小伙伴们好,咱们今天演绎一个使用KerasCV的StableDiffusion模型生成新的图像的示例。
考虑计算机性能的因素,这次咱们在Colab上进行,Colab您可以理解为在线版的Jupyter Notebook,还不熟悉Jupyter的的小伙伴可以去看一下我以前的文章:
政安晨的机器学习笔记——示例讲解机器学习工具Jupyter Notebook入门(超级详细)![]() https://blog.csdn.net/snowdenkeke/article/details/135880886
https://blog.csdn.net/snowdenkeke/article/details/135880886
概述
在本篇中,我们将展示如何使用stability.ai的text-to-image模型Stable Diffusion基于文本提示生成新图像,咱们这里使用的是KerasCV的实现。
Stable Diffusion是一个强大的开源文本到图像生成模型。虽然存在多个开源实现可以轻松地从文本提示创建图像,但KerasCV的实现具有一些明显的优势。其中包括XLA编译和混合精度支持,这两者共同实现了最先进的生成速度。
在本指南中,我们将探索KerasCV的Stable Diffusion实现,展示如何使用这些强大的性能提升,并探索它们所提供的性能优势。
开始前,咱们安装一些依赖项并整理一些导入模块:
pip install tensorflow keras_cv --upgrade --quiet(注意:要在torch后端上运行此指南,请在所有地方将设置jit_compile=False。目前,Stable Diffusion的XLA编译无法与torch一起使用。)
我这里因为使用的是Colab,所以我跳过上述的tensorflow依赖安装(colab自带):

安装好依赖后,咱们导入:
import time
import keras_cv
from tensorflow import keras
import matplotlib.pyplot as plt
稍微罗嗦一下
与大多数讲解文章不同的是,一般讲解都是首先解释一个主题,然后展示如何实现它,但是对于文本到图像生成,展示比讲解更简单。
现在快来看看 keras_cv.models.StableDiffusion() 的强大之处。
首先,我们构建一个模型:
model = keras_cv.models.StableDiffusion(img_width=512, img_height=512)
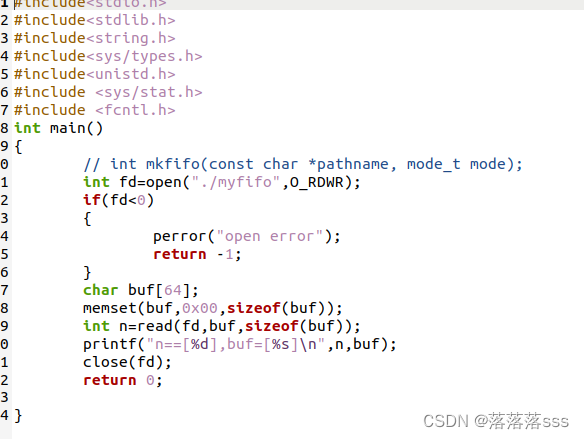
这里有一段提示: By using this model checkpoint, you acknowledge that its usage is subject to the terms of the CreativeML Open RAIL-M license at https://raw.githubusercontent.com/CompVis/stable-diffusion/main/LICENSE说明模型咱们创建成功。
接下来,我们给它一个提示词:
images = model.text_to_image("photograph of an astronaut riding a horse", batch_size=3)def plot_images(images):plt.figure(figsize=(20, 20))for i in range(len(images)):ax = plt.subplot(1, len(images), i + 1)plt.imshow(images[i])plt.axis("off")plot_images(images)我在Colab上运行了差不多6分钟:

真的特别棒!
但这种模型能做的远不止如此。让我们尝试一个更复杂的提示:
images = model.text_to_image("cute magical flying dog, fantasy art, ""golden color, high quality, highly detailed, elegant, sharp focus, ""concept art, character concepts, digital painting, mystery, adventure",batch_size=3,
)
plot_images(images)
这个可能性真的是无穷无尽的(至少Stable Diffusion潜力挖掘是无穷无尽的)。
这一切是如何工作的?
