文章目录
- 实验目的
- 实现流程
- 定义DFA状态
- 实现代码
- 运行结果
- 测试1
- 测试2
- 测试3
- 总结
实验目的
实现自下而上的SLR1语法分析,画出DFA图
实现流程
定义DFA状态
class DFA:def __init__(self, id_, item_, next_ids_):self.id_ = id_ # 编号self.item_ = item_ # productionsself.next_ids_ = next_ids_ # { v1:id1 , v2:id2 ...}def __eq__(self, other):return set(self.item_) == set(other.item_)
类属性:
- id_:一个数字,表示状态的编号
- item_:一个集合,表示状态所含有的项目集
- next_ids_:一个字典,表示其可跳转的状态关系,key值表示经过什么符号跳转,value值表示跳转到的状态编号
类方法:
- 判断两个状态是否相等,依据这两个状态所包含的项目集判断,若项目集中包含的元素完全相同,则这两个状态相等。
例如:
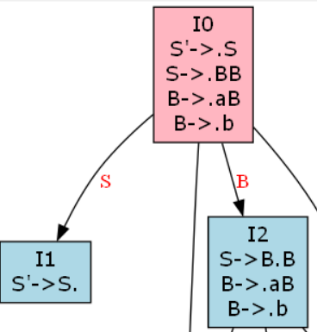
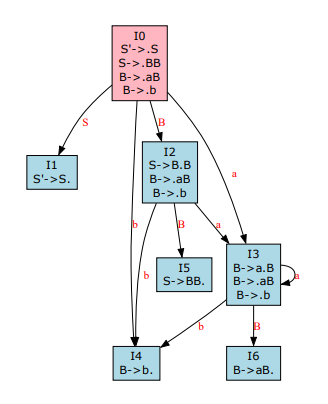
如图,状态I0可以通过S、B分别跳转到I1、I2,则其DFA状态类为:
- id_:0
- item_: { S’->.S, S->.BB, B->.aB, B->.b }
- next_ids_: { ‘S’: 1 , ‘B’:2 }
实现代码
代码逻辑
1.计算所有项目
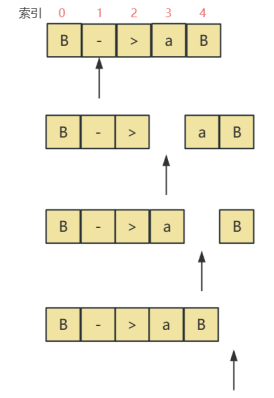
如图,首先找到字符串中 -> 的位置索引,python中字符匹配得到的是 - 的索引,记为ind,因此再ind=ind+2即可得到候选式首个字符a的位置,以这个位置为起点,遍历到末尾,加入小数点即可得到一个新的项目,如:当得到ind=1时,
item1 = str[:ind+2+0] + ’.’ + str[ind+2+0:] = “B->” + “.” + “ab” = “B->.ab”
item2 = str[:ind+2+1] + ’.’ + str[ind+2+1:] = “B->a” + “.” + “b” = “B->a.b”
item3 = str[:ind+2+2] + ’.’ + str[ind+2+2:] = “B->ab” + “.” + “” = “B->ab.”
