目录
4.ByteBuffer详解
4.1 ByteBuffer为什么做成一个抽象类?
4.2 ByteBuffer是抽象类,他的主要实现类为
4.3 ByteBuffer的获取方式
4.4 核心结构(NIO的ByteBuffer底层是啥结构,以及读写模式都是根据这些核心结构进行维护的)
4.4 核心API
4.5 字符串操作
4.6 粘包与半包
4.ByteBuffer详解
4.1 ByteBuffer为什么做成一个抽象类?
回答这个问题之前,先说一下:啥时候设计成抽象类,啥时候设计成接口?
1.针对抽象的概念(名词)设计成抽象类。eg:动物,形状,汽车这些类设计成抽象类
2.针对抽象的动作,功能(动词)设计成接口。eg:DAO设计成接口,Service设计成接口
对于ByteBuffer的设计也是符合这项规定的,ByteBuffer是缓冲区,是一个名词,所以设计成抽象类。
但是同样存在特例,如InputStream,OutputStream,流是动词,应该设计成接口,但是java设计成了抽象类,因为早期java设计不是很通透。
为什么接口可以多继承?
打个比方,一个人有多少功能?一个人可以拥有很多个功能,对吧。所以一个类(一个人)可以继承(可以拥有)很多接口(很多功能)
4.2 ByteBuffer是抽象类,他的主要实现类为
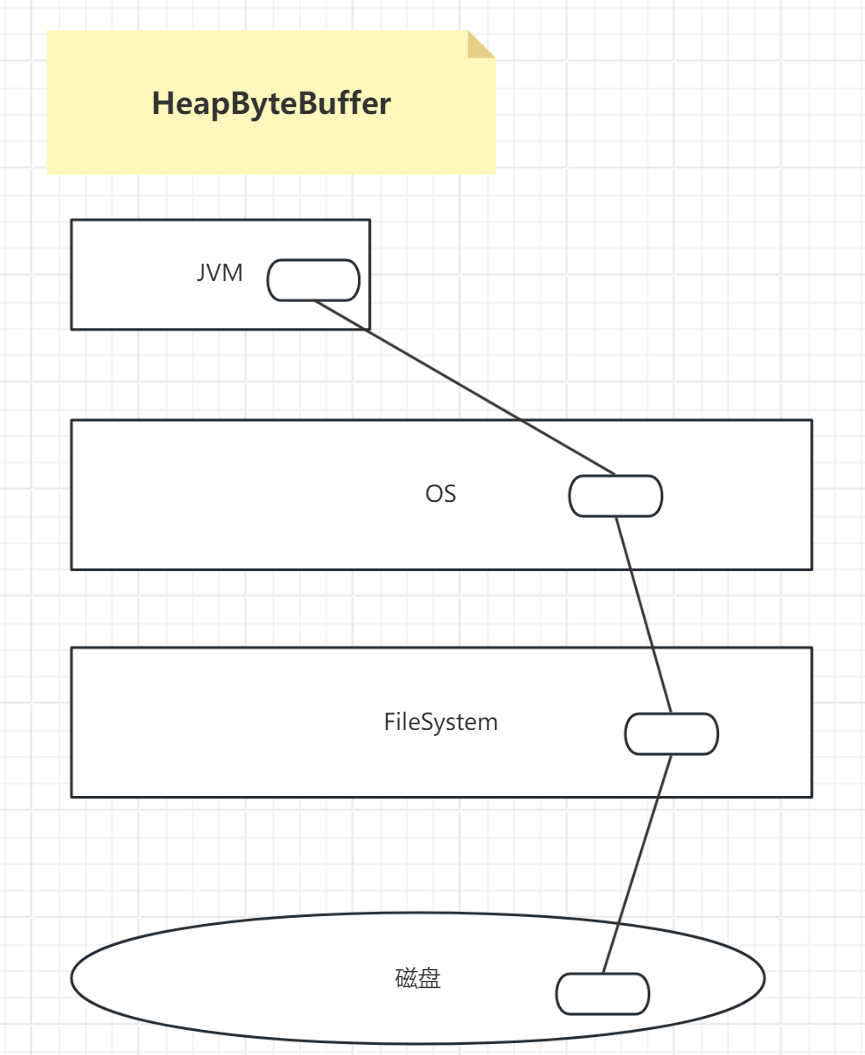
1.HeapBuffer 堆ByteBuffer ----》占用的是JVM内的堆内存 ----》读写操作 效率低 会收到GC影响
2. MappedByteBuffer(DirectByteBuffer) ----》占用的是OS内存----》读写操作 效率高 不会收到GC影响 。 不主动析构,会造成内存的泄露
- 分析一下HeapBuffer与MappedByteBuffer的区别
HeapBuffer:占用的是JVM内的堆内存 ----》读写操作 相对效率低 会收到GC影响
MappedByteBuffer: 占用的是OS内存----》读写操作 相对效率高 不会收到GC影响。但是如果不主动去释放OS的内存,会造成内存泄漏!啥是内存泄漏?内存泄漏就是前一个用户所开辟的内存空间由于忘记释放,所以无法再被之后的其他用户正常使用了
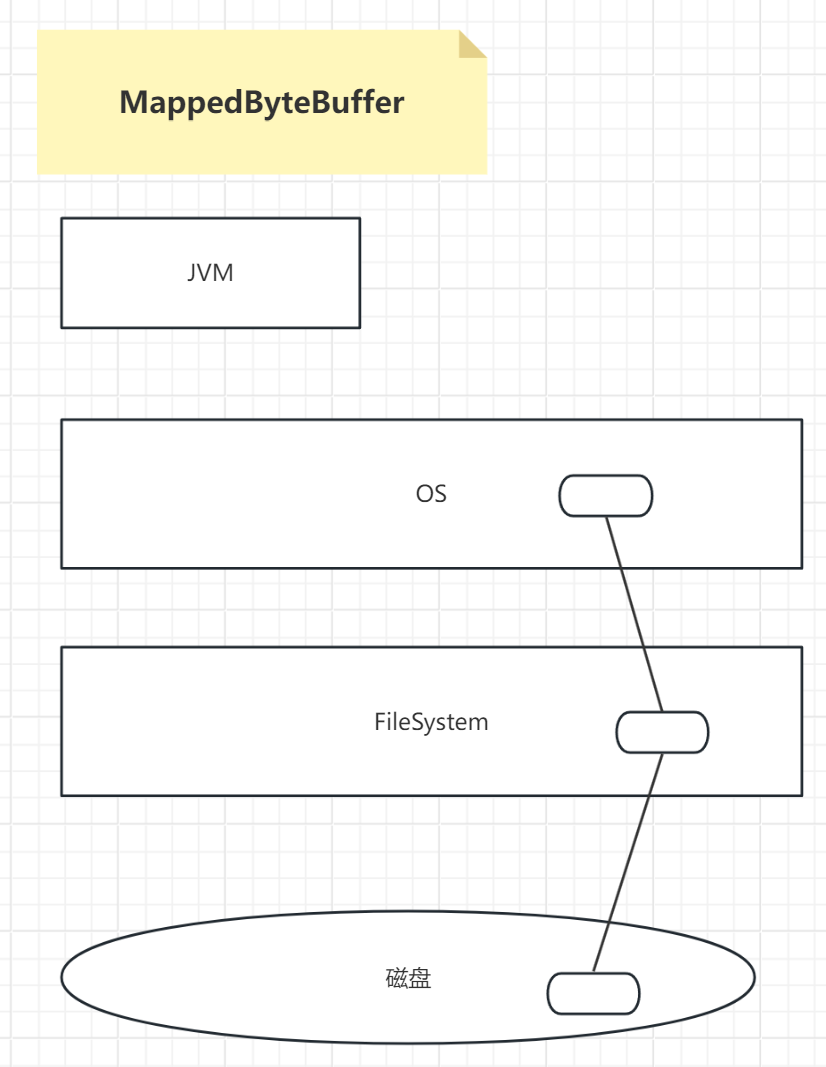
为什么MappedByteBuffer相对效率要高?
