目录
28.netty的相关参数
29.HTTP1.0、HTTP1.1 和 HTTP2.0 的区别
30.如何理解IO多路复用?
28.netty的相关参数
1.netty的参数设置体系
客户端:
bootstrap.option(); //在这里配置客户端一些配置信息
服务端:
serverBootstrap.option();//服务端这里的配置对ServerSocketChannel生效
serverBootstrap.childOption();//服务端这里的配置对SocketChannel生效
2.netty以上配置的操作类
ChannelConfig:netty中的核心配置都位于ChannelConfig,核心配置都在这里
DefaultChannelConfig:核心配置的默认值都位于这个类里面,一种声明
ChannelOption:这个类对ChannelConfig中的参数配置进行配置,不配置默认就是DefaultChannelConfig中的值
3.配置格式
ChannelOption.key,value
参数1.RCVBUF_ALLOCATOR

//设置服务端对应的每一个客户端连接的ByteBuf大小【ByteBuf为应用层缓冲区】
//ByteBuf在netty中是采用直接内存设计,无论是池化还是非池化,采用直接内存目的肯定还是想要减少拷贝次数
//如果不进行自定义设置ByteBuf大小,netty默认值为:最小为64字节,初始值为1024,最大为65535
//为什么要设置三个值呢?服务端为了根据实际的使用进行做动态调整
serverBootstrap.childOption(ChannelOption.RCVBUF_ALLOCATOR,new AdaptiveRecvByteBufAllocator(16,16,16));

参数2:SO_RCVBUF && SO_SNDBUF
作用在SSC,SO_RCVBUF其作用是控制接收端Socket缓冲区的大小,SO_SNDBUF其作用是控制发送端的缓冲区的大小
SO_RCVBUF:在serverSocketChannel中设置。设置接收端socket缓冲区的大小,直接使用option()方法设置
SO_SNDBUF:针对于socketChannel。设置发送端socket缓冲区的大小,在客户端你只能使用option()进行设置。但是在服务端你需要使用childOption()设置。
这个需要注意的两点是:
1.目前的操作系统比较智能,会帮我们自动去调整,所以我们不需要自己去调整这个参数
2.netty中以SO开头的参数,都是和操作系统底层TCP协议相关的参数,这些参数你可以在netty这里通过参数设置,你也可以直接修改操作系统相关的配置文件对应参数值
但是上面的RCVBUF_ALLOCATOR不可以,因为不是SO开头,操作系统中没有这个配置。它是netty自己去封装的ByteBuf的自定义调整【属于应用层面】,下图就是这两个参数作用的位置,我们在发送端发出数据在用户程序层面是存储在ByteBuf中的。但是当陷入内核,去到传输层内核态后,就会把数据存储到socket内核缓冲区中了。

eg:


参数3:ALLOCATOR
内存分配器,作用在SocketChannel,所以服务端也得用childOption()设置
说明白点:该参数就是自定义我们用户自己使用ctx.alloc().buffer()创建ByteBuf时,设置ByteBuf是池化还是非池化?是使用堆内存还是直接内存?