StableDiffusion 实际上当然并不依靠魔法运行,它是一种"扩散模型"。我们来深入了解一下这是什么意思。
你可能对超分辨率的概念比较熟悉:可以训练一个深度学习模型来去噪输入图像,从而将其转变为更高分辨率的版本。这个深度学习模型并不是通过神奇地恢复从噪声、低分辨率输入中丢失的信息来实现的,而是利用其训练数据分布来幻觉出在给定输入下最可能存在的视觉细节。
要了解更多关于超分辨率的内容,你可以查看以下 Keras.io 教程:
Image Super-Resolution using an Efficient Sub-Pixel CNNKeras documentation![]() https://keras.io/examples/vision/super_resolution_sub_pixel/Enhanced Deep Residual Networks for single-image super-resolutionKeras documentation
https://keras.io/examples/vision/super_resolution_sub_pixel/Enhanced Deep Residual Networks for single-image super-resolutionKeras documentation![]() https://keras.io/examples/vision/edsr/
https://keras.io/examples/vision/edsr/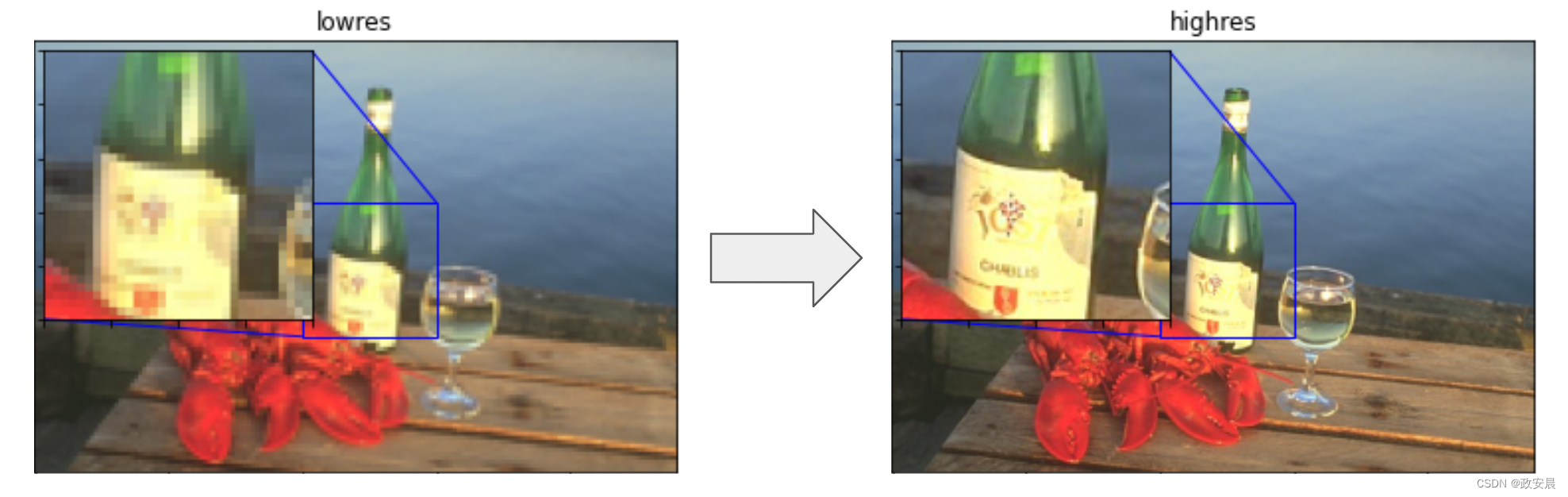
当你将这个想法推向极限时,你可能会开始问自己——如果我们只在纯噪声上运行这样的模型会怎样?模型将会"去除噪声"并开始产生全新的图像。通过多次重复这个过程,你可以将一个小块噪声转化为越来越清晰和高分辨率的人工图片。
这是2020年《使用潜在扩散模型进行高分辨率图像合成》中提出的潜在扩散的关键思想。
