原文:Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
译者:飞龙
协议:CC BY-NC-SA 4.0
第十六章:使用 RNN 和注意力进行自然语言处理
当艾伦·图灵在 1950 年想象他著名的Turing 测试时,他提出了一种评估机器匹配人类智能能力的方法。他本可以测试许多事情,比如识别图片中的猫、下棋、创作音乐或逃离迷宫,但有趣的是,他选择了一项语言任务。更具体地说,他设计了一个聊天机器人,能够愚弄对话者以为它是人类。这个测试确实有其弱点:一组硬编码规则可以愚弄毫无戒心或天真的人类(例如,机器可以对某些关键词给出模糊的预定义答案,可以假装在回答一些最奇怪的问题时开玩笑或喝醉,或者可以通过用自己的问题回答难题来逃避困难的问题),并且许多人类智能的方面完全被忽视(例如,解释非言语交流,如面部表情,或学习手动任务的能力)。但这个测试确实突显了掌握语言可能是智人最伟大的认知能力。
我们能否构建一台能够掌握书面和口头语言的机器?这是自然语言处理研究的终极目标,但实际上研究人员更专注于更具体的任务,比如文本分类、翻译、摘要、问答等等。
自然语言任务的一种常见方法是使用循环神经网络。因此,我们将继续探索循环神经网络(在第十五章中介绍),首先是字符 RNN或char-RNN,训练以预测句子中的下一个字符。这将使我们能够生成一些原创文本。我们将首先使用无状态 RNN(在每次迭代中学习文本的随机部分,没有关于文本其余部分的信息),然后我们将构建有状态 RNN(在训练迭代之间保留隐藏状态,并继续阅读离开的地方,使其能够学习更长的模式)。接下来,我们将构建一个 RNN 来执行情感分析(例如,阅读电影评论并提取评价者对电影的感受),这次将句子视为单词序列,而不是字符。然后我们将展示如何使用 RNN 来构建一个编码器-解码器架构,能够执行神经机器翻译(NMT),将英语翻译成西班牙语。
在本章的第二部分,我们将探索注意机制。正如它们的名字所示,这些是神经网络组件,它们学习选择模型在每个时间步应该关注的输入部分。首先,我们将通过注意机制提高基于 RNN 的编码器-解码器架构的性能。接下来,我们将完全放弃 RNN,并使用一个非常成功的仅注意架构,称为transformer,来构建一个翻译模型。然后,我们将讨论过去几年自然语言处理中一些最重要的进展,包括基于 transformer 的 GPT 和 BERT 等非常强大的语言模型。最后,我将向您展示如何开始使用 Hugging Face 出色的 Transformers 库。
让我们从一个简单而有趣的模型开始,这个模型可以像莎士比亚一样写作(某种程度上)。
使用字符 RNN 生成莎士比亚文本
在一篇著名的2015 年博客文章中,安德烈·卡帕西展示了如何训练一个 RNN 来预测句子中的下一个字符。然后可以使用这个char-RNN逐个字符生成新文本。以下是一个经过训练所有莎士比亚作品后由 char-RNN 模型生成的文本的小样本:
潘达鲁斯:
唉,我想他将会被接近并且这一天
当一点点智慧被获得而从未被喂养时,
而谁不是一条链,是他死亡的主题,
我不应该睡觉。
虽然不是杰作,但仍然令人印象深刻,模型能够学习单词、语法、正确的标点符号等,只是通过学习预测句子中的下一个字符。这是我们的第一个语言模型示例;本章后面讨论的类似(但更强大)的语言模型是现代自然语言处理的核心。在本节的其余部分,我们将逐步构建一个 char-RNN,从创建数据集开始。
创建训练数据集
首先,使用 Keras 方便的 tf.keras.utils.get_file() 函数,让我们下载所有莎士比亚的作品。数据是从 Andrej Karpathy 的char-rnn 项目加载的:
import tensorflow as tfshakespeare_url = "https://homl.info/shakespeare" # shortcut URL
filepath = tf.keras.utils.get_file("shakespeare.txt", shakespeare_url)
with open(filepath) as f:shakespeare_text = f.read()
让我们打印前几行:
>>> print(shakespeare_text[:80])
First Citizen:
Before we proceed any further, hear me speak.All:
Speak, speak.
看起来像是莎士比亚的作品!
接下来,我们将使用 tf.keras.layers.TextVectorization 层(在第十三章介绍)对此文本进行编码。我们设置 split="character" 以获得字符级别的编码,而不是默认的单词级别编码,并且我们使用 standardize="lower" 将文本转换为小写(这将简化任务):
text_vec_layer = tf.keras.layers.TextVectorization(split="character",standardize="lower")
text_vec_layer.adapt([shakespeare_text])
encoded = text_vec_layer([shakespeare_text])[0]
现在,每个字符都映射到一个整数,从 2 开始。TextVectorization 层将值 0 保留给填充标记,将值 1 保留给未知字符。目前我们不需要这两个标记,所以让我们从字符 ID 中减去 2,并计算不同字符的数量和总字符数:
encoded -= 2 # drop tokens 0 (pad) and 1 (unknown), which we will not use
n_tokens = text_vec_layer.vocabulary_size() - 2 # number of distinct chars = 39
dataset_size = len(encoded) # total number of chars = 1,115,394
接下来,就像我们在第十五章中所做的那样,我们可以将这个非常长的序列转换为一个窗口的数据集,然后用它来训练一个序列到序列的 RNN。目标将类似于输入,但是向“未来”移动了一个时间步。例如,数据集中的一个样本可能是代表文本“to be or not to b”(没有最后的“e”)的字符 ID 序列,相应的目标是代表文本“o be or not to be”(有最后的“e”,但没有开头的“t”)的字符 ID 序列。让我们编写一个小型实用函数,将字符 ID 的长序列转换为输入/目标窗口对的数据集:
def to_dataset(sequence, length, shuffle=False, seed=None, batch_size=32):ds = tf.data.Dataset.from_tensor_slices(sequence)ds = ds.window(length + 1, shift=1, drop_remainder=True)ds = ds.flat_map(lambda window_ds: window_ds.batch(length + 1))if shuffle:ds = ds.shuffle(buffer_size=100_000, seed=seed)ds = ds.batch(batch_size)return ds.map(lambda window: (window[:, :-1], window[:, 1:])).prefetch(1)
这个函数开始得很像我们在第十五章中创建的 to_windows() 自定义实用函数:
-
它以一个序列作为输入(即编码文本),并创建一个包含所需长度的所有窗口的数据集。
-
它将长度增加一,因为我们需要下一个字符作为目标。
-
然后,它会对窗口进行洗牌(可选),将它们分批处理,拆分为输入/输出对,并激活预取。
图 16-1 总结了数据集准备步骤:它展示了长度为 11 的窗口,批量大小为 3。每个窗口的起始索引在其旁边标出。

图 16-1. 准备一个洗牌窗口的数据集
现在我们准备创建训练集、验证集和测试集。我们将大约使用文本的 90%进行训练,5%用于验证,5%用于测试:
length = 100
tf.random.set_seed(42)
train_set = to_dataset(encoded[:1_000_000], length=length, shuffle=True,seed=42)
valid_set = to_dataset(encoded[1_000_000:1_060_000], length=length)
test_set = to_dataset(encoded[1_060_000:], length=length)
提示
我们将窗口长度设置为 100,但您可以尝试调整它:在较短的输入序列上训练 RNN 更容易更快,但 RNN 将无法学习任何长于 length 的模式,所以不要将其设置得太小。
就是这样!准备数据集是最困难的部分。现在让我们创建模型。
构建和训练 Char-RNN 模型
由于我们的数据集相当大,而建模语言是一个相当困难的任务,我们需要不止一个简单的具有几个循环神经元的 RNN。让我们构建并训练一个由 128 个单元组成的 GRU 层的模型(如果需要,稍后可以尝试调整层数和单元数):
model = tf.keras.Sequential([tf.keras.layers.Embedding(input_dim=n_tokens, output_dim=16),tf.keras.layers.GRU(128, return_sequences=True),tf.keras.layers.Dense(n_tokens, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam",metrics=["accuracy"])
model_ckpt = tf.keras.callbacks.ModelCheckpoint("my_shakespeare_model", monitor="val_accuracy", save_best_only=True)
history = model.fit(train_set, validation_data=valid_set, epochs=10,callbacks=[model_ckpt])
让我们仔细看看这段代码:
-
我们使用一个
Embedding层作为第一层,用于编码字符 ID(嵌入在第十三章中介绍)。Embedding层的输入维度数是不同字符 ID 的数量,输出维度数是一个可以调整的超参数,我们暂时将其设置为 16。Embedding层的输入将是形状为[批量大小, 窗口长度]的 2D 张量,Embedding层的输出将是形状为[批量大小, 窗口长度, 嵌入大小]的 3D 张量。 -
我们使用一个
Dense层作为输出层:它必须有 39 个单元(n_tokens),因为文本中有 39 个不同的字符,并且我们希望在每个时间步输出每个可能字符的概率。39 个输出概率应该在每个时间步加起来为 1,因此我们将 softmax 激活函数应用于Dense层的输出。 -
最后,我们编译这个模型,使用
"sparse_categorical_crossentropy"损失和 Nadam 优化器,然后训练模型多个 epoch,使用ModelCheckpoint回调来保存训练过程中验证准确性最好的模型。
提示
如果您在启用 GPU 的 Colab 上运行此代码,则训练大约需要一到两个小时。如果您不想等待那么长时间,可以减少 epoch 的数量,但当然模型的准确性可能会降低。如果 Colab 会话超时,请确保快速重新连接,否则 Colab 运行时将被销毁。
这个模型不处理文本预处理,所以让我们将其包装在一个最终模型中,包含tf.keras.layers.TextVectorization层作为第一层,加上一个tf.keras.layers.Lambda层,从字符 ID 中减去 2,因为我们暂时不使用填充和未知标记:
shakespeare_model = tf.keras.Sequential([text_vec_layer,tf.keras.layers.Lambda(lambda X: X - 2), # no <PAD> or <UNK> tokensmodel
])
现在让我们用它来预测句子中的下一个字符:
>>> y_proba = shakespeare_model.predict(["To be or not to b"])[0, -1]
>>> y_pred = tf.argmax(y_proba) # choose the most probable character ID
>>> text_vec_layer.get_vocabulary()[y_pred + 2]
'e'
太好了,模型正确预测了下一个字符。现在让我们使用这个模型假装我们是莎士比亚!
生成虚假的莎士比亚文本
使用 char-RNN 模型生成新文本时,我们可以将一些文本输入模型,让模型预测最有可能的下一个字母,将其添加到文本末尾,然后将扩展后的文本提供给模型猜测下一个字母,依此类推。这被称为贪婪解码。但在实践中,这经常导致相同的单词一遍又一遍地重复。相反,我们可以随机采样下一个字符,概率等于估计的概率,使用 TensorFlow 的tf.random.categorical()函数。这将生成更多样化和有趣的文本。categorical()函数会根据类别对数概率(logits)随机采样随机类别索引。例如:
>>> log_probas = tf.math.log([[0.5, 0.4, 0.1]]) # probas = 50%, 40%, and 10%
>>> tf.random.set_seed(42)
>>> tf.random.categorical(log_probas, num_samples=8) # draw 8 samples
<tf.Tensor: shape=(1, 8), dtype=int64, numpy=array([[0, 1, 0, 2, 1, 0, 0, 1]])>
为了更好地控制生成文本的多样性,我们可以将 logits 除以一个称为温度的数字,我们可以根据需要进行调整。接近零的温度偏好高概率字符,而高温度使所有字符具有相等的概率。在生成相对严格和精确的文本(如数学方程式)时,通常更喜欢较低的温度,而在生成更多样化和创意性的文本时,更喜欢较高的温度。以下next_char()自定义辅助函数使用这种方法选择要添加到输入文本中的下一个字符:
def next_char(text, temperature=1):y_proba = shakespeare_model.predict([text])[0, -1:]rescaled_logits = tf.math.log(y_proba) / temperaturechar_id = tf.random.categorical(rescaled_logits, num_samples=1)[0, 0]return text_vec_layer.get_vocabulary()[char_id + 2]
接下来,我们可以编写另一个小的辅助函数,它将重复调用next_char()以获取下一个字符并将其附加到给定的文本中:
def extend_text(text, n_chars=50, temperature=1):for _ in range(n_chars):text += next_char(text, temperature)return text
现在我们准备生成一些文本!让我们尝试不同的温度值:
>>> tf.random.set_seed(42)
>>> print(extend_text("To be or not to be", temperature=0.01))
To be or not to be the duke
as it is a proper strange death,
and the
>>> print(extend_text("To be or not to be", temperature=1))
To be or not to behold?second push:
gremio, lord all, a sistermen,
>>> print(extend_text("To be or not to be", temperature=100))
To be or not to bef ,mt'&o3fpadm!$
wh!nse?bws3est--vgerdjw?c-y-ewznq
莎士比亚似乎正在遭受一场热浪。为了生成更具说服力的文本,一个常见的技术是仅从前 k 个字符中采样,或者仅从总概率超过某个阈值的最小一组顶级字符中采样(这被称为核心采样)。另外,您可以尝试使用波束搜索,我们将在本章后面讨论,或者使用更多的GRU层和更多的神经元每层,训练更长时间,并在需要时添加一些正则化。还要注意,模型目前无法学习比length更长的模式,length只是 100 个字符。您可以尝试将此窗口扩大,但这也会使训练更加困难,即使 LSTM 和 GRU 单元也无法处理非常长的序列。另一种替代方法是使用有状态的 RNN。
有状态的 RNN
到目前为止,我们只使用了无状态的 RNN:在每次训练迭代中,模型从一个全零的隐藏状态开始,然后在每个时间步更新这个状态,在最后一个时间步之后,将其丢弃,因为不再需要。如果我们指示 RNN 在处理训练批次后保留这个最终状态,并将其用作下一个训练批次的初始状态,会怎样呢?这样,模型可以学习长期模式,尽管只通过短序列进行反向传播。这被称为有状态的 RNN。让我们看看如何构建一个。
首先,注意到有状态的 RNN 只有在批次中的每个输入序列从上一个批次中对应序列的确切位置开始时才有意义。因此,我们构建有状态的 RNN 需要做的第一件事是使用顺序且不重叠的输入序列(而不是我们用来训练无状态 RNN 的洗牌和重叠序列)。在创建tf.data.Dataset时,因此在调用window()方法时必须使用shift=length(而不是shift=1)。此外,我们必须不调用shuffle()方法。
不幸的是,为有状态的 RNN 准备数据集时,批处理比为无状态的 RNN 更加困难。实际上,如果我们调用batch(32),那么 32 个连续窗口将被放入同一个批次中,接下来的批次将不会继续每个窗口的位置。第一个批次将包含窗口 1 到 32,第二个批次将包含窗口 33 到 64,因此如果您考虑,比如说,每个批次的第一个窗口(即窗口 1 和 33),您会发现它们不是连续的。这个问题的最简单解决方案就是只使用批量大小为 1。以下的to_dataset_for_stateful_rnn()自定义实用函数使用这种策略来为有状态的 RNN 准备数据集:
def to_dataset_for_stateful_rnn(sequence, length):ds = tf.data.Dataset.from_tensor_slices(sequence)ds = ds.window(length + 1, shift=length, drop_remainder=True)ds = ds.flat_map(lambda window: window.batch(length + 1)).batch(1)return ds.map(lambda window: (window[:, :-1], window[:, 1:])).prefetch(1)stateful_train_set = to_dataset_for_stateful_rnn(encoded[:1_000_000], length)
stateful_valid_set = to_dataset_for_stateful_rnn(encoded[1_000_000:1_060_000],length)
stateful_test_set = to_dataset_for_stateful_rnn(encoded[1_060_000:], length)
图 16-2 总结了这个函数的主要步骤。

