文章目录
- 架构选型
- ELK
- EFLK
- Elasticsearch
- ES集群搭建
- 常用命令
- Filebeat
- 功能介绍
- 安装步骤
- Filebeat配置详解
- filebeat常用命令
- Logstash
- 功能介绍
- 安装步骤
- Input插件
- Filter插件
- Grok Filter 插件
- Mutate Filter 插件
- 常见的插件配置选项:
- Mutate Filter配置案例:
- Output插件
- Kibana
- 功能介绍
- 安装步骤
架构选型
ELK

“ELK” 是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
- Elasticsearch 是一个搜索和分析引擎。
- Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到Elasticsearch、kafka等。
- Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
一套日志采集系统需要具备以下5个功能:
- 收集 :能够采集多个来源的日志数据。
- 传输 :能够稳定的把日志数据传输到日志服务。
- 存储 :能够存储海量的日志数据。
- 查询 :能够灵活且高效的查询日志数据,并提供一定的分析能力。
- 告警 :能够提供提供告警功能,通知开发和运维等等
Elastic官网:https://www.elastic.co/cn/what-is/elk-stack
EFLK
在采集日志数据时,我们需要在服务器上安装一个 Logstash。不过 Logstash 是基于 JVM 的重量级的采集器,对系统的 CPU、内存、IO 等等资源占用非常高,这样可能影响服务器上的其它服务的运行。所以,Elastic NV 推出 Beats ,基于 Go 的轻量级采集器,对系统的 CPU、内存、IO 等等资源的占用基本可以忽略不计。因此,本文的示例就变成了 ELFK 。其中,Beats 负责采集数据,并通过网路传输给 Logstash。即整体架构:
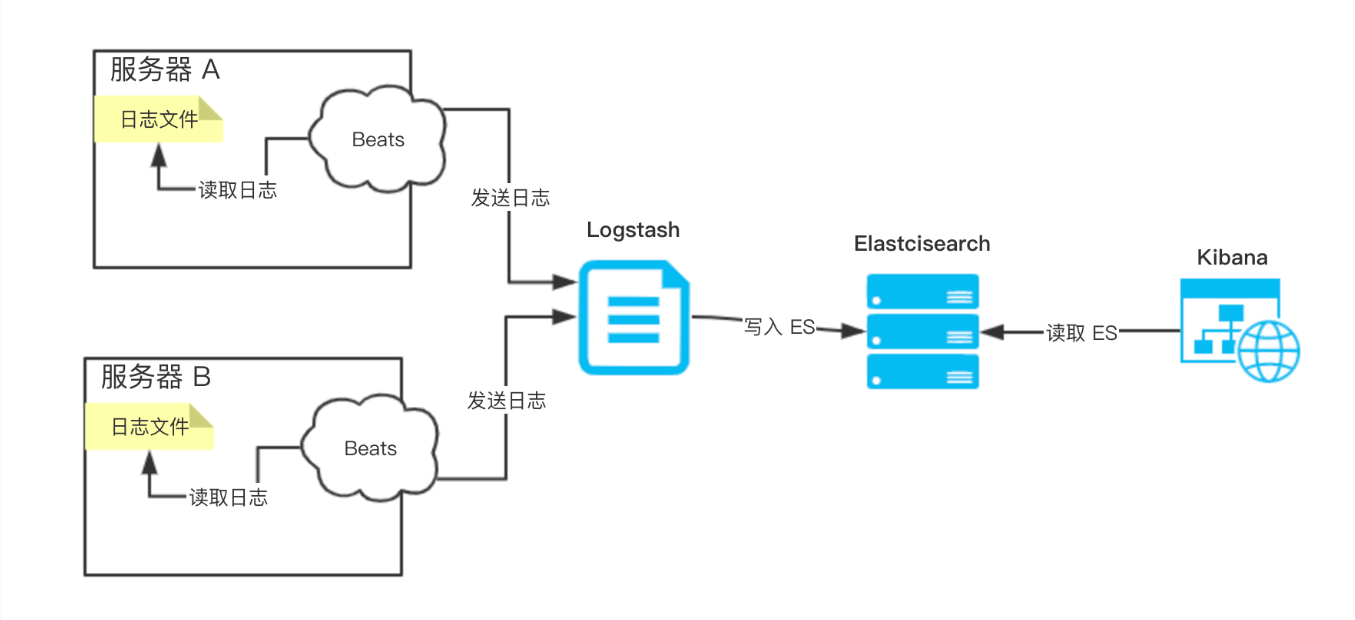
Beats 是一个全品类采集器的系列,包含多个:(使用 Filebeat,采集日志文件)
- Filebeat :轻量型日志采集器。√
- Metricbeat :轻量型指标采集器。
- Packetbeat :轻量型网络数据采集器。
- Winlogbeat :轻量型 Windows 事件日志采集器。
- Auditbeat :轻量型审计日志采集器。
- Heartbeat :面向运行状态监测的轻量型采集器。
- Functionbeat :面向云端数据的无服务器采集器。
Elasticsearch
ES集群搭建
参考:Elasticsearch7.x - 集群部署 - lihewei - 博客园 (cnblogs.com)
常用命令
启动 Elasticsearch 服务:
# 使用命令行启动 Elasticsearch 服务
elasticsearch# 或者使用 systemd(根据您的操作系统)
sudo systemctl start elasticsearch
停止 Elasticsearch 服务:
# 使用命令行停止 Elasticsearch 服务
Ctrl+C# 或者使用 systemd(根据您的操作系统)
sudo systemctl stop elasticsearch
检查 Elasticsearch 集群健康状态:
# 使用 curl 命令检查集群健康状态
curl -X GET "http://localhost:9200/_cat/health?v"
查看节点信息:
shellCopy code
# 使用 curl 命令查看节点信息
curl -X GET "http://localhost:9200/_cat/nodes?v"创建索引:
# 使用 curl 命令创建一个名为 "my_index" 的索引
curl -X PUT "http://localhost:9200/my_index"
删除索引:
# 使用 curl 命令删除名为 "my_index" 的索引
curl -X DELETE "http://localhost:9200/my_index"
索引文档:
# 使用 curl 命令索引一篇文档到 "my_index" 索引中
curl -X POST "http://localhost:9200/my_index/_doc" -d '{"field1": "value1","field2": "value2"
}'
搜索文档:
# 使用 curl 命令执行搜索查询
curl -X GET "http://localhost:9200/my_index/_search?q=field1:value1"
查看索引的映射(Mapping):
