🚩🚩🚩Transformer实战-系列教程总目录
有任何问题欢迎在下面留言
Transformer实战-系列教程1:Transformer算法解读1
Transformer实战-系列教程2:Transformer算法解读2
现在最火的AI内容,chatGPT、视觉大模型、研究课题、项目应用现在都是Transformer大趋势了
名称解释:
- Transformer:一个基于Encoder-Deocder使用纯注意力机制的基础网络
- embbeding:词嵌入,将一个单词(或者汉字)转化为一组向量
- Positional Encoding:位置编码
- Multi-Head Attention:多头注意力机制
- Add:残差连接
- Norm:Normalization,主要分为Batch Normalization和Layer Normalization,一个是对批做归一化,一个是对层做归一化
- Feed Forward:全连接神经网络,加上激活函数以及Dropout
- Encoder-Deocder:编码器-解码器,编码器将原始输入转化为特征,解码器将特征转化为输出
1、传统的RNN
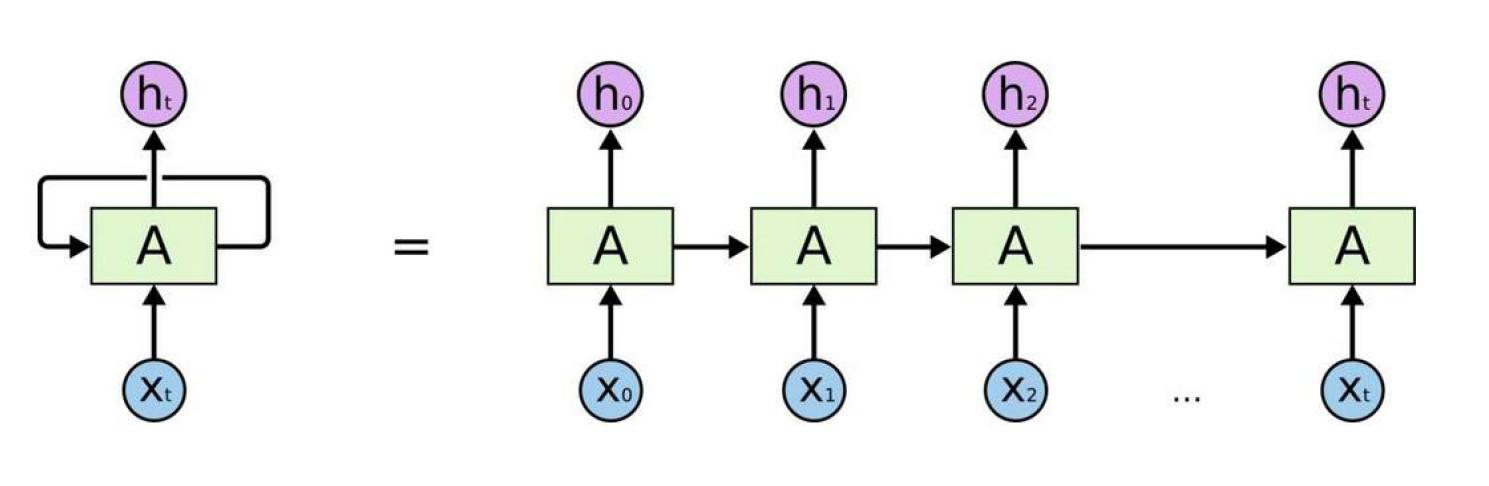
Transformer是基于RNN改进提出的,RNN不同于CNN、MLP是一个需要逐个计算的结构来进行分类回归的任务,它的每一个循环单元不仅仅要接受当前的输入还要接受上一个循环单元的输出,因此它被提出是为了提取带有先后关系、时序信息的特征的。
因此在很长的一段时间,RNN以及RNN的变体LSTM、GRU都被经常用来时间序列分析、文本分析的任务。
如图所示 x 0 x_0 x0经过一个循环单元的计算,得到了 h 0 h_0 h0,而 h 1 h_1 h1是 h 0 h_0 h0和 x 1 x_1 x1经过一个循环单元的计算得到的结果,当然 h 0 h_0 h0的计算不仅有 x 0 x_0 x0还有一个初始化的h。因此这种计算方式使得 h 1 h_1 h1包含了 x 0 x_0 x0、 x 1 x_1 x1的特征, h 2 h_2 h2包含了 x 0 x_0 x0、 x 1 x_1 x1、 x 2 x_2 x2的特征, h t h_t ht包含了前面所有的特征
2、RNN的局限性
RNN的每一个循环单元的计算,都需要前面的所有循环单元计算结束后才可以进行,比如 h 1 h_1 h1的计算需要等 h 0 h_0 h0计算完成后才可以进行,后面同理。当输入序列比较长的时候,对于前面的信息容易遗忘,比如 h t h_t ht可能已经对 h 0 h_0 h0和 h 1 h_1 h1的信息已经包含的较少了(当序列比较长的时候)。还有RNN没有对每一个输入的重要性进行筛选,可能我们最后需要的结果在0到t个输入中,有些比较重要,有些重要性比较低,而有些则根本不重要。
