策略模式是一种行为型设计模式,它允许定义一系列算法,并将每个算法封装起来,使它们可以互换使用。策略模式让算法的变化独立于使用算法的客户端,使得在不修改原有代码的情况下切换或扩展新的算法成为可能。
使用策略模式的场景包括但不限于:
当存在多种实现方式,且需要在运行时根据不同条件动态选择具体实现时。例如,一个购物应用可能需要根据用户的会员等级来计算折扣,不同等级对应不同的计算方式,这时就可以使用策略模式来实现。
当存在一组类似的行为,实现细节略有不同,但又不希望通过继承来添加新的子类时。这样可以避免类的爆炸性增长,保持类的单一职责原则。
代码示例
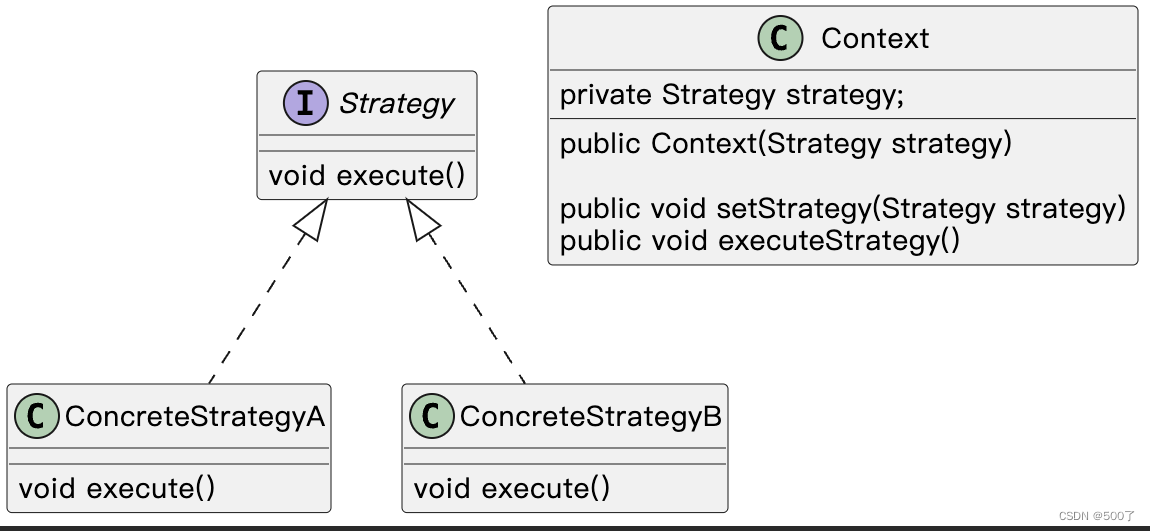
在Java中实现策略模式时,通常会涉及以下几个角色的类和接口,它们之间的关系构成了策略模式的核心:
- 上下文(Context):
维护对策略对象的引用。可定义一个接口来让策略对象访问上下文中的其他数据。 - 策略Strategy):
定义所有支持的算法或行为的策略接口。该接口通常包含一个方法,该方法用于执行策略。 - 具体策略(Concrete Strategy):实现策略接口的具体类。每个具体策略类实现算法或行为的一个变体。
- 客户端(Client):
使用上下文和策略接口的类。不直接调用策略方法,而是通过上下文进行。
如下图所示:
以下是示例的java实现:
// 定义策略接口
interface Strategy {void execute();
}// 实现策略接口的具体策略类A
class ConcreteStrategyA implements Strategy {public void execute() {System.out.println("执行策略A");}
}// 实现策略接口的具体策略类B
class ConcreteStrategyB implements Strategy {public void execute() {System.out.println("执行策略B");}
}// 上下文类,用于维护策略对象
class Context {private Strategy strategy;public Context(Strategy strategy) {this.strategy = strategy;}public void setStrategy(Strategy strategy) {this.strategy = strategy;}public void executeStrategy() {strategy.execute();}