图 16-2。为有状态的 RNN 准备连续序列片段的数据集
批处理更加困难,但并非不可能。例如,我们可以将莎士比亚的文本分成 32 个等长的文本,为每个文本创建一个连续输入序列的数据集,最后使用tf.data.Dataset.zip(datasets).map(lambda *windows: tf.stack(windows))来创建正确的连续批次,其中批次中的第n个输入序列从上一个批次中的第n个输入序列结束的地方开始(请参阅笔记本获取完整代码)。
现在,让我们创建有状态的 RNN。在创建每个循环层时,我们需要将stateful参数设置为True,因为有状态的 RNN 需要知道批量大小(因为它将为批次中的每个输入序列保留一个状态)。因此,我们必须在第一层中设置batch_input_shape参数。请注意,我们可以将第二维度留空,因为输入序列可以具有任意长度:
model = tf.keras.Sequential([tf.keras.layers.Embedding(input_dim=n_tokens, output_dim=16,batch_input_shape=[1, None]),tf.keras.layers.GRU(128, return_sequences=True, stateful=True),tf.keras.layers.Dense(n_tokens, activation="softmax")
])
在每个时期结束时,我们需要在回到文本开头之前重置状态。为此,我们可以使用一个小的自定义 Keras 回调:
class ResetStatesCallback(tf.keras.callbacks.Callback):def on_epoch_begin(self, epoch, logs):self.model.reset_states()
现在我们可以编译模型并使用我们的回调函数进行训练:
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam",metrics=["accuracy"])
history = model.fit(stateful_train_set, validation_data=stateful_valid_set,epochs=10, callbacks=[ResetStatesCallback(), model_ckpt])
提示
训练完这个模型后,只能用它来对与训练时相同大小的批次进行预测。为了避免这个限制,创建一个相同的无状态模型,并将有状态模型的权重复制到这个模型中。
有趣的是,尽管 char-RNN 模型只是训练来预测下一个字符,但这看似简单的任务实际上也需要它学习一些更高级的任务。例如,要找到“Great movie, I really”之后的下一个字符,了解到这句话是积极的是有帮助的,所以下一个字符更有可能是“l”(代表“loved”)而不是“h”(代表“hated”)。事实上,OpenAI 的 Alec Radford 和其他研究人员在一篇 2017 年的论文中描述了他们如何在大型数据集上训练了一个类似于大型 char-RNN 模型,并发现其中一个神经元表现出色地作为情感分析分类器:尽管该模型在没有任何标签的情况下进行了训练,但他们称之为情感神经元达到了情感分析基准测试的最新性能。这预示并激励了 NLP 中的无监督预训练。
但在探索无监督预训练之前,让我们将注意力转向单词级模型以及如何在监督方式下用它们进行情感分析。在这个过程中,您将学习如何使用掩码处理可变长度的序列。
情感分析
生成文本可能很有趣且有教育意义,但在实际项目中,自然语言处理的最常见应用之一是文本分类,尤其是情感分析。如果在 MNIST 数据集上进行图像分类是计算机视觉的“Hello world!”,那么在 IMDb 评论数据集上进行情感分析就是自然语言处理的“Hello world!”。IMDb 数据集包含了来自著名的互联网电影数据库的 50,000 条英文电影评论(25,000 条用于训练,25,000 条用于测试),每条评论都有一个简单的二进制目标,表示其是否为负面(0)或正面(1)。就像 MNIST 一样,IMDb 评论数据集之所以受欢迎是有充分理由的:它足够简单,可以在笔记本电脑上在合理的时间内处理,但足够具有挑战性和有趣。
让我们使用 TensorFlow Datasets 库加载 IMDb 数据集(在第十三章中介绍)。我们将使用训练集的前 90%进行训练,剩下的 10%用于验证:
import tensorflow_datasets as tfdsraw_train_set, raw_valid_set, raw_test_set = tfds.load(name="imdb_reviews",split=["train[:90%]", "train[90%:]", "test"],as_supervised=True
)
tf.random.set_seed(42)
train_set = raw_train_set.shuffle(5000, seed=42).batch(32).prefetch(1)
valid_set = raw_valid_set.batch(32).prefetch(1)
test_set = raw_test_set.batch(32).prefetch(1)
提示
如果您愿意,Keras 还包括一个用于加载 IMDb 数据集的函数:tf.keras.datasets.imdb.load_data()。评论已经被预处理为单词 ID 的序列。
让我们检查一些评论:
>>> for review, label in raw_train_set.take(4):
... print(review.numpy().decode("utf-8"))
... print("Label:", label.numpy())
...
This was an absolutely terrible movie. Don't be lured in by Christopher [...]
Label: 0
I have been known to fall asleep during films, but this is usually due to [...]
Label: 0
Mann photographs the Alberta Rocky Mountains in a superb fashion, and [...]
Label: 0
This is the kind of film for a snowy Sunday afternoon when the rest of the [...]
Label: 1
有些评论很容易分类。例如,第一条评论中的第一句话包含“terrible movie”这几个词。但在许多情况下,事情并不那么简单。例如,第三条评论一开始是积极的,尽管最终是一个负面评论(标签 0)。
为了为这个任务构建一个模型,我们需要预处理文本,但这次我们将其分成单词而不是字符。为此,我们可以再次使用tf.keras.layers.TextVectorization层。请注意,它使用空格来识别单词边界,在某些语言中可能效果不佳。例如,中文书写不使用单词之间的空格,越南语甚至在单词内部也使用空格,德语经常将多个单词连接在一起,没有空格。即使在英语中,空格也不总是分词的最佳方式:想想“San Francisco”或“#ILoveDeepLearning”。
幸运的是,有解决这些问题的解决方案。在2016 年的一篇论文,爱丁堡大学的 Rico Sennrich 等人探索了几种在子词级别对文本进行标记和去标记化的方法。这样,即使您的模型遇到了以前从未见过的罕见单词,它仍然可以合理地猜测它的含义。例如,即使模型在训练期间从未见过单词“smartest”,如果它学会了单词“smart”并且还学会了后缀“est”表示“最”,它可以推断出“smartest”的含义。作者评估的技术之一是字节对编码(BPE)。BPE 通过将整个训练集拆分为单个字符(包括空格),然后重复合并最频繁的相邻对,直到词汇表达到所需大小。
Google 的 Taku Kudo 在 2018 年发表的一篇论文进一步改进了子词标记化,通常消除了标记化之前需要进行特定于语言的预处理的需要。此外,该论文提出了一种称为子词正则化的新型正则化技术,通过在训练期间在标记化中引入一些随机性来提高准确性和稳健性:例如,“New England”可以被标记为“New”+“England”,或“New”+“Eng”+“land”,或简单地“New England”(只有一个标记)。Google 的SentencePiece项目提供了一个开源实现,该实现在 Taku Kudo 和 John Richardson 的一篇论文中有描述。
TensorFlow Text库还实现了各种标记化策略,包括WordPiece(BPE 的变体),最后但同样重要的是,Hugging Face 的 Tokenizers 库实现了一系列极快的标记化器。
然而,对于英语中的 IMDb 任务,使用空格作为标记边界应该足够好。因此,让我们继续创建一个TextVectorization层,并将其调整到训练集。我们将词汇表限制为 1,000 个标记,包括最常见的 998 个单词以及一个填充标记和一个未知单词的标记,因为很少见的单词不太可能对这个任务很重要,并且限制词汇表大小将减少模型需要学习的参数数量:
vocab_size = 1000
text_vec_layer = tf.keras.layers.TextVectorization(max_tokens=vocab_size)
text_vec_layer.adapt(train_set.map(lambda reviews, labels: reviews))
最后,我们可以创建模型并训练它:
embed_size = 128
tf.random.set_seed(42)
model = tf.keras.Sequential([text_vec_layer,tf.keras.layers.Embedding(vocab_size, embed_size),tf.keras.layers.GRU(128),tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="nadam",metrics=["accuracy"])
history = model.fit(train_set, validation_data=valid_set, epochs=2)
第一层是我们刚刚准备的TextVectorization层,接着是一个Embedding层,将单词 ID 转换为嵌入。嵌入矩阵需要每个词汇表中的标记一行(vocab_size),每个嵌入维度一列(此示例使用 128 维,但这是一个可以调整的超参数)。接下来我们使用一个GRU层和一个具有单个神经元和 sigmoid 激活函数的Dense层,因为这是一个二元分类任务:模型的输出将是评论表达对电影积极情绪的估计概率。然后我们编译模型,并在我们之前准备的数据集上进行几个时期的拟合(或者您可以训练更长时间以获得更好的结果)。
遗憾的是,如果运行此代码,通常会发现模型根本无法学习任何东西:准确率保持接近 50%,不比随机机会好。为什么呢?评论的长度不同,因此当TextVectorization层将它们转换为标记 ID 序列时,它使用填充标记(ID 为 0)填充较短的序列,使它们与批次中最长序列一样长。结果,大多数序列以许多填充标记结尾——通常是几十甚至几百个。即使我们使用的是比SimpleRNN层更好的GRU层,它的短期记忆仍然不太好,因此当它经过许多填充标记时,它最终会忘记评论的内容!一个解决方案是用等长的句子批次喂给模型(这也加快了训练速度)。另一个解决方案是让 RNN 忽略填充标记。这可以通过掩码来实现。
掩码
使用 Keras 让模型忽略填充标记很简单:在创建Embedding层时简单地添加mask_zero=True。这意味着所有下游层都会忽略填充标记(其 ID 为 0)。就是这样!如果对先前的模型进行几个时期的重新训练,您会发现验证准确率很快就能达到 80%以上。
这种工作方式是,Embedding层创建一个等于tf.math.not_equal(inputs, 0)的掩码张量:它是一个布尔张量,形状与输入相同,如果标记 ID 为 0,则等于False,否则等于True。然后,该掩码张量会被模型自动传播到下一层。如果该层的call()方法有一个mask参数,那么它会自动接收到掩码。这使得该层能够忽略适当的时间步。每个层可能会以不同的方式处理掩码,但通常它们只是忽略被掩码的时间步(即掩码为False的时间步)。例如,当循环层遇到被掩码的时间步时,它只是复制前一个时间步的输出。
接下来,如果该层的supports_masking属性为True,那么掩码会自动传播到下一层。只要层具有supports_masking=True,它就会继续这样传播。例如,当return_sequences=True时,循环层的supports_masking属性为True,但当return_sequences=False时,它为False,因为在这种情况下不再需要掩码。因此,如果您有一个具有多个return_sequences=True的循环层,然后是一个return_sequences=False的循环层的模型,那么掩码将自动传播到最后一个循环层:该层将使用掩码来忽略被掩码的步骤,但不会进一步传播掩码。同样,如果在我们刚刚构建的情感分析模型中创建Embedding层时设置了mask_zero=True,那么GRU层将自动接收和使用掩码,但不会进一步传播,因为return_sequences没有设置为True。
提示
一些层在将掩码传播到下一层之前需要更新掩码:它们通过实现compute_mask()方法来实现,该方法接受两个参数:输入和先前的掩码。然后计算更新后的掩码并返回。compute_mask()的默认实现只是返回先前的掩码而没有更改。
许多 Keras 层支持掩码:SimpleRNN、GRU、LSTM、Bidirectional、Dense、TimeDistributed、Add等(都在tf.keras.layers包中)。然而,卷积层(包括Conv1D)不支持掩码——它们如何支持掩码并不明显。
如果掩码一直传播到输出,那么它也会应用到损失上,因此被掩码的时间步将不会对损失产生贡献(它们的损失将为 0)。这假设模型输出序列,这在我们的情感分析模型中并不是这样。
警告
LSTM和GRU层具有基于 Nvidia 的 cuDNN 库的优化实现。但是,此实现仅在所有填充标记位于序列末尾时支持遮罩。它还要求您使用几个超参数的默认值:activation、recurrent_activation、recurrent_dropout、unroll、use_bias和reset_after。如果不是这种情况,那么这些层将退回到(速度慢得多的)默认 GPU 实现。
如果要实现支持遮罩的自定义层,应在call()方法中添加一个mask参数,并显然使方法使用该遮罩。此外,如果遮罩必须传播到下一层,则应在构造函数中设置self.supports_masking=True。如果必须在传播之前更新遮罩,则必须实现compute_mask()方法。
如果您的模型不以Embedding层开头,可以使用tf.keras.layers.Masking层代替:默认情况下,它将遮罩设置为tf.math.reduce_any(tf.math.not_equal(X, 0), axis=-1),意味着最后一个维度全是零的时间步将在后续层中被遮罩。
使用遮罩层和自动遮罩传播对简单模型效果最好。对于更复杂的模型,例如需要将Conv1D层与循环层混合时,并不总是适用。在这种情况下,您需要显式计算遮罩并将其传递给适当的层,可以使用函数式 API 或子类 API。例如,以下模型与之前的模型等效,只是使用函数式 API 构建,并手动处理遮罩。它还添加了一点辍学,因为之前的模型略微过拟合:
inputs = tf.keras.layers.Input(shape=[], dtype=tf.string)
token_ids = text_vec_layer(inputs)
mask = tf.math.not_equal(token_ids, 0)
Z = tf.keras.layers.Embedding(vocab_size, embed_size)(token_ids)
Z = tf.keras.layers.GRU(128, dropout=0.2)(Z, mask=mask)
outputs = tf.keras.layers.Dense(1, activation="sigmoid")(Z)
model = tf.keras.Model(inputs=[inputs], outputs=[outputs])
遮罩的最后一种方法是使用不规则张量来向模型提供输入。实际上,您只需在创建TextVectorization层时设置ragged=True,以便将输入序列表示为不规则张量:
>>> text_vec_layer_ragged = tf.keras.layers.TextVectorization(
... max_tokens=vocab_size, ragged=True)
...
>>> text_vec_layer_ragged.adapt(train_set.map(lambda reviews, labels: reviews))
>>> text_vec_layer_ragged(["Great movie!", "This is DiCaprio's best role."])
<tf.RaggedTensor [[86, 18], [11, 7, 1, 116, 217]]>
将这种不规则张量表示与使用填充标记的常规张量表示进行比较:
>>> text_vec_layer(["Great movie!", "This is DiCaprio's best role."])
<tf.Tensor: shape=(2, 5), dtype=int64, numpy=
array([[ 86, 18, 0, 0, 0],[ 11, 7, 1, 116, 217]])>
Keras 的循环层内置支持不规则张量,因此您无需执行其他操作:只需在模型中使用此TextVectorization层。无需传递mask_zero=True或显式处理遮罩——这一切都已为您实现。这很方便!但是,截至 2022 年初,Keras 中对不规则张量的支持仍然相对较新,因此存在一些问题。例如,目前无法在 GPU 上运行时将不规则张量用作目标(但在您阅读这些内容时可能已解决)。
无论您喜欢哪种遮罩方法,在训练此模型几个时期后,它将变得非常擅长判断评论是积极的还是消极的。如果使用tf.keras.callbacks.TensorBoard()回调,您可以在 TensorBoard 中可视化嵌入,看到诸如“棒极了”和“惊人”的词逐渐聚集在嵌入空间的一侧,而诸如“糟糕”和“可怕”的词聚集在另一侧。有些词并不像您可能期望的那样积极(至少在这个模型中),比如“好”这个词,可能是因为许多负面评论包含短语“不好”。
重用预训练的嵌入和语言模型
令人印象深刻的是,这个模型能够基于仅有 25,000 条电影评论学习到有用的词嵌入。想象一下,如果我们有数十亿条评论来训练,这些嵌入会有多好!不幸的是,我们没有,但也许我们可以重用在其他(非常)大型文本语料库上训练的词嵌入(例如,亚马逊评论,可在 TensorFlow 数据集上找到)?毕竟,“amazing”这个词无论是用来谈论电影还是其他事物,通常都有相同的含义。此外,也许即使它们是在另一个任务上训练的,嵌入也对情感分析有用:因为“awesome”和“amazing”这样的词有相似的含义,它们很可能会在嵌入空间中聚集,即使是用于预测句子中的下一个词这样的任务。如果所有积极词和所有消极词形成簇,那么这对情感分析将是有帮助的。因此,我们可以不训练词嵌入,而是下载并使用预训练的嵌入,例如谷歌的Word2vec 嵌入,斯坦福的GloVe 嵌入,或 Facebook 的FastText 嵌入。
使用预训练词嵌入在几年内很受欢迎,但这种方法有其局限性。特别是,一个词无论上下文如何,都有一个表示。例如,“right”这个词在“left and right”和“right and wrong”中以相同的方式编码,尽管它们表示两个非常不同的含义。为了解决这个限制,Matthew Peters 在 2018 年引入了来自语言模型的嵌入(ELMo):这些是从深度双向语言模型的内部状态中学习到的上下文化词嵌入。与仅在模型中使用预训练嵌入不同,您可以重用预训练语言模型的一部分。
大约在同一时间,Jeremy Howard 和 Sebastian Ruder 的通用语言模型微调(ULMFiT)论文展示了无监督预训练在 NLP 任务中的有效性:作者们使用自监督学习(即从数据自动生成标签)在庞大的文本语料库上训练了一个 LSTM 语言模型,然后在各种任务上进行微调。他们的模型在六个文本分类任务上表现优异(在大多数情况下将错误率降低了 18-24%)。此外,作者们展示了一个仅使用 100 个标记示例进行微调的预训练模型可以达到与从头开始训练 10,000 个示例相同的性能。在 ULMFiT 论文之前,使用预训练模型只是计算机视觉中的常态;在 NLP 领域,预训练仅限于词嵌入。这篇论文标志着 NLP 的一个新时代的开始:如今,重用预训练语言模型已成为常态。
例如,让我们基于通用句子编码器构建一个分类器,这是由谷歌研究人员团队在 2018 年介绍的模型架构。这个模型基于 transformer 架构,我们将在本章后面讨论。方便的是,这个模型可以在 TensorFlow Hub 上找到。
import os
import tensorflow_hub as hubos.environ["TFHUB_CACHE_DIR"] = "my_tfhub_cache"
model = tf.keras.Sequential([hub.KerasLayer("https://tfhub.dev/google/universal-sentence-encoder/4",trainable=True, dtype=tf.string, input_shape=[]),tf.keras.layers.Dense(64, activation="relu"),tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="nadam",metrics=["accuracy"])
model.fit(train_set, validation_data=valid_set, epochs=10)
提示
这个模型非常庞大,接近 1GB 大小,因此下载可能需要一些时间。默认情况下,TensorFlow Hub 模块保存在临时目录中,并且每次运行程序时都会重新下载。为了避免这种情况,您必须将TFHUB_CACHE_DIR环境变量设置为您选择的目录:模块将保存在那里,只会下载一次。
请注意,TensorFlow Hub 模块 URL 的最后部分指定我们想要模型的第 4 个版本。这种版本控制确保如果 TF Hub 上发布了新的模块版本,它不会破坏我们的模型。方便的是,如果你只在 Web 浏览器中输入这个 URL,你将得到这个模块的文档。
还要注意,在创建hub.KerasLayer时,我们设置了trainable=True。这样,在训练期间,预训练的 Universal Sentence Encoder 会进行微调:通过反向传播调整一些权重。并非所有的 TensorFlow Hub 模块都是可微调的,所以确保查看你感兴趣的每个预训练模块的文档。
训练后,这个模型应该能达到超过 90%的验证准确率。这实际上非常好:如果你尝试自己执行这个任务,你可能只会稍微好一点,因为许多评论中既包含积极的评论,也包含消极的评论。对这些模棱两可的评论进行分类就像抛硬币一样。
到目前为止,我们已经看过使用 char-RNN 进行文本生成,以及使用基于可训练嵌入的单词级 RNN 模型进行情感分析,以及使用来自 TensorFlow Hub 的强大预训练语言模型。在接下来的部分中,我们将探索另一个重要的 NLP 任务:神经机器翻译(NMT)。
神经机器翻译的编码器-解码器网络
让我们从一个简单的NMT 模型开始,它将英语句子翻译成西班牙语(参见图 16-3)。
简而言之,架构如下:英语句子作为输入馈送给编码器,解码器输出西班牙语翻译。请注意,西班牙语翻译也在训练期间作为解码器的输入使用,但是向后移动了一步。换句话说,在训练期间,解码器被给予上一步应该输出的单词作为输入,而不管它实际输出了什么。这被称为“教师强迫”——一种显著加速训练并提高模型性能的技术。对于第一个单词,解码器被给予序列开始(SOS)标记,期望解码器以序列结束(EOS)标记结束句子。
每个单词最初由其 ID 表示(例如,单词“soccer”的 ID 为854)。接下来,一个Embedding层返回单词嵌入。然后这些单词嵌入被馈送给编码器和解码器。
在每一步中,解码器为输出词汇表(即西班牙语)中的每个单词输出一个分数,然后 softmax 激活函数将这些分数转换为概率。例如,在第一步中,“Me”这个词可能有 7%的概率,“Yo”可能有 1%的概率,依此类推。具有最高概率的单词被输出。这非常类似于常规的分类任务,事实上你可以使用"sparse_categorical_crossentropy"损失来训练模型,就像我们在 char-RNN 模型中所做的那样。

图 16-3。一个简单的机器翻译模型
请注意,在推断时(训练后),你将没有目标句子来馈送给解码器。相反,你需要将它刚刚输出的单词作为上一步的输入,如图 16-4 所示(这将需要一个在图中未显示的嵌入查找)。
提示
在一篇2015 年的论文,Samy Bengio 等人提出逐渐从在训练期间将前一个“目标”标记馈送给解码器转变为将前一个“输出”标记馈送给解码器。

图 16-4。在推断时,解码器作为输入接收它刚刚在上一个时间步输出的单词
让我们构建并训练这个模型!首先,我们需要下载一个英语/西班牙语句子对的数据集:
url = "https://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip"
path = tf.keras.utils.get_file("spa-eng.zip", origin=url, cache_dir="datasets",extract=True)
text = (Path(path).with_name("spa-eng") / "spa.txt").read_text()
每行包含一个英语句子和相应的西班牙语翻译,用制表符分隔。我们将从删除西班牙字符“¡”和“¿”开始,TextVectorization层无法处理这些字符,然后我们将解析句子对并对它们进行洗牌。最后,我们将它们分成两个单独的列表,每种语言一个:
import numpy as nptext = text.replace("¡", "").replace("¿", "")
pairs = [line.split("\t") for line in text.splitlines()]
np.random.shuffle(pairs)
sentences_en, sentences_es = zip(*pairs) # separates the pairs into 2 lists
让我们看一下前三个句子对:
>>> for i in range(3):
... print(sentences_en[i], "=>", sentences_es[i])
...
How boring! => Qué aburrimiento!
I love sports. => Adoro el deporte.
Would you like to swap jobs? => Te gustaría que intercambiemos los trabajos?
接下来,让我们创建两个TextVectorization层——每种语言一个,并对文本进行调整:
vocab_size = 1000
max_length = 50
text_vec_layer_en = tf.keras.layers.TextVectorization(vocab_size, output_sequence_length=max_length)
text_vec_layer_es = tf.keras.layers.TextVectorization(vocab_size, output_sequence_length=max_length)
text_vec_layer_en.adapt(sentences_en)
text_vec_layer_es.adapt([f"startofseq {s} endofseq" for s in sentences_es])
这里有几件事需要注意:
-
我们将词汇表大小限制为 1,000,这相当小。这是因为训练集不是很大,并且使用较小的值将加快训练速度。最先进的翻译模型通常使用更大的词汇表(例如 30,000),更大的训练集(几千兆字节)和更大的模型(数百甚至数千兆字节)。例如,查看赫尔辛基大学的 Opus-MT 模型,或 Facebook 的 M2M-100 模型。
-
由于数据集中的所有句子最多有 50 个单词,我们将
output_sequence_length设置为 50:这样输入序列将自动填充为零,直到它们都是 50 个标记长。如果训练集中有任何超过 50 个标记的句子,它将被裁剪为 50 个标记。 -
对于西班牙文本,我们在调整
TextVectorization层时为每个句子添加“startofseq”和“endofseq”:我们将使用这些词作为 SOS 和 EOS 标记。您可以使用任何其他单词,只要它们不是实际的西班牙单词。
让我们检查两种词汇表中的前 10 个标记。它们以填充标记、未知标记、SOS 和 EOS 标记(仅在西班牙语词汇表中)、然后按频率递减排序的实际单词开始:
>>> text_vec_layer_en.get_vocabulary()[:10]
['', '[UNK]', 'the', 'i', 'to', 'you', 'tom', 'a', 'is', 'he']
>>> text_vec_layer_es.get_vocabulary()[:10]
['', '[UNK]', 'startofseq', 'endofseq', 'de', 'que', 'a', 'no', 'tom', 'la']
接下来,让我们创建训练集和验证集(如果需要,您也可以创建一个测试集)。我们将使用前 100,000 个句子对进行训练,其余用于验证。解码器的输入是西班牙语句子加上一个 SOS 标记前缀。目标是西班牙语句子加上一个 EOS 后缀:
X_train = tf.constant(sentences_en[:100_000])
X_valid = tf.constant(sentences_en[100_000:])
X_train_dec = tf.constant([f"startofseq {s}" for s in sentences_es[:100_000]])
X_valid_dec = tf.constant([f"startofseq {s}" for s in sentences_es[100_000:]])
Y_train = text_vec_layer_es([f"{s} endofseq" for s in sentences_es[:100_000]])
Y_valid = text_vec_layer_es([f"{s} endofseq" for s in sentences_es[100_000:]])
好的,现在我们准备构建我们的翻译模型。我们将使用功能 API,因为模型不是顺序的。它需要两个文本输入——一个用于编码器,一个用于解码器——所以让我们从这里开始:
encoder_inputs = tf.keras.layers.Input(shape=[], dtype=tf.string)
decoder_inputs = tf.keras.layers.Input(shape=[], dtype=tf.string)
接下来,我们需要使用我们之前准备的TextVectorization层对这些句子进行编码,然后为每种语言使用一个Embedding层,其中mask_zero=True以确保自动处理掩码。嵌入大小是一个您可以调整的超参数,像往常一样:
embed_size = 128
encoder_input_ids = text_vec_layer_en(encoder_inputs)
decoder_input_ids = text_vec_layer_es(decoder_inputs)
encoder_embedding_layer = tf.keras.layers.Embedding(vocab_size, embed_size,mask_zero=True)
decoder_embedding_layer = tf.keras.layers.Embedding(vocab_size, embed_size,mask_zero=True)
encoder_embeddings = encoder_embedding_layer(encoder_input_ids)
decoder_embeddings = decoder_embedding_layer(decoder_input_ids)
提示
当语言共享许多单词时,您可能会获得更好的性能,使用相同的嵌入层用于编码器和解码器。
现在让我们创建编码器并传递嵌入输入:
encoder = tf.keras.layers.LSTM(512, return_state=True)
encoder_outputs, *encoder_state = encoder(encoder_embeddings)
为了保持简单,我们只使用了一个LSTM层,但您可以堆叠几个。我们还设置了return_state=True以获得对层最终状态的引用。由于我们使用了一个LSTM层,实际上有两个状态:短期状态和长期状态。该层分别返回这些状态,这就是为什么我们必须写*encoder_state来将两个状态分组在一个列表中。现在我们可以使用这个(双重)状态作为解码器的初始状态:
decoder = tf.keras.layers.LSTM(512, return_sequences=True)
decoder_outputs = decoder(decoder_embeddings, initial_state=encoder_state)
接下来,我们可以通过具有 softmax 激活函数的Dense层将解码器的输出传递,以获得每个步骤的单词概率:
output_layer = tf.keras.layers.Dense(vocab_size, activation="softmax")
Y_proba = output_layer(decoder_outputs)
就是这样!我们只需要创建 KerasModel,编译它并训练它:
model = tf.keras.Model(inputs=[encoder_inputs, decoder_inputs],outputs=[Y_proba])
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam",metrics=["accuracy"])
model.fit((X_train, X_train_dec), Y_train, epochs=10,validation_data=((X_valid, X_valid_dec), Y_valid))
训练后,我们可以使用该模型将新的英语句子翻译成西班牙语。但这并不像调用model.predict()那样简单,因为解码器期望的输入是上一个时间步预测的单词。一种方法是编写一个自定义记忆单元,跟踪先前的输出并在下一个时间步将其馈送给编码器。但为了保持简单,我们可以多次调用模型,每轮预测一个额外的单词。让我们为此编写一个小型实用程序函数:
def translate(sentence_en):translation = ""for word_idx in range(max_length):X = np.array([sentence_en]) # encoder inputX_dec = np.array(["startofseq " + translation]) # decoder inputy_proba = model.predict((X, X_dec))[0, word_idx] # last token's probaspredicted_word_id = np.argmax(y_proba)predicted_word = text_vec_layer_es.get_vocabulary()[predicted_word_id]if predicted_word == "endofseq":breaktranslation += " " + predicted_wordreturn translation.strip()
该函数只是逐步预测一个单词,逐渐完成翻译,并在达到 EOS 标记时停止。让我们试试看!
>>> translate("I like soccer")
'me gusta el fútbol'
万岁,它起作用了!嗯,至少对于非常短的句子是这样。如果您尝试使用这个模型一段时间,您会发现它还不是双语的,特别是在处理更长的句子时会遇到困难。例如:
>>> translate("I like soccer and also going to the beach")
'me gusta el fútbol y a veces mismo al bus'
翻译说:“我喜欢足球,有时甚至喜欢公共汽车”。那么你如何改进呢?一种方法是增加训练集的大小,并在编码器和解码器中添加更多的LSTM层。但这只能让你走得更远,所以让我们看看更复杂的技术,从双向循环层开始。
双向 RNN
在每个时间步骤,常规循环层在生成输出之前只查看过去和现在的输入。换句话说,它是因果的,这意味着它不能预测未来。这种类型的 RNN 在预测时间序列时或在序列到序列(seq2seq)模型的解码器中是有意义的。但对于文本分类等任务,或者在 seq2seq 模型的编码器中,通常最好在编码给定单词之前查看下一个单词。
例如,考虑短语“右臂”,“正确的人”和“批评的权利”:要正确编码单词“right”,您需要向前查看。一个解决方案是在相同的输入上运行两个循环层,一个从左到右读取单词,另一个从右到左读取单词,然后在每个时间步骤组合它们的输出,通常通过连接它们。这就是双向循环层的作用(参见图 16-5)。

图 16-5. 双向循环层
在 Keras 中实现双向循环层,只需将循环层包装在tf.keras.layers.Bidirectional层中。例如,以下Bidirectional层可以用作我们翻译模型中的编码器:
encoder = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(256, return_state=True))
注意
Bidirectional层将创建GRU层的克隆(但是在相反方向),并且将同时运行并连接它们的输出。因此,尽管GRU层有 10 个单元,Bidirectional层将在每个时间步输出 20 个值。
只有一个问题。这一层现在将返回四个状态而不是两个:前向LSTM层的最终短期和长期状态,以及后向LSTM层的最终短期和长期状态。我们不能直接将这个四重状态用作解码器的LSTM层的初始状态,因为它只期望两个状态(短期和长期)。我们不能使解码器双向,因为它必须保持因果关系:否则在训练过程中会作弊,而且不起作用。相反,我们可以连接两个短期状态,并连接两个长期状态:
encoder_outputs, *encoder_state = encoder(encoder_embeddings)
encoder_state = [tf.concat(encoder_state[::2], axis=-1), # short-term (0 & 2)tf.concat(encoder_state[1::2], axis=-1)] # long-term (1 & 3)
现在让我们看看另一种在推理时可以极大提高翻译模型性能的流行技术:束搜索。
束搜索
假设您已经训练了一个编码器-解码器模型,并且您使用它将句子“I like soccer”翻译成西班牙语。您希望它会输出正确的翻译“me gusta el fútbol”,但不幸的是它输出了“me gustan los jugadores”,意思是“我喜欢球员”。看着训练集,您注意到许多句子如“I like cars”,翻译成“me gustan los autos”,所以模型在看到“I like”后输出“me gustan los”并不荒谬。不幸的是,在这种情况下是一个错误,因为“soccer”是单数。模型无法回头修正,所以它尽力完成句子,这种情况下使用了“jugadores”这个词。我们如何让模型有机会回头修正之前的错误呢?最常见的解决方案之一是beam search:它跟踪一个最有希望的句子列表(比如说前三个),在每个解码器步骤中尝试扩展它们一个词,只保留* k 个最有可能的句子。参数k被称为beam width*。
例如,假设您使用模型来翻译句子“I like soccer”,使用 beam search 和 beam width 为 3(参见图 16-6)。在第一个解码器步骤中,模型将为翻译句子中每个可能的第一个词输出一个估计概率。假设前三个词是“me”(75%的估计概率),“a”(3%)和“como”(1%)。这是我们目前的短列表。接下来,我们使用模型为每个句子找到下一个词。对于第一个句子(“me”),也许模型为“gustan”这个词输出 36%的概率,“gusta”这个词输出 32%的概率,“encanta”这个词输出 16%的概率,依此类推。请注意,这些实际上是条件概率,假设句子以“me”开头。对于第二个句子(“a”),模型可能为“mi”这个词输出 50%的条件概率,依此类推。假设词汇表有 1,000 个词,我们将得到每个句子 1,000 个概率。
接下来,我们计算我们考虑的 3,000 个两个词的句子的概率(3 × 1,000)。我们通过将每个词的估计条件概率乘以它完成的句子的估计概率来做到这一点。例如,“me”的句子的估计概率为 75%,而“gustan”这个词的估计条件概率(假设第一个词是“me”)为 36%,所以“me gustan”的估计概率为 75% × 36% = 27%。在计算了所有 3,000 个两个词的句子的概率之后,我们只保留前 3 个。在这个例子中,它们都以“me”开头:“me gustan”(27%),“me gusta”(24%)和“me encanta”(12%)。目前,“me gustan”这个句子领先,但“me gusta”还没有被淘汰。

图 16-6。beam search,beam width 为 3
然后我们重复相同的过程:我们使用模型预测这三个句子中的下一个词,并计算我们考虑的所有 3,000 个三个词的句子的概率。也许现在前三个是“me gustan los”(10%),“me gusta el”(8%)和“me gusta mucho”(2%)。在下一步中,我们可能得到“me gusta el fútbol”(6%),“me gusta mucho el”(1%)和“me gusta el deporte”(0.2%)。请注意,“me gustan”已经被淘汰,正确的翻译现在领先。我们在没有额外训练的情况下提高了我们的编码器-解码器模型的性能,只是更明智地使用它。
提示
TensorFlow Addons 库包含一个完整的 seq2seq API,让您可以构建带有注意力的编码器-解码器模型,包括 beam search 等等。然而,它的文档目前非常有限。实现 beam search 是一个很好的练习,所以试一试吧!查看本章的笔记本,了解可能的解决方案。
通过这一切,您可以为相当短的句子获得相当不错的翻译。不幸的是,这种模型在翻译长句子时会表现得非常糟糕。问题再次出在 RNN 的有限短期记忆上。注意力机制是解决这个问题的划时代创新。
注意力机制
考虑一下从单词“soccer”到其翻译“fútbol”的路径,回到图 16-3:这是相当长的!这意味着这个单词的表示(以及所有其他单词)需要在实际使用之前经过许多步骤。我们难道不能让这条路径变短一点吗?
这是 Dzmitry Bahdanau 等人在一篇具有里程碑意义的2014 年论文中的核心思想,作者在其中介绍了一种技术,允许解码器在每个时间步关注适当的单词(由编码器编码)。例如,在解码器需要输出单词“fútbol”的时间步,它将把注意力集中在单词“soccer”上。这意味着从输入单词到其翻译的路径现在要短得多,因此 RNN 的短期记忆限制对其影响要小得多。注意机制彻底改变了神经机器翻译(以及深度学习一般)的方式,显著改进了技术水平,特别是对于长句子(例如,超过 30 个单词)。
注意
NMT 中最常用的度量标准是双语评估助手(BLEU)分数,它将模型产生的每个翻译与人类产生的几个好翻译进行比较:它计算出现在任何目标翻译中的n-gram(n个单词序列)的数量,并调整分数以考虑在目标翻译中产生的n-gram 的频率。
图 16-7 展示了我们带有注意力机制的编码器-解码器模型。在左侧,您可以看到编码器和解码器。现在,我们不仅在每一步将编码器的最终隐藏状态和前一个目标单词发送给解码器(尽管这仍在进行,但在图中没有显示),还将所有编码器的输出发送给解码器。由于解码器无法一次处理所有这些编码器的输出,因此它们需要被聚合:在每个时间步,解码器的记忆单元计算所有编码器输出的加权和。这决定了它在这一步将关注哪些单词。权重α[(t,i)]是第t个解码器时间步的第i个编码器输出的权重。例如,如果权重α[(3,2)]远大于权重α[(3,0)]和α[(3,1)],那么解码器将在这个时间步更多地关注第 2 个单词(“soccer”)的编码器输出,而不是其他两个输出。解码器的其余部分与之前的工作方式相同:在每个时间步,记忆单元接收我们刚刚讨论的输入,以及来自上一个时间步的隐藏状态,最后(尽管在图中没有表示)它接收来自上一个时间步的目标单词(或在推断时,来自上一个时间步的输出)。

