在本章中,您将了解Linux提供的进程间通信(IPC)接口。通过它们,您将全面了解如何满足系统和软件需求。首先,您将学习消息队列(MQs),这是对[第3章]中关于管道的讨论的延续。此外,我们将详细分析信号量和互斥锁同步技术的工作原理。我们将向您介绍C++20在这一领域的一些新特性,这些特性易于使用,您无需自行实现。
接着,我们将介绍共享内存技术,它可以让您快速传输大量数据。最后,如果您对网络上计算机系统间的通信感兴趣,您将了解套接字和网络通信协议。有了这些知识,我们将为您提供一些实用的命令,以便您在网络上管理自己的系统。
我们将在[第9章]中继续本章开始的讨论。
本章将涵盖以下主要主题:
- 介绍MQs和发布/订阅机制
- 通过信号量和互斥锁保证原子操作
- 使用共享内存
- 通过网络套接字进行通信
技术要求
为了运行代码示例,您需要准备以下内容:
- 一台能够编译和执行C++20的基于Linux的系统(例如,Linux Mint 21)
- GCC 12.2编译器(https://gcc.gnu.org/git/gcc.git gcc-source)并使用
-std=c++2a、-lpthread和-lrt标志 - 对于所有示例,您也可以使用 https://godbolt.org/
- 代码链接:https://share.xueplus.com/s/9fXDVv-4fijh.html
介绍MQs和发布/订阅机制
我们很高兴再次讨论IPC主题。上次我们在[第3章]中讨论了管道,并使用了一些代码示例。您了解了进程间交换数据的基本机制,但如您所记,存在一些阻塞点。就像任何编程工具一样,管道有其特定用途——它们快速,可以帮助您从相关(forked)进程(通过匿名管道)和不相关进程(通过命名管道)发送和接收数据。
同样,我们可以使用MQs传输数据,它们也适用于相关和不相关的进程。它们提供了将单个消息发送到多个接收进程的能力。但正如您所见,管道在发送和接收二进制数据方面是原始的,而MQs则引入了消息的概念。传输策略仍然在调用过程中配置——队列名称、大小、信号处理、优先级等——但其策略和序列化数据的能力现在由MQ的实现掌握。这为程序员提供了一种相对简单且灵活的方式来准备和处理数据消息。根据我们的软件设计,我们可以轻松实现异步的发送接收数据传输或发布/订阅(pub/sub)机制。Linux为MQs提供了两种不同的接口——一种来自System V,用于本地服务器应用,另一种来自POSIX,用于实时应用。出于本书的目的,我们更倾向于使用POSIX接口,因为它在配置上更丰富、更清晰。它也是一种基于文件的机制,正如我们在[第1章]中讨论的,您可以通过以下方式找到一个已挂载的队列:
$ ls /dev/mqueue
此接口可通过操作系统实时函数库librt获得,因此您需要在编译时链接它。MQ本身可以如下可视化:
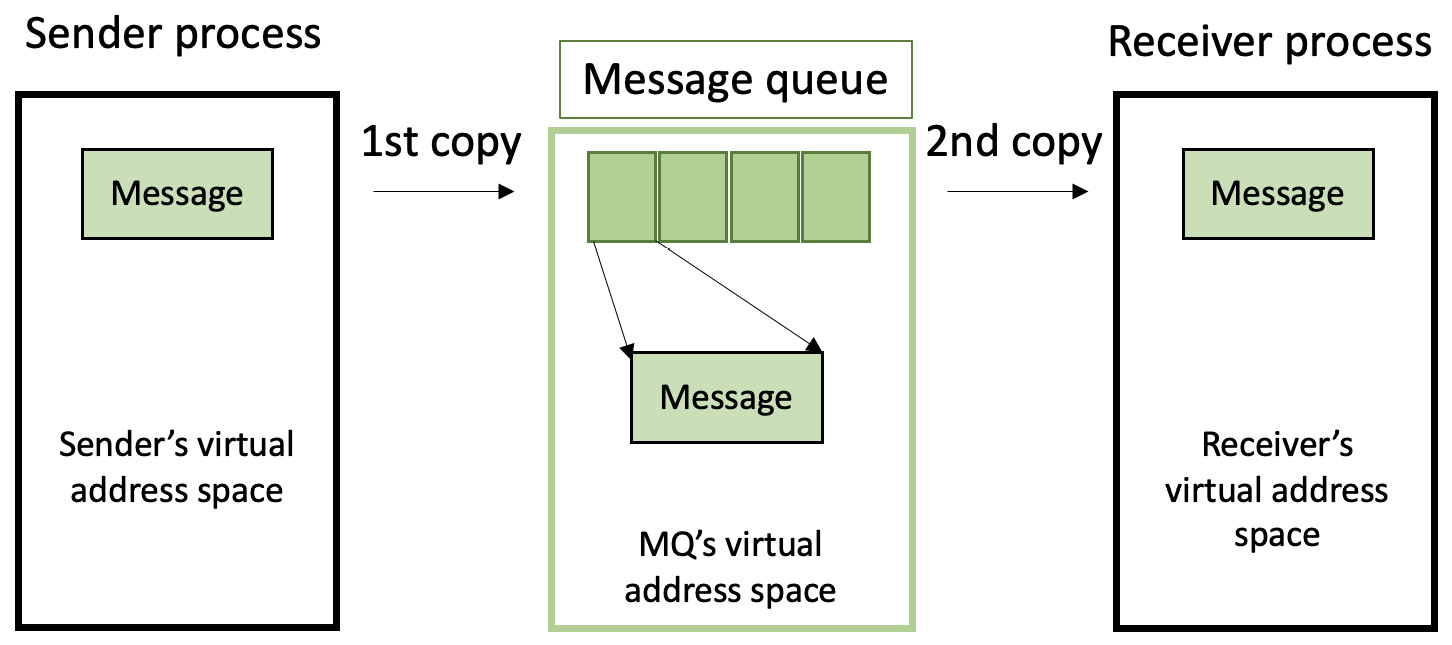
图 7.1 – 通过 MQ 表示 IPC
让我们来看一个示例,我们从一个进程发送数据到另一个进程。示例数据已经存储在文件中,并加载通过MQ发送。
constexpr auto MAX_SIZE = 1024;
string_view QUEUE_NAME = "/test_queue";
我们将初始配置和队列名称作为路径名一起设置:
void readFromQueue() {
...mqd_t mq = { 0 };struct mq_attr attr = { 0 };array<char, MAX_SIZE> buffer{};attr.mq_flags = 0;attr.mq_maxmsg = 10;attr.mq_msgsize = MAX_SIZE;attr.mq_curmsgs = 0;if (mq = mq_open(QUEUE_NAME.data(), O_CREAT | O_RDONLY,0700, &attr); mq > -1) { // {1}for (;;) {if (auto bytes_read = mq_receive(mq,buffer.data(),buffer.size(),NULL);bytes_read > 0) { // {2}buffer[bytes_read] = '\0';cout << "Received: "<< buffer.data()<< endl; // {3}}else if (bytes_read == -1) {cerr << "Receive message failed!";}
对MQ进行了额外的配置,并准备好接收端。调用mq_open()函数以在文件系统上创建MQ并打开其读取端。通过一个无限循环,当从二进制文件读取数据时接收数据,并打印出来(前面代码中的标记{2}和{3}),直到文件完全消耗。然后,关闭接收端和读取端(以下代码中的标记{4})。如果没有其他事情要做,通过mq_unlink()从文件系统中删除MQ:
else {cout << "\n\n\n***Receiving ends***"<< endl;mq_close(mq); // {4}break;}}}else {cerr << "Receiver: Failed to load queue: "<< strerror(errno);}mq_unlink(QUEUE_NAME.data());
}
这个示例是用两个线程实现的,但也可以用两个进程以相同方式完成。MQ的功能将保持不变。我们再次调用mq_open()并打开MQ以进行写入(以下代码中的标记{5})。创建的队列最多可容纳10条消息,每条消息可达1024字节大小——这是通过前面代码片段中的MQ属性定义的。如果您不希望MQ操作阻塞,可以在属性中使用O_NONBLOCK标志,或者在mq_receive()调用之前使用mq_notify()。这样,如果MQ为空,读取器将被阻塞,但mq_notify()将在消息到达时触发信号,进程将恢复。
然后,使用测试数据打开本地存储的文件,并从中读取(以下代码中的标记{6}和{7})。当我们读取时(您也可以使用std::ofstream),我们通过MQ发送其内容(以下代码中的标记{8})。消息的优先级最低,即0。在队列中有更多消息的系统中,我们可以设置更高的优先级,它们将按降序处理。最大值可以从sysconf(_SC_MQ_PRIO_MAX)中看到,对于Linux,这是32768,但POSIX为了符合其他操作系统的要求,也强制从0到31的范围。让我们检查以下代码片段:
void writeToQueue() {
...if (mq = mq_open(QUEUE_NAME.data(), O_WRONLY,0700, NULL); mq > -1) { // {5}int fd = open("test.dat", O_RDONLY); // {6}if (fd > 0) {for (;;) {// This could be taken from cin.array<char, MAX_SIZE> buffer{};if (auto bytes_to_send =read(fd,buffer.data(),buffer.size());bytes_to_send > 0) { // {7}if (auto b_sent =mq_send(mq,buffer.data(),buffer.size(),0);b_sent == -1) {// {8}cerr << "Sent failed!"<< strerror(errno);}
然后,我们发送一个零大小的消息来表示通信的结束(以下代码中的标记{9}):
...else if (bytes_to_send == 0) {cout << "Sending ends...." << endl;if (auto b_sent =mq_send(mq,buffer.data(),0,0); b_sent == -1) {// {9}cerr << "Sent failed!"<< strerror(errno);
结果如下(从文件中打印的数据为了可读性而减少):
Thread READER starting...