很明显,通过图中可以看出,MappedByteBuffer是在OS中直接申请的内存空间,而HeapByteBuffer是在JVM进程中申请的堆内存空间,HeapByteBuffer操作的时候,中间还隔着OS操作系统,自然效率低一些。
补充:
JVM其实就相当于操作系统启动的一个进程,进程占用着一块内存空间,进程中有栈,堆,静态代码区域等,堆空间主要存储的就是new的对象,栈存储一些局部变量,参数等,静态代码区域存储的就是代码。操作系统本质上也是由很多进程组成的一个系统,来管理整个硬件。
- 内存溢出和内存泄漏有什么区别?
内存泄漏:
举个例子:明明具有100M内存,但是实际只处理了80M内存就不能再继续增加处理了。剩余的20M内存就内存泄漏了。
内存泄漏的原因:
1.不主动析构(没有主动释放内存)
分析:前一个用户申请了20M内存空间但是没有释放并且这一个用户的使用已经结束了,后一个用户去使用的时候,100M内存只能正常使用80M内存,按理说应该可以正常使用100M内存,所以20M内存发生内存泄漏
2.内存碎片
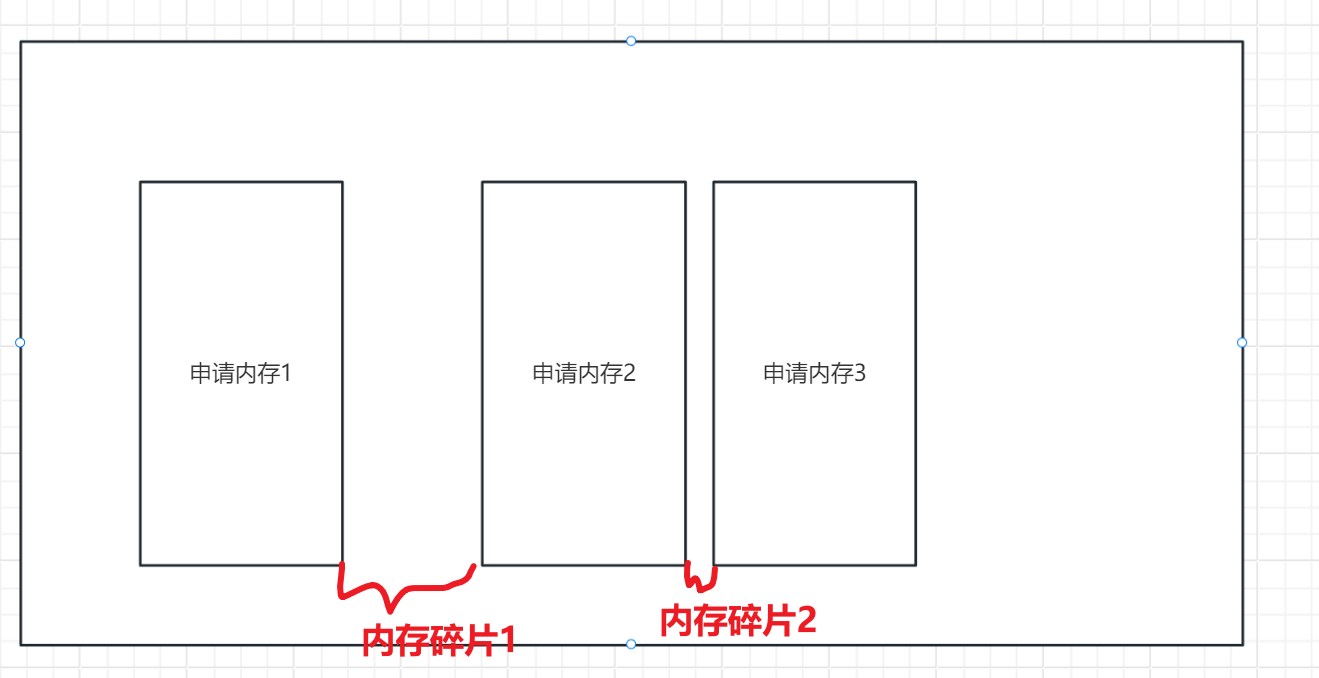
假设说内存碎片1的大小为20M,内存碎片2的大小为10M。假设说内存空间就是剩余30M(内存碎片1和内存碎片2的内存总大小),但此时我们申请一块30M大小的空间,申请失败!!因为我们目前只有20M和10M的内存空间大小,没有一块连续的30M空间大小。这也造成了内存泄漏!
