论文名称:One for All: Unified Workload Prediction for Dynamic Multi-tenant Edge Cloud Platforms
摘要
多租户边缘云平台中的工作负载预测对于高效的应用部署和资源供给至关重要。然而,在多租户边缘云平台中,异构的应用模式、可变的基础设施性能以及频繁的部署给准确和高效的工作负载预测带来了重大挑战。基于聚类的动态多租户边缘云平台建模方法往往因需要维护大量数据聚类和模型而产生过高的成本。现有的端到端时间序列预测方法在动态多租户边缘云平台中难以提供一致的预测性能。本文提出了一个具有全局池化和静态内容感知的端到端框架 DynEformer,为动态多租户边缘云平台提供了统一的工作负载预测方案。精心设计的全局池化和信息融合机制可以有效地识别和利用全局应用模式来驱动局部工作负载预测。静态内容感知机制的整合增强了模型在现实场景中的稳健性。通过对五个真实数据集进行的实验,DynEformer 在多租户边缘云平台动态场景中取得了最先进的成果,并为多租户边缘云平台提供了统一的端到端预测方案。
CCS 概念
• 网络 → 网络性能建模;• 应用计算 → 预测。
关键词
多租户边缘云平台;工作负载预测;Transformer;深度学习;多元时间序列
1 引言
随着云计算架构的发展,云服务的潜力得到了拓展。作为边缘云计算范例的一个实际实例,面向服务网络基础设施提供商、内容提供商(CPs)和网络用户的多租户边缘云平台(MT-ECP)展现出巨大的商业价值。MT-ECP 的核心优势在于整合网络中各种异构的空闲计算资源(如带宽、CPU、内存等)。MT-ECP 中的统一资源整合使得应用服务能够灵活部署,为用户提供低延迟、高可靠的边缘服务。正如图 1 所示,MT-ECP 的作用是在资源上部署应用/服务。彻底并最优地解决这一问题是一项具有挑战性的任务,需要一系列技术来实现对 MT-ECP 中应用性能的感知和可控性[6]。

作为应用性能感知的必要元素,了解工作负载的变化对于 MT-ECP 对解决资源规划和容量供给问题大有裨益[6]。通过准确感知这些性能指标,应用的部署和修复任务可以得到主动且有效地执行。
然而,由于异构的应用模式、不同的基础设施属性以及频繁的应用部署,与传统的云服务不同,MT-ECP 构成了一个动态系统。从马尔可夫模型[18]、移动平均[13]到神经网络[5]和复杂的混合模型[1, 11, 29],工作负载预测变得更加准确和高效。尽管这些模型能够在稳定、静态部署系统中有效地预测工作负载,但在动态系统(如 MT-ECP)中则显得力不从心。
本文聚焦于动态 MT-ECP 的工作负载预测。具体来说,我们总结了引起应用工作负载变化的 MT-ECP 系统动态特性,将其分为以下三种行为,并借助统一的预测框架预测任意行为下的工作负载。
行为1:应用在异构基础设施上运行:如图 2(a)所示,在 MT-ECP 中运行的应用的典型行为表现为周期性的工作负载波动,引导预测器构建。然而,MT-ECP 的异构环境使得问题异常复杂。挑战1:关键挑战源自应用中的异构性,包括不同的约束和用户需求模式,以及基础设施中的多样硬件配置和地理分布。这两个层面的异构性相互耦合,导致了各种各样的工作负载模式。
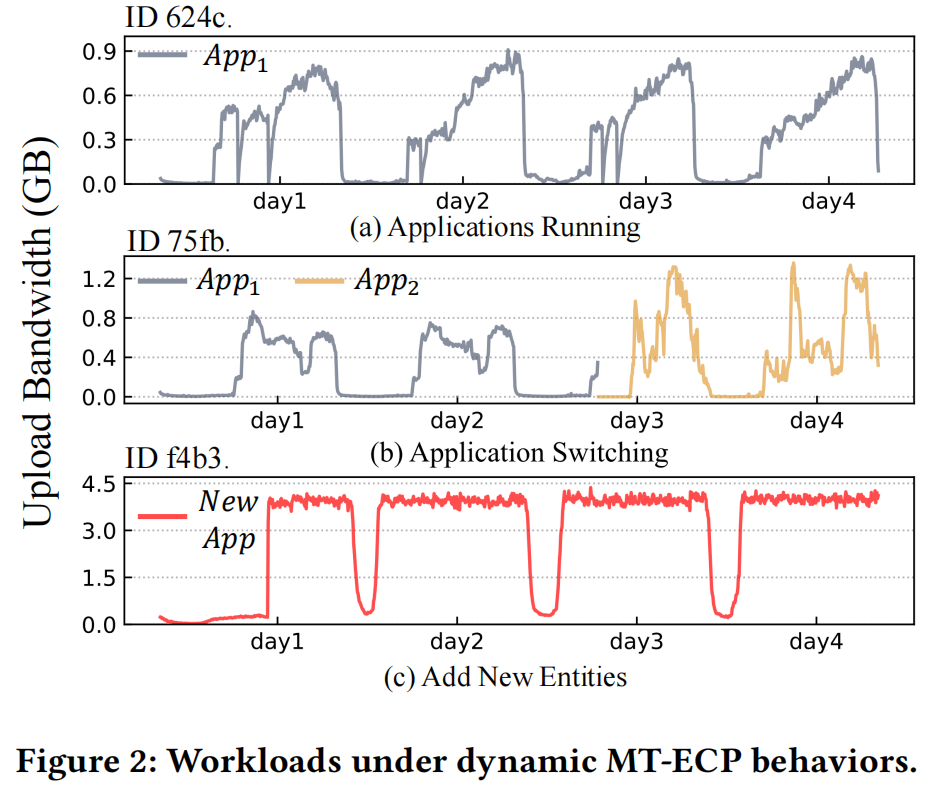
行为2:在边缘服务器上切换不同的应用程序:MT-ECP 经常通过自动调度切换应用,如图 2(b)所示,第三天,设备 75fb 的应用从 𝐴𝑝𝑝1 切换到 𝐴𝑝𝑝2。由于敏捷的部署技术,切换过程通常快速且不会造成中断。挑战2:新应用的工作负载可能与历史模式有所不同或冲突,如图 2(b)中从中午到晚上的日峰值转移。此外,新应用的工作负载数据有限,但对未来模式具有指示作用,这要求预测器能够概括地调整数据关注点。现有研究,如概念漂移的研究[17, 21, 27, 28],解决了动态情况下的模式变化。与之前的研究不同的是,前者会主动切换模型以适应概念漂移,而我们希望通过感知应用切换并以用户不可察觉的方式完成预测来赋能模型。
行为3:在 MT-ECP 中添加新实体:新应用程序或新基础设施对于 MT-ECP 来说是普遍存在的。它们暗示了独特的特征和少量历史数据。如图 2(c)所示,新应用程序的工作负载可能显示出以前从未出现的模式。挑战3:如何快速准确地在新实体上实现工作负载预测涉及模型的冷启动,对于预测器来说是一个挑战。