https://arxiv.org/abs/2112.10752![]() https://arxiv.org/abs/2112.10752要深入了解扩散,您可以查看Keras.io教程《去噪扩散隐式模型》。
https://arxiv.org/abs/2112.10752要深入了解扩散,您可以查看Keras.io教程《去噪扩散隐式模型》。
Denoising Diffusion Implicit ModelsKeras documentation![]() https://keras.io/examples/generative/ddim/
https://keras.io/examples/generative/ddim/
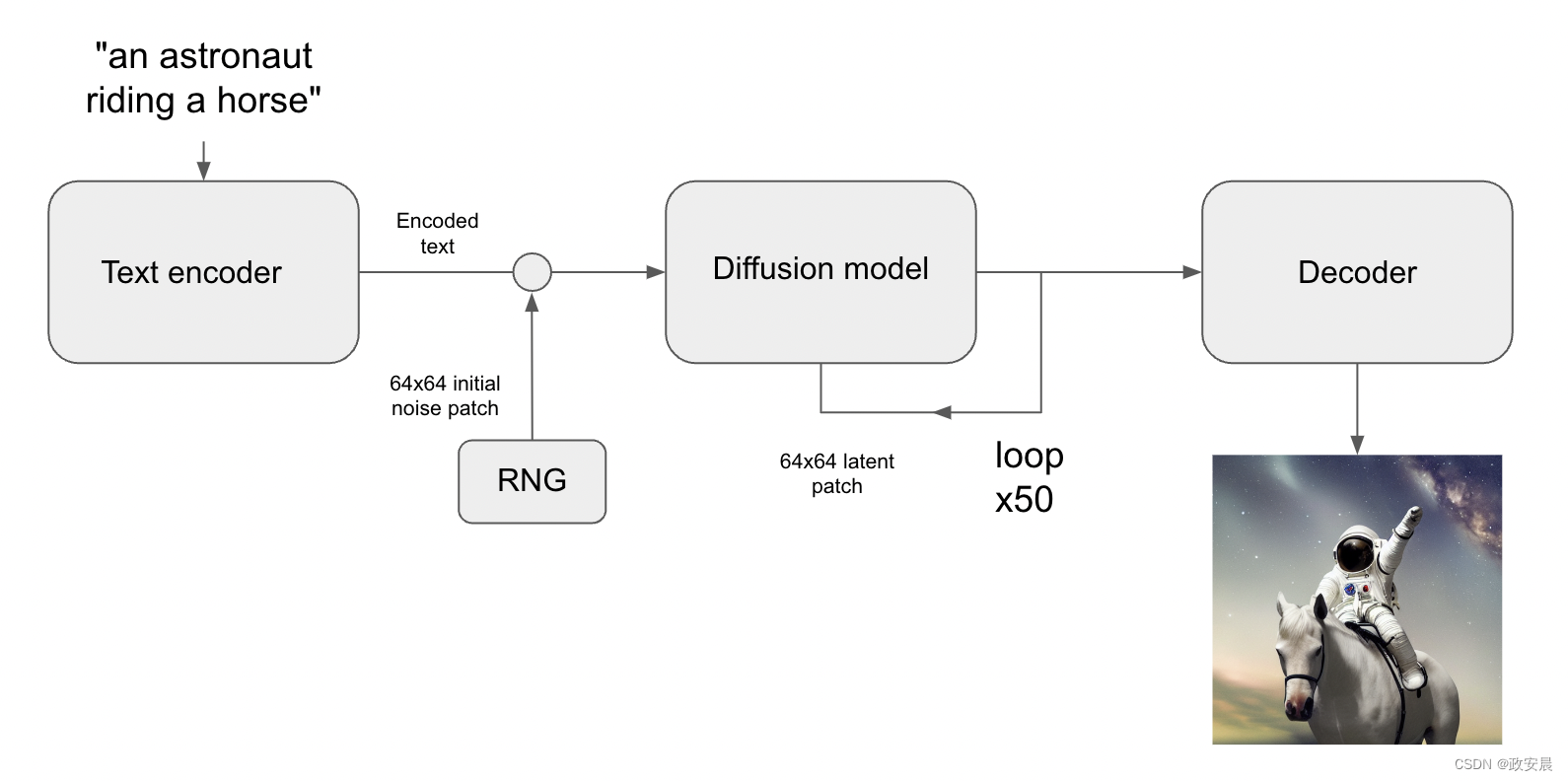
现在,要从潜在的扩散转变为文本到图像系统,仍然需要添加一个关键特性:通过提示关键词控制生成的视觉内容的能力。这通过"条件化"实现,这是一种经典的深度学习技术,它包括将表示一小段文本的向量连接到噪声图像块上,然后在一个{图像:标题}对的数据集上训练模型。
这就产生了稳定扩散架构。稳定扩散由三部分组成:
文本编码器,将您的提示转换为潜在向量。 扩散模型,反复对一个64x64的潜在图像块进行"去噪"。 解码器,将最终的64x64潜在图块转换为更高分辨率的512x512图像。 首先,您的文本提示通过文本编码器投影到潜在向量空间中,这只是一个预训练的、冻结的语言模型。然后,该提示向量与随机生成的噪声图像块连接在一起,通过扩散模型在一系列"步骤"上反复进行"去噪"(步骤越多,图像越清晰、更好 - 默认值为50步)。
最后,64x64的潜在图像被发送到解码器中,以正确地渲染出高分辨率的图像。
总的来说,这是一个相当简单的系统——Keras实现仅包含四个文件,总共不到500行代码:
text_encoder.py:87行代码
diffusion_model.py:181行代码
decoder.py:86行代码
stable_diffusion.py:106行代码
但是,一旦你在数十亿张图片及其标题上进行训练,这个相对简单的系统就会变得像魔术一样。正如费曼所说的关于宇宙的事物:“它并不复杂,只是有很多而已!
