使用多任务高效微调框架MFTCoder,以DeepSeek-Coder-33b模型为底座,微调获得的CodeFuse-DeepSeek-33b模型在Big Code Models Leaderboard代码大模型榜单上以43.58% WinRate成为新晋榜首,同时模型在NLP任务上也取得了很好的表现。本文我们将介绍该模型的得来和使用,包括训练数据、训练超参设置、模型评测效果以及如何获取该模型和基于它继续微调。我们已经在HuggingFace和ModelScope开放了模型下载(下载地址在文末),并同步提供了4bit量化版本供大家直接部署到生产环境。
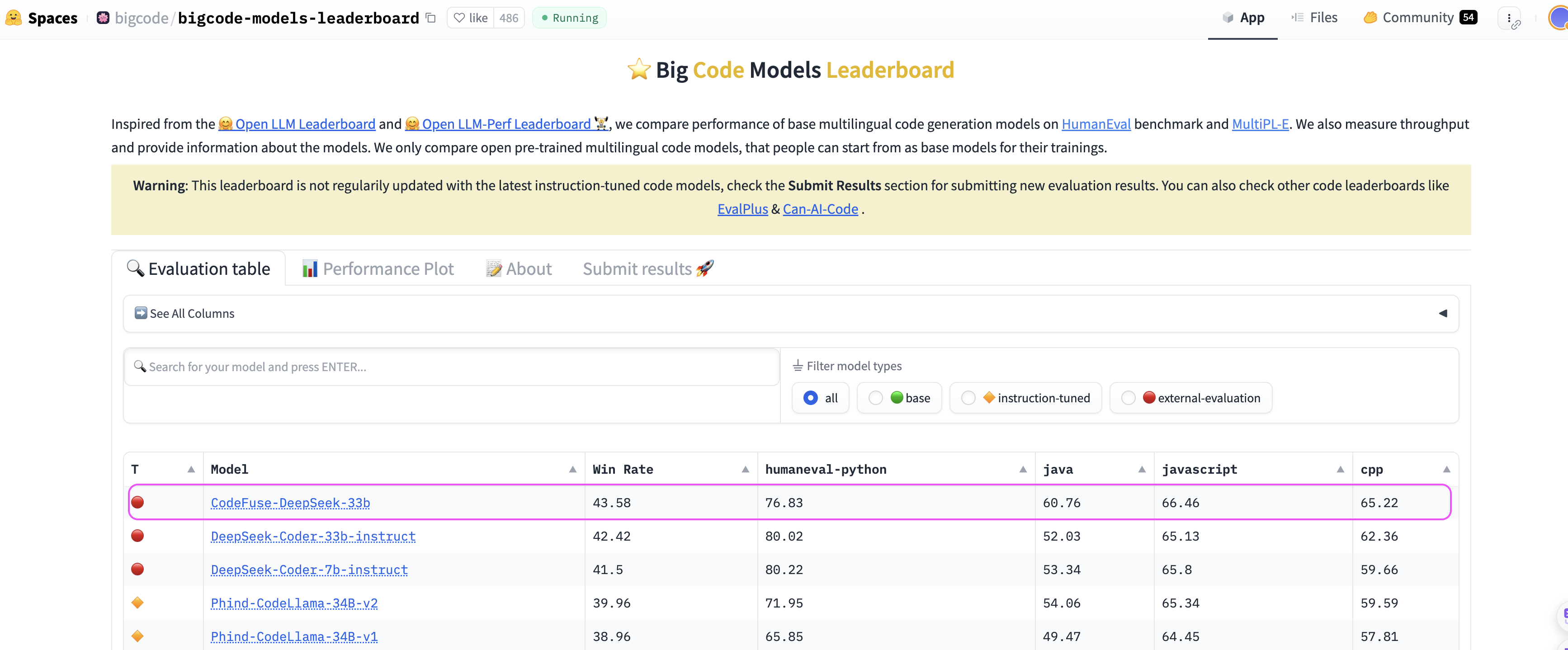
图1: Big Code Models LeaderBoard榜单截图(截取时间2024-01-30)。Big Code Models Leaderboard(https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard)是由HuggingFace BigCode团队维护的代码大模型榜单,是代码大模型领域比较权威的评测榜单。
多任务微调MFT
我们选择以DeepSeek-Coder-33b模型为底座,使用多任务微调框架MFTCoder对5个下游任务数据进行微调,得到CodeFuse-DeepSeek-33b模型。以下将更为详细地进行介绍。
训练数据
本次训练我们设置了5个下游任务,如下表1所示,包括代码补全任务、文本生成代码任务、单测生成任务、自然语言表述对齐任务和代码练习题任务,共约168万样本数据。得益于我们开源的多任务微调框架MFTCoder,这些下游任务能一定程度上相互促进,比直接将所有任务数据混合为一后微调表现更优。
表1: 下游任务训练数据统计
| 序号 | MFT下游任务 | 任务能力 | #Samples |
| 1 | 单测用例生成 | 给定函数级代码生成单元测试用例 | 390,393 |
| 2 | 代码补全 | 根据前文补全代码(方法级) | 192,547 |
| 3 | 文本生成代码 | 基于文本描述生成功能代码 | 66,862 |
| 4 | NLP表述对齐 | 增强NLP理解能力 | 951,278 |
| 5 | 代码练习题 (JAVA/CPP/GO) | 基于文本描述生成基础功能代码 | 82,603 |
| #Total | 1,683,683 | ||
关键超参设置
本次微调使用的是我们已经开源的多任务微调框架MFTCoder(https://github.com/codefuse-ai/MFTCoder/tree/main/mftcoder_accelerate),MFTCoder支持多模型适配(包括Llama 1/2、CodeLlama、Qwen、Baichuan 2、ChatGLM 2/3、CodeGeex 2、GPT-NEOX、Mistral、DeepSeek等)、多任务并行、多种均衡Loss设计、PEFT(Lora和QLora)高效微调,此前已被采纳为Qwen Code AI竞赛初赛推荐微调框架(通义千问AI挑战赛 - Code Qwen能力算法赛道_算法大赛_赛题与数据_天池大赛-阿里云天池的赛题与数据)。本次训练使用的关键超参设置如下表2所示,更多详细的参数说明可参考https://github.com/codefuse-ai/MFTCoder/tree/main/mft_peft_hf#32-loraqlora
表2: MFTCoder微调关键超参设置及解释
| 参数名称 | 参数值 | 简要解释 |
| data_split | "98,2,0" | 98%数据用于训练,2%用于验证 |
| padding_mode | "padding" | 使用动态填充模式,即每张卡每个batch大小是由每次其中的最长者动态决定而不是固定大小。另一种可选数据模式是"pack"。 |
