深入理解Spark BlockManager:定义、原理与实践
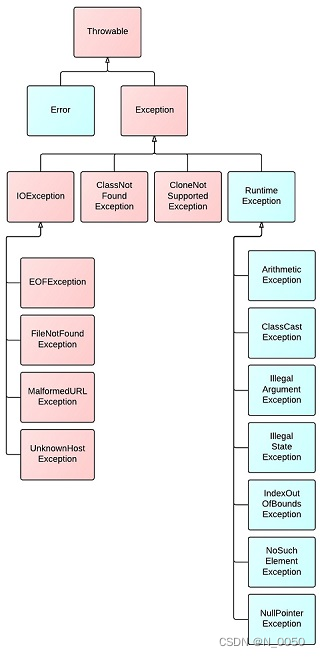
1.定义
Spark是一个开源的大数据处理框架,其主要特点是高性能、易用性以及可扩展性。在Spark中,BlockManager是其核心组件之一,它负责管理内存和磁盘上的数据块,并确保这些数据块在集群中的各个节点上可以高效地共享和访问,其中包括存储、复制、序列化和反序列化数据块,并且负责将这些数据块分发到集群中的各个节点上,以便进行计算。BlockManager还处理数据块的缓存和回收,以及故障恢复和数据迁移等任务。
因为Spark是分布式的计算引擎,因此BlockManager也是一个分布式组件,各个节点(Executor)上都有一个BlockManger实例,管理着当前Executor的数据及元数据进行处理及维护,比如我们常说的block块的增删改的操作,都会在BlockManager上做相应的元素局的变更。而Executor上的BlockManager实例是由Driver端上的BlockManagerMaster统一管理,其关系类似于我们常说的NameNode和DataNode之间的关系。我们知道Spark本身有很多的模块,比如Scheduler调度模块,Standalone资源管理模块等,而BlockManager就是其中非常重要的模块,其源码量也是非常的巨大。总而言之,spark BlockManager是负责Spark上所有的数据的存储与管理的一个极其重要的组件。
2.原理分析
2.1 数据块的管理
在Spark中,每个数据块都有唯一的标识符,称为BlockId。BlockManager通过维护数据块的元数据来管理这些数据块,包括数据块的类型、大小、版本号、所在节点等信息。当一个节点需要访问一个数据块时,它会向BlockManager发送请求,BlockManager根据数据块的标识符和元数据来定位数据块所在的节点,并返回数据块的引用。
sealed abstract class BlockId {// 全局唯一的block的名字def name: String// convenience methodsdef asRDDId: Option[RDDBlockId] = if (isRDD) Some(asInstanceOf[RDDBlockId]) else None// 一下判断不同类型的Block,可能是RDD、Shuffle、Broadcast之一def isRDD: Boolean = isInstanceOf[RDDBlockId]def isShuffle: Boolean = {(isInstanceOf[ShuffleBlockId] || isInstanceOf[ShuffleBlockBatchId] ||isInstanceOf[ShuffleDataBlockId] || isInstanceOf[ShuffleIndexBlockId])}def isShuffleChunk: Boolean = isInstanceOf[ShuffleBlockChunkId]def isBroadcast: Boolean = isInstanceOf[BroadcastBlockId]override def toString: String = name
}2.2 数据块的存储
我们知道,Spark中的数据块可以存在于内存或磁盘中,对于小数据块,BlockManager会优先将其存储在内存中,以提高访问速度;对于大数据块,则会将其存储在磁盘上。BlockManager还支持将数据块存储在外部存储系统中,如HDFS、S3等。
class StorageLevel private(// 磁盘
private var _useDisk: Boolean,
// 内存
private var _useMemory: Boolean,
// 堆外内存
private var _useOffHeap: Boolean,
// 是否序列化
private var _deserialized: Boolean,
// block默认副本
private var _replication: Int = 1)
extends Externalizable2.3 数据块的复制
为了保证数据块的可靠性和高可用性,BlockManager会自动将一些数据块复制到其他节点上,以免数据丢失或节点故障导致数据无法访问。复制策略可以根据具体需求进行配置,例如可以设置副本数、复制间隔、复制位置等。
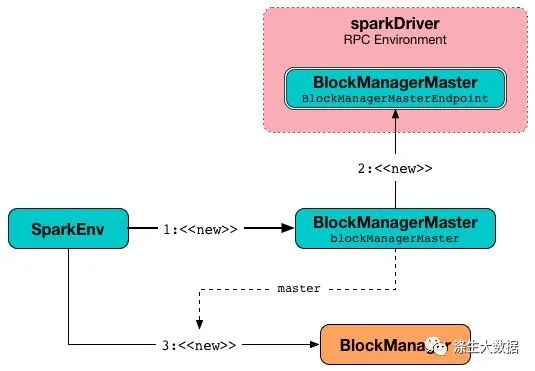
2.4 数据块的序列化和反序列化
在Spark中,数据块经常需要在不同的节点之间传输和共享,因此需要进行序列化和反序列化。BlockManager提供了常用的序列化和反序列化方式,包括Java序列化、Kryo序列化等。
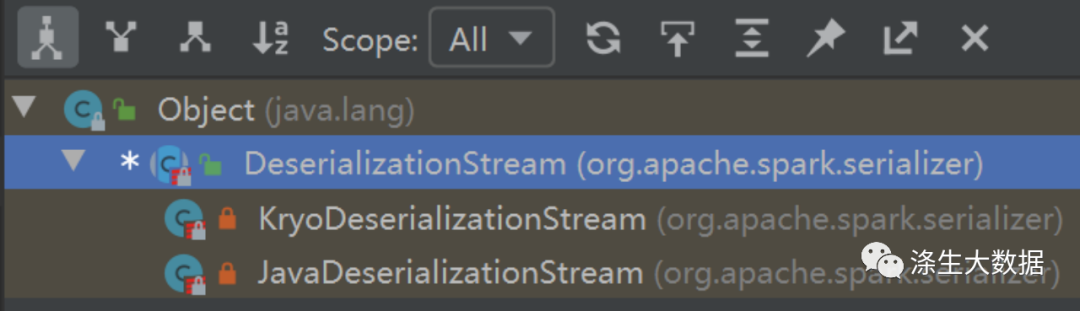
2.5 数据块的缓存和回收