(得益于python简单的切片索引,可以通过str[start:end]取得str中索引位置为start到end-1的子字符串。)
2.计算闭包
自定义一个closure函数
- 输入:待求闭包的项目集item
- 输出:项目集item的闭包
- 求解过程:
- 遍历项目集,对于其中的每个项目,判断“.”的位置在哪:
- 如果“.”在最后,则表明是归约项目,不再对其进行闭包。
- 如果“.”不在最后,看“.”后面的字符是否为非终结符,找到该非终结符所对应的产生式的项目,并将这些项目加入闭包中。
- 再对求过一次闭包后的新的项目集再求其闭包,方法同上,直至求出的新的项目集不再有新的项目产生。(前后两次闭包后,项目集没有加入新的项目,长度不变)
3.计算GO闭包
自定义一个go函数
- 输入:待求闭包的项目集item,跳转字符v
- 输出:项目集item的闭包
- 求解过程:
- 遍历项目集,找出“.”右边为字符v的产生式,并将“.”移动到字符v后面,得到新的产生式集item2
- 将item2代入上述closure函数中求解闭包。
4.构建DFA状态转换图
生成初始状态0:将增广文法所在产生式传入closure函数求解闭包,记为S0_item,根据DFA类定义初始状态:S0 = DFA(0, S0_item, {}),即状态编号为0,项目集为S0_item,跳转关系为空字典。然后将初始状态加入到存储所有状态的列表:all_DFA。即 all_DFA = [S0]
遍历all_DFA中的所有状态,求解每个状态中项目集的Go闭包,记录新的状态。遍历完一轮all_DFA后,继续遍历all_DFA,直到前后两次all_DFA长度不变(没有新的状态产生)
5.判断是否为SLR1文法:
- 先判断是否符合LR0文法
遍历all_DFA中的所有状态S,遍历状态S的项目集的所有产生式,若“.”在末尾,则为归约项目,若“.”后为终结符,则为移进项目,统计归约项目和移进项目个数,若存在2个及以上的归约项目或存在1个移进项目和1个归约项目,则相应存在“归约-归约冲突”和“移进-归约冲突”,不符合LR0文法。- 判断是否符合SLR1文法
如图,依据归约项目和移进项目的follow集进行判断

6.构造SLR1表:
定义actions={} 、 gotos={},分别表示action表和gotos表,key值为一个二元组,如(1,’#’),表示状态1和字符’#’所对应的单元格。
遍历all_DFA中的所有状态S:
- 如果S的next_ids_为空字典,即它没有箭头指向其他状态,则S的项目集中必只包含一个项目,为归约项目或接受项目。
- 若该项目去除“.”后与增广文法所在产生式相等,该项目为接受项目,记录actions[ (id_,’#’) ]=“acc”,id_为当前状态S的编号。
- 否则,则为归约项目。将该产生式依据“->”拆成左部和右部,遍历左部的follow集,记录actions[ (id_,ch) ] = rn,ch为左部follow集的元素,rn为产生式编号。- 如果S的next_ids字典不为空,即表明有指向下一个项目的箭头,从而当前状态S可能存在接受、归约、移进等项目。
- 遍历S的项目集:判断是否为接受项目和归约项目同上
- 遍历S的next_ids字典:若key值为终结符,记录actions[ (id_, key) ] = S+value,value为下一个状态的编号;若key值为非终结符,记录gotos[ (id_, key) ] = value。
7.根据输入串查表分析
建立变量,状态栈state、符号栈symbol、字符指针sp。
- 给state加入0,symbol加入#,sp=0
- 取出state栈顶状态St和symbol栈顶符号Sy,如果actions的key中不存在(St,Sy)二元组,则分析失败,否则进行下一步。
- 用(St,Sy)查actions得到动作a
- 如果a是Sn,为移进操作,将状态Sn加入到状态栈state,将sp指向的字符加入到符号栈中symbol,并且sp+=1
- 如果a是rn, 为归约操作,找到产生式rn,将符号栈symbol中对应产生式右部的字符弹出,也将状态栈state对应产生式右部字符个数的状态弹出。取此时state和symbol栈顶元素St、Sy,查gotos表,如果gotos的key中不存在(St,Sy)二元组,则分析失败,否则将查到的对应的状态加入状态栈state中。
- 如果a是“acc”,分析成功,退出循环
- 循环条件为sp!=分析串长度
需要用到graphviz库,用于画DFA转换图,自行百度搜索下载,不难
(下载graphviz.exe软件–>改环境变量–>python安装graphviz库)
import copy
from collections import defaultdict
import graphviz
