Rust基础拾遗
- 前言
- 1.结构体
- 1.1 具名字段型结构体
- 1.2 元组型结构体
- 1.3 单元型结构体
- 1.4 结构体布局
- 1.5 用impl定义方法
- 1.5.1 以Box、Rc或Arc形式传入self
- 1.5.2 类型关联函数
- 1.6 关联常量
- 1.7 泛型结构体
- 1.8 带生命周期参数的泛型结构体
- 1.9 带常量参数的泛型结构体
- 1.10 让结构体类型派生自某些公共特型
- 1.11 内部可变性
- 2.枚举与模式
- 3.运算符重载
- 3.1 算术运算符与按位运算符
- 3.1.1 一元运算符
- 3.1.2 二元运算符
- 3.1.3 复合赋值运算符
- 3.2 相等性比较
- 3.3 有序比较
- 3.4 Index与IndexMut
- 4.迭代器
- 4.1 Iterator 特型与 IntoIterator 特型
- 4.2 创建迭代器
- 4.4 迭代器适配器
- 消耗迭代器
- 5.集合
- 5.1 Vec< T >
- 迭代
- HashMap<K, V>
前言
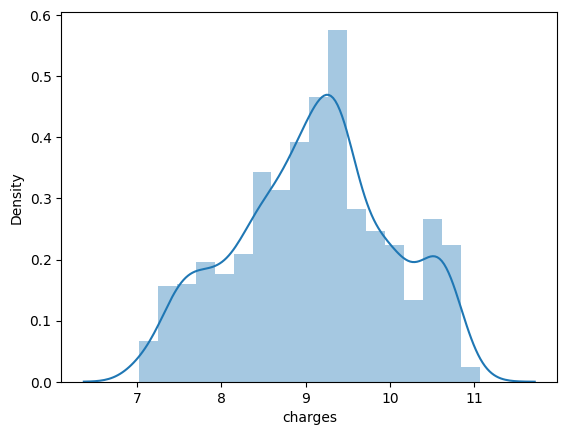
通过Rust程序设计-第二版笔记的形式对Rust相关重点知识进行汇总,读者通读此系列文章就可以轻松的把该语言基础捡起来。
1.结构体
Rust 有 3 种结构体类型:具名字段型结构体、元组型结构体和单元型结构体。
1.1 具名字段型结构体
具名字段型结构体的定义如下所示:
/// 由8位灰度像素组成的矩形
struct GrayscaleMap {pixels: Vec<u8>,size: (usize, usize)
}
它声明了一个 GrayscaleMap 类型,其中包含两个给定类型的字段,分别名为 pixels 和 size。Rust 中的约定是,所有类型(包括结构体)的名称都将每个单词的第一个字母大写(如 GrayscaleMap),这称为大驼峰格式(CamelCase 或 PascalCase)。字段和方法是小写的,单词之间用下划线分隔,这称为蛇形格式(snake_case)。
你可以使用结构体表达式构造出此类型的值,如下所示:
let width = 1024;
let height = 576;
let image = GrayscaleMap {pixels: vec![0; width * height],size: (width, height)
};
结构体表达式以类型名称(GrayscaleMap)开头,后跟一对花括号,其中列出了每个字段的名称和值。还有用来从与字段同名的局部变量或参数填充字段的简写形式:
fn new_map(size: (usize, usize), pixels: Vec<u8>) -> GrayscaleMap {assert_eq!(pixels.len(), size.0 * size.1);GrayscaleMap { pixels, size }
}
结构体表达式 GrayscaleMap { pixels, size } 是 GrayscaleMap { pixels: pixels, size: size } 的简写形式。你可以对某些字段使用 key: value 语法,而对同一结构体表达式中的其他字段使用简写语法。
要访问结构体的字段,请使用我们熟悉的 . 运算符:
assert_eq!(image.size, (1024, 576));
assert_eq!(image.pixels.len(), 1024 * 576);
与所有其他语法项一样,结构体默认情况下是私有的,仅在声明它们的模块及其子模块中可见。你可以通过在结构体的定义前加上 pub 来使结构体在其模块外部可见。结构体中的每个字段默认情况下也是私有的:
/// 由8位灰度像素组成的矩形
pub struct GrayscaleMap {pub pixels: Vec<u8>,pub size: (usize, usize)
}