| dynamic_padding | True | |
| weighted_loss_mode | "case3" | 使用数据均衡Loss函数,更多细节可见论文https://arxiv.org/abs/2311.02303 |
| peft_type | "qlora" | 采取QLora 4bit量化微调模式 |
| quantization | "4bit" | |
| lora_rank | 192 | 决定可训练参数比例 |
| lora_alpha | 32 | |
| per_device_train_batch_size | 4 | 训练时单卡batch大小 |
| per_device_eval_batch_size | 4 | 验证时单卡batch大小 |
| learning_rate | 5e-5 | 初始学习率 |
| min_lr | 1e-6 | 最小学习率 |
| gradient_accumulation_steps | 1 | 梯度累积步数,如果为2,则每累积2步再更新参数,资源不足是一种间接增加global batch size的方式 |
| world_size | 64 | GPU卡数,使用64张A100/A100卡 |
| evalation_steps | 500 | 每500步验证一次 |
| checkpointing_steps | 500 | 每500步保存一次检查点 |
| num_train_epochs | 10 | 最大训练轮数,最大10轮 |
| early_stopping | True | 开启early-stopping机制,即当连续3个检查点的eval loss均比倒数第4个检查点的eval loss大时终止训练 |
| early_stopping_stall_num | 3 |
使用前述训练数据和配置,经过156.5小时,模型在完成5.09 Epochs训练后触发Early-Stopping策略后终止。
模型效果
我们从代码能力和NLP能力两个方面对训练获得的CodeFuse-DeepSeek-33b进行了测试,pass@1测试均采用greedy解码模式(即doSample=False, num_beams=1, num_return_sequences=1)。
代码能力
我们选取了常用的代码评测集对模型进行评测,首先我们使用自己的CodeFuse-Evaluation评测框架(https://github.com/codefuse-ai/codefuse-evaluation)对模型在HumanEval-X(含HumanEval)和MBPP测试集上的表现进行了测试并与CodeFus此前微调过的模型进行了比较,如下表3和表4所示。
CodeFuse-DeepSeek-33b在HumanEval上pass@1指标值为78.65%、在MBPP上为71%(zero-shot),两项平均为74.83%,略高于DeepSeek-Coder-Instruct-33B。
CodeFuse-DeepSeek-33b在多语言评测集HumanEval-X上pass@1指标值平均为67.07%,比此前我们开放的CodeFuse-CodeLlama-34b模型高6.69%,在具体各种语言上高出3.48%~12.19%不等。
表3: CodeFuse-DeepSeek-33b模型与其他开源底座模型及微调模型在HumanEval和MBPP上的对比

表4: CodeFuse-DeepSeek-33b模型与其他开源底座模型及MFT微调模型在HumanEval-X上的对比

