SMedBERT:结构化语义知识 + 医学大模型 = 显著提升医学文本挖掘任务性能
- 名词解释
- 结构化语义知识
- 预训练语言模型
- 医学文本挖掘任务
- 提出背景
- 具体步骤
- 提及-邻居混合注意力机制
- 实体嵌入增强
- 实体描述增强
- 三元组句子增强
- 提及-邻居上下文建模
- 域内词汇权重学习
- 领域自监督任务预训练
- SMedBERT 图示
- 左半部分:SMedBERT架构
- 右半部分:预训练任务
- 方法部分
- 数学部分
- 效果
论文:https://arxiv.org/pdf/2108.08983.pdf
代码:https://github.com/MatNLP/SMedBERT
名词解释
结构化语义知识
结构化语义知识是指以组织良好的形式(如知识图谱、数据库、分类体系等)存储的信息,这些信息明确描述了实体(如人、地点、事物)之间的关系以及实体的属性和类别。
在结构化语义知识中,数据不仅仅是被保存,还被赋予了明确的意义和上下文,使得机器可以理解和处理复杂的关系和属性。
例如,医学知识图谱可能会包含不同疾病、症状、药物和治疗方法的实体,以及这些实体之间的关系(如“引起”、“治疗”、“副作用”等)。
这种知识的结构化形式使得机器能够执行更加复杂的推理任务,从而支持高级的数据分析和决策制定。
预训练语言模型
预训练语言模型是使用大量文本数据训练的模型,旨在捕捉语言的通用特征和结构。
这些模型在没有特定任务指导的情况下进行训练,学习词汇、短语、句子甚至长文本的表示,以及它们之间的语义和语法关系。
预训练完成后,模型可以在特定的下游任务(如文本分类、情感分析、问答系统等)上进行微调,以提高任务的性能。
代表性的预训练语言模型包括BERT、GPT、RoBERTa等,这些模型通过学习大规模文本语料库中的语言规律,能够有效地理解和生成人类语言。
医学文本挖掘任务
医学文本挖掘是指使用计算机算法从医学文献、临床记录、病历报告等文本中提取、分析和理解有用信息的过程。
这些任务包括但不限于:
- 命名实体识别(NER): 识别文本中的医学实体,如疾病、症状、药物等。
- 关系提取: 确定文本中实体之间的关系,例如识别哪种药物用于治疗哪种疾病。
- 文献检索: 在大规模医学文献数据库中检索与特定查询相关的文档。
- 问答系统: 根据用户的自然语言问题提供准确的答案,这些问题通常与医疗健康状况、治疗方案等相关。
医学文本挖掘的目标是从医学文本中自动提取知识,支持临床决策、医学研究和患者护理等活动。
这些任务通常面临医学术语的复杂性、文本的多样性和专业性等挑战。
提出背景
- 问题1: 预训练语言模型(PLMs)在处理医学文本时,难以捕获医学术语之间复杂的关系和医学事实。
- 背景: 医学领域存在大量的专业术语及其复杂关系,这些细节仅仅通过文本是难以充分理解的。
