CSAPP shell lab
shell lab 的目标
实现shell 功能,包括解析命令,调用可执行文件和内置命令,(quit, jobs,fg, 和bg)。实现job控制和signal handler。
shell 介绍
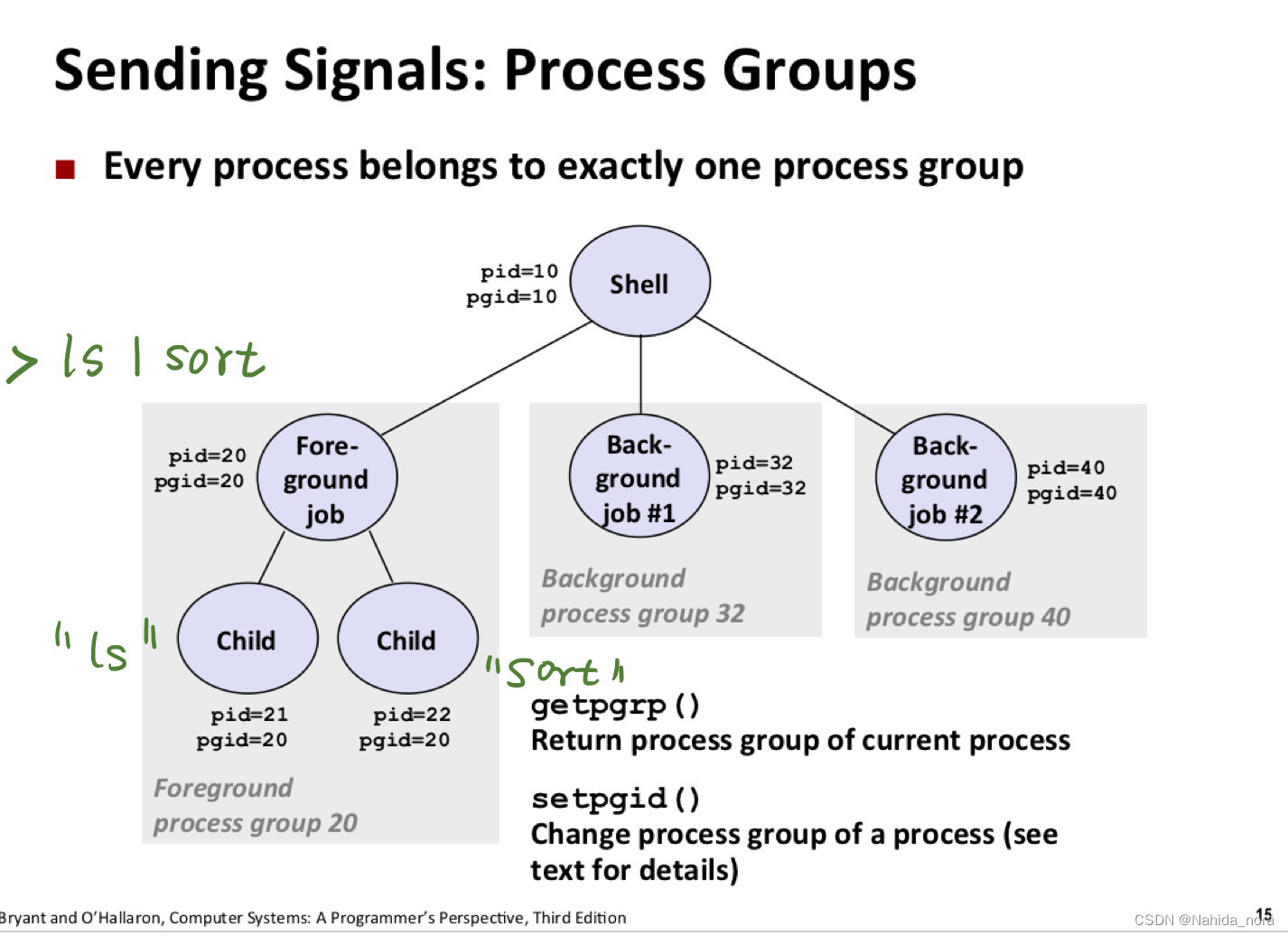
Shell中的作业(job)管理是一种用于跟踪和控制正在运行的进程的机制。Shell通常支持前台任务和后台任务,它们之间有以下差别:
-
前台任务(Foreground Jobs):
- 前台任务是由用户启动并在前台运行的任务。当你在Shell中运行一个命令,它通常会成为前台任务,并且会占用你的终端会话,直到任务完成或被中断。
- 前台任务会接收来自终端的输入,并将其输出显示在终端上。这使得它们非常适合需要与用户交互的任务,例如编辑文本文件或运行交互式程序。
- 要将一个正在运行的前台任务放入后台,你可以使用
Ctrl+Z暂停任务,然后使用bg命令将其放入后台运行。
-
后台任务(Background Jobs):
- 后台任务是在后台(背景)运行的任务,不会占用终端会话。用户可以继续输入其他命令,而不必等待后台任务完成。
- 后台任务通常不接收终端输入,它们的输出通常会被重定向到文件或丢弃。
- 用户可以使用
&符号将一个命令放入后台,例如:command &。
作业管理在shell中的主要目标是允许用户有效地控制和监视正在运行的任务。一些常见的作业管理命令包括:
jobs:显示当前正在运行的作业列表。fg:将一个后台任务切换到前台运行。bg:将一个暂停的前台任务或一个后台任务切换到后台运行。kill:用于终止一个正在运行的作业。nohup:用于在后台运行一个命令,不受终端关闭的影响。disown:从shell的作业表中移除一个作业,使其不再受shell的控制。
作业管理是shell的一个重要功能,允许用户更灵活地处理多个任务,提高了终端的使用效率。不同的shell可能会有不同的作业管理实现方式,但基本概念通常是相似的。
step1 解析用户输入
输入例子:
字符串解析:
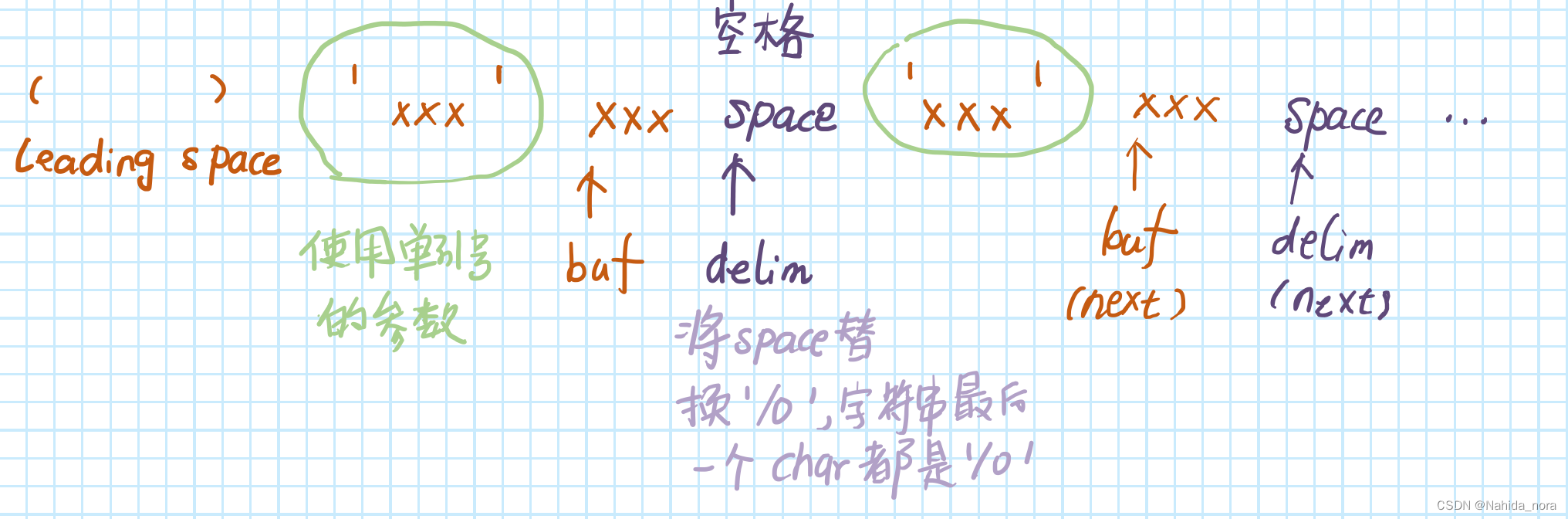
