开篇部分:人工智能、深度神经网络与内存计算的交汇
在当今数字化时代,人工智能(AI)已经成为科技领域的一股强大力量,而深度神经网络(DNN)则是AI的核心引擎之一。DNN是一种模仿人类神经系统运作方式的计算模型,通过层层堆叠的神经元网络来实现复杂的模式识别和数据处理任务。从图像识别、语音识别到自然语言处理,DNN已经在各个领域展现了惊人的能力。然而,随着DNN模型的不断演进和复杂化,对计算资源的需求也与日俱增。
传统的计算机体系结构在处理DNN的推理和训练任务时面临着诸多挑战。数据在内存和处理单元之间的频繁传输导致了巨大的能耗和延迟,限制了计算效率和性能的进一步提升。为了应对这些挑战,内存计算(In-Memory Computing,IMC)技术应运而生。
IMC是一种革命性的计算范式,其核心思想是在内存单元内直接执行计算操作,从而将数据和计算更紧密地集成在一起,最大程度地减少数据传输和能源开销。IMC的出现为加速DNN推理和训练任务提供了全新的可能性,吸引了众多研究者和工程师的关注和投入。在接下来的篇章中,我们将深入探讨IMC技术在DNN加速领域的最新进展和潜在应用,以及面临的挑战和未来发展方向。
第二部分:IMC与传统计算机架构的优势
在探讨内存计算(IMC)技术与传统计算机架构的优势时,我们不仅可以从性能、能效和可扩展性等方面进行比较,还可以深入了解IMC在各个领域的实际应用和潜在影响。
1. 性能优势
IMC技术通过将计算操作直接放置在内存中,实现了数据和计算的紧密集成。这种紧密的结合消除了传统计算机架构中由于数据传输造成的延迟和瓶颈。相比之下,传统计算机架构需要将数据从内存传输到处理单元进行计算,然后再将结果写回内存,这一过程可能会消耗大量时间和能源。而IMC在内存中执行计算操作,大大减少了这种传输过程,从而显著提高了系统的性能和响应速度。
2. 能效优势
IMC技术的能效优势主要体现在两个方面:能源消耗和热管理。首先,由于IMC减少了数据传输过程中的能源消耗,使得整个系统的能耗大大降低。其次,IMC将计算操作直接放置在内存中,减少了处理器的工作负载,降低了系统的发热量,从而减少了对冷却系统的需求,进一步提高了能效。
3. 可扩展性优势
IMC技术具有良好的可扩展性,能够满足不断增长的计算需求。传统计算机架构在面对大规模数据处理和计算任务时往往面临着硬件资源不足和性能瓶颈的问题。而IMC可以通过增加内存单元和并行计算单元来实现水平扩展,从而满足不断增长的计算需求,保持系统的高性能和可靠性。
