文章目录
- 一、前言
- 二、EXT2文件系统 - 逻辑存储结构
- 💾分区(Partition)
- 分区的概念
- 每个分区的内容
- Linux下查询磁盘分区
- 💾块组(Block Group)
- 磁盘格式化
- 每个块组的内容
- 1. Superblock(超级块)
- 2. Group Descriptor Table(组描述符表)
- 3. Block Bitmap(块位图)
- 4. inode Bitmap(inode位图)
- 5. inode Table(inode表)
- 6. Data Blocks(数据块)
- 三、操作磁盘文件的过程
- ✨创建文件
- ✨找到文件
- ✨删除文件
- ✨恢复文件
一、前言
在上篇 文件IO 文件系统调用 文件fd 重定向 文章中,我们已经学习了在内存中被打开(被加载)的文件,还有一部分是磁盘中未被打开的文件。这篇我们来谈磁盘文件。
Linux对文件的管理工作:
- 管理被打开的文件
- 管理磁盘中没有被打开的文件
以上两点构成了Linux的文件系统,文件系统这个名词狭义上指的是磁盘文件系统,例如Linux下的ext2文件系统。
二、EXT2文件系统 - 逻辑存储结构
💾分区(Partition)
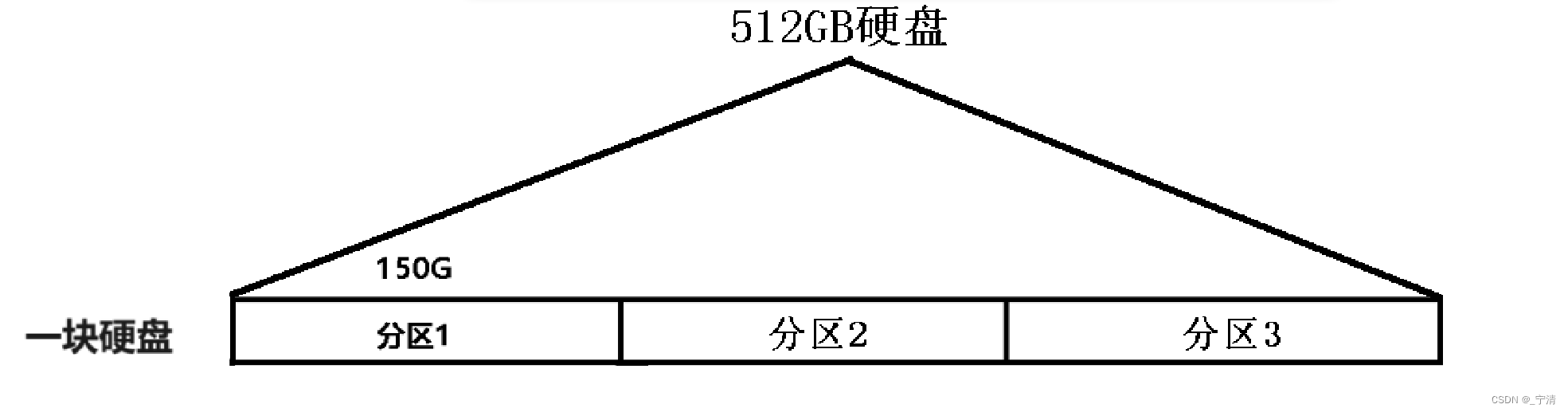
分区的概念
-
定义: 将硬盘划分为逻辑上独立的单元。
-
作用: 实现文件系统的组织和管理,提供隔离的存储空间,体现了分治的思想。
每个分区的内容
- 对于每一个分区:

Boot Block(引导块):
- 定义: Boot block是文件系统中的第一个块,通常包含引导加载程序和文件系统的元数据,用于引导操作系统。
- 作用: 存储引导加载程序,提供文件系统的起始点,引导操作系统的启动。
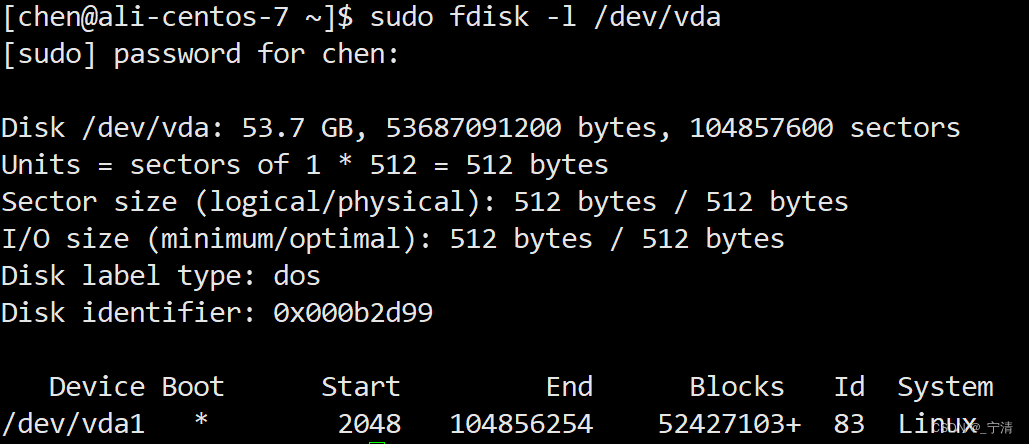
Linux下查询磁盘分区
可以通过以下命令查看当前Linux系统的分区:
- 使用
lsblk命令:lsblk /dev/vda
上述命令会列出
/dev/vda设备的分区信息,包括每个分区的大小、挂载点等。
- 使用
fdisk命令:sudo fdisk -l /dev/vda
