nccl-tests
- 环境
- 1. 安装nccl
- 2. 安装openmpi
- 3. 单机测试
- 4. 多机测试
- mpirun多机多进程
- 多节点运行nccl-tests
- channel获取
环境
- Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)
- cuda 11.8+ cudnn 8
- nccl 2.15.1
- NVIDIA GeForce RTX 4090 *2
1. 安装nccl
#查看cuda版本
nvcc -V
Nvidia官网下载链接 (不过好像需要注册一个Nvidia账户)
根据自己的cuda版本去寻找想要的版本,单击对应行即可显示下载步骤。
采取 Network Installer即可,我选择了nccl2.15.1+cuda11.8
#配置网络存储库
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update#安装特定版本
sudo apt install libnccl2=2.15.1-1+cuda11.8 libnccl-dev=2.15.1-1+cuda11.8#确认系统nccl版本
dpkg -l | grep nccl2. 安装openmpi
#apt安装openmpi
sudo apt-get update
sudo apt-get install openmpi-bin openmpi-doc libopenmpi-dev#验证是否安装成功
mpirun --version
3. 单机测试
nccl-test GitHub链接
如何执行测试和相关参数参考readme.md即可,已经描述的很详细了。
NCCL测试依赖于MPI以在多个进程和多个节点上工作。如果你想使用MPI支持编译这些测试,需要将环境变量MPI设置为1,并将MPI_HOME设置为MPI安装的路径。
#克隆该repo
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests# 编译支持mpi的test
make MPI=1 MPI_HOME=/usr/lib/x86_64-linux-gnu/openmpi
成功后会在build目录下生成可执行文件

NCCL测试可以在多个进程、多个线程和每个线程上的多个CUDA设备上运行。进程的数量由MPI进行管理,因此不作为参数传递给测试(可以通过mpirun -np n(n为进程数)来指定)。
总的ranks数量(即CUDA设备数,也是总的gpu数量)=(进程数)*(线程数)*(每个线程的GPU数)。
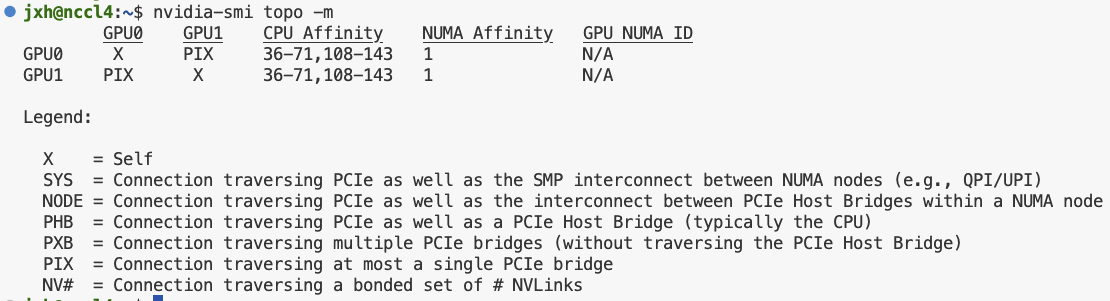