Thread WRITER starting...
Sending ends....
Received: This is a testing file...
Received: ing fileThis is a testing file...
***Receiving ends***
Main: program completed. Exiting.
这是一个非常简单的示例,考虑到我们只有两个工作器——readFromQueue()和writeToQueue()。MQs允许我们扩展并执行多对多通信。这种方法可以在许多嵌入式系统中找到,因为它也符合实时要求,并且不需要使用任何同步原语。许多微服务架构和无服务器应用都依赖于它。在下一节中,我们将讨论基于MQs的最流行模式之一。
发布/订阅机制
您可能已经意识到,当扩展时,一个MQ可能会成为瓶颈。正如您在前一个示例中观察到的,存在消息数量和大小的限制。另一个问题是,消息一旦被消费,就会从队列中移除——一次只能有一个消费者消费给定的消息。数据提供者(生产者)还必须管理正确的消息地址,这意味着添加额外的数据以帮助消费者识别消息发送给谁,每个消费者都必须遵循该策略。
首选的方法是为每个消费者创建一个单独的MQ。生产者将事先知道这些MQ,要么在编译时(所有MQ由系统程序员在数据段中列出),要么在运行时(每个消费者在启动时发送其MQ路径名,生产者将处理这些信息)。这样,消费者就是在订阅从给定生产者那里接收数据,而生产者则将其数据发布到它所知道的所有MQ。因此,我们称之为发布-订阅机制。
当然,具体实现可能会有所不同,这取决于软件设计,但理念将保持不变。此外,可能有多个生产者向多个消费者发送数据,我们称这是多对多实现。请看下面的图表:
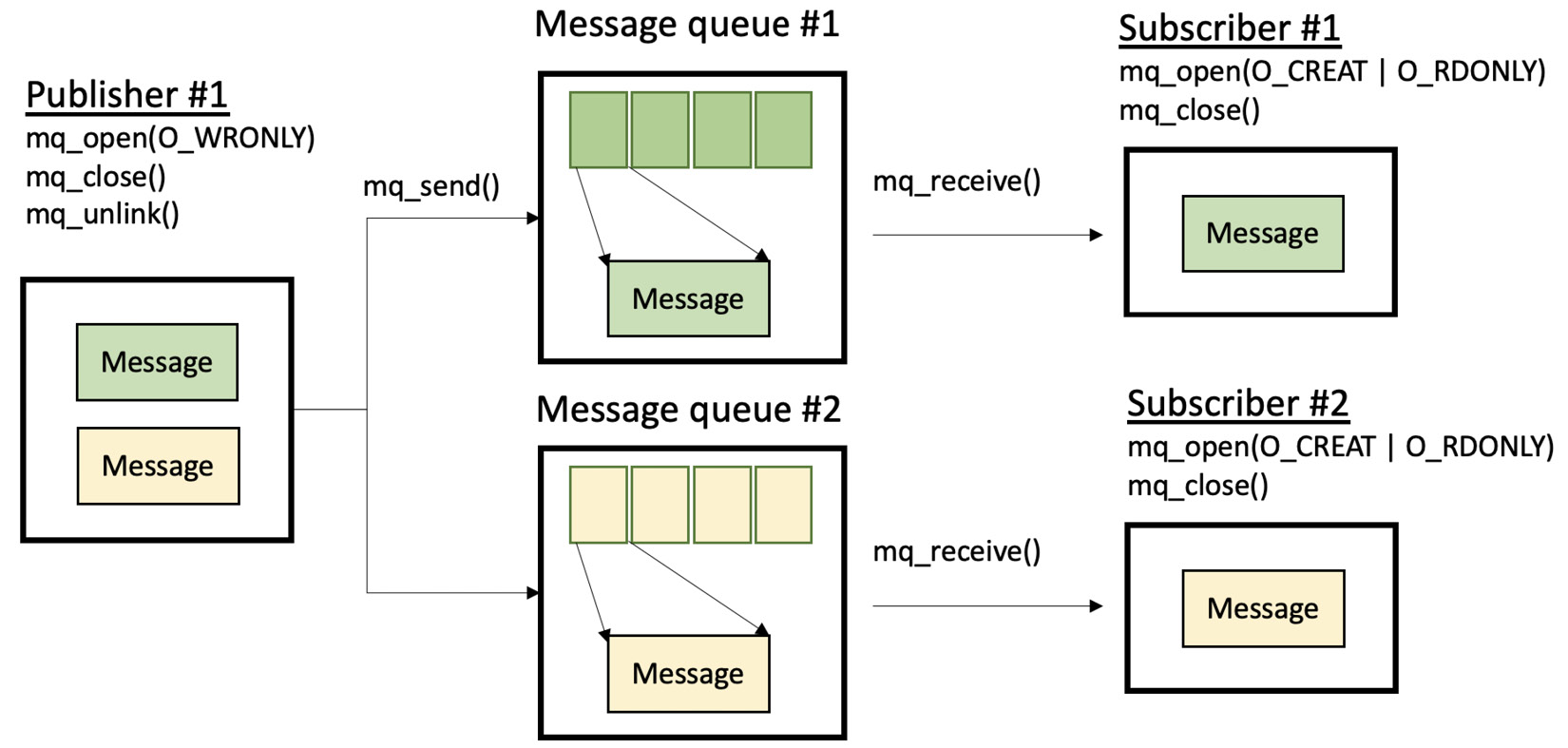
图 7.2 – 发布/订阅机制的 MQ 实现表示
当我们朝着进程解耦前进时,我们使系统更加灵活。随着订阅者不再浪费计算时间来识别消息是否针对他们,扩展变得更容易。添加新的生产者或消费者而不干扰其他人也变得容易。MQ在操作系统级别上实现,因此我们可以将其视为一个健壮的IPC机制。不过,一个可能的缺点是,生产者通常不会从订阅者那里收到任何健康信息。这导致MQ充满了未消费的数据,生产者被阻塞。因此,在更抽象的层面上实现了额外的实现框架,用于处理此类用例。我们鼓励您额外研究观察者和消息代理设计模式。内部开发的发布/订阅机制通常是基于它们构建的,并不总是通过MQs实现的。尽管如此,正如您可能已经猜到的,通过这种机制发送大量数据将是一个缓慢的操作。因此,我们需要一种工具来快速获取大量数据。不幸的是,这需要额外的同步管理以避免类似[第6章]中讨论的数据竞争。下一节将讨论同步原语。
通过信号量和互斥锁保证原子操作
让我们试着聚焦一个共享资源,看看在CPU中会发生什么。我们将提供一种简单而有效的方式来解释数据竞争从何而来。这已在[第6章]中进行了详尽的讨论。我们在这里学到的一切都应该被视为一种补充,但并行和并发处理的分析方法与以前相同。但现在,我们关注具体的低级问题。
让我们仔细看看以下代码片段:
int shrd_res = 0; // 某个共享资源。
void thread_func(){shrd_res ++;std::cout << shrd_res;
}
这是一个非常简单的代码片段,其中一个变量被递增并打印出来。根据C++标准,在多线程环境中,这样的修改是未定义行为。让我们看看怎么回事——而不是在这里讨论进程的内存布局,我们将一边分析它的伪汇编代码:
...
int shrd_res = 0; store 0
shrd_res++; load valueadd 1store value
std::cout << shrd_res; load value
...
假设这个递增过程在一个线程函数中,且有不止一个线程在执行它。add 1指令是在加载的值上执行的,而不是在shrd_res的实际内存位置上。前面的代码片段将被多次执行,很可能是并行执行的。如果我们注意到线程是一组指令,直觉会告诉我们这些指令是以整体的方式执行的。换句话说,每个线程例程应该在不受干扰的情况下运行,这通常是这样的。然而,有一个小细节我们应该记住——CPU被设计成保持小延迟。它不是为数据并行而构建的。因此,打个比方,它的主要目标是装载大量的小任务。我们的每个线程都在不同的处理器上执行;这可能是不同的CPU、CPU线程或CPU核心——这真的取决于系统。如果处理器(CPU、核心或线程)的数量小于N,那么剩余的线程将排队等待直到有处理器空闲。
现在,初始线程的指令已经加载到那里并按原样执行。即使CPU核心在架构上相同,它们的目标是尽快执行。这意味着由于多种硬件波动,它们的速度不可能相同。但shared_resource是一个变量,也就是…一个共享资源。这意味着谁先增加它谁就会这样做,其他人将跟随。即使我们不关心std::cout的结果(例如,打印顺序不再是顺序的),我们仍然有需要担心的事情。你可能已经猜到了!我们不知道我们实际上要增加的是什么值——它会是shared_resource的最后存储值还是新递增的值?这是怎么发生的?
