1. 递归
①什么是递归?
官方一点来说
递归指的是一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法。
通俗一点来说,递归就是一个函数自己调用自己的过程
②什么情况下会用到递归?
我们在遇见一个问题的时候,我怎么知道这里可能会用到递归呢?这就需要我们了解递归的本质,即:在解决一个主问题时如果会衍生出一个相同的子问题,那么这里大概率就可以使用递归来解决。在这里举几个例子
1. 归并排序算法
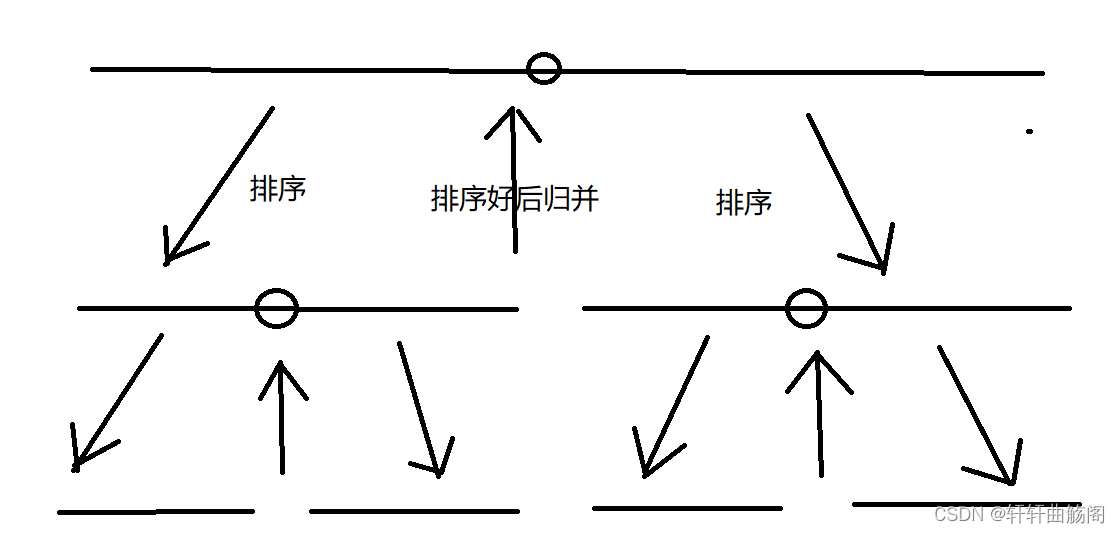
归并排序大致流程如图所示,我们想要对一个数组进行排序,就将它分为两半,对左边的数据排序好后,再对右边数据排序,左右数据排好后再将他们进行归并,为了解决排序的问题,我们将这个数组分为两半之后,我们又需要再分别对左右半边再次进行上述的操作
2. 快速排序算法
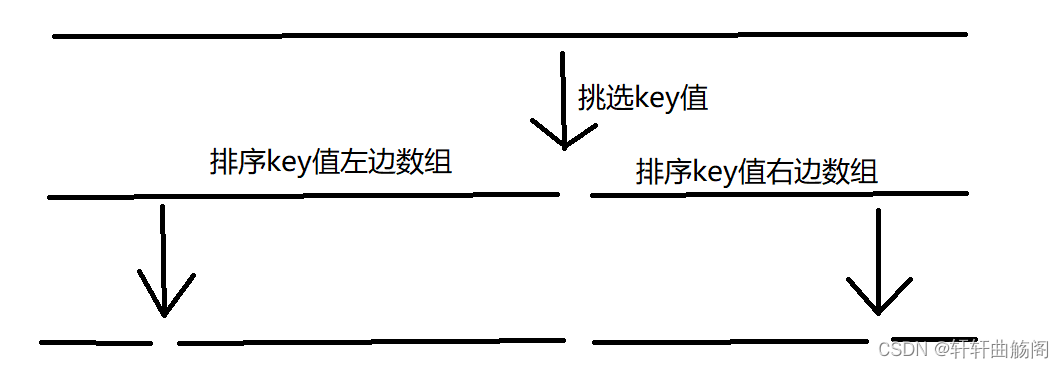
快速排序大致流程如图所示,我们想要对一个数组进行排序,就先挑选一个基准值key,将其移动到正确位置之后,对key左边的数组进行排序,再对key右边的数组排序,为了解决排序问题,我们将两边的数组排序之后,我们需要再次分别对左右部分挑选基准值并排序,即重复之前的过程
3. 二叉树的遍历
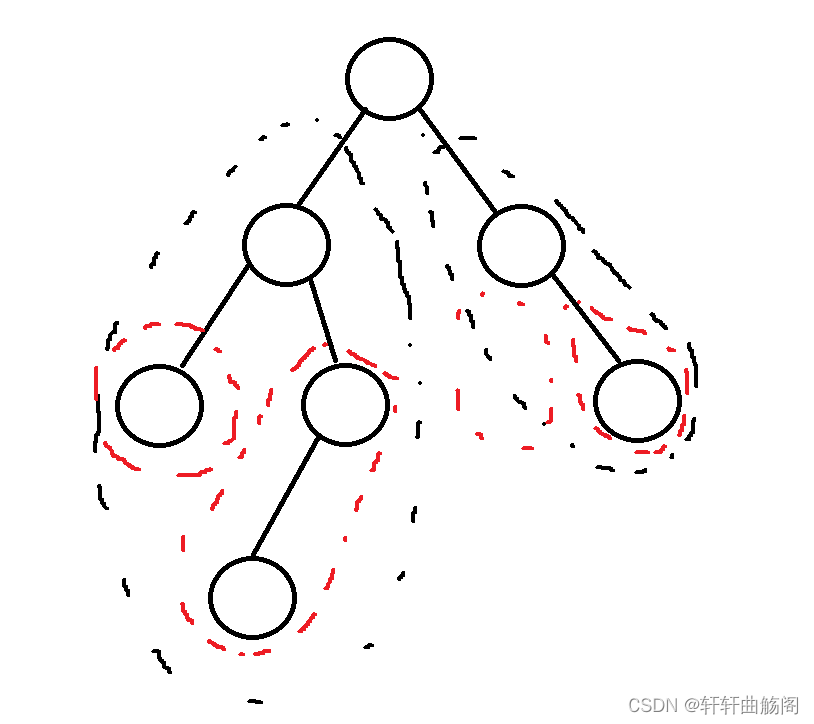
以上面这棵树为例,我们要对其进行后序遍历时,先要遍历左子树(左边黑色部分),然后遍历右子树(右边黑色部分),再访问自己,那么对于根节点的左子树来说,我们先遍历其左子树(左边红色部分),然后遍历其右子树(右边红色部分),本质上也是一种重复的过程
③如何理解递归?
在举例了上面几个例子之后,我们对递归应该有什么样的认识呢?我认为应该至少要有三点
1. 不要过于陷入递归展开图
2. 我们要将进行递归的函数视作一个黑盒
3. 在书写递归函数的过程中,我们要认为黑盒一定可以做到我们想做的事
在这里我们书写几个伪代码来实现上述部分例子
1. 归并
void merge(int nums[], int left, int right)
{// 出口if (left >= right) return;// 相信我们能够排序成功int mid = (left + right) / 2;merge(nums, left, mid);merge(nums, mid+1, right);// 排序好之后归并//...
