简介
n-gram[1] 是文本文档中 n 个连续项目的集合,其中可能包括单词、数字、符号和标点符号。 N-gram 模型在许多与单词序列相关的文本分析应用中非常有用,例如情感分析、文本分类和文本生成。 N-gram 建模是用于将文本从非结构化格式转换为结构化格式的众多技术之一。 n-gram 的替代方法是词嵌入技术,例如 word2vec。N-grams 广泛用于文本挖掘和自然语言处理任务。
示例
通过计算每个唯一的 n 元语法在文档中出现的次数,可以创建包含 n 元语法的语言模型。这称为 bag-of-n-grams 模型。

例如[2],对于“The cow jumps over the moon”这句话。如果 N=2(称为二元模型),那么 ngram 将为:
-
the cow -
cow jumps -
jumps over -
over the -
the moon
所以在这种情况下你有 5 个 n 元语法。请注意,我们从 the->cow 转移到 cow->jumps 到 Jumps->over 等,本质上是向前移动一个单词以生成下一个二元组。
如果 N=3,则 n 元语法将为:
-
the cow jumps -
cow jumps over -
jumps over the -
over the moon
所以在这种情况下你有 4 个 n 元语法。当 N=1 时,这被称为一元语法,本质上是句子中的各个单词。当 N=2 时,称为二元组;当 N=3 时,称为三元组。当N>3时,这通常被称为多元组等等。
-
一个句子中有多少个 N-gram?
如果 X=给定句子 K 中的单词数量,则句子 K 的 n-gram 数量为:
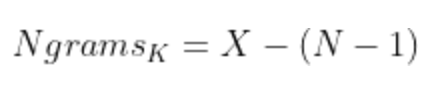
N-gram 有什么用?
N-gram 用于各种不同的任务。例如,在开发语言模型时,n-gram 不仅用于开发一元模型,还用于开发二元模型和三元模型。谷歌和微软开发了网络规模的 n-gram 模型,可用于各种任务,例如拼写纠正、断词和文本摘要。以下是 Microsoft 公开提供的网络规模 n-gram 模型:http://research.microsoft.com/en-us/collaboration/focus/cs/web-ngram.aspx。这是一篇使用 Web N-gram 模型进行文本摘要的论文:Micropinion Generation: An Unsupervised Approach to Generating Ultra-Concise Summaries of Opinions
n-gram 的另一个用途是为有监督的机器学习模型(例如 SVM、MaxEnt 模型、朴素贝叶斯等)开发特征。其想法是在特征空间中使用二元语法等标记,而不仅仅是一元语法。但请注意,根据我的个人经验和我审阅的各种研究论文,在特征空间中使用二元组和三元组不一定会产生任何显着的改进。
Code
在 python 中生成 n-gram。
import re
def generate_ngrams(text,n):
# split sentences into tokens
tokens=re.split("\\s+",text)
ngrams=[]
# collect the n-grams
for i in range(len(tokens)-n+1):
temp=[tokens[j] for j in range(i,i+n)]
ngrams.append(" ".join(temp))
return ngrams
如果您使用的是 Python,还有另一种使用 NLTK 的方法:
from nltk import ngrams
sentence = '_start_ this is ngram _generation_'
my_ngrams = ngrams(sentence.split(), 3)
N-gram: https://www.mathworks.com/discovery/ngram.html
[2]What: https://kavita-ganesan.com/what-are-n-grams/
本文由 mdnice 多平台发布