现在有很多优秀的内存管理器,来减少内存碎片的大小。但我们不能保证内存中不存在碎片,内存碎片(缝隙一定存在)一定存在!而是可以做到让碎片足够的小,这样才能提升空间利用效率。
内存管理器哪里使用的多?redis中用的多,redis是一个基于内存的nosql产品,它对内存的管理要求很高。它的内存管理整合第三方的内存管理器,如gemalloc,tcmalloc等。强大的内存管理器的一个指标就是:内存碎片的管理。
内存溢出:
举个例子:具有100M内存,但实际操作的过程中,把120M的真实数据一次性加入到内存中,由于超过了100M内存的真实大小,所以内存溢出。
总结:
内存溢出就是最后的一个表现,造成内存溢出的一个很大的原因是因为过程中存在内存泄漏。
想想是不是这个道理,在造成一个内存溢出结果的过程中,因为一定会有内存碎片----》所以一定会有内存泄漏。
4.3 ByteBuffer的获取方式
1.ByteBuffer.allocate(10);//一旦分配空间,不可以动态调整。但是在Netty中的ByteBuffer类就是具有动态调整的功能,可以进行动态修改调整所分配的空间大小。因为Netty对ByteBuffer进行了一系列的优化封装,使其可以动态调整空间大小
2.encode(); 注释:encode()方法会让字符串类型的数据转换成ByteBuffer类型
4.4 核心结构(NIO的ByteBuffer底层是啥结构,以及读写模式都是根据这些核心结构进行维护的)
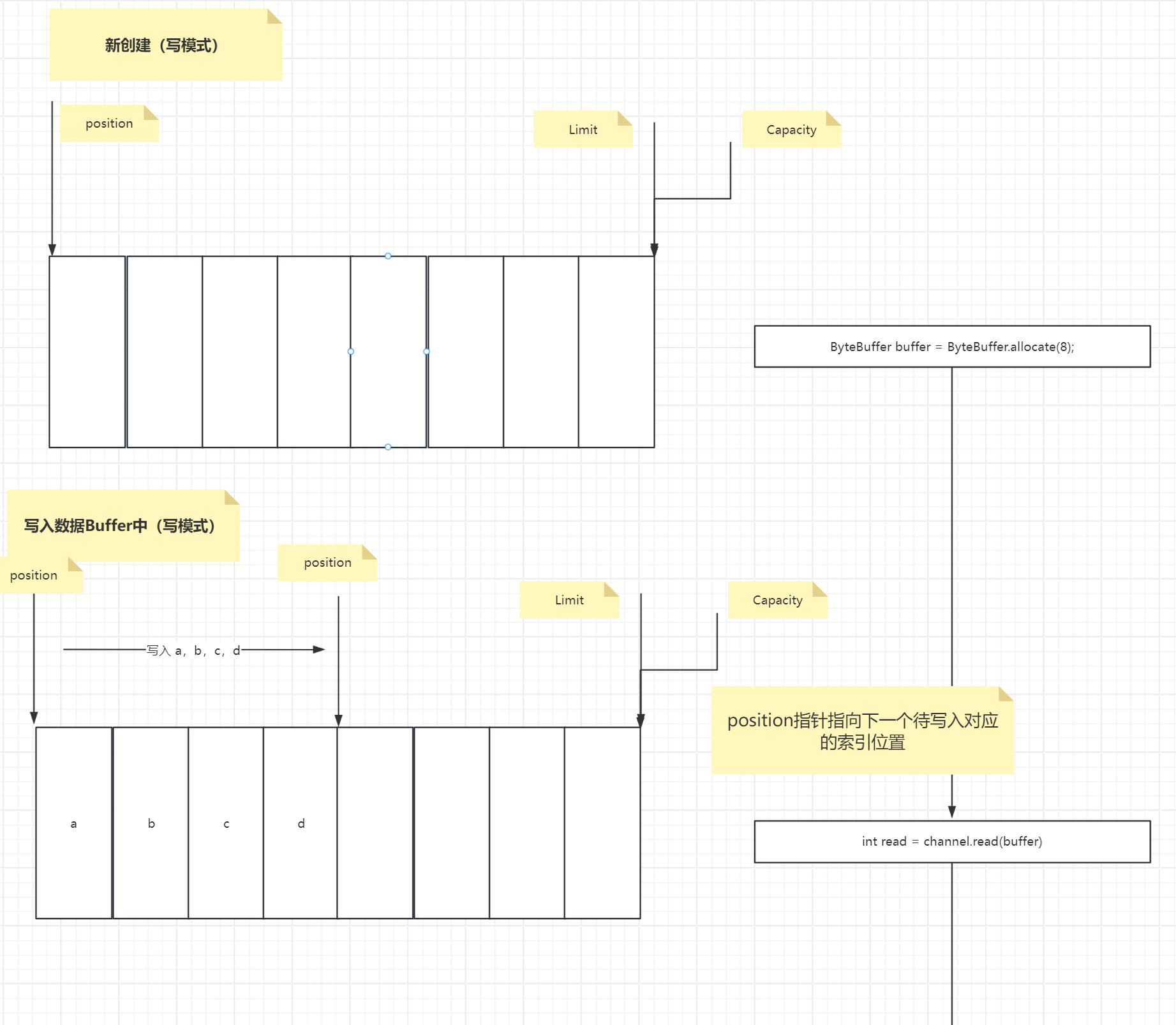
ByteBuffer是一个类似数组的结构,整个结构中包含以下三个主要的指针状态:
以下这三个状态维护出了ByteBuffer的读写模式,读写模式的切换背后实际上都是由这三个状态的不断变化而实现的。
1.Capacity
buffer的容量,类似于数组的size,指向ByteBuffer最后一个位置
2.Position
buffer当前缓存的下标。读取操作时记录下一个待读取的位置下标。写操作时记录下一个待写入的位置下标。位置下标是从0开始,每读取一次,下标+1
3.Limit
读写操作时的一个限制下标。在读操作时,Limit设置你还能再读取多少个字节的数据。在写操作时,设置你还能再写入多少个字节的数据。
- 画图

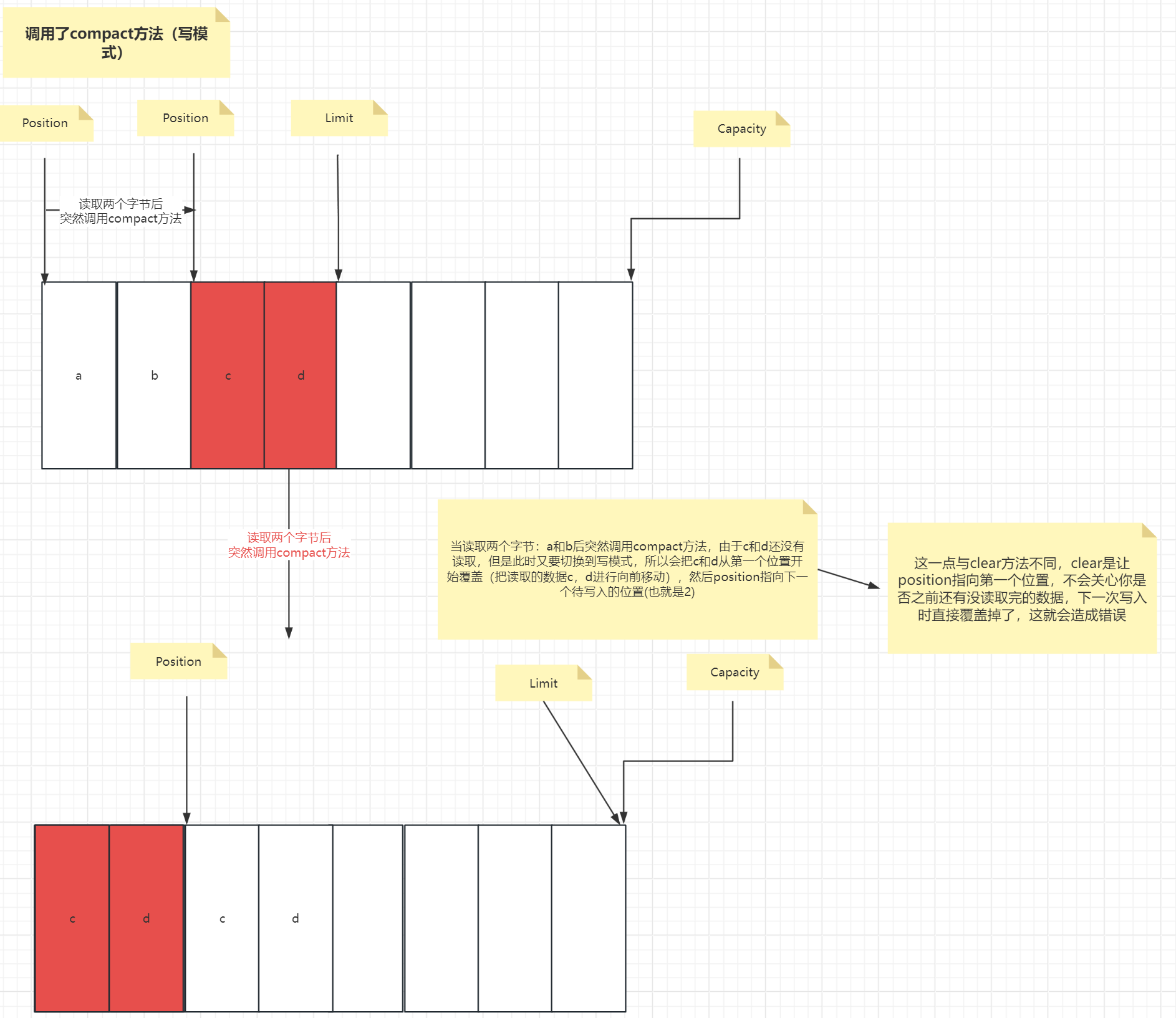
- 为什么clear方法和compact方法都是把Buffer转换成写模式,为什么还需要compact?画图来说明:
单独演示compact方法底层三个指针是如何变化的:
- 代码演示
public class TestNIO4 {public static void main(String[] args) {TestNIO4 test = new TestNIO4();test.testState05();}public void testState01() {//创建完Buffer,默认是写模式ByteBuffer buffer = ByteBuffer.allocate(10);System.out.println("buffer.capacity() = " + buffer.capacity());//10System.out.println("buffer.position() = " + buffer.position());//0System.out.println("buffer.limit() = " + buffer.limit());//10}public void testState02() {//创建完Buffer,默认是写模式ByteBuffer buffer = ByteBuffer.allocate(10);//写入四个字节的数据buffer.put(new