让我们看看:
Thread 1: shrd_res++; T1: load valueT1: add 1
Thread 2: shrd_res++; T2: load valueT2: add 1T2: store valueT1: store value
你跟上了吗?Thread 1的指令序列被打断了,因为Thread 2的执行。现在,我们能预测将打印什么吗?这被称为未定义行为。在某些情况下,它会是因为Thread 2从未执行,因为最后存储在shared_resource中的值将是在以下过程中递增的:
T1: add 1
换句话说,我们丢失了一个递增。没有任何指令告诉CPU这两个过程必须分别调用并连续执行。应该清楚的是,可能存在有限数量的指令组合,所有这些都会导致意外行为,因为它取决于硬件的状态。这种操作被称为非原子的。为了正确处理并行性,我们需要依靠原子操作!软件开发者的工作是考虑这一点,并告知CPU这样的指令集。互斥锁和信号量等机制被用来管理原子范围。我们将在接下来的部分中彻底分析它们的作用。
信号量
如果您向多个行业的人们提出一个关于信号量是什么的调查,您会得到不同的答案。机场的工作人员可能会告诉您,这是一种通过使用旗帜向某人发出信号的系统。一名警察可能会告诉您这只是一个交通信号灯。向火车司机询问可能会得到类似的回答。有趣的是,这正是我们的信号量来源。总的来说,这些答案应该暗示您,这是一种信号机制。
重要说明
编程信号量是由Edsger Dijkstra发明的,主要用于防止竞态条件。它们帮助我们信号指示资源是否可用,以及有多少给定类型的共享资源单位可用。
就像前面提到的信号机制一样,信号量并不能保证代码无误,因为它们并不阻止进程或线程获取资源单位——它们只是通知。就像火车可能会忽略信号,继续前往被占用的铁轨,或者汽车可能会在繁忙的十字路口继续前行一样,这可能是灾难性的!再次强调,软件工程师的任务是弄清楚如何为系统的良好健康使用信号量。因此,让我们开始使用它们。
Dijkstra为我们提供了两个主要函数,围绕着关键部分:P(S)和V(S)。您可能知道,他是荷兰人,所以这些函数的名字来自荷兰语单词尝试和增加(分别是probeer和vrhoog),其中S是信号量变量。仅从它们的名字,您已经对它们将要做什么有了一个概念。让我们用伪代码看看它们:
unsigned int S = 0;
V(S):S=S+1;
P(S):while(S==0):// 无操作。S = S – 1;
所以,P(S)将不断检查信号量是否已经表示资源可用——信号量被递增。一旦S被递增,循环就会停止,信号量值会减少以执行其他代码。基于递增的值,我们识别出两种类型的信号量:二进制和计数。二进制信号量常被误认为互斥锁(mutex)机制。逻辑是一样的——例如,资源是否可自由访问和修改——但技术的本质是不同的,正如我们之前解释的,没有什么能阻止一些糟糕的并发设计忽略信号量。我们会马上讨论到这一点,但现在,让我们关注信号量的作用。在我们开始编写代码之前,让我们声明一下,在类Unix操作系统上有几种信号量接口。使用的选择取决于抽象级别和标准。例如,并不是每个系统都有POSIX,或者它没有完全暴露。由于我们将专注于C++20的使用,我们将仅将下一个示例用作参考。
让我们看看Linux上两种常见的信号量接口。第一个是未命名信号量——我们可以通过以下接口来展示它:
sem_t sem;
sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_destroy(sem_t *sem);
int sem_post(sem_t *sem);
int sem_wait(sem_t *sem);
sem变量是信号量,它分别通过sem_init()和sem_destroy()进行初始化和去初始化。P(S)函数由sem_wait()表示,V(S)函数由sem_post()表示。还有sem_trywait(),如果您想在递减不立即发生时报告错误,以及sem_timedwait(),这是一个阻塞调用,用于递减可能发生的时间窗口。这看起来很清楚,除了初始化部分。您可能已经注意到了value和pshared参数。第一个显示了信号量的初始值。例如,二进制信号量可以是0或1。第二个更有趣。
正如您可能记得的,在[第2章]中我们讨论了内存段。想象一下,我们在数据、BSS或堆上创建信号量。然后,它只会对单个进程中的线程全局可见,但无法在进程之间共享。问题是如何用它来进行进程同步;pshared正是为此目的使用的。如果它被设置为0,那么信号量就是本地的,用于进程,但如果它被设置为非零值,那么它就是跨进程共享的。关键是在如shmem的全局可见的内存区域上创建信号量,包括文件系统作为共享资源池。这里是命名信号量的概述:
-
命名信号量在进程创建者之外可见,因为它位于文件系统中,通常在
/dev/shm下。我们将其视为一个文件。例如,以下代码将创建一个名为/sem的信号量,权限为0644——它只能被其所有者读写,但只能被其他人读取,并且直到以后通过代码移除时,它将在文件系统上可见:sem_t *global_sem = sem_open("/sem", O_CREAT, 0644,0); -
P(S)和V(S)调用保持不变。我们完成后,必须关闭文件,并在不再需要时移除它:sem_close(global_sem); sem_unlink("/sem");
如[第1章]中提到的,您会看到POSIX调用遵循相同的模式,通过<object>_open、<object>_close、<object>_unlink和<object>_<specific function>后缀。这使得它们的使用对于每个POSIX对象都很常见,正如您在本章前面已经观察到的那样。
值得快速提及的是,存在更低级别的信号量,其中系统调用与操作系统类型密切相关或基于直接操作系统信号操纵。这种方法实施和维护起来复杂,因为它们是特定的,被认为是微调。欢迎您进一步研究您自己的系统。
C++信号量
考虑到这一点,我们希望继续提高抽象层次,因此我们将讨论C++中的信号量对象。这是C++20中的一个新特性,当你想让代码更具系统通用性时非常有用。让我们通过生产者-消费者问题来检查它。我们需要一个在进程范围内可见并被多个线程修改的变量:atomic<uint16_t> shared_resource。正如本节开头提到的,信号量有助于任务同步,但我们需要一个数据竞争防护。atomic类型确保我们遵循C++内存模型,并且编译器将根据std::memory_order保持CPU指令序列。您可以重新访问[第6章]以了解数据竞争的解释。
我们将继续创建两个全局的binary_semaphore对象,以适当地同步访问(就像乒乓球一样)。binary_semaphore对象是最大值为1的counting_semaphore对象的别名。我们需要一个程序结束规则,所以我们将定义一个迭代限制。我们将要求编译器通过constexpr关键字尽可能将其设为常量。最后但同样重要的是,我们将创建两个线程,分别扮演生产者(递增共享资源)和消费者(递减它)。让我们看看代码示例:
...
uint32_t shared_resource = 0;
binary_semaphore sem_to_produce(0);
binary_semaphore sem_to_consume(0);
constexpr uint32_t limit = 65536;
信号量被构造和初始化。我们继续进行线程。release()函数递增一个内部计数器,向其他线程发出信号(在以下代码中标记为{2},类似于sem_post())。我们使用osyncstream(cout)来构建非交错输出。以下是生产者线程:
void producer() {for (auto i = 0; i <= limit; i++) {sem_to_produce.acquire(); // {1}++shared_resource;osyncstream(cout) << "Before: "<< shared_resource << endl;sem_to_consume.release(); // {2}osyncstream(cout) << "Producer finished!" << endl;}
}
以下是消费者线程:
void consumer() {for (auto i = 0; i <= limit; i++) {osyncstream(cout) << "Waiting for data..."<< endl;sem_to_consume.acquire();--shared_resource;osyncstream(cout) << "After: "<< shared_resource << endl;sem_to_produce.release();osyncstream(cout) << "Consumer finished!" << endl;} }
int main() {sem_to_produce.release();jthread t1(producer); jthread t2(consumer);t1.join(); t2.join();}
当我们反复执行这个过程时,我们会根据limit多次看到这样的输出:
Waiting for data...
Before: 1
Producer finished!
After: 0
Consumer finished!
...
