdnimg.cn/direct/52824073c9534084abe66fd4399d8b0d.png)
![[C++]使用纯opencv部署yolov8旋转框目标检测](https://img-blog.csdnimg.cn/direct/e509302a23f34c52aeb473fab2d4a092.jpeg)