1 Spark是什么
Spark是用于大规模数据处理的统一分析引擎。对任意类型的数据进行自定义计算。
可以计算:结构化、非结构化,半结构化的数据结构,支持使用Python,Java,Scala、Sql语言开发应用程序计算数据。
计算框架:
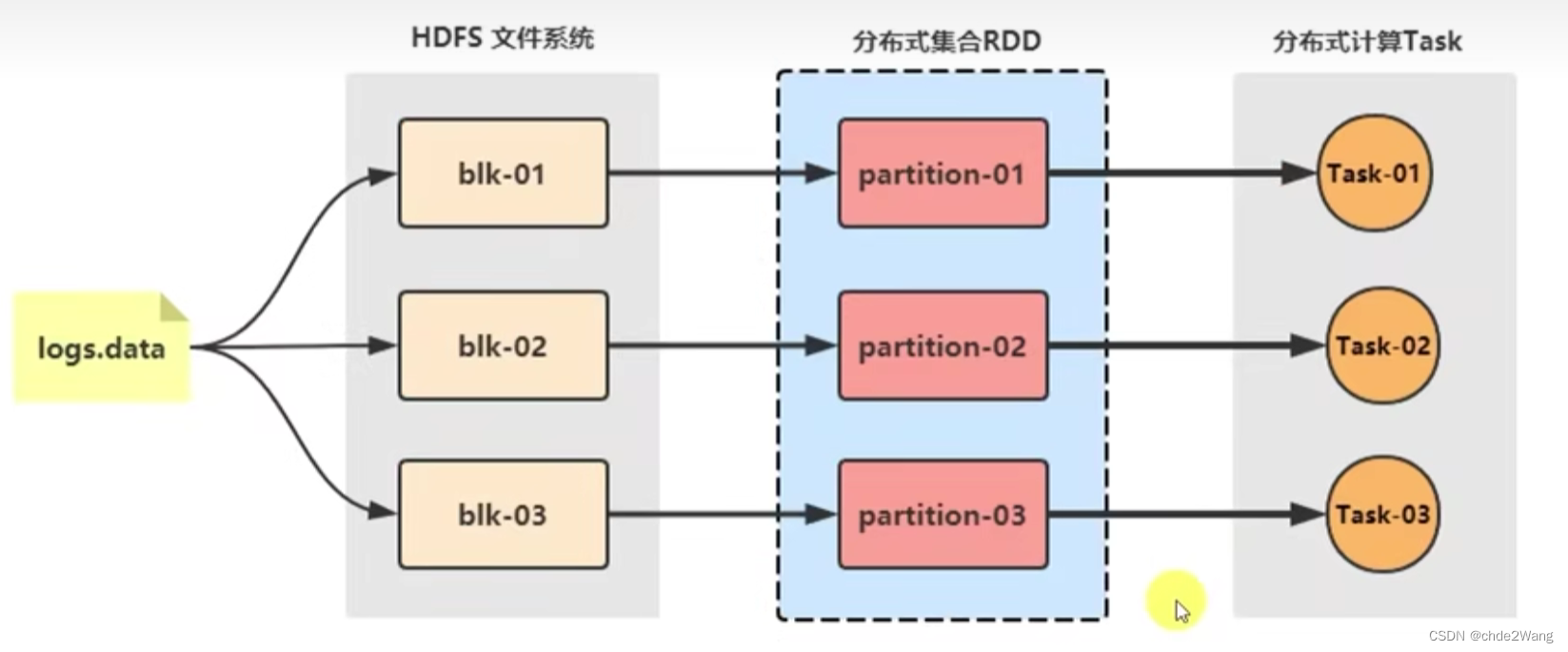
Spark借鉴了MapReduce思想,保留了其分布式并行计算的有点并改进了其明显的缺陷,让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
Hadoop和Spark对比
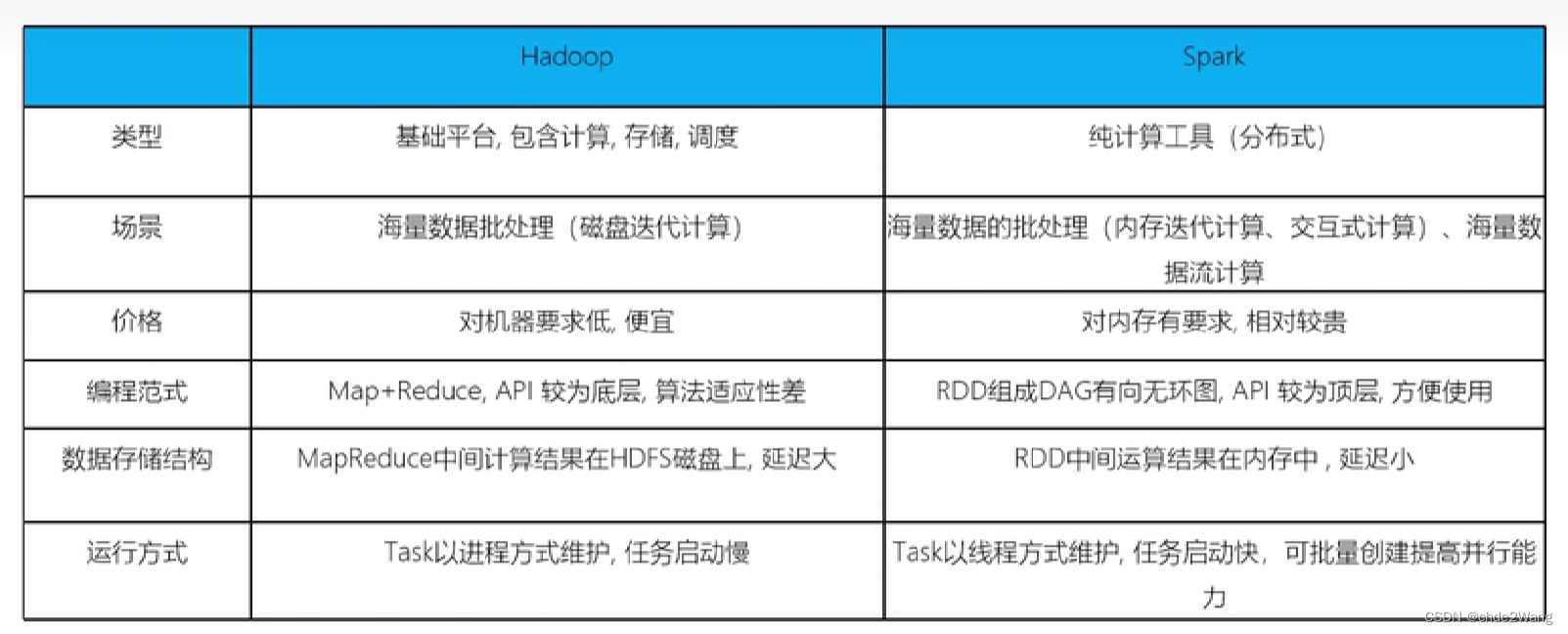
- 在计算层面,Spark相比较MapReduce有巨大的性能优势,但至今仍有很多计算工具基于MR框架
- Spark仅做计算,而Hadoop生态圈不仅有计算MR,还有存储HDFS,和资源管理调度YARN