回到代码逻辑,我们必须强调,C++中的信号量被认为是轻量级的,并允许多个并发访问共享资源。但要小心:提供的代码使用了acquire()(标记{1},类似于sem_wait()),这是一个阻塞调用——例如,您的任务将被阻塞,直到信号量被释放。您可以使用try_acquire()进行非阻塞操作。我们依赖于这两个信号量来创建可预测的操作序列。我们启动进程(例如,主线程)通过释放生产者信号量,以便首先发出信号给生产者开始。
这段代码可以通过移除C++原语并在代码中相同的位置添加前面提到的系统调用,改为使用POSIX信号量。此外,我们鼓励您尝试使用一个信号量实现相同的效果。考虑使用一个辅助变量或条件变量。请记住,这样的操作使得同步变得异构且在大规模上难以管理。
当前代码显然无法像命名信号量那样同步多个进程,所以它并不真正是那里的替代品。我们也可能希望在并发环境中更严格地控制对共享资源的访问——例如,在某一时刻只有一个访问权限。然后,我们需要互斥锁的帮助,如下一节所述。
互斥锁
互斥锁是来自操作系统操作的一种机制。被称为临界区的共享资源需要在没有竞态条件风险的情况下被访问。一种机制,允许在给定时刻只有一个任务修改临界区,排除其他所有任务的相同请求,被称为互斥排斥或互斥锁。互斥锁由操作系统内部实现,并对用户空间保持隐藏。它们提供锁定-解锁访问功能,并被认为比信号量更严格,尽管它们被控制为二进制信号量。
重要说明
调用线程锁定资源并有义务解锁它。没有保证系统层次结构中的更高实体能够覆盖锁并解除并行功能的阻塞。建议每个锁尽快释放,以允许系统线程扩展并节省空闲时间。
POSIX互斥锁的创建和使用与未命名信号量的方式大致相同:
pthread_mutex_t global_lock;
pthread_mutex_init(&global_lock, NULL);
pthread_mutex_destroy(&global_lock);
pthread_mutex_lock(&global_lock);
pthread_mutex_unlock(&global_lock);
再次遵循函数名称的模式,因此让我们关注pthread_mutex_lock()和pthread_mutex_unlock()。我们使用它们来锁定和解锁临界区以进行操作,但它们无法帮助我们进行事件顺序安排。锁定资源只保证没有竞态条件。如果需要,正确的事件顺序由系统程序员设计。错误的顺序可能导致死锁和活锁:
- 死锁:一个或多个线程被阻塞,无法改变它们的状态,因为它们在等待一个永远不会发生的事件。一个常见的错误是两个(或更多)线程被相互循环——例如,一个线程在持有共享资源B的锁时等待共享资源A,而第二个线程持有A的锁但会在B解锁时解锁。由于没有人愿意首先放弃资源,两者都将保持阻塞。即使没有互斥锁,也可能发生这种行为。另一个错误是两次锁定一个互斥锁,在Linux的情况下,操作系统可以检测到。有解决死锁的算法,其中锁定多个互斥锁首次不会成功,因为死锁,但在有限次尝试后将成功。在前面的代码片段中,我们将互斥锁属性设置为
NULL,但我们可以使用它们来决定互斥锁的类型。默认的互斥锁,被称为快速互斥锁,不是死锁安全的。递归互斥锁类型不会导致死锁;它将计算同一线程的锁定请求次数。错误检查互斥锁将检测并标记双重锁定。我们鼓励您尝试使用它们。 - 活锁:线程没有被阻塞,但同样无法改变它们的状态,因为它们需要共享资源才能继续前进。一个很好的现实世界例子是两个人在入口处面对面相遇。出于礼貌,他们都会让开,但他们最有可能像对方一样移动。如果发生这种情况,他们一直这样做,那么没有人会被阻塞,但同时他们也无法继续前进。
这两类错误都很常见,可以用信号量复现,因为它们也是阻塞的,在小规模系统上很少发生,容易调试。只有几个线程时,跟踪代码逻辑是琐碎的,进程是可管理的。拥有成千上万个线程的大规模系统同时执行大量的锁。错误复现通常是由于糟糕的时机和模糊的任务序列。因此,它们很难捕捉和调试,我们建议您在锁定临界区时要小心。
C++提供了灵活的锁接口。它不断升级,我们现在有几种行为可供选择。让我们并行递增一个变量。我们使用increment()线程过程来实现清晰性,类似于之前的代码,但我们用一个互斥锁替换信号量。您可能已经猜到,代码将被保护免受竞态条件,但线程执行的顺序是未定义的。我们可以通过额外的标志、条件变量或简单的睡眠来安排这个顺序,但为了实验,让我们保持这种方式。更新的代码片段如下:
...
uint32_t shared_resource = 0;
mutex shres_guard;
constexpr uint32_t limit = INT_MAX;
我们定义了共享资源和互斥锁。让我们看看递增是如何发生的:
void increment() {for (auto i = 0; i < limit; i++) {lock_guard<mutex> lock(shres_guard); // {1}++shared_resource;}cout << "\nIncrement finished!" << endl;
}
...
观察到的输出如下:
$ time ./test
Increment finished!
Increment finished!
real 0m0,003s
user 0m0,002s
sys 0m0,000s
正如您所看到的,仅通过移除互斥锁,就可以显著提高时间效率。为了论证,您可以将信号量重新添加,您仍然会观察到比互斥锁更快的执行速度。我们建议您查看这三种情况的代码反汇编——只使用atomic变量、使用互斥锁和使用信号量。您会观察到atomic对象在指令上非常简单,并在用户级别执行。由于它是真正的原子操作,CPU(或其核心)在递增期间将保持忙碌。请记住,解决数据竞争的任何技术本质上都会带来性能成本。通过最小化需要同步原语的地方及其范围,可以实现最佳性能。
重要说明
C++20为并发执行提供了令人兴奋的特性,如jthread、协程、更新的原子类型和合作取消。除了第一个之外,我们将在本书后面部分讨论其他特性。除此之外,Linux还有系统调用用于使用IPC实体,这些实体是为多进程数据交换目的而构建的。也就是说,在您尝试结合互斥锁、信号量、标志和条件变量之前,我们建议您考虑使用已有的异步工作机制。所有这些C++和Linux特性都旨在稳定地扩展,并为您节省解决方案设计时间。
到目前为止,我们所做的一切都是为了确保我们对临界区有原子访问。原子性、互斥锁和信号量将为您提供这一点——一种指导CPU关于指令范围的方法。但还有两个问题:我们能做得更快更轻吗?原子性是否意味着我们保持了指令的顺序?对第一个问题的回答是可能。对第二个问题的回答是不!现在我们有动力深入研究C++的内存模型和内存顺序。如果您对此感兴趣,我们邀请您跳转到[第9章],在那里我们将讨论更多有趣的并发任务。现在,我们将继续通过shmem IPC机制讨论共享资源的主题。
使用共享内存
就像管道一样,MQ数据一旦被消费就会丢失。双工消息数据复制会增加用户空间-内核空间的调用,因此预期会有开销。shmem机制是快速的。正如您在上一章和上一节中了解到的,数据访问的同步是必须由系统程序员解决的问题,尤其是在涉及竞态条件时。
重要的是要注意,共享内存这个术语本身就很模糊。它是两个线程可以同时访问的全局变量吗?还是多个CPU核心使用作为共同基础的RAM的共享区域来相互传输数据?它是许多进程修改的文件系统中的文件吗?非常好的问题——谢谢您的提问!通常,所有这些都是共享资源的种类,但当我们谈论内存这个术语时,我们真的应该考虑到主内存中对许多进程可见的区域,多个任务可以在其中交换和修改数据。不仅是任务,还有不同的处理器核心和核心复合体(如ARM),如果它们能够访问同一预定义的内存区域。这样的技术需要一个特定的配置文件——内存映射,它严格依赖于处理器,并且是实现特定的。它提供了使用例如紧耦合内存(TCM)的机会,甚至可以加快频繁使用的代码和数据部分的速度,或使用RAM的一部分作为shmem来在核心之间交换数据。由于这太依赖于处理器,我们不打算继续讨论它。相反,我们将继续讨论Linux的shmem IPC机制。