- 问题2: 现有的知识增强预训练语言模型(KEPLMs)主要关注于实体及其直接链接,忽略了实体之间的结构化语义信息。
- 背景: 医学术语间不仅仅是简单的链接,还包括了类型、关系等丰富的结构化信息,这对于理解医学文本至关重要。
以“视网膜病变”为例,在医学领域,"视网膜病变"不仅是一个单独的医学术语,它与多种因素和疾病有着复杂的关联。
例如,视网膜病变可能由糖尿病(特别是糖尿病视网膜病变)、高血压、遗传疾病等多种原因引起。
每一种原因都代表了与"视网膜病变"有着不同类型关系的实体。
在传统的KEPLMs处理过程中,模型可能识别“视网膜病变”作为一个实体,并可能将其与“糖尿病”通过“导致”这样一个直接链接关联起来。
这种处理忽略了以下几个方面的结构化语义信息:
-
类型信息: “视网膜病变”不仅是由糖尿病引起的,它可以分为多种类型,如糖尿病视网膜病变、高血压视网膜病变等,每种类型的病变与特定的疾病或条件有关。
-
关系多样性: 除了“导致”关系,视网膜病变与其原因之间还可能存在其他类型的关系,如“并发于”糖尿病等。此外,视网膜病变的存在可能影响到患者的视力,这种“影响”关系也是重要的结构化信息。
-
关联实体的属性: 涉及视网膜病变的实体(如糖尿病)自身可能有多种属性,如病程阶段、控制情况等,这些属性也会影响视网膜病变的发展和治疗。
因此,在处理“视网膜病变”这类医学术语时,仅仅关注于实体及其直接链接的KEPLMs方法会丢失大量重要的结构化语义信息。
这种信息对于准确理解医学文本、进行准确的疾病诊断和制定有效的治疗计划至关重要。
例如,了解视网膜病变的具体类型和原因,可以帮助医生选择更加针对性的治疗方法,为患者提供个性化的医疗方案。
论文解法:
- 解法1: 提及-邻居混合注意力机制
“提及”指的是文本中直接出现的实体或概念,而“邻居”则指的是与这些文本提及相关联的知识图谱中的实体。
这种机制不仅关注于知识图谱内的实体关系,还特别关注于如何将这些关系与原始文本中的实体提及相结合,以增强模型的语义理解能力。
强调了两个关键方面的结合:文本中的实体提及(mentions)和这些提及在知识图谱中的邻居(neighbors)之间的信息融合。
- 特征: 为了克服知识噪声并有效利用实体类型和邻近实体信息,提及-邻居混合注意力机制融合了链接实体邻居的节点和类型嵌入到上下文目标提及表示中。
如在处理提到“糖尿病”和“视网膜病变”的文本时,传统模型可能仅识别这两个条件作为独立实体。
然而,使用提及-邻居混合注意力机制,模型不仅识别这些实体,而且还考虑到“糖尿病”作为一个实体可能与“视网膜病变”有直接的临床关联,即“糖尿病”是“视网膜病变”的一个常见原因。
这个机制会将“视网膜病变”作为“糖尿病”的一个邻居节点,并且考虑这种邻居关系的类型——在这个例子中是“导致”。
通过融合这些信息,模型能够更准确地捕捉到两个实体之间的关系,降低了由于缺乏深层次语义理解而导入的知识噪声。