上述命令会显示
/dev/vda设备的分区表信息,包括每个分区的起始扇区、大小等。可能要使用sudo提权。
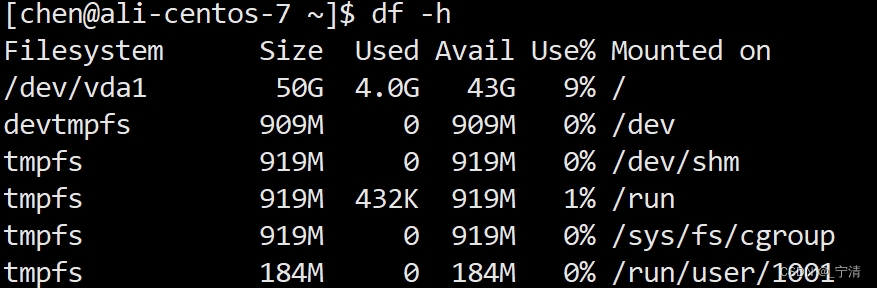
- 使用
df -hdf -h
相当于Windows的 “此电脑”,
df -h提供了一个快速的方式来查看系统上各个文件系统的存储使用情况,以便及时了解磁盘空间的分布和使用率。
💾块组(Block Group)
ext2文件系统会根据分区的大小划分为数个块组(Block Group)。而每个块组都有着相同的结构组成。块组也被称为分组,块组是由分区细分出的产物。
磁盘格式化
- 当磁盘完成分区后,我们还需要对磁盘进行格式化。
- 磁盘格式化就是对磁盘中的分区进行初始化的一种操作,这种操作通常会导致现有的磁盘或分区中所有的文件被清除。
- 磁盘格式化就是对分区后的各个区域写入对应的管理信息。
其中,写入的管理信息是什么是由文件系统决定的,不同的文件系统格式化时写入的管理信息是不同的,常见的文件系统有EXT2、EXT3、XFS、NTFS等。
每个块组的内容
块组与分区的关系如图所示:
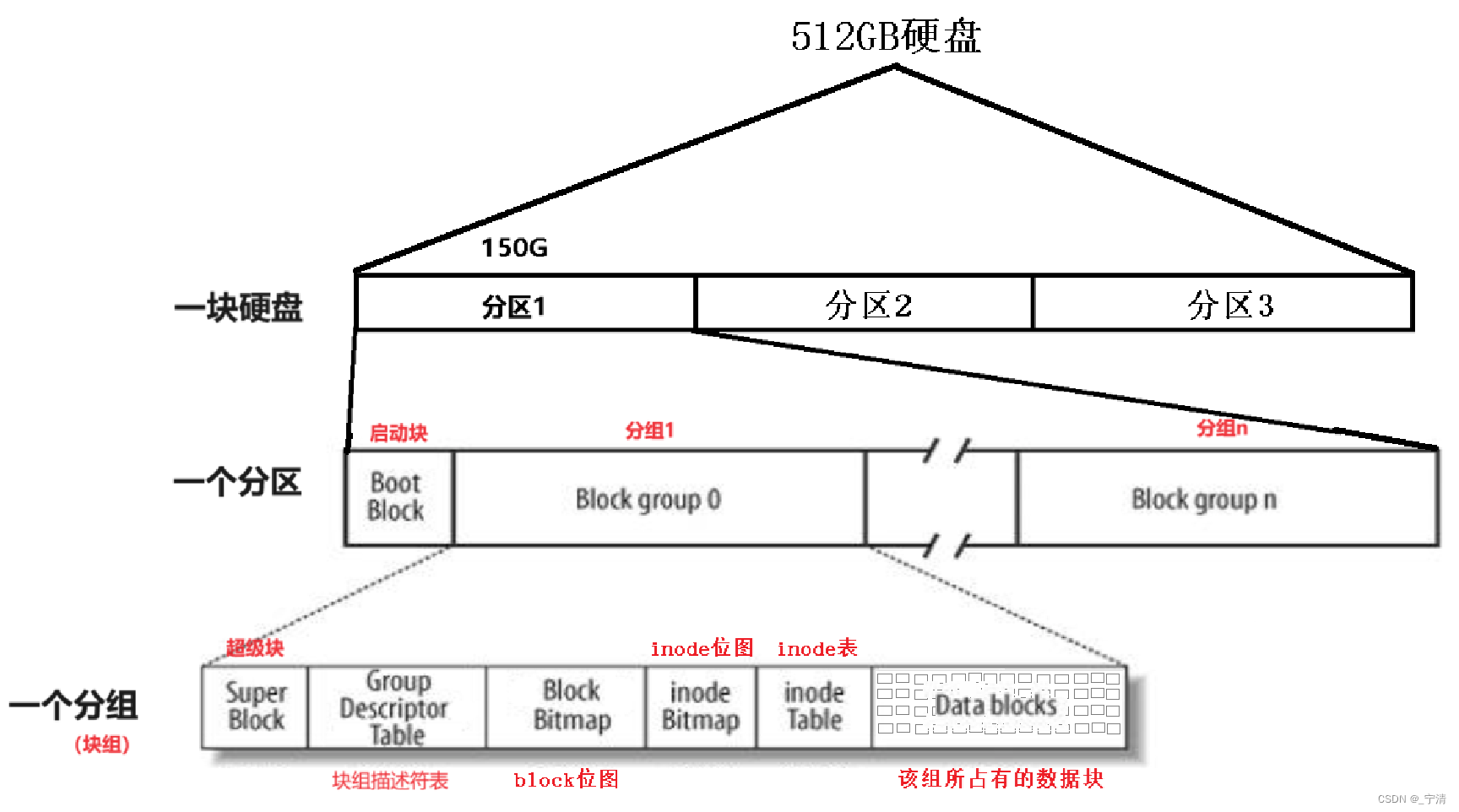
当我们考虑一个块组中的内容时,以下是一个块组中包含的内容:
1. Superblock(超级块)
- 定义: 超级块是文件系统中一个关键的元数据块,包含有关整个文件系统的信息。
- 作用: 提供整个块组的整体信息。存放文件系统本身的结构信息。
- 记录的信息主要有:
- block和 inode的总量
- 未使用的block和inode的数量
- 一个block和inode的大小
- 最近一次挂载的时间
- 最近一次写入数据的时间
- 最近一次检验磁盘的时间等其他文件系统的相关信息。
Super Block的信息被破坏,可以说整个文件系统结构就被破坏了
2. Group Descriptor Table(组描述符表)
-
定义: 组描述符表存储了关于每个块组的元信息,包括块组中的inode和数据块的位置,以及空闲块和inode的数量等信息。
-
作用: 提供了有关块组的重要信息,帮助文件系统在块组级别进行管理和分配。
