文章目录
- 介绍
- AdaBoost算法
- 梯度提升算法(GBDT)
- 极端梯度提升(XGBoost)
- Bagging 算法与 Boosting 算法的不同之处
介绍
Boosting 的意思就是提升,这是一种通过训练弱学习模型的“肌肉”将其提升为强学习模型的算法。要想在机器学习竞赛中追求卓越,Boosting是一种必需的存在。这是一个属于“高手”的技术,我们当然也应该掌握。
Boosting 的基本思路是逐步优化模型。这与Bagging 不同。Bagging 是独立地生成很多不同的模型并对预测结果进行集成。Boosting则是持续地通过新模型来优化同一个基模型,每一个新的弱模型加入进来的时候,就在原有模型的基础上整合新模型,从而形成新的基模型。而对新的基模型的训练,将一直聚集于之前模型的误差点,也就是原模型预测出错的样本(而不是像 Bagging 那样随机选择样本),目标是不断减小模型的预测误差。
下面的 Boosting 示意图展示了这样的过程:一个拟合效果很弱的模型(上左图的水平红线),通过梯度提升,逐步形成了较接近理想拟合曲线的模型(下右图的红线)。
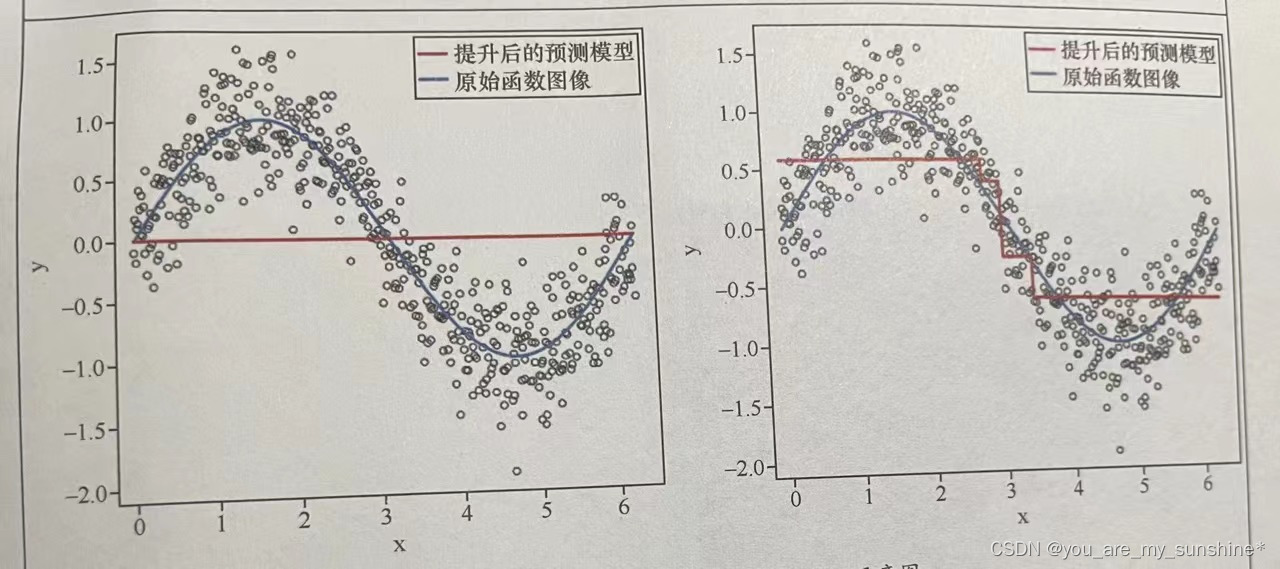
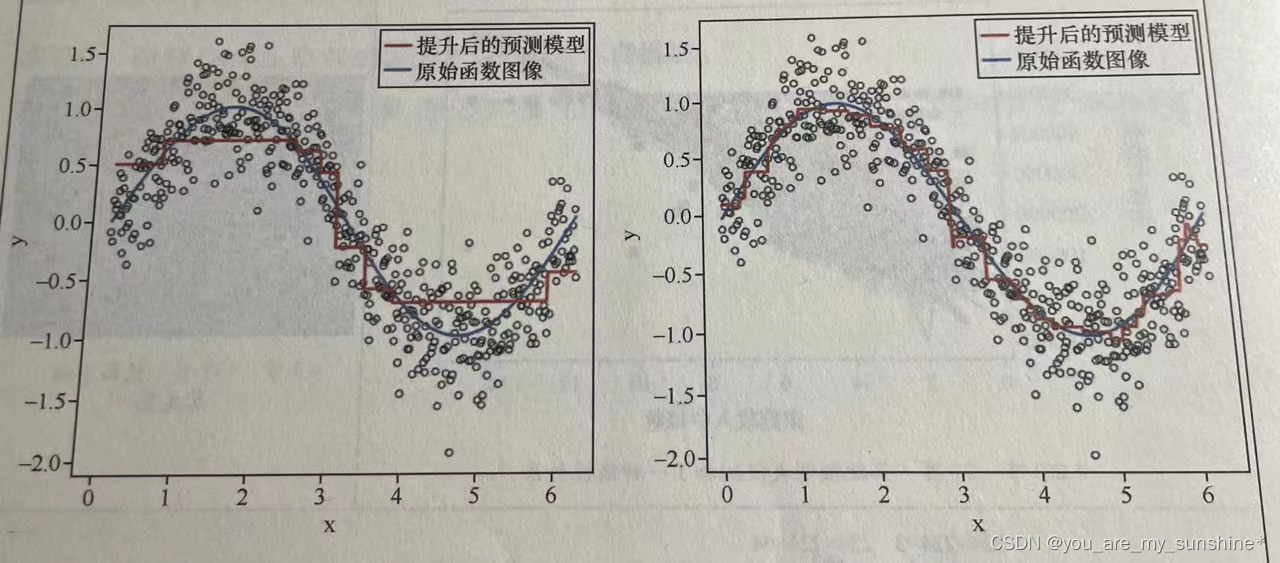
梯度下降是机器得以自我优化的本源。
机器学习的模型内部参数在梯度下降的过程中逐渐自我更新,直到达到最优解。
而Boosting 这个模型逐渐优化,自我更新的过程特别类似于梯度下降,它是把梯度下降的思路从更新模型内部参数扩展到更新模型本身。因此,可以说Boosting就是模型通过梯度下降自我优化的过程。
之前的Bagging非常精准地拟合每一个数据点(如很深的决策树)并逐渐找到更粗放的算法(如随机森林)以削弱对数据的过拟合,目的是降低方差。而现在的Boosting,则是把一个拟合很差的模型逐渐提升得比较好,目的是降低偏差。
Boosting 是如何实现自我优化的呢?有以下两个关键步骤。
- (1)数据集的拆分过程一Boosting 和Bagging的思路不同。Bagging 是随机抽取,而 Boosting 是在每一轮中有针对性的改变训练数据。具体方法包括:增大在前一轮被弱分类器分错的样本的权重或被选取的概率,或者减小前一轮被弱分类器分对的样本的权重或被选取的概率通过这样的方法确保被误分类的样本在后续训练中受到更多的关注。
- (2)集成弱模型的方法也有多种选择。可通过加法模型将弱分类器进行线性组合,比如 AdaBoost的加权多数表决,即增大错误率较小的分类器的权重,同时减小错误率较大的分类器的权重。而梯度提升决策树不是直接组合弱模型,而是通过类似梯度下降的方式逐步减小损失,将每一步生成的模型叠加得到最终模型。