}2. 遍历
void dfs(Node* root)
{// 出口if (root == NULL) return;// 相信我们能够遍历成功dfs(root->left);dfs(root->right);// 遍历细节printf("%d ", root->val);
}④如何写好一个递归?
在看了上面两个伪代码之后,我们可以知道要想写好一个递归,关键在于两点:
1. 要找到一个相同的子问题,即要设计好一个函数头
2. 具体解决好一个子问题即可,即书写递归函数主体
此外,为了避免函数进入死循环,需要给函数设计一个出口
2. 搜索
①深度优先遍历与深度优先搜索
在这里我们用一棵树来举例
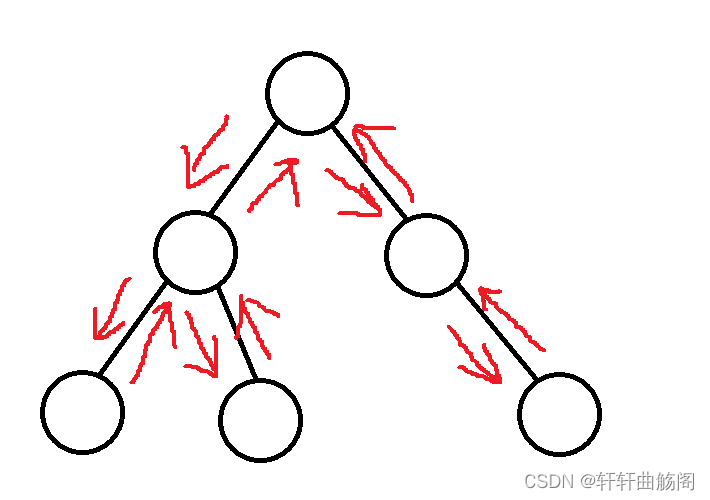
dfs即Depth-First Search,深度优先搜索,字面意思就是不断往深处搜索,搜索到头时返回上一个分支,然后继续往深处搜索,深度优先遍历与深度优先搜索,遍历是形式,搜索是目的
②广度优先遍历与广度优先搜索

bfs即Breadth-First Search,广度优先搜索,字面意思就是每次都遍历一层,然后不断地向外搜索
③拓展搜索问题
在这里我们以全排列问题为例,即
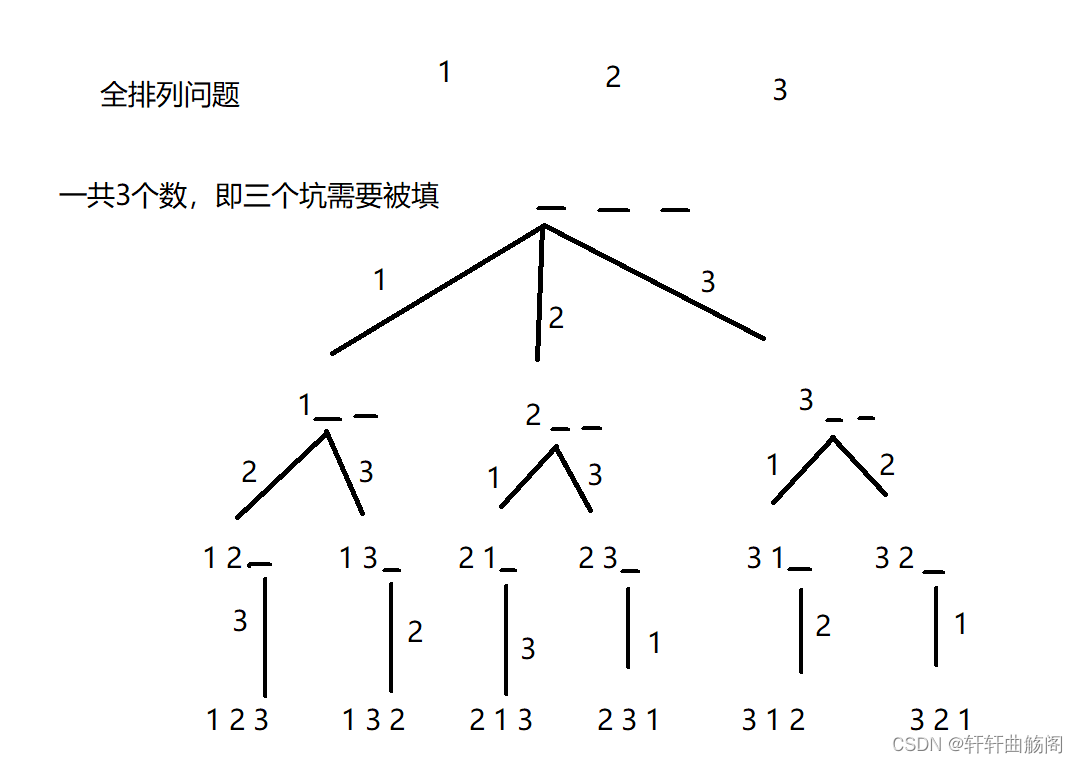
对于1,2,3三个数字来说,要找到它们的全排列,可以采取如上图所示的方式来做到,这之后我们只需要使用dfs或bfs就可以得到最后的全部结果,上面这种方式类似于树,我们也将其称为决策树
3. 回溯与剪枝
对于回溯我们可以将其视为与dfs相似,举个例子