-
组描述符表中的主要信息包括:
1. 块组的起始块号: 记录块组的起始块号,用于定位块组在整个文件系统中的位置。
2. 块位图的起始块号: 记录块组中块位图的起始块号,用于定位块组中块的分配情况。
3. Inode位图的起始块号: 记录块组中Inode位图的起始块号,用于定位块组中Inode的分配情况。
4. Inode表的起始块号: 记录块组中Inode表的起始块号,用于定位块组中Inode的存储位置。
5. 空闲块的数量: 统计块组中未分配的空闲块数量。
6. 空闲Inode的数量: 统计块组中未分配的空闲Inode数量。
3. Block Bitmap(块位图)
- 定义: 块位图是一个位图,记录块组中每个块的使用情况,标记哪些块已被分配,哪些是空闲的。
- 作用: 帮助文件系统管理块的分配和释放,维护块的空闲状态。
4. inode Bitmap(inode位图)
- 定义: Inode位图是一个位图,记录块组中每个inode的使用情况,标记已分配和空闲的inode。
- 作用: 帮助文件系统管理inode的分配和释放,维护inode的空闲状态。
5. inode Table(inode表)
- 定义: Inode表存储了块组中所有文件和目录的元数据,每个文件和目录都关联到一个唯一的inode。
- 作用: 记录文件的属性信息,如文件大小、权限、属主等。
一个典型的
inode结构包含以下信息:
文件类型(File Type): 表示Inode关联的文件类型,如普通文件、目录、符号链接等。
权限和所有者信息:
- 文件所有者(User ID)
- 文件所属组(Group ID)
- 文件权限(Read、Write、Execute)
时间戳:
- 文件的最后访问时间(atime)
- 文件的最后修改时间(mtime)
- Inode的最后修改时间(ctime)
文件大小: 记录文件的大小(以字节为单位)。
链接数: 记录连接到该Inode的硬链接数量。当链接数为0时,表示文件不再被引用,可以被删除。
数据块指针:
- 直接块指针(Direct Block Pointers):用于存储文件的前一定量数据块。