- 解法2: 提及-邻居上下文建模
- 特征: 通过引入两种新颖的自监督学习任务(掩蔽邻居建模和掩蔽提及建模)来促进提及跨度与相应全局上下文之间的交互,从而丰富低频提及跨度的表示。
在同一文本中,提及-邻居上下文建模可以进一步提升模型对于“糖尿病”和“视网膜病变”及其相互关系理解的深度。
通过掩蔽邻居建模,模型学习预测与“糖尿病”直接相关的其他条件或并发症,如“视网膜病变”,基于其在医学知识图谱中的邻居实体。
同时,掩蔽提及建模任务鼓励模型从“糖尿病”与“视网膜病变”的关系中,反向学习到“糖尿病”本身的特性,如是什么类型的疾病,通常会引起哪些并发症等。
这种相互作用不仅丰富了模型对于低频实体“视网膜病变”的表示,还增强了对“糖尿病”这一高频实体深度语义的理解。
通过这两种解法,模型能够更全面和深入地理解医学文本中的复杂信息,提高医学文本挖掘的准确性和效率。
具体步骤
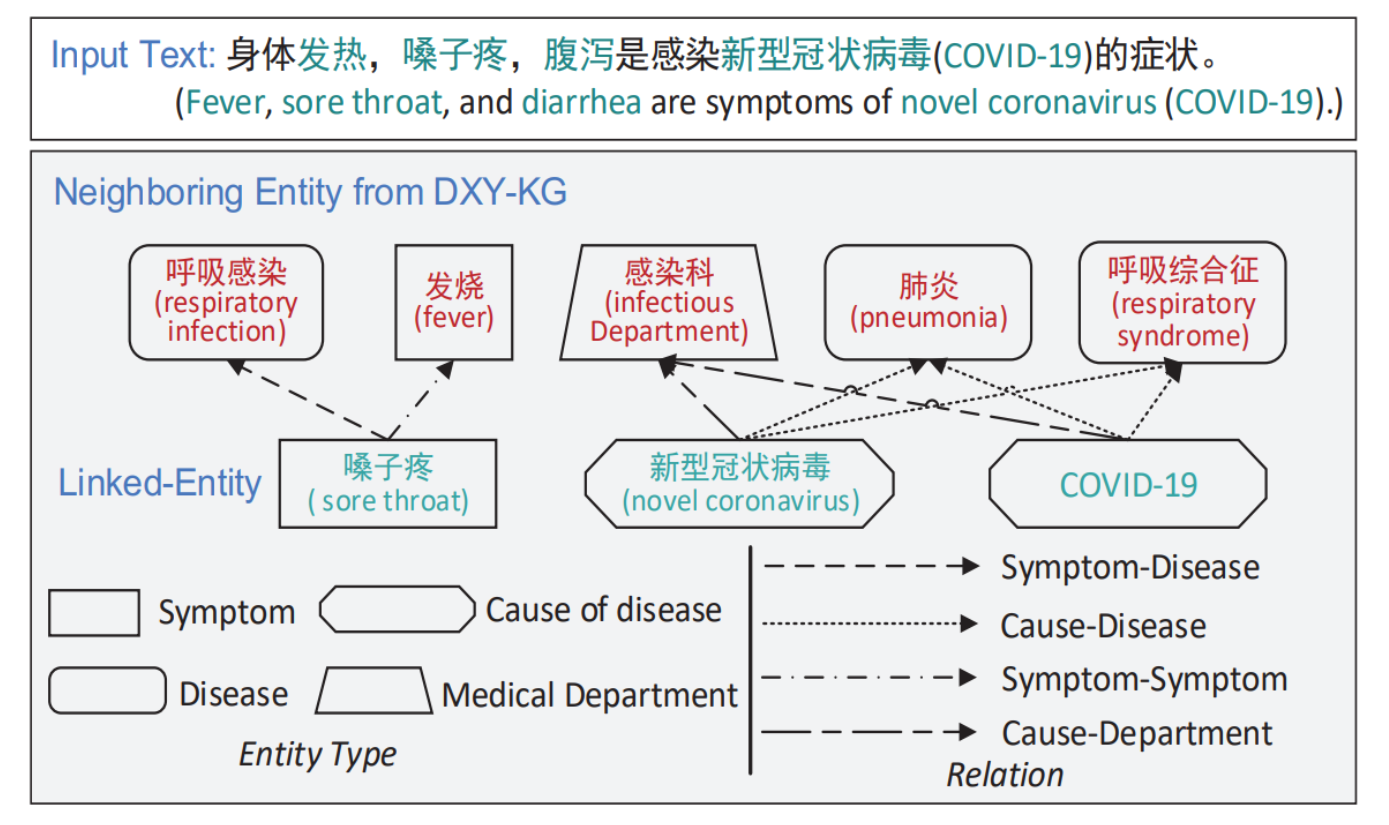
这张图通过一个具体的例子阐释了在医学文本中如何利用知识图谱(在本例中为DXY-KG)来识别和理解文本中提及的医学实体及其关系:
-
输入文本识别:
- 输入文本中的症状被列出:“发热、咽痛、腹泻是新型冠状病毒肺炎(COVID-19)的症状。”
- 这是一个非结构化数据的例子,其中包含了若干医学实体和它们之间的关系。
-
实体识别与分类:
- 在文本中识别出的实体例如“咽痛”被标注为症状类型。
-
知识图谱链接:
- 这些实体被链接到知识图谱中相应的实体上。
- 在本例中,“咽痛”被链接到了“新型冠状病毒”,表示它是由该病毒引起的症状。
-
邻居实体的探索:
- 从知识图谱中探索与“咽痛”相关联的其他实体,如“发热”、“肺炎”和“呼吸综合征”。
- 这些邻居实体与“咽痛”之间的关系被识别和标注。
-
关系类型定义:
- 图中定义了实体之间的不同关系类型,比如“症状-疾病”、“原因-疾病”、“症状-症状”和“原因-科室”。
-
可视化表达:
- 通过不同的线条(实线、虚线)和形状,这些实体和关系在图中被可视化。每种关系类型都有相应的图例说明,例如实线表示症状与疾病之间的直接联系。
提及-邻居混合注意力机制
实体嵌入增强
- 步骤1: 在一篇关于肺炎治疗的文章中,模型识别出“肺炎”、“抗生素”和“咳嗽”等实体。
- 步骤2: 使用TransE算法为这些实体生成向量表示,捕捉它们在知识图谱中的位置和关系。
- 步骤3: 在模型的注意力机制中融合这些向量表示,使得在处理与肺炎相关的文本时,模型能够更好地理解“抗生素”是治疗“肺炎”的一种方法。
实体描述增强
- 步骤1: 收集“肺炎”和“抗生素”的描述文本,如“肺炎是一种呼吸系统疾病,常由细菌或病毒引起”。
- 步骤2: 将描述文本融合到模型的输入中,提供更丰富的上下文信息。
