一、什么的双写一致性
1.定义
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致。
2.正常情况

读操作:缓存命中,直接返回;缓存没命中查询数据库,写入缓存,设定超时时间。
写操作:延时双删。

3.非正常情况
(1)先删除缓存,再修改数据库

缓存和数据库的初始数据: 对应线程1的第一步操作:


对应线程2的操作: 对应线程1的第二步操作:

最后,可以发现缓存的数据与数据库的数据不一致了,也就是脏数据。
(2)先修改数据库,再删除缓存
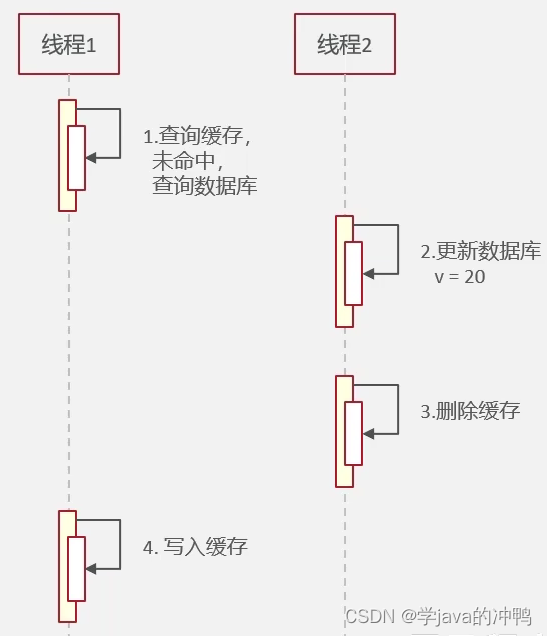
初始数据如下图,由于缓存数据超时,线程1只能查数据库,拿到的数据为10。
线程2这时先更新数据库的数据,再删除缓存。

最后,线程1把之前读到的数据也就是10放入缓存之中。
最后,可以发现缓存的数据与数据库的数据不一致了,也就是脏数据。
4.延时双删
从非正常情况就可以知道为什么需要再删除一次缓存,就是为了降低脏数据的出现。那为什么要延时呢?因为我们的数据库一般是主从模式的,就是读写分离的,数据需要从主节点同步到从节点,所以需要延时删除缓存。但是,这个延时的时间却不好控制。综述,延时双删可以降低脏数据出现的风险,但不能保证数据的强一致性。
5.那怎么保证数据强一致性
(1)分布式锁
缺点:性能低。

