CogCoM: Train Large Vision-Language Models Diving into Details through
Chain of Manipulations
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
2. 方法
2.1. 术语
2.2. 数据生成
2.3 训练
3. 实验
5. 局限性
0. 摘要
视觉-语言模型(Vision-Language Models,VLM)通过对齐视觉指令与答案进行广泛的训练,展示了它们的广泛适用性。然而,这种明确的对齐导致模型忽视了关键的视觉推理,进而在细致入微的视觉问题和不忠实的响应方面失败。在本文中,我们提出了一种名为 "Chain of Manipulations" 的机制,该机制使 VLM 能够通过一系列操纵来解决问题,其中每个操纵都是指对视觉输入进行的操作,可以是通过先前训练获得的内在能力(例如,grounding)或者是模仿类似人类行为的行为(例如,放大)。这种机制鼓励 VLM 生成具有证据支持的视觉推理的忠实响应,并允许用户在可解释的路径中跟踪错误的原因。因此,我们训练了 CogCoM,一种通用的基于内存的 17B 兼容 VLM 架构,使用了推理机制 。实验证明,我们的模型在来自 3 个类别的 8 个基准上实现了最先进的性能,并且在有限数量的训练步骤中,数据迅速获得了竞争性能。
代码:https://github.com/THUDM/CogCoM

2. 方法
2.1. 术语
我们首先介绍术语的正式定义和数据结构,以确保清晰理解。我们将操纵定义为一个灵活的集合,包括来自基础预定义集合的函数,以及模型在推理过程中自行设计的函数,以适应上下文学习。因此,我们预定义了 VLM 可以开发的一组操纵函数,这些函数可以来自先前的训练或通过模仿人类行为而得到:
M ⊆ {
Grounding(tgt)→bbx,
OCR(tgt)→txt,
Calculate(tgt)→num,
Counting(tgt)→num,
CropZoomIn(bbx,x)→img
}
其中参数或返回值 bbx,x,img,tgt,num,txt 分别表示边界框、缩放比例、图像、目标描述、数字和文本。
给定一个语言问题 Q 和一个初始输入图像 I_0,一个使用操纵链(Chain of Manipulation,CoM)的通用视觉-语言模型表示为 VLM(ζ∣I_0,Q) ⇒ A ,其中 ζ 指的是一系列证据推理步骤,

其中 f_i 指的是来自操纵定义集合 M 的实例化操纵函数,desc_i 指的是包括操纵执行在内的语言描述。这个定义明确声明了操纵函数 f_i 的符号执行,并且与现有的自由形式指令-答案数据结构兼容,其中包括语言描述 desc_i。
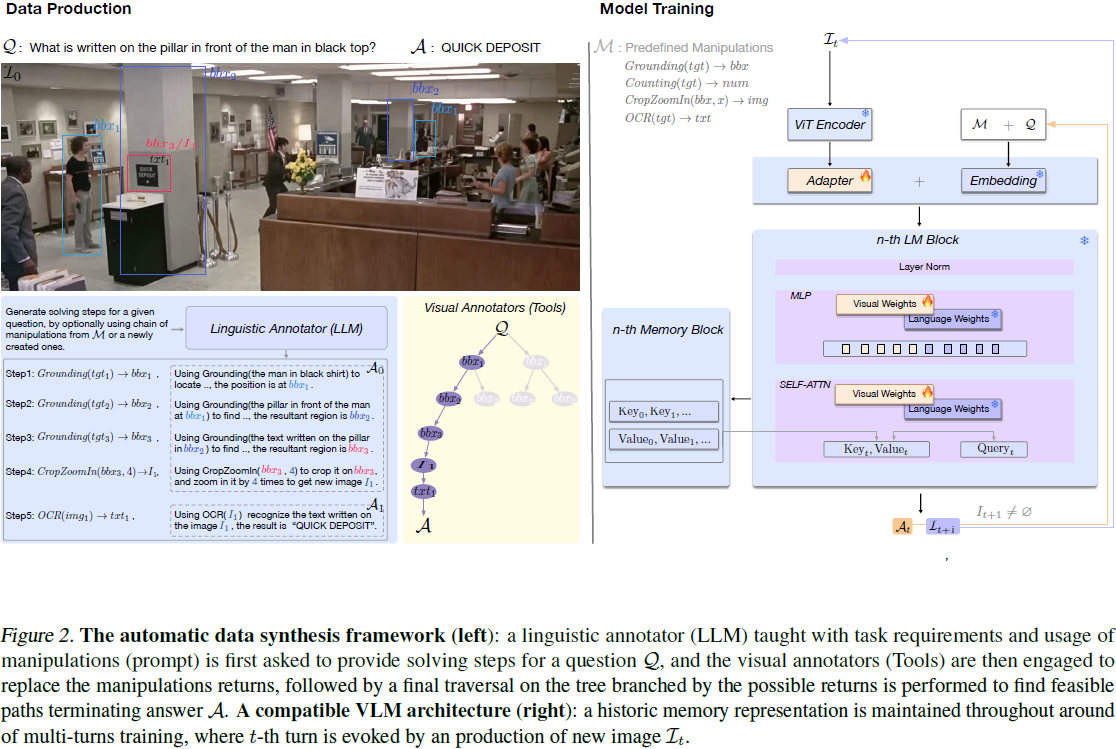
2.2. 数据生成
基于数据结构的定义,我们介绍一个数据生成框架,该框架能够在基于图像的问答对上高效地合成CoM 数据,并且还能够通过用人工劳动替代语言和视觉标注器来生成高质量的注释。
- 给定一个包含图像和相应的视觉问答对的三元样本的通用语料库 D={(I,Q,A)},我们的自动数据合成框架包括一个语言标注器和若干个根据操纵进行视觉标注的标注器。
- 对于每个样本中的问题 Q,我们首先让语言标注器生成具有 CoM 格式(f_i,desc_i)的操纵辅助求解步骤。在本文中,我们选择 GPT4 作为语言标注器。
- 然后,通过精确执行相应操作,我们使用视觉标注器来获得操作的返回值。
- 我们执行这些操作以及推理步骤,将推理步骤转化为一棵树 T,因为当前操作 f1(x1) 的输入可能依赖于先前操作 f2 → x2 的多个返回值之一,即 x1 依赖于 x2(例如,图 2 中查找柱子的第 2 步)。