实际应用和潜在影响
IMC技术在各个领域都具有广泛的应用前景。在人工智能领域,IMC可以加速深度学习模型的推理和训练任务,提高模型的性能和效率。在大数据分析和处理领域,IMC可以加速数据处理和计算任务,提高系统的响应速度和效率。此外,IMC还可以应用于物联网、生物信息学、医学影像处理等领域,为各种应用场景提供高效、可靠的计算解决方案。
总的来说,IMC技术具有明显的性能、能效和可扩展性优势,可以为各种应用场景提供高效、可靠的计算解决方案,对计算机体系结构的发展和演进具有重要的意义和影响。在未来,随着IMC技术的不断成熟和完善,相信其在各个领域的应用前景将更加广阔,为人类社会的发展和进步带来新的机遇和挑战。
第三部分:计算存储器技术介绍
内存计算(IMC)的主要优势在于减少或抑制数据移动,从而提高了能效。减少数据移动的方法有多种,其中主要包括近内存计算、基于静态随机存取存储器(SRAM)的内存计算以及利用新兴的非易失性存储器(NVM)技术进行内存计算。下面将详细介绍这些技术及其优势。
1. 近内存计算
近内存计算是一种将非易失性内存直接嵌入到处理器芯片上的技术,以增加带宽并减少数据传输。这种方法使得大量模型参数,如突触权重和激活,可以直接存储在内存中,从而避免了数据传输的延迟和能耗。近内存计算可以大幅提高系统的性能和能效,是一种非常有效的内存计算技术。
2. 基于SRAM的内存计算
基于SRAM的内存计算是一种直接在SRAM内存阵列中执行计算操作的技术。通过将计算逻辑直接嵌入到内存中,可以实现数据和计算的紧密集成,从而减少了数据传输过程中的能耗和延迟。这种技术虽然在易失性和密度方面存在一些限制,但在某些应用场景下仍然具有重要意义。
3. 利用新兴的非易失性存储器技术进行内存计算
利用新兴的非易失性存储器(NVM)技术进行内存计算是一种最新的技术趋势。这些NVM设备具有非易失性存储特性,可以在电源关闭后保持突触权重,从而避免了数据在计算过程中的丢失。同时,这些设备通常具有较高的集成度和密度,可以实现更高效的内存计算操作。主要的NVM技术包括:
- 电阻随机存取存储器(RRAM)
- 相变存储器(PCM)
- 铁电随机存取存储器(FeRAM)
- 铁电场效应晶体管(FeFET)
