Health-LLM:解决传统医学大模型,难以充分满足个体化需求
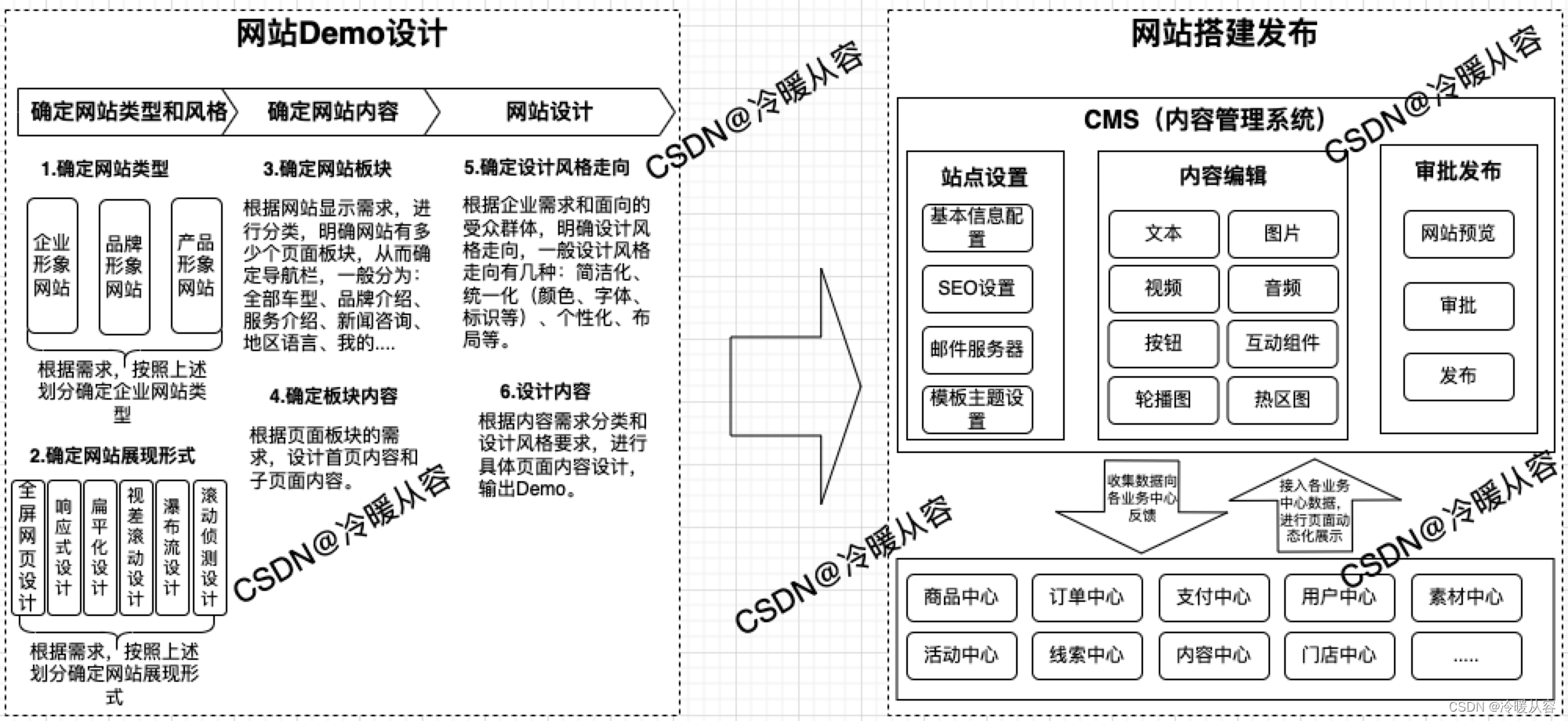
- 提出背景
- 个性化方案 = 大模型 + AutoML + 信息检索(IR)
- 工作流程
- 效果
论文:https://arxiv.org/pdf/2402.00746.pdf
代码:https://github.com/jmyissb/HealthLLM
提出背景
Health-LLM 为解决传统的健康管理方法因静态数据和统一标准的限制,难以充分满足个体化需求,尤其是在疾病预测和个性化健康管理方面。
为了解决这一问题,Health-LLM提出了一种综合框架,涉及以下具体子问题及相应解法:
- 子问题1:如何从病人健康报告中提取重要特征?