下面以一个例子来说明:
1.使用jvm参数进行设置我们ctx.alloc().buffer()时,我们使用的是堆内存

2.在服务端配置childOption(),当使用ctx.alloc().buffer()创建ByteBuffer时,我们想要使用非池化

3.启动服务端,客户端,测试一把:
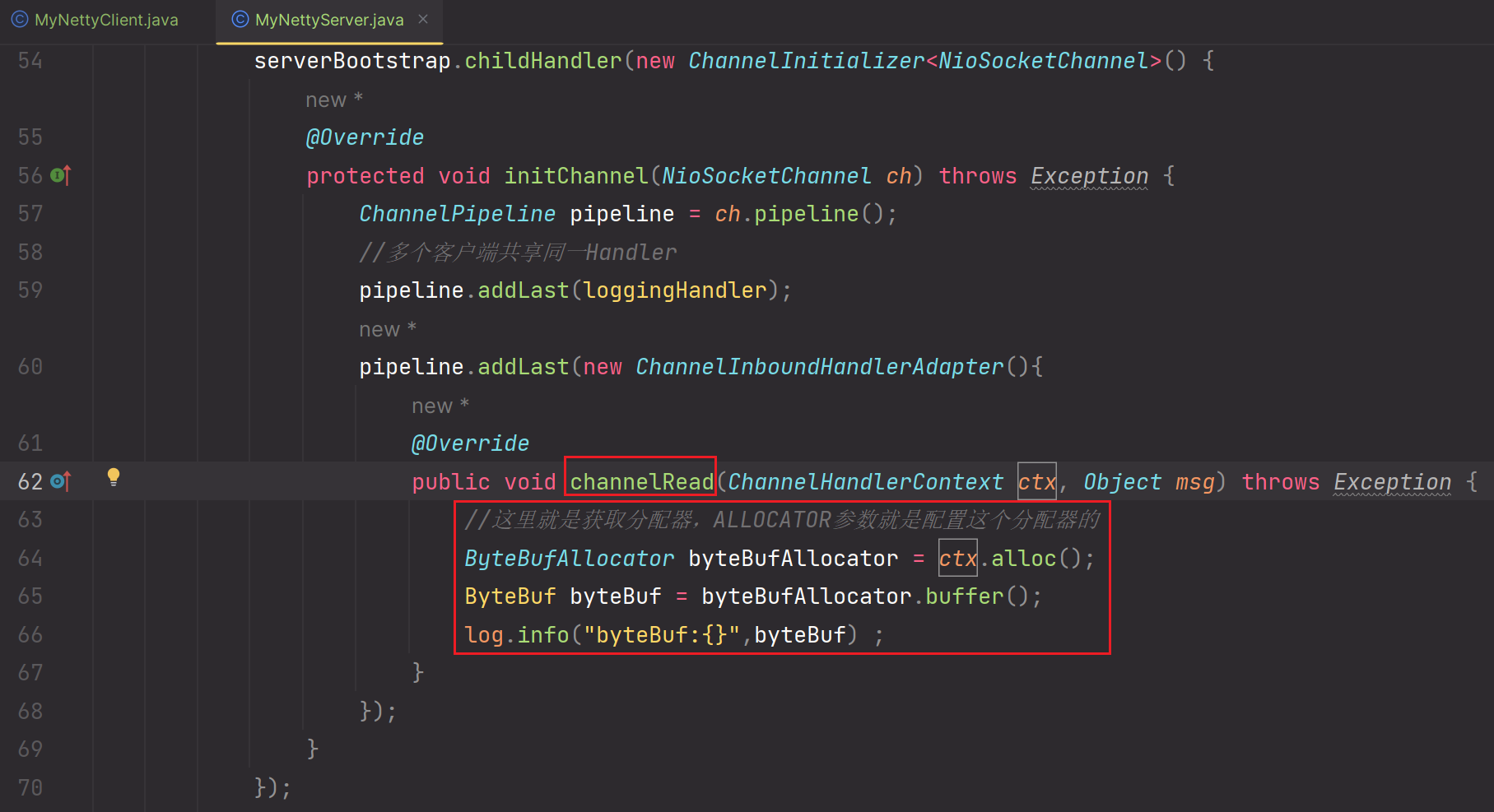
测试成功
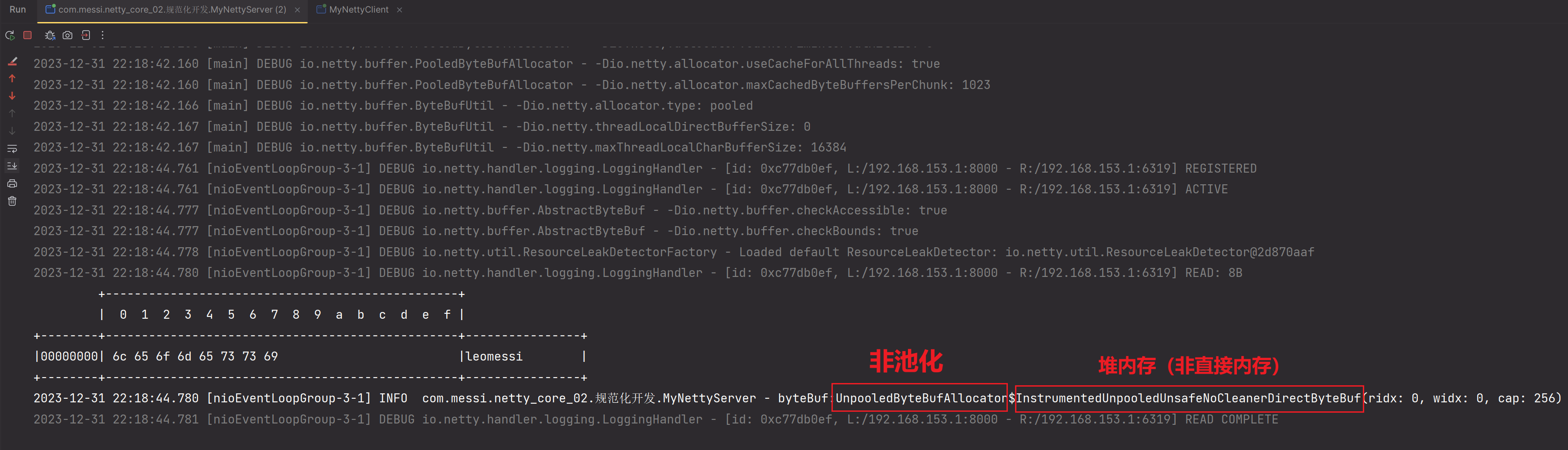
这里容易出现歧义,这个ALLOCATOR和上面的RCVBUF_ALLOCATOR容易产生歧义。我们来解释一下,当一个数据从服务端接收过来的时候,也就是我们上面程序的new ChannelInboundHandlerAdapter这一Handler接收到的msg(假如说没做上面解码操作,还是ByteBuf),此时这个就是netty原生创建的,该ByteBuf就是由RCVBUF_ALLOCATOR参数所决定的,netty原生创建的ByteBuf使用的是直接内存。该ByteBuf是为了方便IO和操作系统内核交互,使用直接内存可以减少数据拷贝次数,所以称之为IO-ByteBuf,
而我们程序员自己在Handler中使用ctx.alloc().buffer()创建出来的ByteBuf是我们程序员自己创建的,也就是ALLOCATOR参数以及jvm参数设置决定的。该参数没有强制要求是直接内存或堆内存,由程序员自行设置。关于如何设置,上面都说明过了。你可以使用ctx.alloc()创建出来的ByteBuf打印出来看看。
再修改测试一下:

此时有一个疑问,如何找到jvm参数并且进行设置的呢???????步骤如下,就以上述这个参数为例子:
我们刚才用的是PooledByteBufAllocator.DEFAULT,我们在内部找到DEFAULT。
public static final PooledByteBufAllocator DEFAULT = new
PooledByteBufAllocator(PlatformDependent.directBufferPreferred());
我们看到他在池化内部传了一个参数来控制是直接内存的,那么我们看下这个参数
PlatformDependent.directBufferPreferred()的源码。
public static boolean directBufferPreferred() {
return DIRECT_BUFFER_PREFERRED;
}
我们看到他返回了一个直接内存优先的变量,我们找到这个变量,private static final boolean
DIRECT_BUFFER_PREFERRED;然后既然是个变量那就能修改,我们按住鼠标和ctrl借助IDEA找到这个变量在哪里被使用。
最终找到是在PlatformDependent类的static静态代码块里面的,
// We should always prefer direct buffers by default if we can use a Cleaner to release direct buffers.