为了解决上述问题,我们提出了 DynEformer,一个用于动态多租户边缘云平台的准确且稳健的工作负载预测框架。DynEformer 的核心在于三个关键点:1. 通过全局池化识别应用的全局工作负载模式。2. 利用全局模式信息驱动动态应用行为下的局部工作负载预测。3. 通过静态内容感知提高模型在现实场景中的稳健性。
在多序列预测任务中,基于聚类的方法被认为是提高模型准确性的有效方式,因为它们有利于利用时间序列之间的相似性,即模式。然而,现有的作品将聚类应用于模型输入,即对原始输入进行聚类并为不同的数据类训练多个模型[27]。在多样化的多租户边缘云平台场景中,创建和同时维护多个模型是低效且成本高昂的。因此,我们设计了一种新颖的聚类替代范式。我们提出通过时间序列分解提取工作负载的季节部分,并通过新颖的全局池化方法识别全局模式。此外,我们设计了一种新的自适应信息合并机制,而不是创建多个模型,以利用模式的相似性/差异,适应内部模型权重以适应动态 MT-ECP 行为并驱动工作负载预测。
在 MT-ECP 中,像基础设施配置和位置等静态数据具有高语义。现有方法通常使用静态特征标记输入,但通过简单编码无法充分理解高语义数据,因此改进效果较小。为解决这一问题,我们设计了一种静态特征融合方法,使模型能够为当前时间特征选择最合适的静态特征,从而在动态 MT-ECP 行为中补充静态上下文。
为了捕获历史信息,我们采用基于 Transformer 的编码器-解码器结构来有效建模长期和短期序列。我们的主要贡献如下:
- 我们提出了一种新颖的全局池化方法和自适应信息合并架构,以整合全局应用模式到模型中,并驱动动态 MT-ECP 行为下的局部工作负载预测。该方法是一种有效的替代基于聚类的方法。
- 为了采用跨领域的静态特征,我们设计了一种新的静态特征融合方法,允许模型为当前时间特征选择最适合的静态特征。
- 我们提出了一种新颖的 DynEformer,这是一个基于全局池化和静态上下文感知的 Transformer 模型,用于动态 MT-ECP 的工作负载预测。DynEformer 在涵盖五个真实数据集的六个基准测试中取得了42%的相对改进。特别是在应用切换或添加新实体行为下,它实现了52%的改进。
2 相关工作
在本节中,我们回顾了关于工作量分析和预测以及基于编码器-解码器的预测器的先前方法。
工作量分析和预测。关于工作量的大量现有工作可分为分析建模和工作量预测两类。前者通常依赖于真实的大规模数据(例如Google [15, 16],Facebook [26]和Wikimedia [3])通过数学方法(例如线性回归[2]和隐马尔可夫模型[18])和传统的机器学习模型(例如k-means [9]和ARIMA [13])对工作量进行分类和描述,旨在解答应用优化、系统自管理和其他高层次问题。
工作量预测的实现更加复杂,因为工作量变化建模需要考虑应用程序、基础设施以及它们之间的交互特性[6]。Gao等人[7]和Yu等人[30]提出将工作负载聚类并构建每个聚类的独立预测器。后者还提出根据初始工作负载模式和静态特征来匹配新添加的工作负载的聚类。这些工作基于传统的聚类方法,如基于密度和基于距离的模型,其聚类结果在时间上不迭代,限制了模型的长期有效性。此外,这些工作也不能很好地解决概念漂移的问题。
Yang等人[27]将RNN集成到VaDE中,提出了一种新的工作负载聚类模型,并根据聚类结果动态分配预测模型,从而提高了模型的准确性,并可以部分解决概念漂移和未知模式的问题。Jayakumar等人[8]提出了一种通用的工作负载预测框架,该框架使用LSTM模型,并通过模型重训练自动优化其内部参数以实现高准确性。上述工作的主要贡献在于预测准备或模型构建机制,并没有设计统一的预测模型。它们仍然需要训练和维护多个预测器进行使用,增加了成本。
基于编码器-解码器的预测器。递归神经网络(RNN)一直是深度时间序列模型的主要方法,直到研究人员开始探索将Transformer的设计引入时间序列预测[25]。由于自注意力机制,基于Transformer的模型可以建模长期和短期时间序列。此外,编码器-解码器架构非常适合时间序列数据结构。