2 Spark四大特点
- 速度快
- 处理数据时,将中间结果数据存储到内存中
- 提供非常丰富的算子(API)
- 易于使用
- 通用性强
 - 运行方式多
- 运行方式多
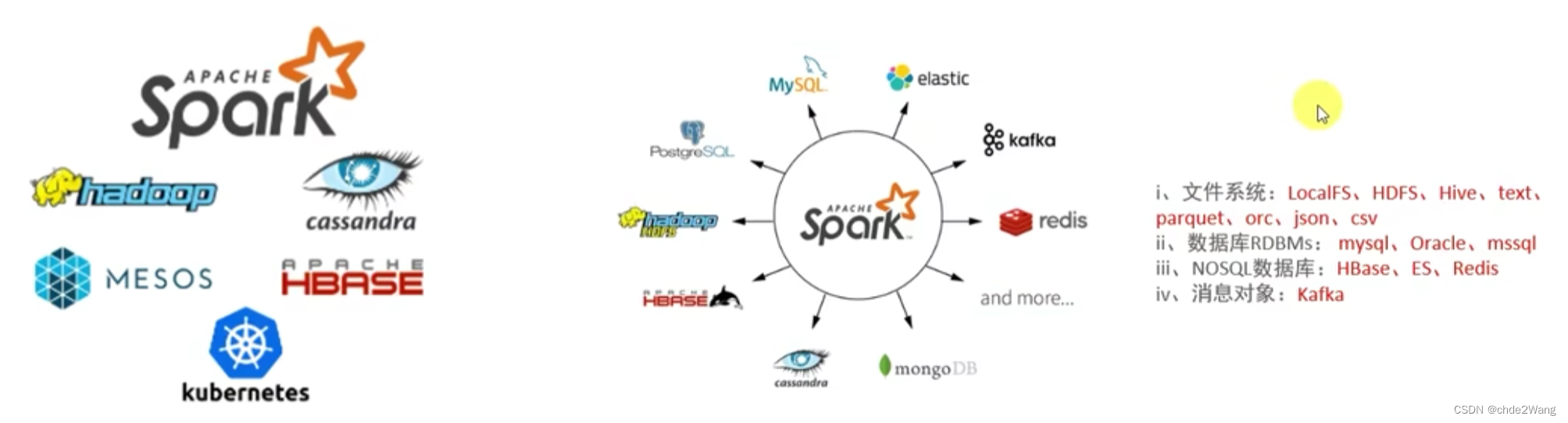
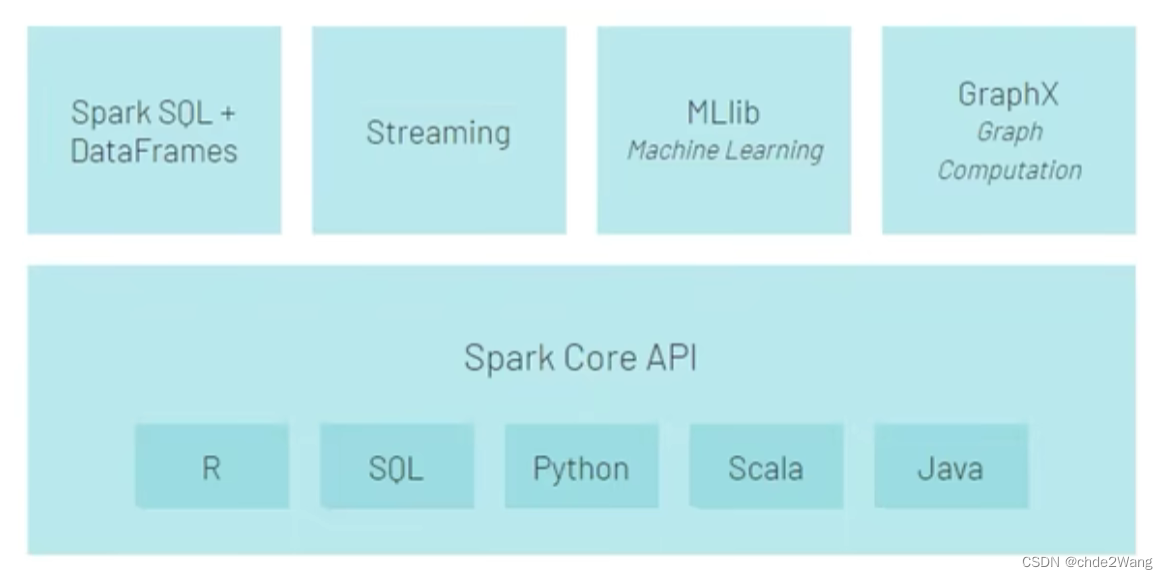
3 Spark框架
- SparkCore:Spark的核心,Spark核心功能均由SparkCore模块提供,是Spark运行的基础。SparkCore以RDD为数据抽象,提供Python、Java、ScalaR语言的API,可以编程进行海量离线数据批处理计算。
- SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparksQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