DIRECT_BUFFER_PREFERRED = CLEANER != NOOP &&
!SystemPropertyUtil.getBoolean("io.netty.noPreferDirect", false);
if (logger.isDebugEnabled()) {
logger.debug("-Dio.netty.noPreferDirect: {}", !DIRECT_BUFFER_PREFERRED);
}
我们看到他是通过一个io.netty.noPreferDirect参数来控制的,当这个参数为-
Dio.netty.noPreferDirect=true表示不使用优先的直接内存(前面加-D),此时他就不是直接内存了,
而是使用堆内存,具体你可以试试。而你也可以把msg打印出来看到其实你这个配置对他是不生效的。因为他是IOByteBuf。
这里给了我们一个思路就是看源码的时候可以通过ctrl+右键找到位置,然后看他的JVM参数的生效配置。
参数4:TCP_NODELAY
这个参数作用于socketChannel,也就是也得使用childOption配置,其作用是是否开启Nagle算法。啥是Nagle算法?Nagle算法是TCP的产物,用例子来说明:
有这么一种情况,每次发送的数据包都非常小,比如只有1个字节,但是TCP的报文头默认有40个字节,数据+报文头一共是41字节。如果这种较小的数据包经常出现,会造成过多的网络资源浪费。比如有1W个这样的数据包,那么总数据量中有400MB都是报文头,只有10MB是真正的数据。
所以TCP中引入了一种叫做Nagle的算法,如若连续几次发送的数据都很小,TCP会根据这个算法把多个数据合并成一个包发出,从而优化传输效率,避免网络资源浪费。
但是现在没啥作用了,因为Nagle算法会导致数据包的延迟发送,导致数据迟延太大。所以这里可以关闭,让数据不延迟。但是这个不延迟是相对的,毕竟还有socket内核缓冲区机制呢。但是有一点需要清楚:Nagle算法让多个小数据包聚合到一起,会产生粘包问题。
在服务端:配置serverBootstrap.childOption(ChannelOption.TCP_NODELAY,true);当然了,默认就是true,就是不延迟,所以不用配就行。nagle是tcp网络协议层面的和java没关系。

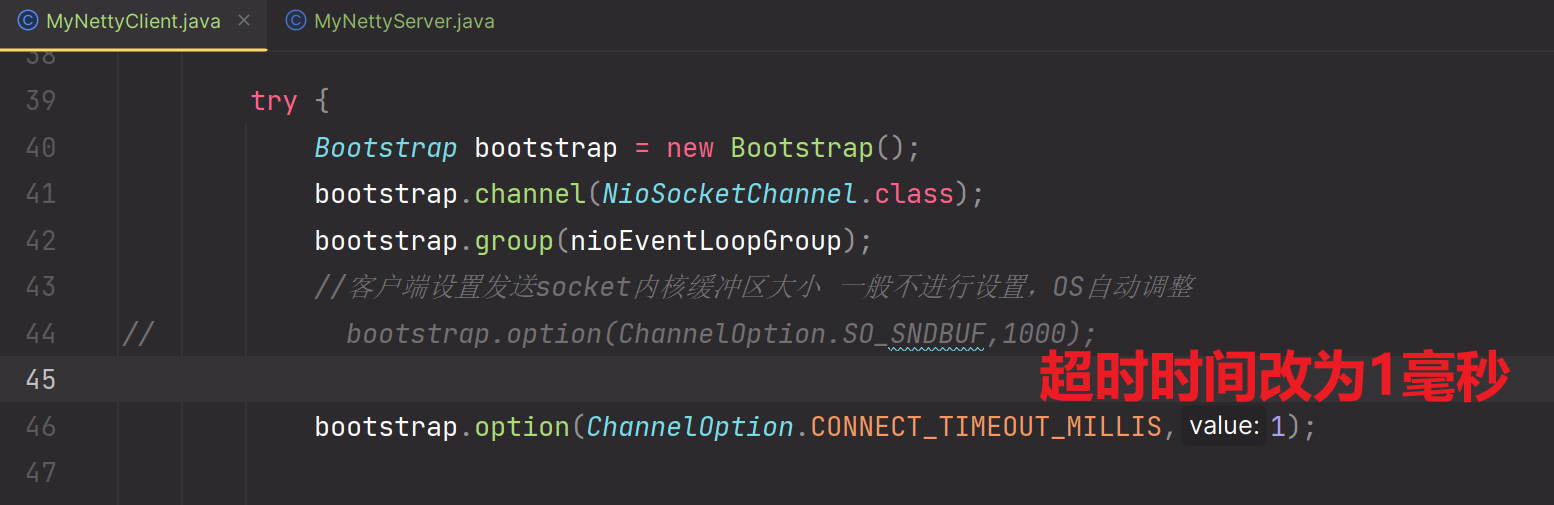
参数5:CONNECT_TIMEOUT_MILLIS
