今天在公司无聊的弄服务器,想着有些常用的工具包安装一下,这里就简单记录一下。
一、sysstat的安装和使用
1、安装
我是通过源码的方式安装的,这样的好处在于可以自由选择你的版本,很直观。
直接去github上找到sysstat的地址,选择对应的tag即可。我这里选择的是12.6.0,这个版本不是最新的,但是功能是完备的。
1,1、源码下载
https://github.com/sysstat/sysstat/releases/tag/v12.6.0
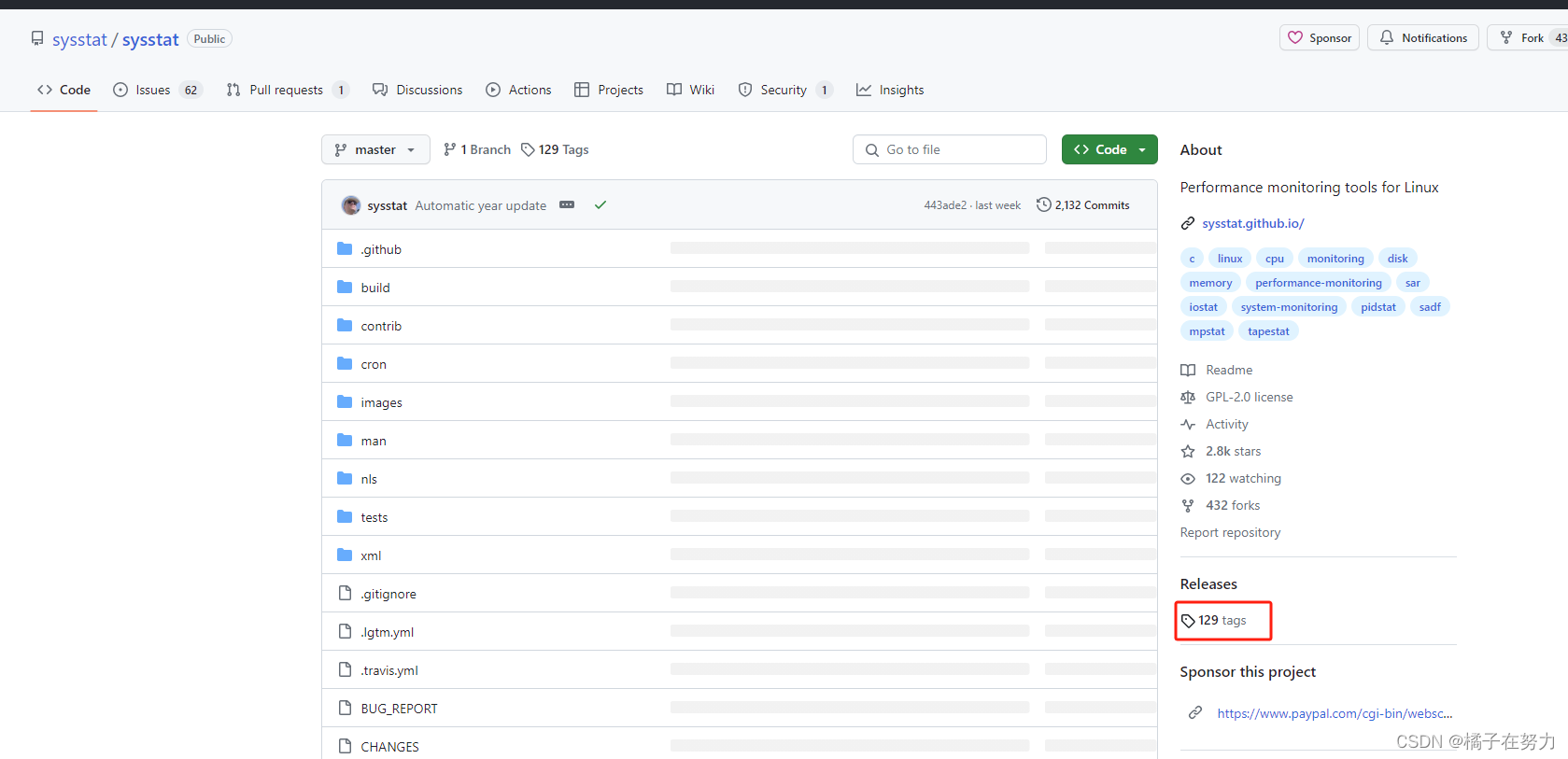
下载他的zip包即可。tar包也可以,看你习惯。
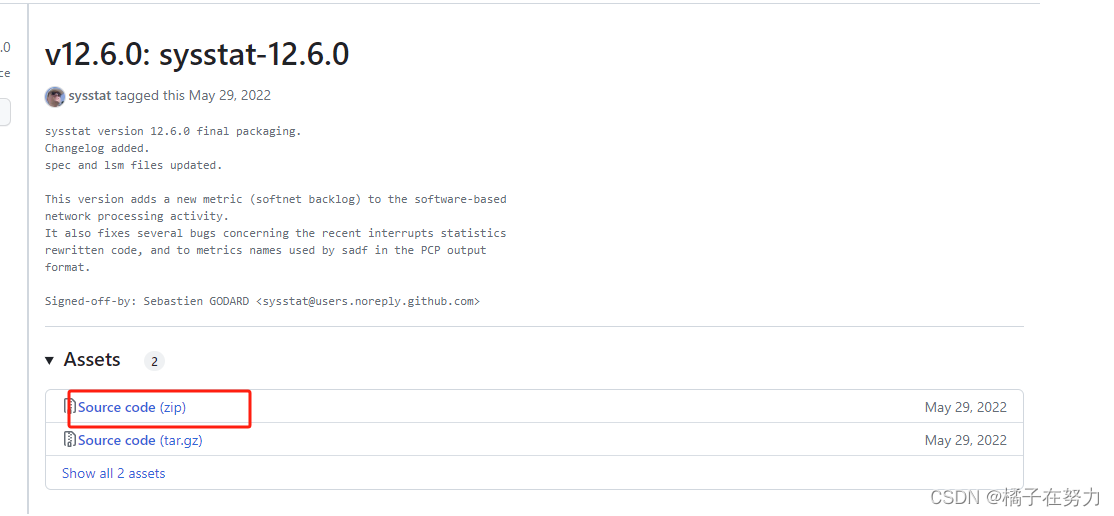
1. 2、上传解压
然后放在你的linux服务器目录下,我的位置在/opt/linux下面,如下图:
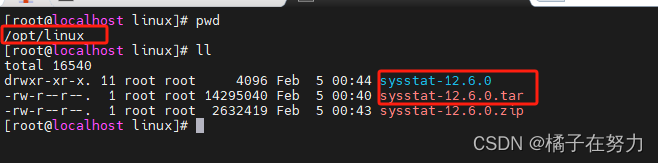
使用unzip sysstat-12.6.0.zip进行解压。
1. 3、编译安装
然后进入解压后的sysstat-12.6.0目录。
依次执行如下命令进行编译安装。
./configure
make
sudo make install
安装之后,需要配置环境变量,vim /etc/profile
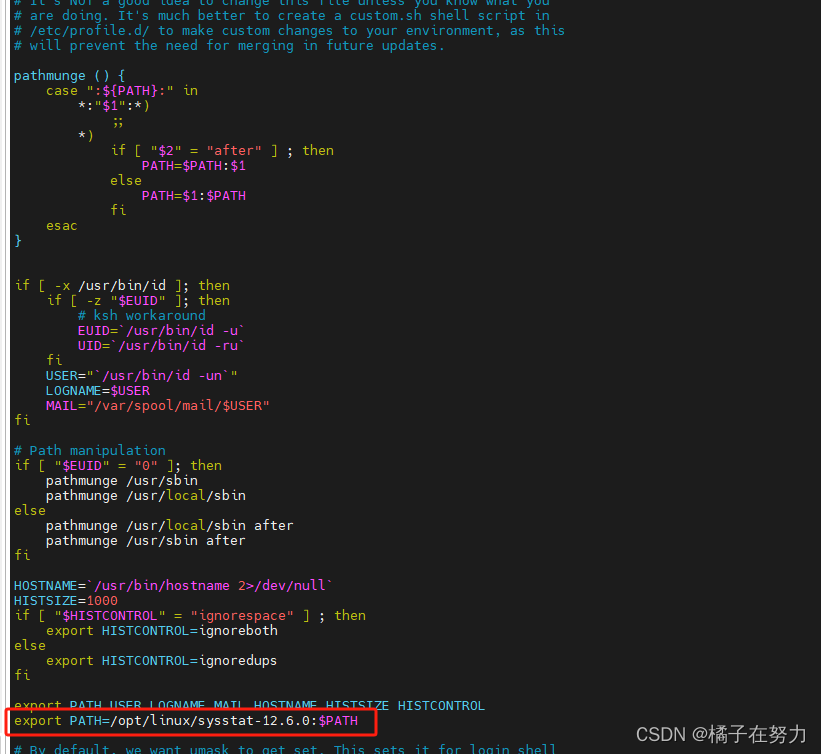
添加:
export PATH=/systat安装目录/sysstat:$PATH
然后使用source刷新配置文件。
source /etc/profile
然后执行mpstat -V查看安装是否完成即可。(mpstat就是sysstat包中的一个工具,有了这个就代表装上了。)

2、使用
他这个包下面包含很多工具,我们就先按照github上的描述贴出一部分他的主要工具有哪些,不然用的都不知道用啥。
The sysstat package contains various utilities, common to many commercial Unixes, to monitor system performance and usage activity:iostat reports CPU statistics and input/output statistics for block devices and partitions.
mpstat reports individual or combined processor related statistics.
pidstat reports statistics for Linux tasks (processes) : I/O, CPU, memory, etc.
tapestat reports statistics for tape drives connected to the system.
cifsiostat reports CIFS statistics.