三元组句子增强
- 步骤1: 选择“肺炎 - 治疗 - 抗生素”的三元组。
- 步骤2: 将其转换为句子“抗生素可以用来治疗肺炎。”并加入训练语料。
- 步骤3: 通过这种方式,模型学习到“抗生素”和“肺炎”之间的治疗关系。
提及-邻居上下文建模
域内词汇权重学习
- 步骤1: 识别出医学领域特有的术语,如“细菌性肺炎”、“病毒性肺炎”等。
- 步骤2: 使用来自医学数据库的大量文本数据训练模型,为这些专业术语生成词汇表和权重。
- 步骤3: 通过这种方法,模型在处理肺炎相关文本时能够准确识别和理解这些术语。
领域自监督任务预训练
- 步骤1: 定义一个自监督任务,比如随机掩码文本中的“肺炎”并让模型预测它。
- 步骤2: 在预训练阶段通过这个任务让模型学习“肺炎”的上下文信息和与之相关的医学知识。
- 步骤3: 这样做使得模型能够在处理医学查询或诊断文本时,更好地理解和回答有关“肺炎”的问题。
通过结合这些子解法,可以显著提升预训练语言模型在特定领域(如医学)的性能,使其更好地理解和处理专业文本。
SMedBERT 图示
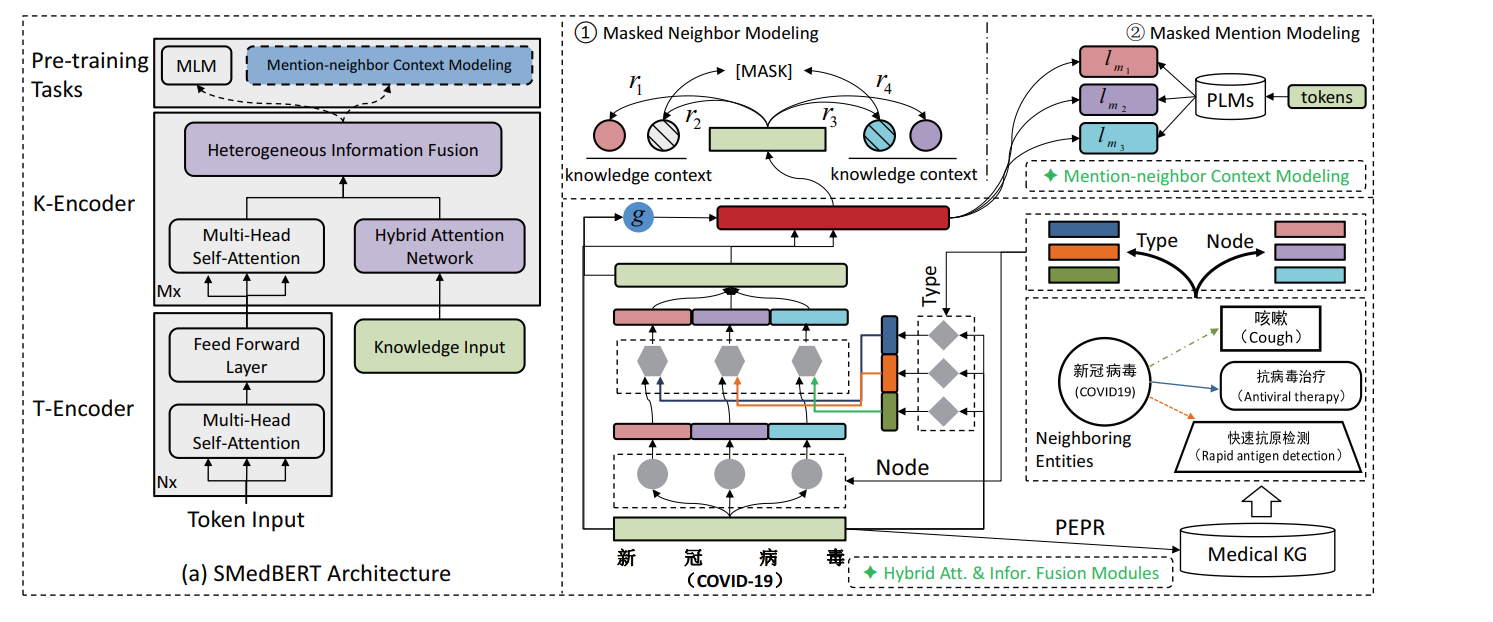
图的左半部分展示了模型的架构,而右半部分详细展示了模型包括混合注意力网络和提及-邻居上下文建模预训练任务的细节。
左半部分:SMedBERT架构
- T-Encoder: 底部是标准的Transformer编码器,它接收文本输入并通过多头自注意力机制处理这些输入。
- K-Encoder: 顶部是知识编码器,它专门处理来自医学知识图谱的输入。它使用混合注意力网络来融合文本输入(通过T-Encoder处理)和外部知识(知识输入)。
右半部分:预训练任务
- 预训练任务: 包括两部分,一是掩蔽邻居建模(Masked Neighbor Modeling),二是掩蔽提及建模(Masked Mention Modeling)。
- 掩蔽邻居建模: 这一任务涉及对知识图谱中的实体邻居进行掩蔽,并要求模型预测缺失的邻居实体,以此来增强模型对知识图谱中实体关系的理解。
- 掩蔽提及建模: 在这个任务中,文本中的实体提及被掩蔽,模型需要预测这些提及,这有助于模型学习实体在文本中的语义表示。
这张图描绘了SMedBERT如何结合传统的Transformer架构与知识图谱信息,通过预训练任务学习医学领域的复杂语义关系。
这种结合可以帮助模型更好地处理医学文本中的专业术语和概念,从而在医学领域的自然语言处理任务中实现更高的准确性和效率。
方法部分
子问题1: 如何在不引入知识噪声的前提下有效地融合知识图谱和文本数据?
- 子解法1: Top-K实体排序(Top-K Entity Sorting),通过个性化PageRank算法筛选与提及最相关的K个邻居实体,减少知识噪声。