重要说明
进程分配它们的虚拟内存的一部分作为共享段。传统上,操作系统禁止进程访问彼此的内存区域,但shmem是进程请求在shmem的边界内删除这一限制的机制。我们使用它来通过简单的读写操作或POSIX中已提供的函数快速摄取和修改大量数据。通过MQ或管道无法实现这样的功能。
与MQ不同,这里没有序列化或同步。系统程序员负责管理IPC的数据传输策略(再次)。但由于共享区域位于RAM中,我们有更少的上下文切换,从而减少了开销。我们可以通过以下图表来可视化它:
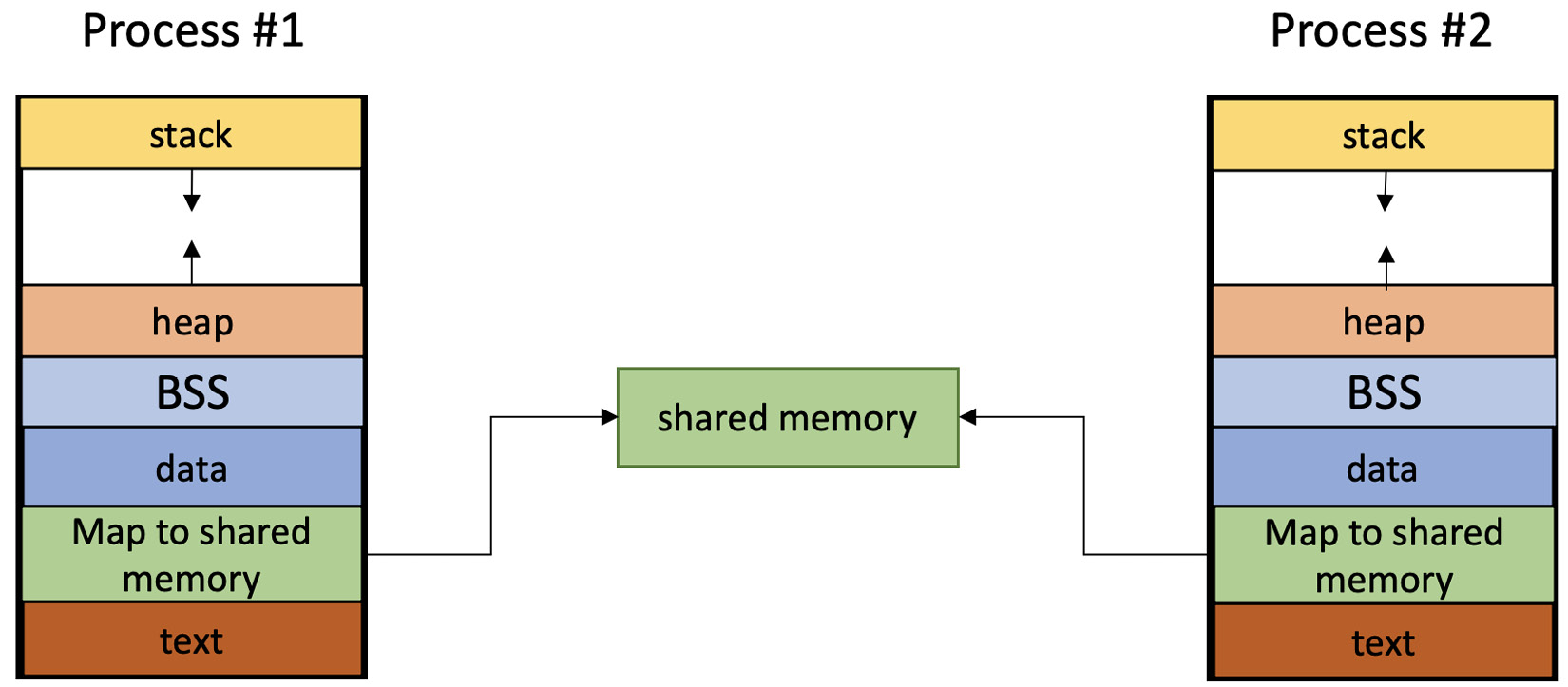
图7.3 - 通过进程的内存段展示shmem
shmem区域通常描绘在两个进程的地址空间之间。这样做的目的是强调该空间确实在进程间共享。实际上,这是特定于实现的,我们将其留给内核处理——我们关心的是shmem段本身的映射。它允许两个进程同时观察到相同的内容。那么,让我们开始吧。
了解mmap()和shm_open()
创建shmem映射的初始系统调用是shmget()。这适用于任何基于Unix的操作系统,但对于符合POSIX的系统,有更舒适的方法。如果我们想象在进程的地址空间和一个文件之间进行映射,那么mmap()函数将完成这项工作。它符合POSIX标准,并在需要时执行读操作。您可以简单地使用mmap()指向一个常规文件,但在进程完成工作后数据将仍然存在。还记得[第3章]中的管道吗?这里的情况类似。有匿名管道,需要两个进程有家族关系,或者您可以有命名管道,允许两个无关的进程共享和传输数据。shmem解决了类似的问题,只是不通过相同的技术。使用shmem进行IPC意味着可能不需要数据持久性——所有其他机制在消费后都会销毁数据。但如果您想要持久性,那就没问题——您可以自由地使用mmap()系统调用与fork()结合使用。
如果您有独立的进程,那么它们唯一知道如何定位共享区域的方式是通过其路径名。shm_open()函数将提供一个具有名称的文件,就像mq_open()一样——您可以在/dev/shm中观察到它。它也需要librt。了解这一点,您会直观地认识到我们限制了由于文件系统操作而产生的I/O开销和上下文切换,因为这个文件位于RAM中。最后但同样重要的是,这种共享内存在大小上是灵活的,可以在需要时扩展到数千兆字节。其限制取决于系统。
...
string_view SHM_ID = "/test_shm";
string_view SEM_PROD_ID = "/test_sem_prod";
string_view SEM_CONS_ID = "/test_sem_cons";
constexpr auto SHM_SIZE = 1024;
sem_t *sem_prod; sem_t *sem_cons;
void process_creator() {
...if (int pid = fork(); pid == 0) {// Child - used for consuming data.if (fd = shm_open(SHM_ID.data(),O_RDONLY,0700); // {1}fd == -1) {
....
这个示例非常具体,因为我们故意使用进程而不是线程。这使我们能够演示shm_open()的使用(标记{1}),因为不同的进程使用shmem的路径名(在编译时已知)来访问它。让我们继续阅读数据:
shm_addr = mmap(NULL, SHM_SIZE,PROT_READ, MAP_SHARED,fd, 0); // {2}if (shm_addr == MAP_FAILED) {
...}array<char, SHM_SIZE> buffer{};
我们可以使用互斥锁,但目前我们只需要一个进程向另一个进程发出信号,表示其工作完成,因此我们应用信号量(在前一个代码块中的标记{3}和{7})如下:
sem_wait(sem_cons);memcpy(buffer.data(),shm_addr,buffer.size()); // {3}if(strlen(buffer.data()) != 0) {cout << "PID : " << getpid()<< "consumed: " << buffer.data();}sem_post(sem_prod); exit(EXIT_SUCCESS);
为了使内存区域共享,我们使用mmap()函数并选择MAP_SHARED选项,并通过以下页面设置相应地标记读取器和写入器的凭据:PROT_READ和PROT_WRITE(标记{2}和{6})。我们还使用ftruncate()函数设置区域的大小(标记{5})。在给定的示例中,信息被写入shmem,有人必须读取它。这是一种单次射击的生产者-消费者,因为写入完成后,写入者给读取者一些时间(标记{8}),然后将shmem设置为零(标记{9})并删除(标记{10})。现在,让我们继续进行父代码 - 数据的生产者:
else if (pid > 0) {// Parent - used for producing data.fd = shm_open(SHM_ID.data(),O_CREAT | O_RDWR,0700); // {4}if (fd == -1) {
...res = ftruncate(fd, SHM_SIZE); // {5}
再次,shmem区域被映射:
if (res == -1) {
...shm_addr = mmap(NULL, SHM_SIZE,PROT_WRITE, MAP_SHARED,fd, 0); // {6}if (shm_addr == MAP_FAILED) {
...sem_wait(sem_prod);string_view produced_data{"Some test data, coming!"};memcpy(shm_addr,produced_data.data(),produced_data.size());sem_post(sem_cons); // {7}waitpid(pid, NULL, 0); // {8}res = munmap(shm_addr, SHM_SIZE); // {9}if (res == -1) {
...fd = shm_unlink(SHM_ID.data()); //{10}if (fd == -1) {
如前所述,我们使用命名信号量sem_open()(标记{11})来允许两个进程同步。我们无法通过本章早期讨论的信号量来实现这一点,因为它们没有名称,只在单个进程的上下文中已知。最后,我们还将信号量从文件系统中移除(标记{12}),如下所示:
...
}
int main() {sem_prod = sem_open(SEM_PROD_ID.data(),O_CREAT, 0644, 0); // {11}
...sem_post(sem_prod);process_creator();sem_close(sem_prod); // {12}sem_close(sem_cons);sem_unlink(SEM_PROD_ID.data());sem_unlink(SEM_CONS_ID.data());return 0;
}
程序的结果如下:
PID 3530: consumed: "Some test data, coming!"