(2)读写锁
因为数据库大多数都是读多写少。所以对读操作加共享锁,其他线程都可以读操作,但不能写操作。在写操作加排他锁,其他线程不得读也不能写。这样不仅保证了数据的强一致性,还兼顾了性能。
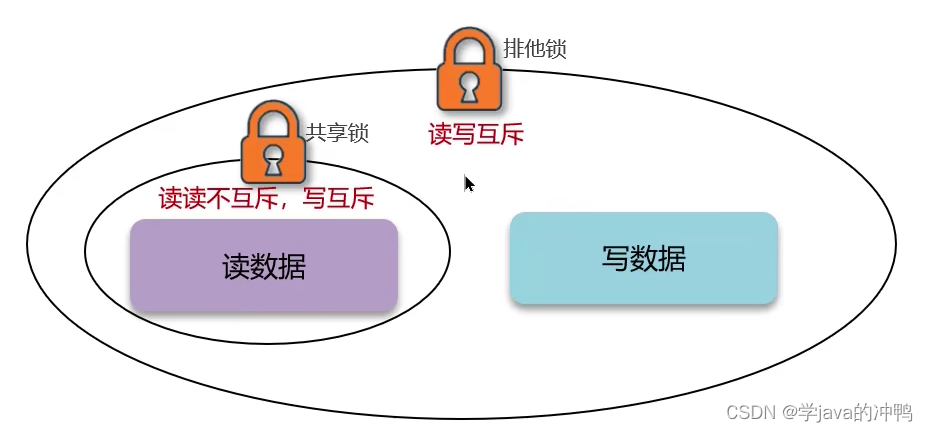
读写锁的代码可以参考网上的,核心就是使用redission,获取读写锁然后操作。
(3)异步通知
实际开发中,大部分都可以有延时的,主要是使用消息队列(mq)。
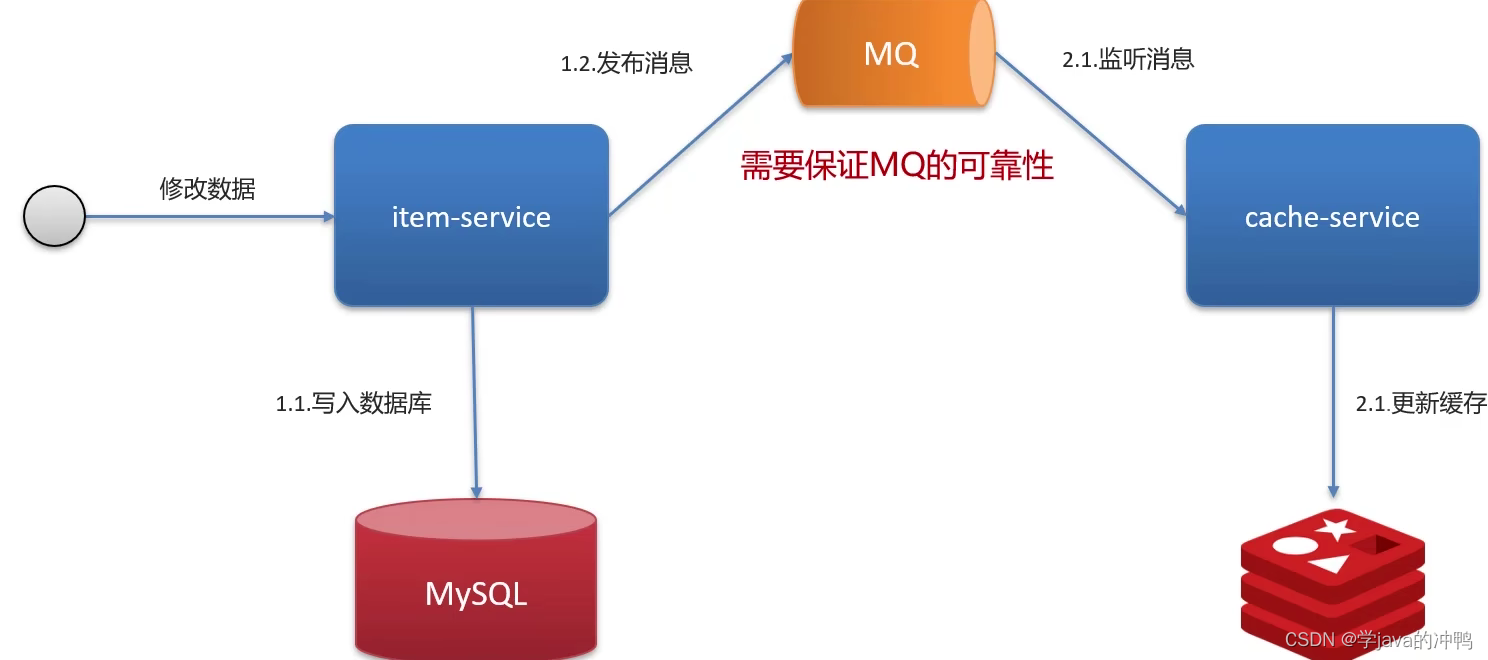
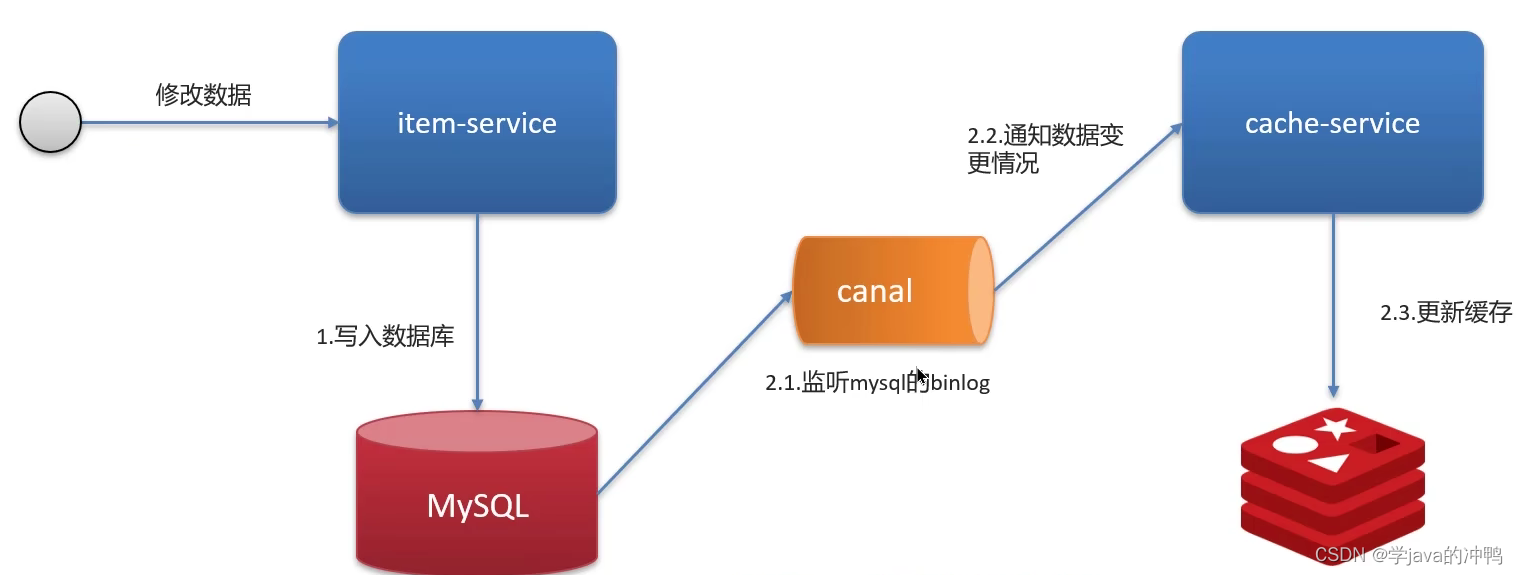
(4)使用Canal
Canal是基于数据库的主从同步来实现的。通过二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询 (SELECT、SHOW)语句。这样的优点就是不会在业务代码上有复杂其他的代码了。
6.面试的时候应该如何回答
(1)强一致性的业务回答
面试官:redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
候选人:就说我最近做的这个项目,里面有xxxx(根据自己的简历上写)的功能,需要让数据库与redis高度保持一致,因为要求时效性比较高,我们当时采用的读写锁保证的强一致性。