KerasCV的好处
为什么应该使用keras_cv.models.StableDiffusion?
除了易于使用的API之外,KerasCV的稳定扩散模型具有一些强大的优势,包括:
- 图模式执行
- 通过jit_compile=True进行XLA编译
- 支持混合精度计算
当这些优势结合在一起时,KerasCV稳定扩散模型的运行速度比朴素实现快上数个数量级。本节介绍如何启用所有这些功能,并展示使用它们所带来的性能提升。
为了进行比较,我们进行了基准测试,比较了HuggingFace diffusers实现的StableDiffusion与KerasCV实现之间的运行时间。两种实现都被要求为每个图像生成50个步骤的3个图像。在这个基准测试中,我们使用了一个Tesla T4 GPU。
咱们所有的基准测试都是在GitHub上公开的开源项目,并且可以在Colab上重新运行以复现结果。以下表格显示了基准测试的结果:
| GPU | Model | Runtime |
|---|---|---|
| Tesla T4 | KerasCV (Warm Start) | 28.97s |
| Tesla T4 | diffusers (Warm Start) | 41.33s |
| Tesla V100 | KerasCV (Warm Start) | 12.45 |
| Tesla V100 | diffusers (Warm Start) | 12.72 |
在Tesla T4上的执行时间提升了30%!尽管在V100上的改进要小得多,但我们通常预计基准测试结果在所有NVIDIA GPU上都会持续支持KerasCV。
为了完整起见,我们报告了冷启动和热启动的生成时间。冷启动执行时间包括模型创建和编译的一次性成本,因此在生产环境中可以忽略不计(在该环境中,您会多次重用同一模型实例)。无论如何,这是冷启动的数据:
| GPU | Model | Runtime |
|---|---|---|
| Tesla T4 | KerasCV (Cold Start) | 83.47s |
| Tesla T4 | diffusers (Cold Start) | 46.27s |
| Tesla V100 | KerasCV (Cold Start) | 76.43 |
| Tesla V100 | diffusers (Cold Start) | 13.90 |
尽管运行此指南的运行时结果可能会有所不同,但在我们的测试中,使用KerasCV实现的Stable Diffusion比其PyTorch版本要快得多。这可能主要归因于XLA编译。
注意:每个优化的性能增益在不同的硬件设置之间可能存在显著差异。
未优化模型的基准测试
在继续开始之前,让我们首先对我们的未优化模型进行基准测试:
benchmark_result = []
start = time.time()
images = model.text_to_image("A cute otter in a rainbow whirlpool holding shells, watercolor",batch_size=3,
)
end = time.time()
benchmark_result.append(["Standard", end - start])
plot_images(images)print(f"Standard model: {(end - start):.2f} seconds")
keras.backend.clear_session() # Clear session to preserve memory.这次咱们用了一分钟:

混合精度
“混合精度”是指使用float16精度进行计算,同时使用float32格式存储权重。这样做是为了利用现代NVIDIA GPU上float16操作背后比其float32对应操作更快的内核。
在Keras中启用混合精度计算(因此也适用于keras_cv.models.StableDiffusion)只需要调用:
keras.mixed_precision.set_global_policy("mixed_float16")
就这样,开箱即用。
model = keras_cv.models.StableDiffusion()print("Compute dtype:", model.diffusion_model.compute_dtype)
print("Variable dtype:",model.diffusion_model.variable_dtype,
)By using this model checkpoint, you acknowledge that its usage is subject to the terms of the CreativeML Open RAIL-M license at https://raw.githubusercontent.com/CompVis/stable-diffusion/main/LICENSE Compute dtype: float16 Variable dtype: float32

