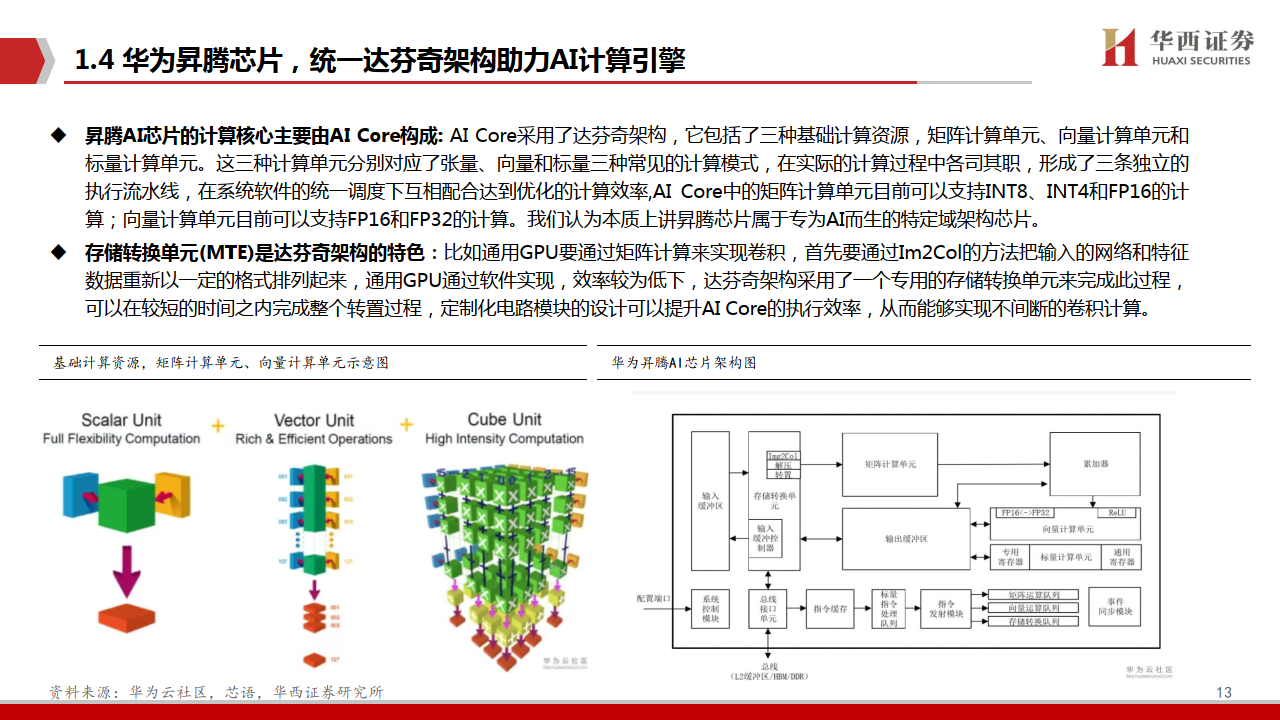
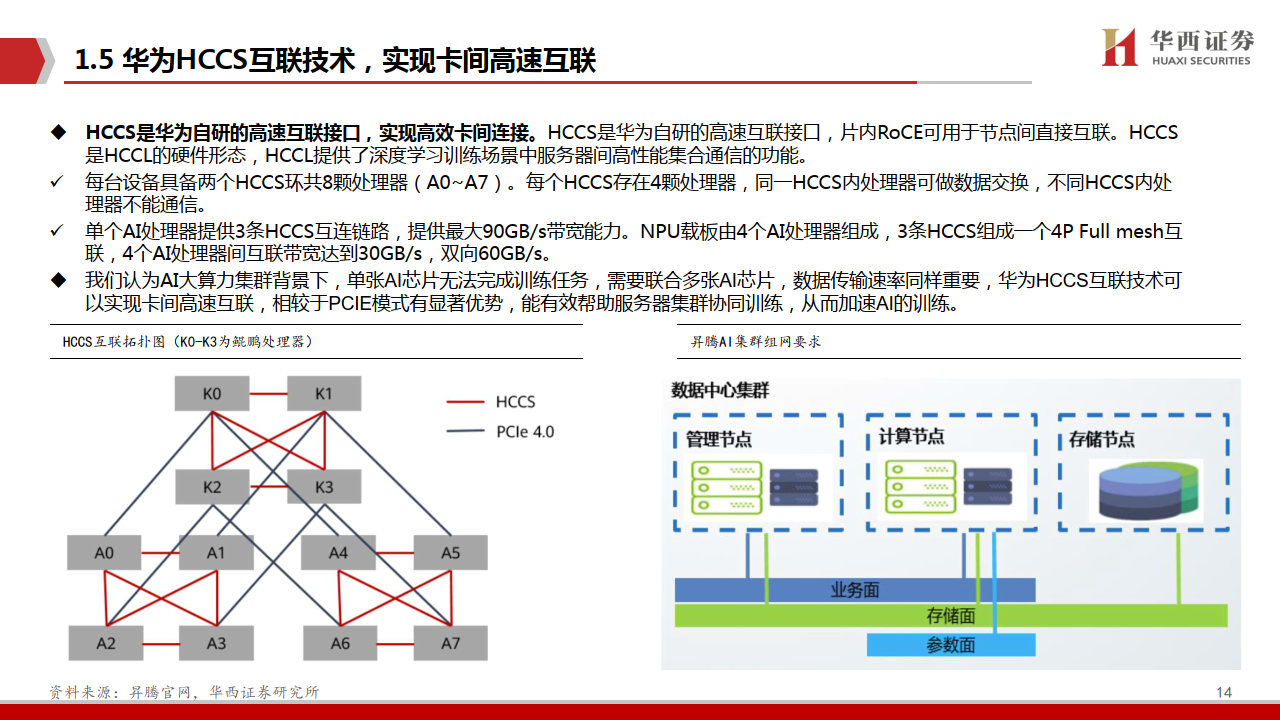
今天分享的是AI算力系列深度研究报告:《AI算力专题:华为算力分拆:全球AI算力的第二极》。
(报告出品方:华西计算机团队)
报告共计:53页
全球龙头英伟达业绩持续高度景气,印证全球AI产业趋势
英伟达二季度业绩持续超预期,印证AI景气度:美东时间8月23日,英伟达公布2024财年第二财季季报。二季度营收135.07亿美元,同 比增长101%,远超市场预期的指引区间107.8亿到112.2亿美元,相较于华尔街预期水平高22%-29%以上。业绩指引方面,英伟达预计, 本季度、即2024财年第三财季营业收入为160亿美元,正负浮动2%,相当于指引范围在156.8亿到163.2亿美元之间。以160亿美元计 算,英伟达预期三季度营收将同比增长170%,连续两个季度翻倍增长,高于市场预期。
AI芯片所在业务同环比均翻倍激增较市场预期高近30%,游戏业务同比重回增长: AI对英伟达业绩的贡献突出。包括AI显卡在内的英伟 达核心业务数据中心同样收入翻倍激增,二季度数据中心营业收入为103.2亿美元,同比增长171%,环比增长141%;二季度游戏营收 24.9亿美元,同比增长22%,环比增长11%,英伟达称,数据中心收入主要来自云服务商和大型消费类互联网公司。基于Hopper和A mpere 架构GPU的英伟达HGX平台之所以强劲需求,主要源于开发生成式AI和大语言模型的推动。