- 子解法1:大规模特征提取。
举个例子:
-
子问题1(特征提取): 如何从一位病人的健康报告中提取出能够预测未来健康风险的关键特征?
-
子解法1(大规模特征提取):
- 使用模型从健康报告中提取关键特征。例如,从病历中识别出高血压、血糖水平和运动频率等特征。
- 健康报告包含了丰富的数据,能够预测未来健康问题并提供个性化建议,但将这些数据转化为实际见解的难点在于如何有效提取和分析这些大量的信息。
- 子问题1:如何根据医学专业知识调整健康特征的权重?
- 子解法2:医学知识权重调整。
举个例子:
-
子问题2(特征权重调整): 如何确保所提取的健康特征被正确地权衡,以反映它们对疾病风险的真实影响?
-
子解法2(医学知识权重调整):
- 与医学专家合作,根据专业知识对特征进行权重分配。
- 例如,如果专家认为基于患者历史的血压波动对心脏病风险的预测更为重要,那么这个特征在模型中的权重会被调高。
- 子问题3:如何利用提取的特征和调整后的权重进行疾病预测?
- 子解法3:自动化机器学习(AutoML)特征工程与线性分类器训练。
举个例子:
-
子问题3(疾病预测): 如何使用这些调整后的特征来预测个体可能遭受的健康问题?
-
子解法3(AutoML特征工程与分类器训练):
- 通过自动化的特征工程方法进一步处理提取的特征,并训练一个线性分类模型来进行最终的疾病预测。
- 例如,AutoML系统可能会识别并选择最具预测价值的特征,然后用这些特征来训练一个XGBoost分类器,以预测心脏病的风险。
- 不仅能提高疾病预测的准确性,并为个体提供个性化的健康管理建议。
这三个子问题及其解法共同构成了 Health-LLM 项目的核心,旨在通过结合大规模特征提取、专业医学知识的权重调整以及高效的机器学习技术,提供一个创新的个性化疾病预测和健康管理框架。
个性化方案 = 大模型 + AutoML + 信息检索(IR)
- 子问题:提取大规模特征后,如何提高疾病预测和诊断的准确性?
- 子解法1:使用大型语言模型(LLMs)。
之所以采用 LLMs,是因为它们在处理和理解大量的临床数据方面表现出了前所未有的能力,如通过 CPLLM 和 COAD 框架改进疾病预测和自动诊断的准确性和效率。
使用 LLMs 来分析电子健康记录,例如,一个模型可能被训练来识别患者描述的症状与特定疾病模式之间的相似性。
通过分析病人的自述症状和临床症状,LLM 能够预测出患者可能患有的疾病,如 CPLLM 模型能够预测出与特定症状匹配的疾病,而 COAD 模型则能够在生成疾病标签时考虑症状顺序,以提高预测的准确性。
CPLLM 展示了基于临床数据微调的 LLMs 在预测未来疾病诊断方面超越传统模型的潜力,而 COAD 通过疾病和症状的协同生成框架解决了早期模型在症状序列匹配方面的挑战。
-
CPLLM (Clinical Prediction with Large Language Models):
- CPLLM 代表一种使用大型语言模型进行临床预测的方法或框架。
- 在这种情况下,大型语言模型(例如GPT-3或GPT-4)被微调以处理临床数据,以改善疾病诊断和预测的准确性。
- 这类模型通常通过分析医疗文本(如患者的健康记录、临床试验报告或医学文献)来提取症状、治疗效果和其他医疗相关信息。
-
COAD (Collaborative Generation Framework for Automatic Diagnosis):
- COAD 是一个用于自动诊断的协作生成框架。
- 这种框架可能利用了基于Transformer的模型(如BERT或其变体)来解决医学诊断中的一些挑战。
- 例如,解决症状顺序不匹配问题。
- COAD框架通过结合疾病和症状生成过程来减少症状顺序对疾病预测的影响,可能涉及到对症状和诊断标签进行句子级别的对齐,从而提高自动诊断过程的准确性和一致性。
- 子问题:如何优化数据科学工作流程中的模型选择、训练和评分?
