目录
1、提取函数来减少重复
2、在函数定义中使用泛型
3、结构体定义中的泛型
4、枚举定义中的泛型
5、方法定义中的泛型
6、泛型代码的性能
每一门编程语言都有高效处理重复概念的工具。在 Rust 中其工具之一就是 泛型(generics)。泛型是具体类型或其他属性的抽象替代。我们可以表达泛型的属性,比如它们的行为或如何与其他泛型相关联,而不需要在编写和编译代码时知道它们在这里实际上代表什么。
首先,我们将回顾一下提取函数以减少代码重复的机制。接下来,我们将使用相同的技术,从两个仅参数类型不同的函数中创建一个泛型函数。我们也会讲到结构体和枚举定义中的泛型。
之后,我们讨论 trait,这是一个定义泛型行为的方法。trait 可以与泛型结合来将泛型限制为只接受拥有特定行为的类型,而不是任意类型。
最后介绍 生命周期(lifetimes),它是一类允许我们向编译器提供引用如何相互关联的泛型。Rust 的生命周期功能允许在很多场景下借用值的同时仍然使编译器能够检查这些引用的有效性。
1、提取函数来减少重复
让我们从下面这个这个寻找列表中最大值的小程序开始,如下所示:
fn main() {let number_list = vec![34, 50, 25, 100, 65]; // 定义一个列表let mut largest = &number_list[0]; // 定义一个可变变量largest,默认取列表的第一个值for number in &number_list {if number > largest { // 遍历如果值大于上面定义第一个值,则对应的值覆盖原来的值largest = number;}}println!("The largest number is {}", largest); // 100
}为了消除重复,我们要创建一层抽象,定义一个处理任意整型列表作为参数的函数。这个方案使得代码更简洁,并且表现了寻找任意列表中最大值这一概念。
fn largest(list: &[i32]) -> &i32 {let mut largest = &list[0];for item in list {if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest(&number_list);println!("The largest number is {}", result);let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];let result = largest(&number_list);println!("The largest number is {}", result);
}
largest 函数有一个参数 list,它代表会传递给函数的任何具体的 i32值的 slice。函数定义中的 list 代表任何 &[i32]。当调用 largest 函数时,其代码实际上运行于我们传递的特定值上。
2、在函数定义中使用泛型
当使用泛型定义函数时,本来在函数签名中指定参数和返回值的类型的地方,会改用泛型来表示。采用这种技术,使得代码适应性更强,从而为函数的调用者提供更多的功能,同时也避免了代码的重复。
回到 largest 函数,以下示例中展示了两个函数,它们的功能都是寻找 slice 中最大值。接着我们使用泛型将其合并为一个函数。
fn largest_i32(list: &[i32]) -> &i32 {let mut largest = &list[0];for item in list {if item > largest {largest = item;}}largest
}fn largest_char(list: &[char]) -> &char {let mut largest = &list[0];for item in list {if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest_i32(&number_list);println!("The largest number is {}", result);let char_list = vec!['y', 'm', 'a', 'q'];let result = largest_char(&char_list);println!("The largest char is {}", result);
}
为了参数化这个新函数中的这些类型,我们需要为类型参数命名,道理和给函数的形参起名一样。任何标识符都可以作为类型参数的名字。这里选用 T,因为传统上来说,Rust 的类型参数名字都比较短,通常仅为一个字母,同时,Rust 类型名的命名规范是首字母大写驼峰式命名法(UpperCamelCase)。T 作为 “type” 的缩写是大部分 Rust 程序员的首选。
如果要在函数体中使用参数,就必须在函数签名中声明它的名字,好让编译器知道这个名字指代的是什么。同理,当在函数签名中使用一个类型参数时,必须在使用它之前就声明它。为了定义泛型版本的 largest 函数,类型参数声明位于函数名称与参数列表中间的尖括号 <> 中,像这样:
fn largest<T>(list: &[T]) -> &T {可以这样理解这个定义:函数 largest 有泛型类型 T。它有个参数 list,其类型是元素为 T 的 slice。largest 函数会返回一个与 T 相同类型的引用。
在以下示例中,largest 函数在它的签名中使用了泛型,统一了两个实现。该示例也展示了如何调用 largest 函数,把 i32 值的 slice 或 char 值的 slice 传给它。请注意这些代码还不能编译!
