KAFKA节点故障的容错方案
- 1. broker启动加载逻辑
- 1.1 日志组成和分析
- 1.2 snapshot文件
- 1.3 broker启动流程
- 1.4 LogManager的初始化和启动过程
- 2. controller高可用
- 1.1 选主逻辑
- 1.2 HA切换
- 1.3 controller的职责
- 3. partition高可用
- 3.1 ISR列表
- 3.1 选举Leader
- 4. 疑问和思考
- 4.1 如果一个broker宕机,运行在broker上的partiton数据丢失,是否会自动做均衡?
- 5. 参考文档
本文主要探讨kafka集群的高可用容错方案和容错能力的探讨。在出现单机故障时相关的容错方案。
更多关于分布式系统的架构思考请参考文档关于常见分布式组件高可用设计原理的理解和思考
1. broker启动加载逻辑
在kafka中,只有broker JVM进程,其余的组件或者角色都是通过broker衍生出来,因此broker的高可用和数据加载流程有必要理解和分析。
1.1 日志组成和分析
可以参考文章KAFKA高可用架构涉及常用功能整理,本文不再赘述。
1.2 snapshot文件
目前,Kafka对三类位移做checkpointing:
- Log Start Offset
- Recovery Point Offset
- Replication Offset
Log Start Offset: 每个topic partition log对象都有一个重要的位移字段:log start offset,标识分区消息对外部用户或应用可见的最早消息位移。在一些事件发生时Kafka会触发对该值的更新。Kafka对该offset进行checkpointing的初衷是更快地保存分区的元数据,这样下次再初始化Log对象时能够直接加载并初始化log start offset。
Recovery Point Offset: 第二个是recovery point offset,它保存的是第一条未flush到磁盘的消息。Kafka对它进行checkpointing能够显著加速日志段恢复(recover)的速度,因为直接从recovery point offset所在的日志段开始恢复即可,没必要从头恢复日志段。毕竟生产环境上,分区下的日志段文件可能是非常多的。
Replication Offset: 保存replication过程中副本的高水位(HW)位移值。通常的场景是当副本重启回来后创建Log对象时直接使用这个文件中的offset对高水位对象进行赋值,省去了读取日志段自行计算HW值的步骤。
总之,checkpointing大体的作用都是将Kafka Broker端重要的日志元数据保存下来,避免需要通过扫描segment日志,计算获取相关元数据,从而提升恢复速度。
1.3 broker启动流程
broker启动后,整体的启动流程如下。
- 修改当前broker的状态为Starting
- 启动kafka内部调度器KafkaScheduler
- 初始化Zookeeper上的kafka基础目录
- 创建并启动日志管理对象LogManager
- 启动通信服务SocketServer
- 创建ReplicaManager管理对象
- 创建offset管理线程OffsetManager
- 创建KafkaController
- 启动请求处理线程,并修改broker的状态为RunningAsBroker
- 启动replicaManager服务
- 启动KafkaController,进行Controller选举
- 创建并启动TopicConfigManager对象
- 创建并启动心跳服务KafkaHealthcheck
- 注册动态统计到JMX
- 启动完成
整体启动流程中,最耗时的是步骤4,创建和启动LogManager后,会扫描和加载本地的日志文件,读取相关的数据索引信息,因此整个加载过程比较耗时。整个过程是串行执行,只有日志加载完成后,才能进行下一步的启动工作。
1.4 LogManager的初始化和启动过程
- 初始化 LogManger 代码有两个主要方法:
- createAndValidateLogDirs():创建指定的数据目录,并做相应的检查: 1.确保数据目录中没有重复的数据目录、2.数据目录不存在的话就创建相应的目录;3. 检查每个目录路径是否是可读的;
- loadLogs():加载所有的日志分区(先加载snapshot,在加载日志文件),而每个日志也会调用 loadSegments() 方法加载该分区所有的 segment 文件,过程比较慢,所以 LogManager 使用线程池的方式,为每个日志的加载都会创建一个单独的线程。整体耗时较长。

- 启动LogManger后,主要在后台启动四个定时线程:
- cleanupLogs:定时清理过期的日志 segment,并维护日志的大小(默认5min);