byte[]{'a','b','c','d'}) ;//System.out.println("buffer.capacity() = " + buffer.capacity());//10System.out.println("buffer.position() = " + buffer.position());//4System.out.println("buffer.limit() = " + buffer.limit());//10}public void testState03() {ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'a','b','c','d'}) ;//改为读模式buffer.flip();//System.out.println("buffer.capacity() = " + buffer.capacity());//10System.out.println("buffer.position() = " + buffer.position());//0System.out.println("buffer.limit() = " + buffer.limit());//4}public void testState04() {ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'a','b','c','d'}) ;//调用clear,让position指向第一个索引位置buffer.clear();//System.out.println("buffer.capacity() = " + buffer.capacity());//10System.out.println("buffer.position() = " + buffer.position());//0System.out.println("buffer.limit() = " + buffer.limit());//10}public void testState05() {ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'a','b','c','d'}) ;buffer.flip();System.out.println("(char) buffer.get() = " + (char) buffer.get());//aSystem.out.println("(char) buffer.get() = " + (char) buffer.get());//bSystem.out.println("buffer.capacity() = " + buffer.capacity());//10System.out.println("buffer.position() = " + buffer.position());//2System.out.println("buffer.limit() = " + buffer.limit());//4System.out.println("----------------------------------");//把未读取的c和d移到最前面索引位置保存起来 position指向下一个d后面的一个索引位置(未读取的索引位置)开始写入buffer.compact();System.out.println("buffer.capacity() = " + buffer.capacity());//10System.out.println("buffer.position() = " + buffer.position());//2System.out.println("buffer.limit() = " + buffer.limit());//10//转换为读模式buffer.flip();System.out.println("(char) buffer.get() = " + (char) buffer.get());//cSystem.out.println("(char) buffer.get() = " + (char) buffer.get());//d}}全部测试成功,主要是对读写模式切换的理解即可,以及对Buffer读写模式切换底层核心结构的理解!