字符串解析函数:
/** parseline - 解析命令行并构建 argv 数组。* * 用单引号括起来的字符被视为一个单独的参数。如果用户请求一个后台作业,则返回 true;如果用户请求一个前台作业,则返回 false。*/
int parseline(const char *cmdline, char **argv)
{static char array[MAXLINE]; /* holds local copy of command line */char *buf = array; /* ptr that traverses command line */char *delim; /* points to first space delimiter */int argc; /* number of args */int bg; /* background job? */printf("parse line : %s", cmdline);strcpy(buf, cmdline);buf[strlen(buf)-1] = ' '; /* replace trailing '\n' with space */while (*buf && (*buf == ' ')) /* ignore leading spaces */buf++;/* Build the argv list */argc = 0;if (*buf == '\'') {buf++;delim = strchr(buf, '\'');}else {delim = strchr(buf, ' ');printf("parse line delim : %s", delim);}while (delim) {argv[argc++] = buf;*delim = '\0';buf = delim + 1;while (*buf && (*buf == ' ')) /* ignore spaces */buf++;if (*buf == '\'') {buf++;delim = strchr(buf, '\'');}else {delim = strchr(buf, ' ');}}argv[argc] = NULL;if (argc == 0) /* ignore blank line */return 1;/* should the job run in the background? */if ((bg = (*argv[argc-1] == '&')) != 0) {argv[--argc] = NULL;}return bg;
}
step2 用户执行指令
ppt中关于shell的指令代码参考:

这个ppt上的代码是简化流程,没有考虑race, 和 error handling等问题。

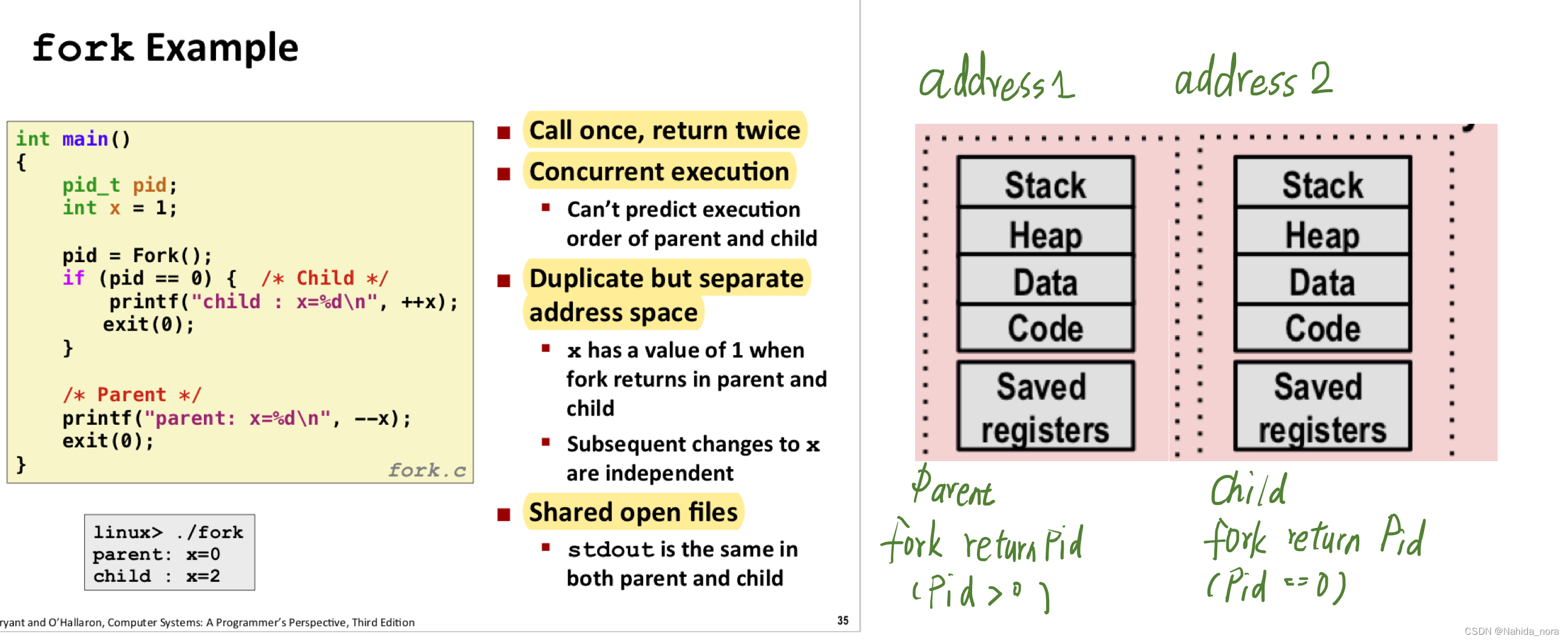
fork 生成的子进程和父进程的内容是一样的,但是pid不同,同时linux 有进程描述符,进程树和进程链表等结构记录进程间关系。fork函数会更新进程树。
全局变量和job数据结构:
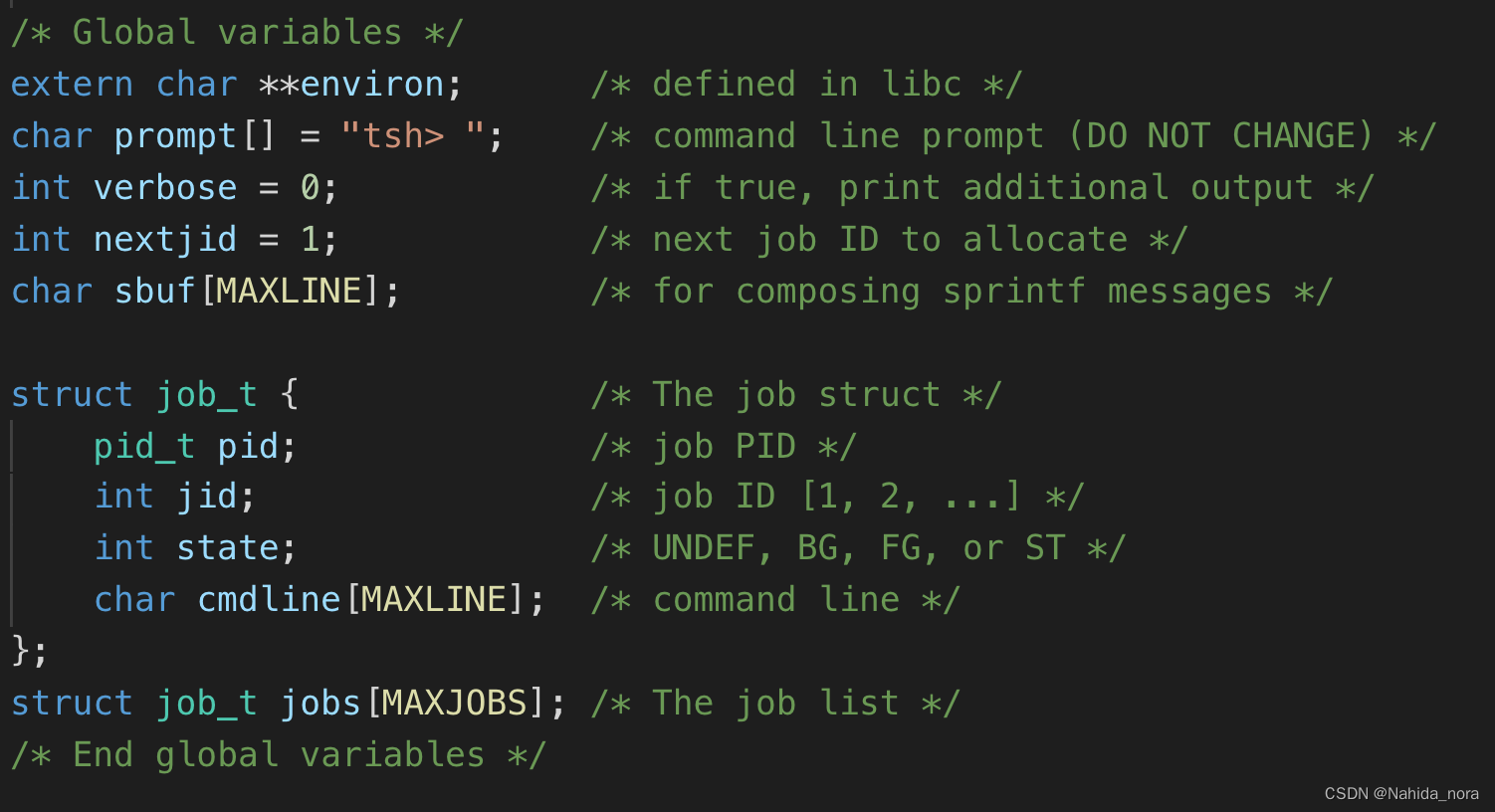
这里简化了pgid 的部分。
setpgid 例子:

命令行中的第一个单词可以是内置命令的名称或可执行文件的路径名。其余的单词是命令行参数。如果第一个单词是一个内置命令,Shell 将立即在当前进程中执行该命令。否则,该单词被假定为可执行程序的路径名。在这种情况下,Shell 将 fork 一个子进程,然后在子进程的上下文中加载并运行该程序。由于解释单个命令行而创建的子进程集合被称为一个作业。一般来说,一个作业可以包含由 Unix 管道连接的多个子进程。

execve 例子:
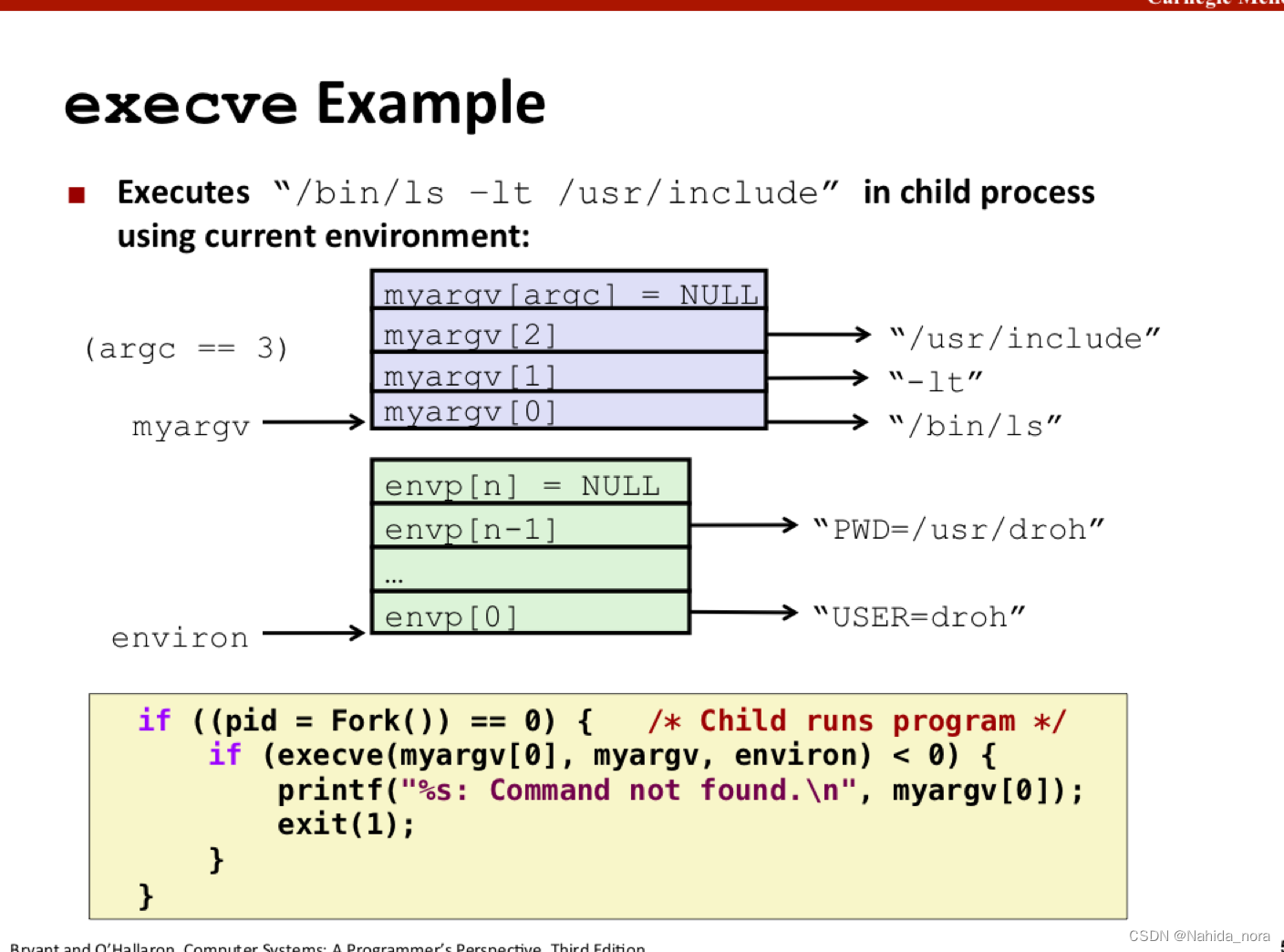
使用fork + execve 函数实现fg 的非builtin cmd。

parent 使用waitpid 函数等待fg job执行结束。waitpid 挂起调用进程的执行,直到其等待集合中的一个子进程终止。
WIFEXITED(status). Returns true if the child terminated normally, via a call to exit or a return.