可以先通过nvidia-smi topo -m命令查看机器内拓扑结构,这里是双卡,两个gpu之间连接方式是PIX(Connection traversing at most a single PCIe bridge)
在 2个 GPU 上运行 ( -g 2 ),扫描范围从 8 字节到 128MB :
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 2
这里-b表示minBytes,-e表示maxBytes,-g表示两张卡,-f表示数据量每次乘2,如开始是8B,往后依次是16,32,64字节…
-g后面的gpu数量不能超过实际的数量,否则会报如下错误- invalid Device ordinal

单机执行结果如下:
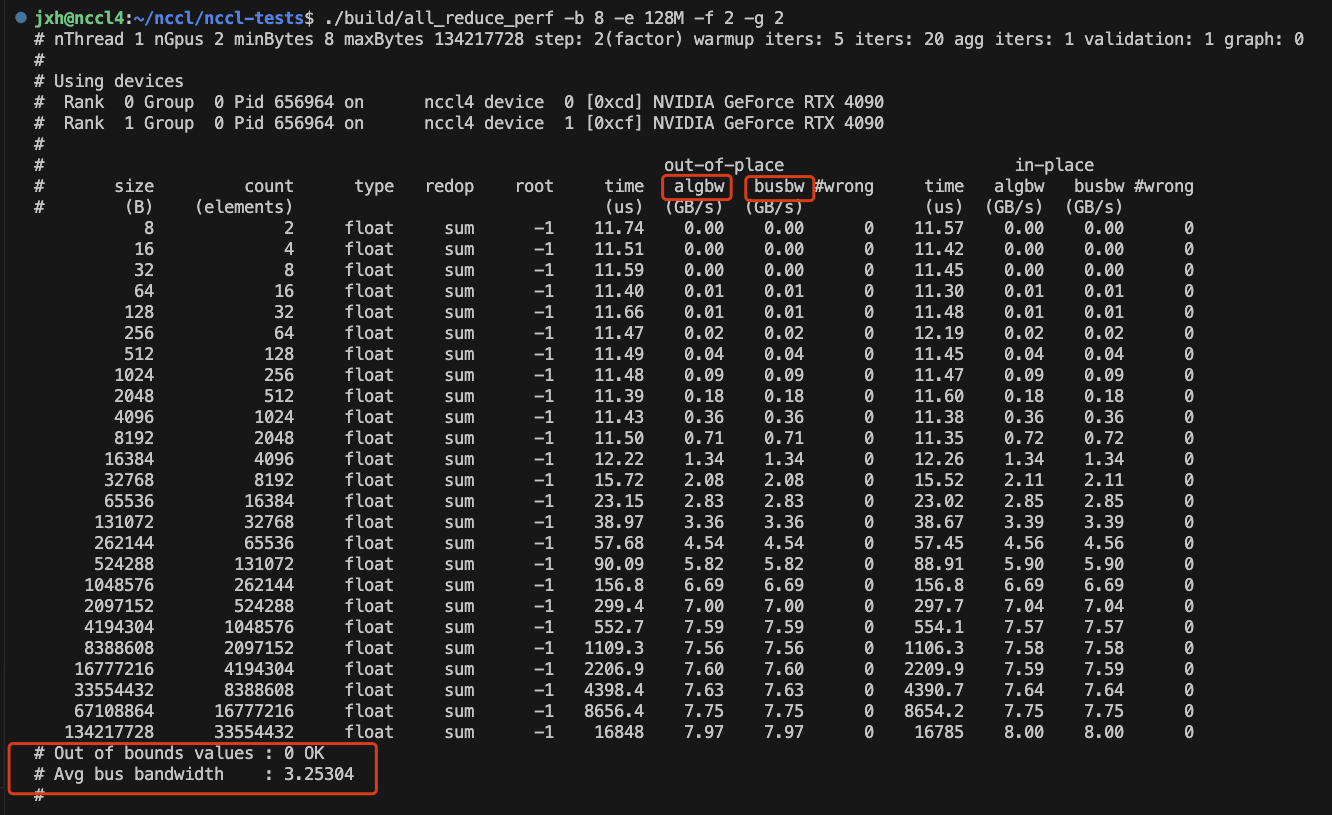
这里执行all_reduce操作时算法带宽(algbw)和总线带宽(busbw)是一致的,并且都是随着数据量的增大而增大。关于二者的区别可见https://github.com/NVIDIA/nccl-tests/blob/master/doc/PERFORMANCE.md#bandwidth
4. 多机测试
关于mpi的基本了解和使用,可参考这篇文章 DL分布式训练基础之openmpi
mpirun多机多进程
这里使用2个节点(126,127)。 运行mpirun命令的为头节点(这里用126),它是通过ssh远程命令来拉起其他节点(127)的业务进程的,故它需要密码访问其他host
#在126生成RSA公钥,并copy给127即可
ssh-keygen -t rsassh-copy-id -i ~/.ssh/id_rsa.pub 192.168.72.127
如果ssh的端口不是22,可以在mpirun命令后添加参数-mca plm_rsh_args "-p 端口号" ,除此之外,还可以在主节点上编辑以下文件
nano ~/.ssh/config
#添加以下内容
Host 192.168.72.127Port 2233
指定连接到特定主机时使用的端口(例如2233),并确保在执行之前检查并设置~/.ssh/config文件的权限,使其对你的用户是私有
的:
chmod 600 ~/.ssh/config
这样配置后,当你使用SSH连接到主机192.168.72.127,SSH将使用端口2233,可以减少在‘mpirun‘命令中指定端口的需要。
然后可以进行多节点测试,节点个数对应-np 后的数字,这里新建一个hostfile内容如下,每行一个ip地址就可以
192.168.72.126
192.168.72.127
mpirun -np 2 -hostfile hostfile -pernode \