}// 客户端代码
public class Client {public static void main(String[] args) {// 创建具体策略对象A和BStrategy strategyA = new ConcreteStrategyA();Strategy strategyB = new ConcreteStrategyB();// 创建上下文对象,并设置具体策略对象Context context = new Context(strategyA);// 执行策略context.executeStrategy();// 切换策略context.setStrategy(strategyB);// 再次执行策略context.executeStrategy();}
}JDK源码中策略模式的应用
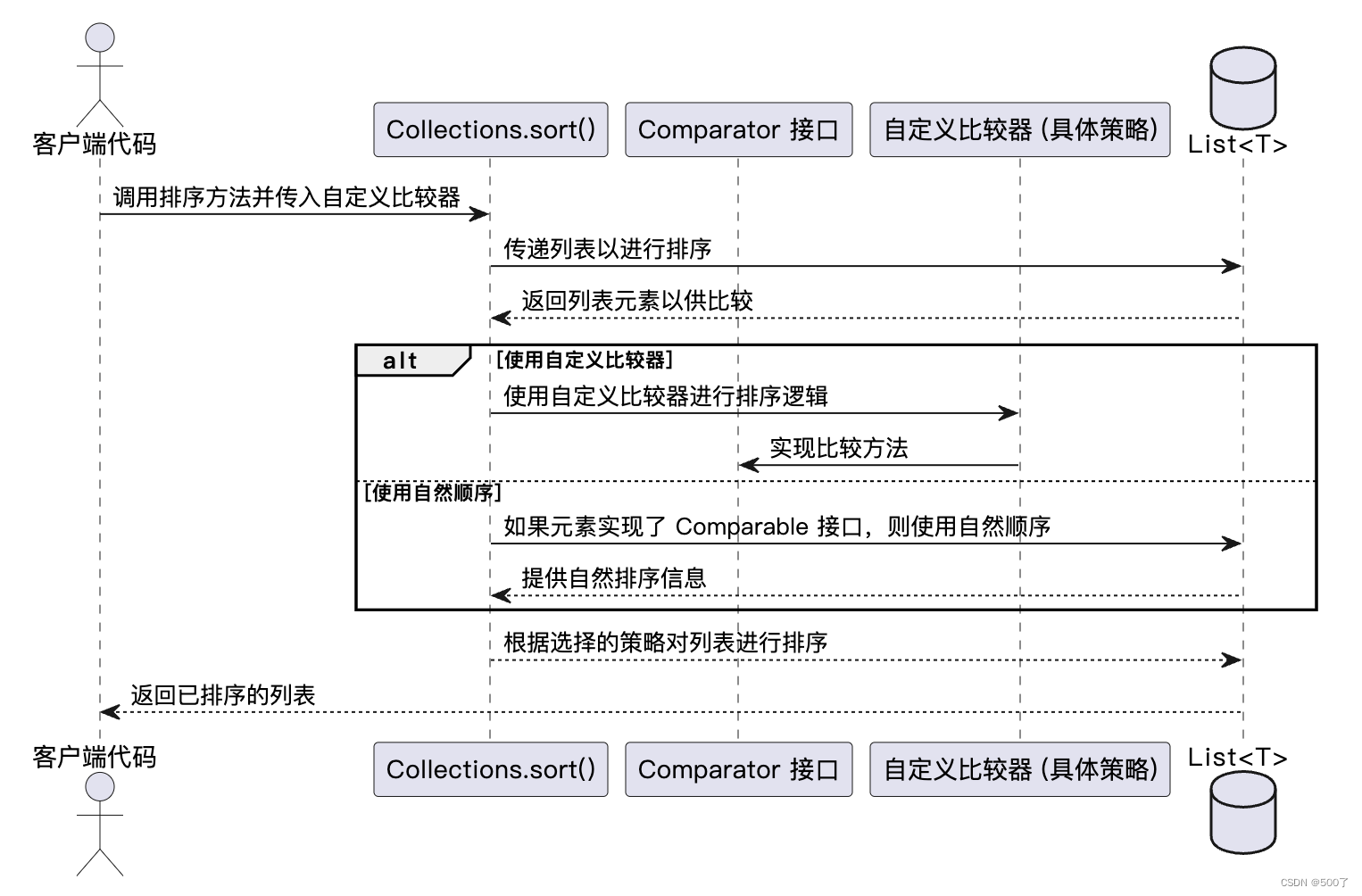
Collections.sort() 方法在 JDK中是策略模式的一个经典应用。这个方法根据传入的列表(List)以及可选的比较器(Comparator),对列表进行排序。
使用流程:
- 客户端代码调用Collections.sort()方法,并传入自定义比较器。
- Collections.sort()方法接收列表作为参数。
- 列表返回其元素给Collections.sort()方法以进行比较。
- Collections.sort()方法使用自定义比较器(如果提供)或元素的自然顺序(如果元素实现了Comparable接口)来确定排序逻辑。
- 根据选择的策略,Collections.sort()方法对列表进行排序。
如图所示:
以下是 Collections.sort() 方法的策略模式分析:
-
策略接口:这里的策略接口是 Comparator,它定义了排序策略的公共行为,即 compare(Object o1, Object o2) 方法。Comparator 可以有多个实现,每个实现提供不同的排序规则。
-
具体策略:Comparator 的实现类代表具体策略。例如,Collections.reverseOrder() 返回一个反向排序的比较器,而 Collections.naturalOrder() 返回自然顺序的比较器。用户也可以自定义 Comparator 来表达特定的排序需求。