图 16-7。使用带有注意力模型的编码器-解码器网络的神经机器翻译
但是这些α[(t,i)]权重是从哪里来的呢?嗯,它们是由一个称为对齐模型(或注意力层)的小型神经网络生成的,该模型与其余的编码器-解码器模型一起进行训练。这个对齐模型在图 16-7 的右侧进行了说明。它以一个由单个神经元组成的Dense层开始,处理每个编码器的输出,以及解码器的先前隐藏状态(例如h[(2)])。这一层为每个编码器输出(例如e[(3,] [2)])输出一个分数(或能量):这个分数衡量每个输出与解码器先前隐藏状态的对齐程度。例如,在图 16-7 中,模型已经输出了“me gusta el”(意思是“我喜欢”),所以现在期望一个名词:单词“soccer”是与当前状态最匹配的,所以它得到了一个高分。最后,所有分数都通过 softmax 层,以获得每个编码器输出的最终权重(例如α[(3,2)])。给定解码器时间步的所有权重加起来等于 1。这种特定的注意力机制被称为Bahdanau 注意力(以 2014 年论文的第一作者命名)。由于它将编码器输出与解码器的先前隐藏状态连接起来,因此有时被称为连接注意力(或加性注意力)。
注意
如果输入句子有n个单词,并假设输出句子长度大致相同,那么这个模型将需要计算大约n²个权重。幸运的是,这种二次计算复杂度仍然可行,因为即使是长句子也不会有成千上万个单词。
另一个常见的注意力机制,称为Luong 注意力或乘法注意力,是在2015 年提出的,由 Minh-Thang Luong 等人提出¹⁹。因为对齐模型的目标是衡量编码器输出和解码器先前隐藏状态之间的相似性,作者建议简单地计算这两个向量的点积(参见第四章),因为这通常是一个相当好的相似性度量,而现代硬件可以非常高效地计算它。为了实现这一点,两个向量必须具有相同的维度。点积给出一个分数,所有分数(在给定的解码器时间步长上)都通过 softmax 层,以给出最终的权重,就像 Bahdanau 注意力中一样。Luong 等人提出的另一个简化是使用当前时间步的解码器隐藏状态,而不是上一个时间步(即h[(t)]而不是h[(t–1)]),然后直接使用注意力机制的输出(标记为h~(t))来计算解码器的预测,而不是用它来计算解码器当前的隐藏状态。研究人员还提出了一种点积机制的变体,其中编码器输出首先经过一个全连接层(没有偏置项),然后再计算点积。这被称为“一般”点积方法。研究人员将两种点积方法与连接注意力机制(添加一个重新缩放参数向量v)进行了比较,他们观察到点积变体的性能优于连接注意力。因此,连接注意力现在使用较少。这三种注意力机制的方程式总结在方程式 16-1 中。
方程式 16-1。注意力机制
h~(t)=∑iα(t,i)y(i) with α(t,i)=expe(t,i)∑i‘expe(t,i’) and e(t,i)=h(t)⊺y(i)doth(t)⊺Wy(i)generalv⊺tanh(W[h(t);y(i)])concat
Keras 为 Luong attention 提供了tf.keras.layers.Attention层,为 Bahdanau attention 提供了AdditiveAttention层。让我们将 Luong attention 添加到我们的编码器-解码器模型中。由于我们需要将所有编码器的输出传递给Attention层,所以在创建编码器时,我们首先需要设置return_sequences=True:
encoder = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(256, return_sequences=True, return_state=True))
接下来,我们需要创建注意力层,并将解码器的状态和编码器的输出传递给它。然而,为了在每一步访问解码器的状态,我们需要编写一个自定义的记忆单元。为简单起见,让我们使用解码器的输出而不是其状态:实际上这也很有效,并且编码更容易。然后我们直接将注意力层的输出传递给输出层,就像 Luong 注意力论文中建议的那样:
attention_layer = tf.keras.layers.Attention()
attention_outputs = attention_layer([decoder_outputs, encoder_outputs])
output_layer = tf.keras.layers.Dense(vocab_size, activation="softmax")
Y_proba = output_layer(attention_outputs)
就是这样!如果训练这个模型,你会发现它现在可以处理更长的句子。例如:
>>> translate("I like soccer and also going to the beach")
'me gusta el fútbol y también ir a la playa'
简而言之,注意力层提供了一种让模型集中注意力于输入的一部分的方法。但是还有另一种方式来思考这个层:它充当了一个可微分的记忆检索机制。
例如,假设编码器分析了输入句子“I like soccer”,并且成功理解了单词“I”是主语,单词“like”是动词,因此在这些单词的输出中编码了这些信息。现在假设解码器已经翻译了主语,并且认为接下来应该翻译动词。为此,它需要从输入句子中提取动词。这类似于字典查找:就好像编码器创建了一个字典{“subject”: “They”, “verb”: “played”, …},解码器想要查找与键“verb”对应的值。
然而,模型没有离散的令牌来表示键(如“主语”或“动词”);相反,它具有这些概念的矢量化表示,这些表示在训练期间学习到,因此用于查找的查询不会完全匹配字典中的任何键。解决方案是计算查询与字典中每个键之间的相似度度量,然后使用 softmax 函数将这些相似度分数转换为总和为 1 的权重。正如我们之前看到的那样,这正是注意力层所做的。如果代表动词的键与查询最相似,那么该键的权重将接近 1。
接下来,注意力层计算相应值的加权和:如果“动词”键的权重接近 1,那么加权和将非常接近单词“played”的表示。
这就是为什么 Keras 的Attention和AdditiveAttention层都期望输入一个包含两个或三个项目的列表:queries,keys,以及可选的values。如果不传递任何值,则它们会自动等于键。因此,再次查看前面的代码示例,解码器输出是查询,编码器输出既是键也是值。对于每个解码器输出(即每个查询),注意力层返回与解码器输出最相似的编码器输出(即键/值)的加权和。
关键是,注意力机制是一个可训练的内存检索系统。它非常强大,以至于您实际上可以仅使用注意力机制构建最先进的模型。进入Transformer架构。
注意力就是你所需要的:原始Transformer架构
在一篇开创性的2017 年论文,²⁰一组谷歌研究人员建议“注意力就是你所需要的”。他们创建了一种称为Transformer的架构,显著改进了 NMT 的最新技术,而不使用任何循环或卷积层,仅使用注意力机制(加上嵌入层、稠密层、归一化层和其他一些部分)。由于该模型不是循环的,所以不像 RNN 那样容易受到梯度消失或梯度爆炸问题的困扰,可以在较少的步骤中训练,更容易在多个 GPU 上并行化,并且可以比 RNN 更好地捕捉长距离模式。原始的 2017 年Transformer架构在图 16-8 中表示。
简而言之,图 16-8 的左侧是编码器,右侧是解码器。每个嵌入层输出一个形状为[批量大小,序列长度,嵌入大小]的 3D 张量。之后,随着数据流经Transformer,张量逐渐转换,但形状保持不变。
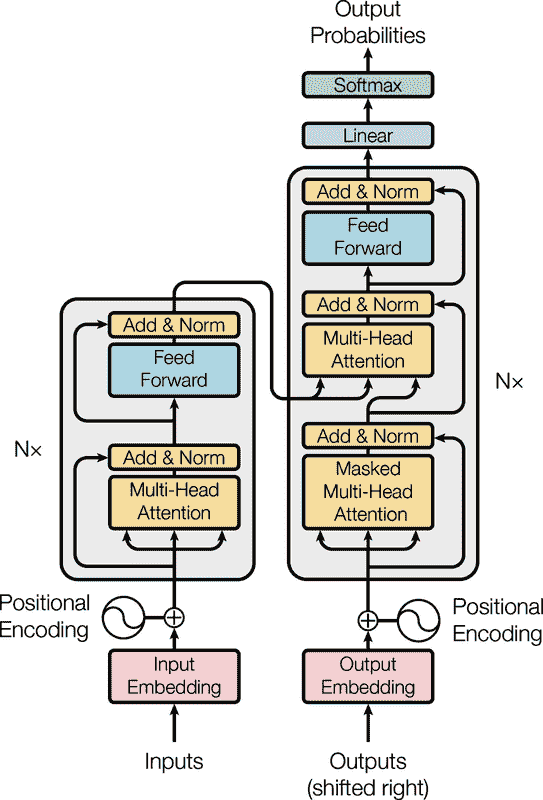
图 16-8。原始的 2017 年Transformer架构²²
如果您将Transformer用于 NMT,则在训练期间必须将英语句子馈送给编码器,将相应的西班牙语翻译馈送给解码器,并在每个句子开头插入额外的 SOS 令牌。在推理时,您必须多次调用Transformer,逐字产生翻译,并在每轮将部分翻译馈送给解码器,就像我们之前在translate()函数中所做的那样。
编码器的作用是逐渐转换输入——英文句子的单词表示——直到每个单词的表示完美地捕捉到单词的含义,在句子的上下文中。例如,如果你用句子“I like soccer”来喂给编码器,那么单词“like”将以一个相当模糊的表示开始,因为这个单词在不同的上下文中可能有不同的含义:想想“I like soccer”和“It’s like that”。但是经过编码器后,单词的表示应该捕捉到给定句子中“like”的正确含义(即喜欢),以及可能需要用于翻译的任何其他信息(例如,它是一个动词)。
解码器的作用是逐渐将翻译句子中的每个单词表示转换为翻译中下一个单词的单词表示。例如,如果要翻译的句子是“I like soccer”,解码器的输入句子是“ me gusta el fútbol”,那么经过解码器后,“el”的单词表示将最终转换为“fútbol”的表示。同样,“fútbol”的表示将被转换为 EOS 标记的表示。
经过解码器后,每个单词表示都经过一个带有 softmax 激活函数的最终Dense层,希望能够输出正确下一个单词的高概率和所有其他单词的低概率。预测的句子应该是“me gusta el fútbol ”。
那是大局观;现在让我们更详细地走一遍图 16-8:
-
首先,注意到编码器和解码器都包含被堆叠N次的模块。在论文中,N = 6。整个编码器堆栈的最终输出在每个这些N级别上被馈送到解码器。
-
放大一下,你会发现你已经熟悉大部分组件:有两个嵌入层;几个跳跃连接,每个连接后面跟着一个层归一化层;几个由两个密集层组成的前馈模块(第一个使用 ReLU 激活函数,第二个没有激活函数);最后输出层是使用 softmax 激活函数的密集层。如果需要的话,你也可以在注意力层和前馈模块之后添加一点 dropout。由于所有这些层都是时间分布的,每个单词都独立于其他所有单词。但是我们如何通过完全分开地查看单词来翻译句子呢?嗯,我们不能,这就是新组件发挥作用的地方:
-
编码器的多头注意力层通过关注同一句子中的所有其他单词来更新每个单词的表示。这就是单词“like”的模糊表示变得更丰富和更准确的表示的地方,捕捉了它在给定句子中的确切含义。我们将很快讨论这是如何工作的。
-
解码器的掩码多头注意力层做同样的事情,但当处理一个单词时,它不会关注在它之后的单词:这是一个因果层。例如,当处理单词“gusta”时,它只会关注“ me gusta”这几个单词,而忽略“el fútbol”这几个单词(否则那就是作弊了)。
-
解码器的上层多头注意力层是解码器关注英文句子中的单词的地方。这被称为交叉注意力,在这种情况下不是自我注意力。例如,当解码器处理单词“el”并将其表示转换为“fútbol”的表示时,解码器可能会密切关注单词“soccer”。
-
位置编码是密集向量(类似于单词嵌入),表示句子中每个单词的位置。第n个位置编码被添加到每个句子中第n个单词的单词嵌入中。这是因为Transformer架构中的所有层都忽略单词位置:没有位置编码,您可以对输入序列进行洗牌,它只会以相同方式洗牌输出序列。显然,单词的顺序很重要,这就是为什么我们需要以某种方式向Transformer提供位置信息的原因:将位置编码添加到单词表示是实现这一点的好方法。
-
注意
图 16-8 中每个多头注意力层的前两个箭头代表键和值,第三个箭头代表查询。在自注意力层中,所有三个都等于前一层输出的单词表示,而在解码器的上层注意力层中,键和值等于编码器的最终单词表示,查询等于前一层输出的单词表示。
让我们更详细地了解Transformer架构中的新颖组件,从位置编码开始。
位置编码
位置编码是一个密集向量,用于编码句子中单词的位置:第i个位置编码被添加到句子中第i个单词的单词嵌入中。实现这一点的最简单方法是使用Embedding层,并使其对批处理中从 0 到最大序列长度的所有位置进行编码,然后将结果添加到单词嵌入中。广播规则将确保位置编码应用于每个输入序列。例如,以下是如何将位置编码添加到编码器和解码器输入的方法:
max_length = 50 # max length in the whole training set
embed_size = 128
pos_embed_layer = tf.keras.layers.Embedding(max_length, embed_size)
batch_max_len_enc = tf.shape(encoder_embeddings)[1]
encoder_in = encoder_embeddings + pos_embed_layer(tf.range(batch_max_len_enc))
batch_max_len_dec = tf.shape(decoder_embeddings)[1]
decoder_in = decoder_embeddings + pos_embed_layer(tf.range(batch_max_len_dec))
请注意,此实现假定嵌入表示为常规张量,而不是不规则张量。²³ 编码器和解码器共享相同的Embedding层用于位置编码,因为它们具有相同的嵌入大小(这通常是这种情况)。
Transformer论文的作者选择使用基于正弦和余弦函数在不同频率下的固定位置编码,而不是使用可训练的位置编码。位置编码矩阵P在方程 16-2 中定义,并在图 16-9 的顶部(转置)表示,其中P[p,i]是句子中位于第p位置的单词的编码的第i个分量。
方程 16-2。正弦/余弦位置编码
Pp,i=sin(p/10000i/d)如果i是偶数cos(p/10000(i-1)/d)如果i是奇数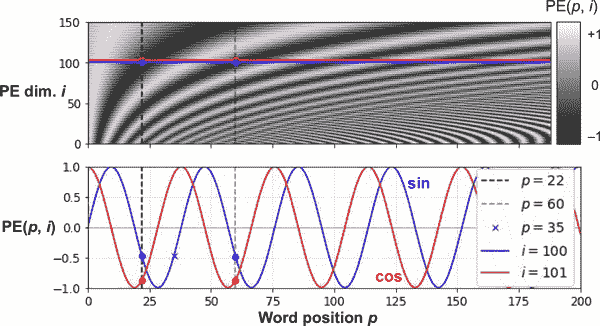
图 16-9。正弦/余弦位置编码矩阵(转置,顶部)关注两个i值(底部)
这个解决方案可以提供与可训练位置编码相同的性能,并且可以扩展到任意长的句子,而不需要向模型添加任何参数(然而,当有大量预训练数据时,通常会优先选择可训练位置编码)。在这些位置编码添加到单词嵌入之后,模型的其余部分可以访问句子中每个单词的绝对位置,因为每个位置都有一个唯一的位置编码(例如,句子中位于第 22 个位置的单词的位置编码由图 16-9 左上角的垂直虚线表示,您可以看到它是唯一的)。此外,选择振荡函数(正弦和余弦)使模型能够学习相对位置。例如,相距 38 个单词的单词(例如,在位置p=22 和p=60 处)在编码维度i=100 和i=101 中始终具有相同的位置编码值,如图 16-9 所示。这解释了为什么我们需要每个频率的正弦和余弦:如果我们只使用正弦(i=100 处的蓝色波),模型将无法区分位置p=22 和p=35(由十字标记)。
在 TensorFlow 中没有PositionalEncoding层,但创建一个并不太困难。出于效率原因,我们在构造函数中预先计算位置编码矩阵。call()方法只是将这个编码矩阵截断到输入序列的最大长度,并将其添加到输入中。我们还设置supports_masking=True以将输入的自动掩码传播到下一层:
class PositionalEncoding(tf.keras.layers.Layer):def __init__(self, max_length, embed_size, dtype=tf.float32, **kwargs):super().__init__(dtype=dtype, **kwargs)assert embed_size % 2 == 0, "embed_size must be even"p, i = np.meshgrid(np.arange(max_length),2 * np.arange(embed_size // 2))pos_emb = np.empty((1, max_length, embed_size))pos_emb[0, :, ::2] = np.sin(p / 10_000 ** (i / embed_size)).Tpos_emb[0, :, 1::2] = np.cos(p / 10_000 ** (i / embed_size)).Tself.pos_encodings = tf.constant(pos_emb.astype(self.dtype))self.supports_masking = Truedef call(self, inputs):batch_max_length = tf.shape(inputs)[1]return inputs + self.pos_encodings[:, :batch_max_length]
让我们使用这个层将位置编码添加到编码器的输入中:
pos_embed_layer = PositionalEncoding(max_length, embed_size)
encoder_in = pos_embed_layer(encoder_embeddings)
decoder_in = pos_embed_layer(decoder_embeddings)
现在让我们更深入地看一下Transformer模型的核心,即多头注意力层。
多头注意力
要理解多头注意力层的工作原理,我们首先必须了解它基于的缩放点积注意力层。它的方程式在方程式 16-3 中以矢量化形式显示。它与 Luong 注意力相同,只是有一个缩放因子。
方程式 16-3. 缩放点积注意力
注意力(Q,K,V)=softmaxQK⊺<mi d<mi k<mi e<mi y<mi sV
在这个方程中:
-
Q是包含每个查询的一行的矩阵。其形状为[n[queries], d[keys]],其中n[queries]是查询的数量,d[keys]是每个查询和每个键的维度数量。
-
K是包含每个键的一行的矩阵。其形状为[n[keys], d[keys]],其中n[keys]是键和值的数量。
-
V是包含每个值的一行的矩阵。其形状为[n[keys], d[values]],其中d[values]是每个值的维度数量。
-
Q K^⊺的形状为[n[queries], n[keys]]:它包含每个查询/键对的一个相似度分数。为了防止这个矩阵过大,输入序列不能太长(我们将在本章后面讨论如何克服这个限制)。softmax 函数的输出具有相同的形状,但所有行的总和为 1。最终输出的形状为[n[queries], d[values]]:每个查询有一行,其中每行代表查询结果(值的加权和)。
-
缩放因子 1 / (<mi d <mi keys)将相似度分数缩小,以避免饱和 softmax 函数,这会导致梯度很小。
-
可以通过在计算 softmax 之前,向相应的相似性分数添加一个非常大的负值来屏蔽一些键/值对,这在掩码多头注意力层中非常有用。
如果在创建tf.keras.layers.Attention层时设置use_scale=True,那么它将创建一个额外的参数,让该层学习如何正确地降低相似性分数。Transformer模型中使用的缩放后的点积注意力几乎相同,只是它总是将相似性分数按相同因子缩放,即 1 / (d keys)。
请注意,Attention层的输入就像Q、K和V一样,只是多了一个批处理维度(第一个维度)。在内部,该层仅通过一次调用tf.matmul(queries, keys)计算批处理中所有句子的所有注意力分数:这使得它非常高效。实际上,在 TensorFlow 中,如果A和B是具有两个以上维度的张量,比如形状为[2, 3, 4, 5]和[2, 3, 5, 6],那么tf.matmul(A, B)将把这些张量视为 2×3 数组,其中每个单元格包含一个矩阵,并将相应的矩阵相乘:A中第i行和第j列的矩阵将与B中第i行和第j列的矩阵相乘。由于一个 4×5 矩阵与一个 5×6 矩阵的乘积是一个 4×6 矩阵,tf.matmul(A, B)将返回一个形状为[2, 3, 4, 6]的数组。
现在我们准备看一下多头注意力层。其架构如图 16-10 所示。
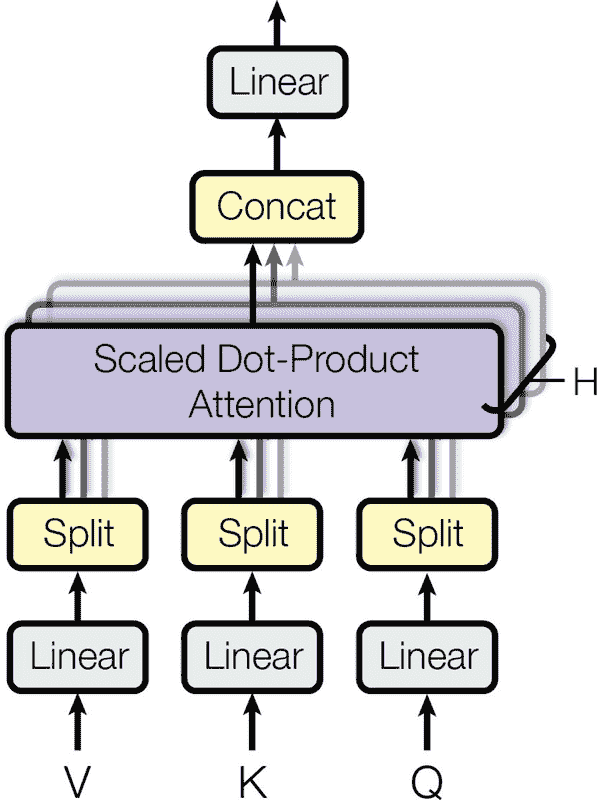
图 16-10. 多头注意力层架构
正如您所看到的,它只是一堆缩放后的点积注意力层,每个层之前都有一个值、键和查询的线性变换(即没有激活函数的时间分布密集层)。所有输出都简单地连接在一起,并通过最终的线性变换(再次是时间分布的)。
但是为什么?这种架构背后的直觉是什么?好吧,再次考虑一下句子“I like soccer”中的单词“like”。编码器足够聪明,能够编码它是一个动词的事实。但是单词表示还包括其在文本中的位置,这要归功于位置编码,它可能还包括许多其他对其翻译有用的特征,比如它是现在时。简而言之,单词表示编码了单词的许多不同特征。如果我们只使用一个缩放后的点积注意力层,我们只能一次性查询所有这些特征。
这就是为什么多头注意力层应用多个不同的线性变换值、键和查询:这使得模型能够将单词表示的许多不同特征投影到不同的子空间中,每个子空间都专注于单词的某些特征。也许其中一个线性层将单词表示投影到一个只剩下单词是动词信息的子空间,另一个线性层将提取出它是现在时的事实,依此类推。然后缩放后的点积注意力层实现查找阶段,最后我们将所有结果连接起来并将它们投影回原始空间。
Keras 包括一个tf.keras.layers.MultiHeadAttention层,因此我们现在拥有构建Transformer其余部分所需的一切。让我们从完整的编码器开始,它与图 16-8 中的完全相同,只是我们使用两个块的堆叠(N = 2)而不是六个,因为我们没有一个庞大的训练集,并且我们还添加了一点辍学:
N = 2 # instead of 6
num_heads = 8
dropout_rate = 0.1
n_units = 128 # for the first dense layer in each feedforward block
encoder_pad_mask = tf.math.not_equal(encoder_input_ids, 0)[:, tf.newaxis]
Z = encoder_in
for _ in range(N):skip = Zattn_layer = tf.keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate)Z = attn_layer(Z, value=Z, attention_mask=encoder_pad_mask)Z = tf.keras.layers.LayerNormalization()(tf.keras.layers.Add()([Z, skip]))skip = ZZ = tf.keras.layers.Dense(n_units, activation="relu")(Z)Z = tf.keras.layers.Dense(embed_size)(Z)Z = tf.keras.layers.Dropout(dropout_rate)(Z)Z = tf.keras.layers.LayerNormalization()(tf.keras.layers.Add()([Z, skip]))
这段代码应该大多数都很简单,除了一个问题:掩码。在撰写本文时,MultiHeadAttention层不支持自动掩码,因此我们必须手动处理。我们该如何做?
MultiHeadAttention层接受一个attention_mask参数,这是一个形状为[batch size, max query length, max value length]的布尔张量:对于每个查询序列中的每个标记,这个掩码指示应该关注对应值序列中的哪些标记。我们想告诉MultiHeadAttention层忽略值中的所有填充标记。因此,我们首先使用tf.math.not_equal(encoder_input_ids, 0)计算填充掩码。这将返回一个形状为[batch size, max sequence length]的布尔张量。然后我们使用[:, tf.newaxis]插入第二个轴,得到形状为[batch size, 1, max sequence length]的掩码。这使我们能够在调用MultiHeadAttention层时将此掩码用作attention_mask:由于广播,相同的掩码将用于每个查询中的所有标记。这样,值中的填充标记将被正确忽略。
然而,该层将为每个单独的查询标记计算输出,包括填充标记。我们需要掩盖与这些填充标记对应的输出。回想一下,在Embedding层中我们使用了mask_zero,并且在PositionalEncoding层中我们将supports_masking设置为True,因此自动掩码一直传播到MultiHeadAttention层的输入(encoder_in)。我们可以利用这一点在跳过连接中:实际上,Add层支持自动掩码,因此当我们将Z和skip(最初等于encoder_in)相加时,输出将自动正确掩码。天啊!掩码需要比代码更多的解释。
现在开始解码器!再次,掩码将是唯一棘手的部分,所以让我们从那里开始。第一个多头注意力层是一个自注意力层,就像在编码器中一样,但它是一个掩码多头注意力层,这意味着它是因果的:它应该忽略未来的所有标记。因此,我们需要两个掩码:一个填充掩码和一个因果掩码。让我们创建它们:
decoder_pad_mask = tf.math.not_equal(decoder_input_ids, 0)[:, tf.newaxis]
causal_mask = tf.linalg.band_part( # creates a lower triangular matrixtf.ones((batch_max_len_dec, batch_max_len_dec), tf.bool), -1, 0)
填充掩码与我们为编码器创建的掩码完全相同,只是基于解码器的输入而不是编码器的。因果掩码使用tf.linalg.band_part()函数创建,该函数接受一个张量并返回一个将对角线带外的所有值设置为零的副本。通过这些参数,我们得到一个大小为batch_max_len_dec(批处理中输入序列的最大长度)的方阵,左下三角形中为 1,右上角为 0。如果我们将此掩码用作注意力掩码,我们将得到我们想要的:第一个查询标记只会关注第一个值标记,第二个只会关注前两个,第三个只会关注前三个,依此类推。换句话说,查询标记不能关注未来的任何值标记。
现在让我们构建解码器:
encoder_outputs = Z # let's save the encoder's final outputs
Z = decoder_in # the decoder starts with its own inputs
for _ in range(N):skip = Zattn_layer = tf.keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate)Z = attn_layer(Z, value=Z, attention_mask=causal_mask & decoder_pad_mask)Z = tf.keras.layers.LayerNormalization()(tf.keras.layers.Add()([Z, skip]))skip = Zattn_layer = tf.keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate)Z = attn_layer(Z, value=encoder_outputs, attention_mask=encoder_pad_mask)Z = tf.keras.layers.LayerNormalization()(tf.keras.layers.Add()([Z, skip]))skip = ZZ = tf.keras.layers.Dense(n_units, activation="relu")(Z)Z = tf.keras.layers.Dense(embed_size)(Z)Z = tf.keras.layers.LayerNormalization()(tf.keras.layers.Add()([Z, skip]))
对于第一个注意力层,我们使用causal_mask & decoder_pad_mask来同时掩盖填充标记和未来标记。因果掩码只有两个维度:它缺少批处理维度,但这没关系,因为广播确保它在批处理中的所有实例中被复制。
对于第二个注意力层,没有特别之处。唯一需要注意的是我们使用encoder_pad_mask而不是decoder_pad_mask,因为这个注意力层使用编码器的最终输出作为其值。
我们快要完成了。我们只需要添加最终的输出层,创建模型,编译它,然后训练它:
Y_proba = tf.keras.layers.Dense(vocab_size, activation="softmax")(Z)
model = tf.keras.Model(inputs=[encoder_inputs, decoder_inputs],outputs=[Y_proba])
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam",metrics=["accuracy"])
model.fit((X_train, X_train_dec), Y_train, epochs=10,validation_data=((X_valid, X_valid_dec), Y_valid))
恭喜!您已经从头开始构建了一个完整的 Transformer,并对其进行了自动翻译的训练。这变得相当高级了!
提示
Keras 团队创建了一个新的Keras NLP 项目,其中包括一个 API,可以更轻松地构建Transformer。您可能还对新的Keras CV 项目(用于计算机视觉)感兴趣。
但领域并没有就此停止。现在让我们来探讨一些最近的进展。
Transformer模型的大量涌现
2018 年被称为 NLP 的“ImageNet 时刻”。从那时起,进展一直令人震惊,基于巨大数据集训练的基于Transformer的架构越来越大。
首先,Alec Radford 和其他 OpenAI 研究人员的GPT 论文再次展示了无监督预训练的有效性,就像 ELMo 和 ULMFiT 论文之前一样,但这次使用了类似Transformer的架构。作者们预训练了一个由 12 个Transformer模块堆叠而成的大型但相当简单的架构,只使用了像原始Transformer解码器中的掩码多头注意力层。他们在一个非常庞大的数据集上进行了训练,使用了我们用于莎士比亚 char-RNN 的相同自回归技术:只需预测下一个标记。这是一种自监督学习形式。然后,他们对各种语言任务进行了微调,每个任务只进行了轻微的调整。这些任务非常多样化:它们包括文本分类、蕴涵(句子 A 是否对句子 B 施加、涉及或暗示必要的后果)、相似性(例如,“今天天气很好”与“阳光明媚”非常相似)和问答(给定一些提供一些背景的文本段落,模型必须回答一些多项选择题)。
然后谷歌的BERT 论文出现了:它也展示了在大型语料库上进行自监督预训练的有效性,使用了与 GPT 类似的架构,但只使用了非掩码多头注意力层,就像原始Transformer的编码器中一样。这意味着模型是自然双向的;因此 BERT 中的 B(来自Transformer的双向编码器表示)。最重要的是,作者提出了两个预训练任务,解释了模型大部分的强度:
掩码语言模型(MLM)
句子中的每个单词有 15%的概率被掩盖,模型经过训练,以预测被掩盖的单词。例如,如果原始句子是“她在生日聚会上玩得很开心”,那么模型可能会得到句子“她在聚会上玩得很开心”,它必须预测单词“had”和“birthday”(其他输出将被忽略)。更准确地说,每个选择的单词有 80%的概率被掩盖,10%的概率被替换为随机单词(为了减少预训练和微调之间的差异,因为模型在微调过程中不会看到标记),以及 10%的概率被保留(以偏向模型正确答案)。
下一个句子预测(NSP)
该模型经过训练,以预测两个句子是否连续。例如,它应该预测“狗在睡觉”和“它打呼噜”是连续的句子,而“狗在睡觉”和“地球绕着太阳转”不是连续的。后来的研究表明,NSP 并不像最初认为的那么重要,因此在大多数后来的架构中被放弃了。
该模型同时在这两个任务上进行训练(参见图 16-11)。对于 NSP 任务,作者在每个输入的开头插入了一个类标记(),相应的输出标记表示模型的预测:句子 B 跟在句子 A 后面,或者不是。这两个输入句子被连接在一起,只用一个特殊的分隔标记()分开,然后作为输入提供给模型。为了帮助模型知道每个输入标记属于哪个句子,每个标记的位置嵌入上面添加了一个段嵌入:只有两种可能的段嵌入,一个用于句子 A,一个用于句子 B。对于 MLM 任务,一些输入词被屏蔽(正如我们刚才看到的),模型试图预测这些词是什么。损失仅在 NSP 预测和被屏蔽的标记上计算,而不是在未被屏蔽的标记上。
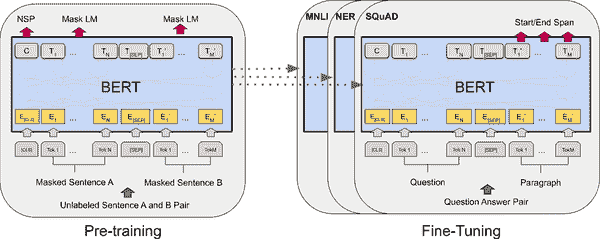
图 16-11. BERT 训练和微调过程
在对大量文本进行无监督预训练阶段之后,该模型然后在许多不同的任务上进行微调,每个任务的变化都很小。例如,对于文本分类(如情感分析),所有输出标记都被忽略,除了第一个,对应于类标记,一个新的输出层取代了以前的输出层,以前的输出层只是一个用于 NSP 的二元分类层。
2019 年 2 月,就在 BERT 发布几个月后,Alec Radford、Jeffrey Wu 和其他 OpenAI 研究人员发表了GPT-2 论文,提出了一个与 GPT 非常相似但规模更大的架构(超过 15 亿个参数!)。研究人员展示了新改进的 GPT 模型可以进行零样本学习(ZSL),这意味着它可以在许多任务上取得良好的表现而无需任何微调。这只是朝着更大更大模型的竞赛的开始:谷歌的Switch Transformers(2021 年 1 月推出)使用了 1 万亿个参数,很快就会推出更大的模型,比如 2021 年 6 月北京人工智能学会(BAII)宣布的 Wu Dao 2.0 模型。
巨型模型的这种趋势不幸地导致只有经济实力雄厚的组织才能负担得起训练这样的模型:成本很容易就能达到几十万美元甚至更高。训练单个模型所需的能量相当于一个美国家庭几年的电力消耗;这一点根本不环保。许多这些模型甚至太大,无法在常规硬件上使用:它们无法适应内存,速度也会非常慢。最后,有些模型成本如此之高,以至于不会公开发布。
幸运的是,聪明的研究人员正在找到新的方法来缩小Transformer并使其更具数据效率。例如,2019 年 10 月由 Hugging Face 的 Victor Sanh 等人推出的DistilBERT 模型是基于 BERT 的一个小型快速Transformer模型。它可以在 Hugging Face 出色的模型中心找到,其中包括成千上万个其他模型——本章后面将会看到一个示例。
DistilBERT 是使用蒸馏(因此得名)进行训练的:这意味着将知识从一个教师模型转移到一个通常比教师模型小得多的学生模型。通常通过使用教师对每个训练实例的预测概率作为学生的目标来实现。令人惊讶的是,蒸馏通常比在相同数据集上从头开始训练学生更有效!事实上,学生受益于教师更加微妙的标签。
在 BERT 之后,还有更多的 transformer 架构陆续推出,几乎每个月都有,通常在所有 NLP 任务的最新技术上有所改进:XLNet(2019 年 6 月),RoBERTa(2019 年 7 月),StructBERT(2019 年 8 月),ALBERT(2019 年 9 月),T5(2019 年 10 月),ELECTRA(2020 年 3 月),GPT3(2020 年 5 月),DeBERTa(2020 年 6 月),Switch Transformers(2021 年 1 月),Wu Dao 2.0(2021 年 6 月),Gopher(2021 年 12 月),GPT-NeoX-20B(2022 年 2 月),Chinchilla(2022 年 3 月),OPT(2022 年 5 月),等等。每个模型都带来了新的想法和技术,但我特别喜欢谷歌研究人员的T5 论文:它将所有 NLP 任务都框定为文本到文本,使用编码器-解码器 transformer。例如,要将“I like soccer”翻译成西班牙语,您只需用输入句子“translate English to Spanish: I like soccer”调用模型,它会输出“me gusta el fútbol”。要总结一段文字,您只需输入“summarize:”后跟段落,它会输出摘要。对于分类,只需将前缀更改为“classify:”,模型会输出类名,作为文本。这简化了使用模型,也使其能够在更多任务上进行预训练。
最后但并非最不重要的是,在 2022 年 4 月,谷歌研究人员使用了一个名为Pathways的新大规模训练平台(我们将在第十九章中简要讨论),来训练一个名为Pathways 语言模型(PaLM),拥有惊人的 5400 亿个参数,使用了超过 6000 个 TPU。除了其令人难以置信的规模之外,这个模型是一个标准的 transformer,只使用解码器(即,带有掩码多头注意力层),只有一些微调(详细信息请参阅论文)。这个模型在各种 NLP 任务中取得了令人难以置信的表现,特别是在自然语言理解(NLU)方面。它能够完成令人印象深刻的壮举,比如解释笑话,给出详细的逐步回答问题的答案,甚至编码。这在一定程度上归功于模型的规模,也归功于一种称为思维链提示的技术,这种技术是几个月前由另一个谷歌研究团队引入的。
在问答任务中,常规提示通常包括一些问题和答案的示例,例如:“Q: Roger 有 5 个网球。他买了 2 罐网球。每罐有 3 个网球。他现在有多少网球?A: 11。”然后提示继续提出实际问题,比如“Q: John 照顾 10 只狗。每只狗每天需要 0.5 小时散步和照顾自己的事务。他每周花多少时间照顾狗?A:”,模型的任务是附加答案:在这种情况下是“35”。
但是通过思维链提示,示例答案包括导致结论的所有推理步骤。例如,不是“A: 11”,提示包含“A: Roger 从 5 个球开始。2 罐每罐 3 个网球,总共 6 个网球。5 + 6 = 11。”这鼓励模型给出对实际问题的详细答案,比如“John 照顾 10 只狗。每只狗每天需要 0.5 小时散步和照顾自己的事务。所以是 10 × 0.5 = 5 小时每天。5 小时每天 × 7 天每周 = 35 小时每周。答案是每周 35 小时。”这是论文中的一个实际例子!
这个模型不仅比使用常规提示更频繁地给出正确答案——我们鼓励模型深思熟虑——而且还提供了所有推理步骤,这对于更好地理解模型答案背后的原理是有用的。
transformers 已经在 NLP 领域占据了主导地位,但它们并没有止步于此:它们很快也扩展到了计算机视觉领域。
视觉 transformers
注意机制在 NMT 之外的第一个应用是使用视觉注意力生成图像字幕:一个卷积神经网络首先处理图像并输出一些特征图,然后一个带有注意力机制的解码器 RNN 逐个单词生成字幕。
在每个解码器时间步骤(即每个单词),解码器使用注意力模型专注于图像的正确部分。例如,在图 16-12 中,模型生成了字幕“A woman is throwing a frisbee in a park”,您可以看到当解码器准备输出单词“frisbee”时,它的注意力集中在输入图像的哪个部分:显然,它的大部分注意力集中在飞盘上。

