课程地址
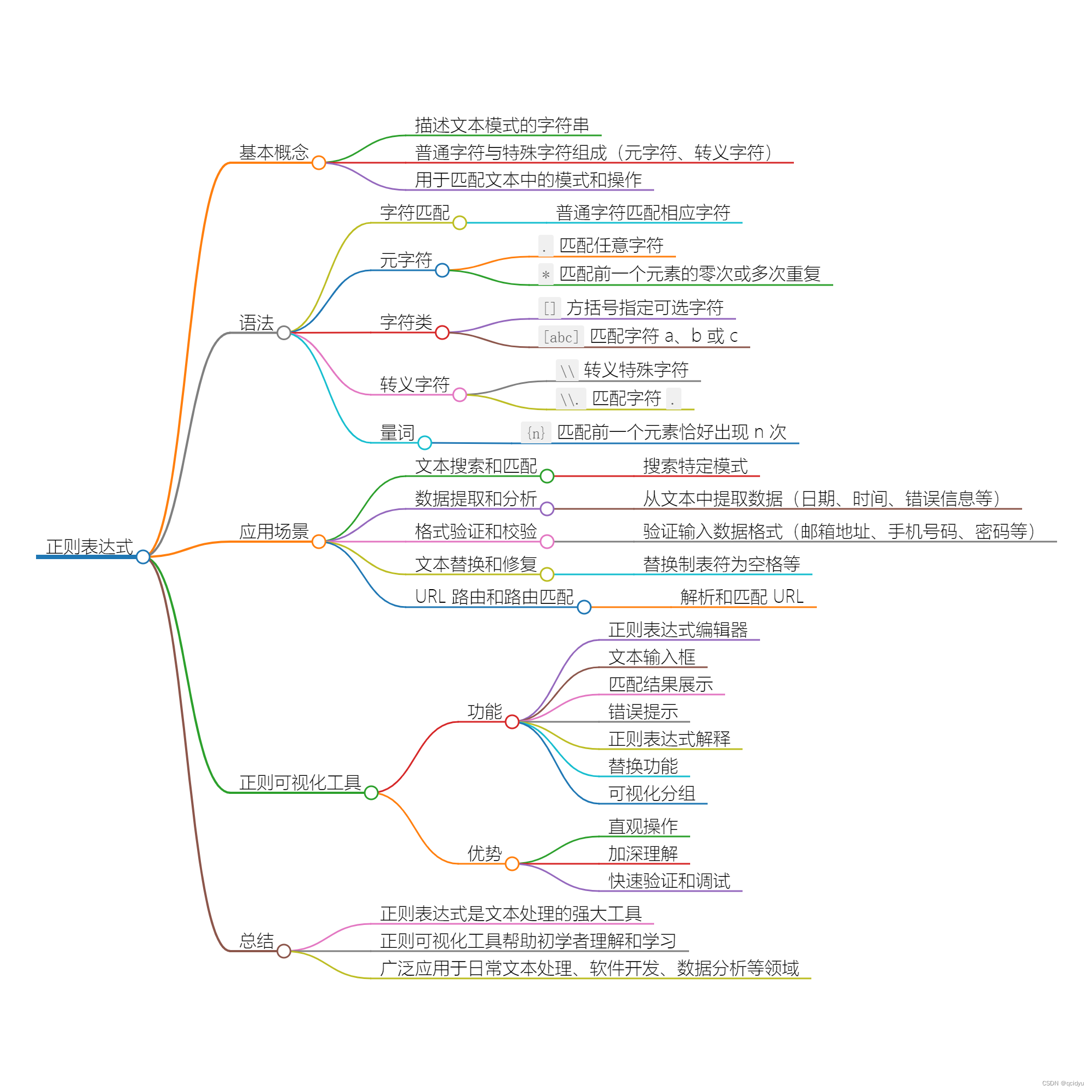
概述
定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ)
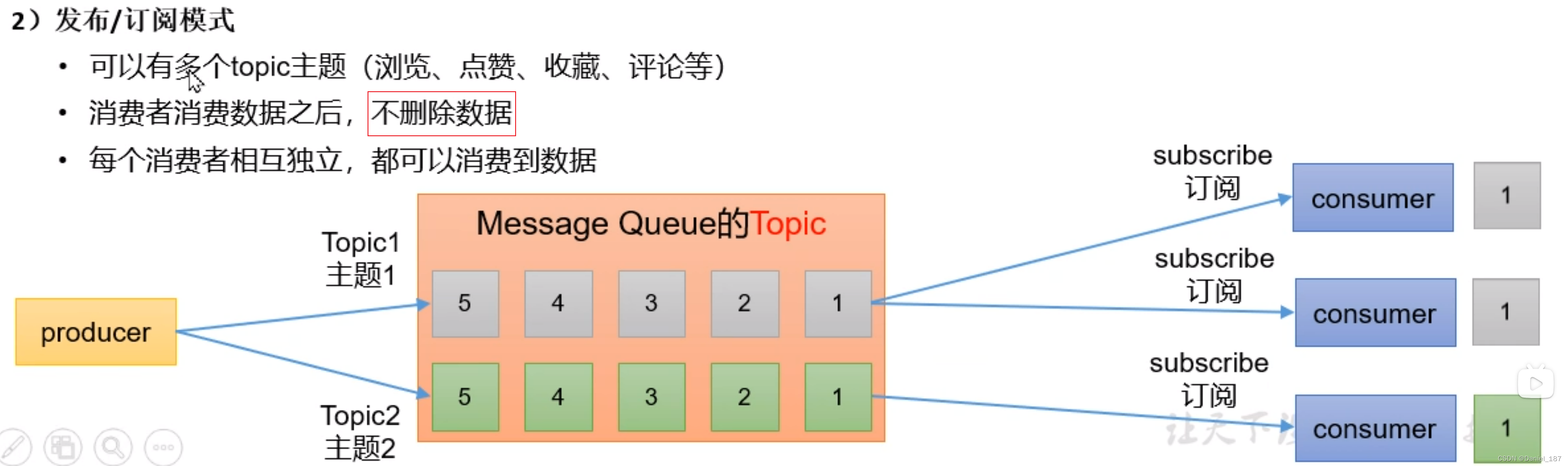
发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接受感兴趣的消息
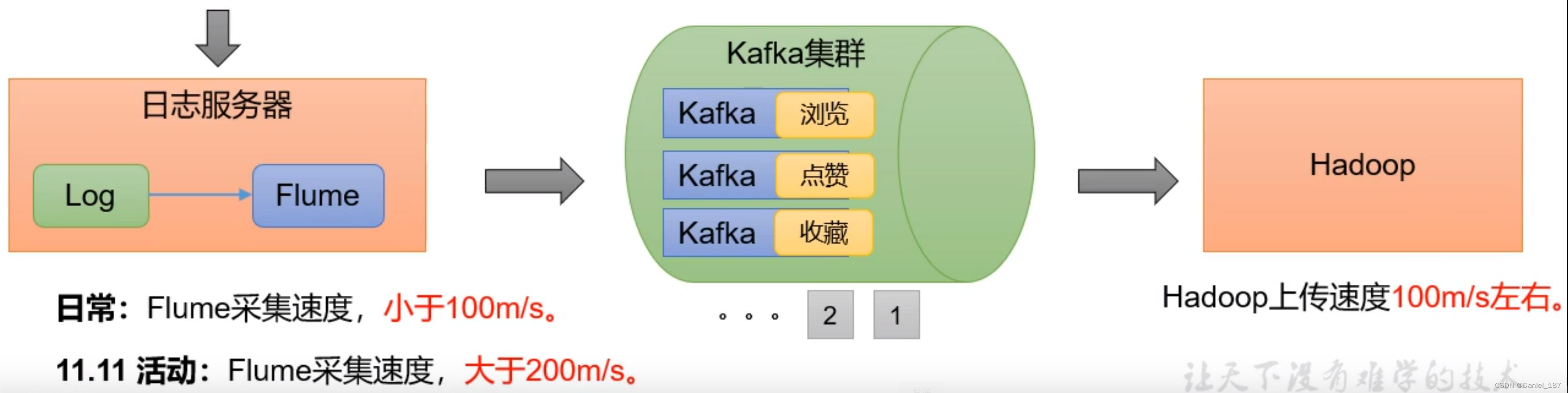
消息队列
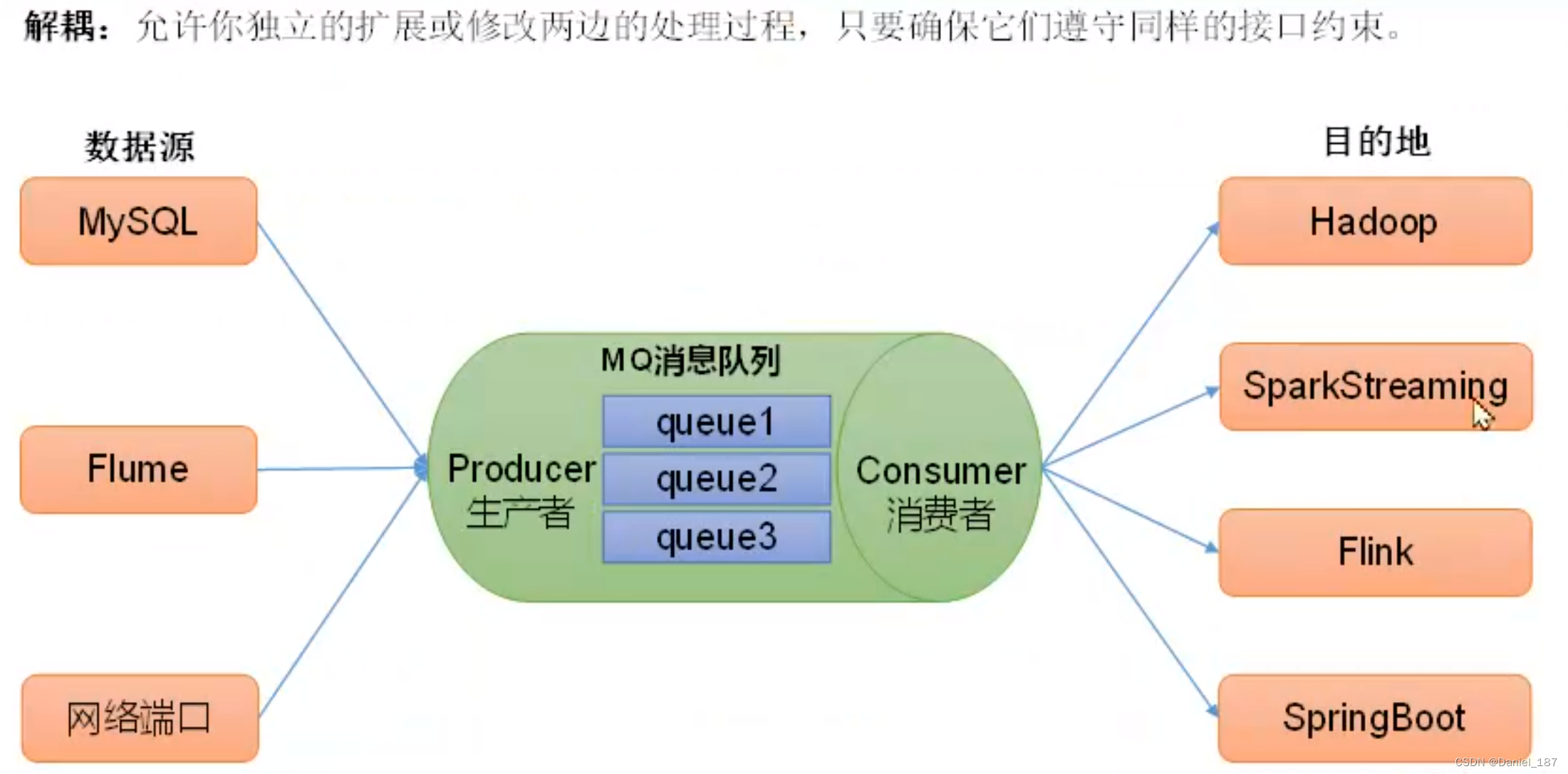
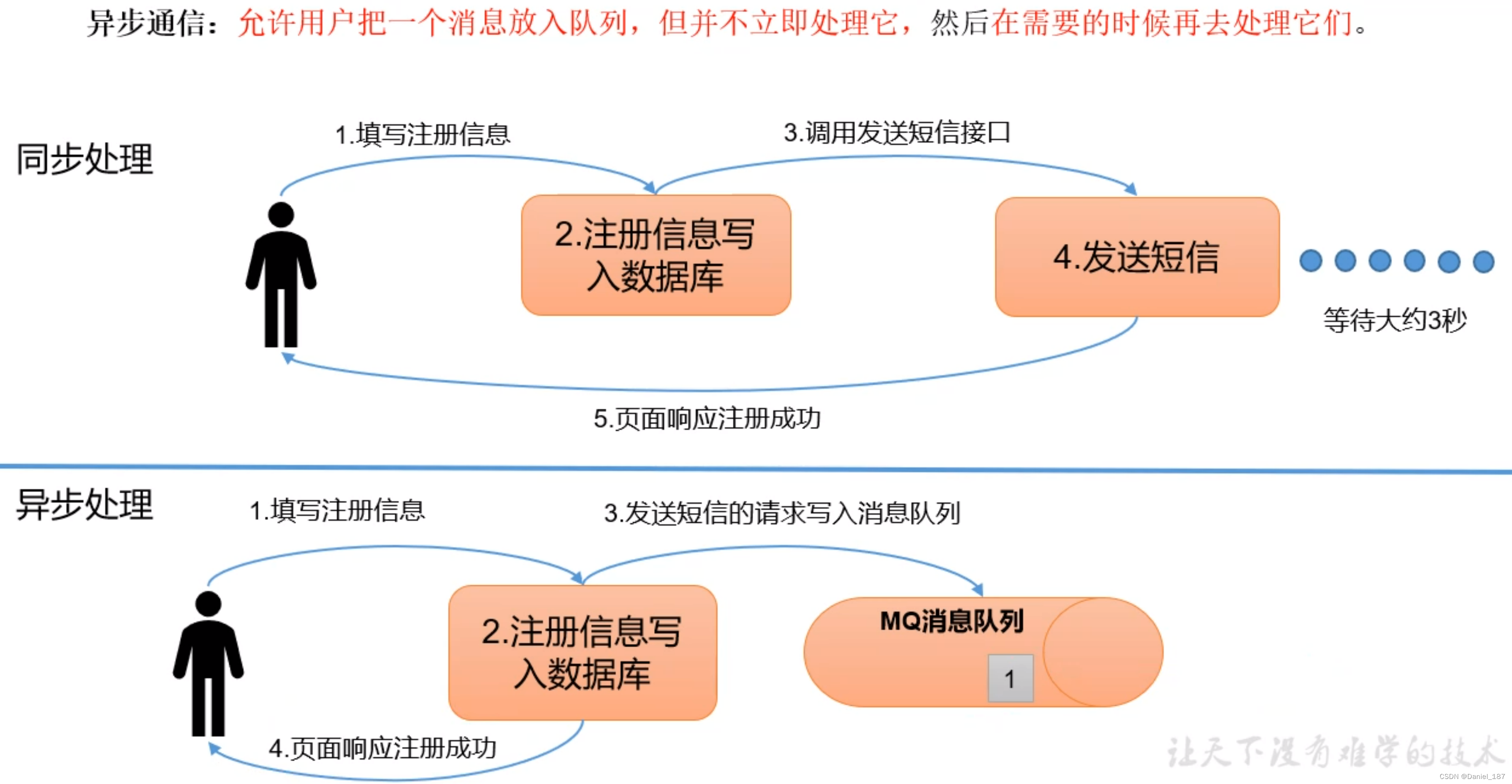
消息队列应用场景:缓存/消峰、解耦、异步通信
消峰:
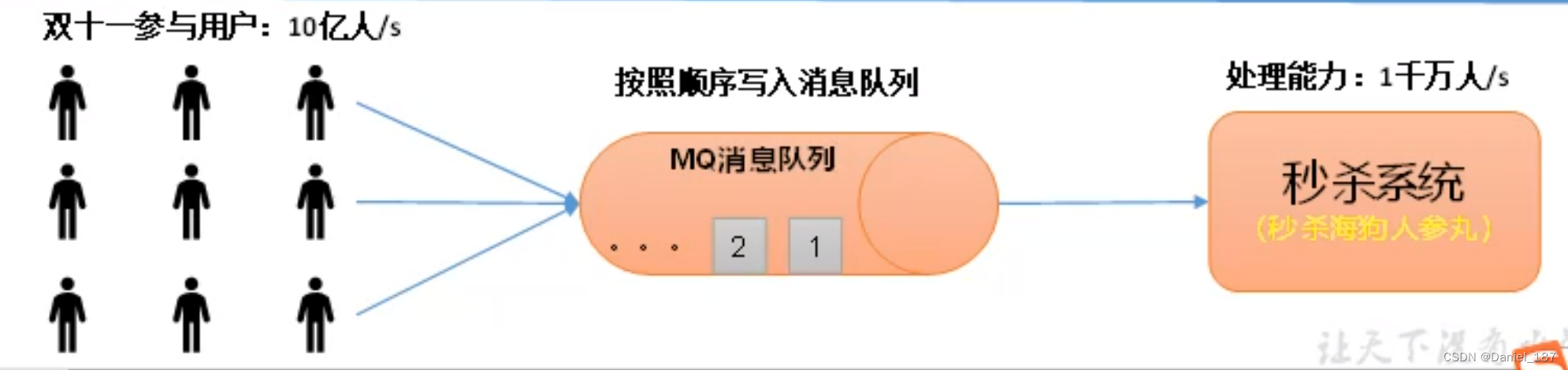
秒杀系统:10亿人发请求(数据量约为 1T)全部存入消息队列,服务端只取前 100 条数据处理,避免了服务端压力过大
解耦:
异步通信:
发布订阅模式:
Kafka 基础架构
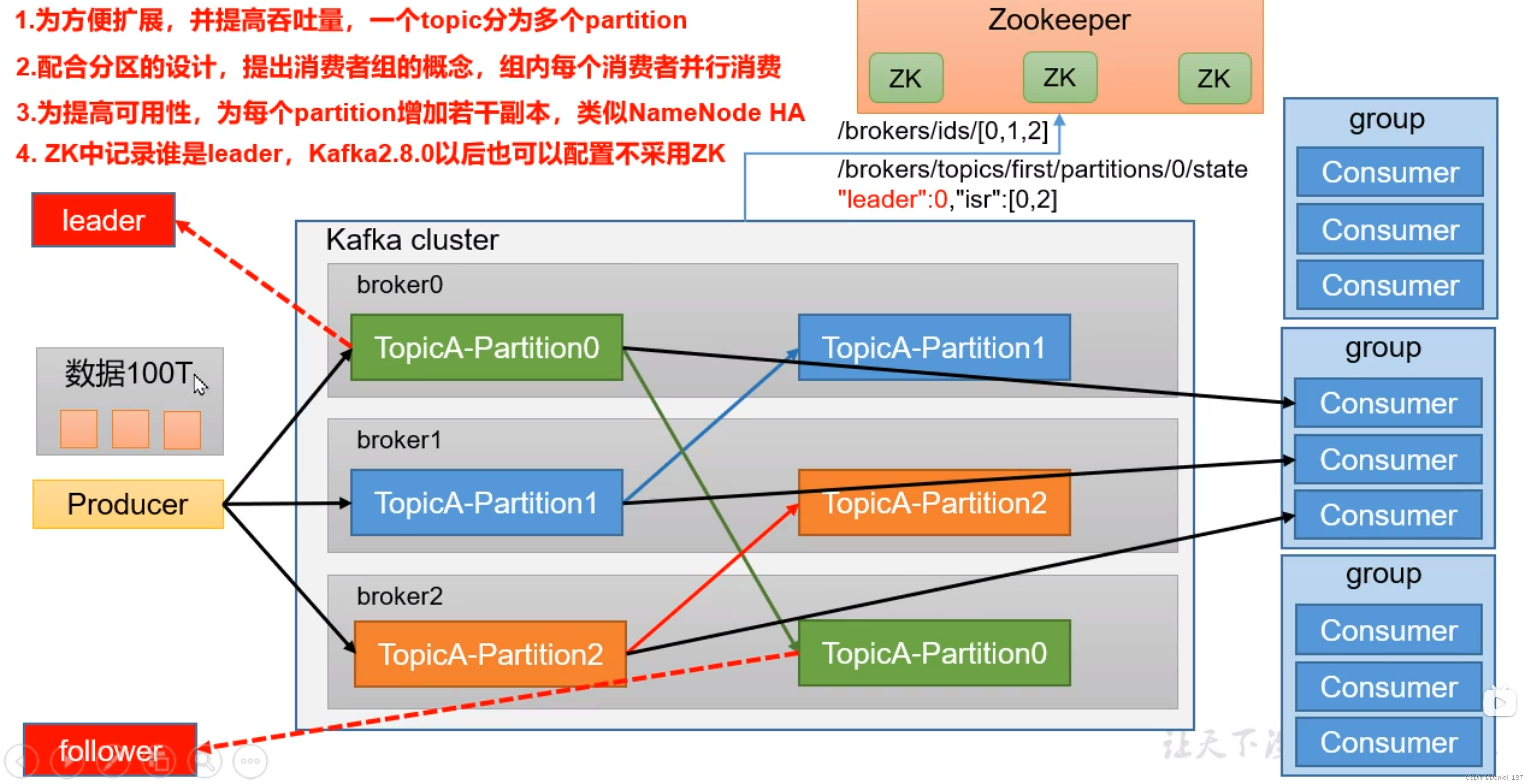
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响
Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成,一个 broker 可以容纳多个 topic
Topic:可以理解为一个队列,生产者和消费者面向的都是一个 Topic
Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker 上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列
Replica:副本。一个 topic 的每个分区都有若干副本,一个 Leader 和若干 Follower
Kafka 快速入门
安装部署
cd /opt/software/
wget https://downloads.apache.org/kafka/3.6.1/kafka_2.12-3.6.1.tgz
tar -zxvf kafka_2.12-3.6.1.tgz -C /opt/module
下载到 /opt/software 目录,然后解压到 /opt/module 目录,最后修改配置文件 server.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0# A comma separated list of directories under which to store log files
log.dirs=/opt/module/kafka_2.12-3.6.1/datas
zookeeper.connect=u22a:2181,u22b:2181,u22c:2181
先启动 zookeeper,再启动 kafka
bin/kafka-server-start.sh -daemon ../config/server.properties
bin/kafka-server-stop.sh
集群启停脚本:
#! /bin/bashcase $1 in