- 自旋转移力矩磁性随机存取存储器(STT-MRAM)
- 自旋轨道力矩磁性随机存取存储器(SOT-MRAM)
- 电化学随机存取存储器(ECRAM)
- 忆晶体管(Memtransistor)
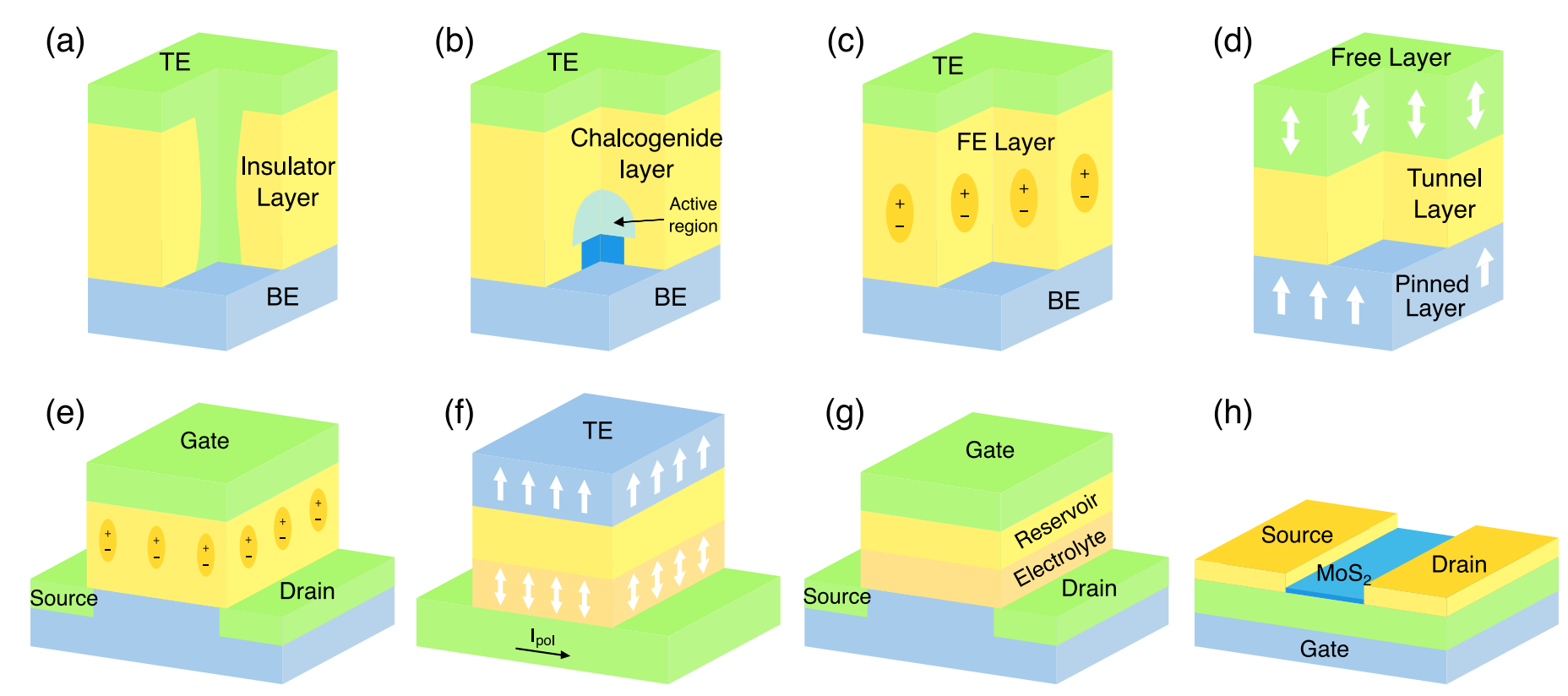
当涉及到各种NVM(非易失性存储器)技术时,每种技术都有其独特的优势和特点。下面将详细介绍几种主要的NVM技术以及它们的优势:
1. 电阻随机存取存储器(RRAM)
-
非易失性: RRAM的突变器件状态可以在断电后保持,这使得它们非常适合于存储长期数据。
-
可扩展性: RRAM器件具有较小的尺寸,并且可以在垂直和水平方向上进行扩展,使得它们可以实现高密度的存储。
-
高速度: 由于其简单的电阻变化原理,RRAM设备具有快速的读写速度,使其在应用中具有较高的性能。
2. 相变存储器(PCM)
-
多态性: PCM器件可以在不同的晶体和非晶态之间切换,这使得它们能够存储多个比特,从而提高了存储密度。
-
长寿命: 相变材料通常具有较长的使用寿命和较高的循环次数,使得PCM器件具有可靠性和耐久性。
-
低功耗: 相变存储器的读写操作通常具有较低的功耗,这使得它们非常适合于移动设备和低功耗应用。
3. 铁电随机存取存储器(FeRAM)
-
快速写入: FeRAM器件具有快速的写入速度,且写入操作不会对器件产生损伤,这使得其在实时数据记录和缓存应用中具有优势。
-
长寿命: 铁电材料具有很长的循环寿命,因此FeRAM器件可以进行大量的写入/擦除操作而不会导致性能下降。
-
低功耗: 与其他NVM技术相比,FeRAM的读写操作通常具有较低的功耗,使其成为节能应用的理想选择。
4. 自旋转移力矩磁性随机存取存储器(STT-MRAM)
-
高速度: STT-MRAM器件具有快速的读写速度,这使得其在高性能计算和存储系统中具有重要作用。
-
长寿命: 自旋转移力矩效应可以实现非常高的循环次数,因此STT-MRAM器件具有很长的使用寿命。
-
可扩展性: STT-MRAM技术可以在不同尺寸和密度上进行扩展,从嵌入式系统到大型数据中心存储系统都可以使用。
5. 自旋轨道力矩磁性随机存取存储器(SOT-MRAM)
-
低功耗: 由于自旋轨道耦合效应,SOT-MRAM器件具有较低的功耗,这使得其在移动设备和节能应用中具有优势。
-