import pandas as pdclass DFA:def __init__(self, id_, item_, next_ids_):self.id_ = id_ # 编号self.item_ = item_ # productionsself.next_ids_ = next_ids_ # { v1:id1 , v2:id2 ...}def __eq__(self, other):return set(self.item_) == set(other.item_)class FirstAndFollow:def __init__(self, formulas_str_list):self.formulas_str_list = formulas_str_listself.formulas_dict = defaultdict(set)self.first = defaultdict(set)self.follow = defaultdict(set)self.S = ""self.Vn = set()self.Vt = set()self.info = {}def process(self, formulas_str_list):formulas_dict = defaultdict(set) # 存储产生式 ---dict<set> 形式# 转为特定类型for production in formulas_str_list:left, right = production.split('->')if "|" in right:r_list = right.split("|")for r in r_list:formulas_dict[left].add(r)else:formulas_dict[left].add(right) # 若left不存在,会自动创建 left: 空setS = list(formulas_dict.keys())[0] # 文法开始符Vn = set()Vt = set()for left, right in formulas_dict.items(): # 获取终结符和非终结符Vn.add(left)for r_candidate in right:for symbol in r_candidate:if not symbol.isupper() and symbol != '@':Vt.add(symbol)# 消除左递归# formulas_dict = self.eliminate_left_recursion(formulas_dict)return formulas_dict, S, Vn, Vtdef cal_v_first(self, v): # 计算符号v的first集# 如果是终结符或ε,直接加入到First集合if not v.isupper():self.first[v].add(v)else:for r_candidate in self.formulas_dict[v]:i = 0while i < len(r_candidate):next_symbol = r_candidate[i]# 如果是非终结符,递归计算其First集合if next_symbol.isupper():if next_symbol == v:breakself.cal_v_first(next_symbol)self.first[v] = self.first[v].union(self.first[next_symbol] - {'@'}) # 合并first(next_symbol)/{@}if '@' not in self.first[next_symbol]:break# 如果是终结符,加入到First集合else:self.first[v].add(next_symbol)breaki += 1# 如果所有符号的First集合都包含ε,将ε加入到First集合if i == len(r_candidate):self.first[v].add('@')def cal_all_first(self):for vn in self.formulas_dict.keys():self.cal_v_first(vn)for vt in self.Vt:self.cal_v_first(vt)self.cal_v_first('@')# def: 计算Follow集合1——考虑 添加first(Vn后一个非终结符)/{ε}, 而 不考虑 添加follow(left)def cal_follow1(self, vn):self.follow[vn] = set()if vn == self.S: # 若为开始符,加入#self.follow[vn].add('#')for left, right in self.formulas_dict.items(): # 遍历所有文法,取出左部单Vn、右部候选式集合for r_candidate in right: # 遍历当前 右部候选式集合i = 0while i <= len(r_candidate) - 1: # 遍历当前 右部候选式if r_candidate[i] == vn: # ch == Vnif i + 1 == len(r_candidate): # 如果是最后一个字符 >>>>> S->....Vself.follow[vn].add('#')breakelse: # 后面还有字符 >>>>> S->...V..while i != len(r_candidate):i += 1# if r_candidate[i] == vn: # 又遇到Vn,回退 >>>>> S->...V..V..