step3 实现bg和fg
bg 和 fg 的格式
bg 和 fg 命令的参数通常是作业编号(job number)或进程组编号。这些参数用于指定要操作的作业或进程组。以下是一些常见的用法:
-
作业编号(job number):
- 形式为
%n,其中n是作业的编号。 - 例如,
%1表示作业编号为 1 的作业。
bg %1 # 将作业编号为 1 的作业放入后台 fg %2 # 将作业编号为 2 的作业切换到前台 - 形式为
-
进程组编号:
- 进程组编号可以是正整数,表示要操作的进程组的标识符。
- 例如,
bg 1234表示将进程组编号为 1234 的进程组放入后台。
bg 1234 # 将进程组编号为 1234 的进程组放入后台 fg 5678 # 将进程组编号为 5678 的进程组切换到前台
在使用这些参数时,可以通过 jobs 命令查看当前终端会话中的作业及其编号,以便正确指定要操作的目标。例如:
jobs
这将显示当前终端会话中的活动作业及其状态,以帮助确定要用于 bg 和 fg 命令的正确作业编号。
bg 和 fg 的实现
waitpid 函数例子

shell 介绍

在解析了命令行之后,eval 函数调用 builtin_command 函数,该函数检查第一个命令行参数是否是内置的 shell 命令。如果是,则立即解释该命令并返回 1。否则,返回 0。简单 shell 只有一个内置命令,即 quit 命令,用于终止 shell。实际的 shell 有许多命令,例如 pwd、jobs 和 fg。
如果 builtin_command 返回 0,则 shell 创建一个子进程,并在子进程中执行请求的程序。如果用户要求在后台运行程序,则 shell 返回到循环的顶部并等待下一个命令行。否则,shell 使用 waitpid 函数等待作业终止。当作业终止时,shell 继续下一次迭代。
简单的 shell 有一个缺陷,即它不会清理任何后台子进程。纠正这个缺陷需要使用信号。



一个进程可以通过使用 signal 函数来修改与信号关联的默认动作。
处理器(handler)是用户定义的函数的地址,称为信号处理器,每当进程接收到类型为signum的信号时都会调用该函数。通过将处理器的地址传递给signal函数来改变默认操作称为安装处理器(installing handler)。对处理器的调用称为捕获信号(catching signal)。执行处理器被称为处理信号(handling signal)。
当进程捕获到类型为k的信号时,为信号k安装的处理器将以一个整数参数k被调用。这个参数允许相同的处理器函数捕获不同类型的信号。
当处理器执行其返回语句时,控制通常会返回到进程由于接收到信号而被中断的控制流中的指令。因为在某些系统中,中断的系统调用会立即返回一个错误。


信号集(例如set)可以使用以下函数进行操作:sigemptyset 将 set 初始化为空集。sigfillset 函数将所有信号添加到 set 中。sigaddset 函数将 signum 添加到 set 中,sigdelset 删除 set 中的 signum,sigismember 如果 signum 是 set 的成员,则返回1,否则返回0。


addjob和deletejob存在race, 需要确保addjob发生在deletejob之前。


sigsuspend 函数是原子性的,可以更好的避免冲突。
在Sigprocmask 屏蔽前收到signal
在调用 sigprocmask 函数之前收到信号是可能的。sigprocmask 用于修改进程的信号屏蔽集,而不是防止在调用之前收到信号。信号是异步事件,可能会在任何时刻发生,即使在执行 sigprocmask 之前。
如果在执行 sigprocmask 之前收到了一个信号,那么该信号将按照信号的默认处理方式进行处理,除非在信号发生之前设置了信号处理函数或者通过 sigaction 显式设置了信号的处理方式。
sigprocmask 的目的是允许程序员在某个临界区域内阻塞或解除阻塞特定信号,以确保在这个区域内不会受到特定信号的干扰。但是,这并不是一个绝对的保证,因为在执行 sigprocmask 之前和之后都有可能收到信号。
为了更精确地控制信号的处理,可以使用 sigaction 函数来设置信号处理函数,并在处理函数中进行信号屏蔽,以确保在处理信号期间其他相关的信号不会中断当前的处理。这样可以更精确地控制信号的处理流程。
async-signal-safe


“async-signal-safe” 通常是 “asynchronous-signal-safe” 的缩写,指的是在异步信号处理上下文中安全使用的函数。异步信号是在程序执行期间随时发生的,通常是由操作系统或其他部分的程序触发的。由于异步信号可能在任何时候中断程序的正常执行,因此在信号处理程序中只能使用一些特定的函数,这些函数是异步信号安全的,以确保程序的稳定性和可靠性。
异步信号安全的函数通常是那些不使用全局变量、不分配内存、不进行文件 I/O 等可能导致不确定性的操作的函数。这些函数应该是线程安全的,而且不能被其他信号中断。
具体的异步信号安全函数取决于编程语言和操作系统。在C语言中,一些标准的异步信号安全函数包括 write, read, signal, kill, getpid等。在特定的环境中,还可能存在特定的异步信号安全函数。需要查看相关文档以获取更具体的信息。
volatile
在计算机编程中,volatile 是一个关键字,用于告诉编译器不要对标记为 volatile 的变量进行优化。通常,编译器会对变量进行优化,以提高程序的性能和效率。这可能包括将变量的值存储在寄存器中,而不是内存中,或者对变量的访问顺序进行重新排序。
然而,有些变量的值可能会在程序的执行过程中由于外部因素而发生变化,而编译器无法检测到这些变化。这种情况下,如果编译器进行了优化,可能会导致程序出现错误的行为。比如,当一个变量被一个信号处理程序修改时,编译器并不知道这一点,它可能仍然使用之前的值。
在这种情况下,可以使用 volatile 关键字来告诉编译器,这个变量的值可能会在编译器控制之外的情况下发生变化,因此编译器不应该对它进行优化。这样,每次对 volatile 变量的读取和写入都会从内存中进行,而不是从寄存器或者缓存中。
总的来说,volatile 关键字用于标记那些可能会被程序以外的因素修改的变量,以确保编译器不会对其进行错误的优化。
sig_atomic_t