# 使用 curl 命令查看索引 "my_index" 的映射
curl -X GET "http://localhost:9200/my_index/_mapping"
查看索引的统计信息:
# 使用 curl 命令查看索引 "my_index" 的统计信息
curl -X GET "http://localhost:9200/my_index/_stats"
查看索引中的文档数量:
# 使用 curl 命令查看索引 "my_index" 中的文档数量
curl -X GET "http://localhost:9200/my_index/_count"
聚合数据:
# 使用 curl 命令执行聚合操作
curl -X POST "http://localhost:9200/my_index/_search" -d '{"size": 0,"aggs": {"avg_field2": {"avg": {"field": "field2"}}}
}'
更新文档:
# 使用 curl 命令更新文档
curl -X POST "http://localhost:9200/my_index/_update/1" -d '{"doc": {"field1": "new_value"}
}'
删除文档:
# 使用 curl 命令删除文档
curl -X DELETE "http://localhost:9200/my_index/_doc/1"
Filebeat
功能介绍
Filebeat是一个轻量型日志采集器,负责采集数据,并通过网路传输给 Logstash。
安装步骤
1)官网下载:https://www.elastic.co/cn/downloads/beats/filebeat
2)解压:tar -zxvf filebeat-7.5.1-darwin-x86_64.tar.gz
3)修改配置:
filebeat.inputs:
- type: logenabled: truepaths:- /home/crbt/logs/crbtRingSync/wrapper.logfields:log_source: vrbt-rd1-hbbjlog_topic: crbt-web-logoutput.kafka:hosts: ["10.1.61.121:9092"]topic: '%{[fields.log_topic]}'
Filebeat配置详解
filebeat.inputs配置项,设置 Filebeat 读取的日志来源。该配置项是数组类型,可以将 Nginx、MySQL、Spring Boot 每一类,作为数组中的一个元素。output.elasticsearch配置项,设置 Filebeat 直接写入数据到 Elasticsearch 中。虽然说 Filebeat5.0版本以来,也提供了 Filter 功能,但是相比 Logstash 提供的 Filter 会弱一些。所以在一般情况下,Filebeat 并不直接写入到 Elasticsearch 中output.logstash配置项,设置 Filebeat 写入数据到 Logstash 中output.kafka配置项,设置Filebeat 写入数据到 kafka 中
filebeat常用命令
# 启动filebeat
nohup ./filebeat -e &# -e 参数表示以前台模式运行 -c 指定配置文件
./filebeat -e -c /home/crbt/lihewei/filebeat-7.5.1-linux-x86_64/filebeat.yml
./filebeat -e -c filebeat.yml# 查看filebeat是否正常启动
curl http://localhost:5066/
ps -ef | grep filebeat
Logstash
功能介绍
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到喜欢的“存储库”中。通过定义了一个 Logstash 管道(Logstash Pipeline),来读取、过滤、输出数据。一个 Logstash Pipeline 包含三部分:
- 【必选】输入(Input): 数据(包含但不限于日志)往往都是以不同的形式、格式存储在不同的系统中,而 Logstash 支持从多种数据源中收集数据(File、Syslog、MySQL、消息中间件等等)
- 【可选】过滤器(Filter) :实时解析和转换数据,识别已命名的字段以构建结构,并将它们转换成通用格式。
- 【必选】输出(Output) :Elasticsearch 并非存储的唯一选择,Logstash 提供很多输出选择。
安装步骤
1)下载: https://www.elastic.co/cn/products/logstash
2)解压:unzip logstash-7.5.1.zip
3)修改配置文件
