网址:https://movie.douban.com/
import requests
from lxml import etree
import re
url = 'https://movie.douban.com'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Safari/537.36'
}
session = requests.session()
response = session.get(url,headers = headers)
# response.encoding='utf-8'
# response.encoding = response.apparent_encoding
index_url = 'https://movie.douban.com'
res = session.get(index_url,headers=headers)
# print(res.text)
# 输出:页面源代码
tree = etree.HTML(res.text)
# print(tree)
# 输出:<Element html at 0x186fa6a3100>
img_all = tree.xpath('//img')
# print(img_all)
for i in img_all:img = etree.tostring(i, encoding='UTF-8').decode('UTF-8')# 得到所有的img标签# print(img)# <img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2900931370.jpg" alt="小行星猎人" rel="nofollow" class=""/>img_url = tree.xpath('//img/@src')# img_name = tree.xpath('//img/@alt')# print(img_url,img_name)# 输出:许多个列表for i in img_url:# print(i)last_str = i.split('/')[-1]# print(last_str)# 输出:多个p2900931370.jpg p2901057189.jpgevery_name = last_str.split('.')[0]# print(every_name)# 输出:多个p2900931370 p2901057189res_url = session.get(i,headers=headers)with open(f'./img/{every_name}.jpg','wb') as f:f.write(res_url.content)运行结果:
下面方法是以电影名称命名图片的方法:
import requests
from lxml import etreeurl = 'https://movie.douban.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Safari/537.36'
}
session = requests.session()
response = session.get(url, headers=headers)
# response.encoding='utf-8'
# response.encoding = response.apparent_encoding
index_url = 'https://movie.douban.com'
res = session.get(index_url, headers=headers)
# print(res.text)
# 输出:页面源代码
tree = etree.HTML(res.text)
# print(tree)
# 输出:<Element html at 0x186fa6a3100>
img_all = tree.xpath('//img')
# print(img_all)
for i in img_all:img = etree.tostring(i, encoding='UTF-8').decode('UTF-8')# 得到所有的img标签# print(img)# <img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2900931370.jpg" alt="小行星猎人" rel="nofollow" class=""/># 图片url地址列表img_url = tree.xpath('//img/@src')# 名称列表img_name = tree.xpath('//img/@alt')# print(img_url,img_name)# 输出:许多个列表# 两个列表一一对应列出for i in range(len(img_url)):m = img_url[i]n = img_name[i] if i < len(img_name) else None # 如果i小于列表名称长度,则输出NONE# print(m,n)# 输出:https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2900931370.jpg 小行星猎人# https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2901057189.jpg 年会不能停! 等every_img_url = session.get(m,headers=headers)with open(f'./img/{n}.jpg','wb') as f:f.write(every_img_url.content)print(f'开始下载{n}!')
print('全部下载完成!')输出:
开始下载小行星猎人!
开始下载年会不能停!!
开始下载养蜂人!
开始下载花千骨!
开始下载临时劫案!
开始下载狗神!
开始下载金手指!
开始下载泰勒·斯威夫特:时代巡回演唱会!
开始下载三大队!
.....
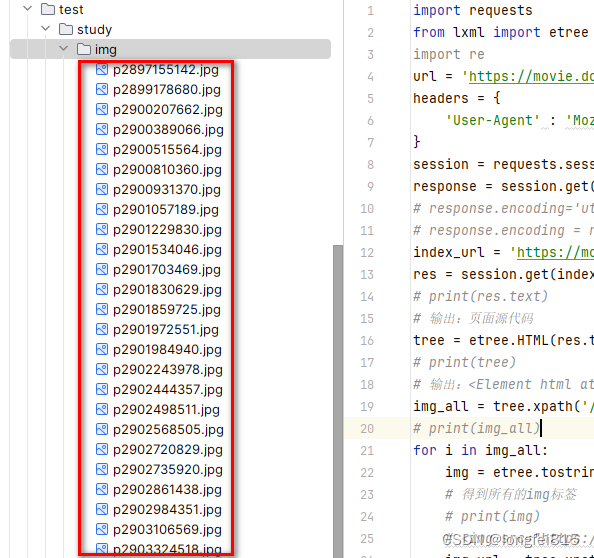
下载的图片:




![【数据结构]排序算法之插入排序、希尔排序和选择排序](https://img-blog.csdnimg.cn/direct/f6a1c78415ac48e2bec8e8a2e3f7356f.png)