sig_atomic_t 是 C 和 C++ 中的一种整数类型,通常用于信号处理程序中。它被设计为在信号处理程序中原子地访问和修改,以确保线程安全性。
在信号处理程序中,信号可以在任何时候中断程序的正常执行,甚至可能在一个指令级的操作中间发生。这就需要确保对共享数据的访问是原子的,即要么完全执行,要么不执行。因此,sig_atomic_t 类型被设计为足够大以容纳任何信号值,并且在对其进行读取和写入时是原子的。
通常,sig_atomic_t 用于信号处理程序中的全局变量,以确保当处理信号时,对它们的访问是线程安全的。虽然在信号处理程序中仍然需要小心地处理共享数据,但使用 sig_atomic_t 类型可以确保对这些数据的访问是原子的,不会导致竞态条件或其他并发问题。
需要注意的是,sig_atomic_t 并不保证具有原子性的操作范围扩展到它所覆盖的所有操作系统和平台。在某些情况下,可能需要额外的同步机制来确保对共享数据的安全访问。
系统调用是可以收到signal
系统调用是用户空间程序与内核之间的接口,它们允许用户空间程序请求内核执行某些特权操作。当系统调用执行时,用户空间程序的控制权转移到内核空间,内核执行相应的操作,然后将控制返回给用户空间程序。
在执行系统调用期间,用户空间程序可以收到各种信号,具体取决于系统和应用程序的实现。一些可能的情况包括:
-
SIGSEGV(段错误):如果系统调用尝试访问无效的内存区域,可能会导致段错误信号。 -
SIGALRM(定时器信号):某些系统调用可能设置了定时器,当定时器到期时,会收到SIGALRM信号。 -
SIGKILL、SIGTERM等:某些系统调用可能会在错误或异常情况下导致进程终止信号。 -
SIGPIPE:如果系统调用尝试向已关闭的管道写入数据,可能会收到SIGPIPE信号。
关于你提到的慢系统调用被中断时可能产生的信号,通常是SIGINT(中断信号)。当进程受到SIGINT信号时,系统调用可能被中断,具体取决于系统的实现。
需要注意的是,不同的操作系统和实现可能有不同的行为,因此在编写跨平台的代码时,程序员需要仔细处理与信号相关的情况。
execve 函数

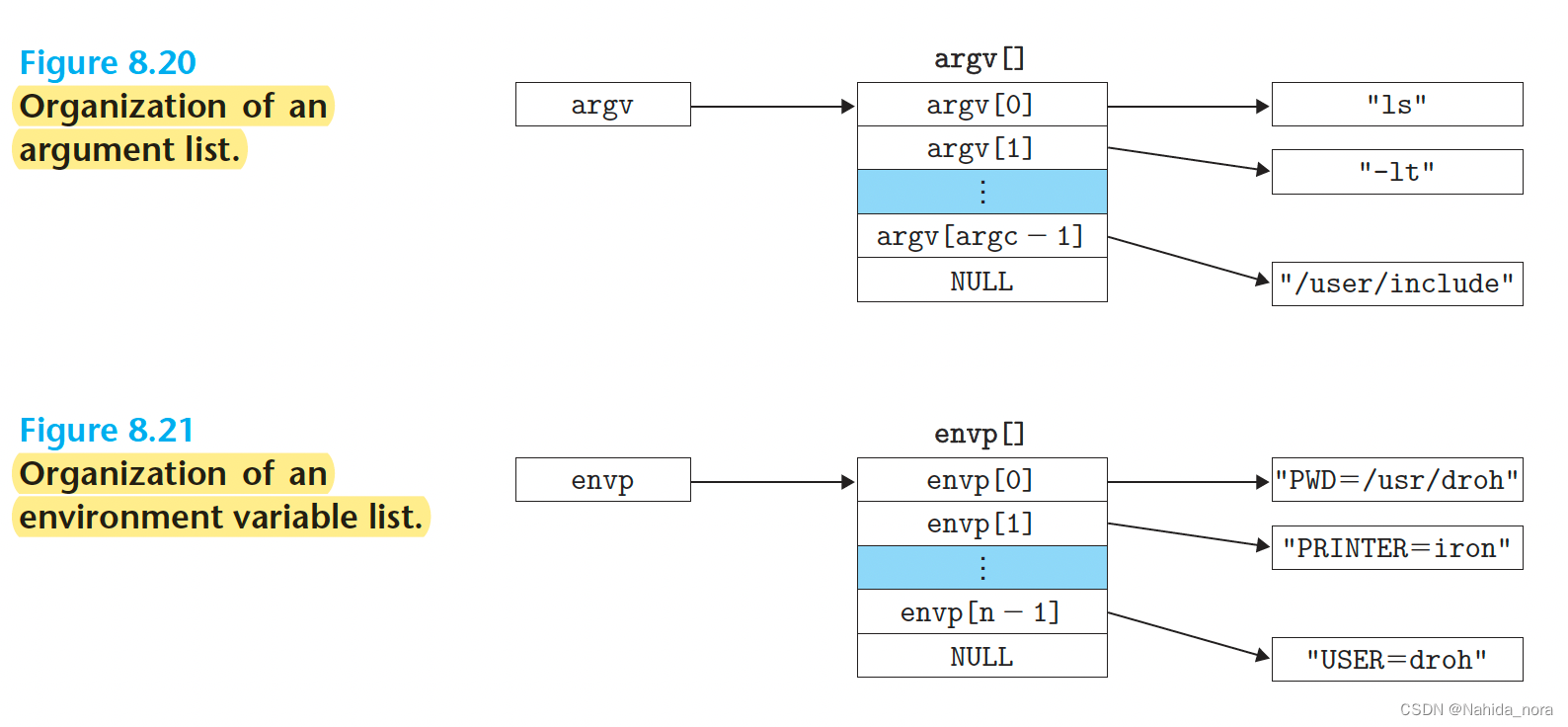
在调用execve后,它加载文件名(指定的可执行文件),然后调用了第7.9节中描述的启动代码。启动代码负责设置栈,并将控制传递给新程序的主例程。新程序的主例程通常具有以下形式的原型:
int main(int argc, char *argv[], char *envp[]);
这是main函数的标准原型,其中:
int argc是命令行参数的数量(argument count)。char *argv[]是一个指向参数字符串的数组(argument vector)。char *envp[]是一个指向环境变量字符串的数组(environment pointer)。
这个main函数是新程序的入口点,它接收命令行参数,并执行程序的主要逻辑。在启动过程中,启动代码负责准备好这些参数,然后将控制传递给main函数,使得新程序能够开始执行。
"主例程"通常指的是一个程序的主要执行入口点,即程序的主函数。在C语言中,主函数通常被命名为main,是程序运行时的起始点。
主例程执行程序的主要逻辑,它是程序中首先被执行的函数。
主例程在程序启动时首先被调用,它执行程序的主要功能,并可以调用其他函数来完成特定任务。在程序执行结束时,main函数返回一个整数值,表示程序的执行状态,该值被传递给操作系统。
strcpy 函数
strcpy 函数是C语言中字符串操作的标准库函数之一,用于将一个字符串复制到另一个字符串中。函数的原型如下:
#include <string.h>char *strcpy(char *dest, const char *src);
dest:目标字符串,即要将源字符串拷贝到的位置。src:源字符串,即要被拷贝的字符串。
函数的作用是将源字符串(src)中的字符复制到目标字符串(dest)中,直到遇到源字符串的空字符 \0 为止。最终得到的目标字符串也是以空字符结尾的。strcpy 返回目标字符串的起始地址(即 dest 的值)。
需要注意的是,strcpy 函数不会检查目标字符串的长度是否足够容纳源字符串的内容,因此使用时需要确保目标字符串足够大以避免溢出。
下面是一个简单的示例:
#include <stdio.h>
#include <string.h>int main() {char source[] = "Hello, World!";char destination[20]; // 目标字符串要足够大strcpy(destination, source);printf("Source: %s\n", source);printf("Destination: %s\n", destination);return 0;
}
在这个例子中,strcpy 被用来将 source 中的内容复制到 destination 中。如果 destination 的长度不足,可能会导致缓冲区溢出的问题,因此在实际使用中应该确保目标字符串足够大。为了更安全的字符串操作,可以使用 strncpy 函数,该函数允许指定要复制的最大字符数,从而避免溢出的风险。
通过char *指针遍历char []
通过 char * 指针遍历 char [] 数组是一种常见的C语言操作。字符串在C中通常以char数组的形式表示,以空字符 '\0' 结尾。你可以使用指针来遍历这个数组,直到遇到空字符为止。
下面是一个简单的示例,演示如何通过 char * 指针遍历 char [] 数组:
#include <stdio.h>int main() {// 定义一个字符数组char myString[] = "Hello, World!";// 使用 char * 指针遍历数组char *ptr = myString;// 遍历数组,直到遇到空字符while (*ptr != '\0') {printf("%c ", *ptr);ptr++; // 移动指针到下一个字符}printf("\n");return 0;
}
在这个例子中,char *ptr 指向字符串 myString 的开头,然后通过循环遍历数组中的每个字符,直到遇到空字符为止。printf 语句用于打印每个字符,ptr++ 用于将指针移动到数组中的下一个字符。
这种方式是C语言中经常使用的遍历字符串的方法,利用指针的特性逐个访问字符。需要注意的是,在使用指针遍历数组时,确保数组以空字符结尾,以便知道何时结束遍历。
strchr 函数介绍