高速度: SOT-MRAM器件具有快速的读写速度,可以满足高性能计算和数据处理的需求。
-
稳定性: 自旋轨道耦合效应可以实现稳定的存储状态,且器件具有较高的可靠性和长寿命。
6. 电化学随机存取存储器(ECRAM)
-
低功耗: ECRAM器件通常具有较低的功耗,因为其操作是基于电化学反应而不是电子流动。
-
高循环次数: 由于电化学反应的性质,ECRAM器件通常具有较高的循环次数和长寿命。
-
稳定性: 电化学存储器的状态可以在断电后保持,这使得其在需要长期存储数据的应用中具有优势。
7. 忆晶体管
-
高速度: 忆晶体管器件具有快速的写入速度和读取速度,使得其在需要快速存储和检索数据的应用中非常有用。
-
多态性: 忆晶体管可以存储多种状态,并且可以实现多比特存储,从而提高了存储密度和容量。
-
可编程性: 忆晶体管的状态可以通过外部控制进行编程,这使得其在灵活性和可定制性方面具有优势。
比较分析
在比较各种NVM技术时,可以根据其性能指标和特点进行评估:
-
非易失性: 所有的NVM技术都具有非易失性,但在具体应用中可能有不同的要求,如循环寿命、耐久性等。
-
速度: 不同的NVM技术具有不同的读写速度,这取决于其工作原理和物理结构。
-
密度: 各种NVM技术在存储密度方面也存在差异,一些技术可能具有更高的存储密度,从而可以实现更大的存储容量。
-
功耗: NVM技术的功耗也是一个重要考虑因素,特别是在移动设备和低功耗应用中。
-
循环寿命: 对于需要频繁写入和擦除操作的应用,循环寿命是一个关键的性能指标,不同的NVM技术具有不同的循环寿命。
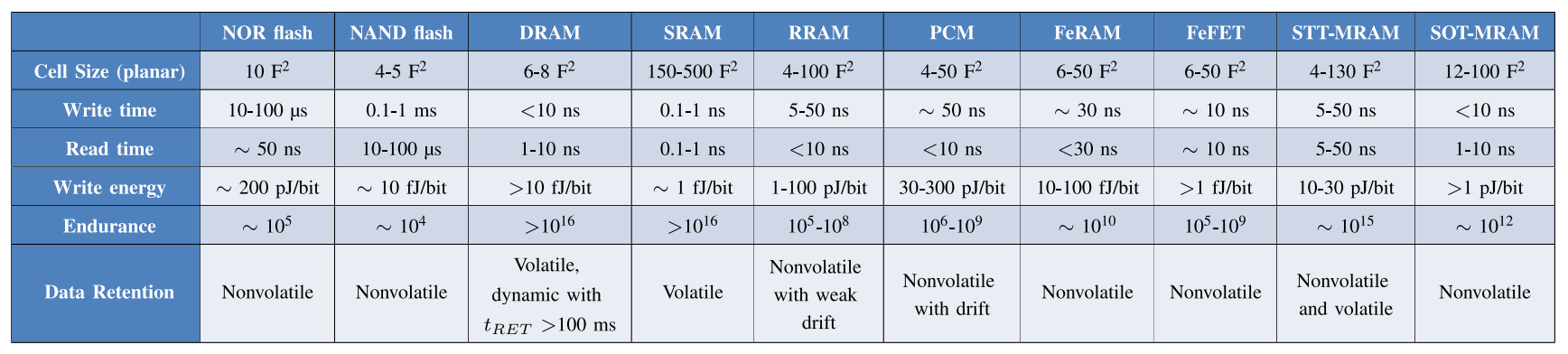
不同半导体存储器技术的指示性性能和特点
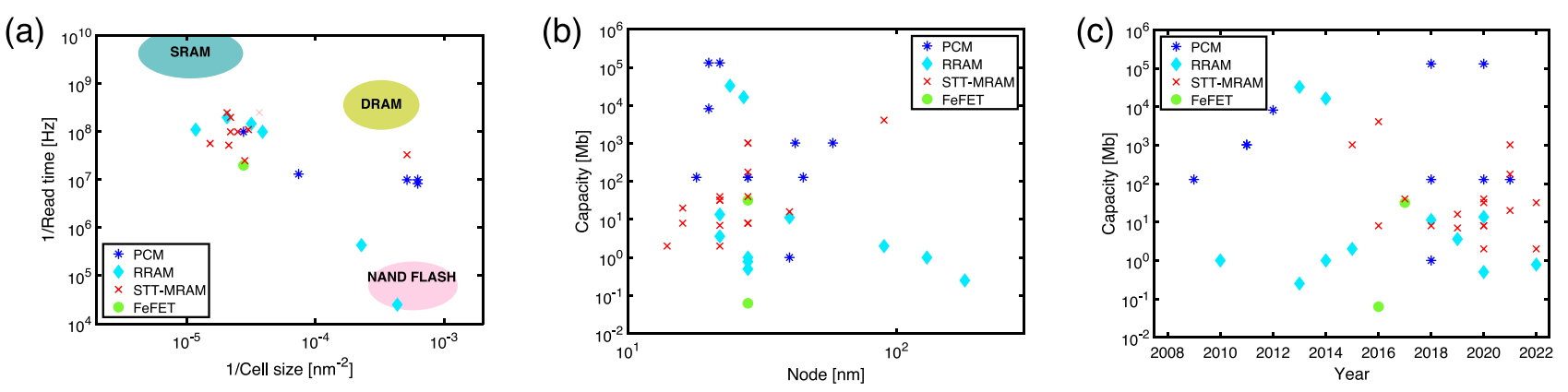
各种新兴存储器演示器的性能和特点
- 图 a 显示了速度(以读取时间的倒数表示)和密度(以单元面积的倒数表示)的相关图。文献中的数据与基于 CMOS 的传统存储器技术(如 SRAM、DRAM 和 NAND 闪存)的典型范围进行了比较。新兴 NVM 的性能/成本通常介于 CMOS 存储器之间,速度接近 DRAM,而密度一般仍介于 SRAM 和 DRAM 之间。