Shmem(共享内存)是一个引人入胜的话题,我们将在[第9章]回到这个讨论。其中一个原因是C++允许我们适当地封装POSIX代码,并使代码更安全。与[第3章]中讨论的类似,将系统调用与C++代码混合使用需要经过周密的考虑。但是,探讨条件变量机制和讨论读/写锁是值得的。我们还将深入探讨一些memory_order的使用案例。如果jthreads或协程不适用于您的用例,那么当前讨论的同步机制,连同智能指针,为您设计系统的最佳可能解决方案提供了灵活性。但在我们深入探讨之前,我们首先需要讨论另一个话题。让我们继续探讨计算机系统之间的通信。
通过网络与套接字进行通信
如果管道、消息队列(MQs)和共享内存(shmem)能够共同克服它们的问题,那么我们为什么还需要套接字呢?这是一个很好的问题,答案很简单——我们需要它们来在网络上不同系统之间进行通信。有了这些,我们就拥有了完整的数据交换工具集。在我们理解套接字之前,我们需要快速了解一下网络通信。无论网络类型或其介质如何,我们都必须遵循开放系统互连(OSI)基本参考模型所建立的设计。如今,几乎所有的操作系统都支持互联网协议(IP)族。使用这些协议是建立与其他计算机系统通信的最简单方式。它们遵循ISO-OSI模型中描述的分层,现在我们将快速了解一下。
OSI模型概述
OSI模型通常如下表所示表示。系统程序员通常需要它来分析他们的通信在哪里被干扰。尽管套接字旨在执行网络数据传输,但它们也适用于本地IPC。其中一个原因是,特别是在大型系统上,通信层是独立的实用程序或应用程序之上的抽象层。由于我们希望使它们对环境无感,这意味着我们不关心数据是在本地传输还是通过互联网传输,那么套接字就非常合适。即便如此,我们必须意识到我们使用的通道以及我们的数据被传输到哪里。让我们来看一看:
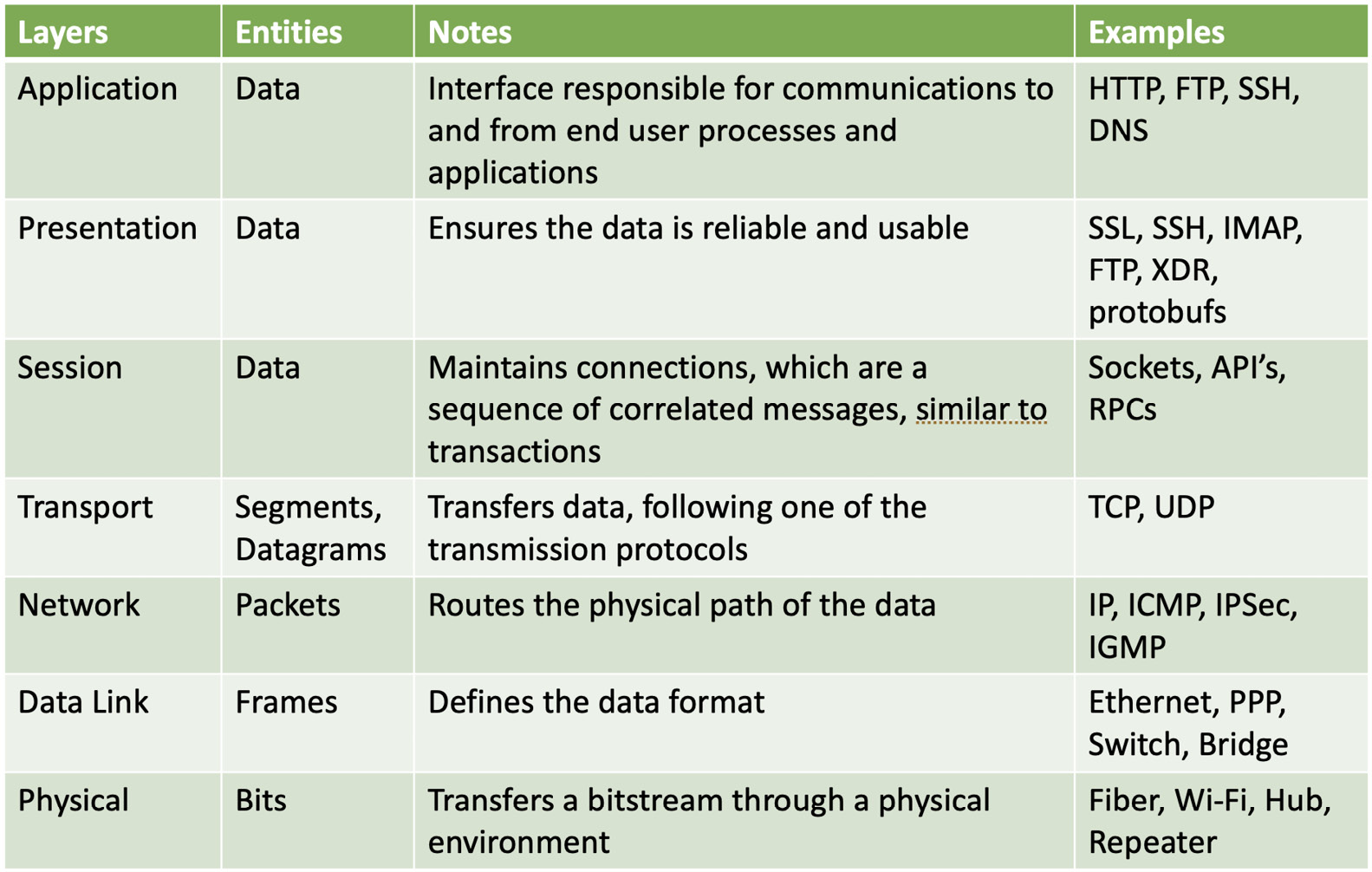
图7.4 - 以表格形式表示的OSI模型
全球网络通信,特别是互联网,是一个广泛且复杂的话题,我们无法在书的单个章节中完全掌握。但是,思考一下您的系统——它具有什么类型的网络通信硬件;也许您应该考虑检查一下物理层和数据链路层。一个简单的练习是自己配置您的家庭网络——连接设备、路由器等。系统能否被外部安全可靠地访问(如果需要的话)?然后检查网络层、表示层和应用层。尝试一些端口转发并创建一个带有数据交换加密的应用程序。软件是否能够以当前的带宽和速度快速扩展?让我们看看会话层和传输层能提供什么——我们将在下一段中讨论。它是否健壮并且在受到攻击时仍然可用?那么请重新审视所有层。当然,这些是简单且片面的观察,但它们可以让您重新检查您的需求。
所以,如果我们忽略硬件的角色,只专注于建立连接,我们可以回到套接字和相应的会话层。您可能已经注意到,有些网站在一段时间后会自动将您登出。曾经想过为什么吗?嗯,会话是在设备或端之间建立的用于信息交换的双向链接。强烈建议为会话应用时间限制并要求会话被销毁。打开的连接不仅意味着攻击者可以进行嗅探的开放通道,而且也是服务器端使用的资源。这需要计算能力,可以重定向到其他地方。服务器通常保存当前状态和会话历史,因此我们将这种通信标记为有状态的——至少有一台设备保持状态。但如果我们设法处理请求而不需要知道和保留以前的数据,我们可以进行无状态的通信。尽管如此,我们仍然需要会话来建立面向连接的数据交换。一个已知的、用于该工作的协议位于传输层——传输控制协议(TCP)。如果我们不想建立双向信息传输通道,只是想实现广播应用程序,那么我们可以继续进行通过用户数据报协议(UDP)提供的无连接通信。让我们在以下章节中检查它们。
通过UDP熟悉网络
正如我们所说,这个协议可以实现无连接通信,尽管这并不意味着端点之间没有连接。这意味着它们不需要不断地保持连接来维护数据传输并在各自端口解释它。换句话说,丢失一些数据包(例如,在在线会议中导致通话时听不清某人)可能对系统本身的行为不会是决定性的。这对您来说可能很关键,但让我们诚实地对此,我们敢打赌,您更需要高速度,而这是有代价的。像域名系统(DNS)、动态主机配置协议(DHCP)、音视频流媒体平台等网络应用程序使用UDP。数据包的差异和丢失通常通过数据重传来处理,但这在应用层实现,并取决于程序员的实现。从概念上讲,建立此类连接的系统调用如下:

图7.5 - UDP系统调用实现
如您所见,这实际上非常简单——通信的双方(或更多方)只需遵循该序列即可。该协议不会强制您遵循消息顺序或传输质量,它只是快速的。让我们看看以下示例,请求从套接字N次掷骰子。代码的完整版本可以在找到:
...
constexpr auto PORT = 8080;
constexpr auto BUF_SIZE = 16;
auto die_roll() {
...
