BLIP-2
- BLIP 对比 BLIP-2
- BLIP
- BLIP-2
- 如何在视觉和语言模型之间实现有效的信息交互,同时降低预训练的计算成本?
- 视觉语言表示学习
- 视觉到语言的生成学习
- 模型架构设计
- 总结
- 主要问题: 如何在计算效率和资源有限的情况下,有效地结合冻结的图像编码器和大型语言模型,来提高在视觉语言任务上的性能?
- 子解法1: 视觉语言表示学习
- 子解法2: 视觉到语言的生成学习
- 子解法3: 模型预训练
论文:https://arxiv.org/pdf/2301.12597.pdf
代码:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
BLIP 对比 BLIP-2
BLIP:跨越视觉-语言界限:BLIP的多任务精细处理策略
BLIP(Bootstrapping Language-Image Pre-training)和BLIP-2都是在视觉-语言预训练领域的重要工作,旨在通过学习视觉和语言之间的联系来提升模型在多种下游任务上的性能。
然而,这两个模型在设计理念、实现方法以及目标任务上存在显著的差异。
BLIP
设计理念:
- BLIP采用了一种创新的预训练框架,通过结合图像编码器和语言模型,并引入标题生成与过滤(CapFilt)机制来优化训练数据的质量。
实现方法:
- 通过多模态混合编解码器(MED),BLIP能够灵活处理不同的视觉-语言任务,包括图像-文本检索、图像描述生成等。
- CapFilt机制通过生成合成标题并过滤掉噪声数据,提高了模型学习的效率和准确性。
目标任务:
- BLIP旨在提升模型在多种视觉-语言任务上的表现,特别是在数据质量和多任务适用性方面进行了优化。
BLIP-2
设计理念:
- BLIP-2关注于降低视觉-语言预训练的计算成本,通过利用现成的、冻结的图像编码器和大型语言模型来实现预训练策略。
实现方法:
- 引入了轻量级的查询变换器(Querying Transformer,简称Q-Former),它在两个阶段中进行预训练:首先从冻结的图像编码器学习视觉-语言表示,然后从冻结的语言模型学习视觉到语言的生成学习。
- Q-Former作为信息瓶颈,将图像特征有效地传递给语言模型,以生成相关的文本描述。
目标任务:
- BLIP-2在多种视觉-语言任务上实现了最先进的性能,包括视觉问答、图像描述和图像-文本检索等。
- 特别地,BLIP-2展示了零样本图像到文本生成的能力,能够遵循自然语言指令生成文本,开启了如视觉知识推理、视觉对话等新能力。
对比总结:
- BLIP强调通过数据质量优化和多任务灵活性来提升性能,而BLIP-2则侧重于计算效率的提升,利用冻结的单模态模型和轻量级转换器降低预训练成本。
- BLIP-2相比于BLIP,在保持高性能的同时,大大减少了可训练参数的数量,显示出在计算资源有限情况下的优势。
- 两者均展现了视觉-语言模型的强大潜力,但各自通过不同的策略和技术实现来解决视觉和语言联合理解的挑战。
如何在视觉和语言模型之间实现有效的信息交互,同时降低预训练的计算成本?
