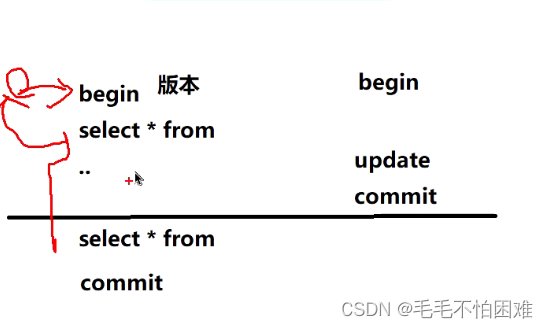
OCR是从图像中提取文本的有价值工具。然而,有时您使用的OCR在特定需求上的表现不如您所希望的那样好。如果您面临这样的问题,微调OCR引擎是解决的一种方法。在本教程中,我将向您展示如何微调EasyOCR,这是一个免费、开源的OCR引擎,您可以在Python中使用。
概述
先决条件
安装所需的软件包
克隆所需的Git存储库
生成数据集
将数据集转换为lmdb格式
检索预训练的OCR模型:
运行微调
使用微调后的模型运行推理
性能的定性测试
性能的定量测试
结论
先决条件
基本的Python知识
如何使用终端的基本知识
安装所需的软件包
首先,让我们安装所需的pip软件包。我建议为此创建一个虚拟环境,尽管这不是必需的。逐行运行以下命令:
pip install fire
pip install lmdb
pip install opencv-python
pip install natsort
pip install nltk您还需要从此网站安装PyTorch(选择您的规格并复制pip install命令,查看下面我用于我的规格的命令)。最好选择GPU版本,但CPU版本也可以正常工作,唯一的区别是在CPU上运行微调会更慢。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118克隆所需的Git存储库
首先,您需要一个Git存储库,它将帮助您运行微调。使用以下命令克隆此Git存储库:
git clone https://github.com/clovaai/deep-text-recognition-benchmark该存储库将为我们提供一些在微调EasyOCR模型时使用的有用文件。请注意,本文中使用的许多终端命令都来自该存储库,然后根据我的需求进行了调整,因此建议阅读该存储库。
我想在这里补充一下,clovaai在Git上总体上有许多对我非常有帮助的好存储库,所以请随时查看他们拥有的其他有趣的存储库。他们还有另一个非常有趣的存储库,即Donut模型存储库,我还写了一篇关于微调Donut模型的文章,您也应该查看一下。
生成数据集
在您可以微调OCR之前,您必须有一个要微调的数据集。您可以下载数据集或自己制作一个。由于我希望我的OCR在扫描超市收据时特别好,我将创建一个包含您可以在超市找到的物品的数据集,但请随时根据您需要OCR在其上执行良好的数据制作数据集。在本章中,我使用此GitHub页面来帮助我。
最简单的方法,使用我的虚拟数据集:
下载数据集
如果您想要另一个更大的数据集,可以从Dropbox官网上下载数据_lmdb_release.zip文件(请注意,其大小略大于18GB)。下载链接:https://drive.google.com/drive/folders/15WPsuPJDCzhp2SvYZLRj8mAlT3zmoAMW
制作您自己的数据集
如果您想采用更酷的方法创建自己的数据集,可以按照这个“生成OCR微调数据集”的教程进行操作。教程链接:https://medium.com/dev-genius/generating-a-fine-tuning-dataset-for-an-ocr-engine-3509167bc8a1
将数据集转换为lmdb格式
Lmdb代表Lightning Memory-Mapped Database Manager,本质上是您可以用于训练AI模型的数据集的编码。您可以在lmdb文档中了解更多信息。制作了数据集之后,您应该有一个包含图像的文件夹,并且所有图像的标签(图像中的文本)在labels.txt文件中。您的文件夹应如下图所示,并且此文件夹应位于deep-text-recognition文件夹内:
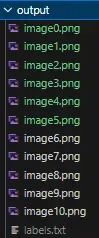
文件夹在转换为lmdb格式之前
注意:确保文件夹中至少有10张图像,因为如果图像太少,运行后面教程中的训练脚本时可能会出现错误。
然后,您必须在deep-text-recognition-benchmark文件夹中的create_lmdb_dataset.py文件中进行一些更改:
由于我遇到了磁盘内存错误,因此我不得不将map_size变量设置得较低。我将map_size的值设置为1073741824,并且您可以看到我更改的行如下所示:
# OLD LINE
# ...
env = lmdb.open(outputPath, map_size=1099511627776)
# ...# NEW LINE
# ...
env = lmdb.open(outputPath, map_size=1073741824)
# ...当打开gtFile时,我还遇到了utf编码错误,因此我在删除utf-8编码时。然后,新行看起来像这样:
# OLD LINE
# ...
with open(gtFile, 'r', encoding='utf-8') as data:
# ...# NEW LINE
# ...
with open(gtFile, 'r') as data:
# ...最后,我还必须更改读取imagePath的方式:
# OLD LINE
# ...
imagePath, label = datalist[i].strip('\n').split('\t')
# ...# NEW LINES
# ...
imagePath, label = datalist[i].strip('\n').split('.png')
imagePath += '.png'
# ...我的完整create_lmdb_dataset.py文件看起来像这样(来自这个Git存储库,应用了上述更改)。
import fire
import os
import lmdb
import cv2import numpy as npdef checkImageIsValid(imageBin):if imageBin is None:return FalseimageBuf = np.frombuffer(imageBin, dtype=np.uint8)img = cv2.imdecode(imageBuf, cv2.IMREAD_GRAYSCALE)imgH, imgW = img.shape[0], img.shape[1]if imgH * imgW == 0:return Falsereturn Truedef writeCache(env, cache):with env.begin(write=True) as txn:for k, v in cache.items():txn.put(k, v)def createDataset(inputPath, gtFile, outputPath, checkValid=True):"""Create LMDB dataset for training and evaluation.ARGS:inputPath : input folder path where starts imagePathoutputPath : LMDB output pathgtFile : list of image path and labelcheckValid : if true, check the validity of every image"""os.makedirs(outputPath, exist_ok=True)env = lmdb.open(outputPath, map_size=1073741824) #TODO Changed map sizecache = {}cnt = 1with open(gtFile, 'r') as data: #TODO removed utf-8 encoding here since I have norwegian lettersdatalist = data.readlines()nSamples = len(datalist)print(nSamples)for i in range(nSamples):#TODO changed the way imagePath is found as well to match my usecaseimagePath, label = datalist[i].strip('\n').split('.png')imagePath += '.png'# imagePath, label = datalist[i].strip('\n').split('\t')imagePath = os.path.join(inputPath, imagePath)# # only use alphanumeric data# if re.search('[^a-zA-Z0-9]', label):# continueif not os.path.exists(imagePath):print('%s does not exist' % imagePath)continuewith open(imagePath, 'rb') as f:imageBin = f.read()if checkValid:try:if not checkImageIsValid(imageBin):print('%s is not a valid image' % imagePath)continueexcept:print('error occured', i)with open(outputPath + '/error_image_log.txt', 'a') as log:log.write('%s-th image data occured error\n' % str(i))continueimageKey = 'image-%09d'.encode() % cntlabelKey = 'label-%09d'.encode() % cntcache[imageKey] = imageBincache[labelKey] = label.encode()if cnt % 1000 == 0:writeCache(env, cache)cache = {}print('Written %d / %d' % (cnt, nSamples))cnt += 1nSamples = cnt-1cache['num-samples'.encode()] = str(nSamples).encode()writeCache(env, cache)print('Created dataset with %d samples' % nSamples)if __name__ == '__main__':fire.Fire(createDataset)在拥有正确的数据和正确的create_lmbd_dataset.py文件后,将文件夹移到deep-text-recognition-benchmark文件夹(您克隆的Git存储库)中。然后运行以下命令:
python .\create_lmdb_dataset.py <data folder name> <path to labels.txt in data folder> <output folder for your lmdb dataset>其中:
<data folder name> 是包含图像和labels.txt的文件夹名称(在我的情况下是output)。
<path to labels.txt>是.\output\labels.txt。
<output folder for your lmdb dataset>是将用于保存转换为lmdb格式的数据集的文件夹的名称(我称之为.\lmbd_output)。
对于我来说,上面的命令是这样的(确保在deep-text-recognition-benchmark文件夹中运行此命令):
python .\create_lmdb_dataset.py .\output .\output\labels.txt .\lmbd_output现在,您应该在deep-text-recognition-benchmark文件夹中有一个新文件夹,类似于下图。

文件夹转换为lmdb格式的数据
注意:在现有文件夹上运行命令不会覆盖现有文件夹。因此,请确保要么删除文件夹,要么为lmdb_output指定新名称(这是我挣扎了一段时间的事情,希望这个警告能确保您避免那个错误)。
检索预训练的OCR模型:
现在,您需要一个可以用您的数据集进行微调的预训练OCR模型。为此,您可以访问此Dropbox网站(https://drive.google.com/drive/folders/15WPsuPJDCzhp2SvYZLRj8mAlT3zmoAMW)并下载TPS-ResNet-BiLSTM-Attn.pth模型,然后将其放置在deep-text-recognition-benchmark文件夹中(我知道这看起来有点可疑,但这是deep-text-recognition-benchmark存储库告诉您如何做的方式。Dropbox不是我的,我在这里提供链接是因为在Git存储库text-recognition-benchmark中链接到了它)。
运行微调:
首先,如果您使用CPU(如果您使用GPU可以忽略此步骤),请注意。如果在CPU上运行,您可能会遇到错误,提示RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False。可以通过更改train.py文件中的第85和87行来修复此错误:
# OLD LINES
# ...
if opt.FT:model.load_state_dict(torch.load(opt.saved_model), strict=False)
else:model.load_state_dict(torch.load(opt.saved_model))
# ...# NEW LINES (change to this if you are using CPU)
#
if opt.FT:model.load_state_dict(torch.load(opt.saved_model,map_location='cpu'), strict=False)
else:model.load_state_dict(torch.load(opt.saved_model,map_location='cpu'))
# ...您还应该注意,如果数据中包含非字母数字字符,OCR 将不会运行微调。这意味着字符 A-Z 和 0-9,您可以在 Python 中使用以下行将所有非字母数字字符替换为空字符串:
new_word = re.sub("[^a-zA-Z]+", "", word)如果您要创建自己的数据集,这一点尤其重要,但如果您使用我在 Google Drive 中提供的数据集,则不必担心这一点,尽管在使用 OCR 时要注意这一点很重要。
最后,您可以运行微调。要运行微调,可以使用以下命令:
python train.py --train_data lmdb_output --valid_data lmdb_output --select_data "/" --batch_ratio 1.0 --Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction Attn --batch_size 2 --data_filtering_off --workers 0 --batch_max_length 80 --num_iter 10 --valInterval 5 --saved_model TPS-ResNet-BiLSTM-Attn.pth对命令的一些注释:
data_filtering_off 设置为True(只需使用该标志,无需给它变量)。我必须不使用数据过滤,因为启用过滤会导致无法训练样本。
workers 必须设置为0以避免错误。我认为这与多GPU设置有关,这也在deep-text-recognition-benchmark文件夹中的train.py文件中有提到。
batch_max_length 是训练数据集中任何文本的最大长度。如果使用不同的数据集,请随意更改此变量,但确保该变量至少与数据集中最长字符串的长度一样大,否则将收到错误。
对于本教程,我使用train_data和valid_data引用相同的文件夹。在实践中,我会创建一个包含训练数据集的文件夹,一个包含验证数据集的文件夹,并引用它们。
我将num_iter设置为10,以确保它可以工作。当进行实际模型微调时,自然必须将此变量设置得更高。