子问题2: 在保持文本原有意义的同时,如何增强实体表示与其在知识图谱中邻居实体的关联性?
- 子解法2: 提及-邻居混合注意力(Mention-neighbor Hybrid Attention),结合实体类型和节点注意力,以及门控位置融合。
子问题3: 如何设计预训练任务以利用实体间的结构化语义知识?
- 子解法3: 提及-邻居上下文建模(Mention-neighbor Context Modeling),包括掩蔽邻居建模(Masked Neighbor Modeling)和掩蔽提及建模(Masked Mention Modeling)。
数学部分
- Top-K实体排序: 使用个性化PageRank算法计算每个实体与提及的相关性,然后选择相关性最高的K个实体。
在训练开始时,对于文本中提及的“糖尿病”,我们查询知识图谱以找到与之相关的实体,如“胰岛素”、“高血糖”、“视网膜病变”等。
使用个性化PageRank算法评估“糖尿病”与这些实体的相关性,并选择相关性最高的K个实体。
假设K=3,选出的实体可能是“胰岛素”、“高血糖”和“视网膜病变”。
- 提及-邻居混合注意力机制:
- 实体类型注意力: 计算每个提及与其相应类型的邻居实体的关联度。
模型计算“糖尿病”(疾病类型)与其邻居实体“胰岛素”(治疗类型)、“高血糖”(症状类型)、“视网膜病变”(并发症类型)之间的关联度。
- 节点注意力: 为每个邻居实体分配一个注意力分数,以确定其对提及的贡献程度。
模型为每个选定的邻居实体分配一个注意力分数,基于它们对“糖尿病”描述的贡献程度。
- 门控位置融合: 使用门控机制结合提及的原始文本表示和知识图谱信息,以减少知识噪声。
结合“糖尿病”的文本表示和从知识图谱中提取的邻居实体信息,使用门控机制调整信息融合的程度。
- 提及-邻居上下文建模:
- 掩蔽邻居建模: 预测与提及相关联的掩蔽邻居实体,强化模型对结构化知识的理解。
随机掩蔽一些与“糖尿病”相关的邻居实体(比如“高血糖”),模型需要预测这个被掩蔽的实体,这有助于模型学习实体间的关系。
- 掩蔽提及建模: 从邻居实体的角度预测被掩蔽的提及,促进实体之间的语义联系。
模型尝试从提及“糖尿病”周围的上下文中预测被掩蔽的提及,促进对“糖尿病”的深层语义理解。
- 训练目标: 模型的最终训练目标是最小化上述所有预训练任务的总损失,通常是通过调整超参数来平衡不同部分的损失。
数学公式
-
实体表示(Entity Representation):
- 每个单词或实体在计算机中都通过一个数字列表表示,这个列表称为“向量”。比如,单词“糖尿病”可能被表示为一个向量
[0.2, -0.1, 0.9, ...]。
- 每个单词或实体在计算机中都通过一个数字列表表示,这个列表称为“向量”。比如,单词“糖尿病”可能被表示为一个向量
-
实体类型注意力(Entity Type Attention):