# breakif r_candidate[i].isupper(): # 非终结符 >>>>> S->...VA..self.follow[vn] = self.follow[vn].union(self.first[r_candidate[i]] - {'@'})if '@' in self.first[r_candidate[i]]: # 能推空 >>>>> S->...VA.. A可推空if i + 1 == len(r_candidate): # 是最后一个字符 >>>>> S->...VA A可推空 可等价为 S->...Vself.follow[vn].add('#')breakelse: # 不能推空 >>>>> S->...VA.. A不可推空breakelse: # 终结符 >>>>> S->...Va..self.follow[vn].add(r_candidate[i])breakelse:i += 1# def: 计算Follow集合2——考虑 添加follow(left)def cal_follow2(self, vn):for left, right in self.formulas_dict.items(): # 遍历所有文法,取出左部单Vn、右部候选式集合for r_candidate in right: # 遍历当前 右部候选式集合i = 0while i <= len(r_candidate) - 1: # 遍历当前 右部候选式if r_candidate[i] == vn: # 找到Vnif i == len(r_candidate) - 1: # 如果当前是最后一个字符,添加 follow(left) >>>>> S->..Vself.follow[vn] = self.follow[vn].union(self.follow[left])breakelse: # 看看后面的字符能否推空 >>>>> S->..V..while i != len(r_candidate):i += 1if '@' in self.first[r_candidate[i]]: # 能推空 >>>>> S->..VB.. B可推空if i == len(r_candidate) - 1: # 且是最后一个字符 >>>>> S->..VB B可推空self.follow[vn] = self.follow[vn].union(self.follow[left])breakelse: # 不是最后一个字符,继续看 >>>>> S->..VBA.. B可推空continueelse: # 不能推空 >>>>> S->..VB.. B不可为空breaki += 1# def: 计算所有Follow集合的总长度,用于判断是否还需要继续完善def cal_follow_total_Len(self):total_Len = 0for vn, vn_follow in self.follow.items():total_Len += len(vn_follow)return total_Lendef cal_all_follow(self):# 先用 cal_follow1 算for vn in self.formulas_dict.keys():self.cal_follow1(vn)# 在循环用 cal_follow2 算, 直到所有follow集总长度不再变化,说明计算完毕while True:old_len = self.cal_follow_total_Len()for vn in self.formulas_dict.keys():self.cal_follow2(vn)new_len = self.cal_follow_total_Len()if old_len == new_len:breakdef solve(self):# print("\n=============FirstFollow=============")self.formulas_dict, self.S, self.Vn, self.Vt = self.process(self.formulas_str_list)self.cal_all_first()self.cal_all_follow()# print(f"first: {self.first}")# print(f"follow: {self.follow}")# print("=============FirstFollow=============\n")return self.first, self.followclass SLR1:def __init__(self, formulas_str_list):self.formulas_str_list = formulas_str_list # listself.S = ""self.Vn = []self.Vt = []self.dot_items = [] # 所有可能的.项目集self.all_DFA = []self.actions = []self.gotos = []self.first = defaultdict(set)self.follow = defaultdict(set)def step1_pre_process(self, grammar_list):formulas_str_list = []S = grammar_list[0][0] # 开始符Vt = [] # 终结符Vn = [] # 非终结符for pro in grammar_list:pro_left, pro_right = pro.split("->")if "|" in pro_right:r_list = pro_right.split("|")for r in r_list:formulas_str_list.append(pro_left + "->" + r)else:formulas_str_list.append(pro)# 增广文法formulas_str_list.insert(0, S + "'->" + S)# print(formulas_str_list)for pro in