- 单间接块指针(Single Indirect Block Pointer):指向一个块,该块包含更多数据块的指针。
- 双间接块指针(Double Indirect Block Pointer):指向一个块,该块包含单间接块的指针。
文件系统标志: 记录Inode所属的文件系统的特定标志。
6. Data Blocks(数据块)
- 定义: 数据块是用于存储文件实际数据的块,也包括目录中文件名和对应inode的映射。
- 作用: 存储文件和目录的实际内容,包括文件数据和目录项。
三、操作磁盘文件的过程
✨创建文件
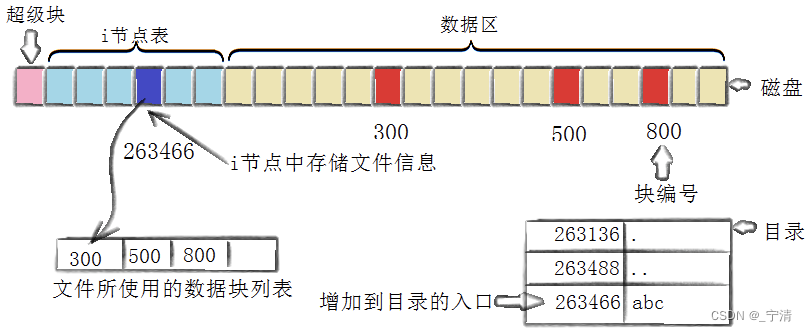
- 存储属性
内核先找到一个空闲的i节点(这里是263466)。内核把文件信息记录到其中。 - 存储数据
该文件需要存储在三个数据块,内核通过块位图找到了三个空闲数据块:300,500,800。将内核缓冲区的第一块数据复制到300,下一块复制到500,以此类推。 - 记录分配情况
文件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表。 - 添加文件名到目录
假如新的文件名是“abc”。linux如何在当前的目录中记录这个文件?内核将映射关系(263466,abc)添加到目录文件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。
✨找到文件
在Linux操作系统的ext2文件系统中,通过一个文件的inode找到该文件的过程涉及到文件目录、内核缓冲区等关键概念。以下是找文件的步骤:
-
文件目录(Directory):
- 文件目录是一个特殊的文件,用于存储文件名与其对应的inode号之间的映射关系。每个目录项都包含文件名和对应文件的inode号。
-
查找文件的inode:
- 当用户提供一个文件名时,内核首先会查找文件所在的目录,即打开包含文件名的目录文件。这可以通过系统调用如
opendir、readdir来实现。
- 当用户提供一个文件名时,内核首先会查找文件所在的目录,即打开包含文件名的目录文件。这可以通过系统调用如
-
读取目录文件:
- 文件目录是一个包含目录项的文件。通过系统调用