实战中的Boosting 算法,有AdaBoost、梯度提升决策树(GBDT),以及XGBoost 等【注:LightGBM、Catboost也是,这两块实战看:机器学习_常见算法比较模型效果(LR、KNN、SVM、NB、DT、RF、XGB、LGB、CAT)】。这些算法都包含了 Boosting提升的思想。也就是说,每一个新模型的生成都是建立在上一个模型的基础之上,具体细节则各有不同。
AdaBoost算法
AdaBoost 是给不同的样本分配不同的权重,被分错的样本的权重在Boosting 过程中会增大,新模型会因此更加关注这些被分错的样本,反之,样本的权重会减小。然后,将修改过权重的新数据集输入下层模型进行训练,最后将每次得到的基模型组合起来,也根据其分类错误率对模型赋予权重,集成为最终的模型。
import numpy as np # 基础线性代数扩展包
import pandas as pd # 数据处理工具箱
df_bank = pd.read_csv("../数据集/BankCustomer.csv") # 读取文件# 构建特征和标签集合
y = df_bank['Exited']
X = df_bank.drop(['Name', 'Exited', 'City'], axis=1)from sklearn.model_selection import train_test_split # 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 对多棵决策树进行Bagging,即树的聚合
from sklearn.ensemble import BaggingClassifier # 导入Bagging分类器
from sklearn.tree import DecisionTreeClassifier # 导入决策树分类器
from sklearn.metrics import (f1_score, confusion_matrix) # 导入评估标准from sklearn.ensemble import AdaBoostClassifier # 导入AdaBoost模型
dt = DecisionTreeClassifier() # 选择决策树分类器作为AdaBoost的基准算法
ada = AdaBoostClassifier(dt) # AdaBoost模型
# 使用网格搜索优化参数
ada_param_grid = {"base_estimator__criterion" : ["gini", "entropy"],"base_estimator__splitter" : ["best", "random"],"base_estimator__random_state" : [7,9,10,12,15],"algorithm" : ["SAMME","SAMME.R"],"n_estimators" :[1,2,5,10],"learning_rate": [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3,1.5]}