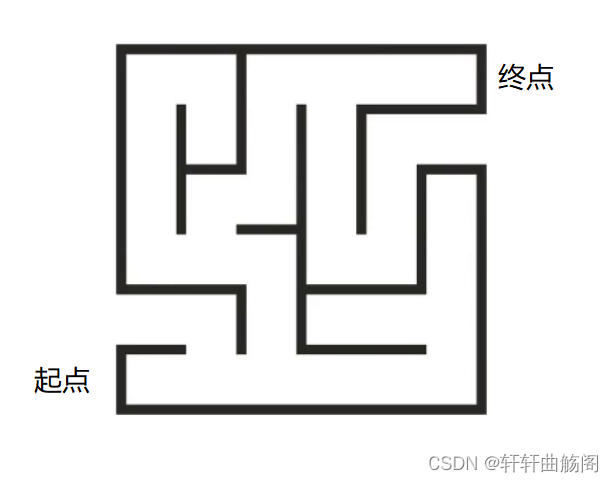
对于上面这个迷宫,我们从起点出发到第一个分叉点时,即
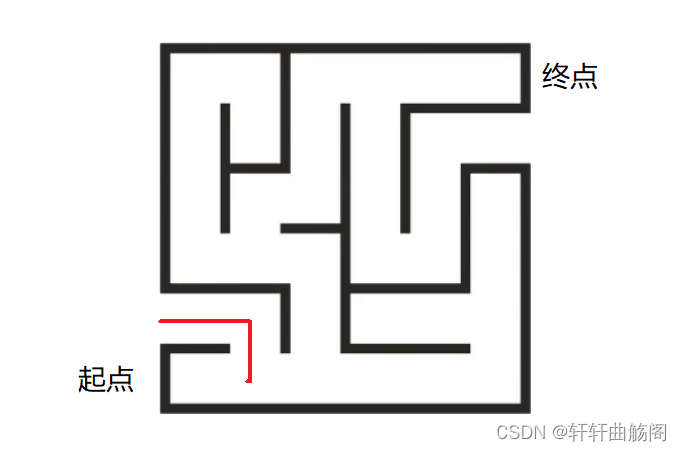
我们向左试探,发现这条路不能到达终点,因此需要我们进行回溯,即回到上一个分叉点
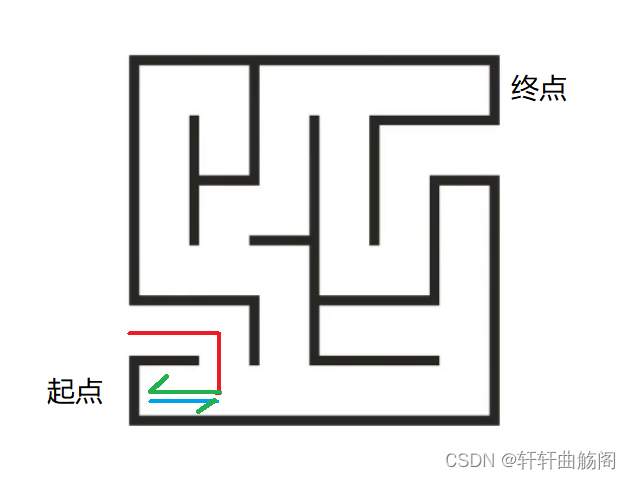
而在下面这种情况时,由于回到上一个分叉节点时,其有两种前进方式,而我们已经排除了其中的一种方式,此时我们需要对已经探索过的路径进行剪枝,即表示该路径无法到达终点
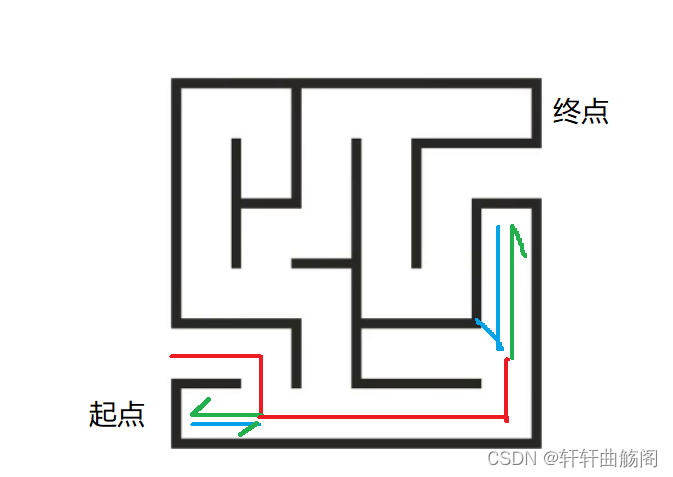
将其称为剪枝也是因为在树中访问过一个子树后,其就不用再次访问,即将树的枝条剪掉,是很形象的一个说法
4. 递归与循环(迭代)
在了解递归后,我们可以知道,递归解决的其实就是重复的问题,而循环也可以解决重复的问题,因此它们之间是可以互相转换的,那么在遇到一个既可以使用循环又可以使用递归的问题时,我们应该如何选择呢?
首先我们要知道,递归在展开后,我们可以发现它的路径和对一颗树进行dfs的路径是一样的,举个例子
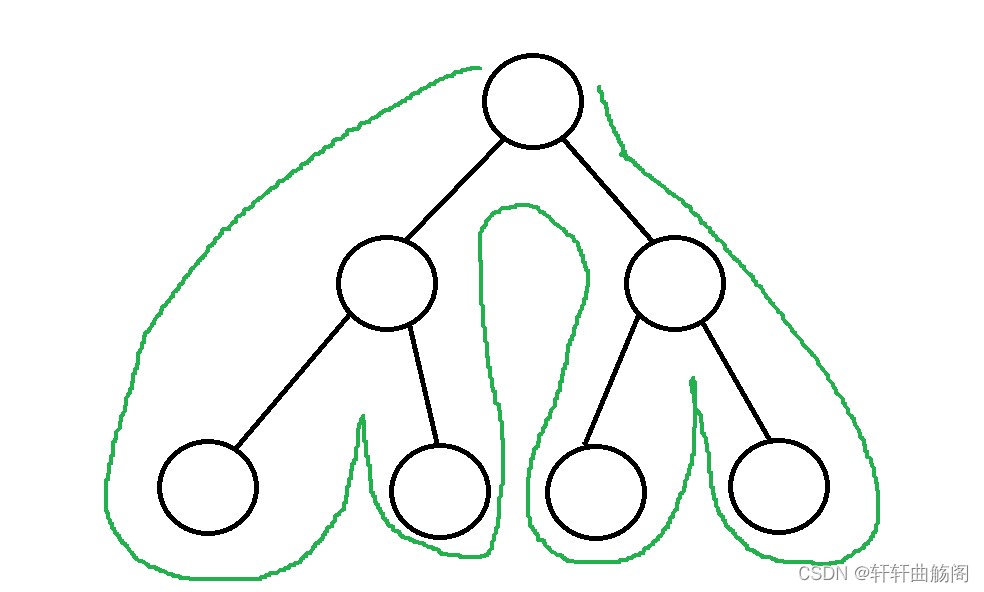
对于上面这棵树, 我们在递归解决它时,在深度递归完一条支路后需要返回到到上一个节点,即保存之前的信息,因此这里如果使用循环的话就需要使用栈来保存信息,因此此处使用递归更好,而在不需要保存信息的情况下,如遍历数组时,使用循环更佳
5. 例题
①递归专题
1. 汉诺塔问题