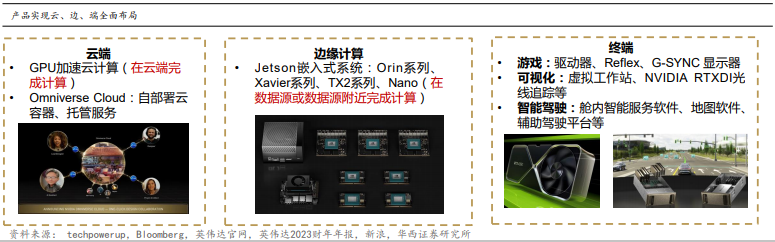
英伟达三大AI法宝
高性能芯片,其中IC设计是重点
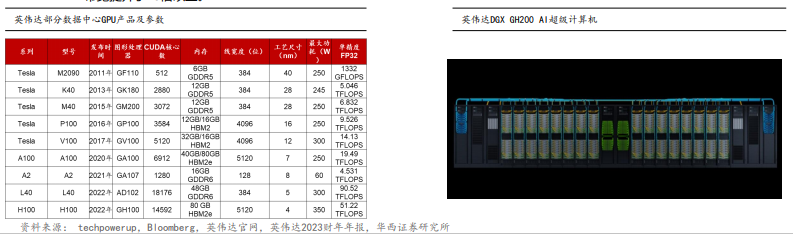
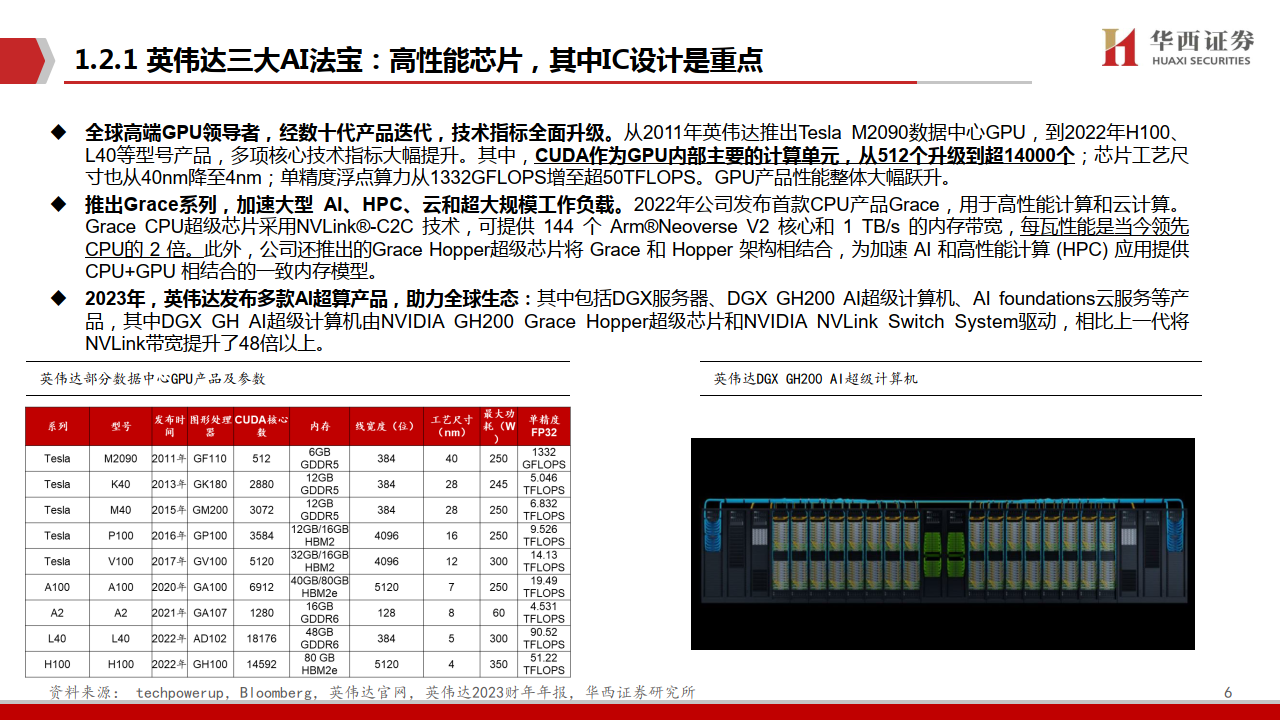
全球高端GPU领导者,经数十代产品迭代,技术指标全面升级。从2011年英伟达推出Tesla M2090数据中心GPU,到2022年H100、 L40等型号产品,多项核心技术指标大幅提升。其中,CUDA作为GPU内部主要的计算单元,从512个升级到超14000个;芯片工艺尺 寸也从40nm降至4nm;单精度浮点算力从1332GFLOPS增至超50TFLOPS。GPU产品性能整体大幅跃升。
推出Grace系列,加速大型 AI、HPC、云和超大规模工作负载。2022年公司发布首款CPU产品Grace,用于高性能计算和云计算。 Grace CPU超级芯片采用NVLink®-C2C 技术,可提供 144 个 Arm®Neoverse V2 核心和 1 TB/s 的内存带宽,每瓦性能是当今领先 CPU的 2 倍。此外,公司还推出的Grace Hopper超级芯片将 Grace 和 Hopper 架构相结合,为加速 AI 和高性能计算 (HPC) 应用提供 CPU+GPU 相结合的一致内存模型。