ada_gs = GridSearchCV(ada,param_grid = ada_param_grid, scoring="f1", n_jobs= 10, verbose = 1)
ada_gs.fit(X_train,y_train) # 拟合模型
ada_gs = ada_gs.best_estimator_ # 最佳模型
y_pred = ada_gs.predict(X_test) # 进行预测
print("Adaboost测试准确率: {:.2f}%".format(ada_gs.score(X_test, y_test)*100))
print("Adaboost测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
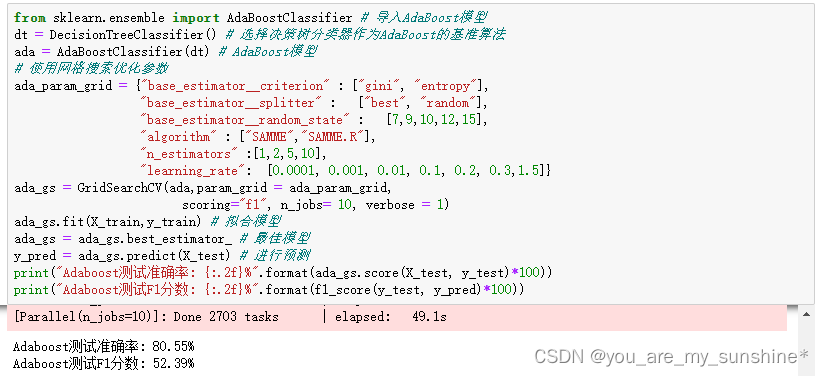
我们仍然选择决策树分类器作为AdaBoost的基准算法。从结果上来看,这个问题应用 AdaBoost 算法求解,效果并不是很好
梯度提升算法(GBDT)
梯度提升(Granding Boosting)算法是梯度下降和Boosting 这两种算法结合的产物。因为常见的梯度提升都是基于决策树的,有时就直接叫作GBDT,即梯度提升决策树(Granding Boosting Decision Tree )。
不同于 AdaBoost只是对样本进行加权,GBDT算法中还会定义一个损失函数,并对损失和机器学习模型所形成的函数进行求导,每次生成的模型都是沿着前面模型的负梯度方向(一阶导数)进行优化,直到发现全局最优解。也就是说,GBDT的每一次迭代中,新的树所学习的内容是之前所有树的结论和损失,对其拟合得到一个当前的树,这棵新的树就相当于是之前每一棵树效果的累加。
梯度提升算法,对于回归问题,目前被认为是最优算法之一。
输出结果显示,梯度提升算法的效果果然很好,F1分数达到60%以上。
from sklearn.ensemble import GradientBoostingClassifier # 导入梯度提升分类器
gb = GradientBoostingClassifier() # 梯度提升分类器
# 使用网格搜索优化参数
gb_param_grid = {'loss' : ["deviance"],'n_estimators' : [100,200,300],'learning_rate': [0.1, 0.05, 0.01],'max_depth': [4, 8],'min_samples_leaf': [100,150],'max_features': [0.3, 0.1]}
gb_gs = GridSearchCV(gb,param_grid = gb_param_grid,scoring="f1", n_jobs= 10, verbose = 1)
gb_gs.fit(X_train,y_train) # 拟合模型