- 图 b 显示了各种 NVM 演示器的阵列大小与技术节点的函数关系。容量范围从嵌入式存储器(1-100 MB)到独立存储器(1-100 GB)。请注意,技术节点越小,阵列容量不一定越大,这是由于技术的成熟度不同造成的。
- 图 c 显示了一些 NVM 演示器的存储器容量与年份的函数关系,凸显了各种存储器技术的不断发展。
综上所述,选择最合适的NVM技术取决于具体的应用需求,需要综合考虑其非易失性、速度、密度、功耗和循环寿命等方面的特点,以及成本和制造工艺等因素。
第四部分:内存矩阵 - 矢量乘法
内存矩阵 - 矢量乘法的基本原理
内存矩阵-矢量乘法(IMC MVM)是一种旨在加速计算的技术,特别是在处理大规模矩阵乘法时。它的核心思想是利用存储器的特性,直接在存储器内执行计算,而无需将数据移动到处理器或其他地方进行处理。
首先,让我们理解一下传统的矩阵乘法操作。假设我们有一个矩阵A(m × n)和一个向量x(n × 1),我们需要将它们相乘以产生一个新的向量y(m × 1)。在传统的计算中,我们会将矩阵A和向量x的数据加载到处理器的内存中,然后使用处理器进行计算,并最终将结果保存到内存中。
而IMC MVM技术则将计算直接嵌入到存储器中,这使得计算可以在存储器级别上并行执行,大大提高了计算速度和效率。具体来说,IMC MVM利用了交叉点存储器阵列的特性。在这种存储器中,每个交叉点上都有一个可编程电阻元件,通过在行和列上施加电压,可以控制电流流过每个交叉点的大小。根据欧姆定律和基尔霍夫电流定律,存储器阵列可以直接执行矩阵-矢量乘法运算,而无需额外的处理器或计算单元。
具体地,通过在列上施加一个电压向量,存储器阵列中的每个交叉点都会产生一个电流,这些电流经过行线并最终被收集起来。这样,输出电流向量就是矩阵A与向量x的乘积的结果。由于存储器阵列具有高度的并行性,计算可以在一个步骤内完成,而不受矩阵大小的限制,因此时间复杂度为O(1),效率非常高。
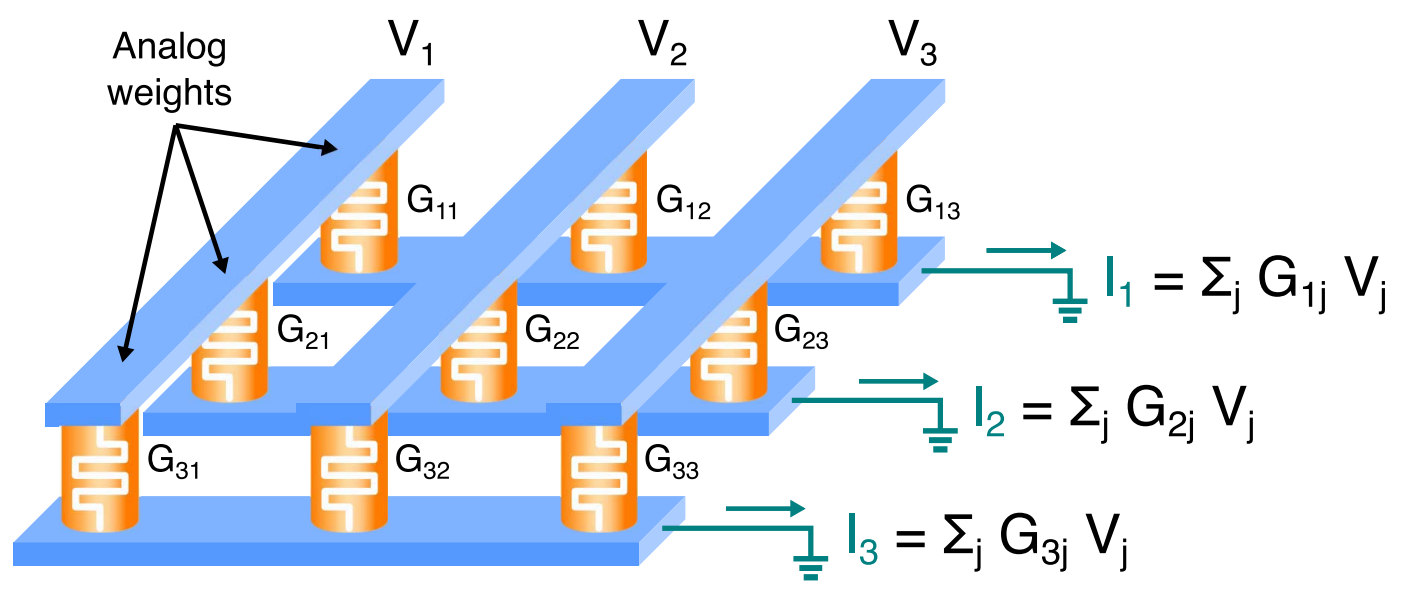
此外,IMC MVM技术还具有灵活性和可扩展性。它可以根据不同的应用需求和存储器器件进行各种实现。例如,可以通过在电阻元件上串联一个接入器件来解决编程问题,或者使用一系列晶体管和电阻器来实现更精细的电流控制。因此,IMC MVM技术可以适用于各种不同的计算任务,并在提高计算速度和效率方面发挥重要作用。
IMC 的应用场景