图 16-12。视觉注意力:输入图像(左)和生成单词“frisbee”之前模型的焦点(右)
当 transformers 在 2017 年问世并且人们开始在 NLP 之外进行实验时,它们最初是与 CNN 一起使用的,而不是取代它们。相反,transformers 通常用来取代 RNN,例如在图像字幕模型中。在2020 年的一篇论文中,Facebook 的研究人员提出了一个混合 CNN-transformer 架构用于目标检测。再次,CNN 首先处理输入图像并输出一组特征图,然后这些特征图被转换为序列并馈送到 transformer 中,transformer 输出边界框预测。但是,大部分视觉工作仍然由 CNN 完成。
然后,在 2020 年 10 月,一组谷歌研究人员发布了一篇论文,介绍了一种完全基于 transformer 的视觉模型,称为vision transformer(ViT)。这个想法非常简单:只需将图像切成小的 16×16 的方块,并将方块序列视为单词表示的序列。更准确地说,方块首先被展平为 16×16×3=768 维向量——3 代表 RGB 颜色通道——然后这些向量经过一个线性层进行转换但保留其维度。然后产生的向量序列可以像单词嵌入序列一样处理:这意味着添加位置嵌入,并将结果传递给 transformer。就是这样!这个模型在 ImageNet 图像分类上击败了现有技术,但公平地说,作者们必须使用超过 3 亿张额外的图像进行训练。这是有道理的,因为 transformer 没有像卷积神经网络那样多的归纳偏差,所以它们需要额外的数据来学习 CNN 隐含假设中的东西。
注意
归纳偏差是模型由于其架构而做出的隐含假设。例如,线性模型隐含地假设数据是线性的。CNN 隐含地假设在一个位置学习到的模式在其他位置也可能有用。RNN 隐含地假设输入是有序的,并且最近的标记比较重要。模型具有的归纳偏差越多,假设它们是正确的,模型所需的训练数据就越少。但是,如果隐含的假设是错误的,那么即使在大型数据集上训练,模型也可能表现不佳。
仅仅两个月后,Facebook 的一个研究团队发布了一篇论文,介绍了数据高效图像变换器(DeiTs)。他们的模型在 ImageNet 上取得了竞争性的结果,而无需额外的训练数据。该模型的架构与原始 ViT 几乎相同,但作者使用了一种蒸馏技术,将来自最先进的 CNN 模型的知识转移到他们的模型中。
然后,2021 年 3 月,DeepMind 发布了一篇重要的论文,介绍了Perceiver架构。这是一种多模态Transformer,意味着您可以向其提供文本、图像、音频或几乎任何其他模态。直到那时,Transformer由于注意力层中的性能和 RAM 瓶颈而被限制在相当短的序列中。这排除了音频或视频等模态,并迫使研究人员将图像视为补丁序列,而不是像素序列。瓶颈是由于自我注意力,其中每个标记必须关注每个其他标记:如果输入序列有M个标记,那么注意力层必须计算一个M×M矩阵,如果M非常大,这可能会很大。Perceiver 通过逐渐改进由N个标记组成的输入的相当短的潜在表示来解决这个问题——通常只有几百个。 (潜在一词表示隐藏或内部。)该模型仅使用交叉注意力层,将潜在表示作为查询输入,并将(可能很大的)输入作为值输入。这只需要计算一个M×N矩阵,因此计算复杂度与M线性相关,而不是二次的。经过几个交叉注意力层后,如果一切顺利,潜在表示最终会捕捉到输入中的所有重要内容。作者还建议在连续的交叉注意力层之间共享权重:如果这样做,那么 Perceiver 实际上就变成了一个 RNN。实际上,共享的交叉注意力层可以被看作是不同时间步的相同记忆单元,而潜在表示对应于单元的上下文向量。相同的输入会在每个时间步骤中重复馈送到记忆单元。看来 RNN 并没有完全消亡!
仅仅一个月后,Mathilde Caron 等人介绍了DINO,一个令人印象深刻的视觉变换器,完全不使用标签进行训练,使用自我监督,并能够进行高精度的语义分割。该模型在训练期间被复制,其中一个网络充当教师,另一个充当学生。梯度下降仅影响学生,而教师的权重只是学生权重的指数移动平均值。学生被训练以匹配教师的预测:由于它们几乎是相同的模型,这被称为自蒸馏。在每个训练步骤中,输入图像以不同方式增强教师和学生,因此它们不会看到完全相同的图像,但它们的预测必须匹配。这迫使它们提出高级表示。为了防止模式坍塌,即学生和教师总是输出相同的内容,完全忽略输入,DINO 跟踪教师输出的移动平均值,并调整教师的预测,以确保它们平均保持在零点上。DINO 还迫使教师对其预测具有高置信度:这被称为锐化。这些技术共同保留了教师输出的多样性。
在一篇 2021 年的论文中,Google 研究人员展示了如何根据数据量来扩展或缩小 ViTs。他们成功创建了一个庞大的 20 亿参数模型,在 ImageNet 上达到了超过 90.4%的 top-1 准确率。相反,他们还训练了一个缩小模型,在 ImageNet 上达到了超过 84.8%的 top-1 准确率,只使用了 1 万张图像:每类只有 10 张图像!
视觉 transformers 的进展一直在稳步进行。例如,2022 年 3 月,Mitchell Wortsman 等人的一篇论文展示了首先训练多个 transformers,然后平均它们的权重以创建一个新的改进模型是可能的。这类似于集成(见第七章),只是最终只有一个模型,这意味着没有推理时间惩罚。
transformers 领域的最新趋势在于构建大型多模态模型,通常能够进行零样本或少样本学习。例如,OpenAI 的 2021 年 CLIP 论文提出了一个大型 transformer 模型,预训练以匹配图像的标题:这个任务使其能够学习出色的图像表示,然后该模型可以直接用于诸如使用简单文本提示进行图像分类的任务,比如“一张猫的照片”。不久之后,OpenAI 宣布了DALL·E,能够根据文本提示生成惊人的图像。DALL·E 2生成更高质量的图像,使用扩散模型(见第十七章)。
2022 年 4 月,DeepMind 发布了Flamingo paper,介绍了一系列在多种任务和多种模态下预训练的模型,包括文本、图像和视频。一个模型可以用于非常不同的任务,比如问答、图像描述等。不久之后,2022 年 5 月,DeepMind 推出了GATO,一个多模态模型,可以作为强化学习代理的策略(强化学习将在第十八章介绍)。同一个 transformer 可以与您聊天,为图像加注释,玩 Atari 游戏,控制(模拟的)机械臂等,所有这些只需“仅有”12 亿个参数。冒险还在继续!
注意
这些惊人的进步使一些研究人员认为人类水平的 AI 已经近在眼前,认为“规模就是一切”,并且一些模型可能“稍微有意识”。其他人指出,尽管取得了惊人的进步,这些模型仍然缺乏人类智能的可靠性和适应性,我们推理的符号能力,基于单个例子进行泛化的能力等等。
正如您所看到的,transformers 无处不在!好消息是,通常您不必自己实现 transformers,因为许多优秀的预训练模型可以通过 TensorFlow Hub 或 Hugging Face 的模型中心轻松下载。您已经看到如何使用 TF Hub 中的模型,所以让我们通过快速查看 Hugging Face 的生态系统来结束本章。
Hugging Face 的 Transformers 库
今天谈论 transformers 时不可能不提到 Hugging Face,这是一家为 NLP、视觉等构建了一整套易于使用的开源工具的人工智能公司。他们生态系统的核心组件是 Transformers 库,它允许您轻松下载一个预训练模型,包括相应的分词器,然后根据需要在自己的数据集上进行微调。此外,该库支持 TensorFlow、PyTorch 和 JAX(使用 Flax 库)。
使用 Transformers 库的最简单方法是使用transformers.pipeline()函数:只需指定您想要的任务,比如情感分析,它会下载一个默认的预训练模型,准备好使用——真的再简单不过了:
from transformers import pipelineclassifier = pipeline("sentiment-analysis") # many other tasks are available
result = classifier("The actors were very convincing".)
结果是一个 Python 列表,每个输入文本对应一个字典:
>>> result
[{'label': 'POSITIVE', 'score': 0.9998071789741516}]
在此示例中,模型正确地发现句子是积极的,置信度约为 99.98%。当然,您也可以将一批句子传递给模型:
>>> classifier(["I am from India.", "I am from Iraq."])
[{'label': 'POSITIVE', 'score': 0.9896161556243896},{'label': 'NEGATIVE', 'score': 0.9811071157455444}]
pipeline()函数使用给定任务的默认模型。例如,对于文本分类任务,如情感分析,在撰写本文时,默认为distilbert-base-uncased-finetuned-sst-2-english——一个在英文维基百科和英文书籍语料库上训练的带有小写标记器的 DistilBERT 模型,并在斯坦福情感树库 v2(SST 2)任务上进行了微调。您也可以手动指定不同的模型。例如,您可以使用在多种自然语言推理(MultiNLI)任务上进行微调的 DistilBERT 模型,该任务将两个句子分类为三类:矛盾、中性或蕴含。以下是如何操作:
>>> model_name = "huggingface/distilbert-base-uncased-finetuned-mnli"
>>> classifier_mnli = pipeline("text-classification", model=model_name)
>>> classifier_mnli("She loves me. [SEP] She loves me not.")
[{'label': 'contradiction', 'score': 0.9790192246437073}]
提示
您可以在https://huggingface.co/models找到可用的模型,以及在https://huggingface.co/tasks找到任务列表。
pipeline API 非常简单方便,但有时您需要更多控制。对于这种情况,Transformers 库提供了许多类,包括各种标记器、模型、配置、回调等。例如,让我们使用TFAutoModelForSequenceClassification和AutoTokenizer类加载相同的 DistilBERT 模型及其对应的标记器:
from transformers import AutoTokenizer, TFAutoModelForSequenceClassificationtokenizer = AutoTokenizer.from_pretrained(model_name)
model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
接下来,让我们标记一对句子。在此代码中,我们激活填充,并指定我们希望使用 TensorFlow 张量而不是 Python 列表:
token_ids = tokenizer(["I like soccer. [SEP] We all love soccer!","Joe lived for a very long time. [SEP] Joe is old."],padding=True, return_tensors="tf")
提示
在将"Sentence 1 [SEP] Sentence 2"传递给标记器时,您可以等效地传递一个元组:("Sentence 1", "Sentence 2")。
输出是BatchEncoding类的类似字典实例,其中包含标记 ID 序列,以及包含填充标记的掩码为 0:
>>> token_ids
{'input_ids': <tf.Tensor: shape=(2, 15), dtype=int32, numpy=
array([[ 101, 1045, 2066, 4715, 1012, 102, 2057, 2035, 2293, 4715, 999,102, 0, 0, 0],[ 101, 3533, 2973, 2005, 1037, 2200, 2146, 2051, 1012, 102, 3533,2003, 2214, 1012, 102]], dtype=int32)>,'attention_mask': <tf.Tensor: shape=(2, 15), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], dtype=int32)>}
当调用标记器时设置return_token_type_ids=True,您还将获得一个额外的张量,指示每个标记属于哪个句子。这对某些模型是必需的,但对 DistilBERT 不是。
接下来,我们可以直接将这个BatchEncoding对象传递给模型;它返回一个包含其预测类 logits 的TFSequenceClassifierOutput对象:
>>> outputs = model(token_ids)
>>> outputs
TFSequenceClassifierOutput(loss=None, logits=[<tf.Tensor: [...] numpy=
array([[-2.1123817 , 1.1786783 , 1.4101017 ],[-0.01478387, 1.0962474 , -0.9919954 ]], dtype=float32)>], [...])
最后,我们可以应用 softmax 激活函数将这些 logits 转换为类概率,并使用argmax()函数预测每个输入句子对的具有最高概率的类:
>>> Y_probas = tf.keras.activations.softmax(outputs.logits)
>>> Y_probas
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.01619702, 0.43523544, 0.5485676 ],[0.08672056, 0.85204804, 0.06123142]], dtype=float32)>
>>> Y_pred = tf.argmax(Y_probas, axis=1)
>>> Y_pred # 0 = contradiction, 1 = entailment, 2 = neutral
<tf.Tensor: shape=(2,), dtype=int64, numpy=array([2, 1])>
在此示例中,模型正确将第一对句子分类为中性(我喜欢足球并不意味着每个人都喜欢),将第二对句子分类为蕴含(乔确实应该很老)。
如果您希望在自己的数据集上微调此模型,您可以像通常使用 Keras 一样训练模型,因为它只是一个常规的 Keras 模型,具有一些额外的方法。但是,由于模型输出的是 logits 而不是概率,您必须使用tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)损失,而不是通常的"sparse_categorical_crossentropy"损失。此外,模型在训练期间不支持BatchEncoding输入,因此您必须使用其data属性来获取一个常规字典:
sentences = [("Sky is blue", "Sky is red"), ("I love her", "She loves me")]
X_train = tokenizer(sentences, padding=True, return_tensors="tf").data
y_train = tf.constant([0, 2]) # contradiction, neutral
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(loss=loss, optimizer="nadam", metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=2)
Hugging Face 还构建了一个 Datasets 库,您可以使用它轻松下载标准数据集(如 IMDb)或自定义数据集,并用它来微调您的模型。它类似于 TensorFlow Datasets,但还提供了在运行时执行常见预处理任务的工具,如掩码。数据集列表可在https://huggingface.co/datasets上找到。
这应该让您开始使用 Hugging Face 的生态系统。要了解更多信息,您可以前往https://huggingface.co/docs查看文档,其中包括许多教程笔记本、视频、完整 API 等。我还建议您查看 O’Reilly 图书使用 Hugging Face 构建自然语言处理应用的Transformer,作者是来自 Hugging Face 团队的 Lewis Tunstall、Leandro von Werra 和 Thomas Wolf。
在下一章中,我们将讨论如何使用自编码器以无监督的方式学习深度表示,并使用生成对抗网络来生成图像等!
练习
-
使用有状态 RNN 与无状态 RNN 的优缺点是什么?
-
为什么人们使用编码器-解码器 RNN 而不是普通的序列到序列 RNN 进行自动翻译?
-
如何处理可变长度的输入序列?可变长度的输出序列呢?
-
什么是波束搜索,为什么要使用它?可以使用什么工具来实现它?
-
什么是注意力机制?它如何帮助?
-
Transformer架构中最重要的层是什么?它的目的是什么?
-
什么时候需要使用采样 softmax?
-
嵌入 Reber 语法被 Hochreiter 和 Schmidhuber 在关于 LSTMs 的论文中使用。它们是产生诸如“BPBTSXXVPSEPE”之类字符串的人工语法。查看 Jenny Orr 的关于这个主题的很好介绍,然后选择一个特定的嵌入 Reber 语法(例如 Orr 页面上表示的那个),然后训练一个 RNN 来识别一个字符串是否符合该语法。您首先需要编写一个能够生成包含约 50%符合语法的字符串和 50%不符合语法的字符串的训练批次的函数。
-
训练一个能够将日期字符串从一种格式转换为另一种格式的编码器-解码器模型(例如,从“2019 年 4 月 22 日”到“2019-04-22”)。
-
浏览 Keras 网站上关于“使用双编码器进行自然语言图像搜索”的示例。您将学习如何构建一个能够在同一嵌入空间内表示图像和文本的模型。这使得可以使用文本提示搜索图像,就像 OpenAI 的 CLIP 模型一样。
-
使用 Hugging Face Transformers 库下载一个预训练的语言模型,能够生成文本(例如,GPT),并尝试生成更具说服力的莎士比亚文本。您需要使用模型的
generate()方法-请参阅 Hugging Face 的文档以获取更多详细信息。
这些练习的解决方案可在本章笔记本的末尾找到,网址为https://homl.info/colab3。
艾伦·图灵,“计算机机器和智能”,心灵 49(1950 年):433-460。
当然,单词chatbot出现得更晚。图灵称其测试为模仿游戏:机器 A 和人类 B 通过文本消息与人类审问者 C 聊天;审问者提出问题以确定哪一个是机器(A 还是 B)。如果机器能够愚弄审问者,那么它通过了测试,而人类 B 必须尽力帮助审问者。
由于输入窗口重叠,因此在这种情况下时代的概念并不那么清晰:在每个时代(由 Keras 实现),模型实际上会多次看到相同的字符。
Alec Radford 等人,“学习生成评论和发现情感”,arXiv 预印本 arXiv:1704.01444(2017 年)。
Rico Sennrich 等人,“使用子词单元进行稀有词的神经机器翻译”,计算语言学年会第 54 届年会论文集 1(2016 年):1715-1725。
⁶ Taku Kudo,“子词规范化:改进神经网络翻译模型的多个子词候选”,arXiv 预印本 arXiv:1804.10959(2018)。
⁷ Taku Kudo 和 John Richardson,“SentencePiece:用于神经文本处理的简单且语言无关的子词标记器和去标记器”,arXiv 预印本 arXiv:1808.06226(2018)。
⁸ Yonghui Wu 等人,“谷歌的神经机器翻译系统:弥合人类和机器翻译之间的差距”,arXiv 预印本 arXiv:1609.08144(2016)。
⁹ 不规则张量在第十二章中被介绍,详细内容在附录 C 中。
¹⁰ Matthew Peters 等人,“深度上下文化的词表示”,2018 年北美计算语言学分会年会论文集:人类语言技术 1(2018):2227–2237。
¹¹ Jeremy Howard 和 Sebastian Ruder,“文本分类的通用语言模型微调”,计算语言学年会第 56 届年会论文集 1(2018):328–339。
¹² Daniel Cer 等人,“通用句子编码器”,arXiv 预印本 arXiv:1803.11175(2018)。
¹³ Ilya Sutskever 等人,“使用神经网络进行序列到序列学习”,arXiv 预印本(2014)。
¹⁴ Samy Bengio 等人,“使用循环神经网络进行序列预测的计划抽样”,arXiv 预印本 arXiv:1506.03099(2015)。
¹⁵ 这个数据集由Tatoeba 项目的贡献者创建的句子对组成。网站作者选择了约 120,000 个句子对https://manythings.org/anki。该数据集在创作共用署名 2.0 法国许可下发布。其他语言对也可用。
¹⁶ 在 Python 中,如果运行a, *b = [1, 2, 3, 4],那么a等于1,b等于[2, 3, 4]。
¹⁷ Sébastien Jean 等人,“在神经机器翻译中使用非常大的目标词汇”,计算语言学年会第 53 届年会和亚洲自然语言处理联合国际会议第 7 届年会论文集 1(2015):1–10。
¹⁸ Dzmitry Bahdanau 等人,“通过联合学习对齐和翻译的神经机器翻译”,arXiv 预印本 arXiv:1409.0473(2014)。
¹⁹ Minh-Thang Luong 等人,“基于注意力的神经机器翻译的有效方法”,2015 年自然语言处理经验方法会议论文集(2015):1412–1421。
²⁰ Ashish Vaswani 等人,“注意力就是一切”,第 31 届国际神经信息处理系统会议论文集(2017):6000–6010。
²¹ 由于Transformer使用时间分布密集层,可以说它使用了核大小为 1 的 1D 卷积层。
²² 这是“注意力就是一切”论文中的图 1,经作者的亲切许可再现。
²³ 如果您使用最新版本的 TensorFlow,可以使用不规则张量。
²⁴ 这是“注意力机制是你所需要的一切”中图 2 的右侧部分,经作者亲切授权复制。
²⁵ 当您阅读本文时,这很可能会发生变化;请查看Keras 问题#16248获取更多详细信息。当这种情况发生时,将不需要设置attention_mask参数,因此也不需要创建encoder_pad_mask。
²⁶ 目前Z + skip不支持自动屏蔽,这就是为什么我们不得不写tf.keras.layers.Add()([Z, skip])的原因。再次强调,当您阅读本文时,情况可能已经发生变化。
²⁷ Alec Radford 等人,“通过生成式预训练改进语言理解”(2018 年)。
²⁸ 例如,“简在朋友的生日派对上玩得很开心”意味着“简喜欢这个派对”,但与“每个人都讨厌这个派对”相矛盾,与“地球是平的”无关。
²⁹ Jacob Devlin 等人,“BERT:深度双向 Transformer 的预训练”,2018 年北美计算语言学协会会议论文集:人类语言技术 1(2019 年)。
³⁰ 这是论文中的图 1,经作者亲切授权复制。
³¹ Alec Radford 等人,“语言模型是无监督多任务学习者”(2019 年)。
³² William Fedus 等人,“Switch Transformers: 通过简单高效的稀疏性扩展到万亿参数模型”(2021 年)。
³³ Victor Sanh 等人,“DistilBERT,Bert 的精简版本:更小、更快、更便宜、更轻”,arXiv 预印本 arXiv:1910.01108(2019 年)。
³⁴ Mariya Yao 在这篇文章中总结了许多这些模型:https://homl.info/yaopost。
³⁵ Colin Raffel 等人,“探索统一文本到文本 Transformer 的迁移学习极限”,arXiv 预印本 arXiv:1910.10683(2019 年)。
³⁶ Aakanksha Chowdhery 等人,“PaLM: 使用路径扩展语言建模”,arXiv 预印本 arXiv:2204.02311(2022 年)。
³⁷ Jason Wei 等人,“思维链提示引发大型语言模型的推理”,arXiv 预印本 arXiv:2201.11903(2022 年)。
³⁸ Kelvin Xu 等人,“展示、关注和叙述:带有视觉注意力的神经图像字幕生成”,第 32 届国际机器学习会议论文集(2015 年):2048–2057。
³⁹ 这是论文中图 3 的一部分。经作者亲切授权复制。
⁴⁰ Marco Tulio Ribeiro 等人,“‘为什么我应该相信你?’:解释任何分类器的预测”,第 22 届 ACM SIGKDD 国际知识发现与数据挖掘会议论文集(2016 年):1135–1144。
⁴¹ Nicolas Carion 等人,“使用 Transformer 进行端到端目标检测”,arXiv 预印本 arxiv:2005.12872(2020 年)。
⁴² Alexey Dosovitskiy 等人,“一幅图像价值 16x16 个词:大规模图像识别的 Transformer”,arXiv 预印本 arxiv:2010.11929(2020 年)。
⁴³ Hugo Touvron 等人,“训练数据高效的图像 Transformer 和通过注意力蒸馏”,arXiv 预印本 arxiv:2012.12877(2020 年)。
⁴⁴ Andrew Jaegle 等人,“Perceiver: 带有迭代注意力的通用感知”,arXiv 预印本 arxiv:2103.03206(2021)。
⁴⁵ Mathilde Caron 等人,“自监督视觉 Transformer 中的新兴属性”,arXiv 预印本 arxiv:2104.14294(2021)。
⁴⁶ Xiaohua Zhai 等人,“缩放视觉 Transformer”,arXiv 预印本 arxiv:2106.04560v1(2021)。
⁴⁷ Mitchell Wortsman 等人,“模型汤:多个微调模型的权重平均提高准确性而不增加推理时间”,arXiv 预印本 arxiv:2203.05482v1(2022)。
⁴⁸ Alec Radford 等人,“从自然语言监督中学习可转移的视觉模型”,arXiv 预印本 arxiv:2103.00020(2021)。
⁴⁹ Aditya Ramesh 等人,“零样本文本到图像生成”,arXiv 预印本 arxiv:2102.12092(2021)。
⁵⁰ Aditya Ramesh 等人,“具有 CLIP 潜变量的分层文本条件图像生成”,arXiv 预印本 arxiv:2204.06125(2022)。
⁵¹ Jean-Baptiste Alayrac 等人,“Flamingo:用于少样本学习的视觉语言模型”,arXiv 预印本 arxiv:2204.14198(2022)。
⁵² Scott Reed 等人,“通用主体代理”,arXiv 预印本 arxiv:2205.06175(2022)。
第十七章:自编码器、GANs 和扩散模型
自编码器是人工神经网络,能够学习输入数据的密集表示,称为潜在表示或编码,而无需任何监督(即,训练集未标记)。这些编码通常比输入数据的维度低得多,使得自编码器在降维方面非常有用(参见第八章),特别是用于可视化目的。自编码器还充当特征检测器,并且可以用于深度神经网络的无监督预训练(正如我们在第十一章中讨论的那样)。最后,一些自编码器是生成模型:它们能够随机生成看起来非常类似于训练数据的新数据。例如,您可以在人脸图片上训练一个自编码器,然后它将能够生成新的人脸。
生成对抗网络(GANs)也是能够生成数据的神经网络。事实上,它们可以生成如此逼真的人脸图片,以至于很难相信它们所代表的人并不存在。您可以通过访问https://thispersondoesnotexist.com来亲自判断,这是一个展示由名为StyleGAN的 GAN 架构生成的人脸的网站。您还可以查看https://thisrentaldoesnotexist.com来查看一些生成的 Airbnb 列表。GANs 现在被广泛用于超分辨率(增加图像的分辨率)、着色、强大的图像编辑(例如,用逼真的背景替换照片炸弹客)、将简单的草图转换为逼真的图像、预测视频中的下一帧、增强数据集(用于训练其他模型)、生成其他类型的数据(如文本、音频和时间序列)、识别其他模型的弱点以加强它们等等。
生成学习领域的一个较新的成员是扩散模型。在 2021 年,它们成功生成了比 GANs 更多样化和高质量的图像,同时训练也更容易。然而,扩散模型运行速度较慢。
自编码器、GANs 和扩散模型都是无监督的,它们都学习潜在表示,它们都可以用作生成模型,并且有许多类似的应用。然而,它们的工作方式非常不同:
-
自编码器简单地学习将输入复制到输出。这听起来可能是一个琐碎的任务,但正如你将看到的,以各种方式约束网络可能会使其变得相当困难。例如,您可以限制潜在表示的大小,或者您可以向输入添加噪声并训练网络以恢复原始输入。这些约束阻止了自编码器直接将输入轻松复制到输出,迫使其学习表示数据的有效方式。简而言之,编码是自编码器在某些约束下学习身份函数的副产品。
-
GANs 由两个神经网络组成:一个生成器试图生成看起来类似于训练数据的数据,另一个鉴别器试图区分真实数据和假数据。这种架构在深度学习中非常独特,因为生成器和鉴别器在训练过程中相互竞争:生成器经常被比作试图制造逼真的假币的罪犯,而鉴别器则像是试图区分真假货币的警察调查员。对抗训练(训练竞争的神经网络)被广泛认为是 2010 年代最重要的创新之一。2016 年,Yann LeCun 甚至说这是“过去 10 年中机器学习中最有趣的想法”。
-
去噪扩散概率模型(DDPM)被训练用于从图像中去除一点噪音。如果你拿一张完全充满高斯噪音的图像,然后反复在该图像上运行扩散模型,一个高质量的图像将逐渐出现,类似于训练图像(但不完全相同)。
在本章中,我们将深入探讨自编码器的工作原理以及如何将其用于降维、特征提取、无监督预训练或生成模型。这将自然地引导我们到 GAN。我们将构建一个简单的 GAN 来生成假图像,但我们会看到训练通常相当困难。我们将讨论对抗训练中遇到的主要困难,以及一些解决这些困难的主要技术。最后,我们将构建和训练一个 DDPM,并用它生成图像。让我们从自编码器开始!
高效的数据表示
你觉得以下哪个数字序列最容易记住?
-
40, 27, 25, 36, 81, 57, 10, 73, 19, 68
-
50, 48, 46, 44, 42, 40, 38, 36, 34, 32, 30, 28, 26, 24, 22, 20, 18, 16, 14
乍一看,第一个序列似乎更容易,因为它要短得多。然而,如果你仔细看第二个序列,你会注意到它只是从 50 到 14 的偶数列表。一旦你注意到这个模式,第二个序列比第一个容易记忆得多,因为你只需要记住模式(即递减的偶数)和起始和结束数字(即 50 和 14)。请注意,如果你能快速轻松地记住非常长的序列,你就不会太在意第二个序列中的模式。你只需要把每个数字背下来,就这样。难以记忆长序列的事实使得识别模式变得有用,希望这解释清楚了为什么在训练期间对自编码器进行约束会促使其发现和利用数据中的模式。
记忆、感知和模式匹配之间的关系在 20 世纪 70 年代初由威廉·查斯和赫伯特·西蒙著名研究。他们观察到,专业的国际象棋选手能够在只看棋盘五秒钟的情况下记住游戏中所有棋子的位置,这是大多数人会觉得不可能的任务。然而,这只有在棋子被放置在现实位置(来自实际游戏)时才是这样,而不是当棋子被随机放置时。国际象棋专家的记忆力并不比你我好多少;他们只是更容易看到国际象棋的模式,这要归功于他们对游戏的经验。注意到模式有助于他们有效地存储信息。
就像这个记忆实验中的国际象棋选手一样,自编码器查看输入,将其转换为高效的潜在表示,然后输出与输入非常接近的内容(希望如此)。自编码器始终由两部分组成:一个编码器(或识别网络),将输入转换为潜在表示,然后是一个解码器(或生成网络),将内部表示转换为输出(参见图 17-1)。
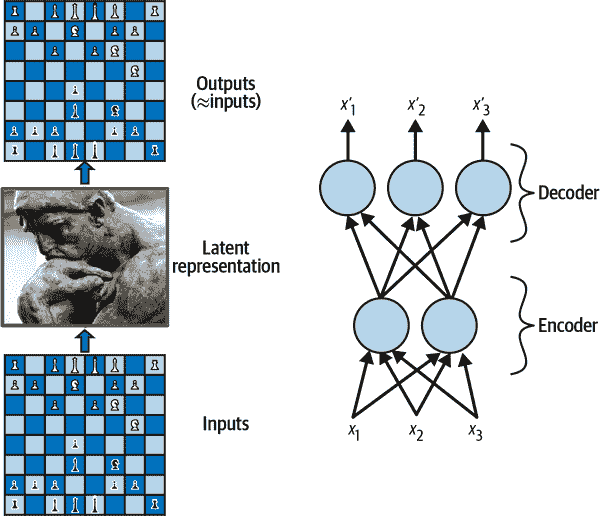
图 17-1。国际象棋记忆实验(左)和简单的自编码器(右)
正如您所看到的,自编码器通常具有与多层感知器(MLP;参见第十章)相同的架构,只是输出层中的神经元数量必须等于输入数量。在这个例子中,有一个由两个神经元组成的隐藏层(编码器),以及一个由三个神经元组成的输出层(解码器)。输出通常被称为重构,因为自编码器试图重构输入。成本函数包含一个重构损失,当重构与输入不同时,惩罚模型。
因为内部表示的维度比输入数据低(是 2D 而不是 3D),所以自编码器被称为欠完备。欠完备自编码器不能简单地将其输入复制到编码中,但它必须找到一种输出其输入的方式。它被迫学习输入数据中最重要的特征(并丢弃不重要的特征)。
让我们看看如何实现一个非常简单的欠完备自编码器进行降维。
使用欠完备线性自编码器执行 PCA
如果自编码器仅使用线性激活函数,并且成本函数是均方误差(MSE),那么它最终会执行主成分分析(PCA;参见第八章)。
以下代码构建了一个简单的线性自编码器,用于在 3D 数据集上执行 PCA,将其投影到 2D:
import tensorflow as tfencoder = tf.keras.Sequential([tf.keras.layers.Dense(2)])
decoder = tf.keras.Sequential([tf.keras.layers.Dense(3)])
autoencoder = tf.keras.Sequential([encoder, decoder])optimizer = tf.keras.optimizers.SGD(learning_rate=0.5)
autoencoder.compile(loss="mse", optimizer=optimizer)
这段代码与我们在过去章节中构建的所有 MLP 并没有太大的不同,但有几点需要注意:
-
我们将自编码器组织成两个子组件:编码器和解码器。两者都是常规的
Sequential模型,每个都有一个Dense层,自编码器是一个包含编码器后面是解码器的Sequential模型(请记住,模型可以作为另一个模型中的一层使用)。 -
自编码器的输出数量等于输入数量(即 3)。
-
为了执行 PCA,我们不使用任何激活函数(即所有神经元都是线性的),成本函数是 MSE。这是因为 PCA 是一种线性变换。很快我们将看到更复杂和非线性的自编码器。
现在让我们在与我们在第八章中使用的相同简单生成的 3D 数据集上训练模型,并使用它对该数据集进行编码(即将其投影到 2D):
X_train = [...] # generate a 3D dataset, like in Chapter 8
history = autoencoder.fit(X_train, X_train, epochs=500, verbose=False)
codings = encoder.predict(X_train)
请注意,X_train既用作输入又用作目标。图 17-2 显示了原始 3D 数据集(左侧)和自编码器的隐藏层的输出(即编码层,右侧)。正如您所看到的,自编码器找到了最佳的 2D 平面来投影数据,尽可能保留数据中的方差(就像 PCA 一样)。
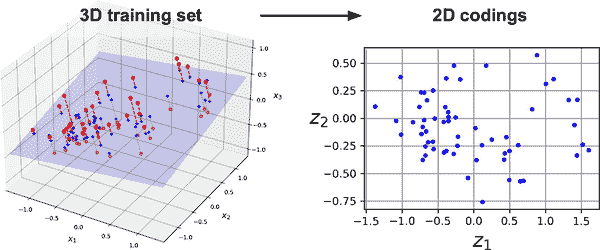
图 17-2. 由欠完备线性自编码器执行的近似 PCA
注意
您可以将自编码器视为执行一种自监督学习,因为它基于一种带有自动生成标签的监督学习技术(在本例中简单地等于输入)。
堆叠自编码器
就像我们讨论过的其他神经网络一样,自编码器可以有多个隐藏层。在这种情况下,它们被称为堆叠自编码器(或深度自编码器)。添加更多层有助于自编码器学习更复杂的编码。也就是说,必须小心不要使自编码器过于强大。想象一个如此强大的编码器,它只学习将每个输入映射到一个单一的任意数字(解码器学习反向映射)。显然,这样的自编码器将完美地重构训练数据,但它不会在过程中学习任何有用的数据表示,并且不太可能很好地推广到新实例。
堆叠自编码器的架构通常关于中心隐藏层(编码层)是对称的。简单来说,它看起来像三明治。例如,时尚 MNIST 的自编码器(在第十章介绍)可能有 784 个输入,然后是具有 100 个神经元的隐藏层,然后是具有 30 个神经元的中心隐藏层,然后是具有 100 个神经元的另一个隐藏层,最后是具有 784 个神经元的输出层。这个堆叠自编码器在图 17-3 中表示。
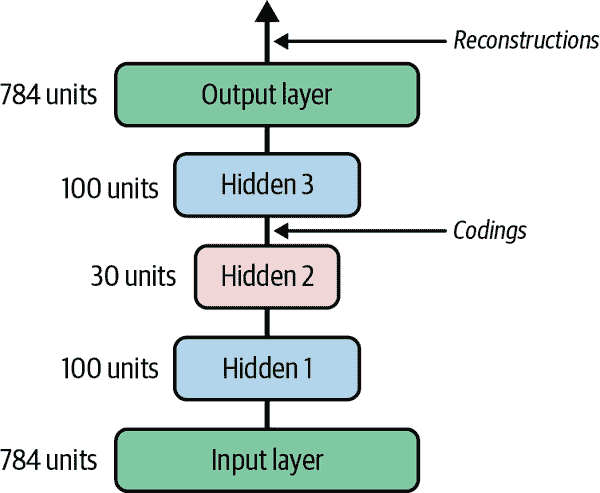
图 17-3. 堆叠自编码器
使用 Keras 实现堆叠自编码器
您可以实现一个堆叠自编码器,非常类似于常规的深度 MLP:
stacked_encoder = tf.keras.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(100, activation="relu"),tf.keras.layers.Dense(30, activation="relu"),
])
stacked_decoder = tf.keras.Sequential([tf.keras.layers.Dense(100, activation="relu"),tf.keras.layers.Dense(28 * 28),tf.keras.layers.Reshape([28, 28])
])
stacked_ae = tf.keras.Sequential([stacked_encoder, stacked_decoder])stacked_ae.compile(loss="mse", optimizer="nadam")
history = stacked_ae.fit(X_train, X_train, epochs=20,validation_data=(X_valid, X_valid))
让我们来看看这段代码:
-
就像之前一样,我们将自编码器模型分成两个子模型:编码器和解码器。
-
编码器接收 28×28 像素的灰度图像,将它们展平,使每个图像表示为大小为 784 的向量,然后通过两个逐渐减小的“密集”层(100 个单元,然后是 30 个单元)处理这些向量,都使用 ReLU 激活函数。对于每个输入图像,编码器输出大小为 30 的向量。
-
解码器接收大小为 30 的编码(由编码器输出),并通过两个逐渐增大的“密集”层(100 个单元,然后是 784 个单元)处理它们,并将最终向量重新整形为 28×28 的数组,以便解码器的输出具有与编码器输入相同的形状。
-
在编译堆叠自编码器时,我们使用 MSE 损失和 Nadam 优化。
-
最后,我们使用
X_train作为输入和目标来训练模型。同样,我们使用X_valid作为验证输入和目标。
可视化重构
确保自编码器得到正确训练的一种方法是比较输入和输出:差异不应太大。让我们绘制一些验证集中的图像,以及它们的重构:
import numpy as npdef plot_reconstructions(model, images=X_valid, n_images=5):reconstructions = np.clip(model.predict(images[:n_images]), 0, 1)fig = plt.figure(figsize=(n_images * 1.5, 3))for image_index in range(n_images):plt.subplot(2, n_images, 1 + image_index)plt.imshow(images[image_index], cmap="binary")plt.axis("off")plt.subplot(2, n_images, 1 + n_images + image_index)plt.imshow(reconstructions[image_index], cmap="binary")plt.axis("off")plot_reconstructions(stacked_ae)
plt.show()
图 17-4 显示了生成的图像。