因此可以总结出RNN的三大缺陷:
- 不能并行计算,只能串行计算,效率低
- 容易遗忘早期信息
- 不能计算各个输入信息的重要性
3、Attention与self-Attention
注意力机制就是用来计算各个输入信息的重要性的一种方法,出现过大量的CNN、RNN结合注意力机制去做CV、NLP任务,2017年一篇论文《Attention is all you need》把注意力机制带到了高潮,因为它是一种纯注意力机制的架构,这个架构被命名为Transformer,后面的故事大家都已经很熟悉了。

所谓的Attention就是让机器学习注意点那些更有价值的信息
比如这两句句话:
The animal didn’t cross the street because it was too tired.
The animal didn’t cross the street because it was too narrow.
如果是这来那个句话对比,很显然,每个词对一句话表达的含义的重要性很显然不同,而且每一个词与每一个词之间的相关性也显然不同,比如第一句话animal和tired的相关性大,第二句话street 和narrow相关性大,因为它们修饰的词都不一样,很显然tired是修饰animal的,narrow是修饰street的。
每个词之间的相关性各不相同,使用Attention将这种相关性计算出来,就被称为Attention机制
每个词之间都存在相关性,那一个词自己与自己之间也是有相关性的,而且这个相关性最大的,考虑了自己与自己之间的关系的Attention被称为self-Attention,自注意力机制。
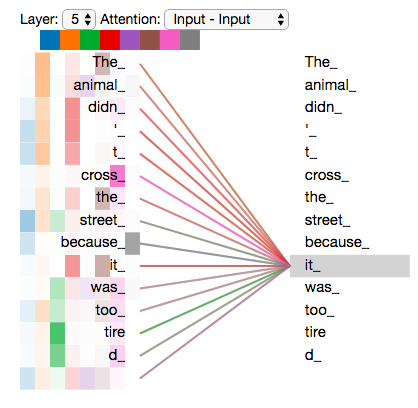
- 假设这个句话有N个词
- 第一个词都与所有的词计算相关性,可以得到N个相关系数
- N个相关系数经过softmax可以得到N个权重
- N个权重再与所有的词的特征进行重构,得到N个特征
- 用这N个特征代替原本第一个词的特征
- 第二个词也用同样的方式进行计算
- 将原本所有的特征都进行重构
这个权重是怎么计算的呢?肯定是通过学习得到的
4、self-Attention如何计算
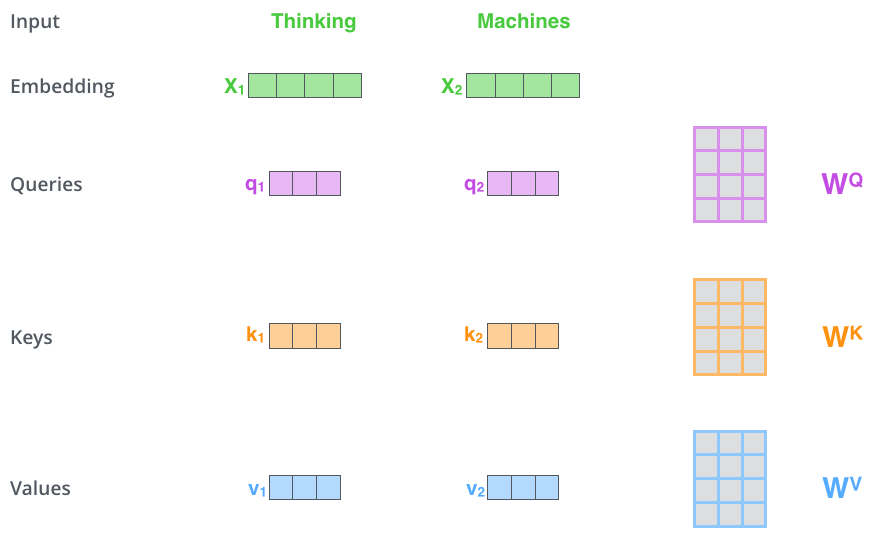
如图所示,计算Thinking与Machines之间的相关性
- Thinking和Machines各自embbeding成一个向量(可以是预训练的词嵌入), x 1 x_1 x1和 x 2 x_2 x2
- x 1 x_1 x1经过 W Q W^Q WQ 、 W K W^K WK 、 W V W^V WV 3组可学习参数,生成3个特征 q 1 q_1 q1 、 k 1 k_1 k1 、 v 1 v_1 v1