void process_creator() {auto sockfd = 0;array<char, BUF_SIZE> buffer{};string_view stop{ "No more requests!" };string_view request{ "Throw dice!" };struct sockaddr_in servaddr {};struct sockaddr_in cliaddr {};
如您所见,通信配置相当简单——一方必须绑定到一个地址,以便知道从哪里接收数据(标记{3}),而另一方只需直接向套接字写入数据。套接字配置在标记{1}处描述:
servaddr.sin_family = AF_INET; // {1}servaddr.sin_addr.s_addr = INADDR_ANY;servaddr.sin_port = htons(PORT);if (int pid = fork(); pid == 0) {// Childif ((sockfd = socket(AF_INET, SOCK_DGRAM, 0))< 0) {const auto ecode{ make_error_code(errc{errno}) };cerr << "Error opening socket!";system_error exception{ ecode };throw exception;} // {2}if (bind(sockfd,(const struct sockaddr*)&servaddr,sizeof(servaddr)) < 0) {const auto ecode{ make_error_code(errc{errno}) };cerr << "Bind failed!";system_error exception{ ecode };throw exception;} // {3}
地址族被定义为AF_INET,意味着我们将依赖于符合IPv4的地址。我们可以使用AF_INET6表示IPv6,或者AF_BLUETOOTH表示蓝牙。我们通过套接字的SOCK_DGRAM设置使用UDP(标记{2}和{10})。通过这种方式,我们在一个进程和另一个进程之间传输一个数字。您可以将它们想象为服务器和客户端:
socklen_t len = sizeof(cliaddr);for (;;) {if (auto bytes_received =recvfrom(sockfd, buffer.data(),buffer.size(),MSG_WAITALL,(struct sockaddr*)&cliaddr,&len);bytes_received >= 0) { // {4}buffer.data()[bytes_received] = '\0';cout << "Request received: "<< buffer.data() << endl;if (request.compare(0,bytes_received,buffer.data()) == 0) {// {5}string_view res_data{ to_string(die_roll()) };
接收到新的掷骰子请求(标记{4}),并打印出请求数据。然后,将请求字符串与不变的字符串进行比较,以便知道这个请求只是为了掷骰子(标记{5})。如您所见,我们使用了MSG_WAITALL设置,这意味着套接字操作将阻塞调用进程——通常在没有传入数据时。此外,这是一种UDP通信,因此数据包的顺序可能不会被遵循,通过recvfrom()接收0字节是一个有效的用例。正因如此,我们使用额外的消息标记通信的结束(标记{6}和{14})。为了简单起见,如果request.compare()的结果不是0,则结束通信。尽管如此,可以添加对多个选项的额外检查。我们可以使用类似的握手来首先开始通信——这取决于系统程序员的决定和应用程序的要求。继续进行客户端的功能:
sendto(sockfd, res_data.data(),res_data.size(),MSG_WAITALL,(struct sockaddr*)&cliaddr,len);}else break; // {6}
...}if (auto res = close(sockfd); res == -1) { // {8}const auto ecode{ make_error_code(errc{errno}) };cerr << "Error closing socket!";system_error exception{ ecode };throw exception;}exit(EXIT_SUCCESS);
为dice_rolls次数调用die_roll()函数(标记{10}和{11}),并通过套接字发送结果(标记{12})。收到结果后(标记{13}),发送结束消息(标记{14})。在这个示例中,我们主要使用了MSG_CONFIRM,但您必须小心这个标志。它应该在您期望从发送的同一对等方获得响应时使用。它告诉OSI模型的数据链路层有一个成功的回复。我们可以将recvfrom()的设置更改为MSG_DONTWAIT,如标记{12}所示,但实现我们自己的重试机制或切换到TCP会是一个好主意:
for (auto i = 1; i <= dice_rolls; i++) { // {11}if (auto b_sent = sendto(sockfd,request.data(),request.size(),MSG_DONTWAIT,(const structsockaddr*)&servaddr,sizeof(servaddr));b_sent >= 0) { // {12}
...if (auto b_recv =recvfrom(sockfd,buffer.data(),buffer.size(),MSG_WAITALL,
... { // {13}buffer.data()[b_recv] = '\0';cout << "Dice roll result for throw number"<< i << " is "<< buffer.data() << endl;}
我们在关闭语句后关闭通信(标记{8}和{15}):
sendto(sockfd,stop.data(),stop.size(),MSG_CONFIRM,(const struct sockaddr*)&servaddr,sizeof(servaddr)); // {14}if (auto res = close(sockfd); res == -1) {const auto ecode{ make_error_code(errc{errno}) };cerr << "Error closing socket!";system_error exception{ ecode };throw exception; // {15}}
...
输出的缩写版本如下所示:
Choose a number of dice throws between 1 and 256.
5
Request received: Throw dice!
Dice roll result for throw number 1 is 2
....
Dice roll result for throw number 5 is 6
Request received: No more requests
我们必须设置我们的服务器可以从哪个地址和端口访问。通常,服务器计算机有许多应用程序不断运行,其中一些执行客户服务。这些服务与服务器的端口绑定,用户可以调用它们来完成一些工作——获取在线商店的内容、检查天气、获取一些银行详情、可视化图形网站等。一次只有一个应用程序(服务)可以使用给定的端口。如果您尝试在第一个激活时用另一个使用它,您将得到Address already in use错误(或类似的)。目前,我们正在使用端口8080,它通常为TCP/UDP(和HTTP)打开。您也可以尝试80,但在Linux上,非root用户没有这个能力——您需要更高的用户权限来使用小于1000的端口。最后但同样重要的是,IP地址被设置为INADDR_ANY。当我们在单个系统上进行通信并且不关心其地址时,这通常被使用。尽管如此,如果我们想要,我们可以在运行以下命令的结果中获取它:
$ ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000link/ether 00:0c:29:94:a5:25 brd ff:ff:ff:ff:ff:ffinet 192.168.136.128/24 brd 192.168.136.255 scope global dynamic noprefixroute ens32valid_lft 1345sec preferred_lft 1345secinet6 fe80::b11f:c011:ba44:35e5/64 scope link noprefixroutevalid_lft forever preferred_lft forever...
在我们的例子中,这个地址是192.168.136.128。我们可以按照下面的方式更新代码中的标记{1}:
servaddr.sin_addr.s_addr = inet_addr("192.168.136.128");
另一个选择是使用本地主机地址——127.0.0.1,与回环设备地址:INADDR_LOOPBACK一起使用。我们通常用它来运行本地服务器,主要是出于测试目的。但如果我们使用确切的IP地址,那么当我们需要非常具体地指定应用程序的终点时就会这样做,如果IP地址是静态的,我们期望本地网络上的其他人能够调用它。如果我们想将其暴露给外部世界,使我们的服务可供他人使用(比如说我们拥有一个在线商店,并希望向世界提供我们的购物服务),那么我们必须考虑端口转发。
重要提示
如今,仅仅暴露端口被认为是不安全的,因为任何人都可以访问该设备。相反,服务不仅受到防火墙、加密机制等的保护,而且还部署在虚拟机上。这为安全性增加了一个额外的层次,因为攻击者永远无法访问真实的设备,只能访问它的一个非常有限的版本。这样的决策还提高了可用性,因为被攻击的表面可以立即被移除,系统管理员可以从健康的快照中启动一个新的虚拟机,使服务再次可用。根据实现的不同,这也可以是自动化的。
最后一点——如果我们传输较大量的数据,文件的内容可能会放错位置。这再次是UDP的预期表现,如前所述,是因为数据包的排序问题。如果这不符合您的目的,并且您需要更加健壮的实现,那么您应该在下一节中检查TCP的描述。
通过TCP考虑健壮性
UDP的替代方案是TCP。它被认为是可靠的——消息是有序的,它是面向连接的,并且延迟较长。世界范围的网络(WWW)、电子邮件、远程管理应用等都基于这个协议。您可能已经注意到(并且将在图7.6中观察到)的是,相应的系统调用序列相同,并且名称与其他编程语言中的名称类似。这有助于不同专业领域的人们在设计网络应用时有一个共同的基础,并且能够轻松理解事件序列。这是一种非常简单的方式,帮助他们遵循OSI模型中的协议,使用这些名称作为当前通信所处位置的提示。正如我们在前一节中已经提到的,套接字用于环境无关的解决方案,其中系统有不同的操作系统,而通信应用使用不同的编程语言。例如,它们可以用C、C++、Java或Python实现,而它们的客户端可能是PHP、JavaScript等。
TCP通信的系统调用在下图中表示:
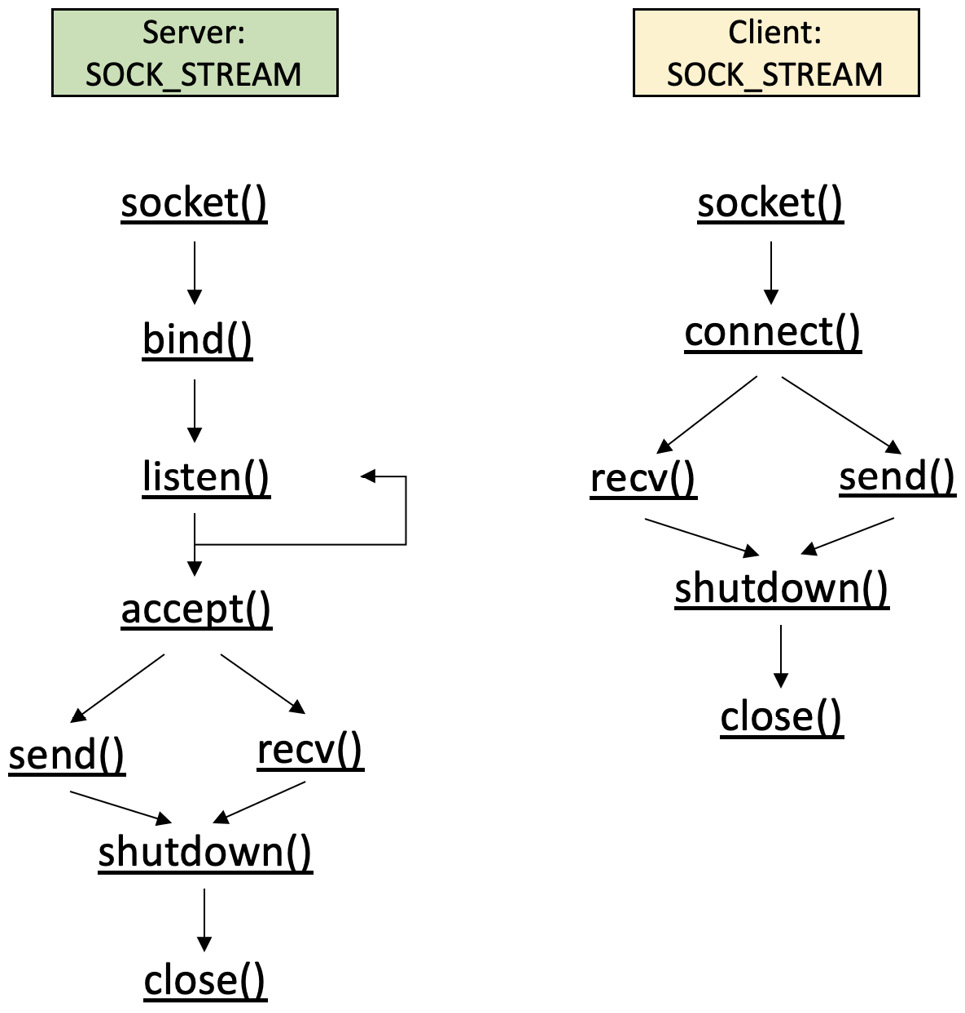
图7.6 - TCP系统调用实现
如您所见,与UDP相比,TCP更为复杂,这是预料之中的。为什么呢?好吧,我们需要保持一个已建立的连接,而内核会确认数据包传输。如果您还记得,在[第1章]和[第2章]中,我们讨论过套接字也是文件,我们可以将它们当作文件来处理。您可以简单地进行write()和read()调用,而不是进行send()和recv()调用。前者专用于网络通信,而后者通常用于所有文件。使用read()和write()调用将类似于通过管道进行通信,但在计算机系统之间,因此它再次取决于您的需求。
让我们看看以下示例——一个简单的请求-响应交换,我们将在本地网络的不同机器上执行,因为前面的IP地址仅对我们的内部网络有效。首先,让我们看看我们是否可以ping通服务器:
$ ping 192.168.136.128
Pinging 192.168.136.128 with 32 bytes of data:
Reply from 192.168.136.128: bytes=32 time<1ms TTL=64
Reply from 192.168.136.128: bytes=32 time<1ms TTL=64
Reply from 192.168.136.128: bytes=32 time<1ms TTL=64
所以,我们可以访问这台机器。现在,让我们运行服务器作为一个单独的应用程序
...
