文章目录
- 🚀前言
- 🚀快排的核心过程partition(划分过程)
- 🚀快排1.0
- 🚀随机快速排序
- 🚀稳定性
🚀前言
铁子们好啊!继续我们排序算法今天要讲的是快排,通常大家所说的快排都是指随机快速排序,这里阿辉会详细的讲快排及其优化以及复杂度和稳定性的分析,话不多说开始我们今天的学习吧!!!
🚀快排的核心过程partition(划分过程)
在整个快排的过程中,快排最为核心的过程就是划分过程
划分过程:就是给定一个数作为划分值,将待划分的数组分成小于划分值的部分放在数组左边、等于划分值的部分在中间和大于划分值的部分在右边(为了方便,下文阿辉就直接简称为小于区、等于区和大于区)
对于划分过程是怎么样的思路呢?
对于一个数组的划分,我们需要三个指针来控制整个划分过程
用指针i来控制整个数组的遍历,用指针left来管理小于区域,用指针right来管理大于区域

假设我们取3作为划分值,i从左向右遍历数组,要分三种情况:
- 当
i指向的元素小于划分值时,i指向的数要与left指向的数字交换,然后++i同时++left - 当
i指向的元素大于划分值时,i指向的数要与right指向的数字交换,然后--right,i不变 - 当
i指向的元素等于划分值时,仅有i自增
为什么这么设计呢?
left控制着小于区,在left左边的元素都属于小于区;right控制着大于区,在right的右边的元素都属于大于区,而等于区的左边界是left右边界是right,left和right自身以及他们俩之间的元素都属于等于区。
++left代表小于划分值的元素发货到小于区,--right代表大于划分值的元素发货到大于区。为什么发货到小于区++i因为i是从左向右遍历的,left的数换到i位置不需要再看一遍了,而发货到大于区的时候,right的数换到i位置还没有看过,还得再看一遍它该发货到哪个区域。
对于上面的数组划分完是下面这样的:
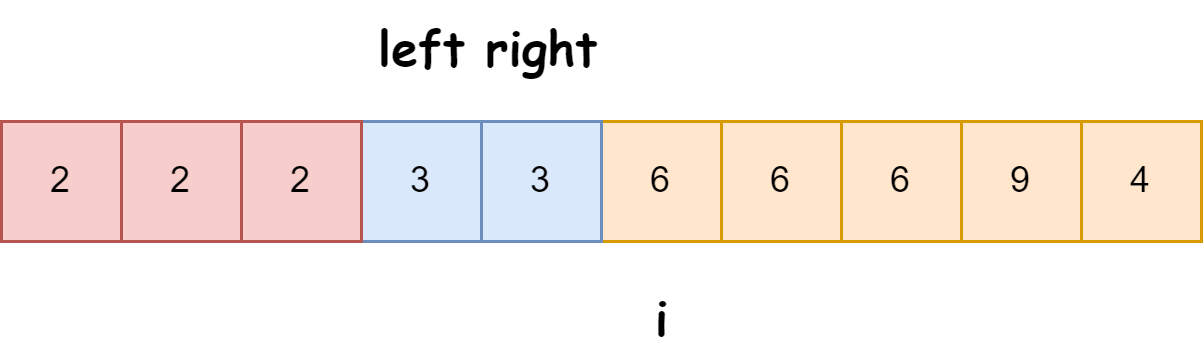
让数组这样划分成这样后,对于中间的等于区域就不需要在管了,因为就算排好序它也应该在这个位置,前面都是小于它的后面都是大于大于它的,你说它是不是该在这!!!