f- lushDirtyLogs:定时刷新将还没有写到磁盘上日志刷新到磁盘(默认 无限大); - checkpointRecoveryPointOffsets:定时将所有数据目录所有日志的检查点写到检查点文件中(默认 60s);
- deleteLogs:定时删除标记为 delete 的日志文件(默认 30s)。
2. controller高可用
controller的高可用和Leader是通过zk的临时锁实现的。
1.1 选主逻辑
在kafka集群启动的时候,会自动选举一台broker作为controller来管理整个集群,选举的过程是集群中每个broker都会尝试在zookeeper上创建一个 /controller 临时节点,zookeeper会保证有且仅有一个broker能创建成功,这个broker就会成为集群的总控器controller。

1.2 HA切换
当这个controller角色的broker宕机了,此时zookeeper临时节点会消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就竞争再次创建临时节点,就是我们上面说的选举机制,zookeeper又会保证有一个broker成为新的controller。
1.3 controller的职责
具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
- 监听broker相关的变化。为Zookeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理broker增减的变化。
- 监听topic相关的变化。为Zookeeper中的/brokers/topics节点添加TopicChangeListener,用来处理topic增减的变化;为Zookeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除topic的动作。
- 从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理。对于所有topic所对应的Zookeeper中的/brokers/topics/[topic]节点添加PartitionModificationsListener,用来监听topic中的分区分配变化。
- 更新集群的元数据信息,同步到其他普通的broker节点中。
所以所有的broker保存的元数据都是一致的,随时可以HA切换成为controller。
3. partition高可用
partition的高可用和Leader是通过controller来实现的。
3.1 ISR列表
副本进入ISR列表有两个条件:
- 副本节点不能产生分区,必须能与zookeeper保持会话以及跟leader副本网络连通
- 副本能复制leader上的所有写操作,并且不能落后太多。(与leader副本同步滞后的副本,是由 replica.lag.time.max.ms 配置决定的,超过这个时间都没有跟leader同步过的一次的副本会被移出ISR列表)
3.1 选举Leader
- controller感知到分区leader所在的broker异常(controller监听了很多zk节点可以感知到broker存活)
- controller会从ISR列表(参数unclean.leader.election.enable=false的前提下)里挑第一个broker作为leader(第一个broker最先放进ISR列表,可能是同步数据最多的副本)
- 如果参数unclean.leader.election.enable为true,代表在ISR列表里所有副本都挂了的时候可以在ISR列表以外的副本中选leader,这种设置,可以提高可用性,但是选出的新leader有可能数据少很多。
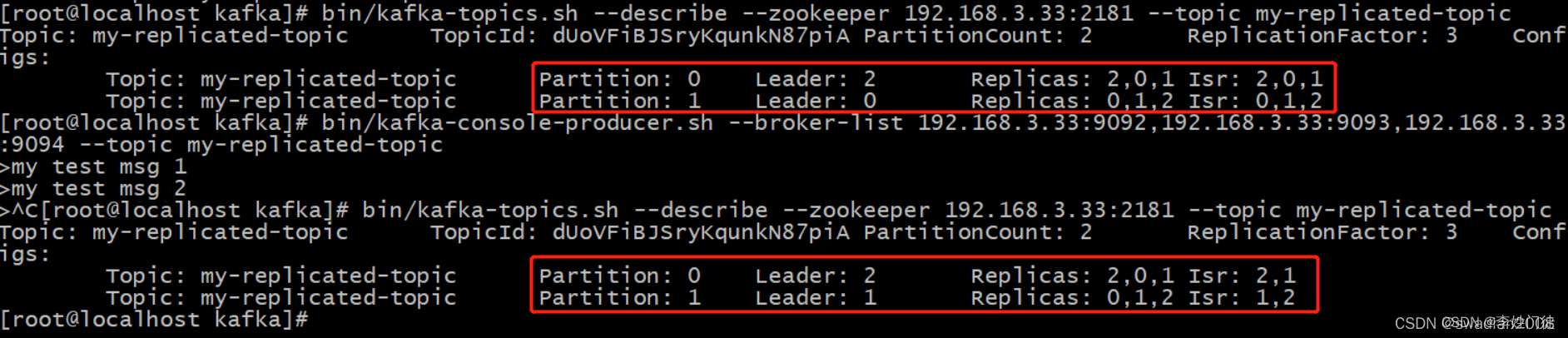
注明
unclean.leader.election.enable:是否启用不在ISR中的副本参与选举leader的最后的手段。这样做有可能丢失数据。
4. 疑问和思考
4.1 如果一个broker宕机,运行在broker上的partiton数据丢失,是否会自动做均衡?
不会,需要人工干预后才能修复。
kafka的数据机制是,对于每一个partition进行数据分配后,原则上不会再改动,因此不会重新分配一个Follower副本给这个paritition,并主动触发数据迁移。需要人工干预,重新分配Follower副本后,新的Follower主动向Leader获取消息,follower每次读取消息都会更新HW状态。具体操作可以参考 KAFKA高可用架构涉及常用功能整理中的《3.2.3 topic的partition扩、缩容、数据均衡》章节。
5. 参考文档
- Kafka 源码解析之日志管理