- 子解法2:自动化机器学习(AutoML)。
AutoML的应用是为了优化模型的选择、训练和评分过程,减少数据科学家在数据工程和清理任务上的工作量。
如 CAAFE 框架会自动化生成特征,从病人的生化检验结果中提取出对疾病预测最重要的指标,并自动化编码成可用于机器学习的Python代码。
它结合了传统机器学习的稳健性和LLMs的领域知识能力,生成可解释的Python代码进行特征工程,从而提高了AutoML管道的效率和自动化程度。
- 子问题:如何从大量数据中检索到与用户查询相关的信息?
- 子解法3:信息检索(IR)技术。
在处理患者咨询时,系统需要从医学文献数据库中检索信息来回答,关于疾病症状或治疗选项的问题。
通过使用IR技术,系统可以快速找到与特定症状或治疗相关的,最新研究论文或临床指南,并将这些信息整合进患者的咨询回答中。
例如,如果一个患者询问有关心脏病的症状,系统可以在医学数据库中检索最相关的文章,并提取信息来回答患者的问题。
IR技术包括文本、图像和音频检索等方法,能够有效地解析用户查询并在数据集中找到匹配信息,是实现健康LLM中知识检索和特征提取的基础。
3 者共同支持了 Health-LLM 项目的目标,即通过结合 AI、AutoML 和 IR 技术提高疾病预测的准确性、优化健康管理工作流程,并有效地从健康数据中提取和利用信息。
工作流程
Health-LLM框架的开发过程,涉及特征生成、文档嵌入、外部知识检索、评分分配、疾病预测模型构建和健康分析。
- 子问题1:如何从疾病范围内系统性提取症状特征?
- 子解法1:利用上下文学习进行特征生成。
- 选择这种解法是因为先进的大规模语言模型通过上下文学习能力,可以根据示例学习症状特征的提取模式,从而高效地生成症状特征。
- 假设患者有一系列症状,如关节痛和晨僵。
- 系统通过上下文学习特征生成方法,分析患者的健康报告,并从中提取关键特征,如症状频率和强度。
Health-LLM 的上下文学习工作流程:
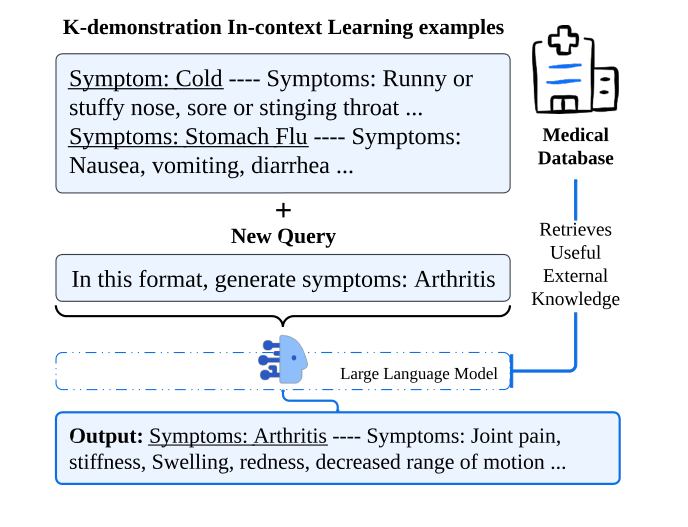
- 左上角显示了使用大型语言模型进行上下文学习的示例,其中提供了冷症和胃流感的症状列表作为示例(K-demonstration)。
- 在“新查询”中,模型被要求以相同的格式生成关于类风湿性关节炎的症状。
- 这个查询被输入到大型语言模型中,模型利用医疗数据库中检索到的有用外部知识,生成了关节炎的症状列表,这些症状包括关节痛、僵硬、肿胀、红热和活动范围减少。