bash -c 'echo "Hello from process $OMPI_COMM_WORLD_RANK of $OMPI_COMM_WORLD_SIZE on $(hostname)"'

多节点运行nccl-tests
运行以下命令,这里对应双机4卡,注意np后面的进程数*单个节点gpu数(-g 指定)=总的gpu数量,即之前提到的等式
总的ranks数量(即CUDA设备数,也是总的gpu数量)=(进程数)*(线程数)*(每个线程的GPU数)。
mpirun -np 2 -pernode \
--allow-run-as-root \
-hostfile hostfile \
-mca btl_tcp_if_include eno2 \
-x NCCL_SOCKET_IFNAME=eno2 \
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 2 -c 0
避免每次命令加–allow-run-as-root
echo 'export OMPI_ALLOW_RUN_AS_ROOT_CONFIRM=1' >> ~/.bashrc
echo 'export OMPI_ALLOW_RUN_AS_ROOT=1' >> ~/.bashrc
不添加参数-mca btl_tcp_if_include eno2 的话会报错如下:Open MPI accepted a TCP connection from what appears to be a
another Open MPI process but cannot find a corresponding process entry for that peer.
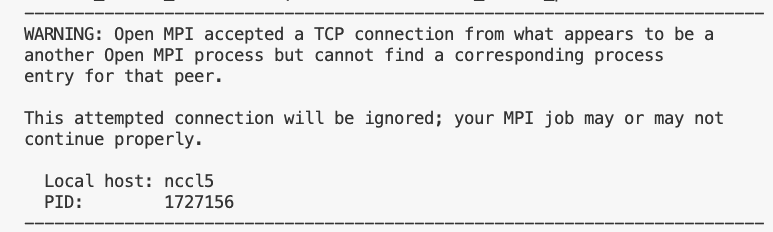
eno2替换为自己的网卡接口名称,可通过ifconfig查看。
执行结果如下:
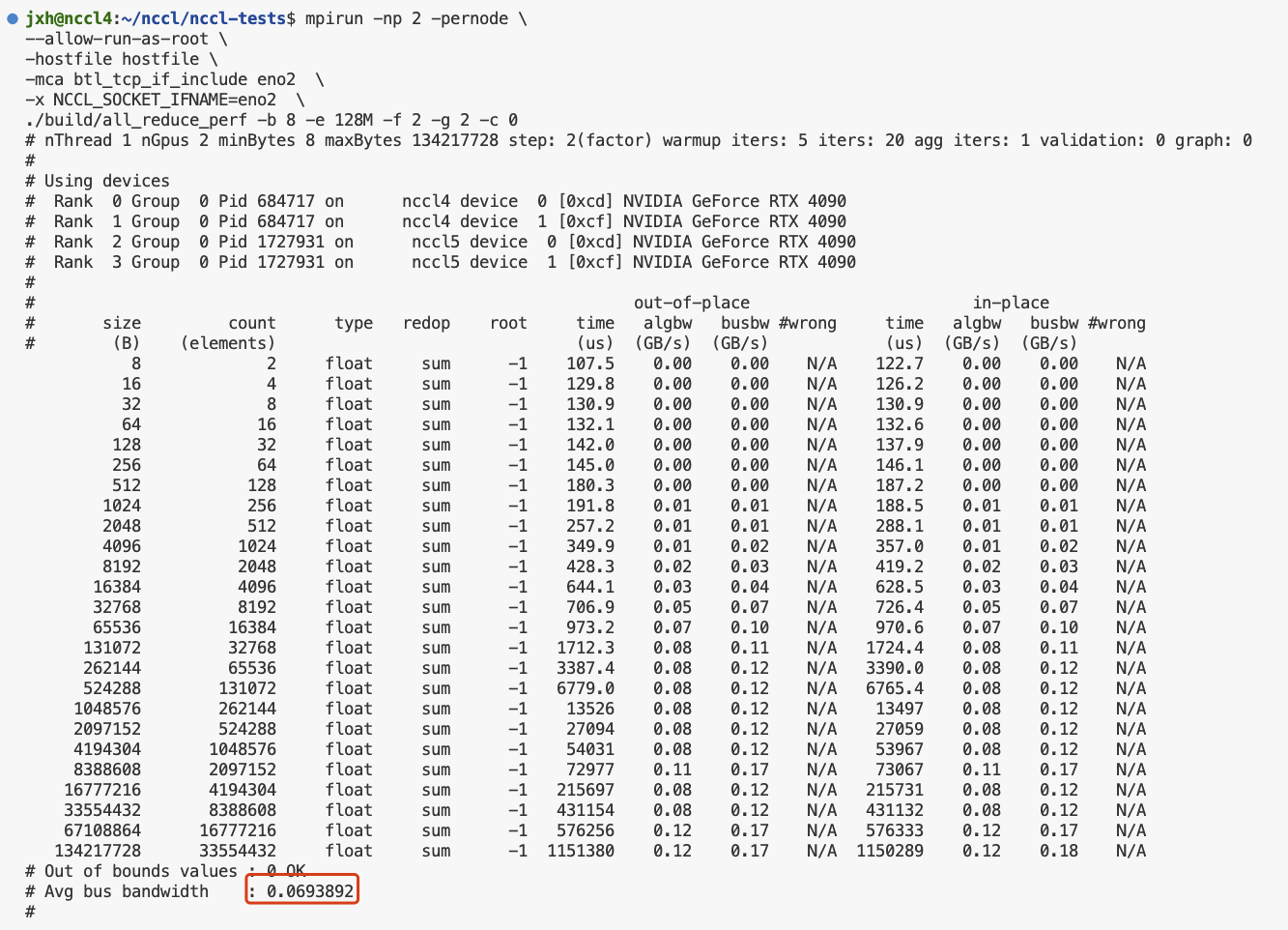
可以看到,同样的操作,同样的数据量双机比单机慢了不是一点,这里平均总先带宽0.07 GB/s,而前文的单机是3.25.
当然这里使用的是普通的千兆以太网,带宽最高1GB/s,也没有IB网卡等。
之前使用100G的网卡测试的带宽双机是可以达到1.几G,现在100G的网卡接口暂时不能用了就没有测。
channel获取
channel的概念:
nccl中channel的概念表示一个通信路径,为了更好的利用带宽和网卡,以及同一块数据可以通过多个channel并发通信,nccl会使用多channel,搜索的过程就是搜索出来一组channel。
具体一点可以参考以下文章:
如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL? - Connolly的回答 - 知乎
https://www.zhihu.com/question/63219175/answer/2768301153
获取channel:
mpirun命令中添加参数-x NCCL_DEBUG=INFO \即可,详细信息就会输出到终端
mpirun -np 2 -pernode \
-hostfile hostfile \
-mca btl_tcp_if_include eno2 \
-x NCCL_SOCKET_IFNAME=eno2 \
-x NCCL_DEBUG=INFO \
-x NCCL_IGNORE_DISABLED_P2P=1 \
-x CUDA_VISIBLE_DEVICES=0,1 \
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 2 -c 0
执行结果:
nThread 1 nGpus 2 minBytes 8 maxBytes 134217728 step: 2(factor) warmup iters: 5 iters: 20 agg iters: 1 validation: 0 graph: 0
#
# Using devicesRank 0 Group 0 Pid 685547 on nccl4 device 0 [0xcd] NVIDIA GeForce RTX 4090Rank 1 Group 0 Pid 685547 on nccl4 device 1 [0xcf] NVIDIA GeForce RTX 4090Rank 2 Group 0 Pid 1728006 on nccl5 device 0 [0xcd] NVIDIA GeForce RTX 4090Rank 3 Group 0 Pid 1728006 on nccl5 device 1 [0xcf] NVIDIA GeForce RTX 4090
nccl4:685547:685547 [0] NCCL INFO Bootstrap : Using eno2:10.112.205.39<0>
nccl4:685547:685547 [0] NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
nccl4:685547:685547 [0] NCCL INFO cudaDriverVersion 12020
NCCL version 2.15.1+cuda11.8
nccl4:685547:685563 [0] NCCL INFO NET/IB : No device found.