BLIP-2 结构:
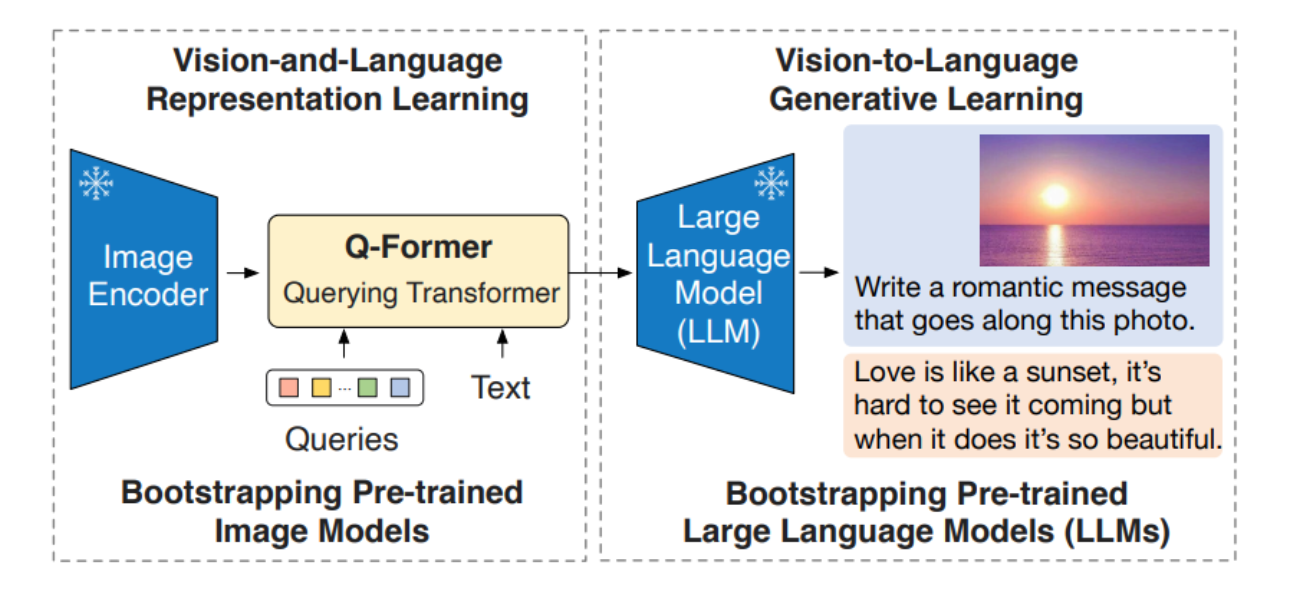
该模型通过两个阶段的预训练Querying Transformer来连接视觉和文本模态。
第一阶段通过冻结的图像编码器启动视觉与语言的表示学习。
第二阶段通过冻结的大型语言模型(LLM)启动视觉到语言的生成学习,使得模型能够实现零样本的图像到文本生成。
- 子问题: 如何有效地从图像中提取特征以供语言模型使用,而不需要重新训练图像编码器?
- 子解法: Bootstrapping Pre-trained Image Models。
- 利用冻结的预训练图像编码器来提取图像特征,降低了额外的计算成本,同时利用了图像编码器强大的视觉理解能力。
- 之所以使用此解法,是因为预训练图像模型已经具有高质量的视觉表示能力,这样可以直接利用这些能力,而无需通过昂贵的重新训练来适应视觉任务。
假设有一张图片,图片上是一只在公园里追球的小狗。
使用BLIP-2的方法,我们不需要对图像编码器进行任何新的训练。
这个冻结的预训练图像编码器已经学会如何识别图片中的对象,比如小狗、球和公园。
当这张图片通过图像编码器时,它能有效地提取出这些特征(小狗、球和公园)。
这些特征随后被用作语言生成模型的输入,即使这个语言模型原本并不直接处理图像数据。
这样,我们就能利用已有的高质量视觉表示,而无需额外的计算成本来重新训练图像编码器。
- 子问题: 如何使冻结的大型语言模型能理解和生成与图像内容相关的文本?
- 子解法: Bootstrapping Pre-trained Large Language Models (LLMs)。
- 通过连接一个轻量级的Querying Transformer(查询变换器)到冻结的LLM,使其能够基于图像特征生成相关的文本描述。
- 之所以使用此解法,是因为大型语言模型虽然在文本生成方面能力强大,但它们未经训练以直接处理图像数据。引入查询变换器可以将图像特征转换成语言模型能理解的格式,从而实现跨模态学习。
现在我们有了小狗追球的图像特征,接下来的挑战是如何让一个未曾直接处理过图像的大型语言模型理解这些特征,并生成相关的文本。
这里,BLIP-2引入了一个轻量级的查询变换器。
这个查询变换器被训练以从图像编码器提取的特征中挑选出最有意义的信息,然后以一种语言模型能理解的方式呈现这些信息。
在这个例子中,查询变换器可能会学习到如何将“小狗”、“球”和“公园”的视觉特征转换成语言模型可以利用的提示,比如“一只小狗在公园里追一个球”。
因此,即使语言模型原先并不直接处理图像数据,它现在也能基于这些转换后的提示生成描述性文本,如“快乐的小狗在阳光下追逐着球”,实现了有效的视觉到语言的跨模态学习。
- 子问题: 如何确保从图像编码器提取的特征对语言生成最有用?