readdir等,内核将目录文件的内容读入内核缓冲区。
- 文件目录是一个包含目录项的文件。通过系统调用
-
在内核缓冲区中查找目录项:
- 内核缓冲区中存储了目录文件的内容,包括文件名和对应的inode号。内核根据用户提供的文件名在内核缓冲区中查找相应的目录项。
目录项
目录项是文件系统中的一个记录单元,用于将文件名与其对应的inode号关联起来。每个目录项包含一个文件或目录的名称以及与之相关联的唯一标识符(inode号),该标识符用于定位并访问文件或目录的详细元数据。目录项是构建目录结构的基本组成部分,使得文件系统能够有效地组织和检索文件。
-
获取文件的inode号:
- 一旦找到了目录项,就可以从中获取文件对应的inode号。
-
访问文件的inode:
- 使用文件的inode号,内核再次进行系统调用(例如
stat)来获取文件的详细元数据。这涉及到文件系统的访问操作,文件系统会将对应inode的信息读取到内核缓冲区中。
- 使用文件的inode号,内核再次进行系统调用(例如
-
获取文件的数据块:
- 通过读取inode中的数据块指针,内核可以找到文件的实际数据块。
-
读取文件内容:
- 最终,内核可以通过读取文件的数据块来获取文件的实际内容。
总体而言,文件系统通过在文件目录中查找文件名与inode号的映射关系,然后通过inode号来获取文件的详细信息,最终访问文件的实际数据块,实现了从用户提供的文件名到文件内容的映射过程。这一系列操作都依赖于内核缓冲区。
✨删除文件
- 将该文件对应的inode在inode位图当中置为无效(比特位设置为0)。
- 将该文件申请过的数据块在块位图当中置为无效(比特位设置为0)。
✨恢复文件
因为删除操作并不会真正将文件对应的信息删除,而只是将其inode号和数据块号置为了无效,所以当我们删除文件后短时间内是可以恢复的,在删除后,有些操作系统会记录日志,日志中会保存被删的inode编号!
为什么说是短时间内可恢复呢?因为该文件对应的inode号和数据块号已经被置为了无效,因此后续创建其他文件或是对其他文件进行写入操作申请inode号和数据块号时,可能会将该置为无效了的inode号和数据块号分配出去,此时删除文件的数据就会被覆盖,也就无法恢复文件了。