saved_model 是一个可选参数,但如果不设置它,将训练一个从头开始的模型。您可能不希望这样做(因为这将需要大量训练),因此将saved_model标志设置为从Dropbox下载的现有模型。
使用微调后的模型运行推理:
在微调模型后,您希望对其进行推理。为此,您可以使用以下命令:
python demo.py --Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction Attn --image_folder--saved_model其中:
<path to images to test on>是包含要测试的PNG图像的文件夹。对我来说,这是: output
<path to model to use>是您微调的模型的保存路径。对我来说,这是: .\saved_models\TPS-ResNet-BiLSTM-Attn-Seed1111\best_accuracy.pth(微调会将微调的模型保存在saved_models文件夹中)
我使用的命令是:
python demo.py --Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction Attn --image_folder output --saved_model .\saved_models\TPS-ResNet-BiLSTM-Attn-Seed1111\best_accuracy.pth我用于base EasyOCR 模型的命令是:
python demo.py --Transformation None --FeatureExtraction VGG --SequenceModeling BiLSTM --Prediction CTC --image_folder output --saved_model .\saved_models\None-VGG-BiLSTM-CTC-Seed1111\best_accuracy.pth该命令简单地输出模型对<要测试的图像路径>文件夹中的每个图像的预测和置信度分数,因此您可以通过自己查看图像并查看模型是否正确预测来检查模型的性能。这是模型性能的定性测试。
性能的定性测试:
为了查看微调是否起作用,我将对原始模型与我的微调模型在10个特定单词和数字上进行性能的定性测试。我测试的单词如下所示(垂直合并到一个图像中)。我通过添加倾斜和模糊使模型变得有些困难。

自制图像与 https://products.aspose.app/pdf/merger/png-to-png 合并。从上到下的单词是: “vanskeligheter”, “uvanligheter”, “skrekkeksempel”, “rosenborg”
考虑到我希望我的OCR能够读取挪威超市收据,我在这里放了一些挪威单词(这些单词来自http://openfoodfacts.com/,您可以在这篇文章中了解更多信息)。希望我的微调模型在这些单词上表现更好,因为原始OCR模型不习惯看到挪威单词,而我的微调模型已经在一些挪威单词上进行了训练。
每个图像中的文本是:
image0 -> vanskeligheter
image1 -> uvanligheter
image2 -> skrekkeksempel
image3 -> rosenborg
原始模型(未微调)的结果:

在定性测试中原始模型(未微调)的结果
微调模型的结果:

在定性测试中微调模型的结果
正如您所看到的,微调已经起作用,微调的模型在这个定性示例中取得了完美的结果。
性能的定量测试:
如果您想要进行更多定量测试,可以查看在微调期间显示的验证结果,或者您可以使用以下命令:
python test.py --eval_data--Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction Attn --saved_model--batch_max_length 70 --workers 0 --batch_size 2 --data_filtering_off其中:
<path to test data set in lmdb format>是包含lmdb格式测试数据的文件夹路径,即 lmdb_norwegian_data_test
<path to model to test>是要测试性能的模型的路径,即 saved_models/TPS-ResNet-BiLSTM-Attn-Seed1111/best_accuracy.pth
因此,我使用的命令是:
python test.py --eval_data lmdb_norwegian_data_test --Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction Attn --saved_model saved_models/TPS-ResNet-BiLSTM-Attn-Seed1111/best_accuracy.pth --batch_max_length 70 --workers 0 --batch_size 2 --data_filtering_off这将输出以百分比表示的准确性,即在测试数据集上OCR模型实现的准确性。在我的经验中,从Dropbox下载的模型需要一些训练。一开始,模型会做出完全没有意义的预测,但如果让它训练30分钟左右,您应该会看到一些改进。然后,我对上面显示的4个图像运行了test.py,并获得了以下结果,左边是旧模型(未微调),右边是新微调模型。您可以看到新的微调模型表现得更好。

旧模型(左边)实现了50%的准确性,新微调模型(右边)实现了100%的准确性
结论
您现在可以对光学字符识别(OCR)模型进行微调了。要对更大的模型产生显著影响并使其具有更好的泛化能力,您可能需要创建一个更大的数据集,您可以在本教程中了解相关信息,然后让模型进行一段时间的训练。最终,期望OCR模型在您的特定用例中表现更好。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除