图 17-4. 原始图像(顶部)及其重构(底部)
重构是可以识别的,但有点丢失。我们可能需要训练模型更长时间,或者使编码器和解码器更深,或者使编码更大。但是,如果我们使网络过于强大,它将能够进行完美的重构,而不必学习数据中的任何有用模式。现在,让我们使用这个模型。
可视化时尚 MNIST 数据集
现在我们已经训练了一个堆叠自编码器,我们可以使用它来降低数据集的维度。对于可视化,与其他降维算法(如我们在第八章中讨论的算法)相比,这并不会产生很好的结果,但自编码器的一个重要优势是它们可以处理具有许多实例和许多特征的大型数据集。因此,一种策略是使用自编码器将维度降低到合理水平,然后使用另一个降维算法进行可视化。让我们使用这种策略来可视化时尚 MNIST。首先,我们将使用堆叠自编码器的编码器将维度降低到 30,然后我们将使用 Scikit-Learn 的 t-SNE 算法实现将维度降低到 2 以进行可视化:
from sklearn.manifold import TSNEX_valid_compressed = stacked_encoder.predict(X_valid)
tsne = TSNE(init="pca", learning_rate="auto", random_state=42)
X_valid_2D = tsne.fit_transform(X_valid_compressed)
现在我们可以绘制数据集:
plt.scatter(X_valid_2D[:, 0], X_valid_2D[:, 1], c=y_valid, s=10, cmap="tab10")
plt.show()
图 17-5 显示了生成的散点图,通过显示一些图像进行美化。t-SNE 算法识别出几个与类别相匹配的簇(每个类别由不同的颜色表示)。
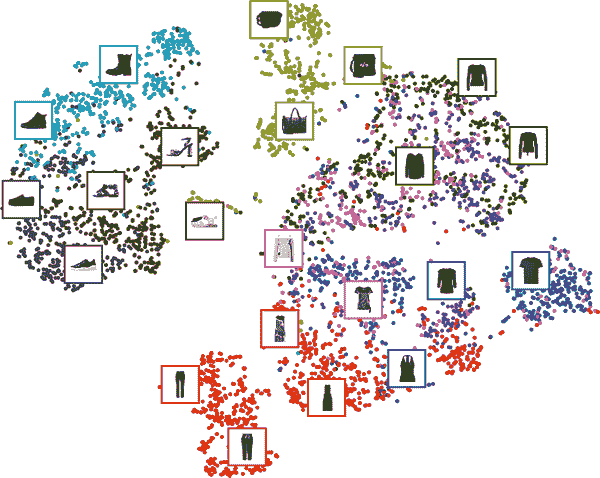
图 17-5. 使用自编码器后跟 t-SNE 的时尚 MNIST 可视化
因此,自编码器可以用于降维。另一个应用是无监督的预训练。
使用堆叠自编码器进行无监督预训练
正如我们在第十一章中讨论的,如果你正在处理一个复杂的监督任务,但没有太多标记的训练数据,一个解决方案是找到一个执行类似任务的神经网络,并重复使用其较低层。这样可以使用少量训练数据训练高性能模型,因为你的神经网络不需要学习所有低级特征;它只需重复使用现有网络学习的特征检测器。
同样,如果你有一个大型数据集,但其中大部分是未标记的,你可以首先使用所有数据训练一个堆叠自编码器,然后重复使用较低层来创建一个用于实际任务的神经网络,并使用标记数据进行训练。例如,图 17-6 展示了如何使用堆叠自编码器为分类神经网络执行无监督预训练。在训练分类器时,如果你确实没有太多标记的训练数据,可能需要冻结预训练层(至少是较低的层)。
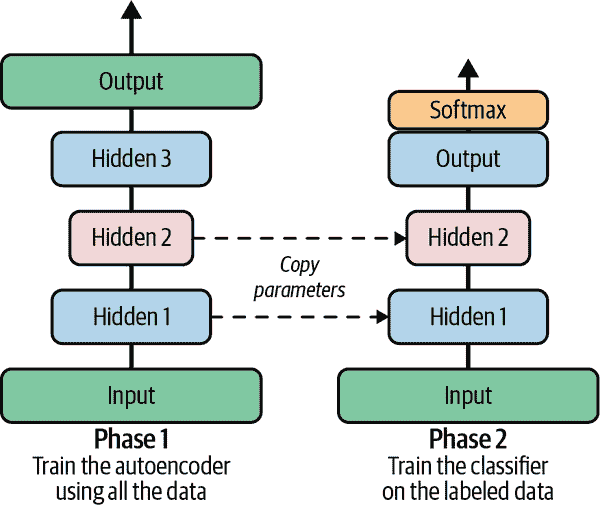
图 17-6。使用自编码器进行无监督预训练
注意
拥有大量未标记数据和少量标记数据是很常见的。构建一个大型未标记数据集通常很便宜(例如,一个简单的脚本可以从互联网上下载数百万张图片),但标记这些图片(例如,将它们分类为可爱或不可爱)通常只能由人类可靠地完成。标记实例是耗时且昂贵的,因此通常只有少量人类标记的实例,甚至更少。
实现上没有什么特别之处:只需使用所有训练数据(标记加未标记)训练一个自编码器,然后重复使用其编码器层来创建一个新的神经网络(请参考本章末尾的练习示例)。
接下来,让我们看一些训练堆叠自编码器的技术。
绑定权重
当一个自编码器是整齐对称的,就像我们刚刚构建的那样,一个常见的技术是将解码器层的权重与编码器层的权重绑定在一起。这样可以减半模型中的权重数量,加快训练速度并限制过拟合的风险。具体来说,如果自编码器总共有N层(不包括输入层),而W[L]表示第L层的连接权重(例如,第 1 层是第一个隐藏层,第N/2 层是编码层,第N层是输出层),那么解码器层的权重可以定义为W[L] = W[N–L+1]^⊺(其中L = N / 2 + 1, …, N)。
使用 Keras 在层之间绑定权重,让我们定义一个自定义层:
class DenseTranspose(tf.keras.layers.Layer):def __init__(self, dense, activation=None, **kwargs):super().__init__(**kwargs)self.dense = denseself.activation = tf.keras.activations.get(activation)def build(self, batch_input_shape):self.biases = self.add_weight(name="bias",shape=self.dense.input_shape[-1],initializer="zeros")super().build(batch_input_shape)def call(self, inputs):Z = tf.matmul(inputs, self.dense.weights[0], transpose_b=True)return self.activation(Z + self.biases)
这个自定义层就像一个常规的Dense层,但它使用另一个Dense层的权重,经过转置(设置transpose_b=True等同于转置第二个参数,但更高效,因为它在matmul()操作中实时执行转置)。然而,它使用自己的偏置向量。现在我们可以构建一个新的堆叠自编码器,与之前的模型类似,但解码器的Dense层与编码器的Dense层绑定:
dense_1 = tf.keras.layers.Dense(100, activation="relu")
dense_2 = tf.keras.layers.Dense(30, activation="relu")tied_encoder = tf.keras.Sequential([tf.keras.layers.Flatten(),dense_1,dense_2
])tied_decoder = tf.keras.Sequential([DenseTranspose(dense_2, activation="relu"),DenseTranspose(dense_1),tf.keras.layers.Reshape([28, 28])
])tied_ae = tf.keras.Sequential([tied_encoder, tied_decoder])
这个模型实现了与之前模型大致相同的重构误差,使用了几乎一半的参数数量。
一次训练一个自编码器
与我们刚刚做的整个堆叠自编码器一次性训练不同,可以一次训练一个浅层自编码器,然后将它们堆叠成一个单一的堆叠自编码器(因此得名),如图 17-7 所示。这种技术现在不太常用,但你可能仍然会遇到一些论文讨论“贪婪逐层训练”,所以了解其含义是很有必要的。
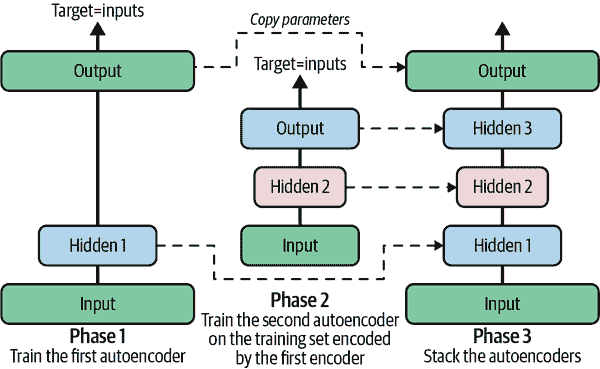
图 17-7。一次训练一个自编码器
在训练的第一阶段,第一个自编码器学习重建输入。然后我们使用这个第一个自编码器对整个训练集进行编码,这给我们一个新的(压缩的)训练集。然后我们在这个新数据集上训练第二个自编码器。这是训练的第二阶段。最后,我们构建一个大的三明治,使用所有这些自编码器,如图 17-7 所示(即,我们首先堆叠每个自编码器的隐藏层,然后反向堆叠输出层)。这给我们最终的堆叠自编码器(请参阅本章笔记本中“逐个训练自编码器”部分以获取实现)。通过这种方式,我们可以轻松训练更多的自编码器,构建一个非常深的堆叠自编码器。
正如我之前提到的,深度学习浪潮的一个触发因素是Geoffrey Hinton 等人在 2006 年发现深度神经网络可以通过无监督的方式进行预训练,使用这种贪婪的逐层方法。他们用受限玻尔兹曼机(RBMs;参见https://homl.info/extra-anns)来实现这一目的,但在 2007 年Yoshua Bengio 等人²表明自编码器同样有效。几年来,这是训练深度网络的唯一有效方式,直到第十一章中引入的许多技术使得可以一次性训练深度网络。
自编码器不仅限于密集网络:你也可以构建卷积自编码器。现在让我们来看看这些。
卷积自编码器
如果你处理的是图像,那么迄今为止我们看到的自编码器效果不佳(除非图像非常小):正如你在第十四章中看到的,卷积神经网络比密集网络更适合处理图像。因此,如果你想为图像构建一个自编码器(例如用于无监督预训练或降维),你将需要构建一个卷积自编码器。³ 编码器是由卷积层和池化层组成的常规 CNN。它通常减少输入的空间维度(即高度和宽度),同时增加深度(即特征图的数量)。解码器必须执行相反操作(放大图像并将其深度降至原始维度),为此你可以使用转置卷积层(或者,你可以将上采样层与卷积层结合)。以下是 Fashion MNIST 的基本卷积自编码器:
conv_encoder = tf.keras.Sequential([tf.keras.layers.Reshape([28, 28, 1]),tf.keras.layers.Conv2D(16, 3, padding="same", activation="relu"),tf.keras.layers.MaxPool2D(pool_size=2), # output: 14 × 14 x 16tf.keras.layers.Conv2D(32, 3, padding="same", activation="relu"),tf.keras.layers.MaxPool2D(pool_size=2), # output: 7 × 7 x 32tf.keras.layers.Conv2D(64, 3, padding="same", activation="relu"),tf.keras.layers.MaxPool2D(pool_size=2), # output: 3 × 3 x 64tf.keras.layers.Conv2D(30, 3, padding="same", activation="relu"),tf.keras.layers.GlobalAvgPool2D() # output: 30
])
conv_decoder = tf.keras.Sequential([tf.keras.layers.Dense(3 * 3 * 16),tf.keras.layers.Reshape((3, 3, 16)),tf.keras.layers.Conv2DTranspose(32, 3, strides=2, activation="relu"),tf.keras.layers.Conv2DTranspose(16, 3, strides=2, padding="same",activation="relu"),tf.keras.layers.Conv2DTranspose(1, 3, strides=2, padding="same"),tf.keras.layers.Reshape([28, 28])
])
conv_ae = tf.keras.Sequential([conv_encoder, conv_decoder])
还可以使用其他架构类型创建自编码器,例如 RNNs(请参阅笔记本中的示例)。
好的,让我们退后一步。到目前为止,我们已经看过各种类型的自编码器(基本、堆叠和卷积),以及如何训练它们(一次性或逐层)。我们还看过一些应用:数据可视化和无监督预训练。
迄今为止,为了强迫自编码器学习有趣的特征,我们限制了编码层的大小,使其欠完备。实际上还有许多其他类型的约束可以使用,包括允许编码层与输入一样大,甚至更大,从而产生过完备自编码器。接下来,我们将看一些其他类型的自编码器:去噪自编码器、稀疏自编码器和变分自编码器。
去噪自编码器
另一种强制自编码器学习有用特征的方法是向其输入添加噪声,训练它恢复原始的无噪声输入。这个想法自上世纪 80 年代就存在了(例如,Yann LeCun 在 1987 年的硕士论文中提到了这一点)。在2008 年的一篇论文中,Pascal Vincent 等人表明自编码器也可以用于特征提取。在2010 年的一篇论文中,Vincent 等人介绍了堆叠去噪自编码器。
噪声可以是添加到输入的纯高斯噪声,也可以是随机关闭的输入,就像 dropout 中一样(在第十一章中介绍)。图 17-8 展示了这两种选项。
实现很简单:这是一个常规的堆叠自编码器,附加了一个Dropout层应用于编码器的输入(或者您可以使用一个GaussianNoise层)。请记住,Dropout层仅在训练期间激活(GaussianNoise层也是如此):
dropout_encoder = tf.keras.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(100, activation="relu"),tf.keras.layers.Dense(30, activation="relu")
])
dropout_decoder = tf.keras.Sequential([tf.keras.layers.Dense(100, activation="relu"),tf.keras.layers.Dense(28 * 28),tf.keras.layers.Reshape([28, 28])
])
dropout_ae = tf.keras.Sequential([dropout_encoder, dropout_decoder])
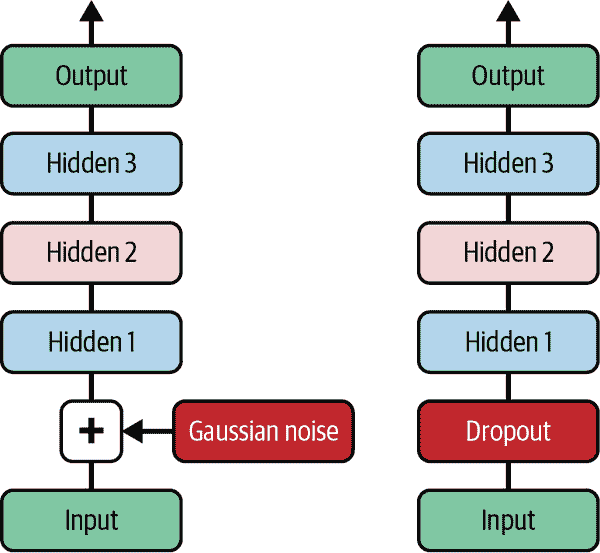
图 17-8。去噪自编码器,带有高斯噪声(左)或 dropout(右)
图 17-9 显示了一些嘈杂的图像(一半像素关闭),以及基于 dropout 的去噪自编码器重建的图像。请注意,自编码器猜测了实际输入中不存在的细节,例如白色衬衫的顶部(底部行,第四幅图)。正如您所看到的,去噪自编码器不仅可以用于数据可视化或无监督预训练,就像我们迄今讨论过的其他自编码器一样,而且还可以非常简单高效地从图像中去除噪声。

