欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!
在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!

亿级数据量表SQL调优实战
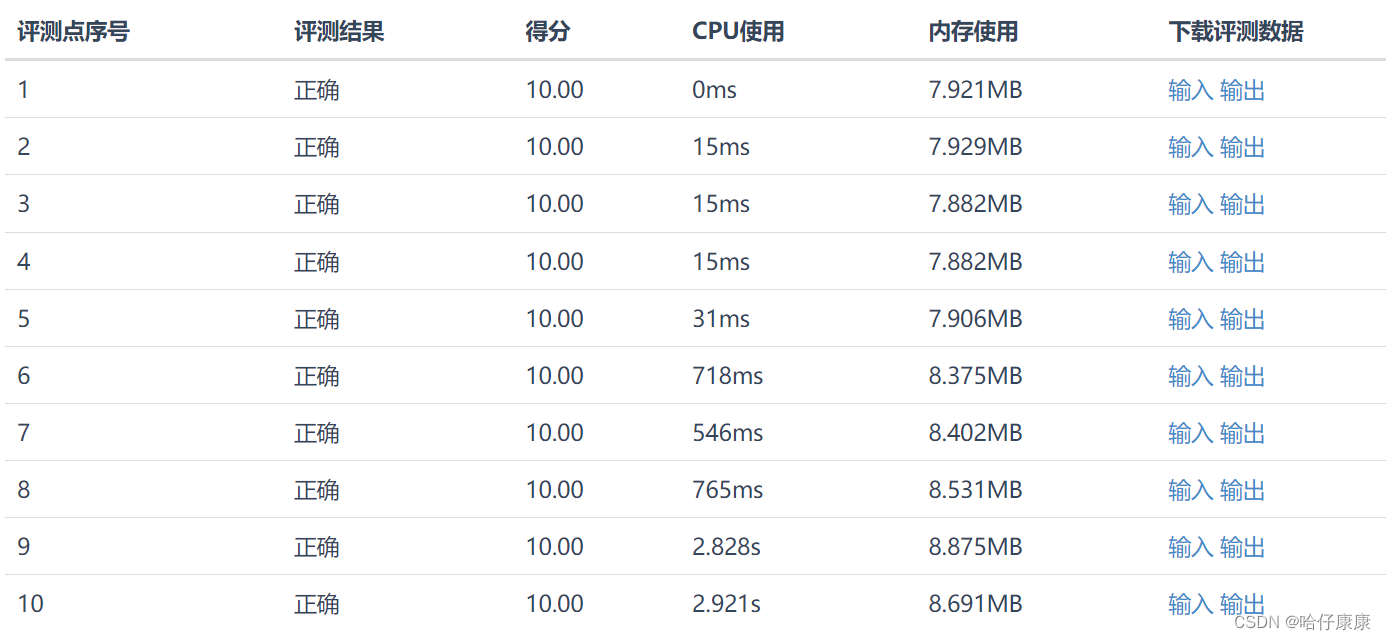
先说一下案例背景: 在电商平台中,有一个商品表,数据量级别上亿,有一天晚上突然出现大量的慢查询告警,导致每一个数据库连接执行慢查询耗费几十秒的时间,以至于数据库的连接被打满,无法建立新的连接,导致用户无法查询数据库中相关数据,相关的慢查询语句为:
select * from products where category = 'xx' and sub_category = 'xx' order by id desc limit xx, 10;
简化后的 SQL 语句如上,就是对商品表进行简单的查询,并且进行排序、分页处理
问题分析:
平常在运行的时候,并没有发现出现慢查询,因此 SQL 出现慢查询先查找代码有无提交,或者表中数据有无变化,经过查看,发现运营人员在商品分类表中新添加了几个分类,猜测和这个操作有关系!