- 总结
最后总结一下:其实在日常开发过程中,无需知道在读写模式切换时底层核心结构标记是如何切换的,但是对于一些复杂开发,我们需要理解底层核心结构标记的切换
写入Buffer数据之前要设置写模式
1. 写模式
1. 新创建的Buffer,默认是写模式
2. 调用了clear,compact方法
读取Buffer数据之前要设置读模式
2. 读模式
1. 调用flip方法
4.4 核心API
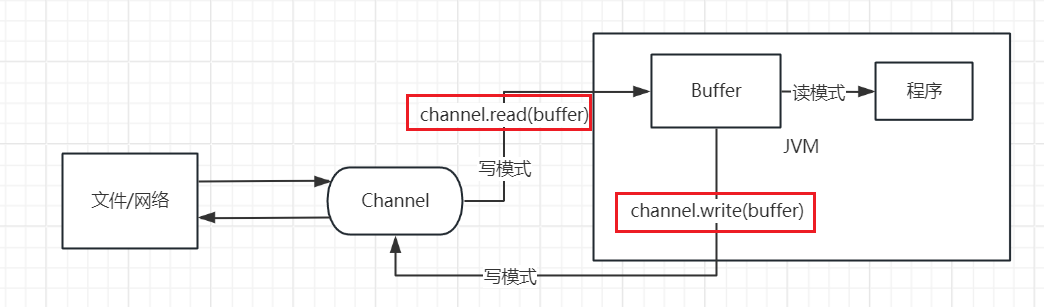
- 向Buffer缓冲区写入数据(写模式,创建一个ByteBuffer时默认为写模式 或 clear方法调用 或 compact方法调用)
1.channel的read方法
channel.read(buffer) --->向ByteBuffer这一缓冲区中写入数据
2.buffer的put方法
buffer.put(byte) ---->一个字节一个字节的写入数据到ByteBuffer 如:buffer.put((byte) 'a')
buffer.put(byte[]) ---->向ByteBuffer缓冲区中写入一个字节数组
- 从Buffer缓冲区中读出数据(读模式)
1.channel的write方法 ---》把ByteBuffer的数据读出到文件中
2.buffer的get()方法调用 ----》每调用一次get(),position位置向后移动一位
3.rewind方法(像手风琴一样来回拉扯)----》将position指向重置为0,用于重新读取数据
4.mark & reset方法 ---》这两个方法结合使用,通过mark方法进行标记一个 position位置,当调用reset方法时,会跳转到上一次mark标记的position的位置坐标,并且从这个position指向的位置坐标开始重新执行。记住一点:mark和reset方法都是结合使用的!!!!
5.get(i)方法 -----》获取特定索引位置上的数据,与get()的不同之处在于:get(i)可以特定获取某一索引位置的数据值 并且 get(i)方法不会改变position的指向!
- 代码演示
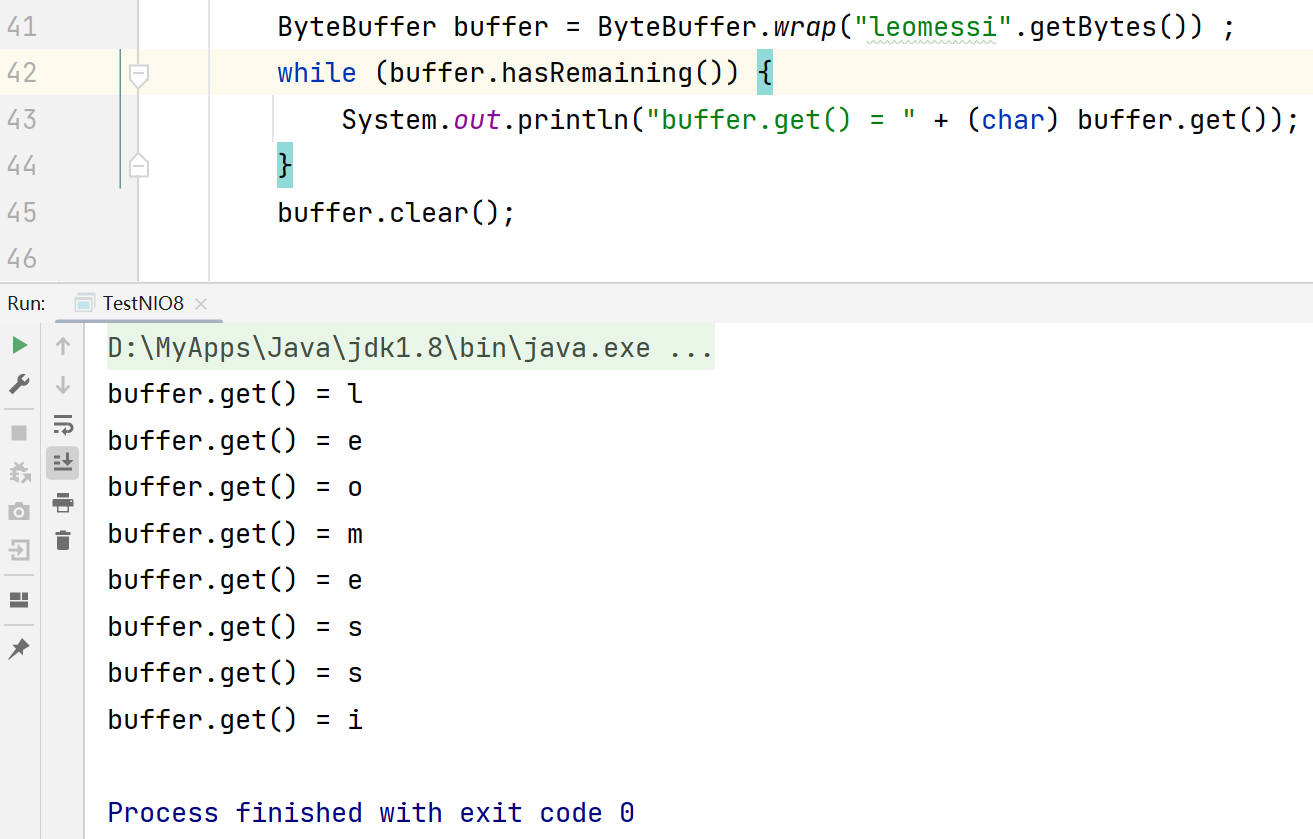
public class TestNIO5 {public static void main(String[] args) {ByteBuffer buffer = ByteBuffer.allocate(10) ;buffer.put(new byte[]{'a','b','c','d'}) ;buffer.flip();while (buffer.hasRemaining()) {System.out.println("(char) = " + (char) buffer.get()) ;}//此时此刻//position = 4 limit=4 capacity=10System.out.println("--------------------------");//把position置为0buffer.rewind();while (buffer.hasRemaining()) {System.out.println("(char) buffer.get() = " + (char) buffer.get());}}}public class TestNIO6 {public static void main(String[] args) {ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'a','b','c','d'}) ;buffer.flip();System.out.println("buffer.get() = " + (char) buffer.get());//aSystem.out.println("buffer.get() = " + (char) buffer.get());//b//记录此时position的位置:2buffer.mark();System.out.println("buffer.get() = " + (char) buffer.get());//cSystem.out.println("buffer.get() = " + (char) buffer.get());//d//恢复成上一次记录的position所指向的位置:2buffer.reset();System.out.println("buffer.get() = " + (char) buffer.get());//cSystem.out.println("buffer.get() = " + (char) buffer.get());//d}}public class TestNIO7 {public static void main(String[] args) {ByteBuffer buffer = ByteBuffer.allocate(10) ;buffer.put(new byte[]{'a','b','c','d'}) ;buffer.flip();System.out.println("(char)buffer.get() = " + (char) buffer.get());//a//虽然此时position指向1,但是由于调用的是get(0),所以输出的还是第一个数据值System.out.println("(char)buffer.get(0) = " + (char) buffer.get(0));//aSystem.out.println(buffer.position());//1}}4.5 字符串操作