1.2 元组型结构体
1.3 单元型结构体
1.4 结构体布局
在内存中,具名字段型结构体和元组型结构体是一样的:值(可能是混合类型)的集合以特定方式在内存中布局。例如,在本章前面我们定义了下面这个结构体:
struct GrayscaleMap {pixels: Vec<u8>,size: (usize, usize)
}
内存中GrayscaleMap结构体
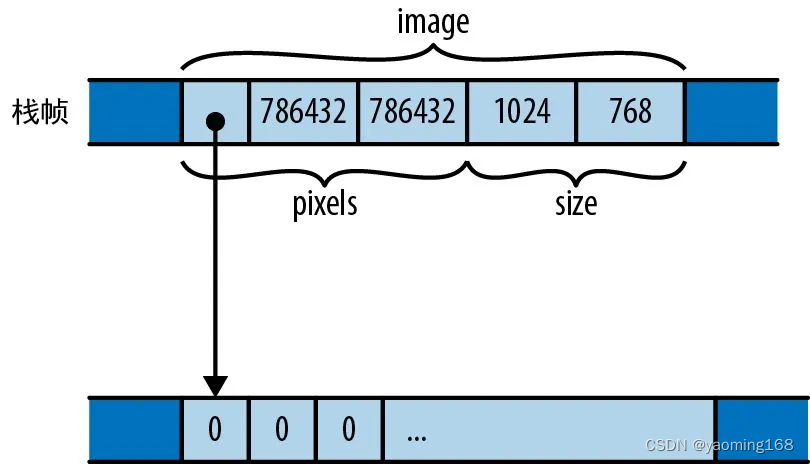
Rust 没有具体承诺它将如何在内存中对结构体的字段或元素进行排序,图 9-1 仅展示了一种可能的安排。然而,Rust 确实承诺会将字段的值直接存储在结构体本身的内存块中。JavaScript、Python 和 Java 会将 pixels 值和 size 值分别放在它们自己的分配在堆上的块中,并让 GrayscaleMap 的字段指向它们,而 Rust 会将 pixels 值和 size 值直接嵌入 GrayscaleMap 值中。只有由 pixels 向量拥有的在堆上分配的缓冲区才会留在它自己的块中。
1.5 用impl定义方法
在本书中,我们一直在对各种值调用方法,比如使用 v.push(e) 将元素推送到向量上、使用 v.len() 获取向量的长度、使用 r.expect(“msg”) 检查 Result 值是否有错误,等等。你也可以在自己的结构体类型上定义方法。Rust 方法不会像 C++ 的方法那样出现在结构体定义中,而是会出现在单独的 impl 块中。
impl 块只是 fn 定义的集合,每个定义都会成为块顶部命名的结构体类型上的一个方法。例如,这里我们定义了一个公共的 Queue 结构体,然后为它定义了 push 和 pop 这两个公共方法:
/// 字符的先入先出队列
pub struct Queue {older: Vec<char>, // 较旧的元素,最早进来的在后面younger: Vec<char> // 较新的元素,最后进来的在后面
}
impl Queue {/// 把字符推入队列的最后pub fn push(&mut self, c: char) {self.younger.push(c);}/// 从队列的前面弹出一个字符。如果确实有要弹出的字符,/// 就返回`Some(c)`;如果队列为空,则返回`None`pub fn pop(&mut self) -> Option<char> {if self.older.is_empty() {if self.younger.is_empty() {return None;}// 将younger中的元素移到older中,并按照所承诺的顺序排列它们use std::mem::swap;swap(&mut self.older, &mut self.younger);self.older.reverse();}// 现在older能保证有值了。Vec的pop方法已经// 返回一个Option,所以可以放心使用了self.older.pop()}
}
在 impl 块中定义的函数称为关联函数,因为它们是与特定类型相关联的。与关联函数相对的是自由函数,它是未定义在 impl 块中的语法项。
Rust 会将调用关联函数的结构体值作为第一个参数传给方法,该参数必须具有特殊名称 self。由于 self 的类型显然就是在 impl 块顶部命名的类型或对该类型的引用,因此 Rust 允许你省略类型,并以 self、&self 或 &mut self 作为 self: Queue、self: &Queue 或 self: &mut Queue 的简写形式。
如果你愿意,也可以使用完整形式,但如前所述,几乎所有 Rust 代码都会使用简写形式。
在我们的示例中,push 方法和 pop 方法会通过 self.older 和 self.younger 来引用 Queue 的字段。在 C++ 和 Java 中,“this” 对象的成员可以在方法主体中直接可见,不用加 this. 限定符,而 Rust 方法中则必须显式使用 self 来引用调用此方法的结构体值,这类似于 Python 方法中使用 self 以及 JavaScript 方法中使用 this 的方式。