formulas_str_list:pro_left, pro_right = pro.split("->")if pro_left not in Vn:Vn.append(pro_left)for r_candidate in pro_right:for symbol in r_candidate:if not symbol.isupper() and symbol != '@':if symbol not in Vt:Vt.append(symbol)print("S:",S)print("Vn:", Vn)print("Vt:", Vt)ff = FirstAndFollow(formulas_str_list)first, follow = ff.solve()return S, Vn, Vt, formulas_str_list, first, followdef step2_all_dot_pros(self, grammar_str):dot_items = []for pro in grammar_str:ind = pro.find("->") # 返回-的下标for i in range(len(pro) - ind - 1):tmp = pro[:ind + 2 + i] + "." + pro[ind + 2 + i:]dot_items.append(tmp)return dot_itemsdef closure(self, item): # 求item所有的产生式的闭包c_item = itemold_c_item = []while len(old_c_item) != len(c_item):old_c_item = copy.deepcopy(c_item)for pro in old_c_item:if pro not in c_item:c_item.append(pro)dot_left, dot_right = pro.split(".")if dot_right == "": # 当前产生式为最后一项为. .不能继续移动,跳过continueif dot_right[0] in self.Vn: # .后面为非终结符, 加入它的Vn->.xxxxfor dot_p in self.dot_items:ind = dot_p.find("->") # 返回-的下标if dot_p[0] == dot_right[0] \and dot_p[ind + 2] == "." \and dot_p[1] != "'" \and dot_p not in c_item: # 首字符匹配 且不为增广符c_item.append(dot_p)return c_itemdef go(self, item, v): # 生成item向v移动后的item_productionto_v_item = []for pro in item: # 生成item能够用v跳转的新的产生式dot_left, dot_right = pro.split(".")if dot_right != "":if dot_right[0] == v: # .右边是跳转符vto_v_item.append(dot_left + dot_right[0] + "." + dot_right[1:])new_item = Noneif len(to_v_item) != 0: # 求新产生式的闭包new_item = self.closure(to_v_item)return new_itemdef exist_idx(self, all_DFA, new_dfa):if new_dfa.item_ is None:return -1for i in range(len(all_DFA)):if new_dfa == all_DFA[i]:return ireturn -1def step3_construct_LR0_DFA(self, dot_items):# 生成初始Item0all_DFA = []item0_pros = []item0_pros.extend(self.closure([dot_items[0]]))all_DFA.append(DFA(0, item0_pros, {}))visited_dfa = [] # close表old_visted_dfa = [] # 用于判断close表长度是否再变化V = list(self.Vn) + list(self.Vt) # 合并非终结符和终结符while True:old_visted_dfa = copy.deepcopy(visited_dfa) # 副本for dfa in all_DFA:if dfa in visited_dfa: # 已经访问过,则continuecontinuevisited_dfa.append(dfa) # 加入close表item = dfa.item_for v in V:new_item = self.go(item, v)if new_item is not None:new_dfa = DFA(-1, new_item, {})idx = self.exist_idx(all_DFA, new_dfa)if idx == -1: # 不存在new_dfa.id_ = len(all_DFA)dfa.next_ids_[v] = new_dfa.id_all_DFA.append(new_dfa)else: # 存在dfa.next_ids_[v] = idxif