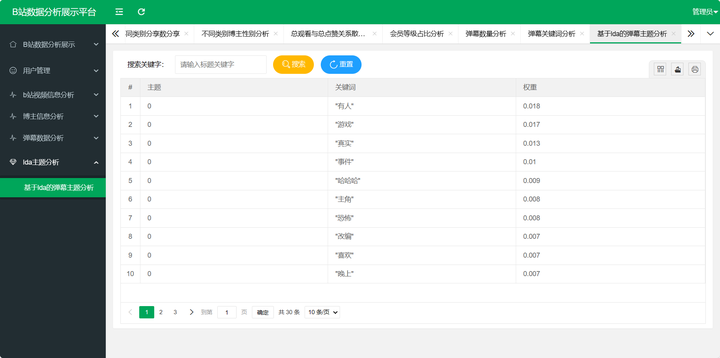
推荐系统简介
推荐系统的问题
根据之前学习到的内容,我们已经基本了解到了要如何构建一个二分类模型。我们都知道模型大体可以分成,回归,二分类和多分类。但推荐系统是属于哪一种场景呢,比如我们常见的广告推荐或者内容推荐,这些场景都是由系统来判断用户的喜好来推送广告或者视频内容,以追求更高的点击率和转化率。这种场景怎么看都不像跟这三种类型的算法有关系。
实现思路
其实解决这个问题的思路也比较简单, 我们可以遵循如下的原则:
- 借助专家系统,根据用户的信息初筛一个候选的视频集合(比如 1000 个),比如可以先简单根据用户的年龄,性别,爱好,职业进行推测他喜欢的类型并过滤出候选集合。 这是一种预处理机制, 在人工智能系统中,模型往往无法处理所有的情况,需要一些预处理与后处理辅助模型。在推荐系统中这个步骤往往被称为大排序,先根据规则来筛选候选集合。这么做有多种原因,其中一种比较典型的是担心模型的性能无法支撑过多的候选集合的计算。
- 训练一个二分类模型,这个模型用于推理出用户是否会点击这个视频(根据业务场景来,有可能是点击,有可能是点赞,也有可能是转化)。
- 将候选集合分别输入给模型进行推理。计算出每个视频会被用户点击的概率。
- 把模型的推理结果进行排序,取 top n 个概率最高的视频推送给用户。这一步就与传统的二分类模型不同, 我们已经知道模型输出的是目标属于某个类别的概率。而在传统二分类模型中, 需要用户自己设定一个阈值(也叫置信度)来辅助判断目标的类别, 概率大于这个阈值的判定为正例,小于这个阈值的判定为负例,这正是二分类模型的原理。但是在推荐系统中, 我们并不会因为用户喜欢这个内容的概率超过了某个阈值就进行推送, 因为候选集合太多了, 我们不能把超过某个阈值的都推送过去(广告位或者内容推送是有数量限制的)。 所以最终选择的是根据用户喜欢这个内容的概率进行排序,然后取 topN 来进行推送。
如此我们就把一个推荐系统的问题转换成了一个二分类的问题。 我们可以理解为世界上所有的监督学习场景,都是由二分类,多分类和回归问题变种而来。
写一个简单的模型训练 DEMO(使用 spark ml 库)
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
from pyspark.ml.feature import Tokenizer, StopWordsRemover, CountVectorizer
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.evaluation import BinaryClassificationEvaluatorfrom pyspark import SparkContext, SparkConf, SQLContext
from pyspark.sql import functions as F
from pyspark.sql.window import Windowconf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)# 定义数据
dicts = [['man', 'The Shawshank Redemption', 1.0],['man', 'The Godfather', 1.0],['man', 'Forrest Gump', 1.0],['woman', 'Titanic', 1.0],['woman', 'Forrest Gump', 0.0],['woman', 'The Godfather', 0.0],['woman', 'The Shawshank Redemption', 0.0],['man', 'Titanic', 0.0],['man', 'A Beautiful Mind', 0.0],['woman', 'A Beautiful Mind', 1.0],
]
rdd = sc.parallelize(dicts, 3)
dataf = sqlContext.createDataFrame(rdd, ['gender', 'title', 'interested'])# 将性别进行独热编码,以便把数据转换成算法可以识别的形式
from pyspark.ml.feature import StringIndexer, OneHotEncoder, VectorAssembler
stringIndexer = StringIndexer(inputCol="gender", outputCol="gender_num")
data_indexed = stringIndexer.fit(dataf).transform(dataf)
encoder = OneHotEncoder(inputCol="gender_num", outputCol="gender_onehot")
data_encoded = encoder.fit(data_indexed).transform(data_indexed)
data = data_encoded.select('gender_onehot', 'interested', 'title')
data.show()# 使用分词器
tokenizer = Tokenizer(inputCol="title", outputCol="words")
# 使用停用词
remover = StopWordsRemover(inputCol="words", outputCol="filtered_words")
# 将文本数据转换成特征向量,注意下面被注释的代码,这里是词向量转换,在NLP中,我们经常会把文本进行词向量转换,我们在下面会详细讲解词向量的内容。
# word2vec.fit(remover)
vectorizer = CountVectorizer(inputCol="filtered_words", outputCol="final_words")# 将所有特征组合成一个特征向量
vectorAssembler = VectorAssembler(inputCols=["gender_onehot", "final_words"], outputCol="features")# 定义逻辑回归
classifier = LogisticRegression(labelCol="interested", featuresCol="features", maxIter=10)
# 定义流水线, 当数据来了以后就可以按顺序处理数据
pipeline = Pipeline(stages=[tokenizer, remover, vectorizer, vectorAssembler, classifier])
# 模型训练
model = pipeline.fit(data)# 模型推理
predictions = model.transform(data)
evaluator = BinaryClassificationEvaluator(labelCol="interested", rawPredictionCol="rawPrediction")
accuracy = evaluator.evaluate(predictions)
print("Accuracy:", accuracy)
predictions.show()df_desc = predictions.orderBy(F.desc("probability"))
df_desc.show()词向量
上面用于训练模型的数据中有一列是视频的标题,我们会发现代码中我们使用了一系列 NLP(Natural Language Processing,自然语言处理)的算法:
- 分词器(tokenizer):用于在一个句子中提取一个一个的词
- 停用词(stop words):用于去掉一些语义无关的语气词,介词等,比如
the或者中文中的语气词啊。 在模型训练中往往需要去掉这些词以去除噪音,优化模型空间,减少索引量等等 - 词向量(也叫词嵌入):可以理解为计算出词与词之间的关联性,从而训练出的围绕中心词的特征向量。
上述概念中可能词向量是最难以理解的,这里尽量尝试用简单易懂的语言来解释这个概念。 我们之前训练反欺诈模型的时候,也遇到过一些离散特征,比如title也是以文本形式存在的数据。
我们在反欺诈中处理这样的使用的 one-hot(独热编码),独热编码也是一种处理离散特征常用的方法。假设我们有一群学生,他们可以通过四个特征来形容,分别是:
- 性别:[“男”,“女”]
- 年级:[“初一”,“初二”,“初三”]
- 学校:[“一中”,“二中”,“三中”,“四中”] 我们用采用 N 位状态寄存器来对 N 个状态进行编码,拿上面的例子来说,就是:

因此,当我们再来描述一个学生的时候(男生,初一,来自一中),就可以采用 [1 0 1 0 0 0 1 0 0] 这样的形式来表示。这也一种用于特征组合的实现方法之一。
或者我们也可以使用类似 bitmap 的方法做出一个 one—hot 向量来表示离散特征。 我们可以用类似下面的形式表达:

假设职业这一列一共有 100 个值, 假设教师在编号 6 这个位置上,编号 6 所在位置 ide 值就是 1,其他的值都是 0,我们以这个向量来代表教师这个特征. 以此类推,如果学生代表的编号是 10,那么
10 这个位置所在的值是 1,其他位置的值都是 0,用词向量来代表学生。 这样最后我们就有 100 个 100 维度的向量来表示这些特征。
上面两种方法都是很常见的用来用来表达文本特征的方法,但它们的问题是词与词之间是独立的,互相没有关联。 比如我们的训练数据中有一个句子this is apple juice,我们期望当
出现 this is orange __ 的时候,模型能够为我们推测出这个空白处也应该填写单词juice。 也就是我们希望模型能通过之前针对第一个句子的训练就能找到单词与单词之间的关系,模型能够知道apple和orange是含义相似的词,从而能推测出orange后面也可以填写juice。 而这正是词向量要做的事情。

如上图,词向量围绕这一些中心词(性别,事务,高贵程度),计算出每一个词与这些中心词的相关程度。而要得到这个词向量本身就需要相关算法训练出来,比如 world2vec:
from pyspark.ml.feature import Word2Vecfrom pyspark.sql import SparkSessionspark = SparkSession \.builder \.appName("dataFrame") \.getOrCreate()# Input data: Each row is a bag of words from a sentence or document.
documentDF = spark.createDataFrame([("Hi I heard about Spark".split(" "),),("I wish Java could use case classes".split(" "),),("Logistic regression models are neat".split(" "),)
], ["text"])documentDF.show()# Learn a mapping from words to Vectors.
word2Vec = Word2Vec(vectorSize=5, minCount=0, inputCol="text", outputCol="result")
model = word2Vec.fit(documentDF)result = model.transform(documentDF)
for row in result.collect():text, vector = rowprint("Text: [%s] => \nVector: %s\n" % (", ".join(text), str(vector)))# 运行结果
Text: [Hi, I, heard, about, Spark] =>
Vector: [-0.056896060705184937,-0.029017432034015658,0.020092955231666567,-0.0003222271800041199,-0.02170231742784381]Text: [I, wish, Java, could, use, case, classes] =>
Vector: [0.003511839745832341,0.025775608922620968,-0.01780955892588411,0.0012207544807876858,-0.0023355478021715365]Text: [Logistic, regression, models, are, neat] =>
Vector: [0.008233835361897946,-0.01995183974504471,-0.013863331265747549,-0.051928133144974714,-0.014838875085115433]
上面是一个训练词向量的代码,它的计算原理大概可以描述为:在文本中选取中心词并选取中心词前后数个单词,并训练出这些词会出现在中心词周围的概率。
总结
这些就是一个推荐系统中的大概步骤, 当然实际的推荐系统是非常复杂的, 我目前也只是列了一个简单的 DEMO,帮助大家理解推荐系统都在做什么事情。 更多手把手教你人工智能测试内容请关注我的星球:



![[NCTF2019]Fake XML cookbook(特详解)](https://img-blog.csdnimg.cn/img_convert/9120e977398ad6ab344248cd4c459b12.png)