2023年,英伟达发布多款AI超算产品,助力全球生态:其中包括DGX服务器、DGX GH200 AI超级计算机、AI foundations云服务等产 品,其中DGX GH AI超级计算机由NVIDIA GH200 Grace Hopper超级芯片和NVIDIA NVLink Switch System驱动,相比上一代将 NVLink带宽提升了48倍以上。
CUDA架构,助力AI加速计算生态
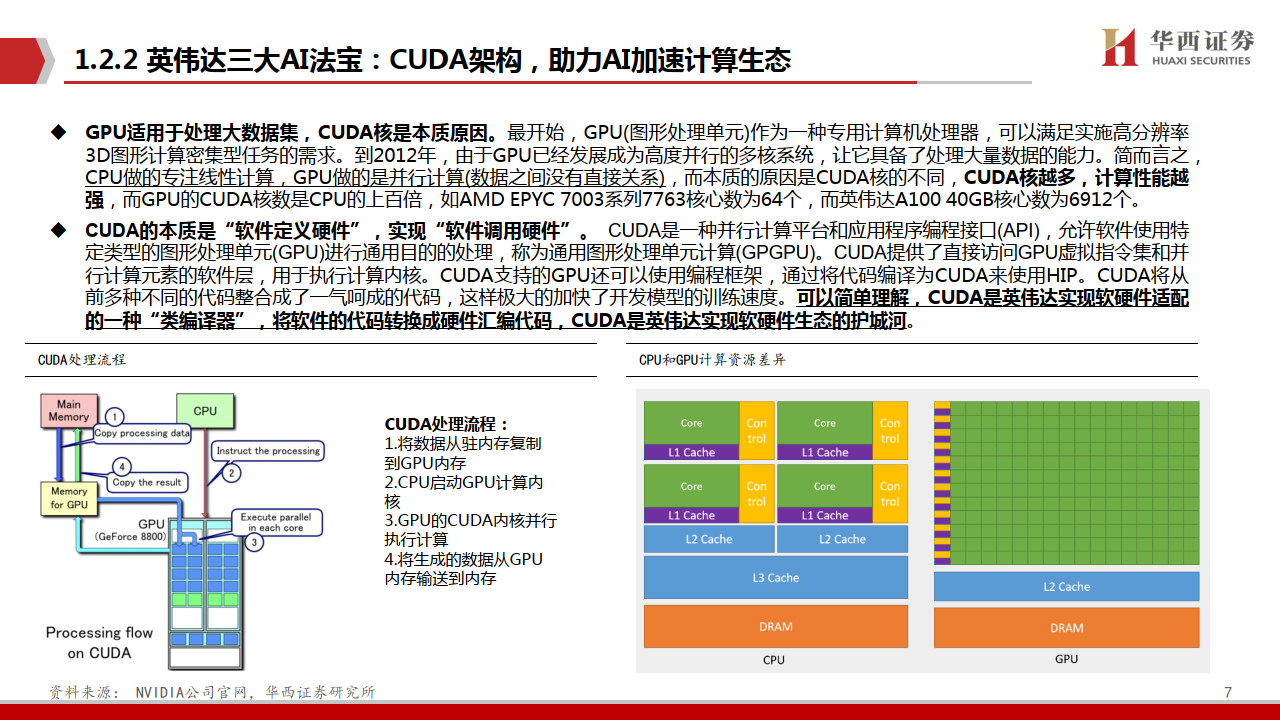
GPU适用于处理大数据集,CUDA核是本质原因。最开始,GPU(图形处理单元)作为一种专用计算机处理器,可以满足实施高分辨率 3D图形计算密集型任务的需求。到2012年,由于GPU已经发展成为高度并行的多核系统,让它具备了处理大量数据的能力。简而言之, CPU做的专注线性计算,GPU做的是并行计算(数据之间没有直接关系),而本质的原因是CUDA核的不同,CUDA核越多,计算性能越 强,而GPU的CUDA核数是CPU的上百倍,如AMD EPYC 7003系列7763核心数为64个,而英伟达A100 40GB核心数为6912个。
CUDA的本质是“软件定义硬件”,实现“软件调用硬件”。 CUDA是一种并行计算平台和应用程序编程接口(API),允许软件使用特 定类型的图形处理单元(GPU)进行通用目的的处理,称为通用图形处理单元计算(GPGPU)。CUDA提供了直接访问GPU虚拟指令集和并 行计算元素的软件层,用于执行计算内核。