ElasticSearch的内存从大的结构可以分堆内存(On Heap)和堆外内存(Off Heap)。Off Heap部分由Lucene进行管理。On Heap部分存在可GC部分和不可GC部分,可GC部分通过GC回收垃圾对象,从而释放内存。不可GC部分不能通过GC回收垃圾对象,这部分会通过LRU算法进行对象清除并释放内存。更加具体的内存占用与分配如下图:

查看和删除缓存
查看cache情况:
GET /_stats/query_cache?pretty&human
GET _cat/nodes?help 查看node参数
GET _cat/nodes?v&h=id,queryCacheMemory,queryCacheEvictions,requestCacheMemory,requestCacheHitCount,requestCacheMissCount,flushTotal,flushTotalTime清理节点查询缓存:
POST /twitter/_cache/clear?query=true清理 request 请求缓存:
POST /twitter/_cache/clear?request=true清理 field data 缓存:
POST /twitter/_cache/clear?fielddata=true 指定索引twitter和kimchy清理缓存:
POST /kimchy,twitter/_cache/clear清理全部的缓存:
POST /_cache/clear
On Heap内存
这部分内存占用的模块包括:Indexing Buffer、Node Query Cache、Shard Request Cache、Field Data Cache以及Segments Cache。
Indexing Buffer
索引写入缓冲区,用于存储新写入的文档,当其被填满时,缓冲区中的文档被refresh到 OS中的 segments 中。这部分空间是可GC被反复利用的。节点上所有 shard 共享indexing buffer。
indices.memory.index_buffer_size:10% # 占总内存比例或绝对值,默认10%
indices.memory.min_index_buffer_size:48M # 最小index buffer内存, 默认48M
indices.memory.max_index_buffer_size:自定义 # 最大index buffer内存, 无默认值参考: Indexing buffer settings | Elasticsearch Guide [8.12] | Elastic
Node Query Cache (Filter Cache)
节点级别的缓存,节点上的所有分片共享此缓存,是Lucene层面的实现。缓存的是某个filter子查询语句在一个segment上的查询结果。如果一个segment缓存了某个filter子查询的结果,下次可以直接从缓存获取结果,无需再在segment内进行过滤查询。
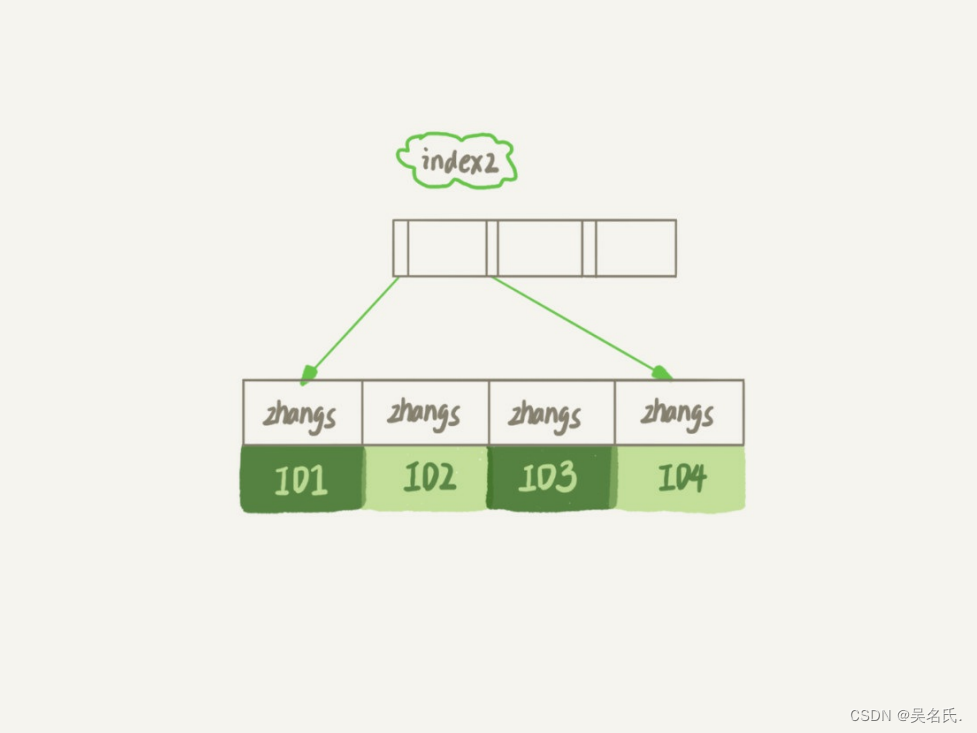
每个segment有自己的缓存,缓存的key为filter子查询(query clause ),缓存内容为查询结果,这些查询结果是匹配到的document numbers,保存在位图FixedBitSet中。
缓存的构建过程是:对segment执行filter子查询,先获取查询结果中最大的 document number: maxDoc(document number是lucene为每个doc分配的数值编号,fetch的时候也是根据这个编号获取文档内容)。然后创建一个大小为 maxDoc的位图:FixedBitSet,遍历查询命中的doc,将FixedBitSet中对应的bit设置为1。