连接超时时间,属于socketChannel的,也就是针对给客户端连接的超时时间,在客户端建立连接时,如果超过这个参数指定的时间,客户端还没有连接上,那么就会抛出超时异常。
所以它是要配置在客户端的,所以你只能使用option进行配置,单位为毫秒
//设置3秒超时
bootstrap.option(ChannelOption.CONNECT_TIMEOUT_MILLIS,3000);

测试一下:
你可以启动服务端,然后客户端主动连接,配置一个很小的时间,他就会超时。注意你得启动服务端,不启动你直接被拒绝,到不了超时。
启动服务端
启动客户端

参数6:SO_BACKLOG
首先是SO开头,是TCP的参数,操作系统可以修改配置文件来修改该参数对应的值
是ServerSocketChannel相关的,在服务端配置,使用option()方法进行配置

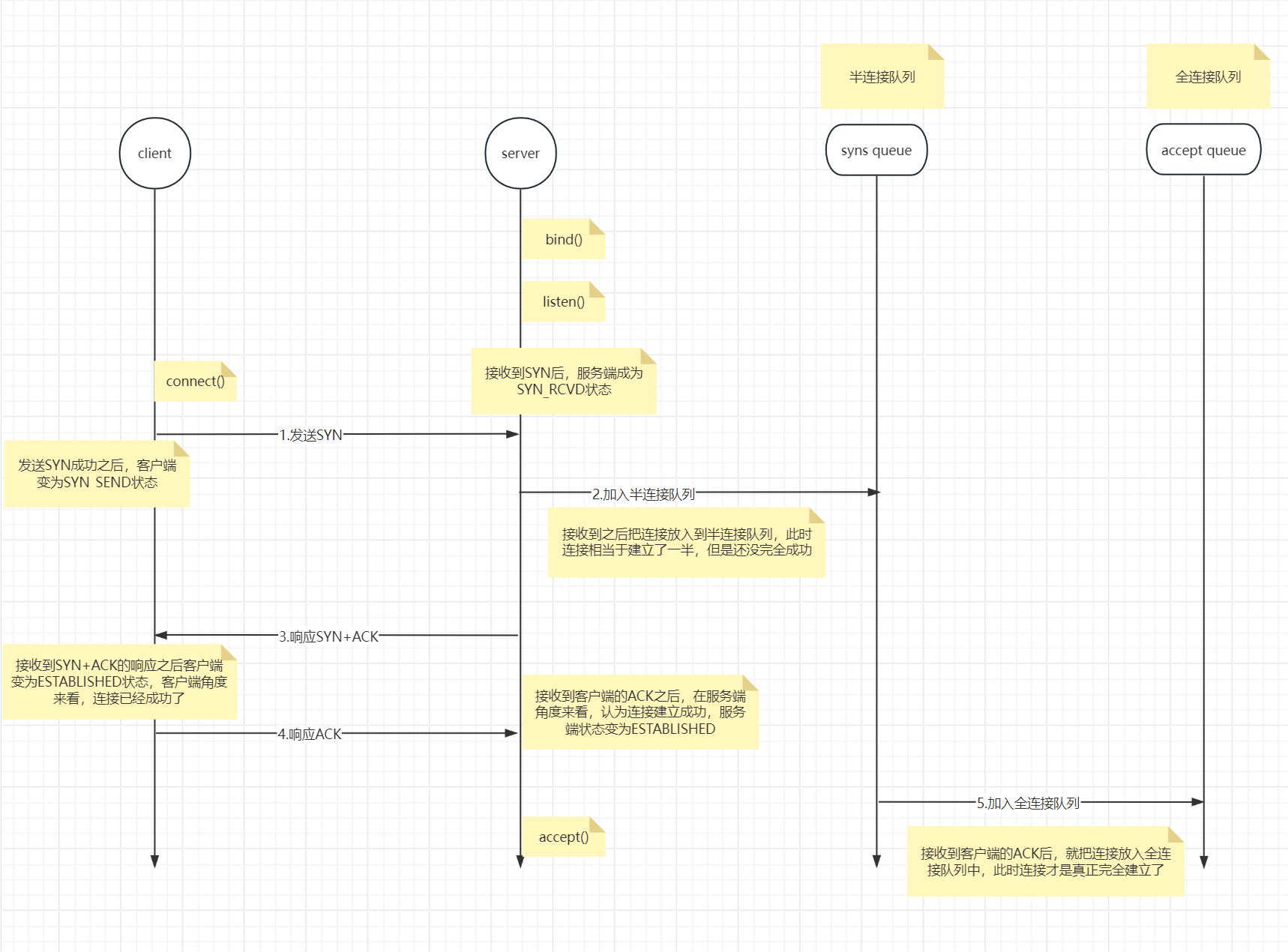
这个是和TCP连接有关系的,来看一下简化图,为什么说简化图,因为真实的连接过程双方状态机状态有11 种之多,而且十分复杂,这里我们只描述几种主干状态。
下图就是TCP三次握手连接的过程,其中我们这个SO_BACKLOG参数就是用来控制全连接队列的大小的。如果队列为5,那么你就只能放5个连接,这个大小实际决定我们客户端连接吞吐量。
我们说了这种SO开头的参数不仅能在netty中配置,还能在OS系统配置文件中配置,比如这个你可以在netty的服务端中配置serverBootstrap.option(xxxx),也可以在linux的/proc/sys/net/core/somaxconn文件中设置这个值
如果你在这两个位置都进行配置了,那么实际运行中会取netty中设置的SO_BACKLOG参数值和在liunx的/proc/sys/net/core/somaxconn二者的最小值,所以配置需要同步,不然你一个配2一个配2000,那么其实还是2。2000这个值就白配了。
我们这里配置的还是全连接队列,半连接队列现在操作系统不设置上限,你也不需要配了,因为它不占用IO资源,因为它都没有建立起来连接。
简化图----》三次握手过程如图所示:
详细描述步骤:
1.服务端启动进程,开启bind端口绑定,然后开始Listen监听等待连接建立
2.客户端通过调用connect函数主动发起连接,第一次握手发送SYN数据包,此时客户端变为SYN_SEND状态
3.服务端接收到SYN数据包,此时服务端变为SYN_RCVD状态,并且把这条连接放入半连接队列,一个连接半成品就完成并存储成功了,但是此时连接依然是不可以使用的