2.3 训练
我们使用与 CogVLM(Wang et al., 2023b)相同的模型架构,这是一种通用的 VLM 方法,包括四个基本组件:
- 视觉编码器。
- MLP 适配器,用于将视觉编码器的输出映射到 LLM 主干的语言空间。
- LLM 主干。
- 视觉专家模块,用于可靠的多模态理解。将视觉特定的权重添加到 LLM 主干中每个块的注意层和前馈层,实现模态的深度融合。
CogCoM-17B 依赖于两个主要阶段的训练,以发展通用多模态任务解决的能力和视觉推理能力:
- 第一阶段的预训练包括两个子阶段的训练,分别用于建立基础的视觉理解和图像-问题-答案三元组的生成。
- 第二阶段的对齐进一步训练模型,使其与人类在解决实际视觉问题上的偏好相一致。
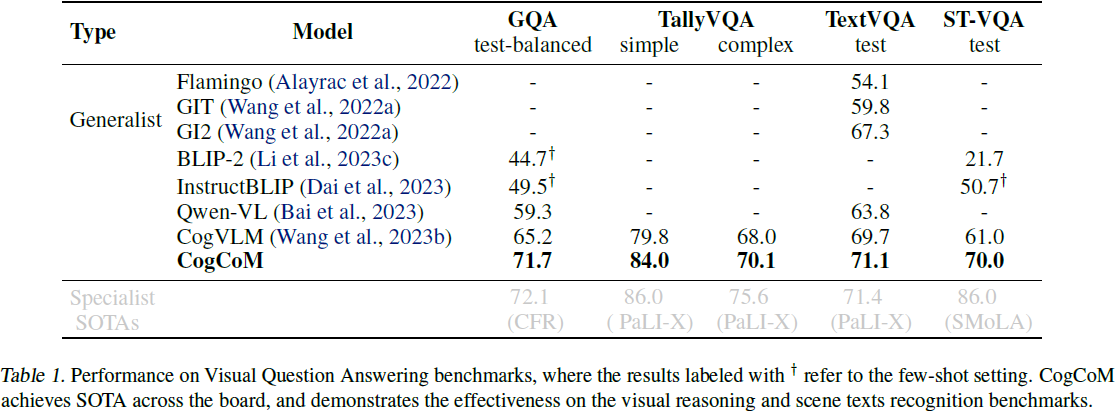
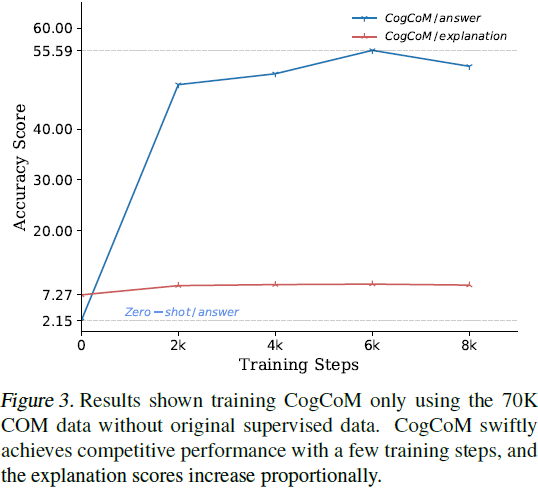
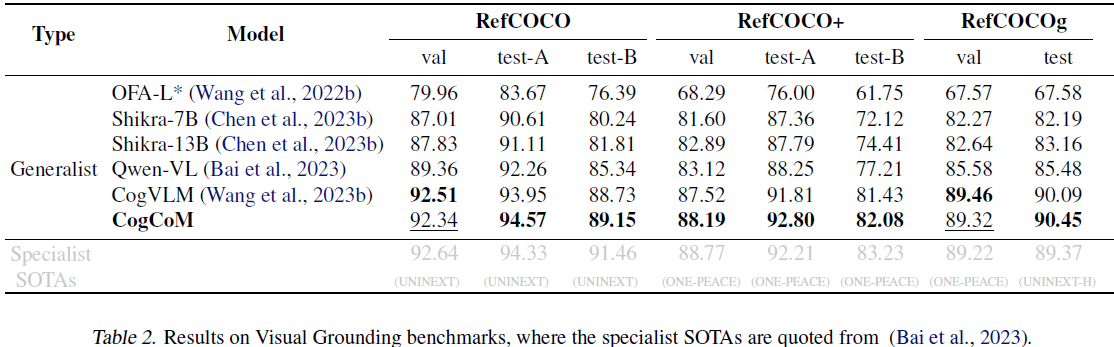
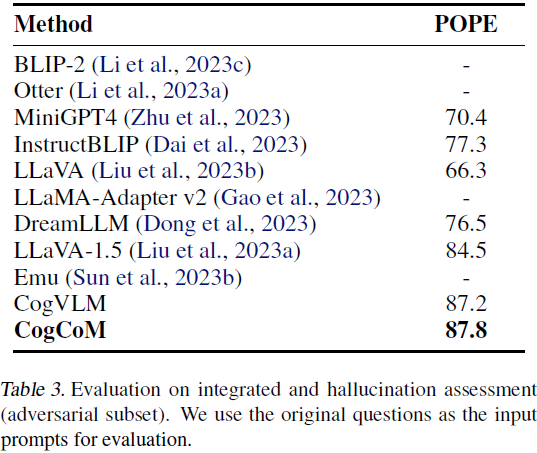
3. 实验
5. 局限性
尽管我们试图开发一个准确而强大的框架,利用显著的 LLM 提供基本解决步骤,采用可靠的视觉工具获取视觉内容,然后基于遍历获取可行路径,但我们的方法仍然存在一些限制,我们希望在未来改进。首先,我们发现语言解决步骤的多样性不足,而视觉工具的不准确性(例如,定位框的粗粒度、斜体字的 OCR 失败)会导致大量负面路径(有效利用这些路径将是有益的)。我们建议通过专用提示和改进的视觉工具来解决这些限制。其次,我们当前的模型通过一组硬提示重新输入了操纵后的图像,这可能会带来速度损失。这有望通过将物理操作纳入向量空间的计算中来改进。