题目链接:面试题 08.06. 汉诺塔问题 - 力扣(LeetCode)

解析:题目说起来可能比较抽象,这里我们画图表示

大致要求是要让小的始终在上面,让后将A的所有圆盘移动到C上,我们在看到这个问题时,不能先入为主的想着用递归去解决它,而是在解决的过程中发现它具有一些递归的特性,然后才会想到使用递归解决它,那么我们如何解决它呢?这里我们可以使用先一般后特殊的方法
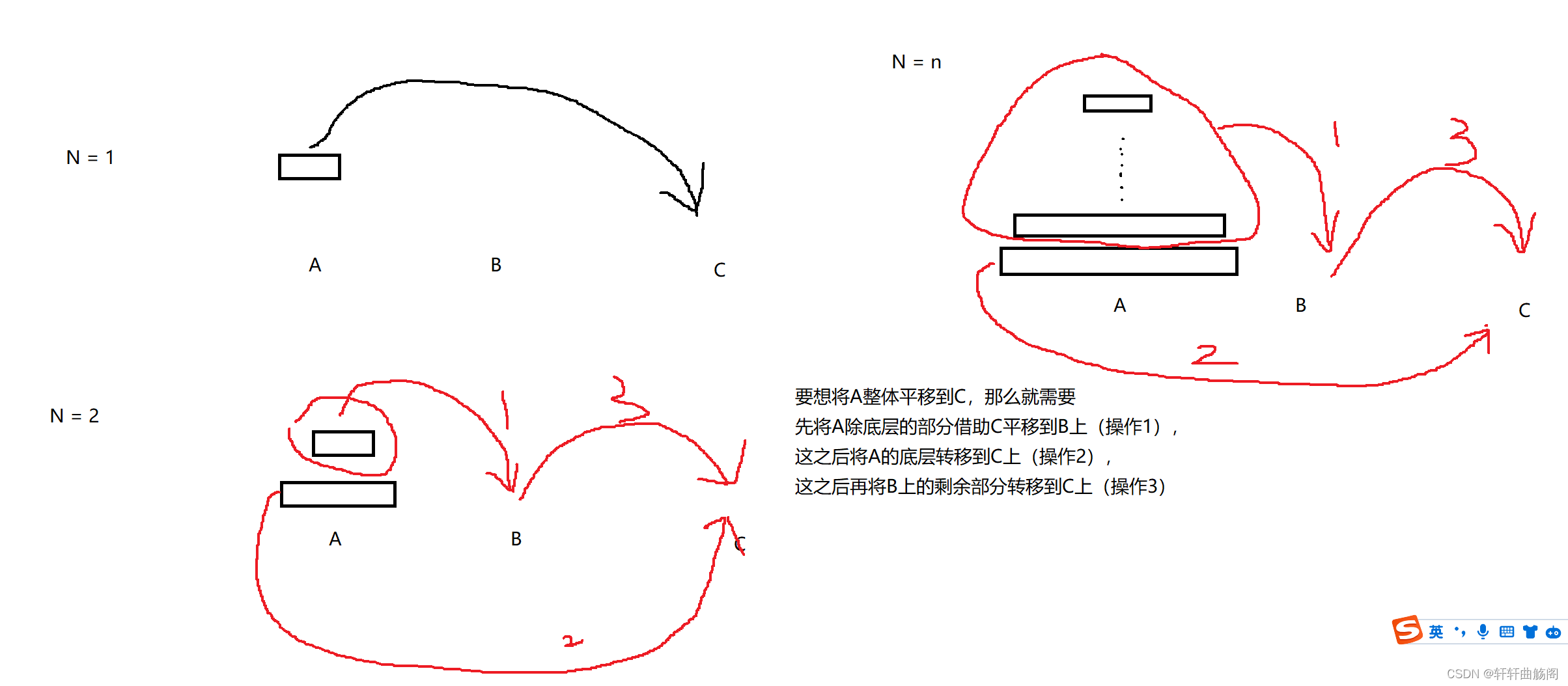
即在解决问题的过程中,我们可以发现在解决主问题时,衍生出来一个和他类似的子问题,而在解决子问题时,又出现一个和子问题相似的子问题,因此我们可以将其分解成若干个相同的子问题,即使用递归解决
其解决代码如下
class Solution
{
public:void Hanota(vector<int>& A, vector<int>& B, vector<int>& C, int n){// 出口if (n == 1) {C.push_back(A.back());A.pop_back();return;}// 操作1:借助C杆,将A上的n-1个圆盘移动到B上Hanota(A, C, B, n-1);// 操作2:将A杆的底层转移到C杆上C.push_back(A.back());A.pop_back();// 操作3:将B上的剩余部分借助A,转移到C杆上Hanota(B, A, C, n-1); }void hanota(vector<int>& A, vector<int>& B, vector<int>& C) {int n = A.size();Hanota(A, B, C, n);}