为了提高计算效率,BlockManager还支持将一些常用的数据块缓存在内存中,以避免频繁地从磁盘或外部存储系统中读取数据块。同时,BlockManager还会定期清除一些不再使用的数据块,以释放资源。
2.6 故障恢复和数据迁移
当一个节点出现故障或者网络出现问题时,BlockManager会自动进行故障恢复,将丢失的数据块重新复制到其他节点上。此外,在集群扩容或缩容时,BlockManager还支持数据迁移,以保证数据块的平衡分布。
2.7 运行原理图
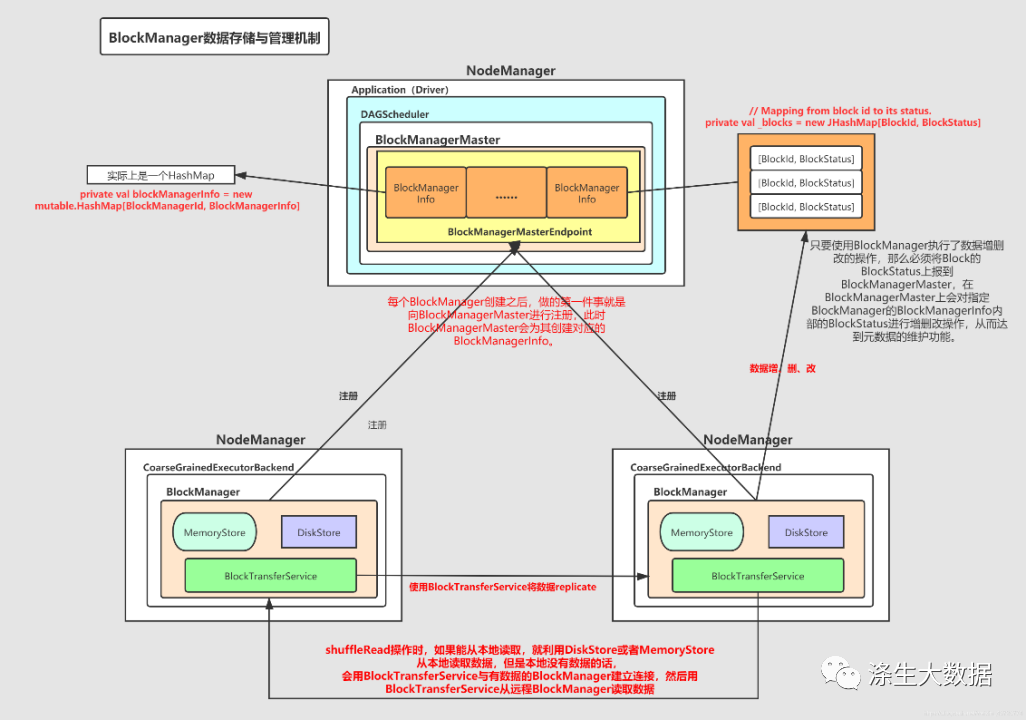
3.代码解读
Spark的BlockManager主要由以下两个类实现:
BlockManagerMaster:负责管理集群中所有节点的BlockManager,并协调各个节点之间的数据块复制和迁移等操作。
BlockManager:负责管理本地节点的数据块,包括数据块的存储、缓存、序列化和反序列化等操作。
接下来,我们重点分析BlockManager,BlockManager的代码主要位于Spark的存储模块中。以下是BlockManager的主要代码结构:
-
BlockManagerMaster:这是BlockManager的主节点,它负责管理所有的数据块。BlockManagerMaster会与每个工作节点上的BlockManager进行通信,了解每个数据块的位置和状态。
-
BlockManagerWorker:这是BlockManager的工作节点,它负责管理本地的数据块。BlockManagerWorker会与BlockManagerMaster进行通信,报告本地数据块的状态。
-
BlockInfo:这是表示一个数据块的信息,包括数据块的大小、位置、副本数等。
-
BlockManager:这是实际执行数据块管理操作的类,它提供了读取、写入、删除数据块的方法。
下面是BlockManager的关键代码解析:
class BlockManager(executorId: String,rpcEnv: RpcEnv,val master: BlockManagerMaster,val defaultSerializer: Serializer,val conf: SparkConf,memoryManager: MemoryManager,mapOutputTracker: MapOutputTracker,shuffleManager: ShuffleManager,blockTransferService: BlockTransferService,securityManager: SecurityManager,numUsableCores: Int)
extends BlockDataManager with Logging {// 存储所有的Blockprivate val blocks = new ConcurrentHashMap[BlockId, BlockInfo]// 存储所有正在读取中的Blockprivate val activeReads = new ConcurrentHashMap[BlockId, BlockFetchingState]// 存储所有正在写入中的Blockprivate val activeWrites = new ConcurrentHashMap[BlockId, BlockOutputStream]// 存储所有已经删除的Blockprivate val deadBlocks = new ConcurrentHashMap[BlockId, Long]// 存储所有已经接收到的Blockprivate val receivedBlockTracker = new ReceivedBlockTracker// 存储所有已经丢失的Blockprivate val blockReplicationPolicy = BlockManager.getReplicationPolicy(conf, master)private val blockTracker = new BlockTracker(blockReplicationPolicy)private val lostBlocks = new ConcurrentHashMap[BlockId, ArrayBuffer[BlockManagerId]]// 存储所有已经被缓存的Blockprivate val cachedBlocks = new ConcurrentHashMap[BlockId, CachedBlock]// BlockManager的内存管理器private val memoryStore =new MemoryStore(conf, memoryManager, this, blockInfoManager)// BlockManager的磁盘管理器private val diskStore = new DiskStore(conf, this, diskBlockManager)// BlockManager的块传输服务private val blockTransferService =new