4.服务端给客户端响应上一步接收到的SYN,响应SYN+ACK数据包。【这次发送目的在于:告诉客户端我服务端已经接收到你发送的SYN了】
5.客户端接收到上一步的SYN+ACK数据包,此时在客户端的角度来看,双方已经完全建立连接成功,能开始收发数据了。此时客户端就变为ESTABLISHED状态。然后给服务端响应一个ACK。【这次发送ACK的目的在于:告诉服务端,我接收到了你发送的ACK+SYN数据,确保万无一失】
6.服务端接收到ACK之后,在服务端的角度认为:双方已经完全建立连接成功,能开始收发数据了。此时服务端也变为ESTABLISHED状态。无论站在客户端还是服务端的角度,该连接已经建立完全,所以会把这条连接放入全连接队列,表示连接已经完全建立成功了。
7.此时服务端就开始accept函数,开始轮询这个连接的事件监听了。
参数7:SO_REUSEADDR
端口复用,意思就是重复去绑定其他客户端使用过的端口,避免出现already port use这个问题。already port use这个问题是如何产生的呢?先说一下四次挥手再引出该问题。
服务端调用channel.close()正常关闭,引发底层TCP四次挥手过程如下:

步骤总结:
1.服务端调用channel.close()正常关闭,服务端首先会发送一个FIN数据包给客户端,以此告诉客户端:我们断开连接吧。发送完FIN后,服务端状态变为:FIN-WAIT-1。但是这个状态不会保留很久,也许很快就切换到下一个状态了,所以FIN-WAIT-1很难被捕获到。【在这个过程中服务端可能会做一些关闭资源的操作,发FIN表示这些操作完成了】
2.客户端接收到服务端的FIN后,客户端会发送一个ACK给服务端,以此告诉服务端:我接收到了你的断开连接的请求。发送完ACK后,客户端状态变为:CLOSE-WAIT。服务端接收到该ACK后 状态变为:FIN-WAIT-2
3.客户端会接着发送一个FIN数据包给服务端,表示客户端也要和你断开。发送完后,客户端状态变为:LAST-ACK。【在这个过程中客户端可能会做一些关闭资源的操作,发FIN表示这些操作完成了】
4.服务端接收到客户端发送的FIN后,会发送一个ACK给客户端表示确认接收。发完后,服务端状态经过2MSL(在linux操作系统中大概为1分钟)后,才会变为CLOSED状态。转化成CLOSED状态后,服务端程序(进程)会释放掉占用的端口号
5.客户端接收到ACK后,也会转化成CLOSED状态,客户端程序也会释放占用的端口号。
这个过程不是很好吗?CLOSED状态后端口号正常释放,怎么会出现already port use的异常呢?