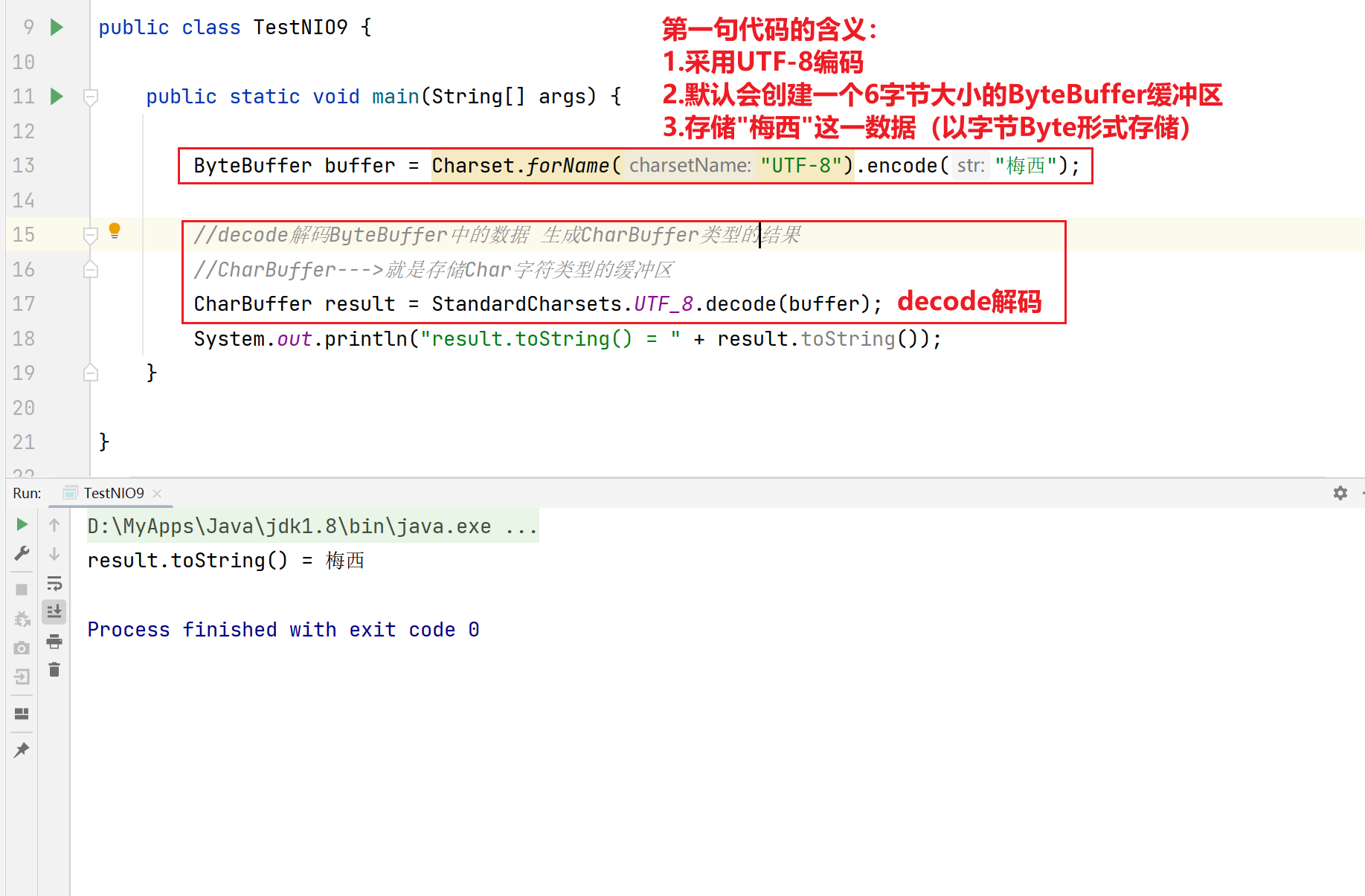
- 字符串存储到Buffer缓冲区中
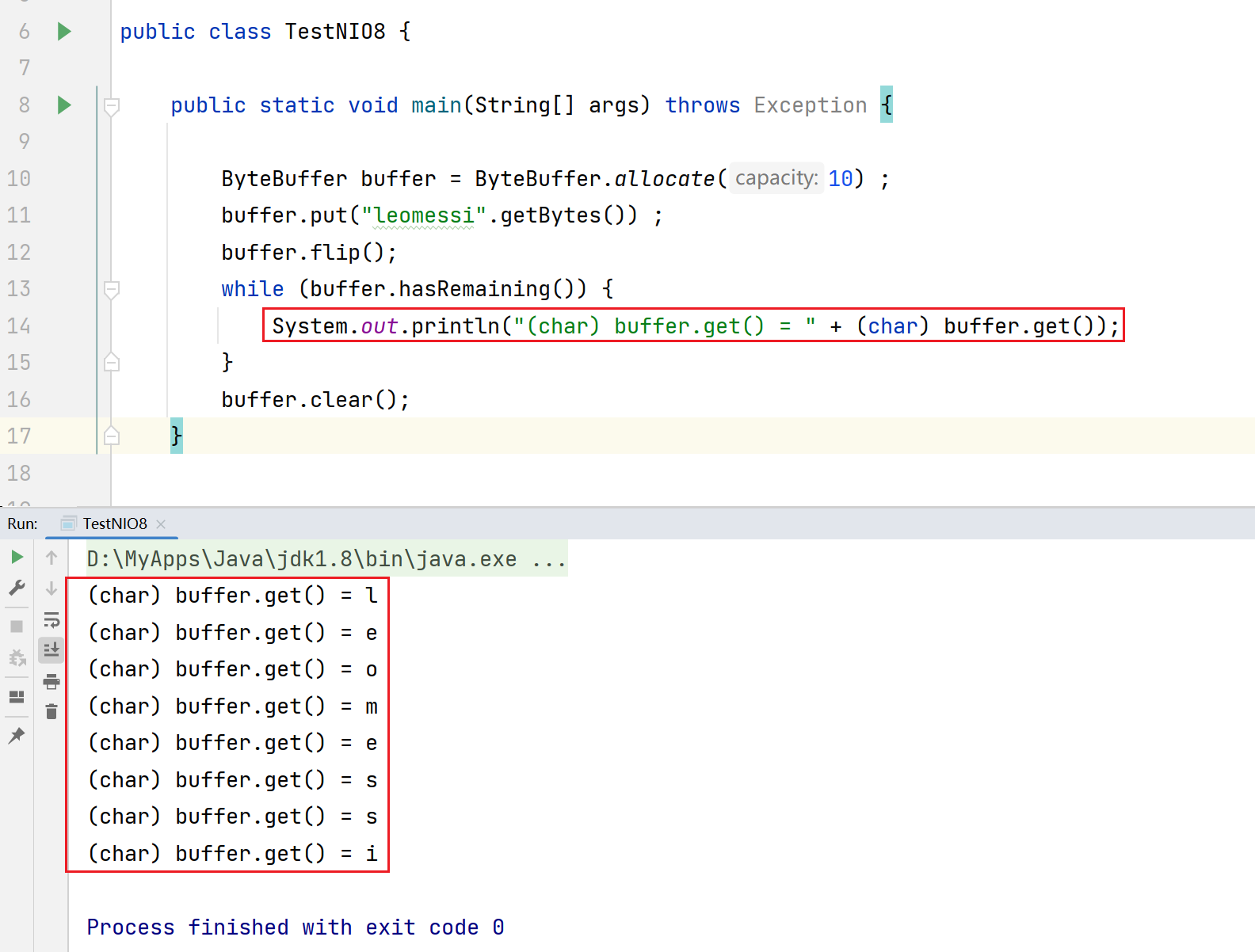
1.使用allocate方法创建ByteBuffer
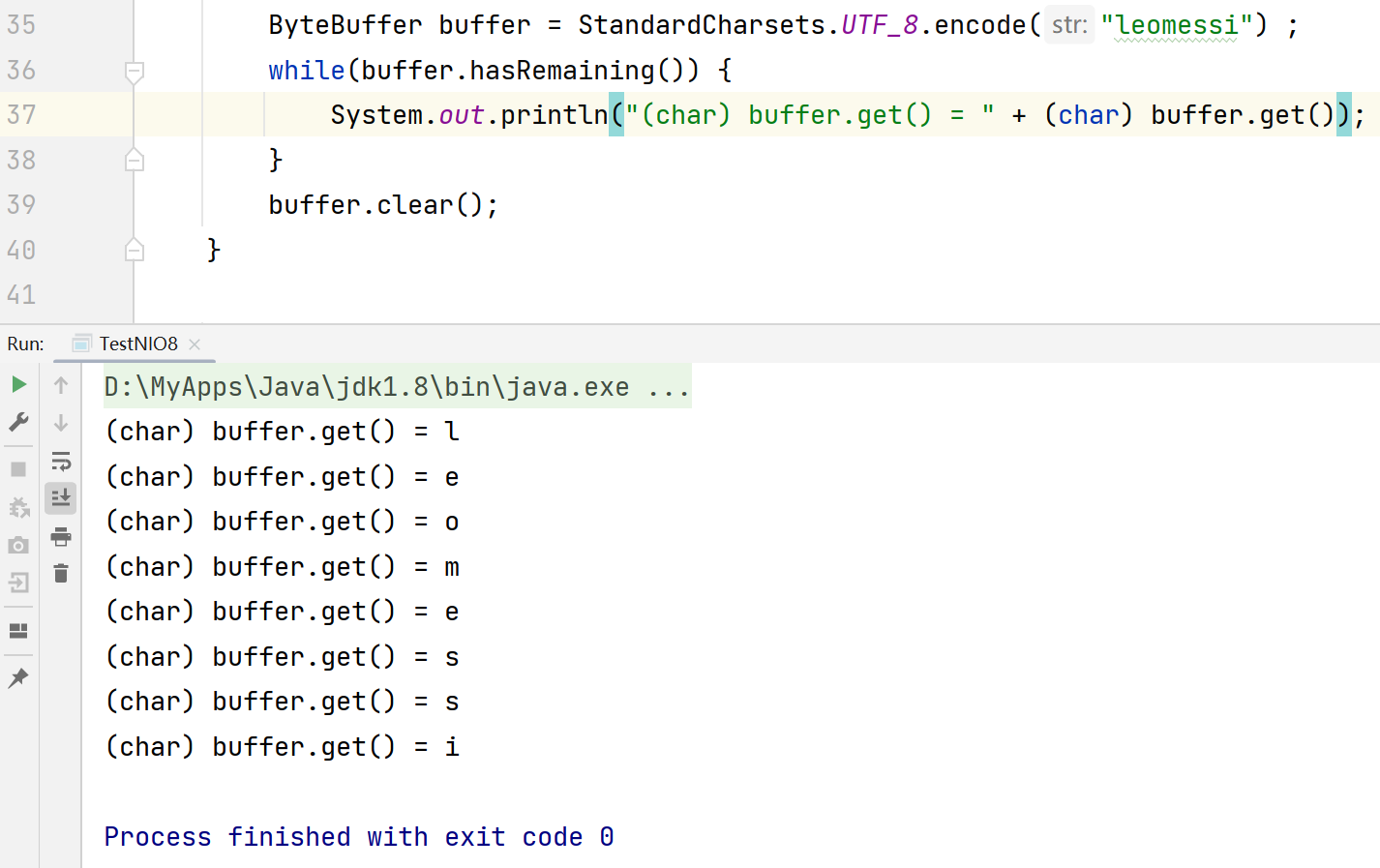
2.使用encode方法创建ByteBuffer缓冲区

flip方法源码:

3.使用新的方法创建ByteBuffer缓冲区
4.使用wrap方法创建ByteBuffer缓冲区
- Buffer缓冲区的数据转换成字符串
补充演示:
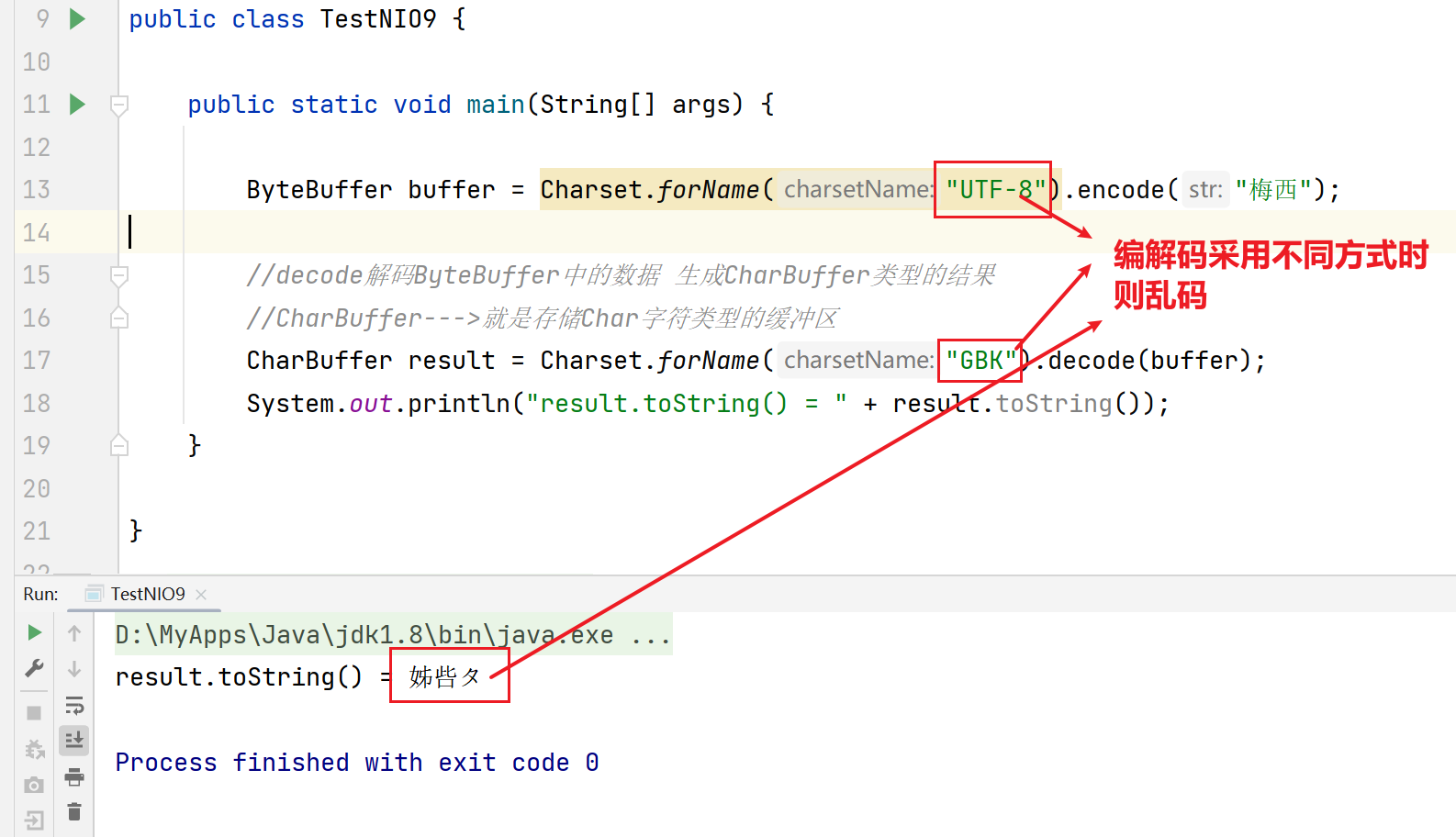
4.6 粘包与半包
粘包:下一句话不完整的粘到上一句话的后面,这就是粘包
半包:不完整的一句话就是半包
eg:
在客户端-服务端网络通信的过程中,客户端原本想要发送三句话给服务端:
1.Hi leomessi\n
2.I love you\n
3.Do you love me?\n
但是由于服务端开辟的ByteBuffer缓冲区大小问题,假设服务端ByteBuffer设为20个字节大小,那么最终服务端接收的时候:第一次ByteBuffer接收读取到的是:Hi leomessi\nI love y,第二次ByteBuffer接收读取到的是:ou\nDo you love me?\n。
服务端本来应该接收到的是完整无缺的三句话:
1.Hi leomessi\n
2.I love you\n
3.Do you love me?\n
结果现在造成割裂,其中第一次接收到的"I love y"就是粘包,第二次接收到的"ou\n"就是半包
补充:
又有新的疑惑了,既然由于ByteBuffer过小造成粘包,半包,那为什么不增大ByteBuffer的大小呢??当然是可以增大的,但是极限法思考一下,可以无限大吗?当然不行!ByteBuffer占用的是内存,无论是JVM进程的内存还是操作系统的内存都是有限的,所以一味的增大ByteBuffer的大小而保证一次可以接收读取客户端所有的数据,这一操作改善是不靠谱的!
所以后续我们需要引出其他解决方法,代码如下:
- 解决半包粘包
public class TestNIO10 {public static void main(String[] args) {//难点2:合理开辟ByteBuffer的大小,如果太小,可能i love y+追加的空间 可能造成Buffer缓冲区的溢出(后续Netty动态扩容会解决,这里手动设置)ByteBuffer buffer = ByteBuffer.allocate(50) ;//难点3:假设说put一行的数据中没有\n,那么就会不断的追加,不断的追加就很难控制ByteBuffer缓冲区的大小。