了Structuredstreaming模块,可以SparkSQL为基础,进行数据的流式计算。
- SparkStreaming: 以Sparkcore为基础,提供数据的流式计算功能。
- MLlib: 以Sparkcore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
- GraphX: 以Sparkcore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
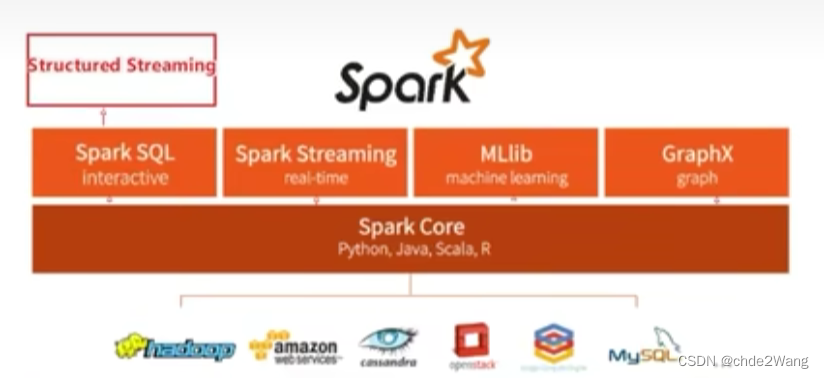
4 Spark的运行模式
- 本地模式(单机):独立的进程,通过其内部的多个线程来模拟整个Spark运行时环境,多用于本地测试