strchr 函数是C语言标准库中的一个字符串查找函数,用于在字符串中查找指定字符的第一次出现位置。函数的原型如下:
#include <string.h>char *strchr(const char *str, int c);
str:要在其中查找的字符串。c:要查找的字符。
函数返回一个指向找到的字符的指针,如果未找到字符,则返回空指针(NULL)。strchr 会从 str 字符串的开头开始查找,一直向后,直到找到第一个与 c 匹配的字符,或者查找到字符串的末尾(即空字符 \0)。返回的指针指向匹配字符的位置,可以用于进一步操作或索引。
以下是一个示例,演示如何使用 strchr 函数:
#include <stdio.h>
#include <string.h>int main() {char myString[] = "Hello, World!";char *ptr = strchr(myString, 'o');if (ptr != NULL) {printf("Found 'o' at position %ld\n", ptr - myString);} else {printf("'o' not found in the string\n");}return 0;
}
在这个例子中,我们在字符串 myString 中查找字符 'o' 的位置,然后打印出字符 'o' 在字符串中的位置。如果字符 'o' 未找到,strchr 将返回空指针,我们可以通过检查返回值是否为 NULL 来判断是否找到了字符。
strchr 还可以用来查找其他字符,不仅仅是单个字符,例如可以用它来查找特定的子字符串的首次出现位置。
字符串比较函数
在C语言中,字符串比较通常使用标准库中的 strcmp 函数。以下是 strcmp 函数的简单用法:
#include <string.h>int strcmp(const char *str1, const char *str2);
该函数接受两个字符串 str1 和 str2 作为参数,并返回一个整数值,表示两个字符串的比较结果。返回值如下:
- 如果
str1等于str2,则返回 0。 - 如果
str1小于str2,则返回负值。 - 如果
str1大于str2,则返回正值。
示例:
#include <stdio.h>
#include <string.h>int main() {char str1[] = "hello";char str2[] = "world";int result = strcmp(str1, str2);if (result == 0) {printf("Strings are equal.\n");} else if (result < 0) {printf("str1 is less than str2.\n");} else {printf("str1 is greater than str2.\n");}return 0;
}
在上面的示例中,strcmp 用于比较两个字符串 str1 和 str2 的大小关系。根据比较结果,程序输出相应的消息。
操作系统和信号处理
操作系统通过信号(signal)机制来向程序发送异步通知,以实现一些特定事件的处理。当程序收到信号时,它可以执行与该信号相关的特定操作。下面是操作系统如何通过信号通知程序的一般步骤:
-
信号的生成: 信号通常由操作系统、其他进程,或者硬件事件生成。例如,用户按下 Ctrl+C 时,产生的
SIGINT信号就是一个由操作系统生成的信号。 -
信号传递: 一旦信号生成,操作系统将尝试将信号传递给目标进程。这包括了找到目标进程的进程标识符(PID)等步骤。
-
信号的接收: 目标进程通过注册信号处理器来声明对特定信号的兴趣。如果目标进程没有注册信号处理器,那么系统将执行默认的信号处理行为。
-
信号处理器的执行: 如果目标进程注册了信号处理器,当信号到达时,操作系统会调用与之相关联的处理函数。这个函数中包含了程序在接收到该信号时应该执行的逻辑。
-
程序状态的改变: 信号处理器执行完成后,程序可能会根据信号类型执行特定的操作,如终止程序、清理资源、修改全局状态等。这取决于信号类型和程序的设计。
需要注意的是,信号是一种异步机制,因此处理信号的过程并不是程序按照正常顺序执行的一部分。操作系统会在程序当前执行的任何地方中断它,然后执行信号处理器。这为程序提供了一种在发生异步事件时执行相应操作的机制。
值得注意的是,程序可以选择忽略某些信号或自定义对信号的处理方式,从而灵活地控制程序在不同情境下的行为。
pending signal
在操作系统中,pending signals(待处理的信号)是指已经被发送给进程但尚未被处理的信号。处理 pending signals 的时机通常有两个关键点:
-
信号传递时机: 当一个信号被发送给进程时,它首先被标记为 pending(等待处理)。然而,该信号不会立即中断进程的正常执行。相反,系统会选择一个合适的时机来传递并处理这个信号。这个时机通常是在进程执行系统调用、陷入内核、或者发生某种事件(如时钟中断)时。
-
系统调用返回时: 在某些情况下,pending signals 的处理被推迟到系统调用返回时。这是因为在系统调用期间,进程可能会处于临界区(critical section),其中一些操作是不可中断的。因此,系统可能选择在系统调用完成后,但在返回到用户空间之前处理 pending signals。
在处理 pending signals 时,有几个相关的概念:
-
信号阻塞(Signal Blocking): 进程可以选择阻塞(block)某些信号,使得这些信号在阻塞期间不会被处理。当信号被阻塞时,它们会被放入 pending signals 队列中。一旦解除阻塞,这些 pending signals 就有机会被处理。
-
信号屏蔽字(Signal Mask): 信号屏蔽字是一个位掩码,用于表示当前被阻塞的信号集合。通过修改信号屏蔽字,进程可以动态地控制哪些信号是阻塞的,哪些是未阻塞的。
-
信号处理器(Signal Handler): 对于每个信号,进程可以注册一个信号处理器。当信号被处理时,相应的处理器函数会被调用。
总体而言,处理 pending signals 是由操作系统负责的,但开发人员可以通过注册信号处理器和修改信号屏蔽字来对信号的处理进行控制。处理信号的时机和方式可以受到操作系统的调度策略、信号处理器的注册情况以及信号的优先级等多个因素的影响。
signal handler 需要上下文切换吗?