- 我们想计算模型有多关注实体的类型(比如,“糖尿病”是一种“疾病”)。为此,我们使用向量表示的实体(“糖尿病”)和实体类型(“疾病”)来计算一个分数,这个分数告诉我们模型有多关注这个类型。
-
节点注意力(Node Attention):
- 类似地,我们想知道模型有多关注与实体相关联的其他实体(节点)。比如,“糖尿病”与“胰岛素注射”有关联,我们计算一个分数来量化这种关联。
-
门控位置融合(Gated Position Infusion):
- 有时候,我们想结合实体在文本中的位置信息。门控机制就像一个开关,它决定我们是否应该将这个位置信息与实体的表示结合起来。
-
总损失函数(Total Loss Function):
- 在训练模型时,我们需要一种方法来告诉模型它的预测有多好。损失函数就是这样一种方法,它计算模型预测和实际情况之间的差异。总损失是所有不同任务损失的组合。
让我们更详细地看一下这些步骤中的数学公式:
- 实体类型注意力:
AttentionScore = exp ( DotProduct ( h e m , h t y p e ) / d ) SumOfAllScores \text{AttentionScore} = \frac{\exp(\text{DotProduct}(h_{em}, h_{type}) / \sqrt{d})}{\text{SumOfAllScores}} AttentionScore=SumOfAllScoresexp(DotProduct(hem,htype)/d)
这里,DotProduct 表示两个向量的点乘(一个简单的向量相乘和累加操作),h_{em} 是实体的向量,h_{type} 是实体类型的向量,d 是向量的维度。这个分数后来会被归一化成概率,这就是 softmax 函数的作用。
- 节点注意力:
NodeAttentionScore = softmax ( W ⋅ tanh ( V e m + V n o d e + b ) ) \text{NodeAttentionScore} = \text{softmax}(W \cdot \text{tanh}(V_{em} + V_{node} + b)) NodeAttentionScore=softmax(W⋅tanh(Vem+Vnode+b))
这里,V_{em} 和 V_{node} 分别是实体和邻居节点的向量,W 和 b 是模型需要学习的参数。
- 门控位置融合:
h n e w = Gate ⊙ h e m + ( 1 − Gate ) ⊙ p e m h_{new} = \text{Gate} \odot h_{em} + (1 - \text{Gate}) \odot p_{em} hnew=Gate⊙hem+(1−Gate)⊙pem
