ddddocr验证码识别模块
简介
ddddocr是一个基于深度学习的OCR(Optical Character Recognition,光学字符识别)工具,主要用于中文场景文字识别。能够对图片中的文字进行识别并提取出来。
ddddocr模块主要特点包括:
- 适用于中文场景:
ddddocr主要针对中文进行优化,对于中文的识别准确率较高。 - 基于深度学习:
ddddocr使用深度学习模型进行文字识别,能够有效处理复杂的场景。 - 简单易用:
ddddocr提供了简洁的API,用户可以通过几行代码就能完成文字识别。 - 支持本地运行:不同于一些需要调用API服务的OCR工具,
ddddocr可以在本地运行,无需联网。
安装
pip install ddddocr
使用案例
测试网站:
登录-软文街—一站式智能广告营销平台 (ruanwen.la)
抓包
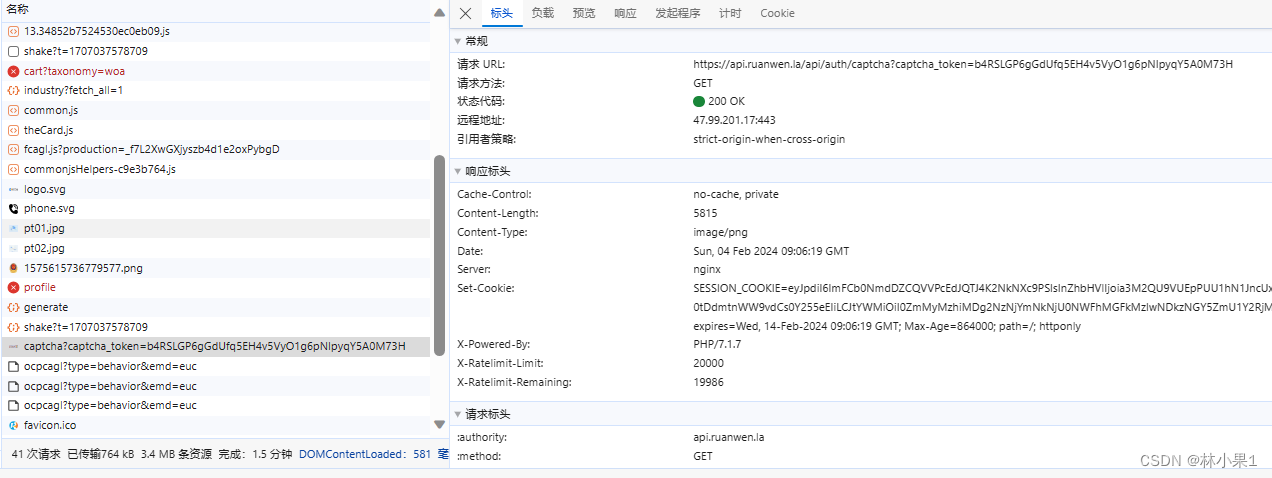
可以看到,验证码图片url带有token信息,要先获取token
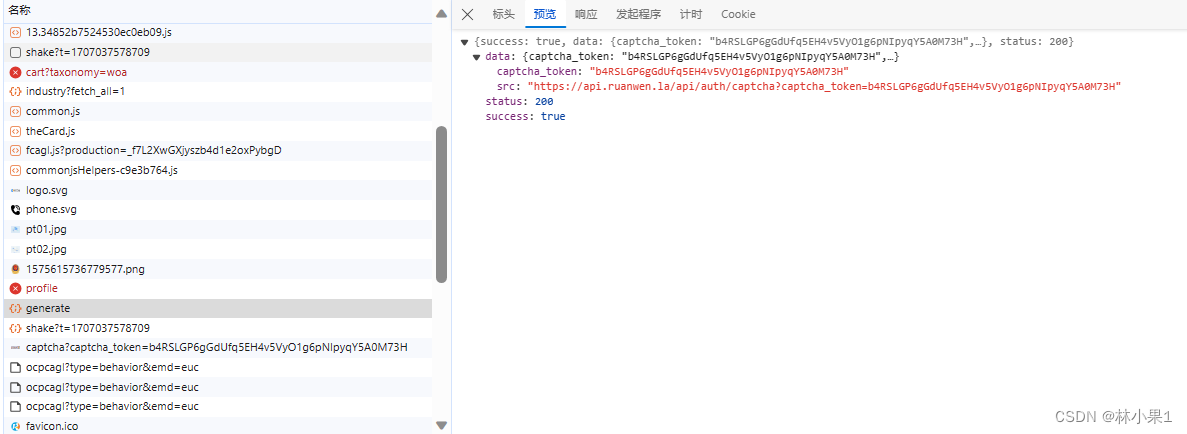
往上翻在generate包中找到token信息,因此要先请求generate的地址;
代码编写
import requests
import ddddocr
res1 = requests.post(url="https://api.ruanwen.la/api/auth/captcha/generate"
) # 获取token
dic_url = res1.json()['data']['src'] # 解析出图片urlres2 = requests = requests.get(url = dic_url
)
orc = ddddocr.DdddOcr(show_ad=False) # 不设置show_ad的话会有广告
code = orc.classification(res2.content)
print(code)