nccl4:685547:685563 [0] NCCL INFO NET/Socket : Using [0]eno2:10.112.205.39<0>
nccl4:685547:685563 [0] NCCL INFO Using network Socket
nccl4:685547:685564 [1] NCCL INFO Using network Socket
nccl5:1728006:1728006 [0] NCCL INFO cudaDriverVersion 12020
nccl5:1728006:1728006 [0] NCCL INFO Bootstrap : Using eno2:10.112.57.233<0>
nccl5:1728006:1728006 [0] NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
nccl5:1728006:1728014 [0] NCCL INFO NET/IB : No device found.
nccl5:1728006:1728014 [0] NCCL INFO NET/Socket : Using [0]eno2:10.112.57.233<0>
nccl5:1728006:1728014 [0] NCCL INFO Using network Socket
nccl5:1728006:1728015 [1] NCCL INFO Using network Socket
nccl5:1728006:1728015 [1] NCCL INFO NCCL_IGNORE_DISABLED_P2P set by environment to 1.
nccl4:685547:685564 [1] NCCL INFO NCCL_IGNORE_DISABLED_P2P set by environment to 1.
nccl4:685547:685563 [0] NCCL INFO Channel 00/02 : 0 1 2 3
nccl4:685547:685563 [0] NCCL INFO Channel 01/02 : 0 1 2 3
nccl4:685547:685563 [0] NCCL INFO Trees [0] 1/2/-1->0->-1 [1] 1/-1/-1->0->2
nccl4:685547:685564 [1] NCCL INFO Trees [0] -1/-1/-1->1->0 [1] -1/-1/-1->1->0
nccl5:1728006:1728014 [0] NCCL INFO Trees [0] 3/-1/-1->2->0 [1] 3/0/-1->2->-1
nccl5:1728006:1728015 [1] NCCL INFO Trees [0] -1/-1/-1->3->2 [1] -1/-1/-1->3->2
nccl5:1728006:1728014 [0] NCCL INFO Channel 00/0 : 1[cf000] -> 2[cd000] [receive] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 00/0 : 3[cf000] -> 0[cd000] [receive] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 01/0 : 1[cf000] -> 2[cd000] [receive] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 00 : 2[cd000] -> 3[cf000] via SHM/direct/direct
nccl5:1728006:1728014 [0] NCCL INFO Channel 01 : 2[cd000] -> 3[cf000] via SHM/direct/direct
nccl4:685547:685564 [1] NCCL INFO Channel 00/0 : 1[cf000] -> 2[cd000] [send] via NET/Socket/0
nccl5:1728006:1728015 [1] NCCL INFO Channel 00/0 : 3[cf000] -> 0[cd000] [send] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 01/0 : 3[cf000] -> 0[cd000] [receive] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 00 : 0[cd000] -> 1[cf000] via SHM/direct/direct
nccl4:685547:685563 [0] NCCL INFO Channel 01 : 0[cd000] -> 1[cf000] via SHM/direct/direct
nccl4:685547:685564 [1] NCCL INFO Channel 01/0 : 1[cf000] -> 2[cd000] [send] via NET/Socket/0
nccl5:1728006:1728015 [1] NCCL INFO Channel 01/0 : 3[cf000] -> 0[cd000] [send] via NET/Socket/0
nccl4:685547:685564 [1] NCCL INFO Connected all rings
nccl4:685547:685564 [1] NCCL INFO Channel 00 : 1[cf000] -> 0[cd000] via SHM/direct/direct
nccl4:685547:685564 [1] NCCL INFO Channel 01 : 1[cf000] -> 0[cd000] via SHM/direct/direct
nccl5:1728006:1728014 [0] NCCL INFO Connected all rings
nccl4:685547:685563 [0] NCCL INFO Connected all rings
nccl5:1728006:1728015 [1] NCCL INFO Connected all rings