CUDA支持的GPU还可以使用编程框架,通过将代码编译为CUDA来使用HIP。CUDA将从 前多种不同的代码整合成了一气呵成的代码,这样极大的加快了开发模型的训练速度。可以简单理解,CUDA是英伟达实现软硬件适配 的一种“类编译器”,将软件的代码转换成硬件汇编代码,CUDA是英伟达实现软硬件生态的护城河。
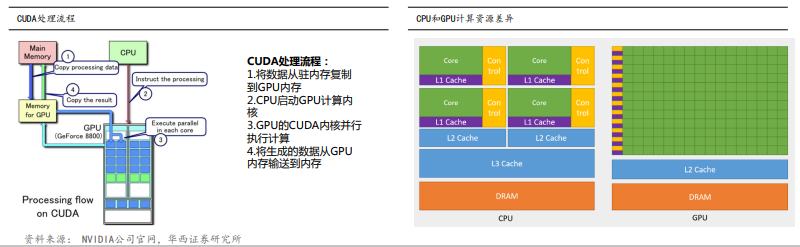
CUDA助力加速计算及深度学习:GPU通过图形应用程序的算法存在算法密集、高度并行、控制简单、分多个阶段执行等特征,英伟达 引入的CUDA使GPU超越了图形领域。同时,CUDA的框架和库可以充分发挥GPU的并行计算能力,提供高效的矩阵运算、卷积运算等 计算任务的实现,大大简化深度学习的编程工作,提高开发效率和代码质量。在经GPU加速的应用中,工作负载的串行部分在CPU上 运行,而应用的计算密集型部分则以并行方式在数千个GPU 核心上运行,能够大幅提升计算效率。目前NVIDIA H100 GPU的CUDA数 已达到14592个,远超AMD EPYC Genoa-X CPU的96个核心。
CUDA生态合作者规模翻倍增长。根据英伟达2023财年年报,目前有400万名开发者正在与CUDA合作,而且规模还在不断扩大。英伟 达通过12年的时间达到200万名开发者,在过去的两年半里该数字翻了一番。目前CUDA的下载量已经超过了4000万次。

Nvlink、NVSwitch助力芯片快速互联互通