- 子解法: 学习查询向量。
- 通过训练Querying Transformer中的查询向量来选择性地提取对语言模型最有意义的图像特征。
- 例子: 假如我们要从一张图片中生成描述,查询变换器学习到的查询向量可能专注于图像中的关键物体或场景,以便生成准确的描述。
- 子问题: 如何优化这种跨模态的信息流动,以提高效率和性能?
- 子解法: 两阶段预训练策略。
- 第一阶段,专注于视觉语言表示学习,强化视觉特征和文本之间的相关性。
- 第二阶段,专注于视觉到语言的生成学习,优化查询变换器以便其输出能被语言模型有效解释。
- 例子: 在第一阶段,系统可能学习将图像中的狗与“狗”这个词联系起来。在第二阶段,系统则学习如何基于图像生成如“一只在草地上玩耍的狗”的详细描述。
通过这种方式,BLIP-2框架有效地解决了视觉和语言之间的信息交互问题,同时显著降低了预训练所需的计算资源。
视觉语言表示学习
- 子问题: 如何让视觉和语言模型在保持冻结状态下有效交互以提高多模态理解?
- 子解法: Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder。
- 通过将Q-Former连接到冻结的图像编码器并使用图像-文本对进行预训练,训练Q-Former使查询能够提取最具文本信息的视觉表示。
- 之所以使用此解法,是因为冻结的图像编码器已经具备高质量的视觉表示能力,而Q-Former通过学习这些表示与文本的关系,可以在不增加计算成本的前提下提高模型的视觉语言理解能力。
Q-Former模型架构:
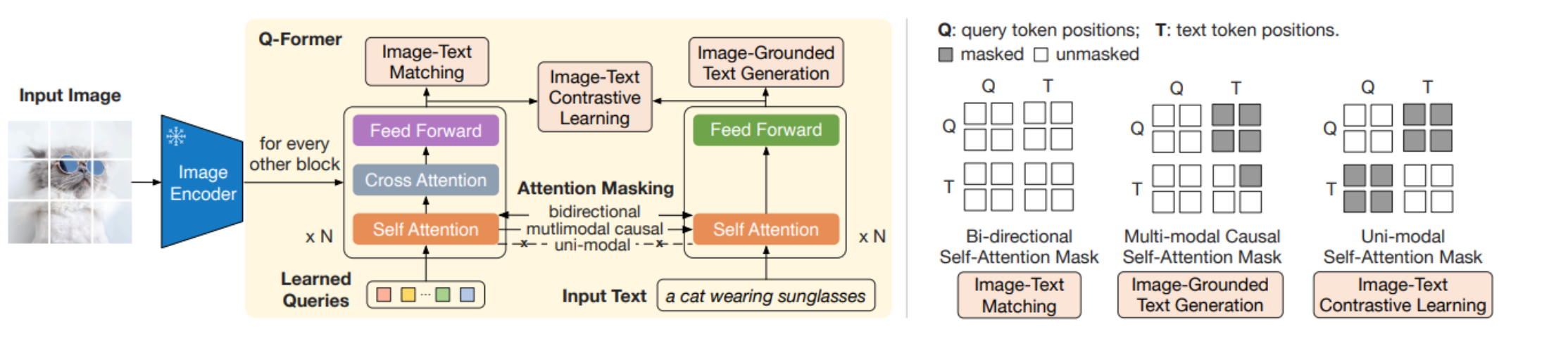
Q-Former由图像变换器和文本变换器组成,共享自注意力层。
上图展示了三个预训练目标:图像-文本对比学习、基于图像的文本生成和图像-文本匹配。
图的右侧显示了用于每个目标的不同自注意力遮罩策略,以控制查询和文本之间的交互。
视觉到语言的生成学习
- 子问题: 在不直接修改大型语言模型的情况下,如何利用其语言生成能力以响应视觉输入?