例如:查询结果的maxDoc是8,那么创建出的FixedBitSet就是:[0,0,0,0,0,0,0,0],可以理解为是一个长度为8的二值数组,初始值都是0,假设filter查询结果的doc列表是:[1,4,8],那么FixedBigSet就设置为:
[1,0,0,1,0,0,0,1],当查询有多个filter子查询时,对位图做交并集位运算即可。
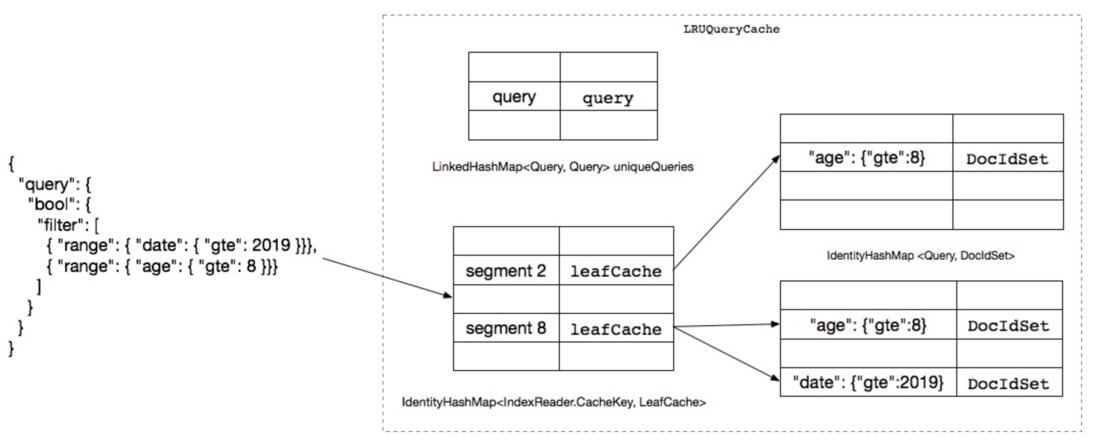
用一个例子来说明Node Query Cache结构。如下图查询语句包含两个子查询,分别是对date和age字段的range查询,Lucene在查询过程中遍历每个 segment,检查其各自的LRUQueryCache能否命中filter子查询,segment 8命中了对age和date两个字段的缓存,将会直接返回结果。segment 2只命中了对age字段的缓存,没有命中date字段缓存,将继续执行查询过程。
缓存设置
Node query cache settings | Elasticsearch Guide [8.12] | Elastic
indices.queries.cache.count #默认 10000, 最多缓存 10000个子查询的结果(LRU 的大小)
indices.queries.cache.size #默认 10%, 最多使用堆内存的10%
index.queries.cache.enabled 是否启用query cache, true/false
indices.queries.cache.all_segments 默认是false, 用于是否在所有 Segment上启用缓存,总结:
1)只有Filter下的子Query才能参与Cache。
2)不能参与Cache的Query有TermQuery/MatchAllDocsQuery/MatchNoDocsQuery/BooleanQuery/DisjunnctionMaxQuery。
3)MultiTermQuery/MultiTermQueryConstantScoreWrapper/TermInSetQuery/Point*Query的Query查询超过2次会被Cache,其它Query要5次。
4)默认每个段大于10000个doc或每个段的doc数大于总doc数的30%时才允许参与cache。
5)结果集比较大的Query在Cache时尽量增加使用周期以免频繁Cache构建DocIdset。
6)Segment被合并或者删除,那么也会清理掉对应的缓存。
Shard Request Cache
Shard Request Cache简称Request Cache,他是分片级别的查询缓存,每个分片有自己的缓存,属于ES层面的实现。ES默认情况下最多使用堆内存的1%用作 Request Cache,这是一个节点级别的配置。内存的管理使用LRU算法。
Request Cache的主要作用是对聚合的缓存,聚合过程是实时计算,通常会消耗很多资源,缓存对聚合来说意义重大。
由于客户端请求信息直接序列化为二进制作为缓存key的一部分,所以客户端请求的json顺序,聚合名称等变化都会导致cache无法命中。
缓存时机: size=0的hits.total, aggregations, and suggestions
失效或回收:
- 新的segment写入到分片后,缓存会失效,因为之前的缓存结果已经无法代表整个分片的查询结果。
- now等时间函数不会缓存
缓存配置
Shard request cache settings | Elasticsearch Guide [8.12] | Elastic
index.requests.cache.enable: true/fase request cache开关
indices.requests.cache.size: 1% request cache占总堆百分比,默认1%Field Data Cache