由于 push 和 pop 需要修改 Queue,因此它们都接受 &mut self 参数。然而,当调用一个方法时,你不需要自己借用可变引用,常规的方法调用语法就已经隐式处理了这一点。因此,有了这些定义,你就可以像下面这样使用 Queue 了:
let mut q = Queue { older: Vec::new(), younger: Vec::new() };q.push('0');
q.push('1');
assert_eq!(q.pop(), Some('0'));q.push('∞');
assert_eq!(q.pop(), Some('1'));
assert_eq!(q.pop(), Some('∞'));
assert_eq!(q.pop(), None);
只需编写 q.push(…) 就可以借入对 q 的可变引用,就好像你写的是 (&mut q).push(…) 一样,因为这是 push 方法的 self 参数所要求的。
如果一个方法不需要修改 self,那么可以将其定义为接受共享引用:
impl Queue {pub fn is_empty(&self) -> bool {self.older.is_empty() && self.younger.is_empty()}
}
但请注意,由于 split 通过值获取 self,因此这会将 Queue 从 q 中移动出去,使 q 变成未初始化状态。由于 split 的 self 现在拥有此队列,因此它能够将这些单独的向量移出队列并返回给调用者。
有时,像这样通过值或引用获取 self 还是不够的,因此 Rust 还允许通过智能指针类型传递 self。
1.5.1 以Box、Rc或Arc形式传入self
方法的 self 参数也可以是 Box 类型、Rc 类型或 Arc 类型。这种方法只能在给定的指针类型值上调用。调用该方法会将指针的所有权传给它。你通常不需要这么做。如果一个方法期望通过引用接受 self,那它在任何指针类型上调用时都可以正常工作:
let mut bq = Box::new(Queue::new());// `Queue::push`需要一个`&mut Queue`,但`bq`是一个`Box<Queue>`
// 这没问题:Rust在调用期间从`Box`借入了`&mut Queue`
bq.push('■');
对于方法调用和字段访问,Rust 会自动从 Box、Rc、Arc 等指针类型中借入引用,因此 &self 和 &mut self 几乎总是(偶尔也会用一下 self)方法签名里的正确选择。
但是如果某些方法确实需要获取指向 Self 的指针的所有权,并且其调用者手头恰好有这样一个指针,那么 Rust 也允许你将它作为方法的 self 参数传入。为此,你必须明确写出 self 的类型,就好像它是普通参数一样。
impl Node {fn append_to(self: Rc<Self>, parent: &mut Node) {parent.children.push(self);}
}
1.5.2 类型关联函数
给定类型的 impl 块还可以定义根本不以 self 为参数的函数。这些函数仍然是关联函数,因为它们在 impl 块中,但它们不是方法,因为它们不接受 self 参数。为了将它们与方法区分开来,我们称其为类型关联函数。
它们通常用于提供构造函数,如下所示:
impl Queue {pub fn new() -> Queue {Queue { older: Vec::new(), younger: Vec::new() }}
}
要使用此函数,需要写成 Queue::new,即类型名称 + 双冒号 + 函数名称:
let mut q = Queue::new();q.push('*');
...