len(old_visted_dfa) == len(visited_dfa): # close表长度不变,退出循环breakreturn all_DFAdef print_DFA(self, all_DFA):for dfa in all_DFA:print("====")print(f"id={dfa.id_}")print(f"item={dfa.item_}")print(f"next={dfa.next_ids_} \n")def step4_draw_DFA(self, all_DFA):# 创建Digraph对象dot = graphviz.Digraph()for dfa in all_DFA:label = f"I{dfa.id_}\n"node_color = "lightblue"if dfa.id_ == 0:node_color = "lightpink"for pro in dfa.item_:label += pro + "\n"dot.node(str(dfa.id_), label=label,style='filled', fillcolor=node_color,shape='rectangle', fontname='Verdana')if len(dfa.next_ids_) != 0:for v, to_id in dfa.next_ids_.items():dot.edge(str(dfa.id_), str(to_id), label=v, fontcolor='red')# 显示图形dot.view()return dotdef step5_check_LR0(self, all_DFA): # 判断是否为LR0文法flag = Truefor dfa in all_DFA:item = dfa.item_shift_num = 0 # 移进数目protocol_num = 0 # 归约数目shift_vt = set()protocol_vn = set()shift_pro = set()protocol_pro = set()for pro in item:dot_left, dot_right = pro.split(".")if dot_right == "": # .在最后,为归约项目# if dot_left[:2] == self.S + "'": # 接受项目,不考虑为归约项目# continueprotocol_num += 1pro_left, pro_right = pro.split("->")protocol_vn.add(pro_left)protocol_pro.add(pro)elif dot_right[0] in self.Vt: # .后面为终结符,为移进项目shift_num += 1shift_vt.add(dot_right[0])shift_pro.add(pro)if protocol_num == 1 and shift_num >= 1:shift_conf_msg = ""for s_pro in shift_pro:shift_conf_msg += s_pro + " "print(f"I{dfa.id_}中:{shift_conf_msg} 与 {next(iter(protocol_pro))}存在移进-归约冲突")for vt in shift_vt:for vn in protocol_vn:if self.first[vt].intersection(self.follow[vn]): # 有交集flag = Falseprint(f"它们的first与follow交集不为空,不满足SLR")return flagflag = Trueprint(f"但它们的first与follow交集为空,可忽略")elif protocol_num >= 2:pro_conf_msg = ""for p_pro in protocol_pro:pro_conf_msg += p_pro + " "print(f"I{dfa.id_}中: {pro_conf_msg} 存在归约-归约冲突,不满足SLR")flag = Falsereturn flagdef step6_construct_LR0_table(self, all_DFA, formulas_str_list):actions = {}gotos = {}for dfa in all_DFA:id_ = dfa.id_next_ids = dfa.next_ids_if len(next_ids) == 0: # 无下一个状态,必定为归约项目或接受项目,且只有一个pro = dfa.item_[0].replace(".", "") # 去除.if pro == formulas_str_list[0]: # 如果这一个为接受项目:S'->Sactions[(id_, "#")] = "acc"else: # 其他的指定产生式# ===========SLR1===========# for vt in self.Vt:# actions[(id_, vt)] = "r" + str(formulas_str_list.index(pro))# actions[(id_, "#")] = "r" + str(formulas_str_list.index(pro))# ===========SLR===========pro_left, pro_right = pro.split("->")for ch in self.follow[pro_left]:actions[(id_, ch)] = "r" + str(formulas_str_list.index(pro))actions[(id_, "#")] = "r" + str(formulas_str_list.index(pro))else: # 有指向下一个项目,同时当前项目可能存在接受项目、归约项目(点在末尾)、移进项目for item in dfa.item_:pro_left, pro_right = item.split(".")if pro_right == "": # .