在 config 目录下,提供了 Logstash 的配置文件,其中,logstash-sample.conf 配置文件,是 Logstash 提供的 Pipeline 配置的示例
crbt@node2:/home/crbt/lihw/logstash-7.5.1/config>ll
total 40
-rw-r--r-- 1 crbt crbt 2019 Dec 17 2019 jvm.options
-rw-r--r-- 1 crbt crbt 7482 Dec 17 2019 log4j2.properties
-rw-rw-r-- 1 crbt crbt 843 Sep 15 19:07 logstash.conf
-rw-r--r-- 1 crbt crbt 342 Dec 17 2019 logstash-sample.conf
-rw-r--r-- 1 crbt crbt 8372 Sep 15 10:53 logstash.yml
-rw-r--r-- 1 crbt crbt 3146 Dec 17 2019 pipelines.yml
-rw-r--r-- 1 crbt crbt 1696 Dec 17 2019 startup.options
crbt@node2:/home/crbt/lihw/logstash-7.5.1/config>cat logstash-sample.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.#日志消息从哪里来(这里使用filebeat进行日志收集)
input {beats {port => 5044}
}#日志信息输出到哪里去(这里写入es数据库)
output {elasticsearch {hosts => ["http://10.1.61.121:9200"]index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"}
}
4)指定配置文件并启动logstash:W
# 启动logstash服务(指定自定义的配置文件logstash.conf)
./logstash -f ../config/logstash.conf# 后台启动logstash服务🚩
nohup ./logstash -f ../config/logstash.conf &Input插件
Logstash 的 input 插件用于从不同的数据源中接收数据,并将其发送到 Logstash 事件流中供进一步处理。每个 input 插件都有其特定的配置选项,以适应不同类型的数据源,修改自定义的配置文件即可生效(下面仅列举了几个常用输入方法)
-
File Input 插件:用于从本地文件读取数据。
input {file {path => "/path/to/your/logfile.log"start_position => "beginning"sincedb_path => "/dev/null"} } -
Beats Input 插件:用于接收来自 Elastic Beats 系列工具(如 Filebeat、Metricbeat)的数据。
input {beats {port => 5044} } -
Kafka Input 插件:用于从 Apache Kafka 主题中消费数据。
input {kafka {bootstrap_servers => "kafka-server:9092"topics => ["your-topic"]} }
Filter插件
Logstash 的 filter 插件用于对接收的事件进行处理、转换和丰富,以便更好地进行索引和分析。每个 filter 插件都有其特定的配置选项,以适应不同的数据处理需求。以下是一些常见的 Logstash filter 插件及其配置示例:
Grok Filter 插件
Logstash 的 Grok Filter 插件用于从非结构化的文本数据中提取结构化的字段。
filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}" }}
}
Mutate Filter 插件
常见的插件配置选项:
-
add_field:添加新字段到事件中,并指定字段的名称和值。
rubyCopy code mutate {add_field => { "new_field" => "New Value" } } -
remove_field:从事件中删除指定字段。
rubyCopy code mutate {remove_field => [ "field1", "field2" ] } -
rename:重命名事件中的字段,将字段从旧名称改为新名称。
rubyCopy code mutate {rename => { "old_field" => "new_field" } } -
copy:复制字段的值到新的字段中。
rubyCopy code mutate {copy => { "source_field" => "destination_field" } } -