"start") {for i in u22a u22b u22c; doecho "-------- start $i kafka --------"ssh $i "/opt/module/kafka_2.12-3.6.1/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.12-3.6.1/config/server.properties"done
};;
"stop") {for i in u22a u22b u22c; doecho "-------- stop $i kafka --------"ssh $i "/opt/module/kafka_2.12-3.6.1/bin/kafka-server-stop.sh"done
};;
esac
kafka 命令行操作
主题命令行操作:
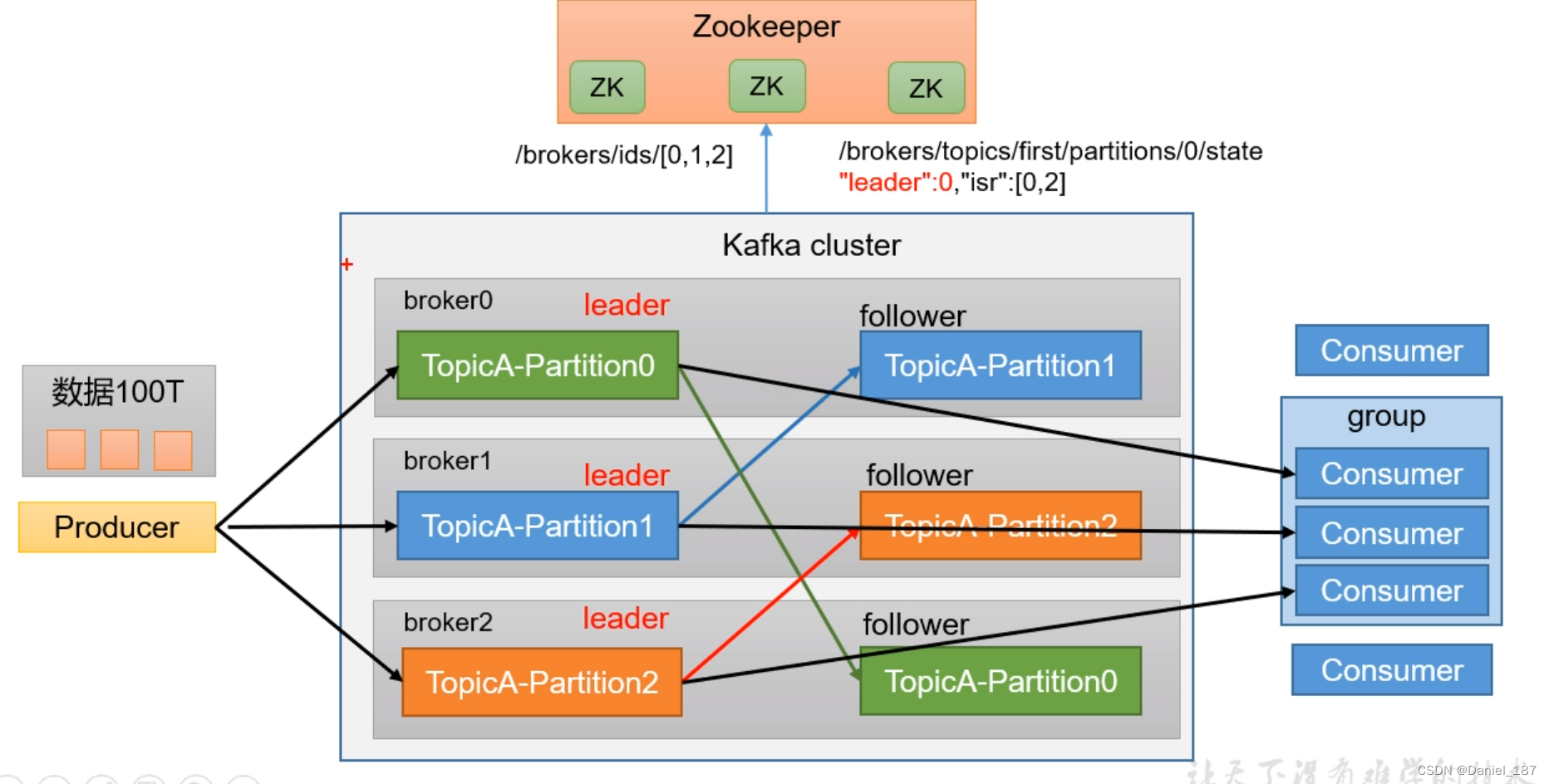
$ ./kafka-topics.sh --bootstrap-server u22b:9092 --list$ ./kafka-topics.sh --bootstrap-server u22b:9092 --create --topic first --partitions 3 --replication-factor 2
Created topic first.$ ./kafka-topics.sh --bootstrap-server u22b:9092 --describe --topic first
Topic: first TopicId: nSI1J7EWQ06EbmQkLTBpYg PartitionCount: 3 ReplicationFactor: 2 Configs:Topic: first Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1Topic: first Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0Topic: first Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2$ ./kafka-topics.sh --bootstrap-server u22b:9092 --delete --topic first
$ ./kafka-topics.sh --bootstrap-server u22b:9092 --alter --topic first --partitions 6
分区个数只能改大不能改小
kafka 生产者消费者命令行操作:
$ ./kafka-console-producer.sh --bootstrap-server u22a:9092 --topic first
$ ./kafka-console-consumer.sh --bootstrap-server u22a:9092 --topic first
$ ./kafka-console-consumer.sh --bootstrap-server u22a:9092 --topic first --from-beginning
分组消费:
./kafka-console-producer.sh --bootstrap-server u22a:9092 --topic first --group kafka1