在 Rust 中,构造函数通常按惯例命名为 new,我们已经见过 Vec::new、Box::new、HashMap::new 等。但是 new 这个名字并没有什么特别之处,它不是关键字。类型通常还有其他关联函数作为构造函数,比如 Vec::with_capacity。
虽然对于一个类型可以有许多独立的 impl 块,但它们必须都在定义该类型的同一个 crate 中。不过,Rust 确实允许你将自己的方法附加到其他类型中。
如果你习惯了用 C++ 或 Java,那么将类型的方法与其定义分开可能看起来很不寻常,但这样做有几个优点。
- 找出一个类型的数据成员总是很容易。在大型 C++ 类定义中,你可能需要浏览数百行成员函数的定义才能确保没有遗漏该类的任何数据成员,而在 Rust 中,它们都在同一个地方。
- 尽管可以把方法放到具名字段型结构体中,但对元组型结构体和单元型结构体来说这看上去不那么简洁。将方法提取到一个 impl 块中可以让所有这 3 种结构体使用同一套语法。事实上,Rust 还使用相同的语法在根本不是结构体的类型(比如 enum 类型和像 i32 这样的原始类型)上定义方法。(任何类型都可以有方法,这是 Rust 很少使用对象这个术语的原因之一,它更喜欢将所有东西都称为值。)
- 同样的 impl 语法也可以巧妙地用于实现特型。
1.6 关联常量
Rust 在其类型系统中的另一个特性也采用了类似于 C# 和 Java 的思想,有些值是与类型而不是该类型的特定实例关联起来的。在 Rust 中,这些叫作关联常量。
关联常量是常量值。它们通常用于表示指定类型下的常用值。例如,你可以定义一个用于线性代数的二维向量和一个关联的单位向量:
pub struct Vector2 {x: f32,y: f32,
}impl Vector2 {const ZERO: Vector2 = Vector2 { x: 0.0, y: 0.0 };const UNIT: Vector2 = Vector2 { x: 1.0, y: 0.0 };
}
这些值是和类型本身相关联的,你可以在不必引用 Vector2 的任一实例的情况下使用它们。这与关联函数非常相似,使用的名字是与其关联的类型名,后面跟着它们自己的名字:
let scaled = Vector2::UNIT.scaled_by(2.0);
关联常量的类型不必是其所关联的类型,我们可以使用此特性为类型添加 ID 或名称。如果有多种类似于 Vector2 的类型需要写入文件然后加载到内存中,则可以使用关联常量来添加名称或数值 ID,这些名称或数值 ID 可以写在数据旁边以标识其类型。
impl Vector2 {const NAME: &'static str = "Vector2";const ID: u32 = 18;
}
1.7 泛型结构体
前面对 Queue 的定义并不令人满意:它是为存储字符而写的,但是它的结构体或方法根本没有任何专门针对字符的内容。如果我们要定义另一个包含 String 值的结构体,那么除了将 char 替换为 String 外,其余代码可以完全相同。这纯属浪费时间。
Rust 结构体可以是泛型的,这意味着它们的定义是一个模板,你可以在其中插入任何自己喜欢的类型。例如,下面是 Queue 的定义,它可以保存任意类型的值:
pub struct Queue<T> {older: Vec<T>,younger: Vec<T>
}
你可以把 Queue 中的 读作“对于任意元素类型 T……”。所以上面的定义可以这样解读:“对于任意元素类型 T,Queue 有两个 Vec 类型的字段。”例如,在 Queue 中,T 是 String,所以 older 和 younger 的类型都是 Vec。而在 Queue 中,T 是 char,我们最终得到的结构体与最初那个针对 char 定义的结构体是一样的。事实上,Vec 本身也是一个泛型结构体,它就是这样定义的。
在泛型结构体定义中,尖括号(<>)中的类型名称叫作类型参数。泛型结构体的 impl 块如下所示:
impl<T> Queue<T> {pub fn new() -> Queue<T> {Queue { older: Vec::new(), younger: Vec::new() }}pub fn push(&mut self, t: T) {self.younger.push(t);}pub fn is_empty(&self) -> bool {self.older.is_empty() && self.younger.is_empty()}...