特征生成过程中的 LLM 使用:
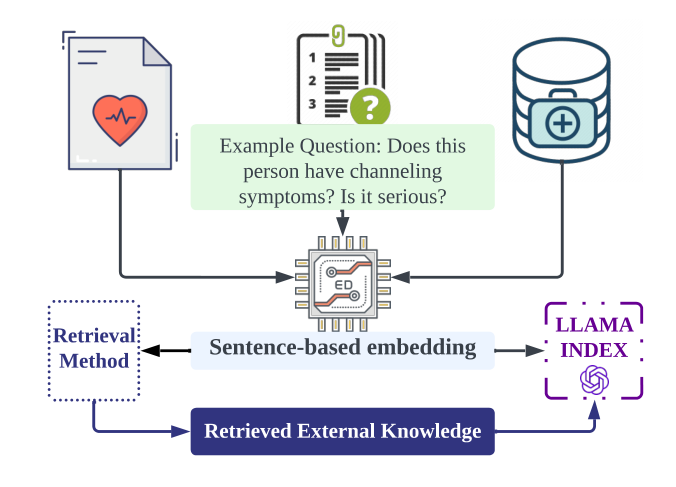
- 图中左侧有一个文件图标,代表病历或医疗记录。
- 中心的问题是一个示例,询问“这个人有通道症状吗?严重吗?”
- 该问题通过句子级嵌入被转化为向量形式,以便进行知识检索。
- 右上角是一个医疗数据库,用于检索外部知识。
- 句子嵌入的输出连接到LLAMA INDEX系统,这个系统可能用于评分或进一步处理特征。
- 最终,检索到的外部知识反馈到检索方法中,可能是为了改进或优化检索过程。
- 子问题2:如何从健康报告文档中提取相关信息?
- 子解法2:健康报告文档嵌入。
- 之所以使用文档嵌入技术,是因为通过计算问题和文档片段之间的相似性,可以精准地定位和利用文档中的相关部分,为模型生成答案提供基础。
- 需要从患者的详细医疗记录中提取相关信息。
- 使用文档嵌入技术,系统计算与患者提出的特定问题相关的医疗记录片段的相似性,从而定位最相关的信息。
Health-LLM 用于特征生成的过程:

- 医疗记录被分割成多个块(chunk_1, chunk_2, …, chunk_N)。
- 这些块经由OpenAI的嵌入系统转化为向量,存储在一个向量数据库中。
- 针对特定问题(例如:“这个人有通道症状吗?严重吗?”),该问题同样被转化为向量形式。
- 然后系统在向量数据库中检索相关性最高的块(chunk_k, chunk_h, chunk_p),并根据这些块处理新的请求。
- 这个过程可以用来评估相关的医疗记录片段,并将它们作为新请求的一部分来生成特征。
- 子问题3:如何处理复杂和知识密集型的问题?
- 子解法3:检索增强生成(RAG)用于外部知识。
- 选择 RAG 方法是因为它结合了检索和生成组件,通过利用大规模文档数据库增强模型的能力,提高处理复杂和知识依赖问题的效率。
- 需要了解患者的症状是否与风湿性关节炎相关。
- 采用RAG,系统检索和参考了大量的医学数据库,以增强对患者症状背后可能疾病的理解。
- 子问题4:如何整合不同来源的LLM模型并提取特征?
- 子解法4:通过Llama Index分配评分。
- 采用这种方法是为了利用高级自然语言处理模型的优势,通过特定问题的系统提问来生成特征,关键步骤是预测疾病和提供健康建议。
- 要整合从不同来源获取的患者的健康数据。
- 通过Llama Index,系统分配了评分给检索到的信息,帮助预测患者可能患有的疾病。
- 子问题5:如何开发一个健壮的疾病分类系统?