Wu等人[24]引入时间分解技术和自相关机制到Transformer中,以提高其效率和准确性。Lim等人[14]提出通过特征选择和循环层将现实场景中跨领域的多个特征(包括时间和静态特征)结合到基于自注意力编码器-解码器的架构中。
在真实的MT-ECP中,工作负载随着应用程序切换和新的应用程序/基础设施接入而变化。这些行为可能导致多种模式、概念漂移和冷启动等问题。针对理想化问题的模型效率和准确性优化的工作无法提供统一的解决方案,导致无法预测的故障,在真实的业务服务平台中是不可接受的。
3 符号和问题定义
工作负载预测的目标是预测未来的工作负载系列,可以定义为在一系列间隔下的带宽、CPU和其他硬件使用情况或作业到达率(JARs)。由于引入了日期等静态和可推断特征,该问题可以定义为多变量多系列预测问题。
在具有固定大小窗口的滚动预测设置下,将不同应用程序在基础设施上的多个工作负载系列作为历史输入进行处理:
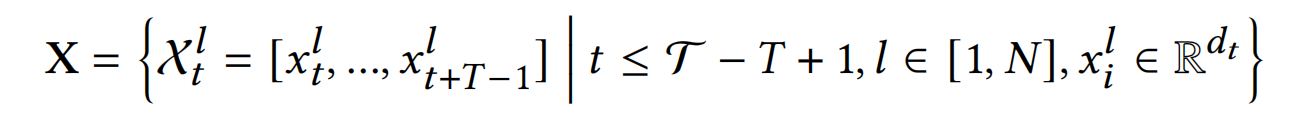
其中![]() 是历史中可观察到的最后时间索引,𝑁是工作负载系列的数量,𝑑𝑡是动态特征维度(𝑑𝑡 > 1)。静态特征由
是历史中可观察到的最后时间索引,𝑁是工作负载系列的数量,𝑑𝑡是动态特征维度(𝑑𝑡 > 1)。静态特征由![]()
![]() 表示,对于一组特定的输入,预测过程可以表达为:
表示,对于一组特定的输入,预测过程可以表达为:
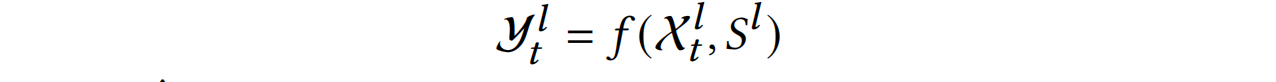
其中![]() 是预测的工作负载系列,𝐿是预测长度,𝑓是预测模型。
是预测的工作负载系列,𝐿是预测长度,𝑓是预测模型。
4 方法
在本节中,我们介绍全局池化方法和DynEformer的架构。正如前面所述,全局池化用于识别应用程序的全局工作负载模式。与之前基于聚类的预测方法不同,我们不会为不同的聚类训练多个模型,而是将它们用作本地工作负载预测的全局模式补充。
为此,我们设计了全局汇集合并层(GP层),并将其实现为模型的编码层的伴随块,以迭代地融入全局模式信息并驱动本地工作负载预测。为了进一步增强模型对动态行为的适应性,我们重复使用全局池来补充额外的数据,并设计了一种同步填充机制,使模型能够提前读取更改后的工作负载数据。
除了上述设计之外,还将静态上下文感知层(SA层)进一步纳入DynEformer中,以增强其对动态MT-ECP行为的预测鲁棒性。
4.1 全局池化
4.1.1 时间序列分解。
在构建全局池之前,需要先发现大量多模式工作负载数据的关键组成部分,因为模型已经学习了原始数据。我们引入传统时间建模的分解技术,以揭示MT-ECP工作负载中的有价值信息。具体而言,我们应用季节性和趋势分解(Seasonal and Trend decomposition using Loess,STL)将工作负载序列划分为更细粒度的组件。鉴于工作负载的周期性,分解过程可以表示如下:
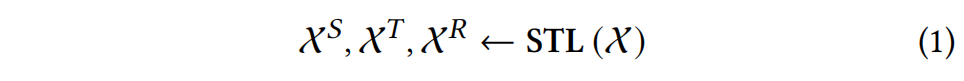
其中X是工作负载序列,X𝑆、X𝑇、X𝑅分别表示X的季节性分量、趋势分量和残差分量。 由于低信息量,我们不考虑残差分量![]() 。对于其他分量,我们区分MT-ECP工作负载中趋势分量
。对于其他分量,我们区分MT-ECP工作负载中趋势分量![]() 为高度随机的情况,模式信息较低。长期来看,所有工作负载只有三类:平滑、增加或减少,但在短期内,它们有大量的随机变化,使得难以分类。对于季节性分量
为高度随机的情况,模式信息较低。长期来看,所有工作负载只有三类:平滑、增加或减少,但在短期内,它们有大量的随机变化,使得难以分类。对于季节性分量![]() ,我们发现应用类型主要反映了它。季节性分量具有明显的特征,可以在设置每日周期时进行有效分类。因此,我们提取工作负载的季节性分量作为构建全局池的源。
,我们发现应用类型主要反映了它。季节性分量具有明显的特征,可以在设置每日周期时进行有效分类。因此,我们提取工作负载的季节性分量作为构建全局池的源。
4.1.2 VaDE聚类。
在构建全局池时,我们对工作负载的季节性分量进行聚类(但不根据聚类结果构建多个模型)。为了实现这一点,我们使用VaDE [10],这是一种与传统基于距离或密度的聚类方法不同的聚类方法,它由编码器、解码器和高斯混合模型(GMM)组成。在将季节性分量输入到VaDE之前,我们使用窗口大小为𝑇2进行相同的滑动窗口处理。VaDE的详细信息如下所示:

其中编码器和解码器是由几个不同的全连接(fc)层组成的块,𝑍𝑡 是工作负载序列的编码向量,𝐶是聚类结果。GMM假设由潜在变量𝐶决定的𝑍𝑡服从高斯混合生成,并可以推断𝐶的概率。 VaDE有两个优点:1. 在聚类中,更长的时间序列意味着更高的特征维度。VaDE可以更好地处理高维数据并捕捉特征之间的相关性。2. 当新数据到达时,VaDE可以在不重新训练的情况下基于预训练模型更新参数,这可以更好地支持长时间的模型更新。
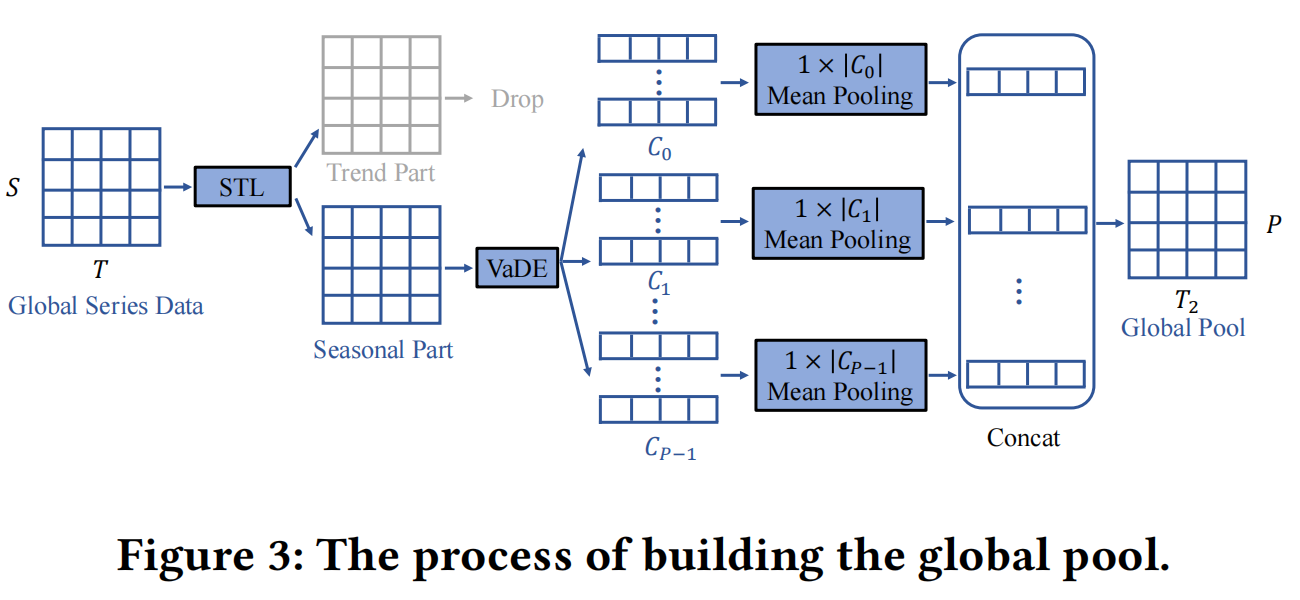
4.1.3 构建全局池。
全局池构建的整个过程如图3所示。为了选择最佳的聚类数𝑃,我们通过经验推断贝叶斯信息准则(BIC)并选择使得模型的BIC低于其他情况的𝑃。在VaDE输出每个序列的类别后,我们对每个类别中的所有序列进行平均汇集,将它们压缩为一个代表性序列,然后将所有类别的代表性序列串联起来形成全局池,如下所示: 请注意,全局池完全基于训练(历史)数据构建,在实验中,任何测试(未来)数据中的工作负载都不会被全局池看到。
4.2 DynEformer
在本节中,我们介绍DynEformer。DynEformer的概述如图4所示,包括编码器和解码器两个主要部分。DynEformer的输入包括编码器输入、解码器输入、静态内容和全局池,并且预测的工作负载在框架处理结束时输出。DynEformer是一个完整的端到端框架,可为MT-ECP的所有动态行为提供统一的工作负载预测。
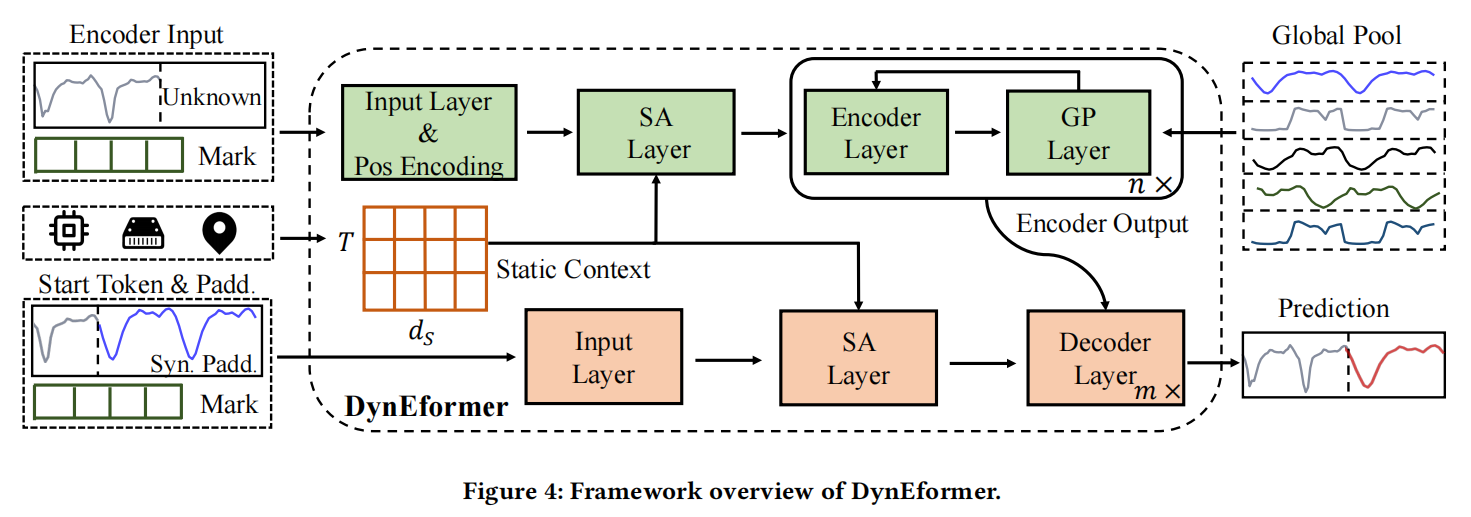
4.2.1 编码器。
DynEformer的编码器由三个组件组成:输入和位置编码层、静态上下文感知层(SA层)和一系列𝑛个相同GP-编码器块。
输入和位置编码层:输入和位置编码层遵循原始Transformer架构[22]。输入层通过全连接网络将过去的工作负载序列映射到维度为![]() 的向量,这一步对于多头注意力机制非常重要。通过正弦和余弦函数进行位置编码,通过输入向量与位置编码向量逐元素相加来编码顺序信息。
的向量,这一步对于多头注意力机制非常重要。通过正弦和余弦函数进行位置编码,通过输入向量与位置编码向量逐元素相加来编码顺序信息。
SA层:SA层用于将静态上下文与变化的工作负载序列数据结合起来。我们引入了从MT-ECP中记录的跨领域数据(例如基础设施的最大带宽、内存、硬盘和地理位置)作为额外的静态内容。为了学习这些高语义数据,我们设计了静态上下文感知层(SA层),它使用交叉注意力根据当前序列嵌入选择最有效的静态内容进行集成。SA层的输入包含通过输入层传递的工作负载嵌入V𝑡和静态上下文矩阵S,其输出维度与V𝑡相同,但包含有关静态内容编码的额外信息。SA层的详细信息如下所示:
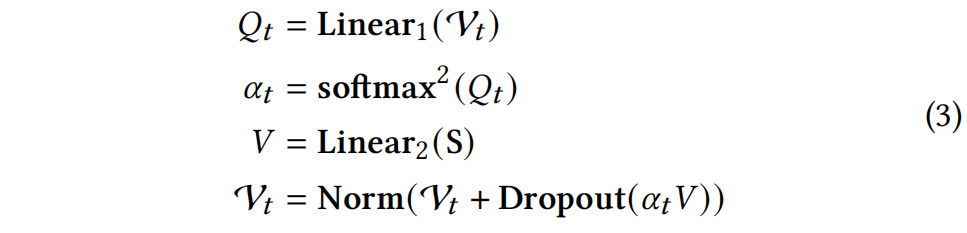
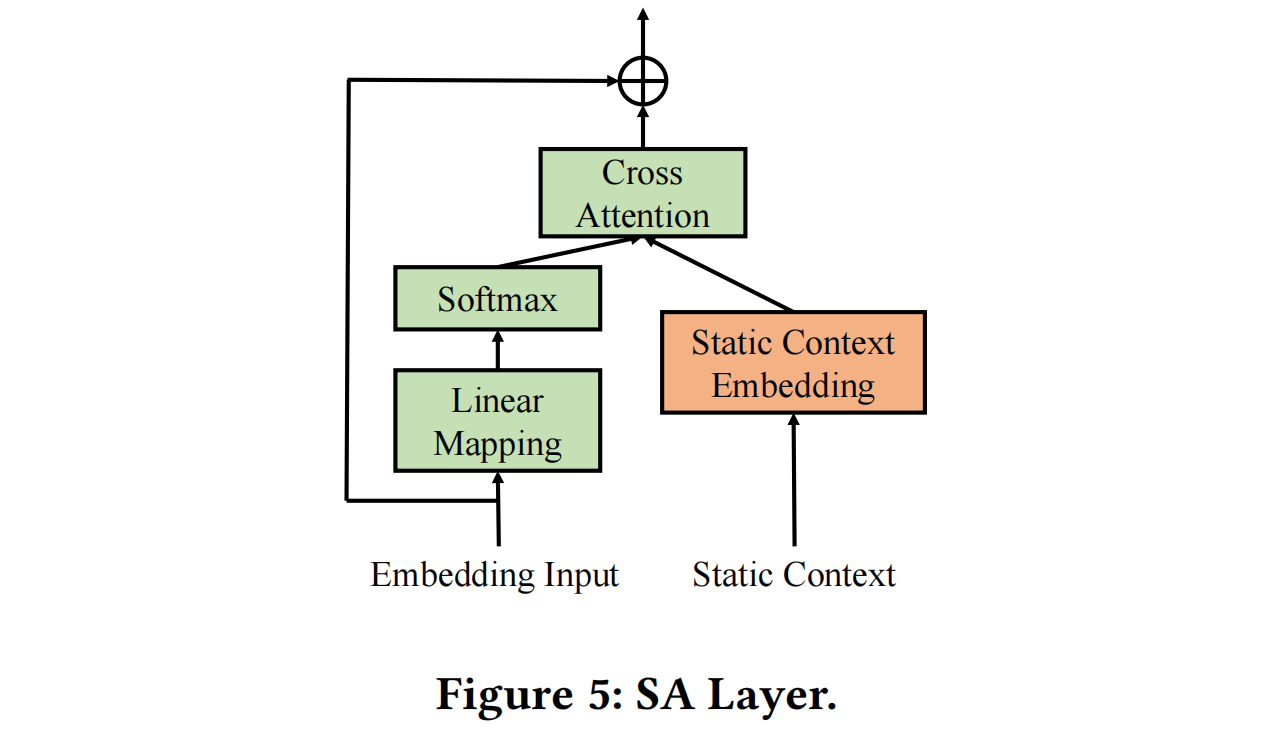
其中softmax2表示对𝑄𝑡的第二个维度进行softmax运算,即为每个系列样本的每个时间点计算权重。与将静态内容作为标记连接到输入中的传统方法不同,提出的SA层充当一个过滤器,学习最有效的静态内容。同时,SA层可以帮助学习类似的基础设施属性,这种对静态内容的感知有助于解决动态MT-ECP中的概念漂移和冷启动问题。
GP-编码器块:GP-编码器块专注于通过合并全局模式信息驱动局部工作负载预测。每个GP-编码器块由具有完全注意机制的常规编码器层和连接编码器层的输入和输出的新型GP层组成,同时不断捕捉来自全局池中最相关的全局应用程序模式。假设有𝑛个编码器块,则第𝑖个GP-编码器块的计算如下所示:

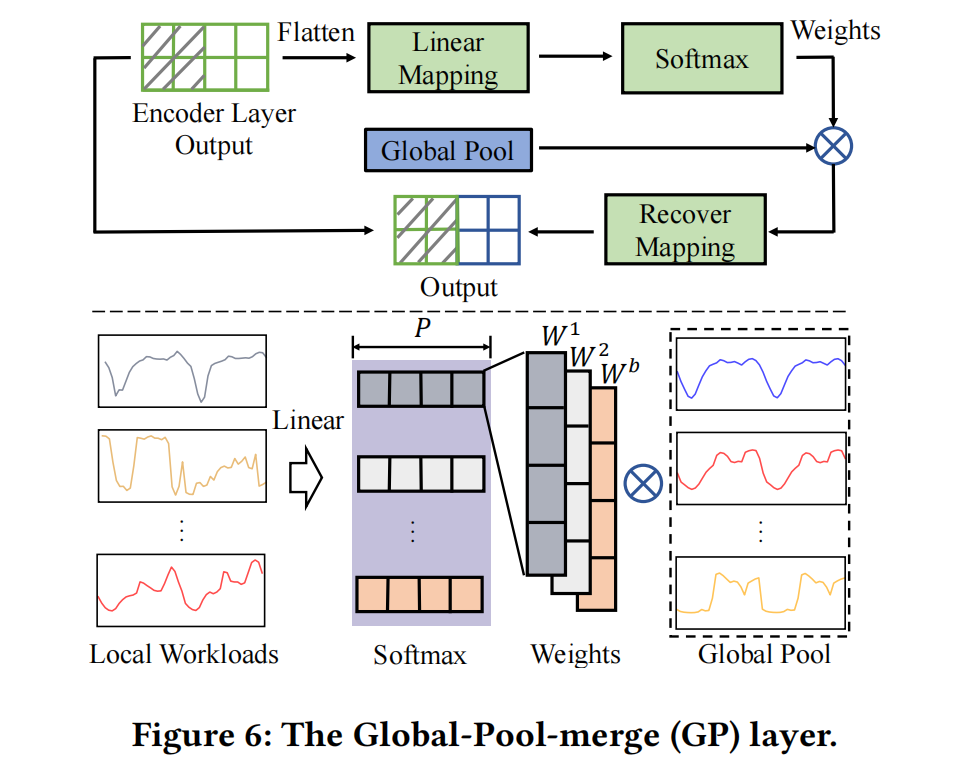
在 𝑖 = 1 时,![]() 是 SA 层的输出。GP 层 接收编码器层的输出和 §4.1 中创建的全局池作为输入,第 i 个 GP 层可以形式化如下:
是 SA 层的输出。GP 层 接收编码器层的输出和 §4.1 中创建的全局池作为输入,第 i 个 GP 层可以形式化如下:
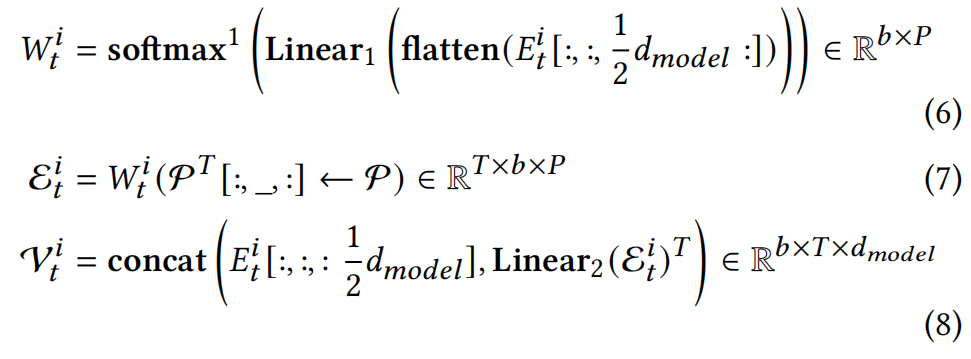
其中 ![]() 表示
表示 ![]() 的最后 1⁄2 特征维度, 𝑏 是批量大小。GP 层使用这部分特征来获取融合权重