./kafka-console-consumer.sh --bootstrap-server u22a:9092 --topic first --group kafka1
如果使用时主题不存在,会自动创建
Kafka 架构深入
kafka 工作流程及文件存储机制
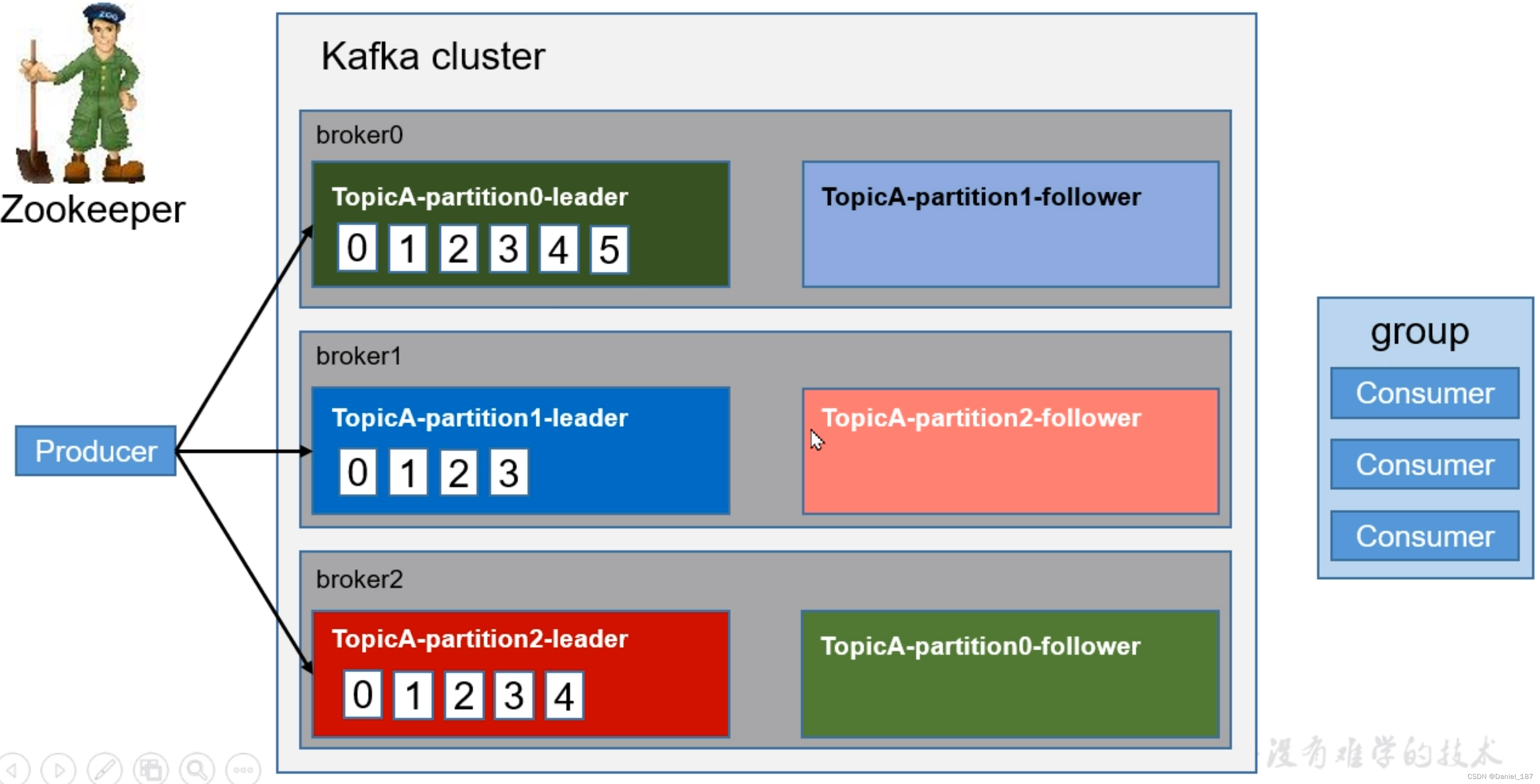
一个 topic 下的每一个分区都单独维护一个 offset,所以分发到不同分区中的数据是不同的数据。消费者的分区维护的是一个消费者组一个主题的一个分区维护一个 offset
同一个消费者组能够支持断点续传:
$ ./kafka-console-consumer.sh --bootstrap-server u22a:9092 --topic first --group kafka1
$ ./kafka-console-producer.sh --bootstrap-server u22a:9092 --topic first

文件存储机制:
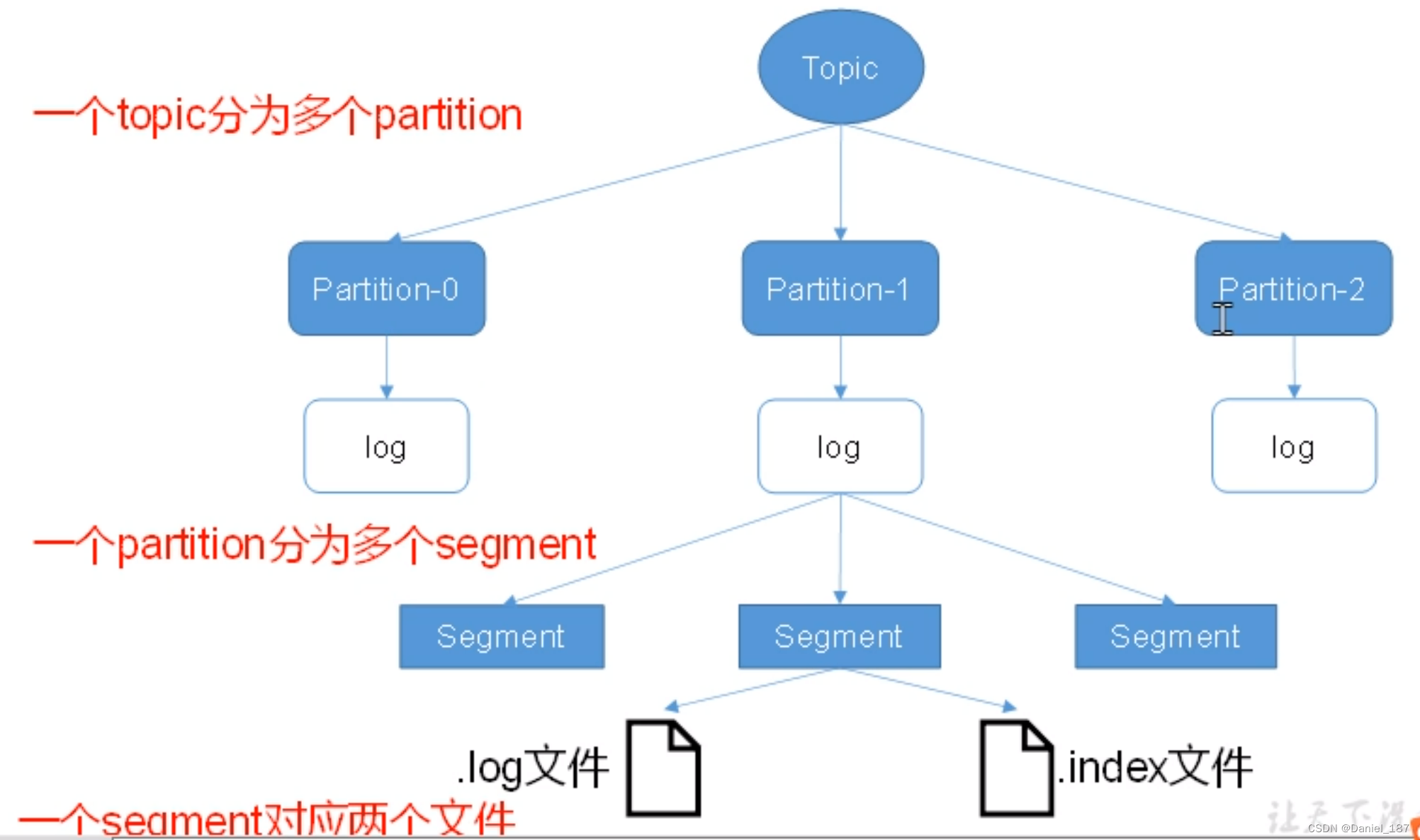

index 和 log 文件以当前 segment 的第一条消息的 offset 命名
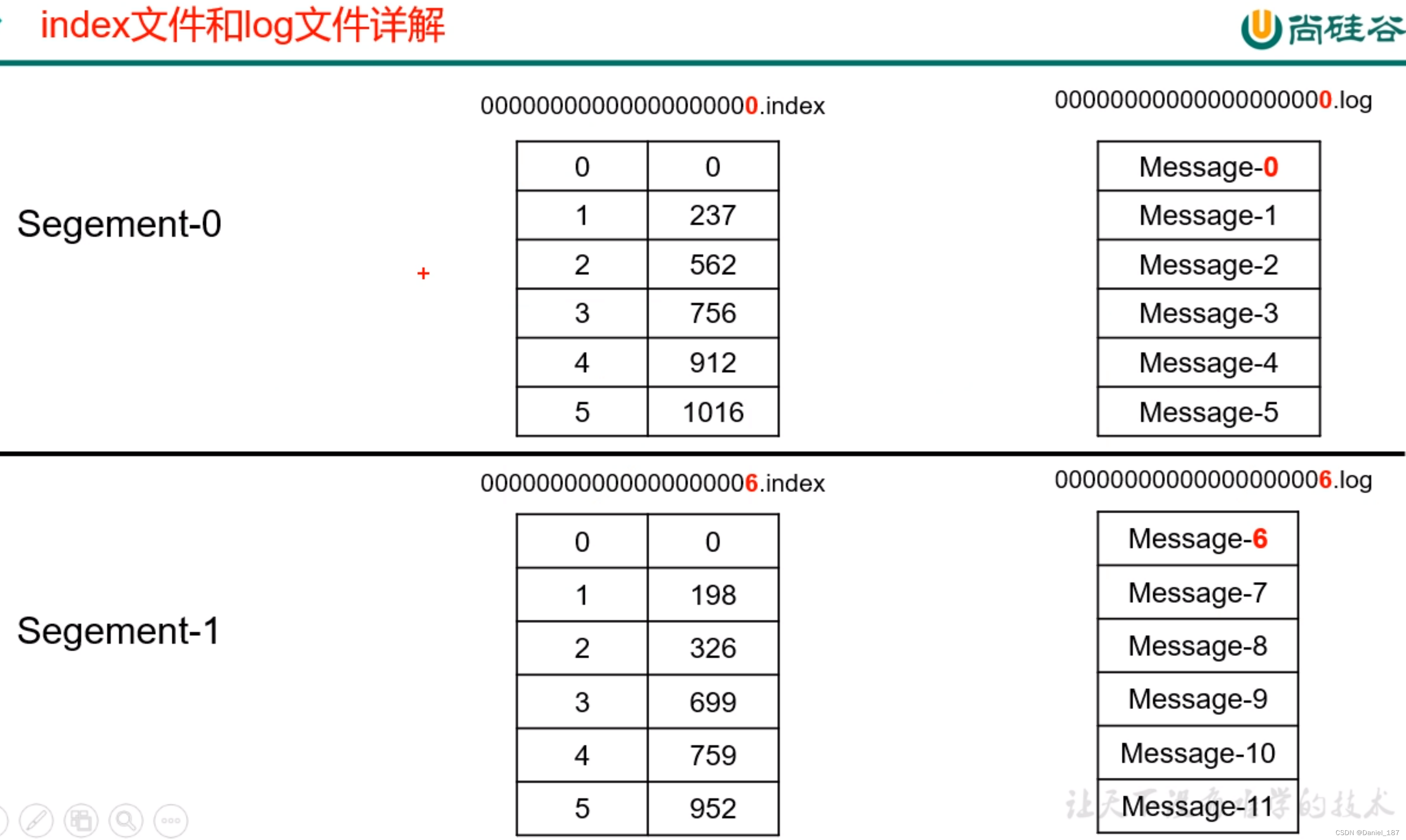
index 文件存储索引信息,索引信息按照数组逻辑排列。log 文件存储数据,数据直接紧密排列,索引文件中的元数据指向对应数据文件中的 message 的物理偏移地址
Kafka 生产者
消息发送流程

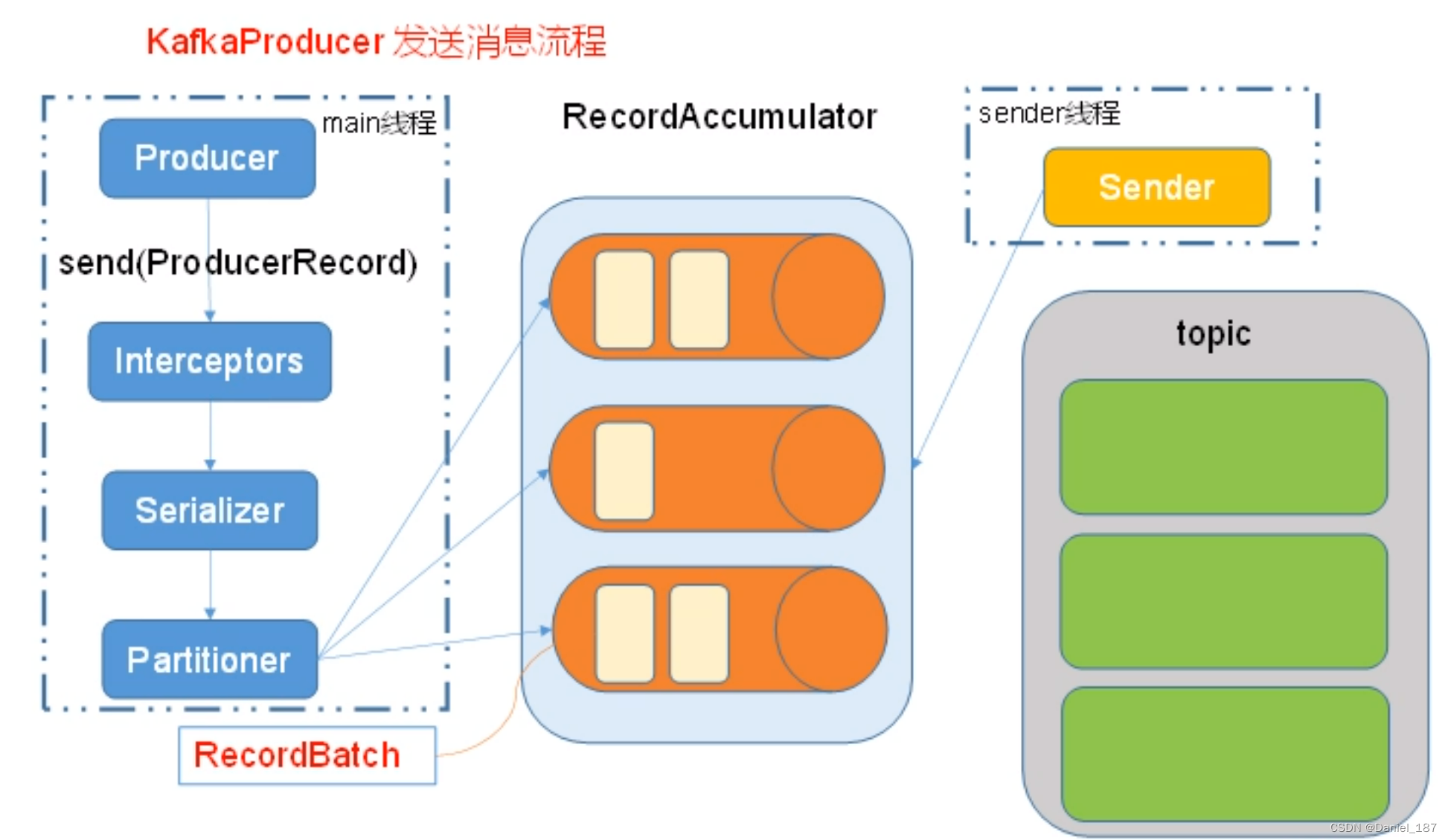
相关参数:
batch.size:只有数据积累到 batch.size 之后,sender 会发送数据
linger.ms:如果数据迟迟未达到 batch.size,sender 等待 linger.time 之后就会发送数据
异步发送 API
package com.atguigu.kafka.producer;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class CustomProducer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "u22a:9092");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);for (int i = 0; i < 10; i++) {//ProducerRecord<K, V>(totpic, value);producer.send(new ProducerRecord<String, String>("first", "atguigu " + i));}producer.close();}
}
在终端监视:
$ ./kafka-console-consumer.sh --bootstrap-server u22a:9092 --topic first --group kafka1
atguigu 0
atguigu 1
atguigu 2
atguigu 3
atguigu 4
atguigu 5
atguigu 6
atguigu 7
atguigu 8
atguigu 9
producer 在关闭之前会 flush 缓冲区