nccl5:1728006:1728015 [1] NCCL INFO Channel 00 : 3[cf000] -> 2[cd000] via SHM/direct/direct
nccl5:1728006:1728015 [1] NCCL INFO Channel 01 : 3[cf000] -> 2[cd000] via SHM/direct/direct
nccl4:685547:685563 [0] NCCL INFO Channel 00/0 : 2[cd000] -> 0[cd000] [receive] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 00/0 : 0[cd000] -> 2[cd000] [receive] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 01/0 : 2[cd000] -> 0[cd000] [receive] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 01/0 : 0[cd000] -> 2[cd000] [receive] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 00/0 : 0[cd000] -> 2[cd000] [send] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 00/0 : 2[cd000] -> 0[cd000] [send] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 01/0 : 0[cd000] -> 2[cd000] [send] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 01/0 : 2[cd000] -> 0[cd000] [send] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Connected all trees
nccl4:685547:685563 [0] NCCL INFO threadThresholds 8/8/64 | 32/8/64 | 512 | 512
nccl4:685547:685563 [0] NCCL INFO 2 coll channels, 2 p2p channels, 2 p2p channels per peer
nccl5:1728006:1728014 [0] NCCL INFO Connected all trees
nccl5:1728006:1728014 [0] NCCL INFO threadThresholds 8/8/64 | 32/8/64 | 512 | 512
nccl5:1728006:1728014 [0] NCCL INFO 2 coll channels, 2 p2p channels, 2 p2p channels per peer
nccl4:685547:685564 [1] NCCL INFO Connected all trees
nccl4:685547:685564 [1] NCCL INFO threadThresholds 8/8/64 | 32/8/64 | 512 | 512
nccl4:685547:685564 [1] NCCL INFO 2 coll channels, 2 p2p channels, 2 p2p channels per peer
nccl5:1728006:1728015 [1] NCCL INFO Connected all trees
nccl5:1728006:1728015 [1] NCCL INFO threadThresholds 8/8/64 | 32/8/64 | 512 | 512
nccl5:1728006:1728015 [1] NCCL INFO 2 coll channels, 2 p2p channels, 2 p2p channels per peer
nccl4:685547:685563 [0] NCCL INFO comm 0x55aec4722370 rank 0 nranks 4 cudaDev 0 busId cd000 - Init COMPLETE
nccl4:685547:685564 [1] NCCL INFO comm 0x55aec472e1e0 rank 1 nranks 4 cudaDev 1 busId cf000 - Init COMPLETE
nccl5:1728006:1728014 [0] NCCL INFO comm 0x557f5e599d40 rank 2 nranks 4 cudaDev 0 busId cd000 - Init COMPLETE
nccl5:1728006:1728015 [1] NCCL INFO comm 0x557f5e5a5f20 rank 3 nranks 4 cudaDev 1 busId cf000 - Init COMPLETE
nccl4:685547:685547 [0] NCCL INFO comm 0x55aec4722370 rank 0 nranks 4 cudaDev 0 busId cd000 - Destroy COMPLETE
nccl5:1728006:1728006 [0] NCCL INFO comm 0x557f5e599d40 rank 2 nranks 4 cudaDev 0 busId cd000 - Destroy COMPLETE
nccl4:685547:685547 [0] NCCL INFO comm 0x55aec472e1e0 rank 1 nranks 4 cudaDev 1 busId cf000 - Destroy COMPLETE
nccl5:1728006:1728006 [0] NCCL INFO comm 0x557f5e5a5f20 rank 3 nranks 4 cudaDev 1 busId cf000 - Destroy COMPLETE
最后就是上图中的带宽展示,这里没有放上去。
以上就是双机4卡nccl执行的一个过程,后续计划结合nccl和nccl-tests的源代码分析一下总体流程,重点是channel部分。