的最后 1⁄2 特征维度, 𝑏 是批量大小。GP 层使用这部分特征来获取融合权重 ![]() 并提取全局模式信息, 而剩余的特征将保留时间特征。flatten 操作作用于
并提取全局模式信息, 而剩余的特征将保留时间特征。flatten 操作作用于 ![]() 的最后两个维度, 结果维度为
的最后两个维度, 结果维度为 ![]() ,softmax1 表示 softmax 在第一个维度上, 即为每个序列样本计算权重,
,softmax1 表示 softmax 在第一个维度上, 即为每个序列样本计算权重,![]() 表示维度提升,之后
表示维度提升,之后 ![]() 的维度从 𝑇 × 𝑃 变为 𝑇 × 1 × 𝑃。 GP-encoder 块能显著增强编码器学习全局模式信息的能力。它取代了传统的聚类框架, 使 DynEformer 能够感知全局和局部模式之间的相似性和差异, 以适应动态 MT-ECP 行为而无需训练多个模型。
的维度从 𝑇 × 𝑃 变为 𝑇 × 1 × 𝑃。 GP-encoder 块能显著增强编码器学习全局模式信息的能力。它取代了传统的聚类框架, 使 DynEformer 能够感知全局和局部模式之间的相似性和差异, 以适应动态 MT-ECP 行为而无需训练多个模型。
4.2.2解码器。
如图 4 所示,解码器专注于未来工作负载系列的生成。 它由三个组件组成:输入层、SA 层(如 § 4.2.1 所述)和一堆 𝑚 个解码器层。根据从编码器中得到的潜变量 ![]() 和解码器输入
和解码器输入 ![]() , 解码器可以被形式化如下:
, 解码器可以被形式化如下:

具有同步填充的输入:解码器的输入![]() 如下:
如下:
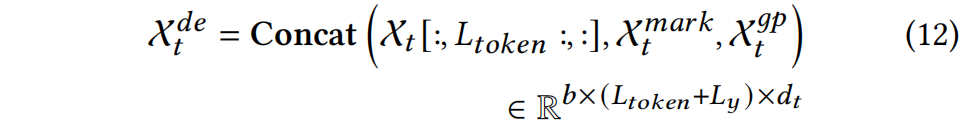
其中 ![]() 是起始令牌 [31],
是起始令牌 [31], ![]() ∈
∈ ![]() 是系列标记,例如日期,而
是系列标记,例如日期,而 ![]() ∈
∈ ![]() 是同步填充。 由于全局信息已并入编码器输出
是同步填充。 由于全局信息已并入编码器输出 ![]() ,将
,将 ![]() 填充相应的填充可以有效地改善解码器在编码器-解码器注意阶段的信息捕获。 同步填充的细节如下:
填充相应的填充可以有效地改善解码器在编码器-解码器注意阶段的信息捕获。 同步填充的细节如下:
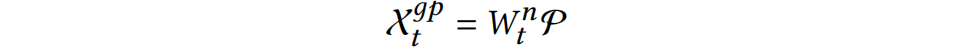
![]() 是 §4.2.1 中的全局池融合权重。
是 §4.2.1 中的全局池融合权重。
4.3 训练过程和损失函数
我们通过预先构建 VaDE 的方式提前生成全局池,并在 DynEformer 的训练之前完成全局池的构建。VaDE 的设计遵循自动编码器机制, 通过无监督学习训练模型,即通过计算![]() 和
和 ![]() 之间的损失来校正编码器和解码器的参数以进行梯度反向传播。 当我们获得全局池后,它将作为 DynEformer 的固定输入。除了输入层和编码器、解码器中的多头注意力机制的参数, SA 层和 GP 层在训练过程中也会更新其最优参数。VaDE 和 DynEformer 都使用均方误差(MSE)损失函数。
之间的损失来校正编码器和解码器的参数以进行梯度反向传播。 当我们获得全局池后,它将作为 DynEformer 的固定输入。除了输入层和编码器、解码器中的多头注意力机制的参数, SA 层和 GP 层在训练过程中也会更新其最优参数。VaDE 和 DynEformer 都使用均方误差(MSE)损失函数。
5 实验
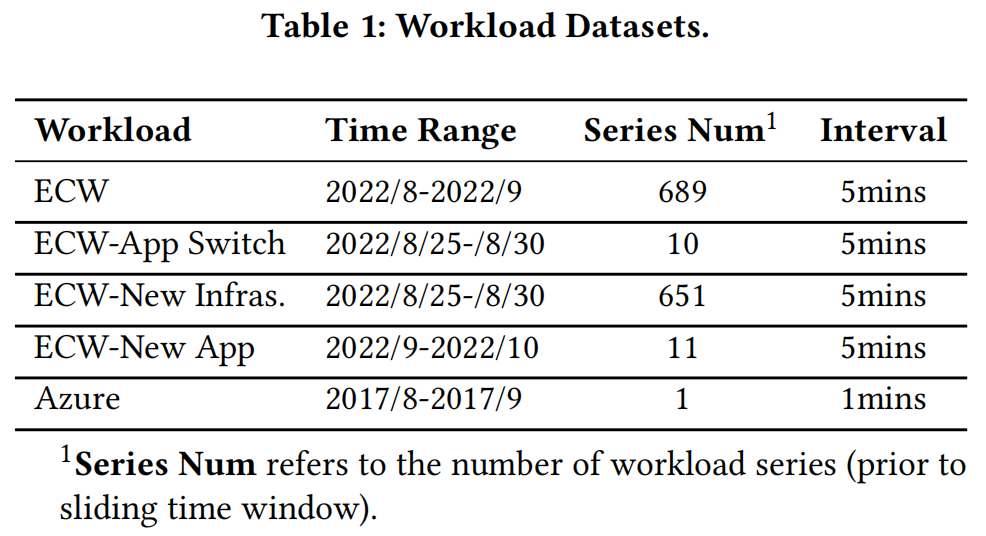
数据集。为了全面评估MT-ECP工作负载预测方案的有效性,我们从商业众包边缘云中收集Edge Cloud上传带宽工作负载数据(ECW),该基础架构包括通过自建、招募和用户租赁的异构设备。该平台分布在全国各地,服务于40多个典型应用程序,其中5174个设备。图2中显示的样本工作负载实际上是在平台上部署的。
为了验证DynEformer在应用程序切换或新实体添加到MT-ECP时的性能,我们提供了一些独特的案例数据,包括(1)ECW-App Switch,即在ECW测试期间发生应用程序切换的工作负载系列;(2)ECW-New Infras.,即运行在从未出现在ECW中的基础设施上的工作负载系列;(3)ECW-New App,即从未在ECW中出现的应用程序的工作负载系列。