public class CustomProducer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "u22a:9092");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 非必要参数properties.put("batch.size", 16384);properties.put("linger.ms", 1);properties.put("buffer.memory", 33554432);KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);for (int i = 0; i < 10; i++) {producer.send(new ProducerRecord<String, String>("first", "atguigu " + i));}producer.close(); // flush}
}
生产者有回调函数的 API:
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class CustomProducerWithCallBack {public static void main(String[] args) {Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "u22a:9092");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 非必要参数properties.put("batch.size", 16384);properties.put("linger.ms", 1);properties.put("buffer.memory", 33554432);KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);for (int i = 0; i < 10; i++) {producer.send(new ProducerRecord<String, String>("first", "atguigu " + i), new Callback() {// 匿名子类:直接重写接口中的方法@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {// 发送消息成功,收到 ack 时调用// 发送消息遇到异常,也会调用if (e != null) {e.printStackTrace();} else {System.out.println("get ack from " + recordMetadata.topic() + ": "+ recordMetadata.partition() + ": " + recordMetadata.offset());}}});}producer.close(); // flush}
}
同步发送 API
send() 函数返回一个 Future 对象,直接对其调用 get() 方法即可同步调用
public class CustomProducerWithCallBackSync {public static void main(String[] args) throws ExecutionException, InterruptedException {Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "u22a:9092");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 非必要参数properties.put("batch.size", 16384);properties.put("linger.ms", 1);properties.put("buffer.memory", 33554432);KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);for (int i = 0; i < 10; i++) {producer.send(new ProducerRecord<String, String>("first", "atguigu " + i), new Callback() {// 匿名子类:直接重写接口中的方法@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {// 发送消息成功,收到 ack 时调用// 发送消息遇到异常,也会调用if (e != null) {e.printStackTrace();} else {System.out.println("get ack from " + recordMetadata.topic() + ": "+ recordMetadata.partition() + ": " + recordMetadata.offset());}}}).get();System.out.println("send " + i);}producer.close(); // flush}
}
分区策略
- 指明 partition 的情况下,直接将指明的值作为 partition 的值
- 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值
- 既没有 partition 值也没有 key 值的情况下,kafka 采用 Sticky Partition,随机选择一个分区,并尽可能一直使用该分区,待该分区的 batch 已满或者已完成,kafka 再随机选择一个分区使用
指定分区:
for (int i = 0; i < 10; i++) {producer.send(new ProducerRecord<String, String>("first", 0, "", "atguigu " + i), new Callback() {// 匿名子类:直接重写接口中的方法@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {// 发送消息成功,收到 ack 时调用// 发送消息遇到异常,也会调用if (e != null) {e.printStackTrace();} else {System.out.println("get ack from " + recordMetadata.topic() + ": "+ recordMetadata.partition() + ": " + recordMetadata.offset());}}});}