replace:替换字段的值为新的值。
rubyCopy code mutate {replace => { "field_to_replace" => "new_value" } } -
update:更新字段的值为新的值,类似于替换操作。
rubyCopy code mutate {update => { "field_to_update" => "new_value" } } -
convert:将字段的数据类型转换为指定的类型。
rubyCopy code mutate {convert => { "numeric_field" => "integer" } } -
gsub:使用正则表达式替换字段中的文本。
rubyCopy code mutate {gsub => [ "field_to_modify", "pattern_to_replace", "replacement_text" ] } -
uppercase/lowercase:将字段值转换为大写或小写。
rubyCopy code mutate {uppercase => [ "field_to_uppercase" ]lowercase => [ "field_to_lowercase" ] } -
strip:删除字段值两端的空格。
rubyCopy code mutate {strip => [ "field_to_strip" ] }
Mutate Filter配置案例:
用于对字段进行修改、重命名和删除。
filter {mutate {add_field => { "new_field" => "New Value" }rename => { "user" => "username" }remove_field => [ "message" ]}
}
在上面的配置中,我们使用 Mutate Filter 插件执行了以下操作:
- add_field:我们添加了一个名为 “new_field” 的新字段,并将其值设置为 “New Value”。此时事件将变为:
- rename:我们重命名了 “user” 字段为 “username”。此时事件将变为:
- remove_field:我们删除了 “message” 字段。此时事件将不再包含 “message” 字段。
#过滤前
{"message": "Log entry","user": "john_doe","status": "success","response_time_ms": 45
}#过滤后
{"username": "john_doe","status": "success","response_time_ms": 45,"new_field": "New Value"
}
Output插件
Logstash 的 output 插件用于将处理过的事件发送到各种目标,如 Elasticsearch、文件、数据库等。每个 output 插件都有其特定的配置选项,以适应不同的目标和需求。以下是一些常见的 Logstash output 插件及其配置示例:
-
Elasticsearch Output 插件:用于将事件发送到 Elasticsearch 集群。
output {elasticsearch {hosts => ["http://localhost:9200"]index => "my_index"} } -
File Output 插件:用于将事件写入本地文件。
output {file {path => "/path/to/output/file.txt"} } -
Kafka Output 插件:用于将事件发送到 Apache Kafka 主题。
rubyCopy code output {kafka {topic_id => "my_topic"bootstrap_servers => "kafka-server:9092"} }
Kibana
功能介绍
通过 Kibana,您可以对自己的 Elasticsearch 进行可视化,也可以通过插件的方式查看es
安装步骤
1)官网下载:https://www.elastic.co/cn/products/kibana
2)解压 tar -zxvf kibana-7.5.1-darwin-x86_64.tar.gz
3)修改配置,vi config/kibana.yml 命令,编辑 Kibana 配置文件
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
kibana.index: ".kibana"
4)启动Kibana:nohup bin/kibana & 命令,后台启动 Kibana 服务。
nohup bin/kibana &nohup ./kibana &ps aux | grep kibana
5)测试:访问 http://10.1.61.122:5601/ 地址,查看 Kibana 是否启动成功