IMC的应用场景非常广泛,包括图像处理、线性代数运算、组合优化、贝叶斯网络等领域。其中,最受欢迎的应用之一是深度神经网络(DNN)推理和训练。在DNN推理中,IMC用于加速MVM操作,而在训练中,则需要原位权重更新方案,以实现迭代梯度下降算法。此外,IMC还可以用于图像处理、特征提取、线性回归等任务,以及组合优化和贝叶斯网络等算法。
第五部分:深度神经网络推理加速:三种内存加速方法
在人工智能技术的迅速发展中,深度神经网络(DNN)扮演着至关重要的角色。然而,DNN在进行推理时通常需要大量的计算资源,这在实际应用中可能会成为一个瓶颈。为了解决这一问题,研究人员们提出了各种各样的加速方法,其中一种方法是利用内存加速器来加快推理过程。本文将介绍三种不同类型的内存加速器,并对它们的工作原理进行解释。
-
全数字电路:这种加速器利用存储逻辑门执行乘法运算,然后使用计数器进行顺序累加。它的优点是对各种非理想情况具有很强的适应能力,但是它的计算并行性受到了限制。
-
数模混合电路:这种加速器在数字域中使用XNOR门执行乘法运算,在模拟域中通过Kirchhoff电流定律(KCL)执行累加。虽然这种方法利用了并行性,但是模拟累加需要更复杂的外围电路,并且对寄生效应更为敏感。
-
全模拟电路:这种加速器利用电阻式存储元件执行乘法,并通过电流或电荷累积进行累加。全模拟加速器可以充分发挥并行性,但是需要精确的读出和转换电路,并且受到器件和电路层面寄生效应的影响。
这三种不同类型的加速器各有优缺点,适合不同类型的应用场景。选择适合特定应用的加速器取决于对性能、功耗和成本的需求,以及对非理想情况的鲁棒性要求。通过不断地研究和改进这些方法,我们可以更有效地加速DNN的推理过程,从而推动人工智能技术的发展。
收尾部分:IMC 电路的未来展望
集成存储器计算(IMC) 在电路密度、速度、能效和可扩展性方面具有显著优势。在机器学习和深度学习领域,已经发现了一些解决方案和应用,但同时也面临着各种技术和设计挑战。为了进一步推动IMC的发展和产业化,需要从两个主要方向来解决这些挑战。
1. 器件技术和材料研究
- 精确、稳定、低电流的存储器件:这些存储器件的采用将使IMC受益匪浅,可以轻松集成到大规模光刻工艺的后端工艺层(BEOL),同时还可以在多个导电层面进行编程。
- 材料和器件物理的研究:研究可以揭示波动和漂移等非理想现象背后的机制,从而开发出免受寄生效应影响的新型存储器件。