自定义分区器
// CustomPartitioner.java
public class CustomPartitioner implements Partitioner {public static void main(String[] args) throws InterruptedException {}@Overridepublic int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {String s1 = o1.toString();if (s1.contains("atguigu")) {return 1;}return 0;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> map) {}
}
在生产者中注册分区器即可:
// 注册使用自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.atguigu.kafka.partition.CustomPartitioner");
数据可靠性
数据可靠性:ack + 全同步机制
为了保证 producer 发送的数据能可靠的发送到指定的 topic,topic 的每个 partition 收到 producer 发送的数据后,都需要向 producer 发送 ack,如果 producer 收到 ack,就会进行下一轮发送,否则重新发送
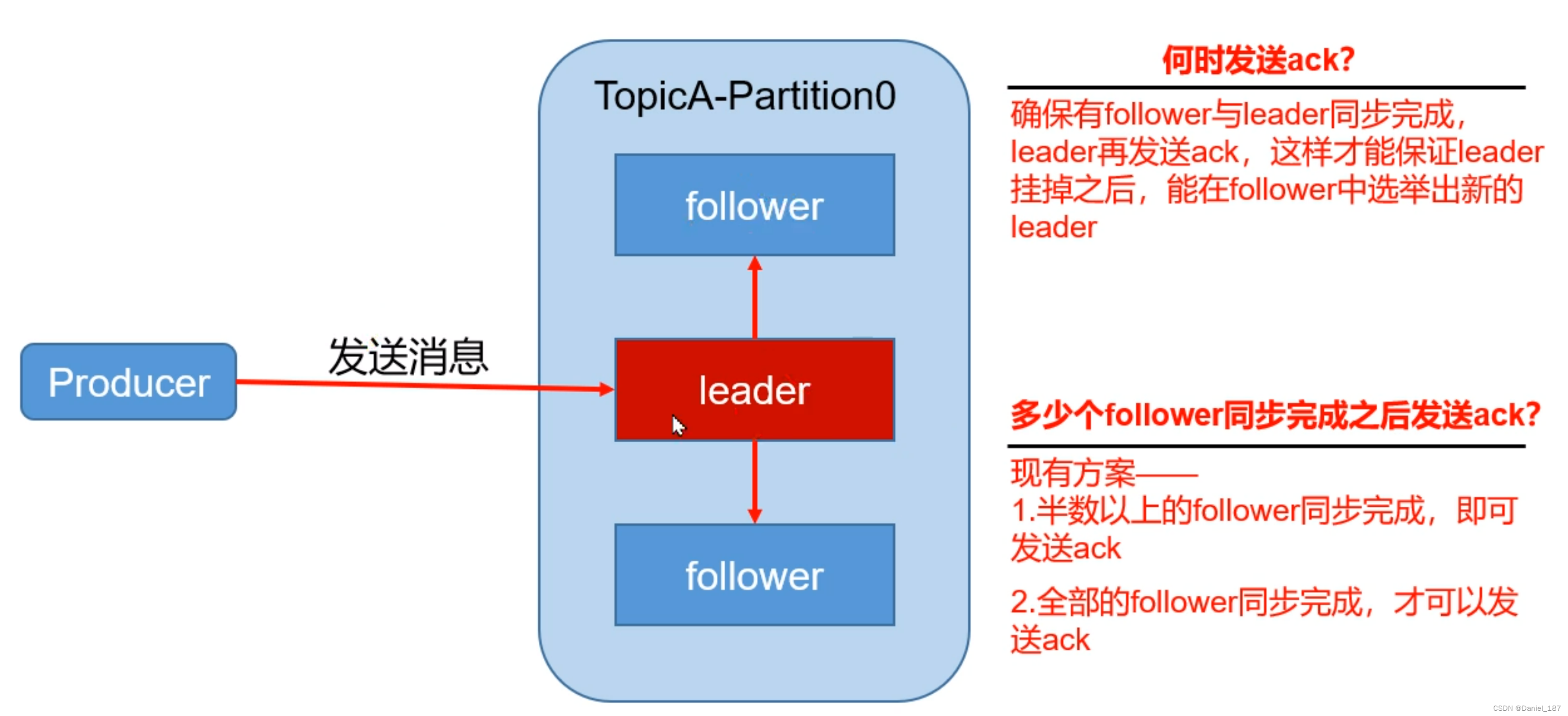
kafka 选用了第二种方案,虽然它受到网络延迟的影响,但是由于集群一般位于同一个局域网,网速对 kafka 的影响比较小
第二种方案带来一个问题:如果有一个 follower 单点故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去。为此,kafka 引入了 ISR:in-sync replica set

在不同的时间点回复 ack 会影响速度和数据可靠性,这个级别可以通过参数 acks 配置:
- 0:partition 的 leader 接收到消息还没写入磁盘就返回 ack,当 leader 故障就会丢失数据,但是这样延迟最低
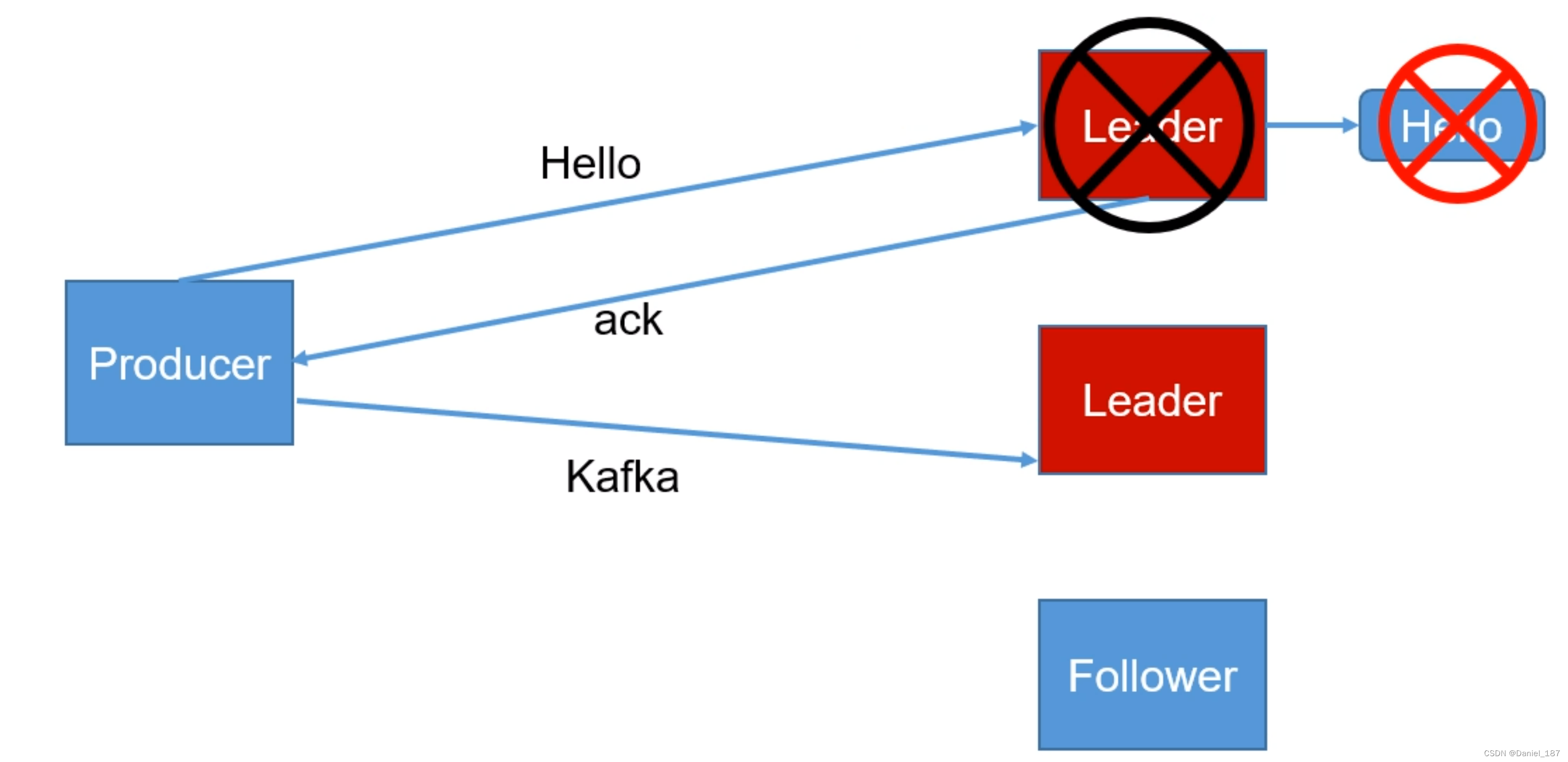
- 1:partition 的 leader 接收到消息落盘成功后回复 ack,如果在 follower 同步成功之前 leader 故障,会丢失数据
- -1:全部落盘成功才回复 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会造成数据重复
注意 acks == 1 的情况,数据还存在原 leader 的磁盘里没有丢失,但是因为选举机制,新的 leader 无法感知原数据的存在,从整个系统来看,数据丢失了:
数据重复的情况:
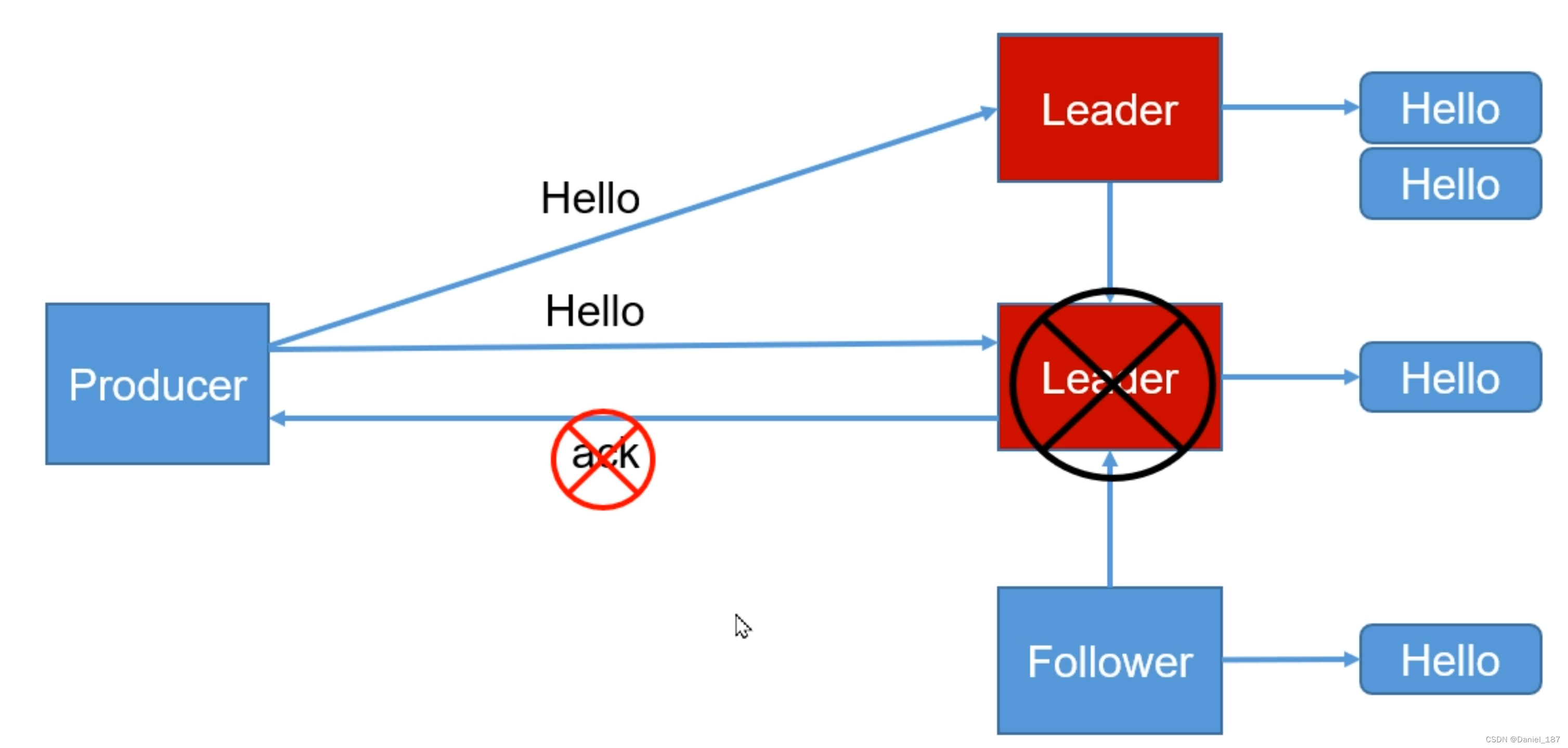
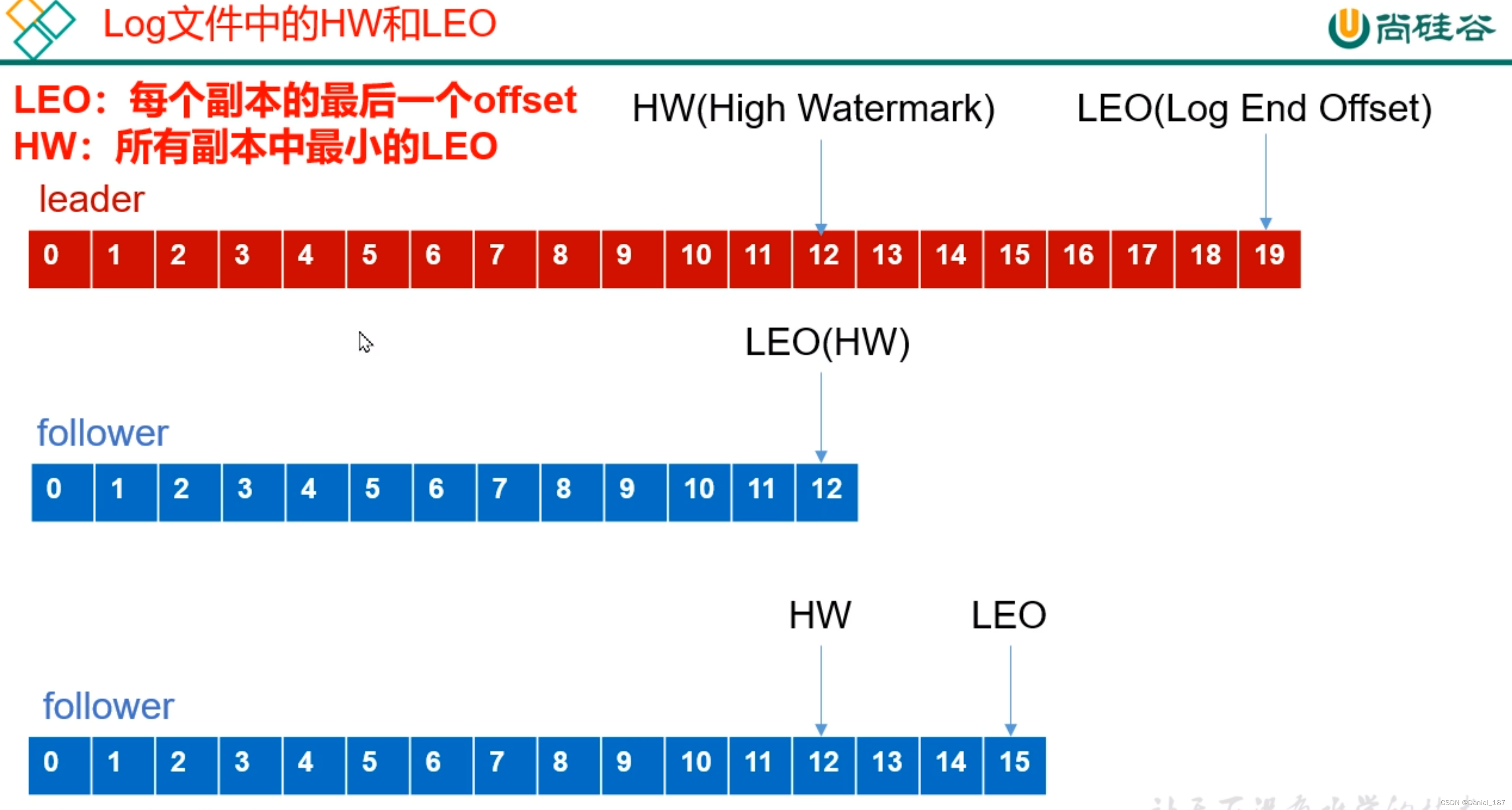
将各自 log 文件高于 HW 的部分截掉,然后从新的 leader 同步数据
Eaxctly Once

Producer 事务

Kafka 消费者
消费方式