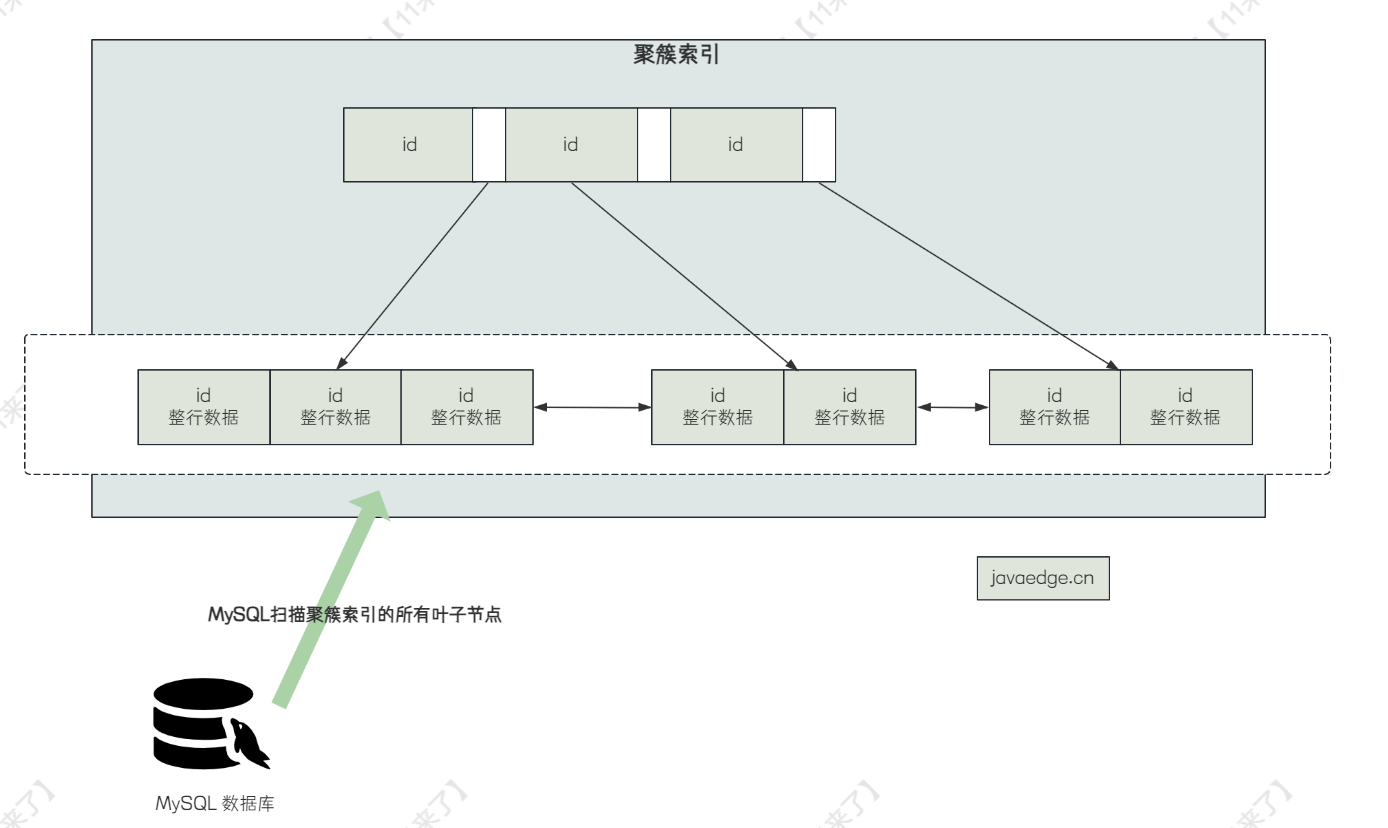
那么先查看 SQL 的执行计划,找到慢查询出现的原因,对 SQL 进行 explain 之后,发现执行计划中 possible_key = index_category 表示要使用 index_category 这个索引,但是在 key 这一列的值为 PRIMARY,说明并没有用到 category 这个索引,而是使用了聚簇索引,并且 Extra 列的值为 Using where,因此分析慢查询出现的原因为: 在聚簇索引上扫描数据,并且使用 where 条件对数据进行过滤导致 SQL 执行过慢
那么尝试一下强制让 SQL 走我们自己定义的 index_category 这个索引,发现 SQL 耗时仅仅上百毫秒,慢查询的现象消失了,因此问题就被解决了
通过 force index 就可以让 MySQL 强制走我们自己定义的索引,改变 MySQL 的执行计划!
问题原因:
既然问题解决了,接下来还要分析一下问题出现的原因,为什么 MySQL 不使用我们自己定义的 index_category 索引,而是去扫描聚簇索引呢?
这就是 MySQL 内部的优化,它认为使用了 index_category 这个索引之后,只能查出来索引数据+主键值,而 SQL 语句中是 select *,因此在扫描二级索引之后,还要根据主键值去聚簇索引中回表查询其他列的数据
因此性能不如直接去聚簇索引中扫描,直接根据 id 倒序扫描,取出来 10 条数据就可以了,这样会更快一些
那么 MySQL 优化之后,去聚簇索引中扫描反而出现了慢查询呢?
这就和上边说的运维人员在商品分类表中新添加了几个分类有关系了,由于这几个分类在商品表中没有对应数据,因此导致每一个用户来商品表查询这几个分类的商品时,都发现找不到对应的商品,因此每一次查询都会将整个聚簇索引给全部扫描一遍,上亿的数据,因此导致出现了慢查询!
所以说,这些问题在生产环境中都是无法避免的,因此一定要掌握 MySQL 中的执行计划,才可以通过执行计划找出 SQL 语句为什么执行速度太慢的原因!