fn largest<T>(list: &[T]) -> &T {let mut largest = &list[0];for item in list {if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest(&number_list);println!("The largest number is {}", result);let char_list = vec!['y', 'm', 'a', 'q'];let result = largest(&char_list);println!("The largest char is {}", result);
}运行以上代码,会报以下错误。

帮助说明中提到了 std::cmp::PartialOrd,这是一个 trait。下一部分会讲到 trait。不过简单来说,这个错误表明 largest 的函数体不能适用于 T 的所有可能的类型。因为在函数体需要比较 T 类型的值,不过它只能用于我们知道如何排序的类型。为了开启比较功能,标准库中定义的 std::cmp::PartialOrd trait 可以实现类型的比较功能(查看附录 C 获取该 trait 的更多信息)。依照帮助说明中的建议,我们限制 T 只对实现了 PartialOrd 的类型有效后代码就可以编译了,因为标准库为 i32 和 char 实现了 PartialOrd。
3、结构体定义中的泛型
同样也可以用 <> 语法来定义结构体,它包含一个或多个泛型参数类型字段。下列示例定义了一个可以存放任何类型的 x 和 y 坐标值的结构体 Point:
struct Point<T> {x: T,y: T,
}fn main() {let integer = Point { x: 5, y: 10 };let float = Point { x: 1.0, y: 4.0 };
}其语法类似于函数定义中使用泛型。首先,必须在结构体名称后面的尖括号中声明泛型参数的名称。接着在结构体定义中可以指定具体数据类型的位置使用泛型类型。
注意 Point<T> 的定义中只使用了一个泛型类型,这个定义表明结构体 Point<T> 对于一些类型 T 是泛型的,而且字段 x 和 y 都是 相同类型的,无论它具体是何类型。如果尝试创建一个有不同类型值的 Point<T> 的实例,在以下示例代码中是不能编译的。
struct Point<T> {x: T,y: T,
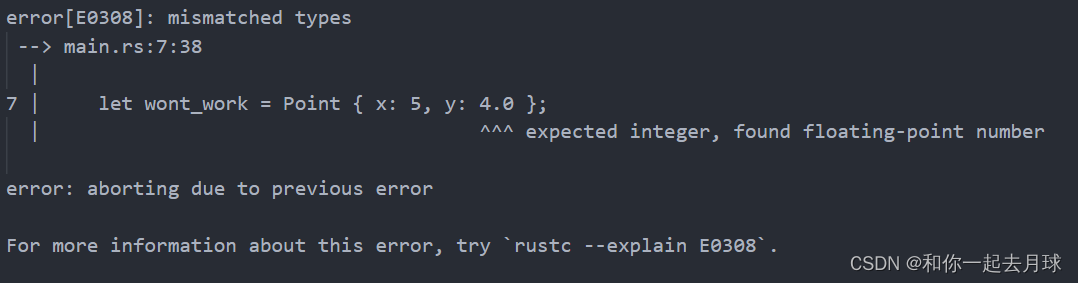
}fn main() {let wont_work = Point { x: 5, y: 4.0 };
}在这个例子中,当把整型值 5 赋值给 x 时,就告诉了编译器这个 Point<T> 实例中的泛型 T 全是整型。接着指定 y 为浮点值 4.0,因为它y被定义为与 x 相同类型,所以将会得到一个像这样的类型不匹配错误:
如果想要定义一个 x 和 y 可以有不同类型且仍然是泛型的 Point 结构体,我们可以使用多个泛型类型参数。在以下示例,我们修改 Point 的定义为拥有两个泛型类型 T 和 U。其中字段 x 是 T 类型的,而字段 y 是 U 类型的:
struct Point<T, U> {x: T,y: U,
}fn main() {let both_integer = Point { x: 5, y: 10 };let both_float = Point { x: 1.0, y: 4.0 };let integer_and_float = Point { x: 5, y: 4.0 };
}4、枚举定义中的泛型
和结构体类似,枚举也可以在成员中存放泛型数据类型。第六章我们曾用过标准库提供的 Option<T> 枚举,这里再回顾一下:
enum Option<T> {Some(T),None,
}现在这个定义应该更容易理解了。如你所见 Option<T> 是一个拥有泛型 T 的枚举,它有两个成员:Some,它存放了一个类型 T 的值,和不存在任何值的None。通过 Option<T> 枚举可以表达有一个可能的值的抽象概念,同时因为 Option<T> 是泛型的,无论这个可能的值是什么类型都可以使用这个抽象。
枚举也可以拥有多个泛型类型。
enum Result<T, E> {Ok(T),Err(E),
}Result 枚举有两个泛型类型,T 和 E。Result 有两个成员:Ok,它存放一个类型 T 的值,而 Err 则存放一个类型 E 的值。这个定义使得 Result 枚举能很方便的表达任何可能成功(返回 T 类型的值)也可能失败(返回 E 类型的值)的操作。
5、方法定义中的泛型
在为结构体和枚举实现方法时(像第五章那样),一样也可以用泛型。
struct Point<T> {x: T,y: T,
}impl<T> Point<T> {fn x(&self) -> &T {&self.x}