};注:在操作2中,不能直接向C直接插入A[0],通过逐步拆分我们可以发现,虽然逻辑上来说,我们是将A除底层的整个部分直接平移的,但在实际上,我们是从最上面开始一个一个平移的,因此这里使用的是back元素。
2. 合并两个有序链表
题目链接:21. 合并两个有序链表 - 力扣(LeetCode)
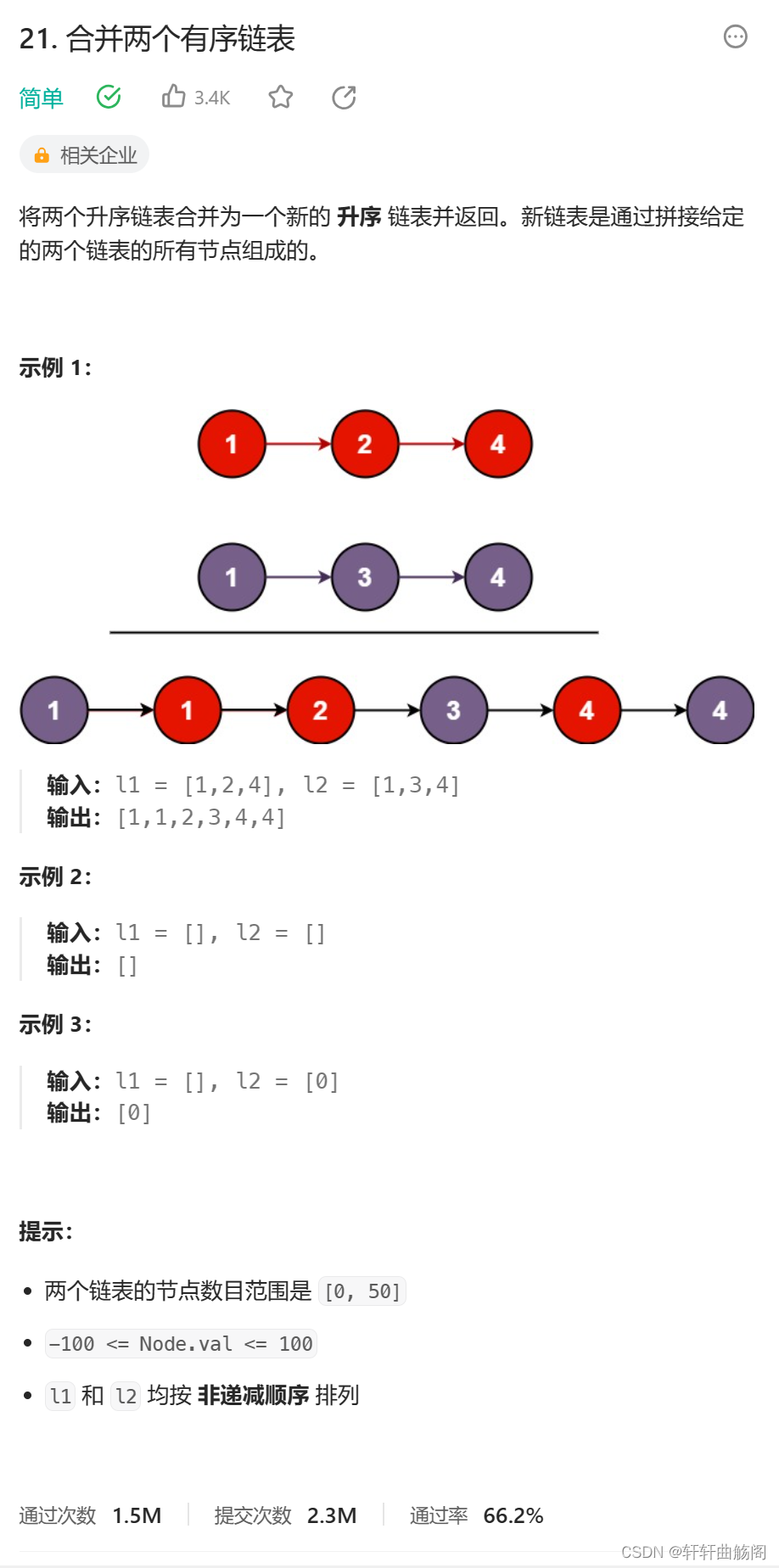
解析:
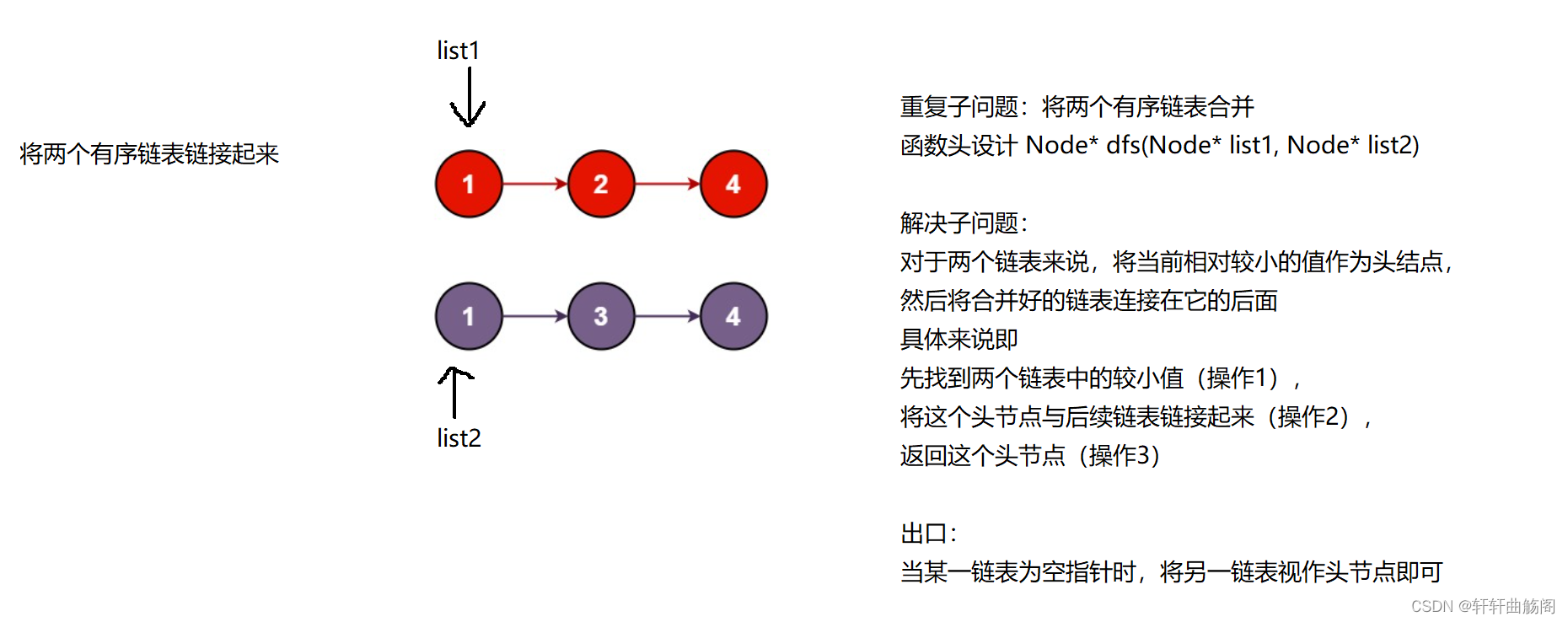
参考代码:
class Solution {
public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {return dfs(list1, list2); }ListNode* dfs(ListNode* list1, ListNode* list2) {// 出口if (list1 == nullptr) return list2;if (list2 == nullptr) return list1;// 比较大小后将当前较小节点作为头节点返回// 然后将它们链接起来if (list1->val < list2->val){list1->next = dfs(list1->next, list2);return list1; }else{list2->next = dfs(list1, list2->next);return list2; }}
};3. 反转链表