在最后 为归约项目pro = item.replace(".", "")if pro == formulas_str_list[0]: # 为接受项目actions[(id_, "#")] = "acc"else: # 其他的归约项目left, right = pro.split("->")for ch in self.follow[left]:actions[(id_, ch)] = "r" + str(formulas_str_list.index(pro))actions[(id_, "#")] = "r" + str(formulas_str_list.index(pro))for v, to_dfa_id in next_ids.items():if v in self.Vt:actions[(id_, v)] = "S" + str(to_dfa_id)elif v in self.Vn:gotos[(id_, v)] = to_dfa_id# 转成df对象merged_dict = {key: value for d in (actions, gotos) for key, value in d.items()}sorted_keys = sorted(merged_dict.keys(), key=lambda x:(x[1].isupper(), x[1] == "#", x[1]))sort_dict = {key: merged_dict[key] for key in sorted_keys}columns = []for k in sort_dict.keys():if k[1] not in columns:columns.append(k[1])rows = set(key[0] for key in sort_dict.keys())df = pd.DataFrame(index=rows, columns=columns)for key, value in sort_dict.items():df.loc[key[0], key[1]] = valueprint(df)return actions, gotosdef step7_LR0_analyse(self, actions, gotos, formulas_str_list, input_str):s = list(input_str)s.append("#")sp = 0 # 字符串指针state_stack = []symbol_stack = []state_stack.append(0)symbol_stack.append("#")step = 0msg = ""info_step, info_state_stack, info_symbol_stack, info_str, info_msg, info_res = [], [], [], [], [], ""# 分析while sp != len(s):step += 1ch = s[sp]top_state = state_stack[-1]top_symbol = symbol_stack[-1]info_step.append(step)info_state_stack.append("".join([str(x) for x in state_stack]))info_symbol_stack.append("".join(symbol_stack))info_str.append("".join(s[sp:]))if (top_state, ch) not in actions.keys():info_res = f"error:分析失败,找不到Action({(top_state, ch)})"info_msg.append("error")breakfind_action = actions[(top_state, ch)]if find_action[0] == "S": # 移进操作state_stack.append(int(find_action[1:]))symbol_stack.append(ch)sp += 1msg = f"Action[{top_state},{ch}]={find_action}: 状态{find_action[1:]}入栈"elif find_action[0] == 'r': # 归约操作pro = formulas_str_list[int(find_action[1:])] # 获取第r行的产生式pro_left, pro_right = pro.split("->")pro_right_num = len(pro_right)for i in range(pro_right_num):state_stack.pop()symbol_stack.pop()symbol_stack.append(pro_left)goto_key = (state_stack[-1], symbol_stack[-1])if goto_key in