Sysstat also contains tools you can schedule via cron or systemd to collect and historize performance and activity data:sar collects, reports and saves system activity information (see below a list of metrics collected by sar).
sadc is the system activity data collector, used as a backend for sar.
sa1 collects and stores binary data in the system activity daily data file. It is a front end to sadc designed to be run from cron or systemd.
sa2 writes a summarized daily activity report. It is a front end to sar designed to be run from cron or systemd.
sadf displays data collected by sar in multiple formats (CSV, XML, JSON, etc.) and can be used for data exchange with other programs. This command can also be used to draw graphs for the various activities collected by sar using SVG (Scalable Vector Graphics) format.
Default sampling interval is 10 minutes but this can be changed of course (it can be as small as 1 second).
翻译一下就是:
sysstat包包含许多商业Unix通用的各种实用程序,用于监视系统性能和使用活动:iostat报告块设备和分区的CPU统计信息和输入/输出统计信息。
mpstat报告单个或组合的处理器相关统计信息。
pidstat报告Linux任务(进程)的统计信息:I/O、CPU、内存等。
tapestat报告连接到系统的磁带驱动器的统计信息。
cifsiostat报告CIFS统计信息。
Sysstat还包含可以通过cron或systemd计划的工具,用于收集和历史化性能和活动数据:sar收集、报告和保存系统活动信息(请参阅下面由sar收集的指标列表)。
sadc是系统活动数据收集器,用作sar的后端。
sa1收集二进制数据并将其存储在系统活动每日数据文件中。它是sadc的前端,设计用于从cron或systemd运行。
sa2写一份总结的日常活动报告。它是sar的前端,设计用于从cron或systemd运行。
sadf以多种格式(CSV、XML、JSON等)显示sar收集的数据,并可用于与其他程序进行数据交换。该命令还可以用于使用SVG(可缩放矢量图形)格式为sar收集的各种活动绘制图形。
默认采样间隔为10分钟,但这当然可以更改(可以小到1秒)。
至于具体的用法和参数,我们后面不断在案例中提出,并且会完善回来这里。而且对于开发来说,很多工具是用不到的。
二、stress的安装和使用
stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
1、安装
# 需要安装扩展源
yum -y install epel-release# 安装stress命令
yum -y install stress
执行完,上述步骤,输入stress回车即可。发现已经有了这个工具
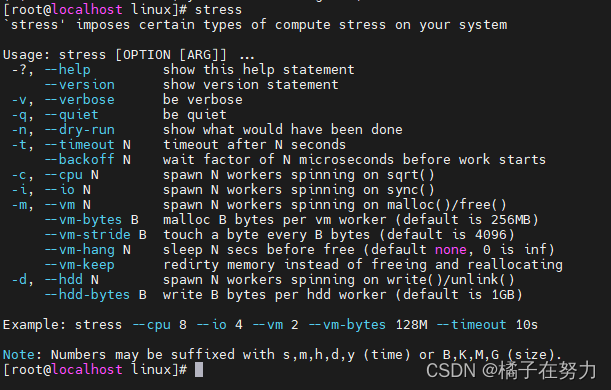
2、使用
stress命令参数:-c, --cpu N :产生 N 个进程,每个进程都反复不停的计算随机数的平方根; -t, --timeout N:在 N 秒后结束程序; -i, --io N :产生 N 个进程,每个进程反复调用 sync() 将内存上的内容写到硬盘上 -m, --vm N :产生 N 个进程,每个进程不断分配和释放内存
--vm-bytes B: 指定分配内存的大小,比如 --vm-bytes 128M 表示申请128M的内存大小--vm-stride B 不断的给部分内存赋值,让 COW(Copy On Write)发生
--vm-hang N 指示每个消耗内存的进程在分配到内存后转入睡眠状态 N 秒,然后释放内存,一直重复执行这个过程
--vm-keep 一直占用内存,区别于不断的释放和重新分配(默认是不断释放并重新分配内存)
-d, --hadd N 产生 N 个不断执行 write 和 unlink 函数的进程(创建文件,写入内容,删除文件)
--hadd-bytes B 指定文件大小
--backoff N 等待N微妙后开始运行
-q, --quiet 程序在运行的过程中不输出信息
-n, --dry-run 输出程序会做什么而并不实际执行相关的操作
--version 显示版本号
-v, --verbose 显示详细的信息
我们来做个例子说明一下这个东西的使用方法。
$ stress --cpu 1 --timeout 600
表示启动一个进程,不断的计算随机数的平方根,然后持续时间是600秒,换言之就是这600秒内,其对于一个cpu的占用是拉满到百分之百的。
stress -i 1 --timeout 600
表示启动一个进程,在600秒内不断地调用sync()系统函数,把缓冲区内容刷盘,也就是产生一个IO密集型的任务。
其余的我们用到再说。