- 子解法: Bootstrap Vision-to-Language Generative Learning from a Frozen LLM。
- 在预训练的第二阶段,将Q-Former(附带冻结的图像编码器)连接到冻结的LLM,使用全连接层将输出查询表示投影到与LLM文本嵌入相同的维度,作为视觉提示输入LLM。
- 之所以使用此解法,是因为LLM的强大语言生成能力可以通过预训练的Q-Former来触发,其中Q-Former作为信息瓶颈,筛选最有用的视觉信息输入LLM,减轻LLM学习视觉语言对齐的负担,同时避免灾难性遗忘问题。
BLIP-2如何使用不同类型的冻结LLM进行视觉到语言的生成学习:
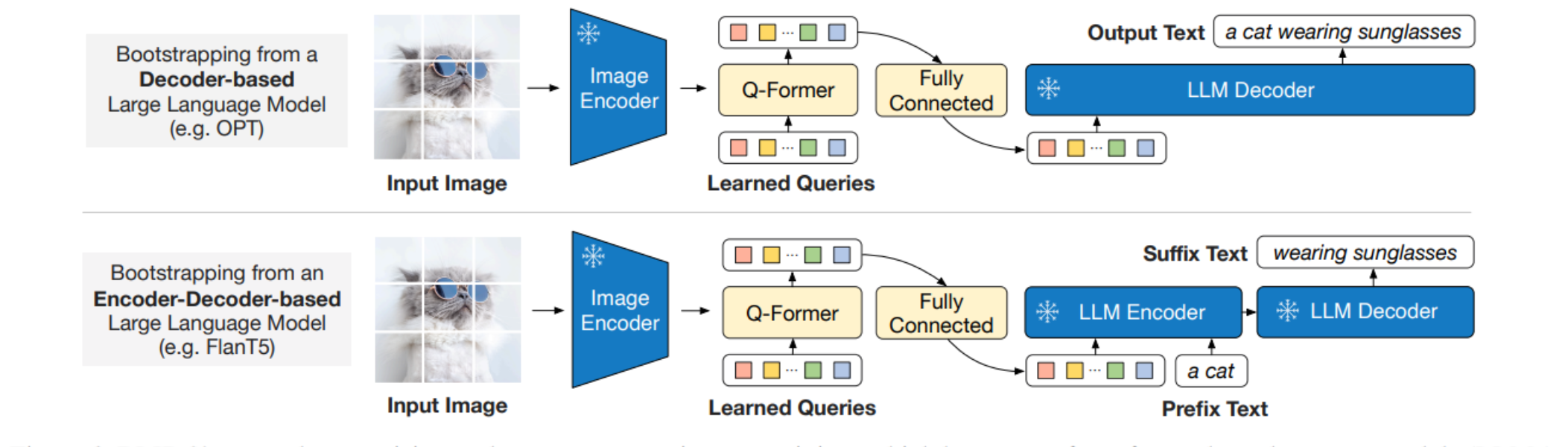
顶部展示了基于解码器的LLM(例如OPT)的启动过程,其中全连接层将Q-Former的输出维度适配到LLM解码器的输入维度。
底部展示了基于编解码器的LLM(例如FlanT5)的启动过程,其中全连接层将Q-Former的输出适配到LLM的编码器,投影后的查询作为视觉提示用于文本生成。
模型架构设计
- 子问题: 如何设计一个能够有效桥接冻结的视觉和语言模型的中间模块?