在信号处理器(Signal Handler)中是否需要进行上下文切换,取决于信号的类型以及信号处理器的执行上下文。
一般来说,信号处理器是在中断上下文(Interrupt Context)中执行的,而不是在用户进程的正常执行上下文中。中断上下文是指在内核执行的上下文,而不是在用户空间执行的上下文。当信号发生时,内核会中断当前进程的执行,转而执行与该信号相关联的信号处理器。
由于信号处理器在中断上下文中执行,通常情况下并不涉及用户进程的完整上下文切换。然而,有一些情况可能导致信号处理器需要访问用户进程的上下文信息,例如处理 SIGSEGV(段错误)信号时需要确定引起段错误的地址。在这种情况下,可能需要一部分上下文切换,以便信号处理器能够访问用户进程的内存和状态信息。
需要注意的是,一些信号可能会异步地中断用户进程的正常执行,而其他信号可能会在进程主动执行系统调用或发生其他特定事件时被处理。这些差异可能导致信号处理器在不同的上下文中执行。
总的来说,信号处理器的执行上下文通常是中断上下文,但在处理某些信号时可能涉及到一定程度的上下文切换,以便访问用户进程的信息。
signal预定义的默认动作
预定义的默认动作是每种信号类型在发生时由内核自动执行的默认行为。以下是一些常见信号的默认动作:
- SIGTERM(终止信号):默认动作是终止进程。
- SIGSEGV(段错误信号):默认动作是终止进程并转储核心。
- SIGSTOP(停止信号):默认动作是暂停进程,只能由 SIGCONT 信号重新启动。
- SIGKILL(强制终止信号):默认动作是强制终止进程,不能被捕获、忽略或阻塞。
- SIGCONT(继续信号):默认动作是继续(恢复)之前被停止的进程。
虽然大多数信号有默认动作,但有一些信号可以通过信号处理器来捕获、忽略或自定义处理。通过使用 signal() 系统调用或 sigaction() 函数,可以为进程中的特定信号设置自定义的信号处理函数。这样,当信号发生时,不会执行默认动作,而是执行相应的信号处理函数。
#include <signal.h>void custom_signal_handler(int signo) {// 自定义的信号处理函数逻辑
}int main() {// 设置自定义的信号处理函数signal(SIGTERM, custom_signal_handler);// 此处可以执行其他初始化操作// 主循环或其他程序逻辑return 0;
}
请注意,对于某些信号,例如 SIGKILL,是不能被捕获或忽略的,因为它们设计为终止进程的一种强制手段。
sigaction 函数
sigaction 是一个用于设置和检查信号处理程序的系统调用。它提供了一种更强大和可移植的方式来处理信号,相对于较旧的 signal 函数而言。
下面是 sigaction 函数的基本介绍:
#include <signal.h>int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
signum:指定要操作的信号的编号。act:指向一个struct sigaction结构体的指针,用于设置新的信号处理程序及相关的属性。oldact:可选参数,指向一个struct sigaction结构体的指针,用于存储之前的信号处理程序及相关的属性。
struct sigaction 的定义如下:
struct sigaction {void (*sa_handler)(int); // 指定信号处理函数的地址void (*sa_sigaction)(int, siginfo_t *, void *); // 指定带有三个参数的信号处理函数的地址sigset_t sa_mask; // 设置在信号处理函数执行期间要阻塞的信号集int sa_flags; // 设置信号处理的各种标志void (*sa_restorer)(void); // 恢复处理函数
};
关键字段解释:
sa_handler:指定普通的信号处理函数的地址。可以设置为SIG_DFL(默认处理)或SIG_IGN(忽略信号)。sa_sigaction:如果非空,将调用具有三个参数的信号处理函数,而不是sa_handler。sa_mask:指定在信号处理函数执行期间要阻塞的信号集。sa_flags:用于设置信号处理的各种标志,例如SA_RESTART(如果系统调用被中断,自动重启)。sa_restorer:不再被使用。
sigaction 的返回值为 0 表示成功,-1 表示失败。失败时,可以使用 errno 变量获取错误信息。
sigaction 提供了更灵活和可靠的信号处理方式,因此在编写信号处理代码时,通常优先使用 sigaction 而不是较旧的 signal 函数。
linux 有什么数据结构可以记录父子进程关系
在Linux系统中,除了PID外,操作系统通过进程表(Process Table)来维护进程间的关系,其中包括父子进程关系。在内核中,进程表是用数据结构来管理和维护进程的信息的,这些信息包括进程的状态、PID、父进程的PID等。
Linux内核中常用的数据结构用于记录父子关系的有:
-
进程描述符(Process Descriptor):在Linux内核中,每个进程都有一个进程描述符,这个描述符存储了关于进程的各种信息,包括PID、父进程的PID等。这个数据结构通常是一个 C 语言的结构体,在内核中被称为
task_struct。 -
进程树(Process Tree):进程树是一个树状结构,用于表示进程之间的父子关系。在Linux系统中,进程树是由内核动态维护的,通过父进程的PID和子进程的PID之间的关系构建。通常,父进程的PID会被记录在子进程的进程描述符中。
-
进程链表(Process List):进程链表是操作系统内核中的一种数据结构,用于存储系统中所有活跃进程的指针或引用。通过这种链表,内核可以访问和管理系统中的所有进程,包括父子关系。
通过这些数据结构,操作系统可以轻松地识别父子进程之间的关系,并对它们进行适当的管理和调度。
shell 的biuiltin 命令
在Shell中,前台进程(foreground process)通常是由Shell启动并直接与用户交互的进程。内置命令(builtin commands)是由Shell自身提供并在Shell进程中执行的命令,而不是通过外部可执行文件的方式执行。
对于内置命令,Shell会直接处理,而不需要创建一个新的子进程。这与外部命令不同,外部命令通常需要通过fork和exec系统调用创建新的进程并在其中执行外部程序。
对于像 jobs 这样的内置命令,Shell会在其自身的上下文中执行,而不是启动一个新的进程。这使得内置命令能够直接访问Shell的内部数据结构和状态,如作业表(job table)。
在实现中,Shell会维护一个作业表,其中记录了当前正在运行和已经结束的作业的信息,包括作业的状态、PID等。当用户输入 jobs 命令时,Shell会查询作业表,并输出相应的信息。
总体来说,内置命令的执行通常不涉及新的进程创建,而是直接在Shell进程中执行。这样可以更轻量和高效地处理用户的命令,尤其是那些与Shell状态和环境交互密切相关的命令。
execve 函数返回值
execve 函数在成功执行时不返回,而是将当前进程的映像替换为新程序,因此它永远不会返回。如果 execve 函数返回,这意味着它发生了错误。在这种情况下,它返回 -1,并设置全局变量 errno 表示具体的错误类型。你可以使用 <errno.h> 头文件来查找和解释错误。