正如您所看到的,上面构建的模型现在使用了混合精度计算;利用float16操作的速度进行计算,同时以float32精度存储变量。
# Warm up model to run graph tracing before benchmarking.
model.text_to_image("warming up the model", batch_size=3)start = time.time()
images = model.text_to_image("a cute magical flying dog, fantasy art, ""golden color, high quality, highly detailed, elegant, sharp focus, ""concept art, character concepts, digital painting, mystery, adventure",batch_size=3,
)
end = time.time()
benchmark_result.append(["Mixed Precision", end - start])
plot_images(images)print(f"Mixed precision model: {(end - start):.2f} seconds")
keras.backend.clear_session()
XLA编译
TensorFlow内置了XLA:加速线性代数编译器。 keras_cv.models.StableDiffusion在开箱即用时支持jit_compile参数。将此参数设置为True可以启用XLA编译,从而实现显著加速。
使用如下:
# Set back to the default for benchmarking purposes.
keras.mixed_precision.set_global_policy("float32")model = keras_cv.models.StableDiffusion(jit_compile=True)
# Before we benchmark the model, we run inference once to make sure the TensorFlow
# graph has already been traced.
images = model.text_to_image("An avocado armchair", batch_size=3)
plot_images(images)
这次咱们用了2分多钟。
让我们来对我们的 XLA 模型进行基准测试:
start = time.time()
images = model.text_to_image("A cute otter in a rainbow whirlpool holding shells, watercolor",batch_size=3,
)
end = time.time()
benchmark_result.append(["XLA", end - start])
plot_images(images)print(f"With XLA: {(end - start):.2f} seconds")
keras.backend.clear_session()
在A100 GPU上,我们获得了大约2倍的加速。太棒了!
融合一起
现在咱们将所有这些都放在一起。
现在咱们看看如何组装世界上性能最佳的StableDiffusion推理流程?
执行下述代码:
keras.mixed_precision.set_global_policy("mixed_float16")
model = keras_cv.models.StableDiffusion(jit_compile=True)![]()
接下来可以自己尝试一下(我这里就不赘述了):
# Let's make sure to warm up the model
images = model.text_to_image("Teddy bears conducting machine learning research",batch_size=3,
)
plot_images(images)start = time.time()
images = model.text_to_image("A mysterious dark stranger visits the great pyramids of egypt, ""high quality, highly detailed, elegant, sharp focus, ""concept art, character concepts, digital painting",batch_size=3,
)
end = time.time()
benchmark_result.append(["XLA + Mixed Precision", end - start])
plot_images(images)print(f"XLA + mixed precision: {(end - start):.2f} seconds")可以这样查看结果:
print("{:<22} {:<22}".format("Model", "Runtime"))
for result in benchmark_result:name, runtime = resultprint("{:<22} {:<22}".format(name, runtime))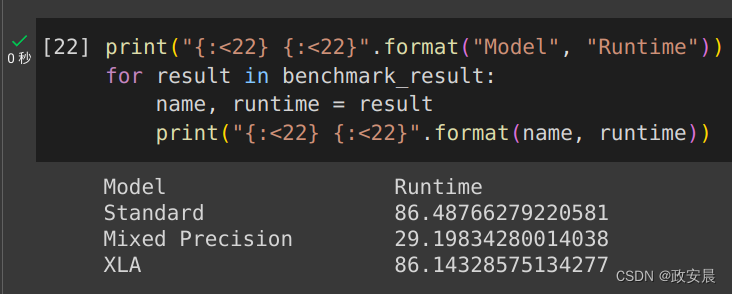
这里咱们受限于资源没有执行优化,其实经过全面优化的模型只需要几秒钟就能够在A100 GPU上从一个文本提示中生成一组图像。
结论
KerasCV提供了Stable Diffusion的先进实现,并通过使用XLA和混合精度。
如果您拥有自己的NVIDIA GPU或最新的MacBookPro等,您也可以在本地计算机上运行模型。(请注意,在MacBookPro上运行时,不应启用混合精度,因为它有可能未得到苹果的良好支持。)