如果服务端不是像上述所说的那种channel.close()正常执行关闭操作,而是非正常关闭操作呢?所谓非正常关闭指的是:kill -9强制关闭 或 异常关闭 或在close()正常关闭的过程中的某一步出现问题导致非正常关闭。
非正常关闭导致的结果就是,Server端无法到达CLOSED状态,那么端口就无法释放。我们知道,当服务端非正常关闭后,我们为了保证客户端连接,需要快速重启服务端,但是由于服务端没有达到CLOSED状态,所以端口没有释放,所以重启服务器时会导致使用原先占用未释放的端口号,进而抛出异常:already port use bind.....
如何解决该问题呢?所以可以使用netty为我们提供的端口复用参数进行解决这一问题。

参数8:SO_KeepAlive
SO开头的,所以为操作系统级别系统参数,默认是关闭的,也可以配置为true开启。
一旦这个参数SO_KeepAlive开启之后,TCP会做如下工作:
TCP连接会做保活的心跳测试,当连接建立之后如果7200秒之内没发生数据通信,就会开启测试心跳,心跳包每75秒发一次,发9次(这里不对,是递增式的探活,这个再说)。如果探活依然没有回复,那就断开这个连接。如果9次探活中有一次发现是活的,那么会重新开始计时:7200秒。当然7200秒,75秒,9次这三个参数都可以配置的,都是net.ipv4.tcp_keepalive.xxx配置的。 如:在linux的配置文件net.ipv4.tcp_keepalive_time=7200这里可以修改7200秒这个数据值。
还有一个问题就是:既然TCP给了我们这种探活机制,那么为什么我们在开发的时候还要在应用程序端去做一个心跳探活机制呢?
1.SO_KeepAlive对应提供的keepalive是操作系统级别的探活,是位于TCP传输层的实现,而应用程序实现的心跳探活是位于应用层的。
2.SO_KeepAlive对应提供的keepalive的探活只解决网络的可用性问题,它只能探测连接这块是不是能通信,而无法保证网络上层维护的应用程序是否可以正常通信使用。而我们应用程序做的探活心跳就是要解决该问题,应用程序心跳可以监测应用程序层面的正常通信使用,也可以保证网络连接的正常通信使用。
举个例子:如果我们只使用SO_KeepAlive对应提供的keepalive的探活,只可以保证网络层面的正常通信,但是当我们应用程序出现死锁,卡bug了,gc了,该探活是监测不到的,它依旧以为客户端-服务端双方是正常通信交互的。所以必须在应用程序做探活心跳,这样才能监测网络层面和应用程序层面都是否正常通信交互。
所以可以得出结论:
SO_KeepAlive对应提供的keepalive的探活不能替代应用程序上做的探活心跳,但是应用程序上的探活心跳可以取代SO_KeepAlive对应提供的keepalive的探活。由于这个缘故,我们一般就不使用SO_KeepAlive对应提供的keepalive的探活,可以直接关闭,而是直接在应用程序层面做一个心跳探活即可。
还有一个问题:无论是应用程序层面的心跳探活,还是TCP的keepalive探活,为什么存在这些探活机制呢?
探活机制是为了监测保证客户端-服务端双方都是正常存活,并且彼此无论是网络层面还是应用程序层面都是能够正常交互通信的。
如果监测到客户端或服务端有一方不正常存活,那么客户端-服务端连接存在的意义就没有了。所以客户端-服务端连接的前提也是:客户端与服务端双方无论是在网络层面还是应用程序层面都是正常通信交互的。如何判断二者是正常存活的?使用以上探活机制进行判断。
还有个问题就是:
http1.1中为了保证有限的长连接,他有一个keepalive请求头,该请求头的作用为:在keepalive请求头数据值所对应的这么长时间内,如果客户端-服务端之间没有通信交互数据,那么才会断开连接。所以http1.1协议被称之为有限的长连接。
这个和TCP的keepalive没关系,做的事情根本不一样,只是名字一样而已。
29.HTTP1.0、HTTP1.1 和 HTTP2.0 的区别
看一下这篇文章:
HTTP1.0、HTTP1.1 和 HTTP2.0 的区别 - 掘金
30.如何理解IO多路复用?