-
上下文(Context):Collections.sort() 方法本身充当上下文角色。它接受一个列表和一个可选的比较器对象。如果提供了比较器,Collections.sort() 会使用该比较器来对列表元素进行排序;如果没有提供,它会使用元素类型的自然顺序(如果元素类型实现了 Comparable 接口)。
-
策略的使用:在 Collections.sort() 内部,默认情况下,如果列表元素实现了 Comparable 接口,并且没有提供比较器,那么排序算法将使用 Comparable 接口提供的 compareTo() 方法作为排序策略。如果提供了 Comparator,则使用该比较器的 compare() 方法。
-
策略的切换:由于 Collections.sort() 能够接受不同的 Comparator 实现,因此可以在运行时动态地改变排序策略,无需修改排序代码本身。
-
算法的独立性:Collections.sort() 方法内部使用了归并排序或者TimSort(Java 7 引入),这个算法独立于策略。策略模式使得算法可以独立于具体的策略实现,增加了代码的灵活性和可扩展性。
优点
- 封装性:策略模式通过将算法封装在独立的策略类中,实现了算法与使用算法的客户端之间的解耦,提高了代码的模块性。
- 可扩展性:新的策略可以很容易地被添加进系统,符合开闭原则,即对扩展开放,对修改封闭。
- 动态替换:可以在运行时根据不同情况选择不同的算法策略,增加了系统的灵活性。
- 避免使用多重条件转移:策略模式提供了用组合来替代继承和庞大的条件语句的新思路,有利于代码的维护和理解。
缺点
- 系统复杂度:由于策略模式需要定义一系列的策略类,这会增加系统的复杂度。
- 数量增多引发的复杂性:随着策略数量的增加,客户端需要进行更多的策略选择和管理,这可能会引入额外的复杂性。
- 可能违反单一职责原则:如果策略类承担了过多的职责,或者某些策略实现过于复杂,可能会违背单一职责原则。
总的来说,策略模式有助于避免使用多重条件语句,随着策略类数量的增长,管理这些策略可能会变得复杂,且在某些情况下可能违反设计原则。因此,在应用策略模式时,应该权衡其带来的灵活性和解耦优势以及可能引入的复杂性和设计问题。