题目链接:206. 反转链表 - 力扣(LeetCode)
解析:
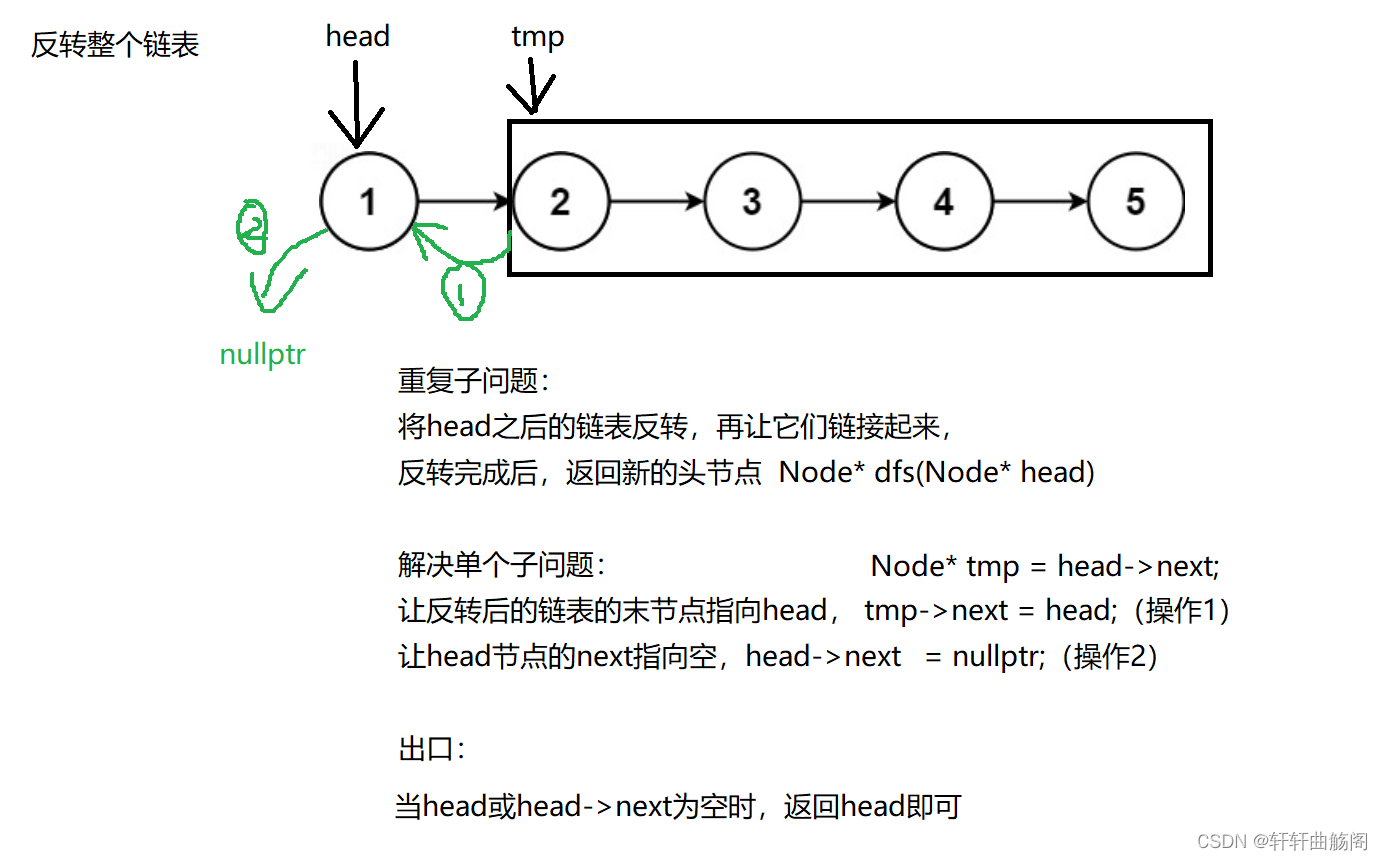
参考代码:
class Solution
{
public:ListNode* reverseList(ListNode* head) {// 出口if (head == nullptr || head->next == nullptr) return head;// 将当前节点之后的链表反转,并返回头节点ListNode* newhead = reverseList(head->next);// 反转之后让后面链表的next指向headhead->next->next = head;// 再将head的next指向空head->next = nullptr;return newhead;}
};4. 两两交换链表中的节点
题目链接:24. 两两交换链表中的节点 - 力扣(LeetCode)
解析:
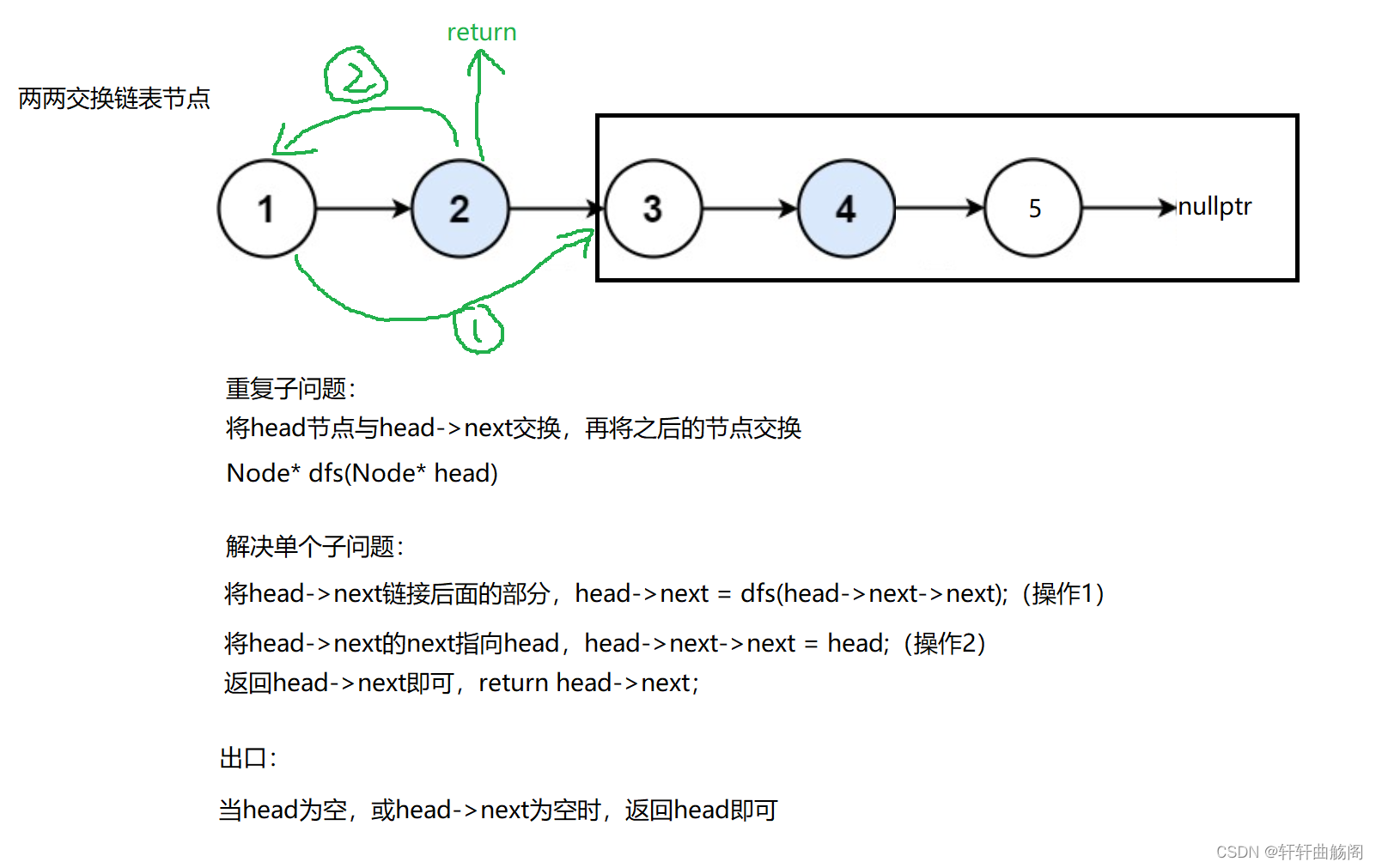
参考代码:
class Solution {
public:ListNode* dfs(ListNode* head){// 出口if (head == nullptr || head->next == nullptr) return head;// 反转之后的链表并链接起来ListNode* next = head->next;head->next = dfs(next->next);next->next = head;return next;}ListNode* swapPairs(ListNode* head){ListNode* newnode = dfs(head);return newnode;}