看一下这篇文章:
IO系列2-深入理解五种IO模型 - 掘金
IO多路复用是一种思想,一种方式。
比方说:Http2.0相对于Http1.1协议就引入了IO多路复用,原先Http1.1协议中,在同一个连接中,客户端-服务端虽然可以进行多次请求响应,但是下一次的请求必须建立在前一次请求响应结束后才能进行。这就极大的降低了请求的及时响应能力。但是当Http2.0引入IO多路复用机制,在同一个连接中,客户端可以一次向服务端发起多个请求,然后客户端可以逐个接收这多个响应。这就是多路复用,一次连接中,可以同时发起多个请求。
再比方说:操作系统层面的Selector监管者,是一种IO多路复用器,也是应用了IO多路复用机制。我们可以把服务端集群所对应的多个ServerSocketChannel注册到一个Selector,以及后续该服务端集群对应处理的多个客户端连接所对应分配的多个SocketChannel也注册到该Selector上,后续当触发Accept连接事件,IO事件(read或write事件)后,Selector.select()会轮询监控到对应事件的触发,进而服务端会开启线程处理事件逻辑的处理。具体IO多路复用是如何体现的呢?其实就是把多个SSC,SC注册到一个Selector多路复用器上,该多路复用器是由操作系统内核提供的,通过调用Selector.select()就可以只陷入一次操作系统内核,然后在内核中监听是否注册到Selector上的SSC或SC上对应有Accepte或IO事件的发生,如果有发生,那么会再进行数据拷贝,通知应用程序,该事件发生了。应用程序层面Selector.select()就会停止阻塞,然后服务端会通过开启线程处理事件逻辑。如果不使用IO多路复用机制(不使用这种注册到Selector的方式),那么多个客户端连接所对应的ServerSocketChannel对应的Accept事件,以及后续分配的SocketChannel所对应的IO事件,我们每一次都需要自己去陷入内核,去询问是否有事件的发生,陷入内核了n次,而且会极大的消耗服务端有限的线程资源,因为需要不断的进行轮询每一个客户端连接。而引入IO多路复用这种机制,并且把每一个操作都当作一个事件,这样只需要陷入一次内核,一次就可以完成之前多次陷入内核的工作,这就是IO多路复用机制。只需要在内核中不断的轮询监控,极大的减少了陷入内核的性能消耗。
当然后续为了进一步提升服务端在有限的线程资源的条件下,进行并发处理客户端连接,以及后续的IO事件的能力,netty封装了NIO,并且引入了Reactor响应式模型。Reactor分为多种模型,1主多从,或多主多从,这种模型可以更大的利用有限的线程资源,进一步提升并发能力。这里再简略概括一下,具体见前面文档所总结的Reactor模型。一般事件处理分为两类:1.Accept连接事件 2.IO事件(read或write事件)当然还有一种处理为业务逻辑的处理。就拿1主多从的Reactor模型来说:1主代表一个Boss线程处理ServerSocketChannel对应的所有的Accept事件,它具有一个独立的Selector多路复用器,会把ServerSocketChannel注册到该Selector上,当多个客户端连接上来时,会触发多个Accpet事件,Boss线程就会去处理这多个Accpet事件,但是由于连接一般只会一次,所以一般使用1个或两个线程来作为Boss线程来处理连接Accept即可。当Accept连接事件完成后,ServerSocketChannel会分配给对应的客户端分配一个独立的SocketChannel用作后续的IO事件通信通道,但是Boss线程不会做这些IO事件的处理,而是传递交给后续多个worker线程所对应的Selector去做,每一个worker线程都会对应一个独立的Selector,每一个Selector都会注册这多个SocketChannel,进行监听这多个SocketChannel上将来可能会发生的IO事件,当发生了,就会进行处理。多从代表有多个worker线程来处理SocketChannel上可能会触发的IO事件。因为IO事件可能会有很多,所以一般会使用很多个worker线程来处理,每一个worker线程都会对应一个独立的Selector监管者监控所有SocketChannel,当SocketChannel上触发IO事件后,worker线程会进行处理。当然还有最后所说的业务逻辑的处理,一般Netty会新开启一组DefaultEventLoopGroup线程来负责处理业务逻辑的代码,因为一般业务逻辑的处理比较耗时,如果使用worker线程或boss线程去处理,那么会大大的阻塞IO事件或Accept事件的处理。使用DefaultEventLoopGroup这个线程组其实就是一组线程,和我们平常new的线程是一样的,只不过使用DefaultEventLoopGroup可以更好的融入到Netty体系中去。