gb_gs = gb_gs.best_estimator_ # 最佳模型
y_pred = gb_gs.predict(X_test) # 进行预测
print("梯度提升测试准确率: {:.2f}%".format(gb_gs.score(X_test, y_test)*100))
print("梯度提升测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))

极端梯度提升(XGBoost)
极端梯度提升(eXtreme Gradient Boosting,xGBoost,有时候也直接叫作XGB)和 GBDT类似,也会定义一个损失函数。不同于GBDT只用到一阶导数信息,XGBoost会利用泰勒展开式把损失函数展开到二阶后求导,利用了二阶导数信息,这样在训练集上的收敛会更快。
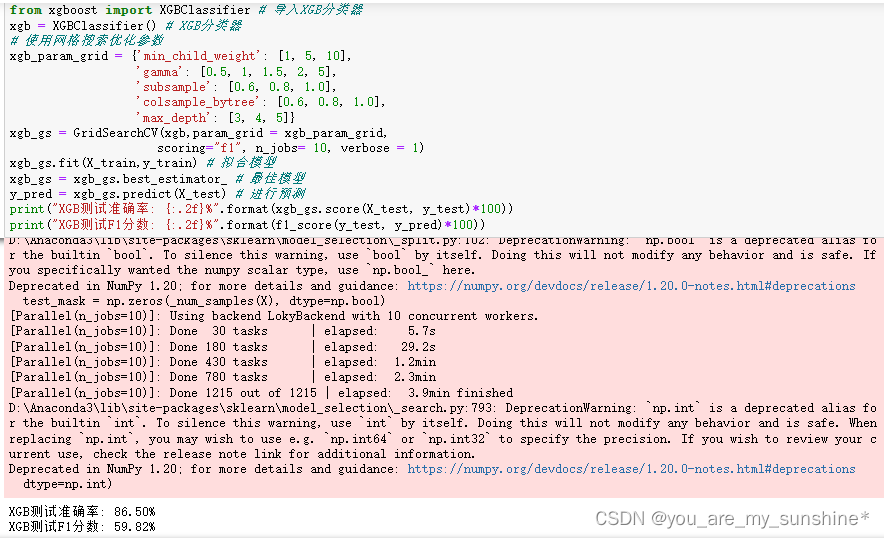
from xgboost import XGBClassifier # 导入XGB分类器
xgb = XGBClassifier() # XGB分类器
# 使用网格搜索优化参数
xgb_param_grid = {'min_child_weight': [1, 5, 10],'gamma': [0.5, 1, 1.5, 2, 5],'subsample': [0.6, 0.8, 1.0],'colsample_bytree': [0.6, 0.8, 1.0],'max_depth': [3, 4, 5]}
xgb_gs = GridSearchCV(xgb,param_grid = xgb_param_grid, scoring="f1", n_jobs= 10, verbose = 1)
xgb_gs.fit(X_train,y_train) # 拟合模型
xgb_gs = xgb_gs.best_estimator_ # 最佳模型
y_pred = xgb_gs.predict(X_test) # 进行预测
print("XGB测试准确率: {:.2f}%".format(xgb_gs.score(X_test, y_test)*100))
print("XGB测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
对于很多浅层的回归、分类问题,上面的这些Boosting 算法目前都是很热门、很常用的。整体而言,Boosting 算法都是生成一棵树后根据反馈,才开始生成另一棵树。
Bagging 算法与 Boosting 算法的不同之处
Bagging是降低方差,利用基模型的独立性;而Boosting是降低偏差,基于同一个基模型,通过增加被错分的样本的权重和梯度下降来提升模型性能。
学习机器学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
…