}fn main() {let p = Point { x: 5, y: 10 };println!("p.x = {}", p.x());
}这里在 Point<T> 上定义了一个叫做 x 的方法来返回字段 x 中数据的引用:
注意必须在 impl 后面声明 T,这样就可以在 Point<T> 上实现的方法中使用 T 了。通过在 impl 之后声明泛型 T,Rust 就知道 Point 的尖括号中的类型是泛型而不是具体类型。我们可以为泛型参数选择一个与结构体定义中声明的泛型参数所不同的名称,不过依照惯例使用了相同的名称。在声明泛型类型参数的 impl 中编写的方法将会定义在该类型的任何实例上,无论最终替换泛型类型参数的是何具体类型。
定义方法时也可以为泛型指定限制(constraint)。例如,可以选择为 Point<f32> 实例实现方法,而不是为泛型 Point 实例。示例 10-10 展示了一个没有在 impl 之后(的尖括号)声明泛型的例子,这里使用了一个具体类型,f32:
impl Point<f32> {fn distance_from_origin(&self) -> f32 {(self.x.powi(2) + self.y.powi(2)).sqrt()}
}这段代码意味着 Point<f32> 类型会有一个方法 distance_from_origin,而其他 T 不是 f32 类型的 Point<T> 实例则没有定义此方法。这个方法计算点实例与坐标 (0.0, 0.0) 之间的距离,并使用了只能用于浮点型的数学运算符。
结构体定义中的泛型类型参数并不总是与结构体方法签名中使用的泛型是同一类型。示例 10-11 中为 Point 结构体使用了泛型类型 X1 和 Y1,为 mixup 方法签名使用了 X2 和 Y2 来使得示例更加清楚。这个方法用 self 的 Point 类型的 x 值(类型 X1)和参数的 Point 类型的 y 值(类型 Y2)来创建一个新 Point 类型的实例:
struct Point<X1, Y1> {x: X1,y: Y1,
}impl<X1, Y1> Point<X1, Y1> {fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> {Point {x: self.x,y: other.y,}}
}fn main() {let p1 = Point { x: 5, y: 10.4 };let p2 = Point { x: "Hello", y: 'c' };let p3 = p1.mixup(p2);println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}在 main 函数中,定义了一个有 i32 类型的 x(其值为 5)和 f64 的 y(其值为 10.4)的 Point。p2 则是一个有着字符串 slice 类型的 x(其值为 "Hello")和 char 类型的 y(其值为c)的 Point。在 p1 上以 p2 作为参数调用 mixup 会返回一个 p3,它会有一个 i32 类型的 x,因为 x 来自 p1,并拥有一个 char 类型的 y,因为 y 来自 p2。println! 会打印出 p3.x = 5, p3.y = c。
6、泛型代码的性能
Rust 通过在编译时进行泛型代码的 单态化(monomorphization)来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程。
在这个过程中,编译器所做的工作正好与示例 10-5 中我们创建泛型函数的步骤相反。编译器寻找所有泛型代码被调用的位置并使用泛型代码针对具体类型生成代码。
让我们看看这如何用于标准库中的 Option 枚举:
let integer = Some(5);
let float = Some(5.0);当 Rust 编译这些代码的时候,它会进行单态化。编译器会读取传递给 Option<T> 的值并发现有两种 Option<T>:一个对应 i32 另一个对应 f64。为此,它会将泛型定义 Option<T> 展开为两个针对 i32 和 f64 的定义,接着将泛型定义替换为这两个具体的定义。
编译器生成的单态化版本的代码看起来像这样(编译器会使用不同于如下假想的名字):
enum Option_i32 {Some(i32),None,
}enum Option_f64 {Some(f64),None,
}fn main() {let integer = Option_i32::Some(5);let float = Option_f64::Some(5.0);
}泛型 Option<T> 被编译器替换为了具体的定义。因为 Rust 会将每种情况下的泛型代码编译为具体类型,使用泛型没有运行时开销。当代码运行时,它的执行效率就跟好像手写每个具体定义的重复代码一样。这个单态化过程正是 Rust 泛型在运行时极其高效的原因。