基础消费者
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "u22a:9092");properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// 必须设置消费者组: --group kafka2properties.put(ConsumerConfig.GROUP_ID_CONFIG, "kafka2");KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);// 注册主题: --topic firstArrayList<String> strings = new ArrayList<>();strings.add("first");kafkaConsumer.subscribe(strings);while(true) {// 设置超时等待时长ConsumerRecords<String, String> res = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> r : res) {System.out.println(r.toString());}}}
}
消费者组
同一个主题的分区,同一时刻只能有一个消费者消费
重新发送到一个全新的主题中,由于默认创建的主题分区数为 1,可以看到只有一个消费者消费到数据
分区分配策略
一个消费者组中有多个消费者,一个主题下有多个分区,所以必然会涉及到分区的分配问题,即确定哪个分区由哪个消费者消费
kafka 有 3 种分配策略:RoundRobin,Range 和 Sticky。默认使用 Range 分区器
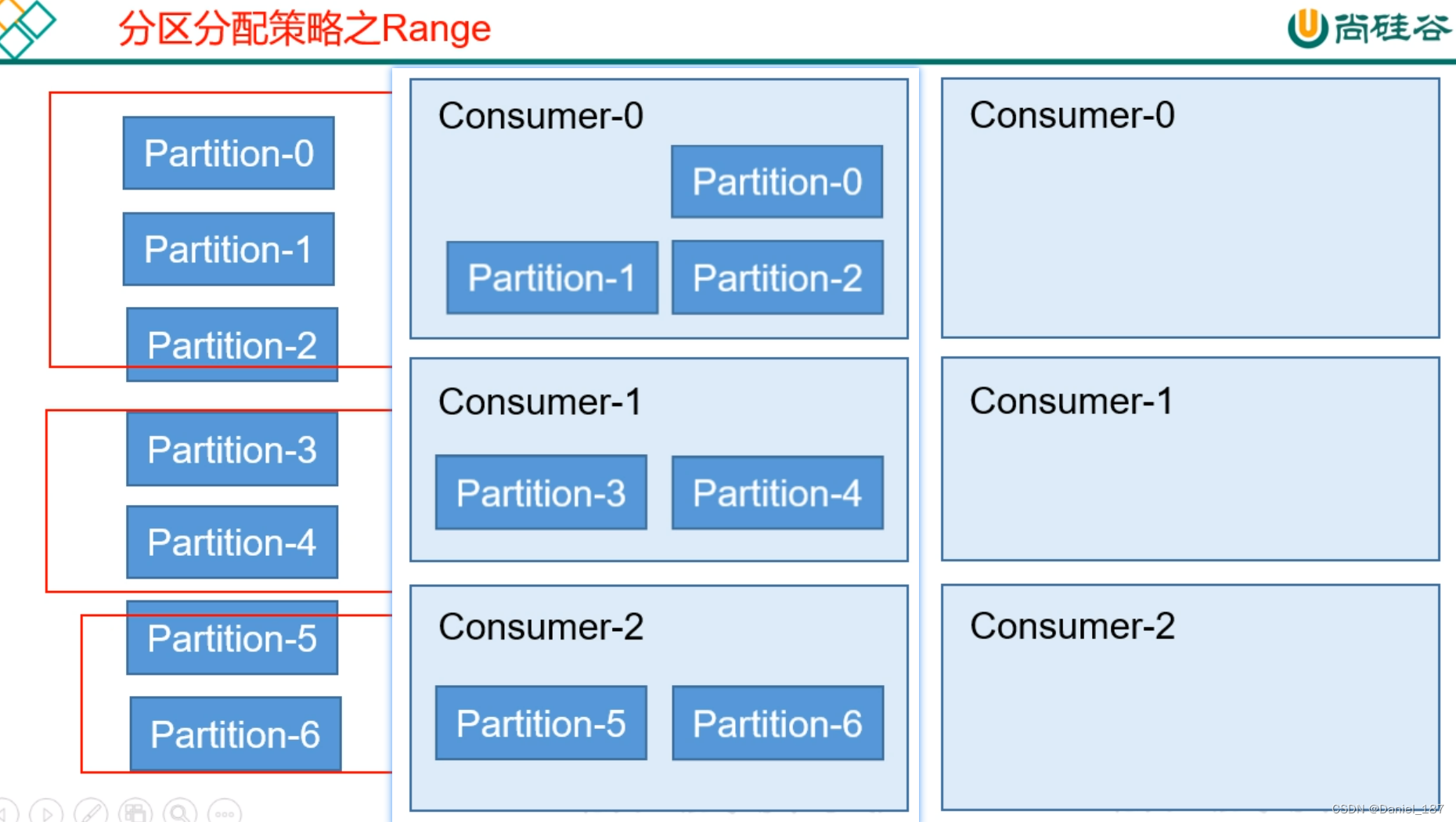
更改分区分配策略:
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.RoundRobinAssignor");
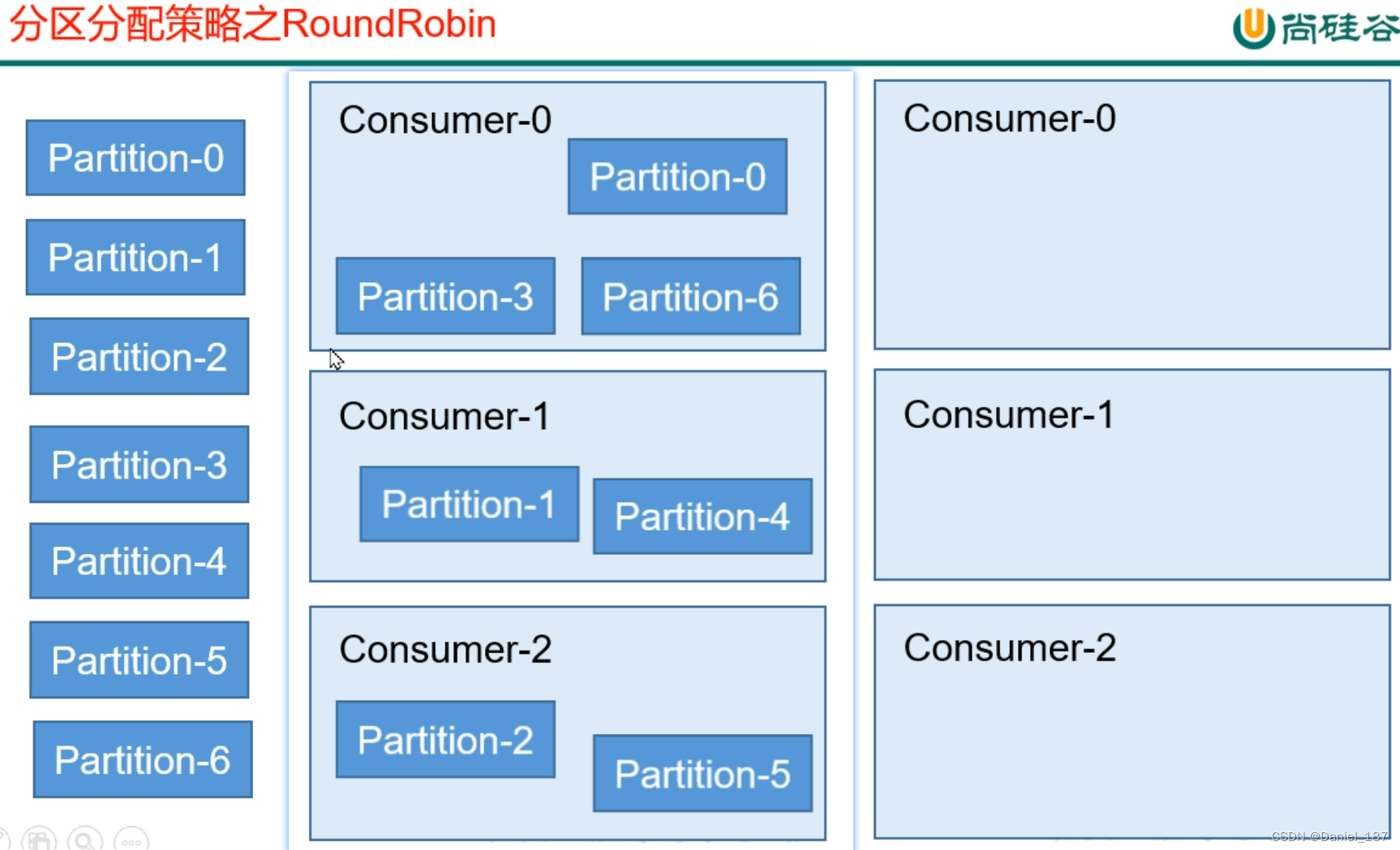
粘性分区分配策略(StickyAssignor),首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化
offset 的维护
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个 ofset,以便故障恢复后继续消费
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中。从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka一个内置的 topic 中,该topic为 __consumer_offsets
查看该主题:
先修改配置文件,增加配置项 exclude.internal.topics=false
./bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server u22b:9092 --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
自动提交 offset
- enable.auto.commit:是否开启自动提交 offset