除了时间工作负载数据外,ECW还提供了14个静态内容数据维度,例如最大带宽、CPU数量、位置和其他基础架构属性。由于所有工作负载预测任务都无法获取静态内容数据,因此我们提供了DynEformer在这些任务上有效性的评估。我们使用Azure 2[4]公共云工作负载(使用JARs)数据集来验证该方案的泛化能力。详细的数据集信息如表1所示。
尽管Azure是公共云服务数据集,但它仍然包含一些常见的MT-ECP特征和挑战,例如不同的应用负载模式和波动[1]。通过使用这个数据集,我们展示了DynEformer不仅能够处理MT-ECP中的独特挑战,而且在其他类似的时间序列预测任务中也表现出有效性。
5.1 实施细节
所有ECW数据集中的工作负载系列都按小时分区,并且每小时取最大值以匹配MT-ECP中的应用程序调度和计费规则的时间粒度。Azure中的系列按5分钟求和以减少0值。两个数据集的输入工作负载系列长度𝑇= 48,预测长度𝐿= 24。我们按照6:2:2的比率将ECW和Azure分成训练、验证和测试集,并在其他ECW数据集上测试DynEformer。
STL的分解周期设置为24。第4.1.2节中的数据滑动窗口大小𝑇2设置为𝑇2 = 𝑇。DynEformer使用ADAM [12]优化器进行训练,初始学习率为。批量大小设置为256,起始标记长度𝐿𝑡𝑜𝑘𝑒𝑛设置为12。所有实验均重复三次,使用PyTorch [19]实现,并在两台NVIDIA GeForce RTX 3090 GPU机器上进行。DynEformer包含2个GP-encoder块和1个解码器层。
评估指标和基线。我们使用两个评估指标,包括![]() 和
和![]() 。我们选择六种时间序列预测方法进行比较,包括三种最新的基于Transformer的模型:Deep Transformer[25]、Informer[31]和Autoformer[24];两种基于RNN的模型:MQRNN [23]和DeepAR [20];以及一种基于聚类的模型:VaRDE-LSTM [27]。这些模型被普遍用于解决大多数经典的时间序列预测问题,并且在类似的功率和流量工作负载预测任务中表现良好。为了公平起见,当基线在ECW数据集上实施时,静态内容数据被输入为标记。
。我们选择六种时间序列预测方法进行比较,包括三种最新的基于Transformer的模型:Deep Transformer[25]、Informer[31]和Autoformer[24];两种基于RNN的模型:MQRNN [23]和DeepAR [20];以及一种基于聚类的模型:VaRDE-LSTM [27]。这些模型被普遍用于解决大多数经典的时间序列预测问题,并且在类似的功率和流量工作负载预测任务中表现良好。为了公平起见,当基线在ECW数据集上实施时,静态内容数据被输入为标记。
考虑到模型训练成本,我们识别了五个数据类,并在两个数据集上对VaRDE-LSTM(VaRDE-L)进行了五个单独预测器的培训(相对于其他模型,它产生了3.5倍的训练时间)。
5.2 全局池
为了确定最优的全局池大小𝑃,我们获得了VaDE模型的BIC,针对不同的𝑃,并根据验证集给出了DynEformer不同大小的全局池的性能提升百分比。结果如图7所示。
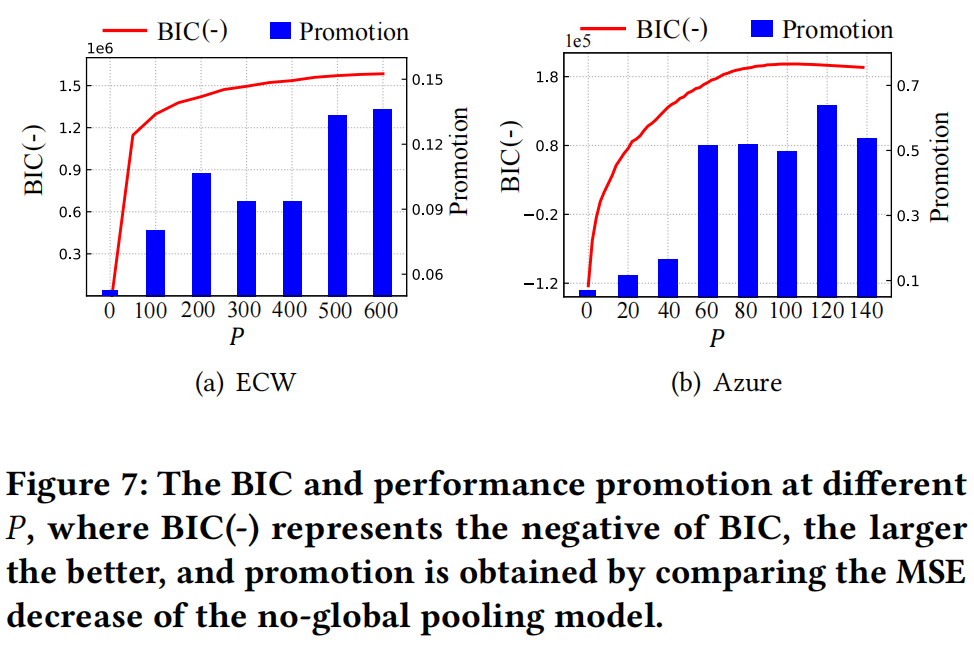
同𝑃下的BIC和性能提升,其中BIC(-)表示负的BIC,值越大越好,通过比较没有全局池模型的MSE减少来获得提升。
如图7所示,VaDE聚类结果的BIC随着𝑃的增加而减小,而DynEformer中全局池的性能提升呈增长趋势。在ECW上,当𝑃从0增加到400时,BIC显著减小并在𝑃 = 400之后趋于稳定,而性能提升在𝑃 = 200和𝑃 = 500处有两个突变,表明全局池在这些设置中充分提取了全局应用模式。因此,我们将DynEformer在ECW上的全局池设置为𝑃 = 500。同样,Azure上的全局池设置为𝑃 = 120。总之,选择具有最大BIC(-)的𝑃使得与MSE提升类似的性能。在现实世界的场景中,我们依靠BIC(通过VaDE聚类获得)来选择最佳𝑃,避免暴露未来的先验信息。
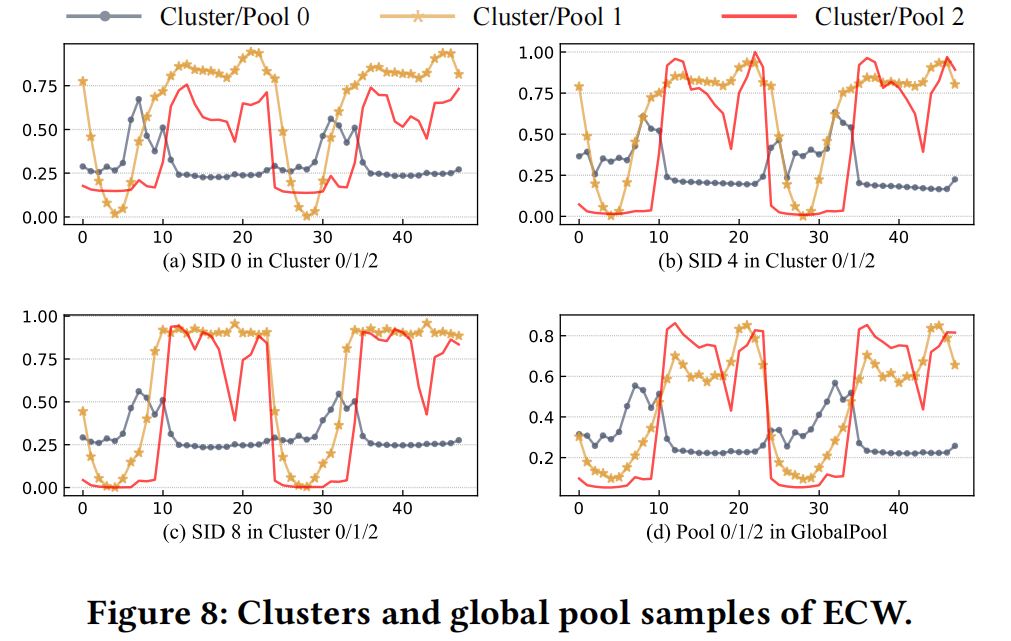