图 17-9。嘈杂的图像(顶部)及其重建(底部)
稀疏自编码器
另一种通常导致良好特征提取的约束是稀疏性:通过向成本函数添加适当的项,自编码器被推动减少编码层中活跃神经元的数量。例如,它可能被推动使编码层中平均只有 5%的显著活跃神经元。这迫使自编码器将每个输入表示为少量激活的组合。结果,编码层中的每个神经元通常最终代表一个有用的特征(如果您每个月只能说几个词,您可能会尽量使它们值得倾听)。
一个简单的方法是在编码层中使用 sigmoid 激活函数(将编码限制在 0 到 1 之间),使用一个大的编码层(例如,具有 300 个单元),并向编码层的激活添加一些ℓ[1]正则化。解码器只是一个常规的解码器:
sparse_l1_encoder = tf.keras.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(100, activation="relu"),tf.keras.layers.Dense(300, activation="sigmoid"),tf.keras.layers.ActivityRegularization(l1=1e-4)
])
sparse_l1_decoder = tf.keras.Sequential([tf.keras.layers.Dense(100, activation="relu"),tf.keras.layers.Dense(28 * 28),tf.keras.layers.Reshape([28, 28])
])
sparse_l1_ae = tf.keras.Sequential([sparse_l1_encoder, sparse_l1_decoder])
这个ActivityRegularization层只是返回其输入,但作为副作用,它会添加一个训练损失,等于其输入的绝对值之和。这只影响训练。同样,您可以删除ActivityRegularization层,并在前一层中设置activity_regularizer=tf.keras.regularizers.l1(1e-4)。这种惩罚将鼓励神经网络生成接近 0 的编码,但由于如果不能正确重建输入也会受到惩罚,因此它必须输出至少几个非零值。使用ℓ[1]范数而不是ℓ[2]范数将推动神经网络保留最重要的编码,同时消除不需要的编码(而不仅仅是减少所有编码)。
另一种方法,通常会产生更好的结果,是在每次训练迭代中测量编码层的实际稀疏度,并在测量到的稀疏度与目标稀疏度不同时对模型进行惩罚。我们通过计算编码层中每个神经元的平均激活值来实现这一点,整个训练批次上。批次大小不能太小,否则平均值将不准确。
一旦我们有了每个神经元的平均激活,我们希望通过向成本函数添加稀疏损失来惩罚那些激活过多或不足的神经元。例如,如果我们测量到一个神经元的平均激活为 0.3,但目标稀疏度为 0.1,那么它必须受到惩罚以减少激活。一种方法可能是简单地将平方误差(0.3 - 0.1)²添加到成本函数中,但实际上更好的方法是使用 Kullback–Leibler (KL)散度(在第四章中简要讨论),它比均方误差具有更强的梯度,如您可以在图 17-10 中看到的那样。
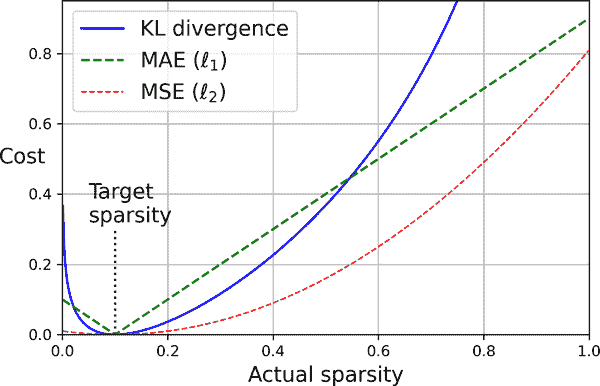
图 17-10. 稀疏损失
给定两个离散概率分布P和Q,这些分布之间的 KL 散度,记为DKL,可以使用方程 17-1 计算。
方程 17-1. Kullback–Leibler 散度
D KL ( P ∥ Q ) = ∑ i P ( i ) log P(i) Q(i)
在我们的情况下,我们想要衡量编码层中神经元激活的目标概率p和通过测量整个训练批次上的平均激活来估计的实际概率q之间的差异。因此,KL 散度简化为方程 17-2。
方程 17-2. 目标稀疏度p和实际稀疏度q之间的 KL 散度
D KL ( p ∥ q ) = p log p q + ( 1 - p ) log 1-p 1-q
一旦我们计算了编码层中每个神经元的稀疏损失,我们将这些损失相加并将结果添加到成本函数中。为了控制稀疏损失和重构损失的相对重要性,我们可以将稀疏损失乘以一个稀疏权重超参数。如果这个权重太高,模型将严格遵循目标稀疏度,但可能无法正确重构输入,使模型无用。相反,如果权重太低,模型将主要忽略稀疏目标,并且不会学习任何有趣的特征。
现在我们有了所有需要基于 KL 散度实现稀疏自编码器的东西。首先,让我们创建一个自定义正则化器来应用 KL 散度正则化:
kl_divergence = tf.keras.losses.kullback_leibler_divergenceclass KLDivergenceRegularizer(tf.keras.regularizers.Regularizer):def __init__(self, weight, target):self.weight = weightself.target = targetdef __call__(self, inputs):mean_activities = tf.reduce_mean(inputs, axis=0)return self.weight * (kl_divergence(self.target, mean_activities) +kl_divergence(1. - self.target, 1. - mean_activities))
现在我们可以构建稀疏自编码器,使用KLDivergenceRegularizer来对编码层的激活进行正则化:
kld_reg = KLDivergenceRegularizer(weight=5e-3, target=0.1)
sparse_kl_encoder = tf.keras.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(100, activation="relu"),tf.keras.layers.Dense(300, activation="sigmoid",activity_regularizer=kld_reg)
])
sparse_kl_decoder = tf.keras.Sequential([tf.keras.layers.Dense(100, activation="relu"),tf.keras.layers.Dense(28 * 28),tf.keras.layers.Reshape([28, 28])
])
sparse_kl_ae = tf.keras.Sequential([sparse_kl_encoder, sparse_kl_decoder])
在 Fashion MNIST 上训练这个稀疏自编码器后,编码层的稀疏度大约为 10%。
变分自编码器
2013 年,Diederik Kingma 和 Max Welling⁶引入了一个重要类别的自编码器,并迅速成为最受欢迎的变体之一:变分自编码器(VAEs)。
VAEs 在这些特定方面与我们迄今讨论过的所有自编码器都有很大不同:
-
它们是概率自编码器,这意味着它们的输出在训练后部分地由机会决定(与去噪自编码器相反,在训练期间仅使用随机性)。
-
最重要的是,它们是生成自编码器,这意味着它们可以生成看起来像是从训练集中采样的新实例。
这两个特性使得 VAEs 与 RBM 相当相似,但它们更容易训练,采样过程也更快(对于 RBM,您需要等待网络稳定到“热平衡”状态,然后才能对新实例进行采样)。正如它们的名字所暗示的,变分自编码器执行变分贝叶斯推断,这是进行近似贝叶斯推断的有效方法。回想一下,贝叶斯推断意味着根据新数据更新概率分布,使用从贝叶斯定理推导出的方程。原始分布称为先验,而更新后的分布称为后验。在我们的情况下,我们想要找到数据分布的一个很好的近似。一旦我们有了这个,我们就可以从中进行采样。
让我们看看 VAEs 是如何工作的。图 17-11(左)展示了一个变分自编码器。您可以认出所有自编码器的基本结构,具有一个编码器后面跟着一个解码器(在这个例子中,它们都有两个隐藏层),但有一个转折:编码器不是直接为给定输入产生编码,而是产生一个均值编码 μ 和一个标准差 σ。然后,实际编码随机地从均值 μ 和标准差 σ 的高斯分布中采样。之后解码器正常解码采样的编码。图的右侧显示了一个训练实例通过这个自编码器的过程。首先,编码器产生 μ 和 σ,然后一个编码被随机采样(请注意它并不完全位于 μ),最后这个编码被解码;最终输出类似于训练实例。
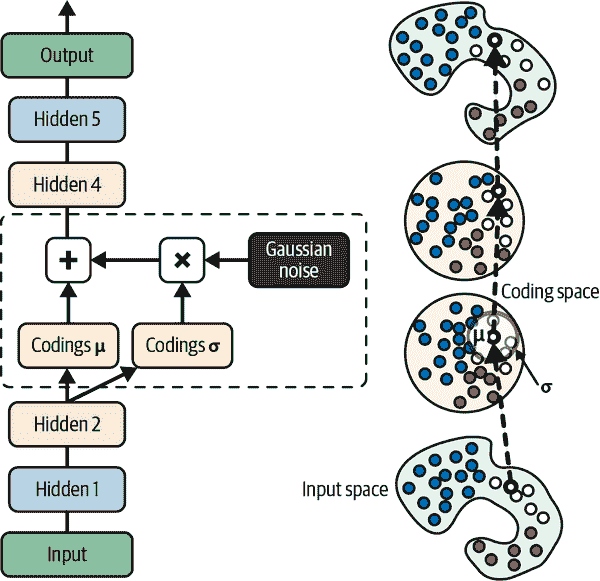
图 17-11. 变分自编码器(左)和通过它的实例(右)
正如您在图中所看到的,尽管输入可能具有非常复杂的分布,但变分自编码器倾向于产生看起来像是从简单的高斯分布中采样的编码:⁷在训练期间,成本函数(下面讨论)推动编码逐渐在编码空间(也称为潜在空间)内迁移,最终看起来像一个高斯点云。一个很大的结果是,在训练变分自编码器之后,您可以非常容易地生成一个新实例:只需从高斯分布中随机采样一个随机编码,解码它,然后就完成了!
现在,让我们看一下成本函数。它由两部分组成。第一部分是通常的重构损失,推动自编码器重现其输入。我们可以使用 MSE 来实现这一点,就像我们之前做的那样。第二部分是潜在损失,推动自编码器具有看起来像是从简单高斯分布中抽样的编码:这是目标分布(即高斯分布)与编码的实际分布之间的 KL 散度。数学比稀疏自编码器更复杂,特别是由于高斯噪声,它限制了可以传输到编码层的信息量。这推动自编码器学习有用的特征。幸运的是,方程简化了,因此可以使用 Equation 17-3 计算潜在损失。⁸
方程 17-3。变分自编码器的潜在损失
L=-12∑i=1n1+log(σi2)-σi2-μi2
在这个方程中,ℒ是潜在损失,n是编码的维度,μ[i]和σ[i]是编码的第i个分量的均值和标准差。向量μ和σ(包含所有μ[i]和σ[i])由编码器输出,如 Figure 17-11(左)所示。
变分自编码器架构的常见调整是使编码器输出γ = log(σ²)而不是σ。然后可以根据 Equation 17-4 计算潜在损失。这种方法在数值上更稳定,加快了训练速度。
方程 17-4。变分自编码器的潜在损失,使用γ = log(σ²)重写
L=-12∑i=1n1+γi-exp(γi)-μi2
现在,让我们开始为 Fashion MNIST 构建一个变分自编码器(如 Figure 17-11 所示,但使用γ调整)。首先,我们需要一个自定义层来根据μ和γ抽样编码:
class Sampling(tf.keras.layers.Layer):def call(self, inputs):mean, log_var = inputsreturn tf.random.normal(tf.shape(log_var)) * tf.exp(log_var / 2) + mean
这个Sampling层接受两个输入:mean(μ)和log_var(γ)。它使用函数tf.random.normal()从均值为 0,标准差为 1 的高斯分布中抽样一个随机向量(与γ形状相同)。然后将其乘以 exp(γ / 2)(数学上等于σ,您可以验证),最后加上μ并返回结果。这样从均值为μ,标准差为σ的高斯分布中抽样一个编码向量。
接下来,我们可以创建编码器,使用函数式 API,因为模型不是完全顺序的:
codings_size = 10inputs = tf.keras.layers.Input(shape=[28, 28])
Z = tf.keras.layers.Flatten()(inputs)
Z = tf.keras.layers.Dense(150, activation="relu")(Z)
Z = tf.keras.layers.Dense(100, activation="relu")(Z)
codings_mean = tf.keras.layers.Dense(codings_size)(Z) # μ
codings_log_var = tf.keras.layers.Dense(codings_size)(Z) # γ
codings = Sampling()([codings_mean, codings_log_var])
variational_encoder = tf.keras.Model(inputs=[inputs], outputs=[codings_mean, codings_log_var, codings])
注意,输出codings_mean(μ)和codings_log_var(γ)的Dense层具有相同的输入(即第二个Dense层的输出)。然后,我们将codings_mean和codings_log_var都传递给Sampling层。最后,variational_encoder模型有三个输出。只需要codings,但我们也添加了codings_mean和codings_log_var,以防我们想要检查它们的值。现在让我们构建解码器:
decoder_inputs = tf.keras.layers.Input(shape=[codings_size])
x = tf.keras.layers.Dense(100, activation="relu")(decoder_inputs)
x = tf.keras.layers.Dense(150, activation="relu")(x)
x = tf.keras.layers.Dense(28 * 28)(x)
outputs = tf.keras.layers.Reshape([28, 28])(x)
variational_decoder = tf.keras.Model(inputs=[decoder_inputs], outputs=[outputs])
对于这个解码器,我们可以使用顺序 API 而不是功能 API,因为它实际上只是一个简单的层堆栈,与我们迄今构建的许多解码器几乎相同。最后,让我们构建变分自编码器模型:
_, _, codings = variational_encoder(inputs)
reconstructions = variational_decoder(codings)
variational_ae = tf.keras.Model(inputs=[inputs], outputs=[reconstructions])
我们忽略编码器的前两个输出(我们只想将编码输入解码器)。最后,我们必须添加潜在损失和重构损失:
latent_loss = -0.5 * tf.reduce_sum(1 + codings_log_var - tf.exp(codings_log_var) - tf.square(codings_mean),axis=-1)
variational_ae.add_loss(tf.reduce_mean(latent_loss) / 784.)
我们首先应用方程 17-4 来计算批处理中每个实例的潜在损失,对最后一个轴求和。然后我们计算批处理中所有实例的平均损失,并将结果除以 784,以确保它具有适当的比例,与重构损失相比。实际上,变分自编码器的重构损失应该是像素重构误差的总和,但是当 Keras 计算"mse"损失时,它计算所有 784 个像素的平均值,而不是总和。因此,重构损失比我们需要的要小 784 倍。我们可以定义一个自定义损失来计算总和而不是平均值,但将潜在损失除以 784(最终损失将比应该的大 784 倍,但这只是意味着我们应该使用更大的学习率)更简单。
最后,我们可以编译和拟合自编码器!
variational_ae.compile(loss="mse", optimizer="nadam")
history = variational_ae.fit(X_train, X_train, epochs=25, batch_size=128,validation_data=(X_valid, X_valid))
生成时尚 MNIST 图像
现在让我们使用这个变分自编码器生成看起来像时尚物品的图像。我们只需要从高斯分布中随机采样编码,并解码它们:
codings = tf.random.normal(shape=[3 * 7, codings_size])
images = variational_decoder(codings).numpy()
图 17-12 显示了生成的 12 张图像。