我们采用的是redisson实现的读写锁,在读的时候添加共享锁,可以保证读读不互斥,读写互斥。当我们更新数据的时候,添加排他锁,它是读写,读读都互斥,这样就能保证在写数据的同时是不会让其他线程读数据的,避免了脏数据。这里面需要注意的是读方法和写方法上需要使用同一把锁才行。
面试官:那这个排他锁是如何保证读写、读读互斥的呢?
候选人:其实排他锁底层使用也是setnx,保证了同时只能有一个线程操作锁住的方法
面试官:你听说过延时双删吗?为什么不用它呢?
候选人:延迟双删,如果是写操作,我们先把缓存中的数据删除,然后更新数据库,最后再延时删除缓存中的数据,其中这个延时多久不太好确定,在延时的过程中可能会出现脏数据,并不能保证强一致性,所以没有采用它。
(2)允许有延时的业务回答
面试官:redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
候选人:嗯!就说我最近做的这个项目,里面有xxxx(根据自己的简历上写)的功能,数据同步可以有一定的延时(符合大部分业务)
我们当时采用的阿里的canal组件实现数据同步:不需要更改业务代码,部署一个canal服务。canal服务把自己伪装成mysql的一个从节点,当mysql数据更新以后,canal会读取binlog数据,然后在通过canal的客户端获取到数据,更新缓存即可。