- 子解法5:预测模型。
- 之所以采用 AutoML 和 CAAFE,是因为它们通过利用 LLMs 生成具有语义相关性的特征,提高疾病预测的准确性,同时将系统从半自动化转向完全自动化,提高特征工程的效率。
- 需要对患者的症状进行分类,以预测可能的疾病。
- 利用 AutoML 和 CAAFE,系统自动化地处理和迭代特征,然后使用这些特征训练一个疾病分类模型。
- 子问题6:如何识别个人可能面临的潜在疾病并提供相应的预防和治疗方法?
- 子解法6:健康分析。
- 选择这种解法是因为通过利用大型外部医疗知识数据库,可以访问到由医疗专业人士整理的相关预防和治疗方法,从而为寻求咨询的个人提供信息,并通过持续对话来响应进一步的查询和关注。
- 患者希望得到针对他个人情况的预防和治疗建议。
- 系统通过健康分析步骤,利用外部医疗知识库提供了个性化的健康建议,包括生活方式改变和潜在治疗选项。
工作流程:特征生成 -> 文档嵌入 -> 外部知识检索 -> 特征整合 -> 疾病分类 -> 健康分析。
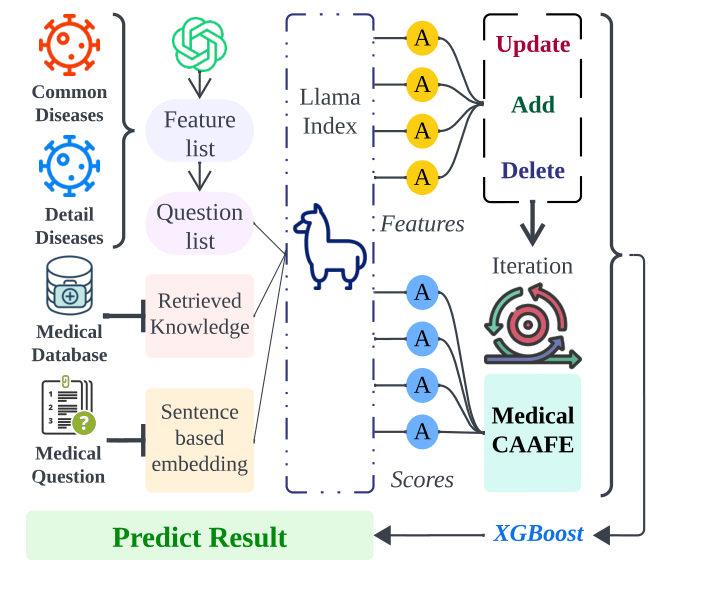
Health-LLM框架的工作流程,用于疾病预测和健康管理的系统:
-
特征和问题列表的生成:
- 从常见和详细疾病数据库中提取信息,生成一个特征列表。
- 使用这些特征来形成一个问题列表,这些问题将用于从医疗知识数据库中检索相关信息。
- 从患者的电子健康记录中,系统提取了常见的特征,如心率、血压、胆固醇水平等。
- 基于这些特征,系统形成了一个问题列表,例如,“患者的血压趋势如何?”或“她有无不寻常的心率变化?”