- 存储器单元配置的工程设计:如1S1R或1T1R结构,可大幅降低工作电流,从而降低能耗、减少IR下降,并提高IMC系统的面积效率。
2. 计算架构研究及与工作负载的相互作用
- 最大限度提高计算并行性:以防止读出链的多路复用,需要研究并实现高度并行的计算架构。
- 精确的协同设计:通过对硬件和神经网络进行精确的协同设计,可以最大限度地提高系统性能。
- 定制的神经网络:根据应用需求对神经网络进行定制,以采用适合IMC加速的功能,如低级量化或硬件感知训练程序。
- 电子设计自动化(EDA)工具链:需要一个完善的EDA工具链,以弥合终端用户与硬件系统之间的差距,包括特定于应用的高抽象层设计工具和专用编译器,类似于现有的基于CPU和GPU的计算系统。
综上所述,集成存储器计算(IMC)的发展不仅需要在器件技术和材料研究方面取得进展,还需要研究和实现高效的计算架构,并建立完善的电子设计自动化工具链,以推动IMC在机器学习和深度学习领域的广泛应用和产业化。
结尾
内存计算(IMC)技术与传统计算机架构相比具有显著的性能、能效和可扩展性优势,为各种应用场景提供了高效、可靠的计算解决方案。从近内存计算到基于SRAM的内存计算,再到利用新兴的非易失性存储器(NVM)技术进行内存计算,不同的技术都在不同程度上改善了数据处理和计算任务的效率和能效。随着各种NVM技术的不断发展和成熟,我们有望看到更多高性能、低功耗的存储器设备应用于各种领域,推动计算机体系结构的进一步发展和演进。
在未来,IMC技术将继续发挥重要作用,为人工智能、大数据分析、物联网等领域的应用提供更加高效、可靠的计算支持。同时,我们也应该意识到,IMC技术虽然带来了诸多优势,但也面临着诸多挑战,如制造工艺的成本、技术的稳定性等。因此,我们需要不断加强研发和创新,进一步完善IMC技术,以应对日益增长的计算需求,推动科技进步,为人类社会的发展和进步做出更大的贡献。
引用文献
- In-Memory Computing for Machine Learning and Deep Learning
- In-Memory Computing Synthesis and Optimization
- In-Memory Computing Architectures forBig Data and Machine Learning Applications