constexpr auto PORT = 8080;
constexpr auto BUF_SIZE = 256;
constexpr auto BACKLOG = 5;
constexpr auto SIG_MAX = 128;
void exitHandler(int sig) {cerr << "Exit command called - terminating server!"<< endl;exit(SIG_MAX + sig);
}
int main() {signal(SIGINT, exitHandler);constexpr auto ip = "192.168.136.128";
...
我们打开套接字:
if (auto server_sock =socket(AF_INET, SOCK_STREAM, 0);server_sock < 0) {
我们使用SOCK_STREAM来指示这是一个TCP连接。我们还使用硬编码的IP。在我们绑定到地址之后,我们需要监听BACKLOG数量的活动连接。如果连接数小于BACKLOG值,通常可以接受每个新连接:
...server_addr.sin_addr.s_addr = inet_addr(ip);result = bind(server_sock,(struct sockaddr*)&server_addr,sizeof(server_addr));
...result = listen(server_sock, BACKLOG);if (result != 0) {cerr << "Cannot accept connection";}cout << "Listening..." << endl;for (;;) {addr_size = sizeof(client_addr);client_sock =accept(server_sock,(struct sockaddr*)&client_addr,&addr_size);
直到这一点,我们只有以下情况:
$ ./server
Listening...
现在,让我们准备接受客户端并处理其请求。我们使用MSG_PEEK标志来检查传入消息,并使用MSG_DONTWAIT发送消息。为了简单和可读性,我们不检查sendto()的结果:
if (client_sock > 0) {cout << "Client connected." << endl;array<char, BUF_SIZE> buffer{};if (auto b_recv = recv(client_sock,buffer.data(),buffer.size(),MSG_PEEK);b_recv > 0) {buffer.data()[b_recv] = '\0';cout << "Client request: "<< buffer.data() << endl;string_view response ={ to_string(getpid()) };cout << "Server response: "<< response << endl;send(client_sock,response.data(),response.size(),MSG_DONTWAIT);}
套接字在最后关闭:
...if (auto res =close(client_sock); res == -1) {
...
现在,让我们从另一个系统连接一个客户端。它的实现类似于UDP,只是必须调用connect()并且必须成功:
...if (auto res =connect(serv_sock,(struct sockaddr*)&addr,sizeof(addr)); res == -1) {const auto ecode{ make_error_code(errc{errno}) };cerr << "Error connecting to socket!";system_error exception{ ecode };throw exception;}string_view req = { to_string(getpid()) };cout << "Client request: " << req << endl;
服务器的输出随之变化:
$ ./server
Listening...
Client connected.
Client request: 12502
Server response: 12501
让我们继续通信,发送信息回来:
if (auto res =send(serv_sock,req.data(),req.size(),MSG_DONTWAIT);res >= 0) {array<char, BUF_SIZE> buffer{};if (auto b_recv =recv(serv_sock,buffer.data(),buffer.size(),MSG_PEEK);res > 0) {buffer.data()[b_recv] = '\0';cout << "Server response: "<< buffer.data();
...if (auto res = close(serv_sock); res == -1) {
...cout << "\nJob done! Disconnecting." << endl;
我们正在关闭客户端的通信,包括套接字。客户端的输出如下:
$ ./client
Client request: 12502
Server response: 12501
Job done! Disconnecting.
随着客户端的任务完成,进程终止,套接字关闭,但服务器保持活动状态以接受其他客户端,因此如果我们多次从不同的shell调用客户端,服务器的输出将如下:
Listening...
Client connected.
Client request: 12502
Server response: 12501
Client connected.
Client request: 12503
Server response: 12501
服务器将在其待处理队列中处理多达五个客户端会话。如果客户端不关闭其套接字,或者服务器在某个超时后不强制终止它们的连接,它将无法接受新客户端,将观察到Client connection failed消息。在下一章中,我们将讨论不同的基于时间的技术,因此考虑将它们与您的实现相结合,以提供有意义的会话超时。
如果我们想优雅地处理服务器终止,我们可以简单地实现一个信号处理程序,就像我们在[第3章]中所做的那样。这次,我们将处理Ctrl + C键组合,导致以下输出:
...
Client request: 12503
Server response: 12501
^CExit command called - terminating server!
正如前所述,服务器和客户端的不优雅终止可能会导致套接字挂起和端口开放。这将为系统带来问题,因为简单的应用程序重启会因“地址已被使用”(Address already in use)而失败。如果发生这种情况,请通过ps命令仔细检查剩余的进程。您可以通过kill命令终止正在运行的进程,正如您在[第1章]和[第2章]中学到的。有时,这还不够,服务器也不应该那么容易就被终止。因此,您可以在检查哪些端口已经开放后更换端口。您可以通过以下命令来完成这一操作:
$ ss -tnlp
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 5 192.168.136.128:8080 0.0.0.0:* users:(("server",pid=9965,fd=3))
LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:*
LISTEN 0 5 127.0.0.1:631 0.0.0.0:*
LISTEN 0 5 [::1]:631 [::]:*
您可以看到服务器正在相应的地址和端口上运行:192.168.136.128:8080。我们还可以使用以下方法检查某个端口的连接情况:
$ lsof -P -i:8080
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
server 10116 oem 3u IPv4 94617 0t0 TCP oem-virtual-machine:8080 (LISTEN)
如今,随着多种在线服务的出现,我们无法避免网络编程。我们鼓励您使用这些示例作为起点进行简单的应用开发。同时,花一些时间了解更多关于多种套接字设置的信息也很重要,因为它们将帮助您满足您的特定需求。
总结
在本章中,您了解了执行IPC的各种方式。您熟悉了MQs作为简单、实时且可靠的工具,用于发送小块数据。我们还深入探讨了基本的同步机制,如信号量和互斥锁,以及它们在C++20中的接口。结合shmem,您观察到我们如何能够快速交换大量数据。最后,通过主要协议UDP和TCP向您介绍了通过套接字进行的网络通信。
复杂的应用程序通常依赖于多种IPC技术来实现它们的目标。了解它们的优点和缺点非常重要。这将帮助您决定您的特定实现。大多数时候,我们在IPC解决方案之上构建层,以确保应用程序的健壮性——例如,通过重试机制、轮询、事件驱动设计等。我们将在[第9章]中重新审视这些主题。下一章将为您提供自我监控可用性和性能的工具,通过不同的计时器。
![[ESP32]在Thonny IDE中,如何將MicroPython firmware燒錄到ESP32開發板中?](https://img-blog.csdnimg.cn/direct/48013f462d3c415da60991e4e32513e2.png)