由于不同评测框架在代码后处理和生成终止条件(Stop Words)等方面常存在差异,除了用我们自己的CodeFuse-Evaluation评测框架,我们也用代码大模型榜单Big Code Models LeaderBoard所用的开源评测框架bigcode-evaluation-harness (https://github.com/bigcode-project/bigcode-evaluation-harness)进行了评测,并与榜单上的模型进行了比较。榜单会测试模型在Python代码补全测试集HumenEval和多语言代码补全测试集MultiPL-E共12种语言上的表现,并根据各语言表现进行WinRate排序。(结果复现代码地址:https://github.com/twelveand0/bigcode-evaluation-harness)
表5: 采用bigcode-evaluation-harness评测CodeFuse-DeepSeek-33b模型后的新榜单

如表5所示,CodeFuse-DeepSeek-33b模型的WinRate为43.58%,超过原榜首DeepSeek-Coder-33b-instruct。在HumanEval评测集上,CodeFuse-DeepSeek-33b表现不如DeepSeek-Coder-33b-instruct,但在其他8种语言(包括Java和JS等)上超过后者,均值(Average Score)亦超过后者1.7%。
NLP通用能力
对于NLP通用能力测试,我们参照OpenCompass选择了18个评测集,包括语言能力(AFQMC、CHID、Wic、WSC)、推理能力(COPA、CMNLI、OCNLI、Ax-b、Ax-g、RTE)、理解能力(CSL、C3、EPRSTMT)、学科综合能力(MMLU、C-Eval、ARC-c)、代码能力(HumanEval、MBPP)。对于每个模型,我们会使用生成式和PPL方式计算每个指标,并在每个维度上选取两种方式中较高的值作为指标值。
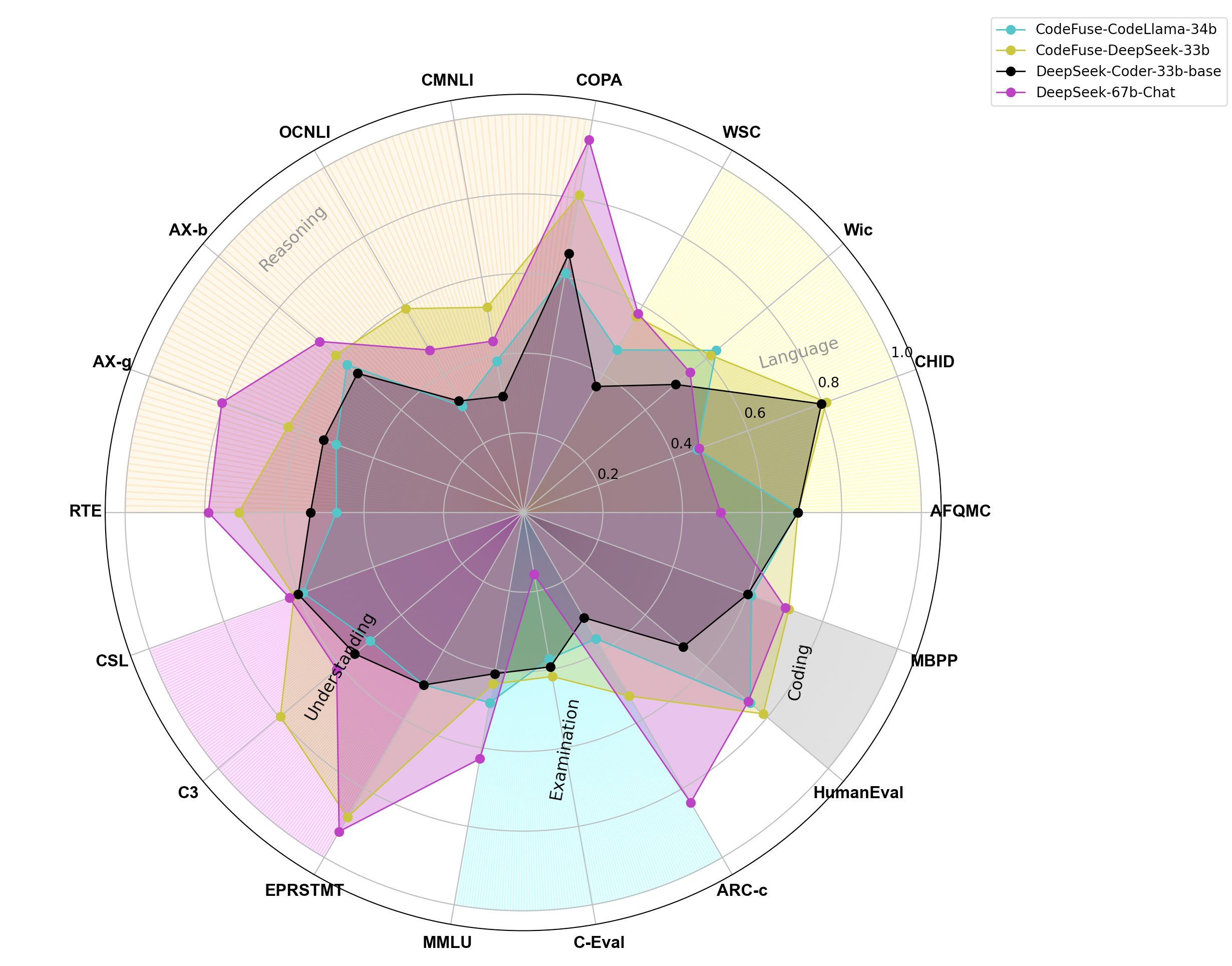
图2: CodeFuse-DeepSeek-33b NLP通用能力雷达图
CodeFuse-DeepSeek-33b模型的评测结果如图3雷达图所示,我们将其与底座模型DeepSeek-Coder-33b和DeepSeek通用模型DeepSeek-67b-Chat进行了对比。从图中可以看出,相较于底座模型DeepSeek-Coder-33b,CodeFuse-DeepSeek-33b在所有维度上均有正向提升;相较于我们此前开源的CodeFuse-CodeLlama-34b,CodeFuse-DeepSeek-33b在绝大多数维度上表现更优;相较于通用模型DeepSeek-67b-Chat,CodeFuse-DeepSeek-33b在语言能力、代码能力和理解能力上整体表现更优,在推理能力上表现稍差,在学科综合能力上差距较大。考虑到模型参数规模差距和底座目标功能类型差异,我们认为CodeFuse-DeepSeek-33b已经表现很好。
模型INT4量化
为了便于直接部署投入生产,我们同步提供了CodeFuse-DeepSeek-33b-INT4量化版本。对于量化后的模型,我们测试了它的代码能力,如表5所示,量化后模型在代码补全任务上只有微弱降幅。
表5:模型量化前后在HumanEval-X和MBPP上的指标对比
| Model | HumanEval-X | MBPP | ||||
| Python | Java | C++ | JS | Go | ||
| CodeFuse-DeepSeek-33b | 78.65% | 67.68% | 65.85% | 67.07% | 56.10% | 71.0% |
| CodeFuse-DeepSeek-33b-INT4 | 78.05% | 68.29% | 62.19% | 64.63% | 55.49% | |
此外,我们测试了该模型实际部署后的性能。测试环境为单张A10(24G显存)、部署框架为NVIDIA开源的tensorRT。测试结果具体如表6所示:
表6: CodeFuse-DeepSeek-33b-INT4在单张A10的推理性能