例如,可以使用以下方式处理错误:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>int main() {char *args[] = {"ls", "-l", NULL};if (execve("/bin/ls", args, NULL) == -1) {perror("execve");exit(EXIT_FAILURE);}// This code is unreachable if execve is successful.exit(EXIT_SUCCESS);
}
在这个例子中,如果 execve 失败,perror 函数将打印相关的错误信息,然后程序通过 exit(EXIT_FAILURE) 退出。如果 execve 成功,那么程序不会继续执行到这个部分。
waitpid 函数例子
waitpid 函数是一个在 Unix/Linux 系统中用于等待子进程结束并获取其状态的系统调用。它允许父进程指定要等待的子进程的进程ID,并提供了一些额外的选项来控制等待的行为。
函数原型如下:
#include <sys/types.h>
#include <sys/wait.h>pid_t waitpid(pid_t pid, int *status, int options);
-
pid参数指定要等待的子进程的进程ID。有几种可能的值:< -1: 等待进程组ID等于pid绝对值的任何子进程。-1: 等待任何子进程,类似于wait函数。0: 等待与调用进程在同一进程组的任何子进程。> 0: 等待指定进程ID的子进程。
-
status参数是一个指向整数的指针,用于存储子进程的退出状态。这是一个输出参数。 -
options参数用于提供一些额外的选项,例如:WNOHANG: 如果没有子进程退出,则立即返回,而不阻塞等待。WUNTRACED: 也等待已经停止的子进程的信息。
waitpid 函数的返回值表示等待的子进程的进程ID,如果出错则返回 -1。
以下是一个简单的例子,演示了 waitpid 函数的基本用法:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>int main() {pid_t childPid, waitPid;int status;if ((childPid = fork()) == 0) {// Child processprintf("Child process with PID: %d\n", getpid());exit(EXIT_SUCCESS);} else if (childPid > 0) {// Parent processprintf("Parent process with PID: %d\n", getpid());// Wait for the child process to finishwaitPid = waitpid(childPid, &status, 0);if (waitPid == -1) {perror("waitpid");exit(EXIT_FAILURE);}if (WIFEXITED(status)) {printf("Child process exited with status: %d\n", WEXITSTATUS(status));} else if (WIFSIGNALED(status)) {printf("Child process terminated by signal: %d\n", WTERMSIG(status));} else if (WIFSTOPPED(status)) {printf("Child process stopped by signal: %d\n", WSTOPSIG(status));}} else {perror("fork");exit(EXIT_FAILURE);}return 0;
}
在这个例子中,父进程创建了一个子进程,然后使用 waitpid 等待子进程的结束。它打印出子进程的退出状态,包括是否正常退出、被信号终止还是被信号停止。
setpgid 函数
setpgid 函数用于设置进程组ID(Process Group ID)。这个函数通常用于创建新的进程组或将一个进程添加到一个已存在的进程组中。setpgid 的原型如下:
int setpgid(pid_t pid, pid_t pgid);
pid参数是指定的进程的进程ID(Process ID)。pgid参数是指定的进程组的进程组ID(Process Group ID)。
函数的作用是将指定的进程(由 pid 参数指定)加入到指定的进程组(由 pgid 参数指定)中。如果 pgid 参数为 0,表示将指定的进程加入到其父进程的进程组中,这通常用于创建新的进程组。
这个函数在进程管理和作业控制中常常使用。例如,当你在一个终端中启动一个进程时,这个进程通常会成为一个新的进程组的领头进程,而其他与之关联的进程将成为这个进程组的成员。
这里有一个简单的例子,演示了 setpgid 的用法:
#include <stdio.h>
#include <unistd.h>int main() {pid_t pid = fork();if (pid == 0) {// Child processprintf("Child process, PID: %d\n", getpid());// Set the process group ID to its own PIDsetpgid(0, 0);// Child process logic goes here...} else if (pid > 0) {// Parent processprintf("Parent process, PID: %d\n", getpid());// Parent process logic goes here...} else {// Error handling if fork failsperror("fork");}return 0;
}
在这个例子中,子进程通过 setpgid(0, 0) 将自己放入一个新的进程组中,进而脱离了父进程的进程组。
bg和fg
bg 和 fg 是用于在Unix/Linux系统中控制作业(jobs)的命令。这两个命令通常与终端中运行的进程相关联,用于在前台(foreground)和后台(background)之间切换进程的状态。
-
bg命令:-
功能:
bg命令用于将一个在后台暂停(stopped)的作业重新放入后台运行。它将作业编号(job number)或进程组编号作为参数,并将该作业放入后台运行,使其继续执行。 -
实现:可以通过以下方式使用
bg命令:bg %job_number其中
%job_number是作业的编号(可以使用jobs命令查看)。例如:bg %1这将把编号为 1 的作业放入后台继续执行。
-
-
fg命令:-
功能:
fg命令用于将一个作业从后台切换到前台继续执行。它也接受作业编号或进程组编号作为参数,并将指定的作业切换到前台。 -
实现:可以通过以下方式使用
fg命令:fg %job_number其中
%job_number是作业的编号。例如:fg %1这将把编号为 1 的作业切换到前台继续执行。
-
在实现上,这两个命令的核心是通过向作业发送信号来改变作业的状态。在后台运行的作业通常会收到 SIGTSTP 信号使其停止,而 bg 命令则发送 SIGCONT 信号以恢复其执行。fg 命令则将作业移到前台并发送 SIGCONT 信号。
一个简单的例子如下:
# 在后台运行一个命令
$ sleep 100 &
[1] 1234 # [1] 是作业编号,1234 是进程号# 使用 bg 命令将作业放入后台
$ bg %1# 使用 fg 命令将作业切换到前台
$ fg %1
这里,bg 和 fg 命令的执行改变了作业的状态,使其在前台和后台之间切换。