- auto.commit.interval.ms:自动提交 offset 时间间隔
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
重置 offset
auto.offset.reset = earliest | latest | none
当 kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时
如果一直使用同一个消费者组,会触发断点续传,能够消费到之前的数据
如果使用一个新的消费者组来消费,会触发 offset 重置,相当于 from beginning
// 新的消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "kafka3");
// 一旦使用新的消费者组,重置 offset
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
手动提交 offset
如果自动提交 offset,会在内存中拉取到数据的时候就完成 offset 的提交
ConsumerRecords<String, String> res = kafkaConsumer.poll(Duration.ofSeconds(1));
手动提交 offset 的方法有 2 种,分别是 commitSync(同步提交)和 commitAsync (异步提交)
二者的相同点是,都会将本次 poll 的一批数据最高的偏移量提交
不同点是,commitSync 会阻塞当前线程,一直到提交成功,并且失败后会自动重试
commitAsync 没有失败重试机制,故有可能提交失败
首先关闭自动提交的配置参数:
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
ConsumerRecords<String, String> res = kafkaConsumer.poll(Duration.ofSeconds(1));// kafkaConsumer.commitSync(); // 同步提交kafkaConsumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {if (e != null) {e.printStackTrace();} else {System.out.println(map);}}}); // 异步提交,更高效
Consumer 事务(精准一次性消费)
kafka 消费端将消费过程和提交 offset 过程做原子绑定
Kafka 高效读写数据
顺序写磁盘:写的过程是一直追加到文件末端,为顺序写

零拷贝技术:
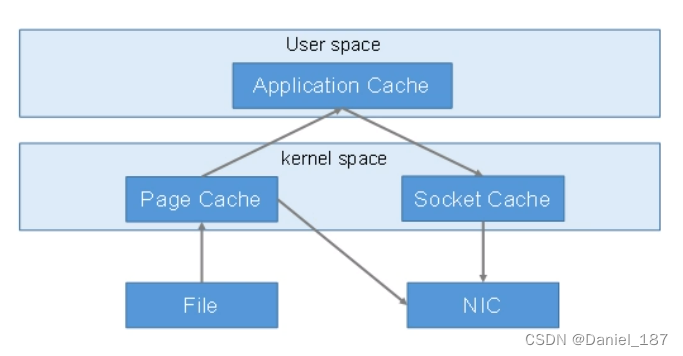
Zookeeper 在 Kafka 中的作用
Kafka 监控
安装:
cd /opt/software
wget https://github.com/smartloli/kafka-eagle-bin/archive/v3.0.1.tar.gz
tar -zxvf v3.0.1.tar.gz
cd kafka-eagle-bin-3.0.1/
tar -axvf efak-web-3.0.1-bin.tar.gz -C /opt/module/