图8显示了ECW工作负载的季节性组件的VaDE聚类和全局池结果。图8(a)、(b)和(c)分别是聚类0、1、2中的不同工作负载序列样本,图8(d)是全局池中对应的第0、1和2个池。 如图8(a)-(c)所示,同一聚类中的序列具有相似的模式,与图8(d)中对应池的模式一致。结果表明,VaDE有效地聚合了全局应用程序的工作负载模式,从而捕捉到相同应用类型的工作负载相似性。
5.3 边缘云负载预测
总体评估。从表2可以看出:(1)DynEformer在两个工作负载数据集的所有基准测试中均取得了持续的最先进性能。特别是,与基于Transformer的模型家族相比,DynEformer在ECW和Azure上的MSE平均降低了12%和83%。DynEformer在MSE上优于MQRNN和DeepAR,分别降低了18%、95%(在ECW中)、97%和99%(在Azure中)。与基于聚类的模型相比,DynEformer在MSE上降低了55%(0.150→0.067,在ECW中)和94%(1.124→0.069,在Azure中)。
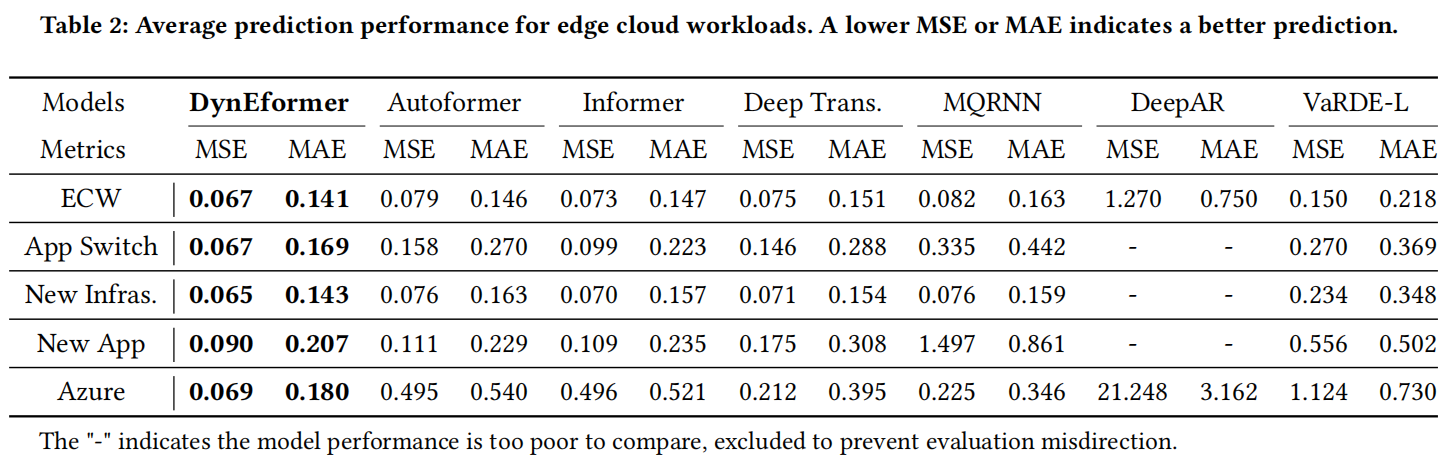
边缘云工作负载的平均预测性能。较低的MSE或MAE表明有更好的预测。
(2)Transformer系列的性能不保证优于基于RNN的模型。事实上,从表2可以看出,MQRNN在Azure上优于Autoformer和Informer。这表明在短期工作负载预测场景中,为自注意机制进行的各种优化可能不会比具有长网络路径的RNN模型产生更好的结果。然而,DynEformer仍然优于MQRNN和Deep Transformer,这反映了DynEformer无与伦比的预测能力。
对应用切换的鲁棒性(概念漂移)来说,如表2所示,所有基线模型的性能在从ECW中选择的应用切换数据上显著下降(Autoformer、Informer、Deep Trans.、MQRNN和VaRDE-L的MSE分别增加了100%、36%、95%、309%和80%)。其中,我们的方法显示出最低的误差,令人印象深刻的是,DynEformer在MSE指标上保持了一致的性能,而MAE增加了20%。结果表明,该方法可以在应用切换下稳健地进行预测。
如图10(b)所示,第二天发生的应用切换导致工作负载分布出现突变,即突变式的概念漂移。然而,即使只有四分之一的有效后切输入,DynEformer仍然能够捕捉到正确的工作负载模式,并减少了前切工作负载模式和幅度的影响。这得益于DynEformer对全局模式信息的有效捕获,使其能够准确检测到本地工作负载与常规全局模式之间的细微差异。由于这些过程在模型权重内隐蔽地发生,用户无需担心更新和切换模型的额外成本。

对未知实体的鲁棒性(冷启动)。DynEformer对未知实体具有鲁棒性,具有较高的可扩展性。我们通过ECW-New Infras.和ECW-New App对DynEformer进行了未知应用程序和基础设施数据的评估。从表2可以看出,对于这两个面向未知实体的数据,DynEformer优于所有基线模型。在ECW-New Infras.方面,DynEformer平均减少了10%的MSE,优于transformers系列,并且相较于MQRNN和VaRDE-L分别减少了15%和72%的MSE。此外,在更具挑战性的ECW-New App上,MSE下降进一步提高到32%、94%和84%。
如图10(c)和图10(d)所示,与其他方法相比,通过DynEformer模型预测结果可能没有引起任何不协调的感觉。这一结果表明,所提出的框架可以在训练中未见到的数据分布上进行最佳预测,而无需额外的学习。因此,当添加新的基础设施和应用程序时,该框架具有可扩展性。
5.4 DynEformer的工作原理:消融研究和模型分析
在本节中,我们进行消融研究以说明不同组件的作用。如表3所示,DynEformer中的每个组件和机制都提高了模型在动态MT-ECP行为下的预测性能。全局池通过DynEformer(-GP)相比,使模型的综合改进率提高了12%,这表明全局池有效地解决了动态MT-ECP行为引起的复杂模式、概念漂移和冷启动问题,并提高了Transformer在实际预测中的适用性。
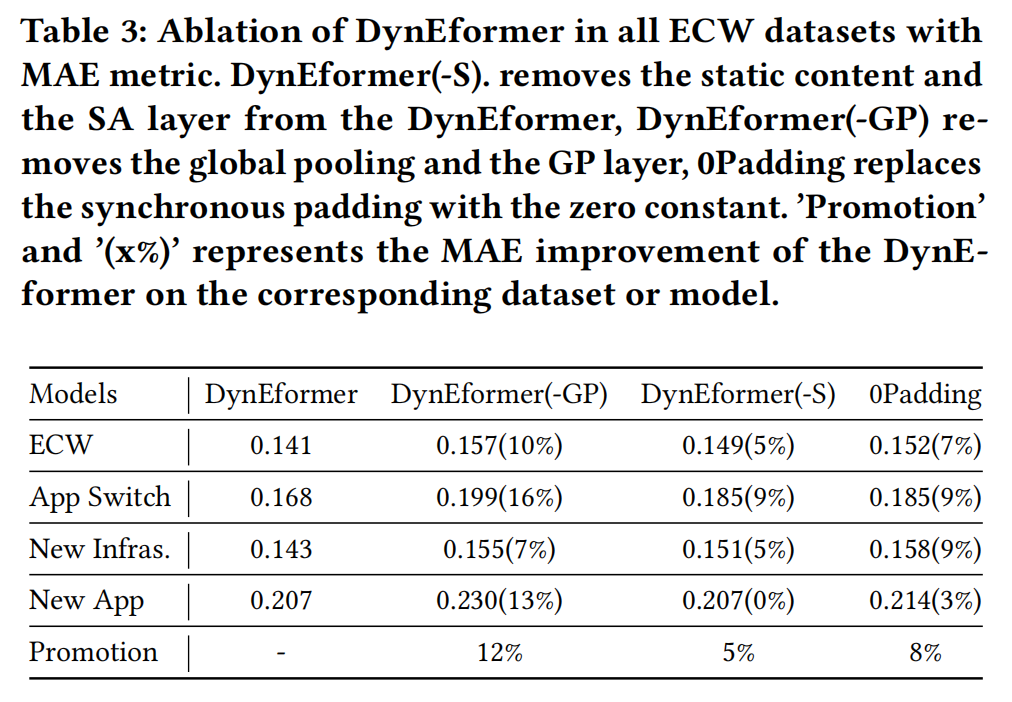
