【Langchain+Streamlit】打造一个旅游问答AI-CSDN博客
项目线上地址,无需openai秘钥可直接体验:http://101.33.225.241:8502/
github地址:GitHub - jerry1900/langchain_chatbot: langchain+streamlit打造的一个有memory的旅游聊天机器人,可以和你聊旅游相关的事儿
上节课,我们介绍了一个用streamlit和langchain打造的问答机器人,但是这个机器人有一个问题就是它只能一问一答,而且这个机器人是没有记忆的,你问他连续的问题他就傻帽了,所以,今天我们介绍一下如何打造一个类似chatGPT界面,有上下文感知、可以和你连续聊天的机器人,当然,我们也限定这个机器人只能聊旅游相关的问题。


1. 工程结构介绍
之后我们做的项目越来越大,不可能所有代码都堆到一个主文件里,所以要设计良好的工程代码结构,这个是本项目的工程结构:
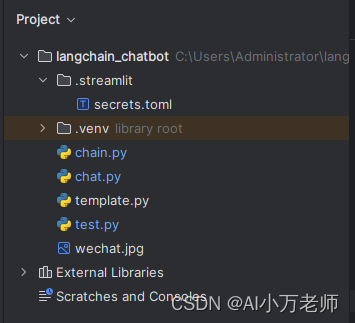 。
。
.streamlit里面的secrets.toml是存放key和其他一些常用配置参数的文件。
.venv是虚拟环境。
chain.py里有两个函数,一个build_chain,一个generate_response。
chat.py是主体程序。
template.py是存放prompt模板的地方。
其他两个文件不用管。
完整的代码,去github上去拉。
2. 引入必要的包
我们先用streamlit打造一个聊天界面,之前我们已经有了一些streamlit的基础,这里我们就讲的稍微稍微快一点:
import io
import streamlit as st
from PIL import Imagefrom langchain.memory import ConversationBufferMemoryfrom chain import generate_response,build_chainst.title('🤖AI小万的旅游聊天机器人😜')with st.sidebar:# 设置一个可点击打开的展开区域with st.expander("🤓国内可访问的openai账号"):st.write("""1. 如果使用默认地址,可以使用openai官网账号(需科学上网🥵).2. 如果你没有openai官网账号,可以联系博主免费试用国内openai节点账号🥳.""")# 本地图片无法直接加载,需先将图片读取加载为bytes流,然后才能正常在streamlit中显示image_path = r"C:\Users\Administrator\langchain_chatbot\wechat.jpg"image = Image.open(image_path)image_bytes = io.BytesIO()image.save(image_bytes, format='JPEG')st.image(image_bytes, caption='AI小万老师的微信', use_column_width=True)3. 进行聊天记录和memory的初始化,打印聊天记录
先引入必要的包,注意要引入ConversationBufferMemory,因为我们要在初始化的时候先初始化一个memory,同时我们要初始化一个messages,这些都要放到session里。
# 初始化聊天记录
if "messages" not in st.session_state:st.session_state.messages = []st.session_state.memory = ConversationBufferMemory(memory_key='chat_history')streamlit有一个特性:用户只能使用互动组件(interactive widgets)触发回调,并且每次操作互动组件时,都会触发重新运行(rerun)。rerun(重新运行)是streamlit的一个特色,指的是将应用代码从头到尾重新运行一遍。
# 展示聊天记录
for message in st.session_state.messages:if message["role"] == "user":with st.chat_message(message["role"], avatar='☺️'):st.markdown(message["content"])else:with st.chat_message(message["role"], avatar='🤖'):st.markdown(message["content"])因此,我们要把session里的messages里的消息遍历一遍打印出来,这样确保你刚才添加的最新的消息 也在页面上显示出来,我们继续。
4. 进行用户输入、回答生成和回答展示
if prompt := st.chat_input('我们来聊一点旅游相关的事儿吧'):with st.chat_message('user', avatar='☺️'):st.markdown(prompt)st.session_state.messages.append({'role': 'user', 'content': prompt})chain = build_chain(st.session_state.memory)answer = generate_response(chain, prompt)response = answer['text']with st.chat_message('assistant', avatar='🤖'):st.markdown(response)st.session_state.messages.append({'role': 'assistant', 'content': response})下面这行代码,先检查prompt是否为空,如果为空则给他一个st的输入:
if prompt := st.chat_input('聊点和旅游相关的事儿吧,么么哒'):然后设置用户的输入和头像,然后把用户的输出用markdown语法显示出来(我没有试用write可不可以,你可以自己试一下):
with st.chat_message('user', avatar='☺️'):st.markdown(prompt)st.session_state.messages.append({'role': 'user', 'content': prompt})然后这里用了两个我们自己构造的函数,一个是build_chain,这里记住要把session里的memory传入进来,这个动作帮助我们构造的模型保持上下文的记忆:
chain = build_chain(st.session_state.memory)然后我们调用generate_response方法来获得模型的回答:
answer = generate_response(chain, prompt)5. build_chain方法
这个方法的入参是一个在前文中构造好的memory,其他的方法我们在之前的课中都介绍过,大家可以自己去翻看:
def build_chain(memory):llm = OpenAI(temperature=0,# openai_api_key=os.getenv("OPENAI_API_KEY"),openai_api_key=st.secrets['api']['key'],# base_url=os.getenv("OPENAI_BASE_URL")base_url=st.secrets['api']['base_url'])prompt = PromptTemplate.from_template(BASIC_TEMPLATE)conversation = LLMChain(llm=llm,prompt=prompt,verbose=True,memory=memory,)return conversation6.generate_response方法
这个更简单,不多说了:
def generate_response(chain,input_text):response = chain.invoke(input_text)return response7. template单独设置
我看别的项目,都是把template单独建一个文件,然后引入,这样代码结构比较清晰,我也有样学样了:
from template import BASIC_TEMPLATE这里是template里BASIC_TEMPLATE的具体内容:
BASIC_TEMPLATE="""
你是一个万贺创造的旅游问答机器人,你只回答用户关于旅游和地理方面的问题。
如果用户的问题中没有出现地名或者没有出现如下词语则可以判定为与旅游无关:‘玩、旅游、好看、有趣、风景’案例:
1. 用户问题:今天天气如何? 你的回答:抱歉,我只负责回答和旅游、地理相关的问题。
2. 用户问题:你是谁?你的回答:我是万贺创造的旅游问答机器人,我只负责回答和旅游、地理相关的问题。
3. 用户问题:今天股市表现如何?你的回答:抱歉我只负责回答和旅游、地理相关的问题注意:
1. 价格也是旅游相关的问题,如果你不清楚的话直接回答不知道过去的聊天记录:
{chat_history}用户的问题:
{question}你的回答:
"""8. 完整代码
chat.py
import io
import streamlit as st
from PIL import Imagefrom langchain.memory import ConversationBufferMemoryfrom chain import generate_response,build_chainst.title('🤖AI小万的旅游聊天机器人😜')with st.sidebar:# 设置一个可点击打开的展开区域with st.expander("🤓国内可访问的openai账号"):st.write("""1. 如果使用默认地址,可以使用openai官网账号(需科学上网🥵).2. 如果你没有openai官网账号,可以联系博主免费试用国内openai节点账号🥳.""")# 本地图片无法直接加载,需先将图片读取加载为bytes流,然后才能正常在streamlit中显示image_path = r"C:\Users\Administrator\langchain_chatbot\wechat.jpg"image = Image.open(image_path)image_bytes = io.BytesIO()image.save(image_bytes, format='JPEG')st.image(image_bytes, caption='AI小万老师的微信', use_column_width=True)# 初始化聊天记录
if "messages" not in st.session_state:st.session_state.messages = []st.session_state.memory = ConversationBufferMemory(memory_key='chat_history')# 展示聊天记录
for message in st.session_state.messages:if message["role"] == "user":with st.chat_message(message["role"], avatar='☺️'):st.markdown(message["content"])else:with st.chat_message(message["role"], avatar='🤖'):st.markdown(message["content"])# 用于用户输入
if prompt := st.chat_input('我们来聊一点旅游相关的事儿吧'):with st.chat_message('user', avatar='☺️'):st.markdown(prompt)st.session_state.messages.append({'role': 'user', 'content': prompt})chain = build_chain(st.session_state.memory)answer = generate_response(chain, prompt)response = answer['text']with st.chat_message('assistant', avatar='🤖'):st.markdown(response)st.session_state.messages.append({'role': 'assistant', 'content': response})
chain.py
import osimport streamlit as stfrom langchain_openai import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChainfrom template import BASIC_TEMPLATEdef build_chain(memory):llm = OpenAI(temperature=0,# openai_api_key=os.getenv("OPENAI_API_KEY"),openai_api_key=st.secrets['api']['key'],# base_url=os.getenv("OPENAI_BASE_URL")base_url=st.secrets['api']['base_url'])prompt = PromptTemplate.from_template(BASIC_TEMPLATE)conversation = LLMChain(llm=llm,prompt=prompt,verbose=True,memory=memory,)return conversationdef generate_response(chain,input_text):response = chain.invoke(input_text)return response