1.数据集介绍
CIFAR-10 数据集由 10 个类的 60000 张 32x32 彩色图像组成,每类 6000 张图像。有 50000 张训练图像和 10000 张测试图像。
数据集分为5个训练批次和1个测试批次,每个批次有10000张图像。测试批次正好包含从每个类中随机选择的 1000 张图像。训练批次以随机顺序包含剩余的图像,但某些训练批次可能包含来自一个类的图像多于另一个类的图像。在它们之间,训练批次正好包含来自每个类的 5000 张图像。
总结:
Size(大小): 32×32 RGB图像 ,数据集本身是 BGR 通道
Num(数量): 训练集 50000 和 测试集 10000,一共60000张图片
Classes(十种类别): plane(飞机), car(汽车),bird(鸟),cat(猫),deer(鹿),dog(狗),frog(蛙类),horse(马),ship(船),truck(卡车)

下载链接
来自博主(Dream是个帅哥)的分享:
链接: https://pan.baidu.com/s/1gKazlkk108V_1nrc68VoSQ 提取码: 0213
数据集文件夹
CIFAR-100数据集(拓展)
这个数据集与CIFAR-10类似,只不过它有100个类,每个类包含600个图像。每个类有500个训练图像和100个测试图像。CIFAR-100中的100个子类被分为20个大类。每个图像都有一个“fine”标签(它所属的子类)和一个“coarse”标签(它所属的大类)。
CIFAR-10数据集与MNIST数据集对比
- 维度不同:CIFAR-10数据集有4个维度,MNIST数据集有3个维度(CIRAR-10的四维: 一次的样本数量, 图片高, 图片宽, 图通道数 -> N H W C;MNIST的三维: 一次的样本数量, 图片高, 图片宽 -> N H W)
- 图像类型不同:CIFAR-10数据集是RGB图像(有三个通道),MNIST数据集是灰度图像,这也是为什么CIFAR-10数据集比MNIST数据集多出一个维度的原因。
- 图像内容不同:CIFAR-10数据集展示的是各种不同的物体(猫、狗、飞机、汽车…),MNIST数据集展示的是不同人的手写0~9数字。
2.数据集读取
读取数据集
选取data_batch_1可视化其中一张图:
def unpickle(file):import picklewith open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
print(dict)
输出结果:
一批次的数据集中有4个字典键,我们需要用到的就是 数据标签 和 数据内容(10000×32×32×3,10000张32×32大小为rgb三通道的图片)