在所有ECW数据集上使用MAE指标测试DynEformer的不同版本的实验结果如下。DynEformer(-S)去除了DynEformer中的静态内容和SA层,DynEformer(-GP)去除了全局池和GP层,0Padding将同步填充替换为零常数。'Promotion'和'(x%)'表示DynEformer在对应数据集或模型上的MAE改进程度。
SA层在应用切换和新增基础设施的MT-ECP行为中发挥着重要作用,分别为模型的改进带来了9%和5%,这表明DynEformer有效利用静态基础设施属性来应对工作负载预测中的动态不稳定性。
此外,0Padding模型在所有情况下表现不及DynEformer,尽管它仍然保留了GP层和SA层。当同步padding被禁用时,全局池的效果减弱,因为添加的全局信息与0 padding不匹配,会误导附加的编码器-解码器注意力。
图9展示了GP层的工作效果。通过GP层,本地工作负载可以与最相关的全局应用模式相联系。例如,应用切换工作负载(工作负载555)通过GP层与应用切换前的全局池(PID 237)和应用切换后的全局池(PID 14和340)相联系。此外,GP层成功地将注意力集中在PID 340的全局模式上,权重为0.28,对PID 237的关注较少,权重为0.01。因此,DynEformer可以防止被落后的本地模式误导,并及时将注意力转移到新模式上。

在GP编码器中展示了全局池合并机制的一个例子。与为每个聚类创建单独的模型不同,GP层可以为每个本地工作负载选择最合适的全局池。最佳观看方式为彩色显示。
在另一个实例中,GP层成功地通过叠加两个现有的全局池(PID 8和PID 105)来识别新的工作负载模式(工作负载2700)。结果表明,我们提出的模型可以有效地合并全局工作负载模式,用于本地工作负载预测,并减轻应用切换和添加新实体时所带来的复杂模式的干扰。
5.5 MT-ECP中的使用案例
我们将在ECW的测试期间(08/25-08/30),以应用贬值率作为衡量标准,比较表现最佳的基准模型(Informer)和DynEformer,并按照从大到小的顺序对它们进行排名。
应用贬值率是评估MT-ECP中应用收入的重要指标。应用贬值来源于应用提供者和设备提供者之间计费时间的差异,即计费应用工作负载少于运行该应用的所有设备的计费工作负载之和,导致该应用的收入工作负载少于支出工作负载。应用𝑎的贬值率![]() 可以形式化表示如下:
可以形式化表示如下:
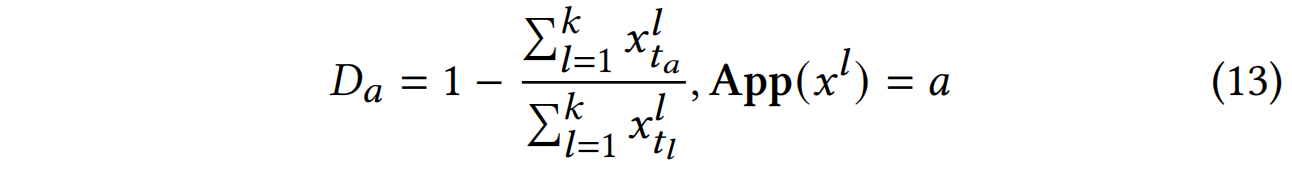
其中,![]() 是应用计费时间𝑡𝑎处的工作负载,
是应用计费时间𝑡𝑎处的工作负载,![]() 是不同设备计费时间𝑡𝑙处的工作负载。
是不同设备计费时间𝑡𝑙处的工作负载。
结果报告在表4中。DynEformer在正确的排名计数上大多胜过Informer,即5>2,这支持DynEformer在MT-ECP中辅助决策的潜力。观察Informer的结果,可能会认为𝐴𝑃𝑃2和𝐴𝑃𝑃3的贬值率大于𝐴𝑃𝑃1。由于更高的贬值率意味着更低的收入效率,这将导致MT-ECP减少这些应用的部署。然而,实际的排名却讲述了一个完全相反的事情——𝐴𝑃𝑃2和𝐴𝑃𝑃3的贬值率小于𝐴𝑃𝑃1,与𝐴𝑃𝑃1相比,应该部署更多基础设施与𝐴𝑃𝑃3相关。DynEformer成功地得出了正确的结论,从而避免了巨大的收入损失。
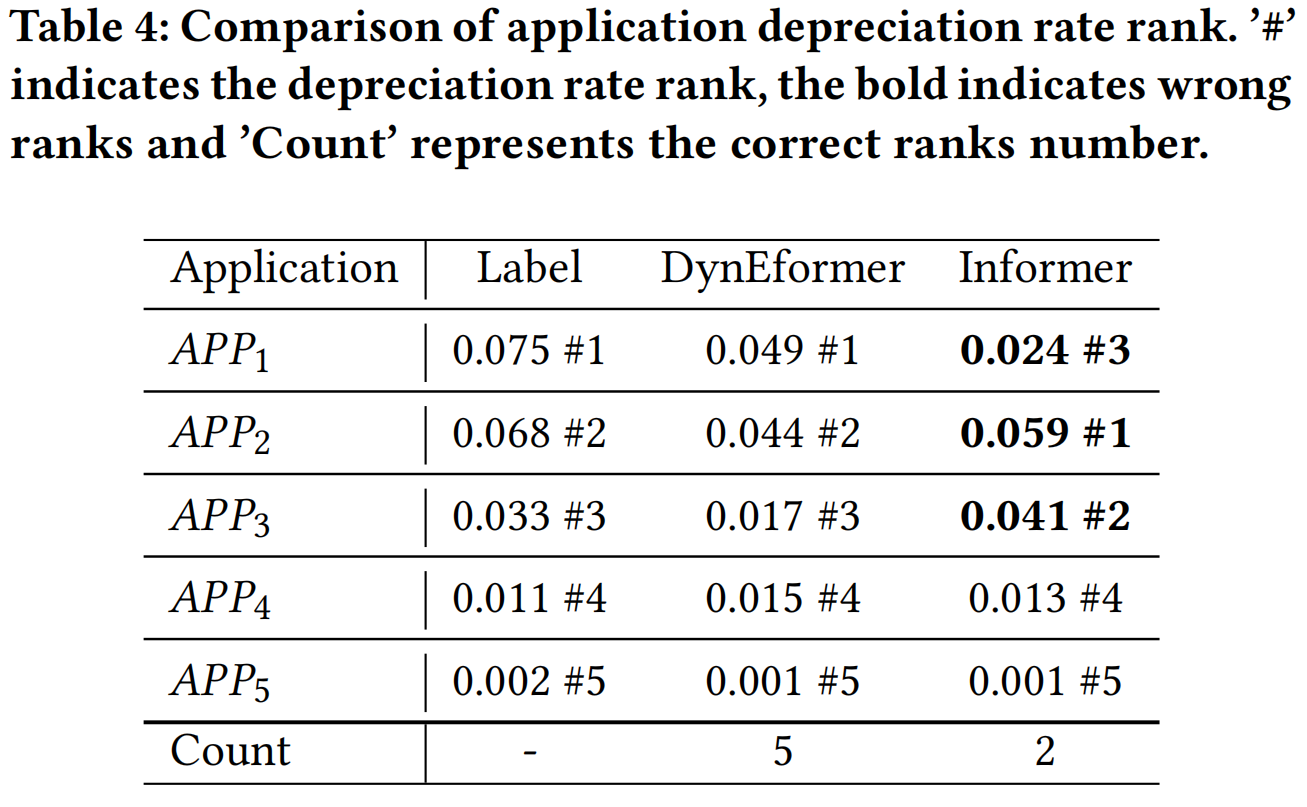
应用贬值率排名比较。'#'表示贬值率排名,加粗表示错误的排名,'Count'表示正确的排名数量。
6 结论
我们提出了DynEformer,一种用于动态MT-ECP中工作负载预测的转换器,采用全局池化和静态上下文感知技术。基于识别出的工作负载因素,全局池通过一种新的信息合并机制改进本地工作负载预测。实验结果表明,DynEformer在五个实际数据集上超越了当前的标准。消融研究突显了我们设计选择的本质和有效性。在实际的MT-ECP案例中,DynEformer展示了它如何支持决策,并改善应用部署的效益。我们相信DynEformer是一种有效的替代基于聚类方法的方法,将前者捕捉到的相似模式能力结合起来,并将其应用于更加灵活的方式。未来,我们将探索全局池的自动更新机制,使用户能够在长期预测中持续使用DynEformer而不需要间断地更新全局池。