图 17-12. 由变分自编码器生成的时尚 MNIST 图像
这些图像中的大多数看起来相当令人信服,虽然有点模糊。其余的不太好,但不要对自编码器太苛刻——它只有几分钟时间学习!
变分自编码器使得执行语义插值成为可能:不是在像素级别插值两个图像,看起来就像两个图像只是叠加在一起,我们可以在编码级别进行插值。例如,让我们在潜在空间中沿着任意线取几个编码,并解码它们。我们得到一系列图像,逐渐从裤子变成毛衣(见图 17-13):
codings = np.zeros([7, codings_size])
codings[:, 3] = np.linspace(-0.8, 0.8, 7) # axis 3 looks best in this case
images = variational_decoder(codings).numpy()

图 17-13. 语义插值
现在让我们转向 GANs:它们更难训练,但当你设法让它们工作时,它们会产生非常惊人的图像。
生成对抗网络
生成对抗网络是由 Ian Goodfellow 等人在2014 年的一篇论文中提出的⁹,尽管这个想法几乎立即激发了研究人员的兴趣,但要克服训练 GANs 的一些困难还需要几年时间。就像许多伟大的想法一样,事后看来似乎很简单:让神经网络相互竞争,希望这种竞争能推动它们取得卓越的成就。如图 17-14 所示,GAN 由两个神经网络组成:
生成器
以随机分布(通常是高斯)作为输入,并输出一些数据——通常是图像。您可以将随机输入视为要生成的图像的潜在表示(即编码)。因此,正如您所看到的,生成器提供了与变分自编码器中的解码器相同的功能,并且可以以相同的方式用于生成新图像:只需将一些高斯噪声输入,它就会输出一个全新的图像。但是,它的训练方式非常不同,您很快就会看到。
鉴别器
以生成器的假图像或训练集中的真实图像作为输入,必须猜测输入图像是假还是真。
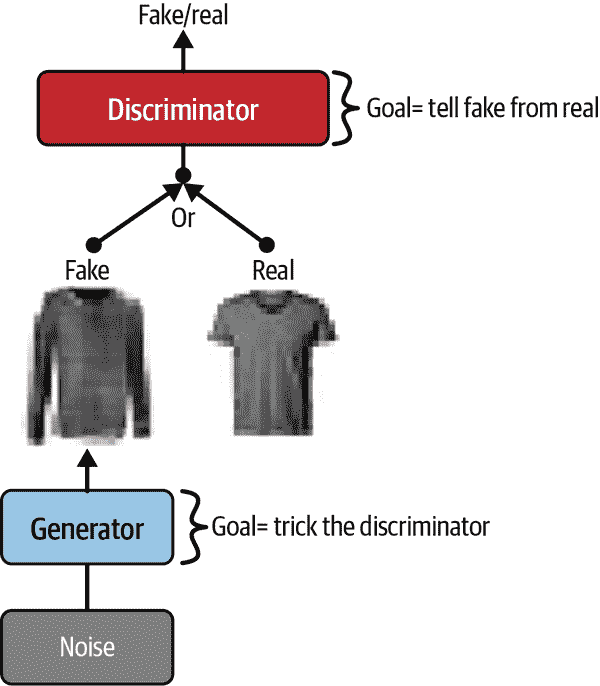
图 17-14. 生成对抗网络
在训练过程中,生成器和鉴别器有着相反的目标:鉴别器试图区分假图像和真实图像,而生成器试图生成看起来足够真实以欺骗鉴别器的图像。由于 GAN 由具有不同目标的两个网络组成,因此无法像训练常规神经网络那样进行训练。每个训练迭代被分为两个阶段:
-
在第一阶段,我们训练鉴别器。从训练集中抽取一批真实图像,并通过生成器生成相同数量的假图像来完成。标签设置为 0 表示假图像,1 表示真实图像,并且鉴别器在这个带标签的批次上进行一步训练,使用二元交叉熵损失。重要的是,在这个阶段只有鉴别器的权重被优化。
-
在第二阶段,我们训练生成器。我们首先使用它生成另一批假图像,然后再次使用鉴别器来判断图像是假的还是真实的。这次我们不在批次中添加真实图像,所有标签都设置为 1(真实):换句话说,我们希望生成器生成鉴别器会(错误地)认为是真实的图像!在这一步骤中,鉴别器的权重被冻结,因此反向传播只影响生成器的权重。
注意
生成器实际上从未看到任何真实图像,但它逐渐学会生成令人信服的假图像!它所得到的只是通过鉴别器反向传播的梯度。幸运的是,鉴别器越好,这些二手梯度中包含的关于真实图像的信息就越多,因此生成器可以取得显著进展。
让我们继续构建一个简单的 Fashion MNIST GAN。
首先,我们需要构建生成器和鉴别器。生成器类似于自编码器的解码器,鉴别器是一个常规的二元分类器:它以图像作为输入,最终以包含单个单元并使用 sigmoid 激活函数的Dense层结束。对于每个训练迭代的第二阶段,我们还需要包含生成器后面的鉴别器的完整 GAN 模型:
codings_size = 30Dense = tf.keras.layers.Dense
generator = tf.keras.Sequential([Dense(100, activation="relu", kernel_initializer="he_normal"),Dense(150, activation="relu", kernel_initializer="he_normal"),Dense(28 * 28, activation="sigmoid"),tf.keras.layers.Reshape([28, 28])
])
discriminator = tf.keras.Sequential([tf.keras.layers.Flatten(),Dense(150, activation="relu", kernel_initializer="he_normal"),Dense(100, activation="relu", kernel_initializer="he_normal"),Dense(1, activation="sigmoid")
])
gan = tf.keras.Sequential([generator, discriminator])
接下来,我们需要编译这些模型。由于鉴别器是一个二元分类器,我们可以自然地使用二元交叉熵损失。gan模型也是一个二元分类器,因此它也可以使用二元交叉熵损失。然而,生成器只会通过gan模型进行训练,因此我们根本不需要编译它。重要的是,在第二阶段之前鉴别器不应该被训练,因此在编译gan模型之前我们将其设置为不可训练:
discriminator.compile(loss="binary_crossentropy", optimizer="rmsprop")
discriminator.trainable = False
gan.compile(loss="binary_crossentropy", optimizer="rmsprop")
注意
trainable属性只有在编译模型时才会被 Keras 考虑,因此在运行此代码后,如果我们调用其fit()方法或train_on_batch()方法(我们将使用),则discriminator是可训练的,而在调用这些方法时gan模型是不可训练的。
由于训练循环是不寻常的,我们不能使用常规的fit()方法。相反,我们将编写一个自定义训练循环。为此,我们首先需要创建一个Dataset来迭代图像:
batch_size = 32
dataset = tf.data.Dataset.from_tensor_slices(X_train).shuffle(buffer_size=1000)
dataset = dataset.batch(batch_size, drop_remainder=True).prefetch(1)
现在我们准备编写训练循环。让我们将其封装在一个train_gan()函数中:
def train_gan(gan, dataset, batch_size, codings_size, n_epochs):generator, discriminator = gan.layersfor epoch in range(n_epochs):for X_batch in dataset:# phase 1 - training the discriminatornoise = tf.random.normal(shape=[batch_size, codings_size])generated_images = generator(noise)X_fake_and_real = tf.concat([generated_images, X_batch], axis=0)y1 = tf.constant([[0.]] * batch_size + [[1.]] * batch_size)discriminator.train_on_batch(X_fake_and_real, y1)# phase 2 - training the generatornoise = tf.random.normal(shape=[batch_size, codings_size])y2 = tf.constant([[1.]] * batch_size)gan.train_on_batch(noise, y2)train_gan(gan, dataset, batch_size, codings_size, n_epochs=50)
正如之前讨论的,您可以在每次迭代中看到两个阶段:
-
在第一阶段,我们向生成器提供高斯噪声以生成假图像,并通过连接相同数量的真实图像来完成这一批次。目标
y1设置为 0 表示假图像,1 表示真实图像。然后我们对这一批次训练鉴别器。请记住,在这个阶段鉴别器是可训练的,但我们不会触及生成器。 -
在第二阶段,我们向 GAN 提供一些高斯噪声。其生成器将开始生成假图像,然后鉴别器将尝试猜测这些图像是假还是真实的。在这个阶段,我们试图改进生成器,这意味着我们希望鉴别器失败:这就是为什么目标
y2都设置为 1,尽管图像是假的。在这个阶段,鉴别器是不可训练的,因此gan模型中唯一会改进的部分是生成器。
就是这样!训练后,您可以随机从高斯分布中抽取一些编码,并将它们馈送给生成器以生成新图像:
codings = tf.random.normal(shape=[batch_size, codings_size])
generated_images = generator.predict(codings)
如果显示生成的图像(参见图 17-15),您会发现在第一个时期结束时,它们已经开始看起来像(非常嘈杂的)时尚 MNIST 图像。

图 17-15。在训练一个时期后由 GAN 生成的图像
不幸的是,图像从未真正比那更好,甚至可能会出现 GAN 似乎忘记了它学到的东西的时期。为什么会这样呢?原来,训练 GAN 可能是具有挑战性的。让我们看看为什么。
训练 GAN 的困难
在训练过程中,生成器和鉴别器不断试图在零和博弈中互相智胜。随着训练的进行,游戏可能会进入博弈论家称之为纳什均衡的状态,以数学家约翰·纳什命名:这是当没有玩家会因为改变自己的策略而变得更好,假设其他玩家不改变自己的策略。例如,当每个人都在道路的左侧行驶时,就达到了纳什均衡:没有司机会因为成为唯一一个换边的人而变得更好。当然,还有第二种可能的纳什均衡:当每个人都在道路的右侧行驶时。不同的初始状态和动态可能导致一个或另一个均衡。在这个例子中,一旦达到均衡状态(即,与其他人一样在同一侧行驶),就会有一个单一的最佳策略,但是纳什均衡可能涉及多种竞争策略(例如,捕食者追逐猎物,猎物试图逃跑,双方都不会因为改变策略而变得更好)。
那么这如何应用于 GAN 呢?嗯,GAN 论文的作者们证明了 GAN 只能达到单一的纳什均衡:那就是生成器生成完全逼真的图像,鉴别器被迫猜测(50%真实,50%假)。这个事实非常令人鼓舞:似乎只需要训练足够长的时间,它最终会达到这种均衡,为您提供一个完美的生成器。不幸的是,事情并不那么简单:没有任何保证这种均衡会被达到。
最大的困难被称为模式坍塌:这是指生成器的输出逐渐变得不那么多样化。这是如何发生的呢?假设生成器在制作令人信服的鞋子方面比其他任何类别都更擅长。它会用鞋子更多地欺骗鉴别器,这将鼓励它生成更多的鞋子图像。逐渐地,它会忘记如何制作其他任何东西。与此同时,鉴别器将看到的唯一假图像将是鞋子,因此它也会忘记如何鉴别其他类别的假图像。最终,当鉴别器设法将假鞋子与真实鞋子区分开来时,生成器将被迫转向另一个类别。然后它可能擅长衬衫,忘记鞋子,鉴别器也会跟随。GAN 可能逐渐在几个类别之间循环,从未真正擅长其中任何一个。
此外,由于生成器和鉴别器不断相互对抗,它们的参数可能最终会振荡并变得不稳定。训练可能开始正常,然后由于这些不稳定性,突然出现无明显原因的分歧。由于许多因素影响这些复杂的动态,GAN 对超参数非常敏感:您可能需要花费大量精力对其进行微调。实际上,这就是为什么在编译模型时我使用 RMSProp 而不是 Nadam:使用 Nadam 时,我遇到了严重的模式崩溃。
自 2014 年以来,这些问题一直让研究人员忙碌不已:许多论文已经发表在这个主题上,一些论文提出了新的成本函数(尽管谷歌研究人员在2018 年的一篇论文中质疑了它们的效率)或稳定训练或避免模式崩溃问题的技术。例如,一种流行的技术称为经验重播,它包括在每次迭代中存储生成器生成的图像在重播缓冲区中(逐渐删除较旧的生成图像),并使用来自该缓冲区的真实图像加上假图像来训练鉴别器(而不仅仅是当前生成器生成的假图像)。这减少了鉴别器过度拟合最新生成器输出的机会。另一种常见的技术称为小批量鉴别:它测量批次中图像的相似性,并将此统计信息提供给鉴别器,以便它可以轻松拒绝缺乏多样性的整个批次的假图像。这鼓励生成器产生更多样化的图像,减少模式崩溃的机会。其他论文简单地提出了表现良好的特定架构。
简而言之,这仍然是一个非常活跃的研究领域,GAN 的动态仍然没有完全被理解。但好消息是取得了巨大进展,一些结果真的令人惊叹!因此,让我们看一些最成功的架构,从几年前的深度卷积 GAN 开始。然后我们将看一下两个更近期(更复杂)的架构。
深度卷积 GAN
原始 GAN 论文的作者尝试了卷积层,但只尝试生成小图像。不久之后,许多研究人员尝试基于更深的卷积网络生成更大的图像的 GAN。这被证明是棘手的,因为训练非常不稳定,但 Alec Radford 等人最终在 2015 年底成功了,经过许多不同架构和超参数的实验。他们将其架构称为深度卷积 GAN(DCGANs)。以下是他们为构建稳定的卷积 GAN 提出的主要准则:
-
用步进卷积(在鉴别器中)和转置卷积(在生成器中)替换任何池化层。
-
在生成器和鉴别器中使用批量归一化,除了生成器的输出层和鉴别器的输入层。
-
删除更深层次架构的全连接隐藏层。
-
在生成器的所有层中使用 ReLU 激活,除了输出层应使用 tanh。
-
在鉴别器的所有层中使用泄漏 ReLU 激活。
这些准则在许多情况下都适用,但并非总是如此,因此您可能仍需要尝试不同的超参数。实际上,仅仅改变随机种子并再次训练完全相同的模型有时会奏效。以下是一个在时尚 MNIST 上表现相当不错的小型 DCGAN:
codings_size = 100generator = tf.keras.Sequential([tf.keras.layers.Dense(7 * 7 * 128),tf.keras.layers.Reshape([7, 7, 128]),tf.keras.layers.BatchNormalization(),tf.keras.layers.Conv2DTranspose(64, kernel_size=5, strides=2,padding="same", activation="relu"),tf.keras.layers.BatchNormalization(),tf.keras.layers.Conv2DTranspose(1, kernel_size=5, strides=2,padding="same", activation="tanh"),
])
discriminator = tf.keras.Sequential([tf.keras.layers.Conv2D(64, kernel_size=5, strides=2, padding="same",activation=tf.keras.layers.LeakyReLU(0.2)),tf.keras.layers.Dropout(0.4),tf.keras.layers.Conv2D(128, kernel_size=5, strides=2, padding="same",activation=tf.keras.layers.LeakyReLU(0.2)),tf.keras.layers.Dropout(0.4),tf.keras.layers.Flatten(),tf.keras.layers.Dense(1, activation="sigmoid")
])
gan = tf.keras.Sequential([generator, discriminator])
生成器接受大小为 100 的编码,将其投影到 6,272 维度(7 * 7 * 128),并重新整形结果以获得一个 7×7×128 张量。这个张量被批量归一化并馈送到一个步幅为 2 的转置卷积层,将其从 7×7 上采样到 14×14,并将其深度从 128 减少到 64。结果再次进行批量归一化,并馈送到另一个步幅为 2 的转置卷积层,将其从 14×14 上采样到 28×28,并将深度从 64 减少到 1。这一层使用 tanh 激活函数,因此输出将范围从-1 到 1。因此,在训练 GAN 之前,我们需要将训练集重新缩放到相同的范围。我们还需要重新整形以添加通道维度:
X_train_dcgan = X_train.reshape(-1, 28, 28, 1) * 2. - 1. # reshape and rescale
鉴别器看起来很像用于二元分类的常规 CNN,只是不是使用最大池化层来对图像进行下采样,而是使用步幅卷积(strides=2)。请注意,我们使用了泄漏的 ReLU 激活函数。总体而言,我们遵守了 DCGAN 的指导方针,只是将鉴别器中的BatchNormalization层替换为Dropout层;否则,在这种情况下训练会不稳定。随意调整这个架构:您将看到它对超参数非常敏感,特别是两个网络的相对学习率。
最后,要构建数据集,然后编译和训练这个模型,我们可以使用之前的相同代码。经过 50 个训练周期后,生成器产生的图像如图 17-16 所示。它还不完美,但其中许多图像相当令人信服。