- 子解法: Q-Former Model Architecture。
- Q-Former设计为能够从冻结的图像编码器提取固定数量的输出特征并与冻结的LLM交互的可训练模块。它包括图像转换器和文本转换器两个子模块,通过自注意力层共享信息,使用可学习的查询嵌入作为输入。
- 之所以使用此解法,是因为需要一个轻量级但灵活的桥梁来提取和传递图像特征给LLM,而Q-Former正好提供了这样一个桥梁,它通过精心设计的查询机制和自注意力层,确保了有效的信息提取和传递。
假设我们有一张图片显示一只猫在窗边晒太阳,目标是生成描述这一场景的文本。
- 在视觉语言表示学习阶段,Q-Former学习从图像中提取代表“猫”、“窗户”和“晒太阳”等元素的特征。
这一阶段通过图像-文本对比学习和图像-文本匹配任务来优化,使得Q-Former能够识别和提取与文本信息最相关的视觉特征。
- 在视觉到语言的生成学习阶段,这些特征被用作触发冻结LLM生成描述文本的软提示。
例如,Q-Former的输出可能被转换成LLM能理解的形式:“一只猫坐在窗户旁边享受阳光”。
这时,冻结的LLM基于这些视觉提示开始生成文本,可能会产生如“一只悠闲的猫咪在温暖的阳光下打盹,享受着宁静的午后时光。”
这样详细且富有情感的描述。这个过程展示了Q-Former作为桥梁如何有效地将视觉信息转换成LLM可以理解和进一步加工的语言信息。
通过这个实例,我们看到了BLIP-2框架如何解决跨模态学习的挑战:
-
通过预训练的Q-Former桥接冻结的视觉和语言模型,使得无需对这些大型模型进行昂贵的再训练或微调,就能有效地结合它们的能力来解决复杂的视觉语言任务。
-
利用Q-Former的灵活架构和预训练策略,提取和传递最有意义的视觉信息给LLM,从而实现精确且自然的语言生成,这不仅提升了生成文本的质量,也展示了模型在理解和生成与视觉内容紧密相关的描述方面的能力。
这种方法的优点在于它结合了预训练模型的强大能力与新颖的训练策略,创造了一个既高效又强大的视觉语言学习框架。
BLIP-2证明了即使在资源有限的情况下,也能通过智能的模型设计和预训练策略,实现高水平的视觉语言任务性能。
总结
主要问题: 如何在计算效率和资源有限的情况下,有效地结合冻结的图像编码器和大型语言模型,来提高在视觉语言任务上的性能?
子解法1: 视觉语言表示学习
- 子问题: 如何提取并学习图像的特征表示,使之能够与文本有效结合,而不需要重新训练图像编码器?
- 子解法: 使用Q-Former进行视觉语言表示学习。Q-Former通过与冻结的图像编码器的交互来提取视觉特征,并通过自注意力和交叉注意力层来学习这些视觉特征与相关文本之间的对应关系。
- 之所以使用此解法,是因为冻结的图像编码器具有高质量的视觉表示,而Q-Former可以在不改变这些预训练模型的前提下,学习这些特征与文本之间的关联。
子解法2: 视觉到语言的生成学习
- 子问题: 在不修改大型语言模型的前提下,如何实现基于视觉输入的语言生成?
- 子解法: 从冻结的LLM进行视觉到语言的生成学习。Q-Former的输出通过全连接层适配到LLM的输入维度,使得冻结的LLM能够基于这些视觉提示来生成文本。
- 之所以使用此解法,是因为LLM具有强大的语言生成能力,但不直接处理视觉数据。Q-Former作为一个信息瓶颈,筛选并传递关键视觉信息给LLM,使得LLM能够在没有视觉训练的情况下生成与图像相关的文本。
子解法3: 模型预训练
- 子问题: 如何有效地预训练Q-Former来实现上述两个子问题的目标?
- 子解法: Q-Former的双阶段预训练。第一阶段是视觉语言表示学习,第二阶段是视觉到语言的生成学习。
- 之所以使用此解法,是因为需要一个逐步学习和优化的过程来确保Q-Former能够有效地提取视觉特征,并且这些特征能够被LLM用于生成文本。
假设我们的目标是生成一张图片的描述文本,其中图片显示一只戴着太阳镜的猫。
-
在视觉语言表示学习阶段,Q-Former学习如何从图像中提取代表“猫”和“太阳镜”等关键特征,并学习这些特征与“戴太阳镜的猫”这样的文本描述之间的关联。
-
在视觉到语言的生成学习阶段,这些视觉特征被转换成LLM能够理解的形式,并作为生成描述文本的输入。例如,Q-Former提取的特征被用来提示LLM生成文本描述“一只戴着太阳镜的猫”。
通过这个双阶段预训练过程,BLIP-2在视觉语言任务上实现了高性能,同时避免了对大规模预训练模型的昂贵重新训练。