输出的是一个字典:
{
b’batch_label’: b’training batch 1 of 5’,
b’labels’: [6, 9 … 1,5],
b’data’: array([[ 59, 43, …, 84, 72],…[ 62, 61, 60, …, 130, 130, 131]], dtype=uint8),
b’filenames’: [b’leptodactylus_pentadactylus_s_000004.png’,…b’cur_s_000170.png’]
}
其中,各个代表的意思如下:
b’batch_label’ : 所属文件集
b’labels’ : 图片标签
b’data’ :图片数据
b’filename’ :图片名称
读取类型
print(type(dict[b'batch_label']))
print(type(dict[b'labels']))
print(type(dict[b'data']))
print(type(dict[b'filenames']))
输出结果:
<class ‘bytes’>
<class ‘list’>
<class ‘numpy.ndarray’>
<class ‘list’>
读取图片
img = dict[b'data']
print(img.shape)
输出结果:(10000, 3072),其中 3072 = 32 * 32 * 3 (图片 size)
3.数据集调用
TensorFlow 调用
from tensorflow.keras.datasets import cifar10(x_train,y_train), (x_test, y_test) = cifar10.load_data()
本地调用
def unpickle(file):import picklewith open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
4.卷积神经网络训练
此处参考:传送门
1.指定GPU
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0],True)
#初始化
plt.rcParams['font.sans-serif'] = ['SimHei']
2.加载数据
cifar10 = tf.keras.datasets.cifar10
(train_x,train_y),(test_x,test_y) = cifar10.load_data()
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s'%(train_x.shape,train_y.shape,test_x.shape,test_y.shape))
3.数据预处理
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32) #归一化
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
4.建立模型
adam算法参数采用keras默认的公开参数,损失函数采用稀疏交叉熵损失函数,准确率采用稀疏分类准确率函数
model = tf.keras.Sequential()
##特征提取阶段
#第一层
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu,data_format='channels_last',input_shape=X_train.shape[1:])) #卷积层,16个卷积核,大小(3,3),保持原图像大小,relu激活函数,输入形状(28,28,1)
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2))) #池化层,最大值池化,卷积核(2,2)
#第二层
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2)))
##分类识别阶段
#第三层
model.add(tf.keras.layers.Flatten()) #改变输入形状
#第四层
model.add(tf.keras.layers.Dense(128,activation='relu')) #全连接网络层,128个神经元,relu激活函数
model.add(tf.keras.layers.Dense(10,activation='softmax')) #输出层,10个节点
print(model.summary()) #查看网络结构和参数信息#配置模型训练方法
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
5.训练模型
批量训练大小为64,迭代5次,测试集比例0.2(48000条训练集数据,12000条测试集数据)
history = model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
6.评估模型
model.evaluate(X_test,y_test,verbose=2) #每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力#保存整个模型
model.save('CIFAR10_CNN_weights.h5')
7.结果可视化
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['sparse_categorical_accuracy'] #训练集准确率
val_acc = history.history['val_sparse_categorical_accuracy'] #测试集准确率plt.figure(figsize=(10,3))plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('loss')
plt.legend()plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
8.使用模型
plt.figure()
for i in range(10):num = np.random.randint(1,10000)plt.subplot(2,5,i+1)plt.axis('off')plt.imshow(test_x[num],cmap='gray')demo = tf.reshape(X_test[num],(1,32,32,3))y_pred = np.argmax(model.predict(demo))plt.title('标签值:'+str(test_y[num])+'\n预测值:'+str(y_pred))
plt.show()
输出结果:

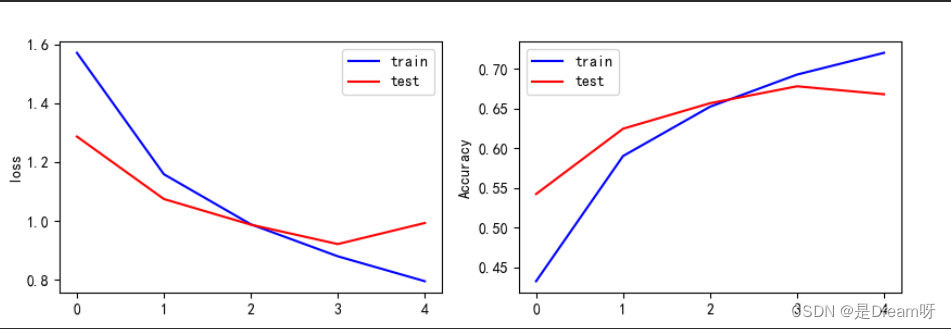
上面的内容分别是训练样本的损失函数值和准确率、测试样本的损失函数值和准确率,可以看到它每次训练迭代时损失函数和准确率的变化,从最后一次迭代结果上看,测试样本的损失函数值达到0.9123,准确率仅达到0.6839。
这个结果并不是很好,我尝试过增加迭代次数,发现训练样本的损失函数值可以达到0.04,准确率达到0.98;但实际上训练模型却产生了越来越大的泛化误差,这就是训练过度的现象,经过尝试泛化能力最好时是在迭代第5次的状态,故只能选择迭代5次。

训练好的模型文件——直接用
CIFAR10数据集介绍,并使用卷积神经网络训练图像分类模型——附完整代码和训练好的模型文件——直接用:https://download.csdn.net/download/weixin_51390582/88788820




![[晓理紫]每日论文分享(有中文摘要,源码或项目地址)--大模型、扩散模型、视觉语言导航](https://img-blog.csdnimg.cn/direct/c8019a1db8d940c99286d32464664db6.jpeg#pic_center)