- Standlone模式(集群):各个角色以独立进程的形式存在,并组成Spark集群环境,Standalone是Spark自带的一个资源调度框架,支持完全分布式
- Hadoop YARN模式(集群):各个角色运行在YARN的容器内部,并组成Spark集群环境
- Kubernetes模式(容器模式):各个角色运行在Kubernetes的容器内部,并组成Spark集群环境
- 云服务模式(运行在云平台上)
5 Spark架构角色
5.1.YARN角色回顾
YARN主要有4类角色,从2个层面去看:
- 资源管理层面
* 集群资源管理者 (Master):ResourceManager
* 单机资源管理者 (Worker):NodeManager,所在服务器的资源管理 - 任务计算层面
- 单任务管理者(Master):ApplicationMaster(当前计算任务的管家)
- 单任务执行者(Worker):Task(容器内计算框架的工作角色)
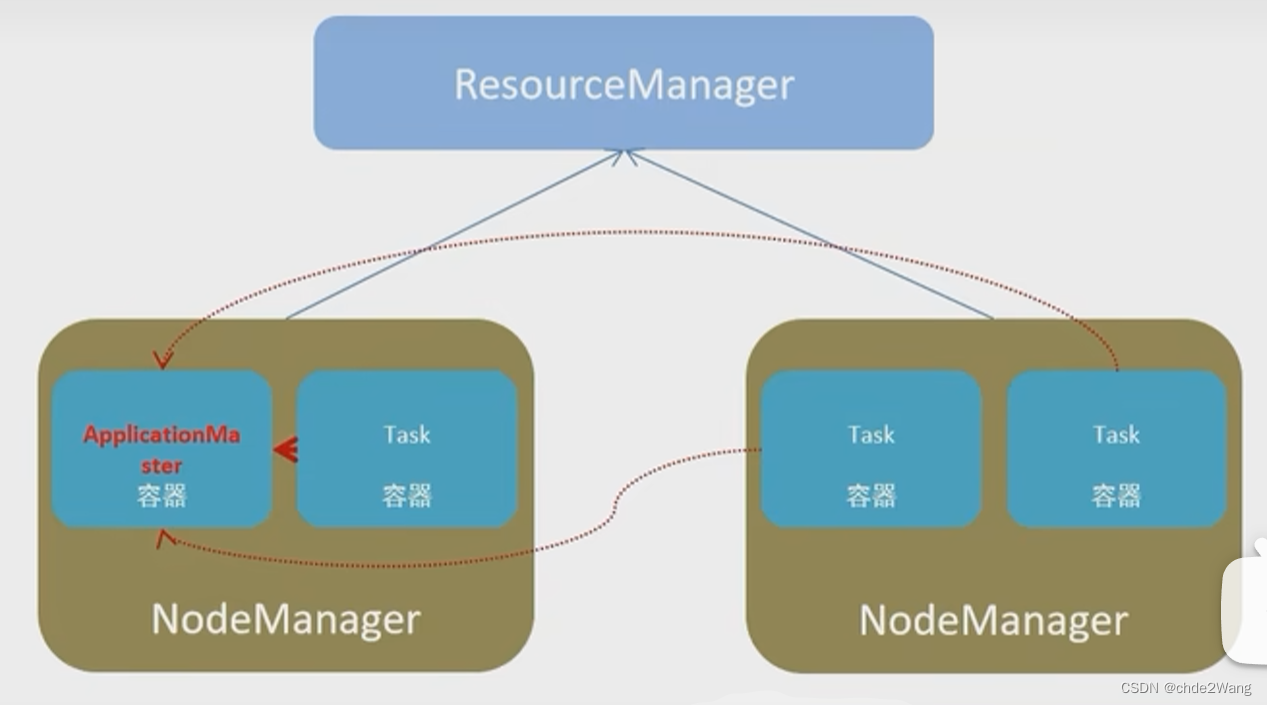
5.2.Spark运行角色
- 资源管理层面
* 集群资源管理者 :Master
* 单机资源管理者 :Worker - 任务计算层面
- 单任务管理者:Driver,管理单个Spark任务在运行时工作
- 单任务执行者:Executor,单个任务运行时的一堆工作者
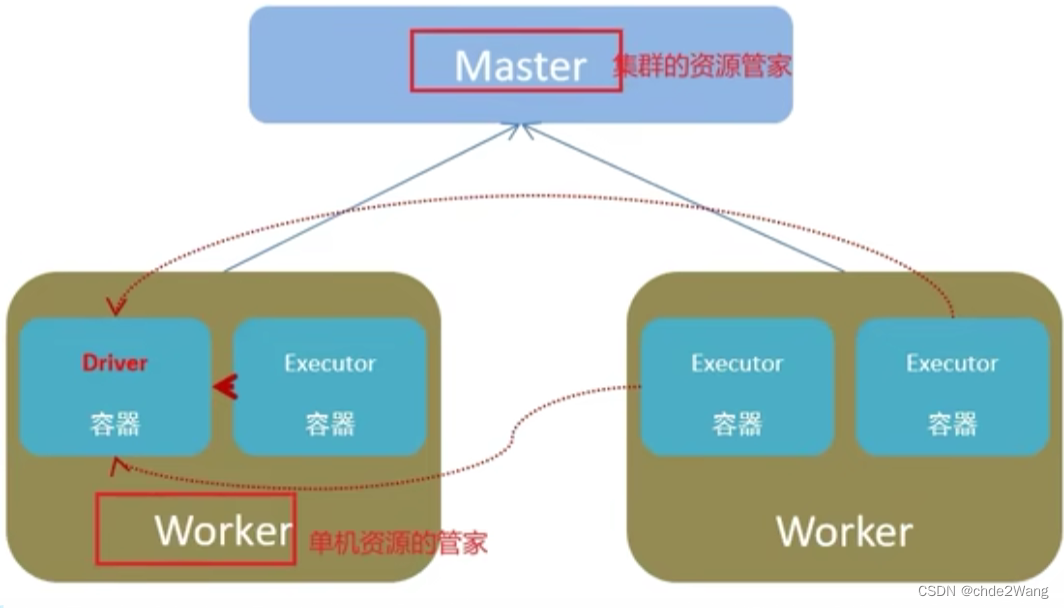
5.3 YARN和Spark对比
从2个层面划分:
- 资源管理层面:
管理者:Spark是Master角色, YARN是ResourceManager
工作中:Spark是Worker角色,YARN是NodeManager - 任务执行层面:
某任务管理者:Spark是Driver角色,YARN是ApplicationMaster
某任务执行者:Spark是Executor角色,YARN是容器中运行的具体工作进程