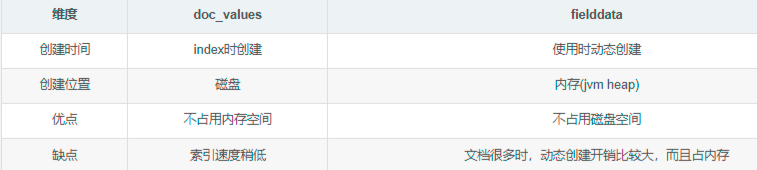
默认Elasticsearch2.0 开始,在非 text 字段开启 doc_values,基于 doc_values 做排序和聚合,可以减少对FielddataCache的依赖,减少内存消耗,减少节点 OOM 的概率,由于doc_values的特性性能上也不会有多少损失,doc_value是一种正向索引结构以顺序预读的方式进行获取,所以随机获取就很慢了。
Elasticsearch(后面简称ES)除了强大的搜索功能外,还可以支持排序,聚合之类的操作。搜索需要用到倒排索引,而排序和聚合则需要使用 “正排索引”。说白了就是一句话,倒排索引的优势在于查找包含某个项的文档,而反过来确定哪些项在单个文档里并不高效。
doc_values和fielddata就是用来给文档建立正排索引的。他俩一个很显著的区别是,前者的工作地盘主要在磁盘,而后者的工作地盘在内存。
5.0 开始,text 字段默认关闭了 Fielddata 功能, Fielddata Cache 应当只用于 global ordinals。
Fielddata Cache大家做了解吧,使用它的也非常的少了,基本可以用doc_value代替了,doc_value使用不需要全部载入内存
缓存配置
Field data cache settings | Elasticsearch Guide [8.12] | Elastic
indices.fielddata.cache.size 38%/12G 设置fielddata cache大小,默认没有限制
indices.breaker.fielddata.limit fielddata熔断器,默认值堆的40%失效或回收:segment 被合并后失效
Segment Cache(Segment FST Cache)
一个segment是一个完备的lucene倒排索引,倒排索引是通过词典 (Term Dictionary)到文档列表(Postings List)的映射关系实现快速查询的。由于词典和文档的数据量比较大,全部装载到heap里不现实,所以存储在硬盘上的。
为了快速定位一个词语在词典中的位置。Lucene为词典(Term Dictionary)做了一层词典索引(Term Index)。这个词典索引采用的数据结构是FST (Finite State Transducer)。Lucene在打开索引的时候将词典索引(Term Index)全量装载到内存中,即:Segment FST Cache,这部分数据永驻堆内内存,且无法设置大小,长期占用50% ~ 70%的堆内存。内存管理使用LRU算法。
FST(详细参考这里) 。可以参考TRIE树进行理解。FST在时间复杂度和空间复杂度上都做了最大程度的优化,使得Lucene能够将Term Dictionary(词典)完全加载到内存,快速的定位Term找到响应的output(posting倒排列表)。
内存回收与释放:
1.删除不用的索引
2.关闭索引(文件仍然存在于磁盘,只是释放掉内存),需要的时候可重新打开。
3.定期对不再更新的索引做force merge。实质是对segment file强制做合并,segment数量的减少可以节省大量的Segment Cache的内存占用。
Off Heap内存
Segments Memory
Lucene中的倒排索引以段文件(segment file)的形式存储在磁盘上,为了提高倒排索引的加载与检索速度,避免磁盘IO访问导致的性能损耗,Lucene会把倒排索引数据加载到磁盘缓存(操作系统一般会用系统内存来实现磁盘缓存),所以在进行内存分配的时候,需要考虑到这部分内存,一般建议是把50%的内存给Elasticsearch,剩下的50%留给Lucene。
熔断器
Circuit breaker settings | Elasticsearch Guide [8.12] | Elastic