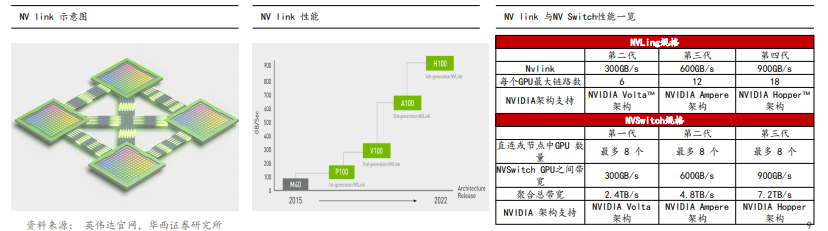
速度更快、可扩展性更强的互连已成为当前的迫切需求: AI和高性能计算领域的计算需求不断增长,对于能够在每个GPU之间实现无缝 高速通信的多节点、多GPU系统的需求也在与日俱增。要打造功能强大且能够满足业务速度需求的端到端计算平台,可扩展的快速互 连必不可少。简而言之,随着模型复杂程度增加,单张GPU无法完成训练任务,需要联合多张GPU,乃至多台服务器搭建集群协同工 作,并需要GPU之间以及服务器之间进行数据传输交互。我们认为数据传输同样也是大模型算力集群能力的重要体现。
英伟达推出NVLink技术代替传统的PCIe技术:第四代NVIDIA® NVLink® 技术可为多GPU系统配置提供高于以往1.5倍的带宽,以及增 强的可扩展性。单个 NVIDIA H100 Tensor Core GPU 支持多达18个NVLink 连接,总带宽为900GB/s,是PCIe 5.0带宽的7倍。NVIDIA DGX™ H100等服务器可利用这项技术来提高可扩展性,进而实现超快速的深度学习训练。
NVSwitch与Nvlink协同互联,助力英伟达高速通信能力构建: NVSwitch是一种高速交换机技术,可以将多个 GPU 和 CPU 直接连接起 来,形成一个高性能计算系统。每个NVSwitch都有 64 个 NVLink 端口,并配有 NVIDIA SHARP™ 引擎,可用于网络内归约和组播加 速。








报告共计:53页