这里,Gate 是决定使用多少位置信息的门控分数,h_{em} 是实体的向量,p_{em} 是位置的向量。
- 总损失函数:
L t o t a l = λ 1 L t y p e + λ 2 L n o d e + λ 3 L g a t e + L b a s e L_{total} = \lambda_1 L_{type} + \lambda_2 L_{node} + \lambda_3 L_{gate} + L_{base} Ltotal=λ1Ltype+λ2Lnode+λ3Lgate+Lbase
这里, L t y p e , L n o d e , L g a t e L_{type}, L_{node}, L_{gate} Ltype,Lnode,Lgate 分别代表实体类型注意力、节点注意力和门控位置融合的损失函数,而 L b a s e L_{base} Lbase 代表基础的预训练损失(如交叉熵损失)。
λ 1 , λ 2 , λ 3 \lambda_1, \lambda_2, \lambda_3 λ1,λ2,λ3 是用来平衡不同损失组件的超参数。
实体类型注意力有助于模型识别“糖尿病”是一种疾病;
节点注意力帮助模型理解“糖尿病”与“胰岛素注射”之间的联系;
门控位置融合确保位置信息以合适的方式被使用;
总损失函数则是在训练过程中,指导模型朝着正确方向改进其预测。
效果
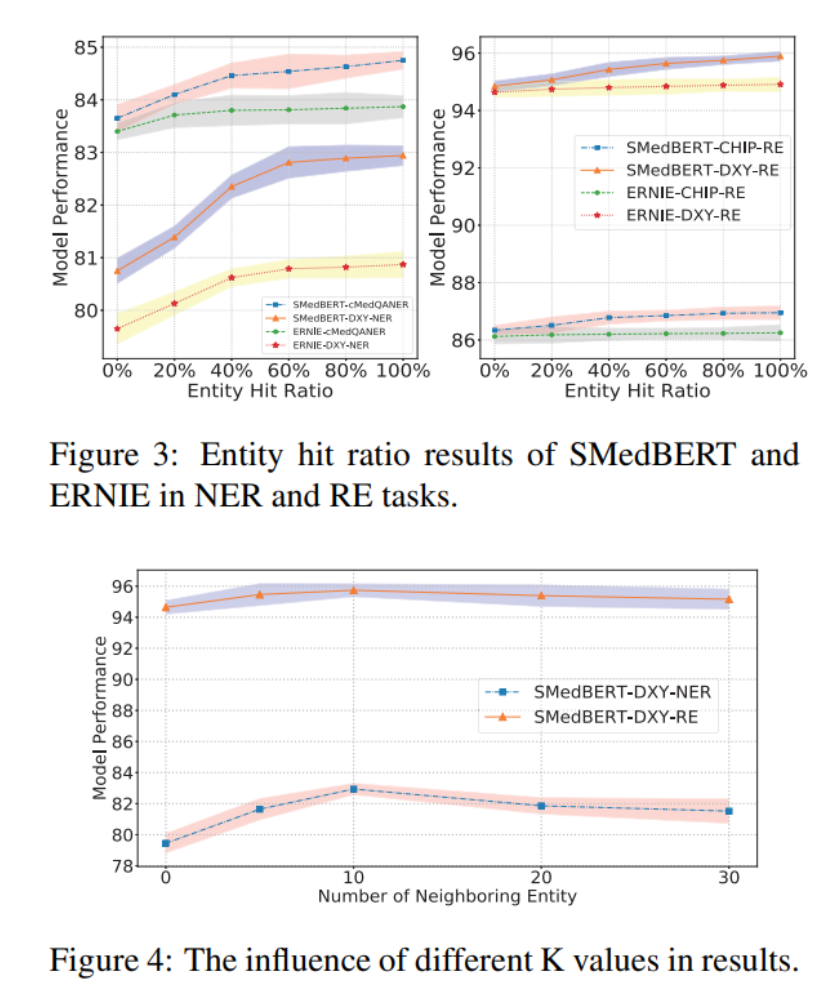
实验结论:
-
SMedBERT模型的优势:
- SMedBERT在包含结构化语义知识的预训练中表现出色,特别是在处理需要深度语义理解的医学文本任务上。
- 通过整合医学领域的知识图谱信息,SMedBERT在各种医学自然语言处理(NLP)任务上显著超越了基线模型,包括命名实体识别(NER)、关系抽取(RE)和问答(QA)等任务。
-
知识图谱的融合有效性:
- 实验结果表明,结构化的知识图谱信息对于提高模型在医学领域任务中的性能至关重要。
- 特别是对于那些具有大量共享邻居的实体对,SMedBERT能够更有效地利用这些全局上下文信息,增强了模型对低频提及的表示能力。
-
实体命中比率和邻居实体数量的影响:
- 对于命名实体识别和关系抽取任务,当增加知识增强提及的比例(即实体命中比率)时,模型性能显著提升,但超过一定阈值后性能趋于稳定。这表明虽然结构化知识对模型有益,但过多的知识可能会引入噪声,影响模型性能。
- 邻居实体数量的实验进一步证实了这一点,合理的邻居实体数量能够提升模型性能,而过多的邻居实体则可能导致知识噪声问题。
-
模型组件的重要性:
- 通过对SMedBERT模型进行消融研究,我们发现混合注意力机制是模型中最关键的组成部分。
- 移除混合注意力机制后,模型性能有最大幅度的下降,这强调了在预训练模型中注入丰富的异构邻居实体知识的重要性。