- 同理, X 2 X_2 X2生成 q 2 q_2 q2 、 k 2 k_2 k2 、 v 2 v_2 v2
- q 1 q_1 q1和 q 2 q_2 q2和拼接得到Q,K、V同理,这就是Q(Query)K(Key)V(Value)的来源
- q 1 q_1 q1和 k 1 k_1 k1内积得到一个值 s 1 s_1 s1, q 1 q_1 q1和 k 2 k_2 k2内积也得到一个值 s 2 s_2 s2,这个s表示的是Score分数的意思
- s 1 s_1 s1和 s 2 s_2 s2都要除以一个数 d k \sqrt{d_k} dk再经过softmax,得到两个 w 1 w_1 w1和 w 2 w_2 w2,这两个权重分别乘以 v 1 v_1 v1、 v 2 v_2 v2后再相加,得到 z 1 z_1 z1
- 同理 q 2 q_2 q2和 k 1 k_1 k1、 k 2 k_2 k2也经过这样的计算得到 z 2 z_2 z2, X 1 X_1 X1和 X 2 X_2 X2就这样重构成了 z 1 z_1 z1和 z 2 z_2 z2
这就是两个特征之间进行一次self-Attention计算的结果,实际任务中不可能只有两个特征相互计算,可能是10个100个等,那么同样也是这样的计算方式,比如 q 1 q_1 q1就要和 k 1 k_1 k1、 k 2 k_2 k2、…、 k 100 k_{100} k100计算内积得到100个分数,再除以对应的 d k \sqrt{d_k} dk后经过softmax得到100个权重,100个权重再分别和 v 1 v_1 v1、 v 2 v_2 v2、…、 v 100 v_{100} v100相乘后再相加就得到了 z 1 z_1 z1
其中 d k d_k dk表示的是 q 1 q_1 q1、 k 1 k_1 k1这些向量的长度,所有的q、k、v的维度(一般用768比较多)都是一样的
为什么要除以 d k \sqrt{d_k} dk呢,因为不能让分值随着向量维度的增大而增加
因为 z 1 z_1 z1、 z 2 z_2 z2、…、 z n z_{n} zn的计算都是可以同时进行的,所以这种并行的计算方式相比RNN,极大的提高了运行速度,此外也不会产生遗忘早期信息的问题,而经过多次计算损失的训练, W Q W^Q WQ 、 W K W^K WK 、 W V W^V WV 与经过softmax计算的权重都会使得所有的z能够更好的关注在原始输入中( x 1 x_1 x1、 x 2 x_2 x2、…、 x n x_{n} xn)与自己相关性比较大的的输入。这完美的解决了RNN存在的3个问题
Transformer实战-系列教程1:Transformer算法解读1
Transformer实战-系列教程2:Transformer算法解读2