文章目录
- 前言
- 笔记正文
- 大模型部署背景
- 部署挑战
- 部署方案
- LMDeploy框架
- 量化
- 推理引擎Turbomind
- 推理服务api server
前言
本文是对于InternLM全链路开源体系系列课程的学习笔记
【LMDeploy 大模型量化部署实践】 https://www.bilibili.com/video/BV1iW4y1A77P/?share_source=copy_web&vd_source=99d9a9488d6d14ace3c7925a3e19793e
笔记正文
大模型部署背景
- 内存开销巨大:7B模型仅权重就需要14+G内存;采用子回归生成token带来开销
- 动态shape:请求数、token数,不固定
- 结构简单,transfomer结构,且大部分是decoder-only
部署挑战
设备、推理、服务
部署方案

方案则是有很多的推理框架适用于不同运算端。
LMDeploy框架
很多这个框架的内容在第一节课程中已经讲解过了,本段主要讲解了这个框架的核心功能
量化
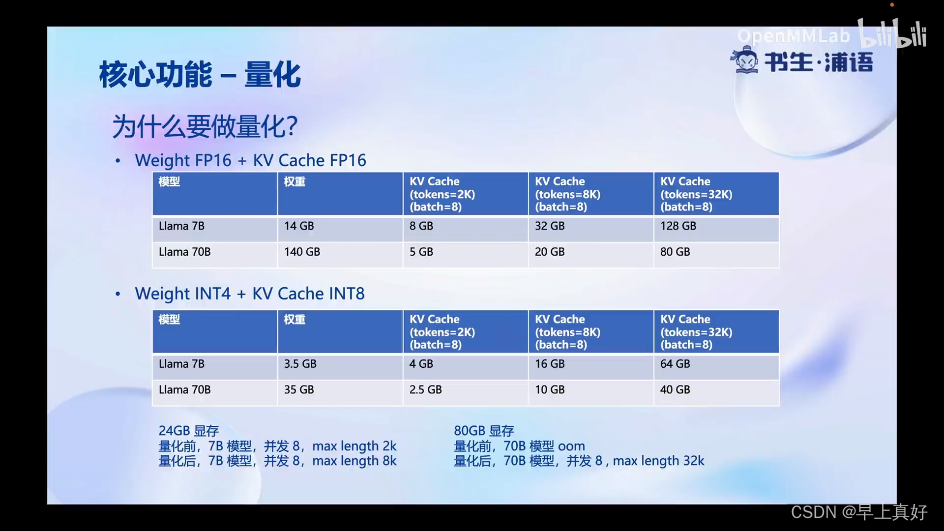
为什么做量化,首先就是显存。
然后为什么做权重的量化,因为这即降低了计算密集,又降低了访存密集,(因为数值的位数减少了且权重的大小减少了)。

如何去做:使用awq算法,比gptq算法的推理速度更快,量化的时间更短。
推理引擎Turbomind
- 持续批处理
- 有状态的处理
- 分块锁定KV缓存
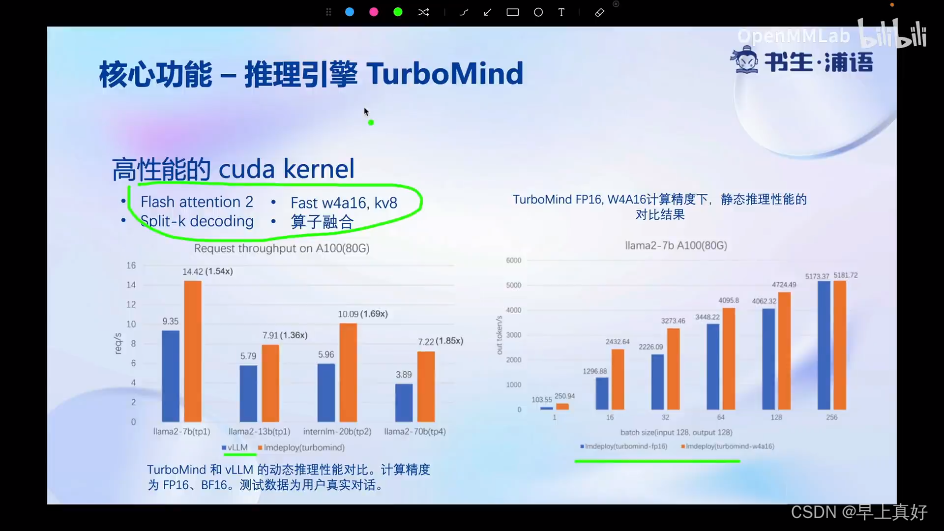
- 高性能cuda kernel
推理服务api server
可以通过lmdeploy很方便地启动api server用于调用。可以访问页面获取更多调用的格式的信息。
作业后面做。



![[Python进阶] 识别验证码](https://img-blog.csdnimg.cn/direct/aa9549fafa054cf5ae4c747ea7abee38.png)