}
你可以将 impl Queue 这一行解读为“对于任意元素类型 T,这里有一些在 Queue 上可用的关联函数。”然后,你可以使用类型参数 T 作为关联函数定义中的类型。语法可能看起来有点儿累赘,但 impl 可以清楚地表明 impl 块能涵盖任意类型 T,这便能将它与为某种特定类型的 Queue 编写的 impl 块区分开来,如下所示:
这个 impl 块标头表明“这里有一些专门用于 Queue 的关联函数”。这为 Queue 提供了一个 sum 方法,不过该方法在其他类型的 Queue 上不可用。我们在前面的代码中使用了 Rust 的 self 参数简写形式,如果到处都写成 Queue,则让人觉得拗口且容易分心。作为另一种简写形式,每个 impl 块,无论是不是泛型,都会将特殊类型的参数 Self(注意这里是大驼峰 CamelCase)定义为我们要为其添加方法的任意类型。对前面的代码来说,Self 就应该是 Queue,因此我们可以进一步缩写 Queue::new 的定义:
你可能注意到了,在 new 的函数体中,不需要在构造表达式中写入类型参数,简单地写 Queue { … } 就足够了。这是 Rust 的类型推断在起作用:由于只有一种类型适用于该函数的返回值(Queue),因此 Rust 为我们补齐了该类型参数。但是,你始终都要在函数签名和类型定义中提供类型参数。Rust 不会推断这些,相反,它会以这些显式类型为基础,推断函数体内的类型。Self 也可以这样使用,我们可以改写成 Self { … }。你觉得哪种写法最容易理解就写成哪种。在调用关联函数时,可以使用 ::<>(比目鱼)表示法显式地提供类型参数:
事实上,我们在本书中经常这样使用另一种泛型结构体类型 Vec。不仅结构体可以是泛型的,枚举同样可以接受类型参数,而且语法也非常相似。10.1 节会详细介绍“枚举”。
1.8 带生命周期参数的泛型结构体
如果结构体类型包含引用,则必须为这些引用的生命周期命名。例如,下面这个结构体可能包含对某个切片的最大元素和最小元素的引用:
struct Extrema<'elt> {greatest: &'elt i32,least: &'elt i32
}
早些时候,我们建议你把像 struct Queue 这样的声明理解为:给定任意类型 T,都可以创建一个持有该类型的 Queue。同样,可以将 struct Extrema<'elt> 理解为:给定任意生命周期 'elt,都可以创建一个 Extrema<'elt> 来持有对该生命周期的引用。
下面这个函数会扫描切片并返回一个 Extrema 值,这个值的各个字段会引用其中的元素:
fn find_extrema<'s>(slice: &'s [i32]) -> Extrema<'s> {let mut greatest = &slice[0];let mut least = &slice[0];for i in 1..slice.len() {if slice[i] < *least { least = &slice[i]; }if slice[i] > *greatest { greatest = &slice[i]; }}Extrema { greatest, least }
}
在这里,由于 find_extrema 借用了 slice 的元素,而 slice 有生命周期 's,因此我们返回的 Extrema 结构体也使用了 's 作为其引用的生命周期。Rust 总会为各种调用推断其生命周期参数,所以调用 find_extrema 时不需要提及它们:
let a = [0, -3, 0, 15, 48];
let e = find_extrema(&a);
assert_eq!(*e.least, -3);
assert_eq!(*e.greatest, 48);
因为返回类型的生命周期与参数的生命周期相同是很常见的情况,所以如果有一个显而易见的候选者,那么 Rust 就允许我们省略生命周期。因此也可以把 find_extrema 的签名写成如下形式,意思不变:
fn find_extrema(slice: &[i32]) -> Extrema {...
}
当然,我们的意思也可能是 Extrema<'static>,但这很不寻常。Rust 只为最常见的情况提供了简写形式。
1.9 带常量参数的泛型结构体
泛型结构体也可以接受常量值作为参数。例如,你可以定义一个表示任意次数多项式的类型,如下所示:
/// N - 1 次多项式
struct Polynomial<const N: usize> {/// 多项式的系数////// 对于多项式 a + bx + cx<sup>2</sup> + ... + zx<sup>n-1</sup>,其第`i`个元素是 x<sup>i</sup>的系数coefficients: [f64; N]
}
例如,根据这个定义,Polynomial<3> 是一个二次多项式。这里的 子句表示 Polynomial 类型需要一个 usize 值作为它的泛型参数,以此来决定要存储多少个系数。
与通过字段保存长度和容量而将元素存储在堆中的 Vec 不同,Polynomial 会将其系数(coefficients)直接存储在值中,再无其他字段。长度直接由类型给出。(这里不需要容量的概念,因为 Polynomial 不能动态增长。)
也可以在类型的关联函数中使用参数 N:
impl<const N: usize> Polynomial<N> {fn new(coefficients: [f64; N]) -> Polynomial<N> {Polynomial { coefficients }}/// 计算`x`处的多项式的值fn eval(&self, x: f64) -> f64 {// 秦九韶算法在数值计算上稳定、高效且简单:// c<sub>0</sub> + x(c<sub>1</sub> + x(c<sub>2</sub> + x(c<sub>3</sub> + ... x(c[n-1] + x c[n]))))let mut sum = 0.0;for i in (0..N).rev() {sum = self.coefficients[i] + x * sum;}sum}
}
这里,new 函数会接受一个长度为 N 的数组,并将其元素作为新 Polynomial 值的系数。eval 方法将在 0…N 范围内迭代以找到给定点 x 处的多项式值。
与类型参数和生命周期参数一样,Rust 通常也能为常量参数推断出正确的值:
use std::f64::consts::FRAC_PI_2; // π/2// 用近似法对`sin`函数求值:sin x ≅ x - 1/6 x³ + 1/120 x<sup>5</sup>
// 误差几乎为 0,相当精确!