-
知识检索和句子嵌入:
- 针对提出的医疗问题,系统从医疗数据库中检索相关知识。
- 使用基于句子的嵌入技术来处理这些问题和检索到的知识。
- 对于每个问题,系统使用自然语言处理技术从医学数据库中检索相关的研究、临床指南和案例报告。
- 检索到的文档通过句子嵌入技术转换为向量形式,以便于比较和分析。
-
特征处理和评分:
- 使用Llama Index技术处理检索到的知识和问题,以生成特征。
- 对这些特征进行评分,这些评分可能会影响预测结果的置信度。
- 使用Llama Index,系统为患者的每个健康特征分配了评分,这些评分基于医学文献的相关性和可靠性。
- 例如,如果患者的心率变化与某个研究中描述的心律不齐症状非常匹配,这个特征的评分会较高。
-
AutoML特征工程 - Medical CAAFE:
- 利用AutoML框架,特别是Medical CAAFE,进行特征工程的迭代更新,包括添加、更新或删除特征。
- 这些评分特征被输入到AutoML系统,通过Medical CAAFE进行特征工程的迭代优化。
- 系统可能会发现患者的体重和活动量的某种组合是预测 2 型糖尿病的一个关键特征,并据此调整特征集。
- 然后,系统使用XGBoost算法来训练一个模型,该模型使用经过优化的特征集来预测患者可能存在的健康风险。
在这个阶段,系统可能发现患者有发展心脏疾病的高风险。
-
XGBoost模型:
- 使用XGBoost算法,这是一个高性能的机器学习模型,对特征进行训练,以预测疾病结果。
- 最终,XGBoost模型输出了患者的健康风险预测结果,指出她有高血压和心脏疾病的风险。
- 基于这些结果,Health-LLM可能会建议患者增加体育活动,改进饮食习惯,并进行定期的心血管系统检查。
-
预测结果:
- 经过训练的XGBoost模型最终输出预测结果,这可能是关于个体可能患有的疾病的预测。
工作流程通过整合医疗知识库、问题嵌入、特征评分、AutoML特征工程和机器学习模型,来提高疾病预测的准确性,并为用户提供个性化的健康管理建议。
效果
测试 Health-LLM 模型的有效性。
- 子问题1:如何验证 Health-LLM 在疾病诊断上的有效性?
- 子解法1:对比实验。
- 之所以采用对比实验,是因为通过将 Health-LLM 与开源模型 GPT-3.5 和 GPT-4 在零次学习(没有举例)和少次学习(有举例)的设置下进行比较,可以直观地展示 Health-LLM 在处理特定医疗咨询数据集上的优越性。
- 通过进一步集成医疗知识,提炼预测,并对LLaMA-2进行微调,展现了Health-LLM在性能上的显著提升。
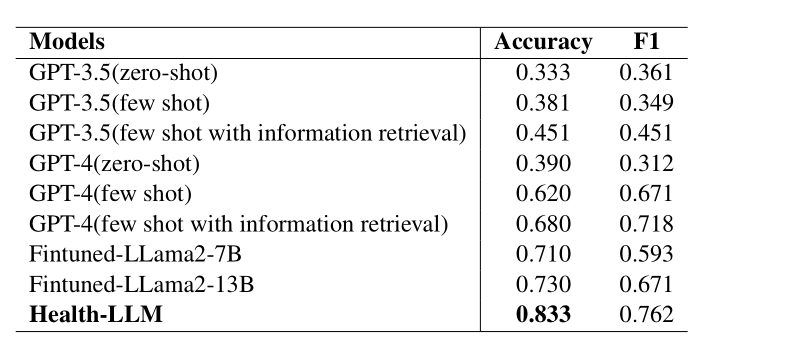
每个模型,都有在一项数据集上的准确性(Accuracy)和F1分数(F1)。
Health-LLM 在这些度量上表现最佳,准确性达到0.833,F1分数为0.762,代表 Health-LLM 在诊断测试上超越了其他模型。
- 子问题2:外部医学知识检索的重要性是什么?
- 子解法2:外部医学知识检索的消融研究。
- 采用这种方法是因为,通过比较完整的 Health-LLM 模型与移除了专业医疗知识检索部分的模型,可以证明专业医疗知识检索对于确保诊断推理准确性的重要性。
- 实验结果显示,索引到的专业医疗知识显著提高了诊断推理的准确度。

- 对比了没有信息检索功能的 Health-LLMs 和完整的 Health-LLMs 模型。
- 准确性(ACC)从没有信息检索的 0.78 提高到了使用信息检索的 0.83,证明了信息检索对提高 Health-LLM 诊断准确性的重要性。
- 子问题3:AutoML在特征预处理中的作用是什么?
- 子解法3:AutoML特征预处理的消融研究。
- 选择这种解法是为了验证 AutoML 在数据集预处理和特征提取中的效果。
- 通过对比原始特征与经 AutoML 预处理后的特征在模型推理中的表现,结果表明AutoML的预处理对于提高整个Health-LLM模型的推理性能具有积极影响,尽管这一部分仍需进一步迭代以达到更好的性能提升效果。