NettyBlockTransferService(conf, securityManager, numUsableCores)// BlockManager的块上传服务private val blockUploadHandler = new BlockUploadHandler(this)// BlockManager的块下载服务private val blockDownloader = new BlockDownloader(blockTransferService, this)// BlockManager的安全管理器private val blockTransferServiceServer =blockTransferService.initServer(rpcEnv, blockUploadHandler, blockDownloader)// BlockManager的Shuffle管理器private val shuffleBlockResolver = new ShuffleBlockResolver(conf)// BlockManager的Shuffle上传服务private val shuffleUploadHandler = new ShuffleUploadHandler(this, shuffleBlockResolver)// BlockManager的Shuffle下载服务private val shuffleDownloader = new ShuffleDownloader(blockTransferService, this)// BlockManager的Shuffle管理器private val shuffleServerId = SparkEnv.get.blockManager.blockManagerId.shuffleServerId// BlockManager的Shuffle服务private val shuffleService =new NettyShuffleService(shuffleServerId, conf, securityManager, shuffleUploadHandler,shuffleDownloader)// BlockManager的Metricsprivate val metricsSystem = SparkEnv.get.metricsSystemprivate val numBlocksRegistered = metricsSystem.counter("blocks.registered")private val numBlocksRemoved = metricsSystem.counter("blocks.removed")// 启动BlockManager的各个服务blockTransferService.init(clientMode = false)blockTransferServiceServer.start()shuffleService.start()// BlockManager的IDval blockManagerId = BlockManagerId(executorId, blockTransferService.hostName, rpcEnv.address.port)代码中,BlockManager主要包括以下几个部分:
-
存储结构:使用ConcurrentHashMap存储所有的Block、正在读取中的Block、正在写入中的Block、已经删除的Block、已经接收到的Block、已经缓存的Block以及已经丢失的Block等信息。
-
内存管理器和磁盘管理器:内存管理器负责将小的数据块存储在内存中,而磁盘管理器则负责将大的数据块存储在磁盘上。
-
块传输服务:负责处理节点之间的数据块传输,例如上传、下载和复制等操作。
-
Shuffle管理器:负责处理Spark的Shuffle操作,包括Shuffle数据的存储和传输等。
Metrics:用于收集BlockManager的各种指标,如已注册的Block数、已删除的Block数等。
4.案例分析
下面以WordCount为例,演示BlockManager在Spark中的使用过程:
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)val lines = sc.textFile("data.txt")
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(word => (word, 1)).reduceByKey(_ + _)wordCounts.collect().foreach(println)在这个例子中,首先调用textFile方法读取文本文件,并将其划分为多个Block。然后,使用flatMap和map方法对每个Block中的文本进行处理,最后使用reduceByKey方法将相同的单词进行合并。在这个过程中,BlockManager扮演着重要的角色,它负责管理所有的Block,并确保它们可以高效地共享和访问。