图 17-16。DCGAN 在训练 50 个周期后生成的图像
如果您扩大这个架构并在大量人脸数据集上进行训练,您可以获得相当逼真的图像。事实上,DCGAN 可以学习相当有意义的潜在表示,如图 17-17 所示:生成了许多图像,手动选择了其中的九个(左上角),包括三个戴眼镜的男性,三个不戴眼镜的男性和三个不戴眼镜的女性。对于这些类别中的每一个,用于生成图像的编码被平均,然后基于结果的平均编码生成图像(左下角)。简而言之,左下角的三幅图像分别代表位于其上方的三幅图像的平均值。但这不是在像素级别计算的简单平均值(这将导致三个重叠的脸),而是在潜在空间中计算的平均值,因此图像看起来仍然像正常的脸。令人惊讶的是,如果您计算戴眼镜的男性,减去不戴眼镜的男性,再加上不戴眼镜的女性——其中每个术语对应于一个平均编码——并生成对应于此编码的图像,您将得到右侧面孔网格中心的图像:一个戴眼镜的女性!其周围的其他八幅图像是基于相同向量加上一点噪音生成的,以展示 DCGAN 的语义插值能力。能够在人脸上进行算术运算感觉像是科幻!
然而,DCGAN 并不完美。例如,当您尝试使用 DCGAN 生成非常大的图像时,通常会出现局部令人信服的特征,但整体上存在不一致,比如一只袖子比另一只长得多的衬衫,不同的耳环,或者眼睛看向相反的方向。您如何解决这个问题?
图 17-17。视觉概念的向量算术(DCGAN 论文中的第 7 部分图)¹³
提示
如果将每个图像的类别作为额外输入添加到生成器和鉴别器中,它们将学习每个类别的外观,因此您将能够控制生成器生成的每个图像的类别。这被称为条件 GAN(CGAN)。¹⁴
GAN 的渐进增长
在一篇2018 年的论文,Nvidia 的研究人员 Tero Kerras 等人提出了一项重要技术:他们建议在训练开始时生成小图像,然后逐渐向生成器和鉴别器添加卷积层,以生成越来越大的图像(4×4、8×8、16×16,…,512×512、1,024×1,024)。这种方法类似于贪婪逐层训练堆叠自编码器。额外的层被添加到生成器的末尾和鉴别器的开头,并且之前训练过的层仍然可训练。
例如,当将生成器的输出从 4×4 增加到 8×8 时(参见图 17-18),在现有卷积层(“Conv 1”)中添加了一个上采样层(使用最近邻过滤)以生成 8×8 特征图。这些被馈送到新的卷积层(“Conv 2”),然后馈送到新的输出卷积层。为了避免破坏 Conv 1 的训练权重,我们逐渐淡入两个新的卷积层(在图 17-18 中用虚线表示),并淡出原始输出层。最终输出是新输出(权重为α)和原始输出(权重为 1-α)的加权和,从 0 逐渐增加α到 1。当向鉴别器添加新的卷积层时(后跟一个平均池化层进行下采样),也使用类似的淡入/淡出技术。请注意,所有卷积层都使用"same"填充和步幅为 1,因此它们保留其输入的高度和宽度。这包括原始卷积层,因此它现在产生 8×8 的输出(因为其输入现在是 8×8)。最后,输出层使用核大小为 1。它们只是将它们的输入投影到所需数量的颜色通道(通常为 3)。
图 17-18。逐渐增长的 GAN:GAN 生成器输出 4×4 彩色图像(左);我们将其扩展到输出 8×8 图像(右)
该论文还介绍了几种旨在增加输出多样性(以避免模式崩溃)并使训练更稳定的技术:
小批量标准差层
添加到鉴别器的末尾附近。对于输入中的每个位置,它计算批次中所有通道和所有实例的标准差(S = tf.math.reduce_std(inputs, axis=[0, -1]))。然后,这些标准差在所有点上进行平均以获得单个值(v = tf.reduce_mean(S))。最后,在批次中的每个实例中添加一个额外的特征图,并填充计算出的值(tf.concat([inputs, tf.fill([batch_size, height, width, 1], v)], axis=-1))。这有什么帮助呢?如果生成器生成具有很少变化的图像,那么在鉴别器的特征图中将会有很小的标准差。由于这一层,鉴别器将更容易访问这个统计数据,使得它不太可能被生成器欺骗,生成器产生的多样性太少。这将鼓励生成器产生更多样化的输出,减少模式崩溃的风险。
均衡学习率
使用均值为 0,标准差为 1 的高斯分布初始化所有权重,而不是使用 He 初始化。然而,在运行时(即每次执行该层时),权重会按照 He 初始化的相同因子进行缩放:它们会被除以2ninputs,其中n[inputs]是该层的输入数量。论文表明,当使用 RMSProp、Adam 或其他自适应梯度优化器时,这种技术显著提高了 GAN 的性能。实际上,这些优化器通过其估计的标准偏差对梯度更新进行归一化(参见第十一章),因此具有较大动态范围的参数将需要更长时间进行训练,而具有较小动态范围的参数可能会更新得太快,导致不稳定性。通过在模型本身中重新缩放权重,而不仅仅在初始化时重新缩放它们,这种方法确保了在整个训练过程中所有参数的动态范围相同,因此它们都以相同的速度学习。这既加快了训练速度,又稳定了训练过程。
像素级归一化层
在生成器的每个卷积层之后添加。它根据同一图像和位置处的所有激活进行归一化,但跨所有通道(除以均方激活的平方根)。在 TensorFlow 代码中,这是inputs / tf.sqrt(tf.reduce_mean(tf.square(X), axis=-1, keepdims=True) + 1e-8)(需要平滑项1e-8以避免除以零)。这种技术避免了由于生成器和鉴别器之间的激烈竞争而导致激活爆炸。
所有这些技术的结合使作者能够生成极具说服力的高清面部图像。但是,“说服力”到底是什么意思呢?评估是在使用 GAN 时面临的一大挑战:尽管可以自动评估生成图像的多样性,但评估其质量是一项更加棘手和主观的任务。一种技术是使用人类评分者,但这既昂贵又耗时。因此,作者提出了一种方法,即考虑生成图像与训练图像之间的局部图像结构的相似性,考虑每个尺度。这个想法引领他们走向另一个开创性的创新:StyleGANs。
StyleGANs
高分辨率图像生成领域的最新技术再次由同一 Nvidia 团队在2018 年的一篇论文中推进,引入了流行的 StyleGAN 架构。作者在生成器中使用风格转移技术,以确保生成的图像在每个尺度上具有与训练图像相同的局部结构,极大地提高了生成图像的质量。鉴别器和损失函数没有被修改,只有生成器。StyleGAN 生成器由两个网络组成(参见图 17-19):
映射网络
一个将潜在表示z(即编码)映射到向量w的八层 MLP。然后,将该向量通过多个仿射变换(即没有激活函数的Dense层,在图 17-19 中用“A”框表示)发送,从而产生多个向量。这些向量控制生成图像的风格在不同层次上,从细粒度纹理(例如头发颜色)到高级特征(例如成人或儿童)。简而言之,映射网络将编码映射到多个风格向量。
合成网络
负责生成图像。它有一个恒定的学习输入(明确地说,这个输入在训练之后将是恒定的,但在训练期间,它会通过反向传播不断调整)。它通过多个卷积和上采样层处理这个输入,就像之前一样,但有两个变化。首先,在输入和所有卷积层的输出(在激活函数之前)中添加了一些噪音。其次,每个噪音层后面都跟着一个自适应实例归一化(AdaIN)层:它独立地标准化每个特征图(通过减去特征图的均值并除以其标准差),然后使用风格向量确定每个特征图的比例和偏移(风格向量包含每个特征图的一个比例和一个偏置项)。
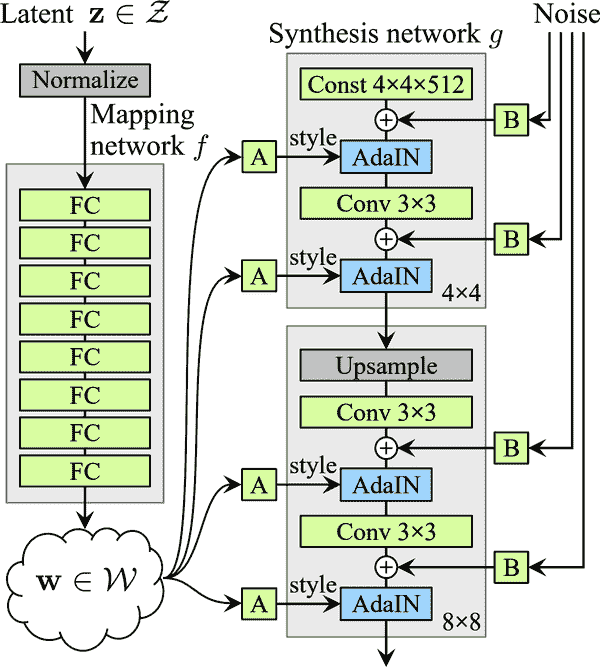
图 17-19. StyleGAN 的生成器架构(来自 StyleGAN 论文的图 1 的一部分)¹⁸
独立于编码添加噪音的想法非常重要。图像的某些部分是相当随机的,比如每个雀斑或头发的确切位置。在早期的 GAN 中,这种随机性要么来自编码,要么是生成器本身产生的一些伪随机噪音。如果来自编码,这意味着生成器必须将编码的表征能力的相当一部分用于存储噪音,这是相当浪费的。此外,噪音必须能够流经网络并到达生成器的最终层:这似乎是一个不必要的约束,可能会减慢训练速度。最后,一些视觉伪影可能会出现,因为在不同级别使用相同的噪音。如果生成器尝试生成自己的伪随机噪音,这种噪音可能看起来不太令人信服,导致更多的视觉伪影。此外,生成器的一部分权重将被用于生成伪随机噪音,这再次似乎是浪费的。通过添加额外的噪音输入,所有这些问题都可以避免;GAN 能够利用提供的噪音为图像的每个部分添加适量的随机性。
每个级别的添加噪音都是不同的。每个噪音输入由一个充满高斯噪音的单个特征图组成,该特征图被广播到所有特征图(给定级别的)并使用学习的每个特征比例因子进行缩放(这由图 17-19 中的“B”框表示)然后添加。
最后,StyleGAN 使用一种称为混合正则化(或风格混合)的技术,其中一定比例的生成图像是使用两种不同的编码生成的。具体来说,编码c[1]和c[2]被送入映射网络,得到两个风格向量w[1]和w[2]。然后合成网络根据第一级的风格w[1]和剩余级别的风格w[2]生成图像。截断级别是随机选择的。这可以防止网络假设相邻级别的风格是相关的,从而鼓励 GAN 中的局部性,这意味着每个风格向量只影响生成图像中的有限数量的特征。
有这么多种类的 GAN,需要一本整书来覆盖它们。希望这个介绍给您带来了主要思想,最重要的是让您有学习更多的愿望。继续实现您自己的 GAN,如果一开始学习有困难,请不要灰心:不幸的是,这是正常的,需要相当多的耐心才能使其正常运行,但结果是值得的。如果您在实现细节上遇到困难,有很多 Keras 或 TensorFlow 的实现可以参考。实际上,如果您只是想快速获得一些惊人的结果,那么您可以使用预训练模型(例如,有适用于 Keras 的预训练 StyleGAN 模型可用)。
现在我们已经研究了自编码器和 GANs,让我们看看最后一种架构:扩散模型。
扩散模型
扩散模型的理念已经存在多年,但它们首次以现代形式在斯坦福大学和加州大学伯克利分校的 Jascha Sohl-Dickstein 等人的2015 年论文中得到正式形式化。作者们应用了热力学工具来建模扩散过程,类似于一滴牛奶在茶杯中扩散的过程。核心思想是训练一个模型来学习反向过程:从完全混合状态开始,逐渐将牛奶从茶中“分离”。利用这个想法,他们在图像生成方面取得了令人期待的结果,但由于当时 GANs 生成的图像更具说服力,扩散模型并没有得到太多关注。
然后,在 2020 年,也来自加州大学伯克利分校的 Jonathan Ho 等人成功构建了一个能够生成高度逼真图像的扩散模型,他们称之为去噪扩散概率模型(DDPM)。几个月后,OpenAI 研究人员 Alex Nichol 和 Prafulla Dhariwal 的2021 年论文分析了 DDPM 架构,并提出了几项改进,使 DDPM 最终击败了 GANs:DDPM 不仅比 GANs 更容易训练,而且生成的图像更加多样化且质量更高。正如您将看到的那样,DDPM 的主要缺点是生成图像需要很长时间,与 GANs 或 VAEs 相比。
那么 DDPM 究竟是如何工作的呢?假设您从一张猫的图片开始(就像您将在图 17-20 中看到的那样),记为x[0],并且在每个时间步t中向图像添加一点均值为 0,方差为β[t]的高斯噪声。这种噪声对于每个像素都是独立的:我们称之为各向同性。您首先得到图像x[1],然后x[2],依此类推,直到猫完全被噪声隐藏,无法看到。最后一个时间步记为T。在最初的 DDPM 论文中,作者使用T = 1,000,并且他们安排了方差β[t]的方式,使得猫信号在时间步 0 和T之间线性消失。在改进的 DDPM 论文中,T增加到了 4,000,并且方差安排被调整为在开始和结束时变化更慢。简而言之,我们正在逐渐将猫淹没在噪声中:这被称为正向过程。
随着我们在正向过程中不断添加更多高斯噪声,像素值的分布变得越来越高斯。我遗漏的一个重要细节是,每一步像素值都会被稍微重新缩放,缩放因子为1-βt。这确保了像素值的均值逐渐接近 0,因为缩放因子比 1 稍微小一点(想象一下反复将一个数字乘以 0.99)。这也确保了方差将逐渐收敛到 1。这是因为像素值的标准差也会被1-βt缩放,因此方差会被 1 - β[t](即缩放因子的平方)缩放。但是方差不能收缩到 0,因为我们在每一步都添加方差为β[t]的高斯噪声。而且由于当你对高斯分布求和时方差会相加,您可以看到方差只能收敛到 1 - β[t] + β[t] = 1。
前向扩散过程总结在 Equation 17-5 中。这个方程不会教你任何新的关于前向过程的知识,但理解这种数学符号是有用的,因为它经常在机器学习论文中使用。这个方程定义了给定 x[t–1] 的概率分布 q 中 x[t] 的概率分布,其均值为 x[t–1] 乘以缩放因子,并且具有等于 β[t]I 的协方差矩阵。这是由 β[t] 乘以单位矩阵 I 得到的,这意味着噪音是各向同性的,方差为 β[t]。
方程 17-5. 前向扩散过程的概率分布 q
q(xt|xt-1)=N(1-βtxt-1,βtI)
有趣的是,前向过程有一个快捷方式:可以在不必先计算 x[1], x[2], …, x[t–1] 的情况下,给定 x[0] 来采样图像 x[t]。实际上,由于多个高斯分布的和也是一个高斯分布,所有的噪音可以在一次性使用 Equation 17-6 中的公式添加。这是我们将要使用的方程,因为它速度更快。
方程 17-6. 前向扩散过程的快捷方式
q(xt|x0)=Nα¯tx0,(1-α¯t)I
当然,我们的目标不是让猫淹没在噪音中。相反,我们想要创造许多新的猫!我们可以通过训练一个能够执行逆过程的模型来实现这一点:从 x[t] 到 x[t–1]。然后我们可以使用它从图像中去除一点噪音,并重复这个操作多次,直到所有的噪音都消失。如果我们在包含许多猫图像的数据集上训练模型,那么我们可以给它一张完全充满高斯噪音的图片,模型将逐渐使一个全新的猫出现(见 Figure 17-20)。

图 17-20. 前向过程 q 和逆过程 p
好的,让我们开始编码!我们需要做的第一件事是编写前向过程的代码。为此,我们首先需要实现方差计划。我们如何控制猫消失的速度?最初,100%的方差来自原始猫图像。然后在每个时间步t,方差会按照 1 - β[t]乘以,如前所述,并添加噪声。因此,来自初始分布的方差部分在每一步都会缩小 1 - β[t]倍。如果我们定义α[t] = 1 - β[t],那么经过t个时间步骤后,猫信号将被乘以α̅[t] = α[1]×α[2]×…×α[t] = α¯t=∏i=1tαt。这个“猫信号”因子α̅[t]是我们希望安排的,使其在时间步 0 和T之间逐渐从 1 缩小到 0。在改进的 DDPM 论文中,作者根据方程 17-7 安排α̅[t]。这个计划在图 17-21 中表示。
方程 17-7。前向扩散过程的方差计划方程
βt=1-α¯tα¯t-1,其中 α¯t=f(t)f(0) 和 f(t)=cos(t/T+s1+s·π2)2
在这些方程中:
-
s是一个微小值,防止β[t]在t = 0 附近太小。在论文中,作者使用了s = 0.008。
-
β[t]被剪切为不大于 0.999,以避免在t = T附近的不稳定性。
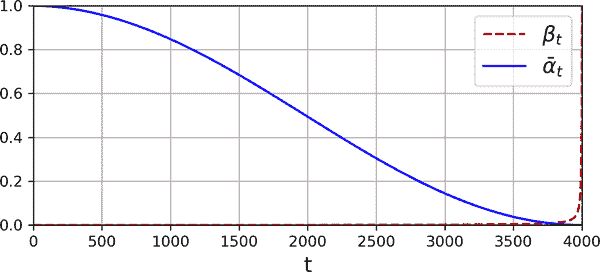
图 17-21。噪声方差计划β[t],以及剩余信号方差α̅[t]
让我们创建一个小函数来计算α[t],β[t]和α̅[t],并使用T = 4,000 调用它:
def variance_schedule(T, s=0.008, max_beta=0.999):t = np.arange(T + 1)f = np.cos((t / T + s) / (1 + s) * np.pi / 2) ** 2alpha = np.clip(f[1:] / f[:-1], 1 - max_beta, 1)alpha = np.append(1, alpha).astype(np.float32) # add α₀ = 1beta = 1 - alphaalpha_cumprod = np.cumprod(alpha)return alpha, alpha_cumprod, beta # αₜ , α̅ₜ , βₜ for t = 0 to TT = 4000
alpha, alpha_cumprod, beta = variance_schedule(T)
为了训练我们的模型来逆转扩散过程,我们需要来自前向过程不同时间步的嘈杂图像。为此,让我们创建一个prepare_batch()函数,它将从数据集中获取一批干净图像并准备它们:
def prepare_batch(X):X = tf.cast(X[..., tf.newaxis], tf.float32) * 2 - 1 # scale from –1 to +1X_shape = tf.shape(X)t = tf.random.uniform([X_shape[0]], minval=1, maxval=T + 1, dtype=tf.int32)alpha_cm = tf.gather(alpha_cumprod, t)alpha_cm = tf.reshape(alpha_cm, [X_shape[0]] + [1] * (len(X_shape) - 1))noise = tf.random.normal(X_shape)return {"X_noisy": alpha_cm ** 0.5 * X + (1 - alpha_cm) ** 0.5 * noise,"time": t,}, noise
让我们看一下这段代码:
-
为简单起见,我们将使用 Fashion MNIST,因此函数必须首先添加一个通道轴。将像素值从-1 缩放到 1 也会有所帮助,这样它更接近均值为 0,方差为 1 的最终高斯分布。
-
接下来,该函数创建
t,一个包含每个图像批次中随机时间步长的向量,介于 1 和T之间。 -
然后它使用
tf.gather()来获取向量t中每个时间步长的alpha_cumprod的值。这给我们了向量alpha_cm,其中包含每个图像的一个α̅[t]值。 -
下一行将
alpha_cm从[批次大小]重塑为[批次大小, 1, 1, 1]。这是为了确保alpha_cm可以与批次X进行广播。 -
然后我们生成一些均值为 0,方差为 1 的高斯噪声。
-
最后,我们使用方程 17-6 将扩散过程应用于图像。请注意,
x ** 0.5等于x的平方根。该函数返回一个包含输入和目标的元组。输入表示为一个 Pythondict,其中包含嘈杂图像和用于生成每个图像的时间步。目标是用于生成每个图像的高斯噪声。
注意
通过这种设置,模型将预测应从输入图像中减去的噪声,以获得原始图像。为什么不直接预测原始图像呢?嗯,作者尝试过:它简单地效果不如预期。
接下来,我们将创建一个训练数据集和一个验证集,将prepare_batch()函数应用于每个批次。与之前一样,X_train和X_valid包含像素值从 0 到 1 的时尚 MNIST 图像:
def prepare_dataset(X, batch_size=32, shuffle=False):ds = tf.data.Dataset.from_tensor_slices(X)if shuffle:ds = ds.shuffle(buffer_size=10_000)return ds.batch(batch_size).map(prepare_batch).prefetch(1)train_set = prepare_dataset(X_train, batch_size=32, shuffle=True)
valid_set = prepare_dataset(X_valid, batch_size=32)
现在我们准备构建实际的扩散模型本身。它可以是您想要的任何模型,只要它将嘈杂的图像和时间步骤作为输入,并预测应从输入图像中减去的噪声:
def build_diffusion_model():X_noisy = tf.keras.layers.Input(shape=[28, 28, 1], name="X_noisy")time_input = tf.keras.layers.Input(shape=[], dtype=tf.int32, name="time")[...] # build the model based on the noisy images and the time stepsoutputs = [...] # predict the noise (same shape as the input images)return tf.keras.Model(inputs=[X_noisy, time_input], outputs=[outputs])
DDPM 的作者使用了一个修改过的U-Net 架构,它与我们在第十四章中讨论的 FCN 架构有许多相似之处,用于语义分割:它是一个卷积神经网络,逐渐对输入图像进行下采样,然后再逐渐对其进行上采样,跳跃连接从每个下采样部分的每个级别跨越到相应的上采样部分的级别。为了考虑时间步长,他们使用了与Transformer架构中的位置编码相同的技术对其进行编码(参见第十六章)。在 U-Net 架构的每个级别上,他们通过Dense层传递这些时间编码,并将它们馈送到 U-Net 中。最后,他们还在各个级别使用了多头注意力层。查看本章的笔记本以获取基本实现,或者https://homl.info/ddpmcode以获取官方实现:它基于已弃用的 TF 1.x,但非常易读。
现在我们可以正常训练模型了。作者指出,使用 MAE 损失比 MSE 效果更好。您也可以使用 Huber 损失:
model = build_diffusion_model()
model.compile(loss=tf.keras.losses.Huber(), optimizer="nadam")
history = model.fit(train_set, validation_data=valid_set, epochs=100)
一旦模型训练完成,您可以使用它生成新图像。不幸的是,在反向扩散过程中没有捷径,因此您必须从均值为 0,方差为 1 的高斯分布中随机抽样x[T],然后将其传递给模型预测噪声;使用方程 17-8 从图像中减去它,然后您会得到x[T–1]。重复这个过程 3999 次,直到得到x[0]:如果一切顺利,它应该看起来像一个常规的时尚 MNIST 图像!
方程 17-8。在扩散过程中向后走一步
xt-1=1αtxt-βt1-α¯tϵθ(xt,t)+βtz
在这个方程中,ϵ[θ](x[t], t)代表模型给定输入图像x[t]和时间步长t预测的噪声。θ代表模型参数。此外,z是均值为 0,方差为 1 的高斯噪声。这使得反向过程是随机的:如果您多次运行它,您将得到不同的图像。
让我们编写一个实现这个反向过程的函数,并调用它生成一些图像:
def generate(model, batch_size=32):X = tf.random.normal([batch_size, 28, 28, 1])for t in range(T, 0, -1):noise = (tf.random.normal if t > 1 else tf.zeros)(tf.shape(X))X_noise = model({"X_noisy": X, "time": tf.constant([t] * batch_size)})X = (1 / alpha[t] ** 0.5* (X - beta[t] / (1 - alpha_cumprod[t]) ** 0.5 * X_noise)+ (1 - alpha[t]) ** 0.5 * noise)return XX_gen = generate(model) # generated images
这可能需要一两分钟。这是扩散模型的主要缺点:生成图像很慢,因为模型需要被多次调用。通过使用较小的T值或者同时使用相同模型预测多个步骤,可以加快这一过程,但生成的图像可能不那么漂亮。尽管存在这种速度限制,扩散模型确实生成高质量和多样化的图像,正如您在图 17-22 中所看到的。

图 17-22。DDPM 生成的图像
最近,扩散模型取得了巨大的进展。特别是,2021 年 12 月由Robin Rombach, Andreas Blattmann 等人发表的一篇论文²³介绍了潜在扩散模型,其中扩散过程发生在潜在空间,而不是在像素空间中。为了实现这一点,使用强大的自编码器将每个训练图像压缩到一个更小的潜在空间中,扩散过程发生在这里,然后自编码器用于解压缩最终的潜在表示,生成输出图像。这极大地加快了图像生成速度,大大减少了训练时间和成本。重要的是,生成的图像质量非常出色。
此外,研究人员还采用了各种调节技术来引导扩散过程,使用文本提示、图像或任何其他输入。这使得快速生成一个漂亮的高分辨率图像成为可能,比如一只读书的蝾螈,或者你可能喜欢的其他任何东西。您还可以使用输入图像来调节图像生成过程。这使得许多应用成为可能,比如外部绘制——在输入图像的边界之外扩展——或内部绘制——填充图像中的空洞。
最后,一个名为稳定扩散的强大预训练潜在扩散模型于 2022 年 8 月由慕尼黑大学 LMU 与包括 StabilityAI 和 Runway 在内的几家公司合作开源,得到了 EleutherAI 和 LAION 的支持。2022 年 9 月,它被移植到 TensorFlow,并包含在KerasCV中,这是由 Keras 团队构建的计算机视觉库。现在任何人都可以在几秒钟内免费生成令人惊叹的图像,即使是在普通笔记本电脑上(请参阅本章的最后一个练习)。可能性是无限的!
在下一章中,我们将转向深度强化学习的一个完全不同的分支。
练习
-
自编码器主要用于哪些任务?
-
假设你想要训练一个分类器,你有大量未标记的训练数据,但只有几千个标记实例。自编码器如何帮助?你会如何继续?
-
如果自编码器完美地重建输入,它一定是一个好的自编码器吗?你如何评估自编码器的性能?
-
什么是欠完备和过完备自编码器?过度欠完备自编码器的主要风险是什么?过度完备自编码器的主要风险又是什么?
-
如何在堆叠自编码器中绑定权重?这样做的目的是什么?
-
什么是生成模型?你能说出一种生成自编码器吗?
-
什么是 GAN?你能说出几个 GAN 可以发挥作用的任务吗?
-
训练 GAN 时的主要困难是什么?
-
扩散模型擅长什么?它们的主要限制是什么?
-
尝试使用去噪自编码器预训练图像分类器。您可以使用 MNIST(最简单的选项),或者如果您想要更大的挑战,可以使用更复杂的图像数据集,比如CIFAR10。无论您使用的数据集是什么,都要遵循以下步骤:
-
将数据集分割成训练集和测试集。在完整的训练集上训练一个深度去噪自编码器。
-
检查图像是否被相当好地重建。可视化激活编码层中每个神经元的图像。
-
构建一个分类 DNN,重用自编码器的较低层。仅使用训练集中的 500 张图像进行训练。它在有无预训练的情况下表现更好吗?
-
-
在您选择的图像数据集上训练一个变分自编码器,并使用它生成图像。或者,您可以尝试找到一个您感兴趣的无标签数据集,看看是否可以生成新样本。
-
训练一个 DCGAN 来处理您选择的图像数据集,并使用它生成图像。添加经验重放,看看这是否有帮助。将其转换为条件 GAN,您可以控制生成的类别。
-
浏览 KerasCV 出色的稳定扩散教程,并生成一幅漂亮的图画,展示一只读书的蝾螈。如果您在 Twitter 上发布您最好的图画,请在@ aureliengeron 处标记我。我很想看看您的创作!
这些练习的解决方案可在本章笔记本的末尾找到,网址为https://homl.info/colab3。
¹ William G. Chase 和 Herbert A. Simon,“国际象棋中的感知”,认知心理学 4,第 1 期(1973 年):55-81。
² Yoshua Bengio 等,“深度网络的贪婪逐层训练”,第 19 届神经信息处理系统国际会议论文集(2006):153-160。
³ Jonathan Masci 等,“用于分层特征提取的堆叠卷积自编码器”,第 21 届国际人工神经网络会议论文集 1(2011):52-59。
⁴ Pascal Vincent 等,“使用去噪自编码器提取和组合稳健特征”,第 25 届国际机器学习会议论文集(2008):1096-1103。
⁵ Pascal Vincent 等,“堆叠去噪自编码器:使用局部去噪标准在深度网络中学习有用的表示”,机器学习研究杂志 11(2010):3371-3408。
⁶ Diederik Kingma 和 Max Welling,“自编码变分贝叶斯”,arXiv 预印本 arXiv:1312.6114(2013)。
⁷ 变分自编码器实际上更通用;编码不限于高斯分布。
⁸ 要了解更多数学细节,请查看有关变分自编码器的原始论文,或查看 Carl Doersch 的优秀教程(2016)。
⁹ Ian Goodfellow 等,“生成对抗网络”,第 27 届神经信息处理系统国际会议论文集 2(2014):2672-2680。
¹⁰ 要了解主要 GAN 损失的良好比较,请查看 Hwalsuk Lee 的这个GitHub 项目。
¹¹ Mario Lucic 等,“GAN 是否平等?大规模研究”,第 32 届神经信息处理系统国际会议论文集(2018):698-707。
¹² Alec Radford 等,“使用深度卷积生成对抗网络进行无监督表示学习”,arXiv 预印本 arXiv:1511.06434(2015)。
¹³ 在作者的亲切授权下再现。
¹⁴ Mehdi Mirza 和 Simon Osindero,“有条件生成对抗网络”,arXiv 预印本 arXiv:1411.1784(2014)。
¹⁵ Tero Karras 等,“用于改善质量、稳定性和变化的 GAN 的渐进增长”,国际学习表示会议论文集(2018)。
¹⁶ 变量的动态范围是其可能取的最高值和最低值之间的比率。
¹⁷ Tero Karras 等人,“基于风格的生成对抗网络架构”,arXiv 预印本 arXiv:1812.04948(2018)。
¹⁸ 在作者的亲切授权下复制。
¹⁹ Jascha Sohl-Dickstein 等人,“使用非平衡热力学进行深度无监督学习”,arXiv 预印本 arXiv:1503.03585(2015)。
²⁰ Jonathan Ho 等人,“去噪扩散概率模型”(2020)。
²¹ Alex Nichol 和 Prafulla Dhariwal,“改进的去噪扩散概率模型”(2021)。
²² Olaf Ronneberger 等人,“U-Net:用于生物医学图像分割的卷积网络”,arXiv 预印本 arXiv:1505.04597(2015)。
²³ Robin Rombach,Andreas Blattmann 等人,“使用潜在扩散模型进行高分辨率图像合成”,arXiv 预印本 arXiv:2112.10752(2021)。