| 模型版本 | CodeFuse-DeepSeek-33b | |
| 推理速度指标 | Tokens/s | |
| 模型并行/gpu型号 | 单卡A10 | |
| 量化格式 | int4 | |
| 输入/输出长度 | 16/8 | 21.7 |
| 64/32 | 21.5 | |
| 256/128 | 21.1 | |
| 1024/512 | 20.5 | |
模型下载试用
我们开放了量化前后2个模型的下载,提供了推理格式和推理示例,并说明了如何在此基础上继续微调。
下载
我们已经将2个模型(CodeFuse-DeepSeek-33b和CodeFuse-DeepSeek-33b-INT4)发布到HuggingFace和ModelScope社区,大家可以选择通过以下链接下载:
| Model | HuggingFace | ModelScope |
| CodeFuse-DeepSeek-33b | https://huggingface.co/codefuse-ai/CodeFuse-DeepSeek-33B | CodeFuse-DeepSeek-33B |
| CodeFuse-DeepSeek-33b-4bits | https://huggingface.co/codefuse-ai/CodeFuse-DeepSeek-33B-4bits | CodeFuse-DeepSeek-33B-4bits |
推理格式与代码
CodeFuse-DeepSeek-33b使用的推理格式如下:
<s>system
{THIS IS YOUR SYSTEM PROMPT}
<s>human
{THIS IS YOUR PROMPT of ROUND 1}
<s>bot
{THIS IS MODEL's RESPONSE of ROUND 1}
<s>human
{THIS IS YOUR PROMPT of ROUND 2}
<s>bot在这个格式中,sysem部分是可选的,对话轮数可以是多轮的也可以是单轮的。下面是一些具体的案例展示:
<s>human
请写一个快排程序
#Python
<s>bot
<s>system
你是CodeFuse,你会被给定一个任务,你必须按照用户的要求完成任务。
<s>human
请写一个快排程序
#Python
<s>bot
下面是一个使用Python编写的快速排序算法的示例代码:
```python
def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)
# 测试快速排序算法
arr = [3, 6, 8, 10, 1, 2, 1]
print(quick_sort(arr))
```
这段代码定义了一个`quick_sort`函数,它接受一个列表作为参数,并返回排序后的列表。在函数内部,首先判断列表的长度是否小于等于1,如果是,则直接返回列表本身。否则,选择列表中间的元素作为基准值,并将列表分成三个部分:小于基准值的部分、等于基准值的部分和大于基准值的部分。然后,对这三个部分分别递归调用`quick_sort`函数进行排序,最后将排序后的三个部分合并并返回。
通过这个示例,你可以了解到如何使用Python编写快速排序算法,并对其进行测试。
<s>human
请为以上代码生成单测用例
<s>bot