};5. Pow(x, n) —— 快速幂
题目链接:50. Pow(x, n) - 力扣(LeetCode)

解析:

参考代码:
class Solution {
public:double dfs(double x, int n){if (n == 0) return 1;double tmp = dfs(x, n/2);return n % 2 == 0 ? tmp * tmp : tmp * tmp * x;} double myPow(double x, int n) {int flag = 0;long long num = n;if (n < 0) {flag = 1;num *= -1;}double ret = dfs(x, n);return flag == 1 ? 1.0/ret : ret;}
};注:在这里因为n可能会取到INT_MIN,将其取负时会导致int类型的变量储存不下,因此需要long long类型来储存 。
②二叉树专题
1. 计算布尔⼆叉树的值
题目链接:2331. 计算布尔二叉树的值 - 力扣(LeetCode)
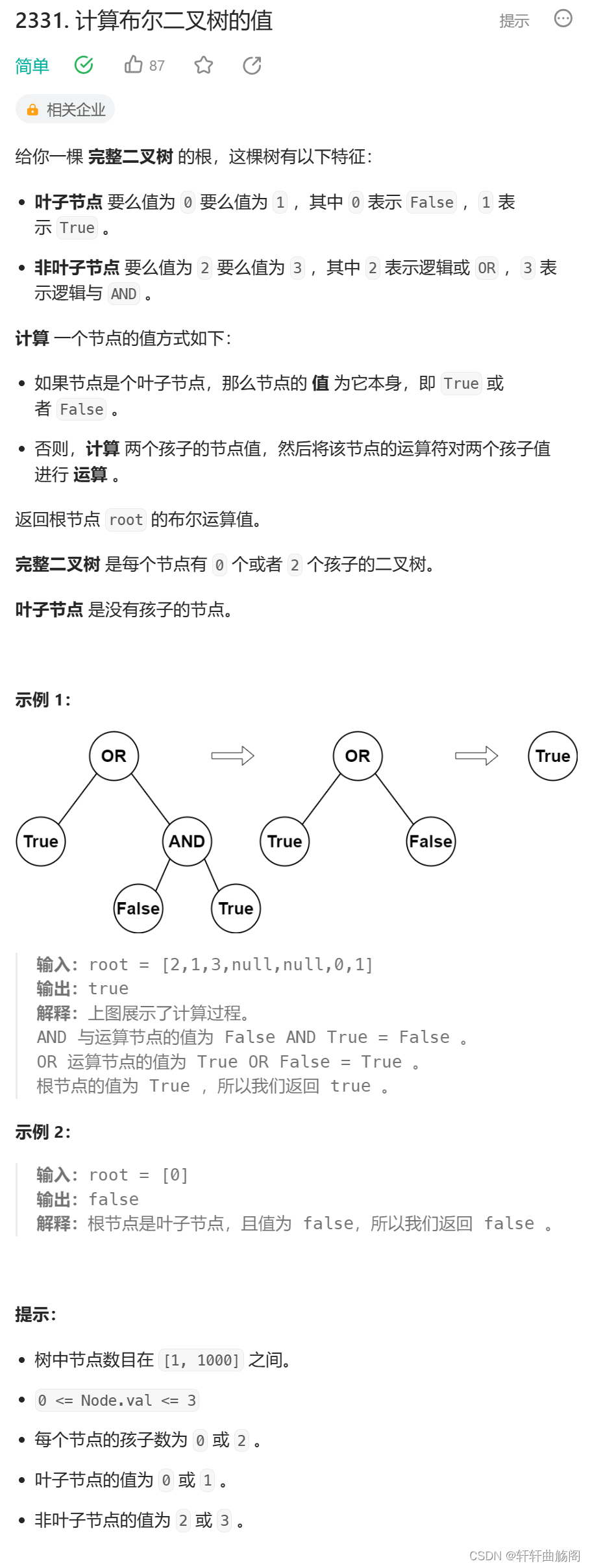
解析:
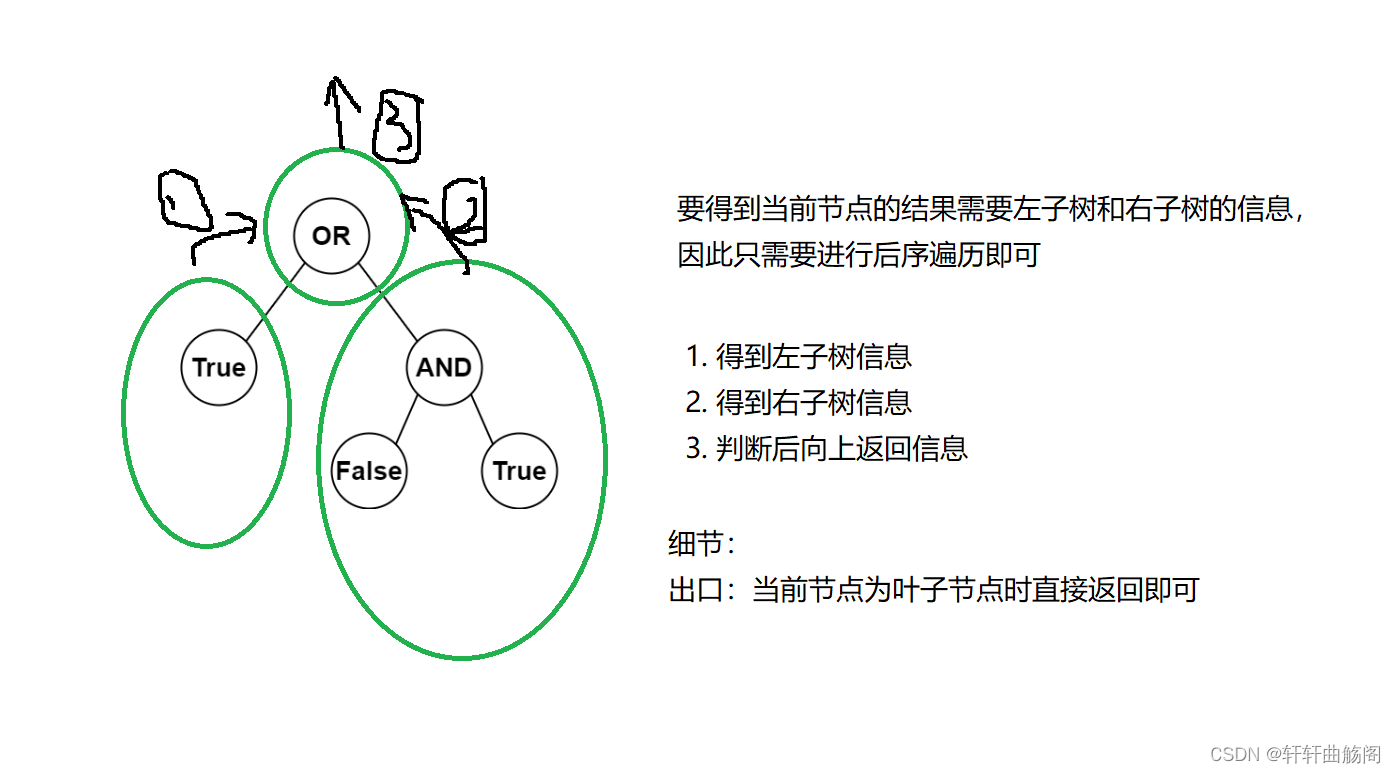
参考代码:
class Solution
{