gotos.keys():state_stack.append(gotos[goto_key])msg = f"{find_action}: 用{pro}归约,Goto[{top_state},{symbol_stack[-1]}]={gotos[goto_key]}入栈"else:info_res = f"error:分析失败,找不到GOTO({state_stack[-1]},{symbol_stack[-1]})"elif find_action == "acc":msg = "acc: 分析成功!"info_msg.append(msg)info_res = "Success!"breakinfo_msg.append(msg)# printprint("{:<10} {:<10} {:<10} {:<10} {:<20}".format("步骤","状态栈","输入串","符号栈","分析"))for i in range(len(info_step)):print("{:<10} {:<10} {:<10} {:<10} {:<20}".format(info_step[i],info_state_stack[i],info_symbol_stack[i],info_str[i],info_msg[i]))info = {"info_step": info_step,"info_state_stack": info_state_stack,"info_symbol_stack": info_symbol_stack,"info_str": info_str,"info_msg": info_msg,"info_res": info_res}return infodef init(self):print("===========基本信息==========")self.S, self.Vn, self.Vt, self.formulas_str_list, self.first, self.follow = self.step1_pre_process(self.formulas_str_list)self.dot_items = self.step2_all_dot_pros(self.formulas_str_list) # 计算所有项目(带点)self.all_DFA = self.step3_construct_LR0_DFA(self.dot_items) # 计算项目集的DFA转换关系# self.print_DFA(self.all_DFA)self.step4_draw_DFA(self.all_DFA) # 画项目集的DFA转换图print("===========移进-归约重冲突=========")self.step5_check_LR0(self.all_DFA) # 检测是否符合LR0文法print("===========SLR1表=========")self.actions, self.gotos = self.step6_construct_LR0_table(self.all_DFA, self.formulas_str_list) # 画表def solve(self, input_str):print("===========分析过程=========")self.info = self.step7_LR0_analyse(self.actions, self.gotos, self.formulas_str_list, input_str)if __name__ == "__main__":grammar1 = [ # + ()"E->E+T","E->T","T->(E)","T->i"]grammar2 = [ # 课本例子"S->BB","B->aB","B->b"]grammar3 = [ # + * ()"E->E+T","E->T","T->T*F","T->F","F->(E)","F->i"]lr0 = SLR1(grammar1)lr0.init()lr0.solve("i+i")运行结果
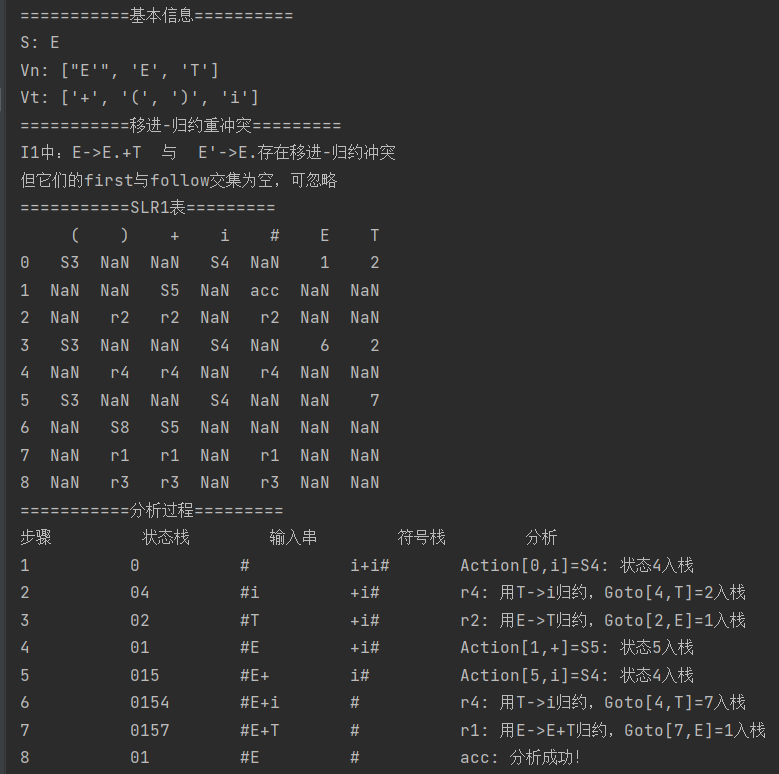
测试1
输入:
文法:
分析串:

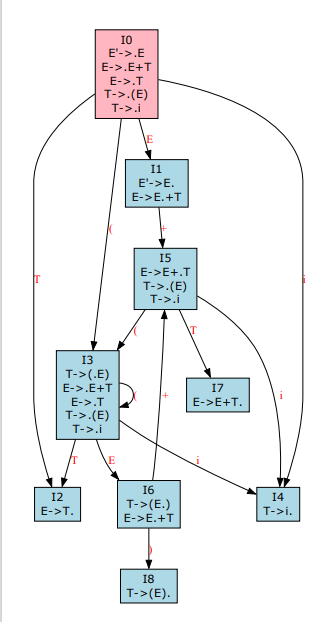
输出:
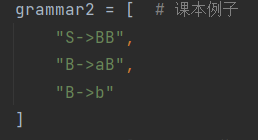
测试2
输入:
文法:
分析串:

输出:
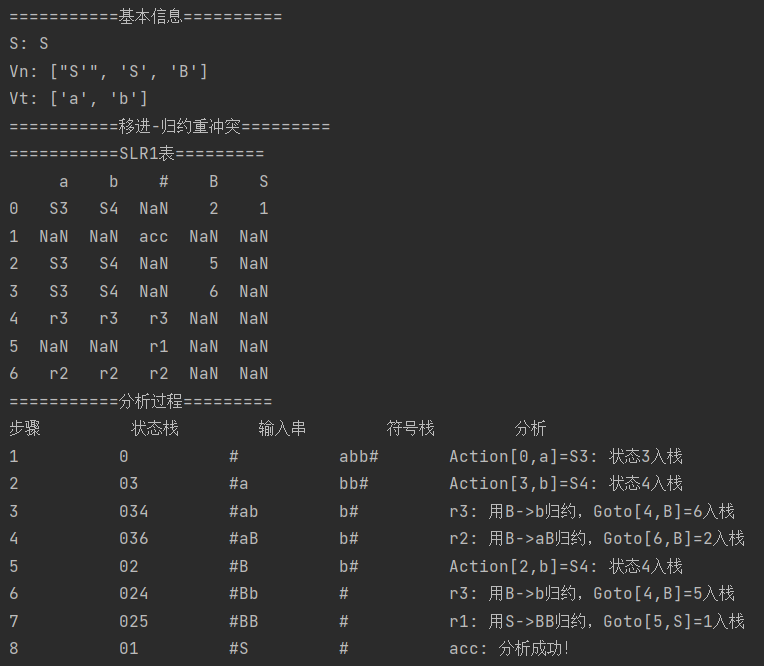
测试3
输入:
文法:
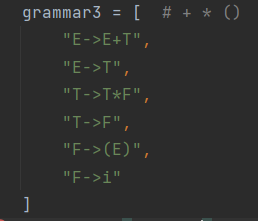
分析串:

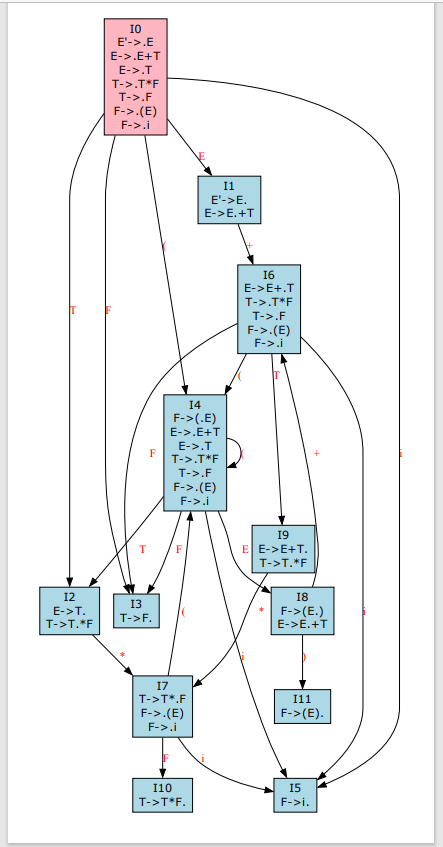
输出:
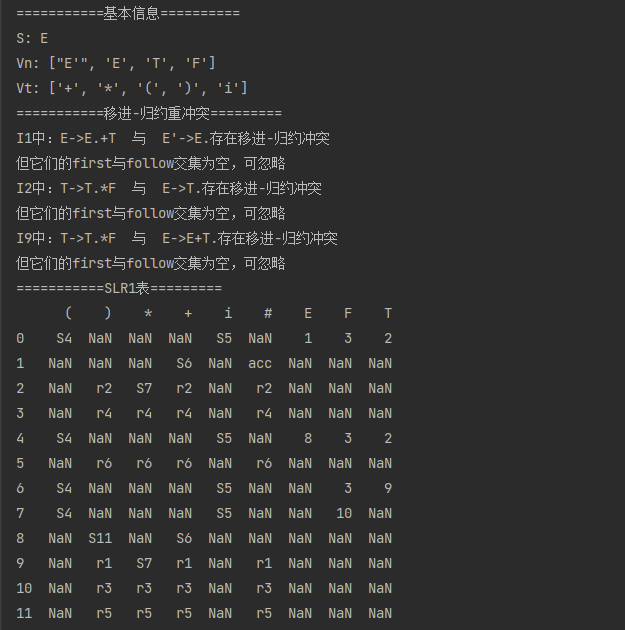
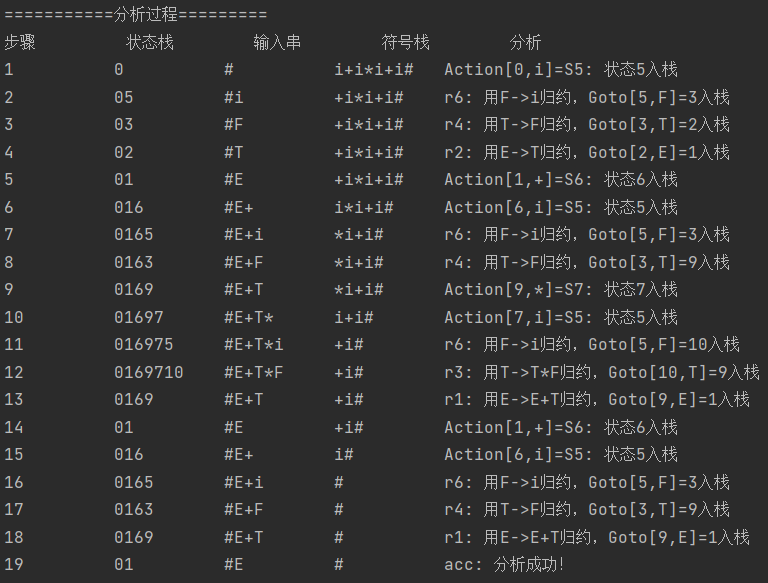
总结
对于SLR1分析法,检查是否符合SLR1文法时,需要在LR1文法的基础上,增加了各个项目对于follow集是否有交集的判断,因此需要另外实现first集和follow集的求解,另外。而且,SLR文法主要解决了LR0文法中出现的“移进-归约”冲突,但对于“归约-归约”冲突仍然不能解决。





![最大子数组和[中等]](https://img-blog.csdnimg.cn/direct/054d660177f04abab28f0fc0af6ae8bc.png)