let sine_poly = Polynomial::new([0.0, 1.0, 0.0, -1.0/6.0, 0.0,1.0/120.0]);
assert_eq!(sine_poly.eval(0.0), 0.0);
assert!((sine_poly.eval(FRAC_PI_2) - 1.).abs() < 0.005);
由于我们向 Polynomial::new 传递了一个包含 6 个元素的数组,因此 Rust 知道必须构造出一个 Polynomial<6>。eval 方法仅通过查询其 Self 类型就知道 for 循环应该运行多少次迭代。由于长度在编译期是已知的,因此编译器可能会用一些顺序执行的代码完全替换循环。
常量泛型参数可以是任意整数类型、char 或 bool。不允许使用浮点数、枚举和其他类型。
如果结构体还接受其他种类的泛型参数,则生命周期参数必须排在第一位,然后是类型,接下来是任何 const 值。例如,一个包含引用数组的类型可以这样声明:
struct LumpOfReferences<'a, T, const N: usize> {the_lump: [&'a T; N]
}
常量泛型参数是 Rust 的一个相对较新的功能,目前它们的使用受到了一定的限制。例如,像下面这样定义 Polynomial 显然更好:
/// 一个N次多项式
struct Polynomial<const N: usize> {coefficients: [f64; N + 1]
}
虽然 [f64; N] 没问题,但像 [f64; N + 1] 这样的类型显然对 Rust 来说太过激进了。所以 Rust 暂时施加了这个限制,以避免遇到像下面这样的问题:
struct Ketchup<const N: usize> {tomayto: [i32; N & !31],tomahto: [i32; N - (N % 32)],
}
通过计算可知,不管 N 取何值,N & !31 和 N - (N % 32) 总是相等的,因此 tomayto 和 tomahto 始终具有相同的类型。例如,应该允许将任何一个赋值给另一个。但是,如果想让 Rust 的类型检查器识别这种位运算,就需要把一些令人困惑的极端情况引入这种本已相当复杂的语言中,而这会带来复杂度失控的风险。当然,支持像 N + 1 这样的简单表达式是没问题的,并且也确实已经有人在努力教 Rust 顺利处理这些问题。
由于此处关注的是类型检查器的行为,因此这种限制仅适用于出现在类型中的常量参数,比如数组的长度。在普通表达式中,可以随意使用 N:像 N + 1 和 N & !31 这样的写法是完全可以的。
如果要为 const 泛型参数提供的值不仅仅是字面量或单个标识符,那么就必须将其括在花括号中,就像 Polynomial<> 这样。此规则能让 Rust 更准确地报告语法错误。
1.10 让结构体类型派生自某些公共特型
结构体很容易编写:
struct Point {x: f64,y: f64
}
但是,如果你要开始使用这种 Point 类型,很快就会发现它有点儿难用。像这样写的话,Point 不可复制或克隆,不能用 println!(“{:?}”, point); 打印,而且不支持 == 运算符和 != 运算符。
这些特性中的每一个在 Rust 中都有名称——Copy、Clone、Debug 和 PartialEq,它们被称为特型。
如何为自己的结构体手动实现特型?