// 那么该如何设置ByteBuffer的大小,同理难点2,后续Netty会自动调整容量大小buffer.put("Hello leomessi\ni love y".getBytes());doLineSplit(buffer);//i love you\nDo you like me?\nbuffer.put("ou\nDo you like me\n?".getBytes());doLineSplit(buffer);buffer.put("ceshi\n".getBytes());doLineSplit(buffer);}//ByteBuffer接收的数据 \nprivate static void doLineSplit(ByteBuffer buffer) {//写模式转换成读模式buffer.flip();for (int i = 0; i < buffer.limit(); i++) {if(buffer.get(i) == '\n') {//难点1:为什么要减去buffer.position()? 为了在当前buffer数据中存在多个\n,此时为了节省开辟的target空间大小int length = i+1-buffer.position();ByteBuffer target = ByteBuffer.allocate(length) ;for (int j = 0; j < length; j++) {target.put(buffer.get());}//写入工作完成,从写模式转换成读模式target.flip();System.out.println("StandardCharsets.UTF_8.decode(target).toString() = " + StandardCharsets.UTF_8.decode(target).toString());}}buffer.compact();}}- 上述代码未解决的问题
1.
代码依旧存在问题,当读取行数据没有\n,我们需要读取完第一行后接着继续读取第二行的数据,直到第3,4,5........第n行的数据。这个过程需要ByteBuffer缓冲区的大小不断扩容,使用NIO就很麻烦,后续Netty帮我们都做好了,并且Netty可以动态调整ByteBuffer缓冲区的大小
2.
ByteBuffer buffer = ByteBuffer.allocate(50),50这个值不可以设置的太小。
假如设为20,设为20后。
第一次读取Hi sunshuai\n,第一次读取后,未读取的l love y被移到前面,后面接着追加写入ou\nDo you like me\n? 但是ByteBuffer的空间(20)不够用了,所以会Buffer缓冲区溢出!