public:bool evaluateTree(TreeNode* root){if (root->left == nullptr && root->right == nullptr) return root->val;bool left = evaluateTree(root->left);bool right = evaluateTree(root->right);return root->val == 2 ? left || right : left && right;}
};2. 求根节点到叶节点数字之和
题目链接:129. 求根节点到叶节点数字之和 - 力扣(LeetCode)
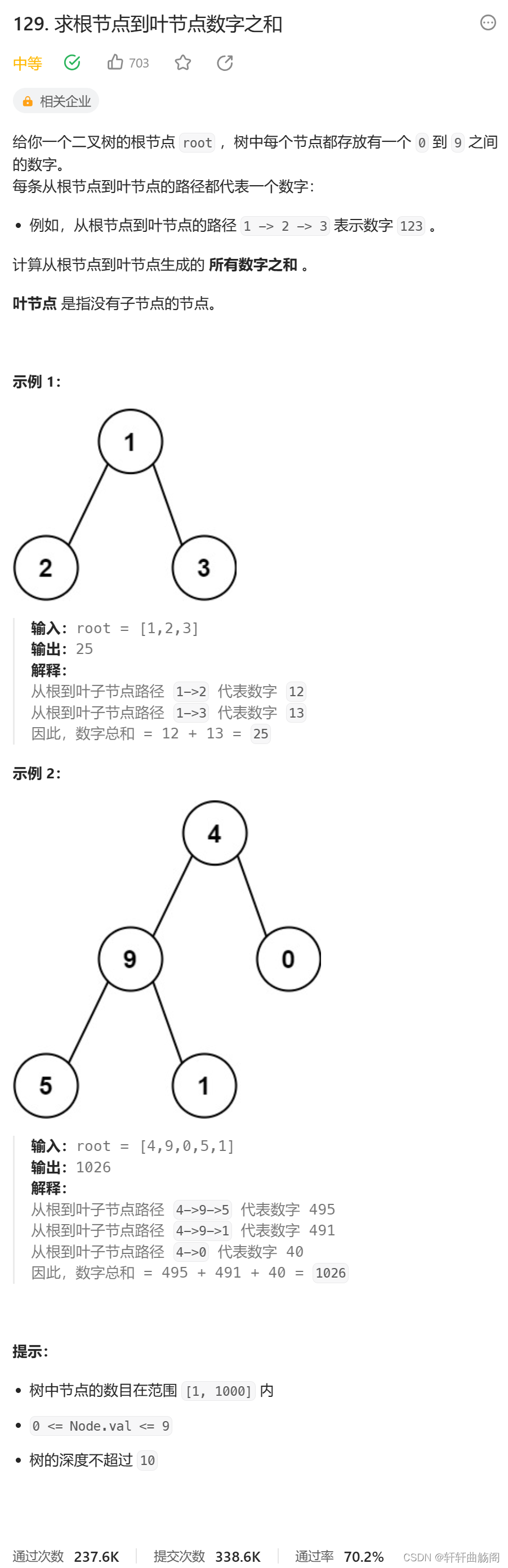
解析:
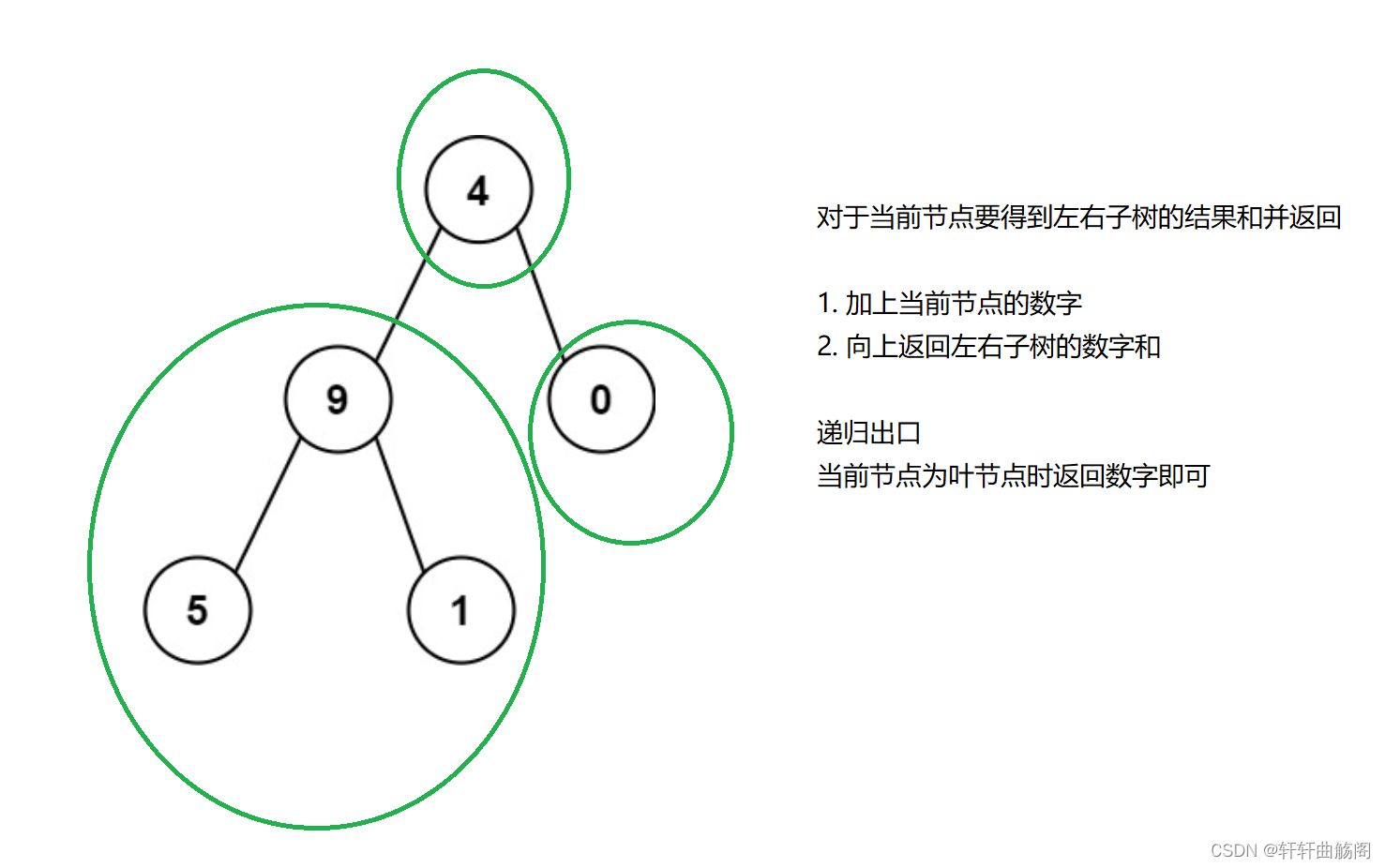
参考代码:
class Solution
{
public:int dfs(TreeNode* root, int prev){prev = prev * 10 + root->val;if (root->left == nullptr && root->right == nullptr) return prev;int res = 0;if (root->left) res += dfs(root->left, prev);if (root->right) res += dfs(root->right, prev);return res;}int sumNumbers(TreeNode* root){return dfs(root, 0);}
};