下面是一段示例的推理代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfigmodel_dir = "codefuse-ai/CodeFuse-DeepSeek-33B"def load_model_tokenizer(model_path):tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)tokenizer.eos_token = "<|end▁of▁sentence|>"tokenizer.pad_token = "<|end▁of▁sentence|>"tokenizer.eos_token_id = tokenizer.convert_tokens_to_ids(tokenizer.eos_token)tokenizer.pad_token_id = tokenizer.convert_tokens_to_ids(tokenizer.pad_token)tokenizer.padding_side = "left"model = AutoModelForCausalLM.from_pretrained(model_path, device_map='auto',torch_dtype=torch.bfloat16, trust_remote_code=True)return model, tokenizerHUMAN_ROLE_START_TAG = "<s>human\n"
BOT_ROLE_START_TAG = "<s>bot\n"text_list = [f'{HUMAN_ROLE_START_TAG}Write a QuickSort program\n#Python\n{BOT_ROLE_START_TAG}']model, tokenizer = load_model_tokenizer(model_dir)
inputs = tokenizer(text_list, return_tensors='pt', padding=True, add_special_tokens=False).to('cuda')
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
generation_config = GenerationConfig(eos_token_id=tokenizer.eos_token_id,pad_token_id=tokenizer.pad_token_id,temperature=0.1,max_new_tokens=512,num_return_sequences=1,num_beams=1,top_p=0.95,do_sample=False
)
outputs = model.generate(inputs= input_ids,attention_mask=attention_mask,**generation_config.to_dict()
)
gen_text = tokenizer.batch_decode(outputs[:, input_ids.shape[1]:], skip_special_tokens=True)
print(gen_text[0])继续微调
如果你想在这两个模型基础上继续微调,欢迎使用我们开源的多任务高效微调框架MFTCoder(https://github.com/codefuse-ai/MFTCoder/tree/main/mftcoder_accelerate)。要继续微调,你需要准备好训练数据集(CodeFuse-ChatML格式)、设置训练配置文件、设置运行配置文件并启动训练。这里提供一个对Qwen-1.8模型用MFTCoder进行微调的案例供参考:https://github.com/codefuse-ai/MFTCoder/tree/codeqwen_competition/mft_peft_hf。
联系我们
MFTCoder已经开源,本文中提到的模型和数据集也在陆续开源中,如果您喜欢我们的工作,欢迎试用、指正错误和贡献代码,可以的话请给我们的项目增加Star以支持我们。
- GitHub项目主页:https://github.com/codefuse-ai/MFTCoder
- HuggingFace主页:https://huggingface.co/codefuse-ai
- 魔搭社区主页:ModelScope 魔搭社区