附上partition函数的代码:
void partition(int a[],int l,int r,int x){//划分函数//l是待划分区域左边界,r是待划分过程右边界,x是划分值int i = l;//遍历偏移量while(i <= end){//i>end时说明要划分的区域已经划分完成if(a[i] == x){//遇到等于区域数不用管,i直接遍历下一位置++i;}else if(a[i] < x){//遇到小于区域数,发货到小于区域swap(a[i++],a[l++]);//l、i同时去到下一个位置}else{//遇到大于区域数发货到大于区域swap(a[i],a[r--]);//r同时去到下一位置}}}
划分过程是O(N)的时间复杂度,因为划分过程会遍历数组整个元素,跳出循环的条件是i>r,在每一次循环过程中都是i++或者--r,所以时间复杂度是O(N)
🚀快排1.0
有了上面的划分过程,就好办了,请出我们的老伙计——递归,当我们对于原数组等于区排好了,我们给原数组小于区域和大于区再次划分然后递归下去,递归到数组只有1个元素时数组天然有序作为我们的base case也就是递归的限制条件。
现在我们的重心就是要选定划分值,但是对于固定流程的程序,我们一定可以找到让这个程序最难受的数据状况,比如数组中只有1~9这9个元素,如果我们划分值选在数组最右的元素,对于下面这个数组

我们每次都会选到数组最大的元素,导致没有大于区域,而且一次递归只能排好一个位置的数,对于划分过程partition函数的时间复杂度是O(N),然后每次待排序数组递减,明显和冒泡、插入一个级别的O(N2)的时间复杂度,也就是说快排1.0的时间复杂度是O(N2)
代码:
int begin,end;void quicksort(int a[],int l,int r){//快排主逻辑if(l >= r) return;//base case终止条件int x = a[r];//以数组最右元素作为划分值partition(a,l,r,x);//给数组根据随机出的划分值,做划分//用临时变量捕捉当前的边界,全局变量会被子递归过程更改int left = begin;int right = end;quicksort(a,l,left - 1);//左部分递归quicksort(a,right + 1,r);//右部分递归}void partition(int a[],int l,int r,int x){//划分函数//l是划分区域左边界,r是划分过程右边界begin = l;//全局变量记录等于区域左边界end = r;//全局变量记录等于区域右边界int i = l;//遍历偏移量while(i <= end){//i>end时说明要划分的区域已经划分完成if(a[i] == x){//遇到等于区域数不用管,i直接遍历下一位置++i;}else if(a[i] < x){//遇到小于区域数,发货到小于区域swap(a[i++],a[begin++]);//begin、i同时去到下一个位置}else{//遇到大于区域数发货到大于区域swap(a[i],a[end--]);//end、i同时去到下一位置}}}
我们想要的是O(NlogN)的快排,可不是这个和三大最挫排序一样效率的排序,好,让我们见识一下全盛时期的快排吧!!!
🚀随机快速排序
其实随机快排就比上面的快排1.0只换了一行代码,就让快拍的时间复杂度达到了O(NlogN)
代码:
int begin,end;void quicksort(vector<int>& a,int l,int r){//快排主逻辑if(l >= r) return;//base case终止条件int x = a[l + rand() % (r - l + 1)];//随机一个划分值partition(a,l,r,x);//给数组根据随机出的划分值,做划分//用临时变量捕捉当前的边界,全局变量会被子递归过程更改int left = begin;int right = end;quicksort(a,l,left - 1);//左部分递归quicksort(a,right + 1,r);//右部分递归}void partition(vector<int>& a,int l,int r,int x){//划分函数//l是划分区域左边界,r是划分过程右边界begin = l;//全局变量记录等于区域左边界end = r;//全局变量记录等于区域右边界int i = l;//遍历偏移量while(i <= end){//i>end时说明要划分的区域已经划分完成if(a[i] == x){//遇到等于区域数不用管,i直接遍历下一位置++i;}else if(a[i] < x){//遇到小于区域数,发货到小于区域swap(a[i++],a[begin++]);//begin、i同时去到下一个位置}else{//遇到大于区域数发货到大于区域swap(a[i],a[end--]);//end、i同时去到下一位置}}}
就改了对与划分值的选取,用了随机的方式,在数组中随机选取一个元素作为划分值,随机快速排序的时间复杂度是O(NlogN),这里是为什么呢,阿辉也只是记住,并不知道原理,这是数学家把每一种结果的概率都求出来,然后算出期望,随机快排的时间复杂度收敛于O(NlogN),在算法导论上有证明,感兴趣的小伙伴可以去研究
🚀稳定性
随机快排是没有稳定性的,换句话说是划分过程没有稳定性,比如:
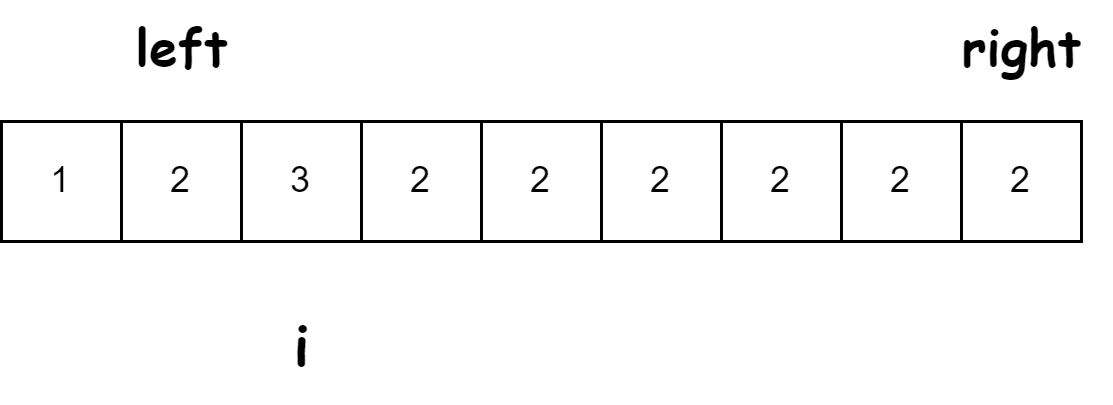
对于这样的数组,i位置与right一换,最后位置的2一下子跨越他前面那么多2,所以快排没有稳定性,但是快排比归并以及堆排序都快,是常数时间上快