对于这些标准特型和其他一些特型,无须手动实现,除非你想要某种自定义行为。Rust 可以自动为你实现它们,而且结果准确无误。只需将 #[derive] 属性添加到结构体上即可:
#[derive(Copy, Clone, Debug, PartialEq)]
struct Point {x: f64,y: f64
}
这些特型中的每一个都可以为结构体自动实现特型,但前提是结构体的每个字段都实现了该特型。我们可以要求 Rust 为 Point 派生 PartialEq,因为它的两个字段都是 f64 类型,而 f64 类型已经实现了 PartialEq。
Rust 还可以派生 PartialOrd,这将增加对比较运算符 <、>、<= 和 >= 的支持。我们在这里并没有这样做,因为比较两个点以了解一个点是否“小于”另一个点是一件很奇怪的事情。毕竟点和点之间并没有任何常规意义上的顺序可言。所以我们选择不让 Point 值支持这些运算符。这种特例就是 Rust 让我们自己编写 #[derive] 属性而不会自动为它派生每一个可能特型的原因之一。而另一个原因是,只要实现某个特型就会自动让它成为公共特性,因此可复制性、可克隆性等都会成为该结构体的公共 API 的一部分,应该慎重选择。
1.11 内部可变性
可变性与其他任何事物一样:过犹不及,而你通常只需要一点点就够了。假设你的蜘蛛机器人控制系统有一个中心结构体 SpiderRobot,其中包含一些设置和 I/O 句柄。该结构体会在机器人启动时设置好,并且值永不改变:
pub struct SpiderRobot {species: String,web_enabled: bool,leg_devices: [fd::FileDesc; 8],...
}
机器人的每个主要系统由不同的结构体处理,它们都有一个指向 SpiderRobot 的指针:
use std::rc::Rc;pub struct SpiderSenses {robot: Rc<SpiderRobot>, // <--指向设置和I/O的指针eyes: [Camera; 32],motion: Accelerometer,...
}
织网、捕食、毒液流量控制等结构体也都有一个 Rc 智能指针。回想一下,Rc 代表引用计数(reference counting),并且 Rc 指向的值始终是共享的,因此将始终不可变。
现在假设你要使用标准 File 类型向 SpiderRobot 结构体添加一点儿日志记录。但有一个问题:File 必须是可变的。所有用于写入的方法都需要一个可变引用。
这种情况经常发生。我们需要一个不可变值(SpiderRobot 结构体)中的一丁点儿可变数据(一个 File)。这称为内部可变性。Rust 提供了多种可选方案,本节将讨论两种最直观的类型,即 Cell 和 RefCell,它们都在 std::cell 模块中。
Cell 是一个包含类型 T 的单个私有值的结构体。Cell 唯一的特殊之处在于,即使你对 Cell 本身没有 mut 访问权限,也可以获取和设置这个私有值字段。
Cell::new(value)(新建)
创建一个新的 Cell,将给定的 value 移动进去。
cell.get()(获取)
返回 cell 中值的副本。
cell.set(value)(设置)
将给定的 value 存储在 cell 中,丢弃先前存储的值。
此方法接受一个不可变引用型的 self。
fn set(&self, value: T) // 注意:不是&mut self
当然,这对名为 set 的方法来说是相当不寻常的。迄今为止,Rust 一直在告诉我们如果想更改数据,就需要 mut 型访问。但出于同样的原因,这个不寻常的细节正是 Cell 的全部意义所在。Cell 只是改变不变性规则的一种安全方式——一丝不多,一毫不少。cell 还有其他一些方法,你可以查阅其文档进行了解。如果你想在 SpiderRobot 中添加一个简单的计数器,那么 Cell 是一个不错的工具。可以写成如下形式:
use std::cell::Cell;
pub struct SpiderRobot {
…
hardware_error_count: Cell,
…
}
行为与 borrow() 和 borrow_mut() 一样,但会返回一个 Result。如果该值已被以可变的方式借出,那么这两个方法不会 panic,而是返回一个 Err 值。同样,RefCell 也有一些其他的方法,你可以在其文档中进行查找。仅当你试图打破“可变引用必须独占”的 Rust 规则时,这两个 borrow 方法才会 panic。例如,以下代码会引起 panic:
use std::cell::RefCell;let ref_cell: RefCell<String> = RefCell::new("hello".to_string());let r = ref_cell.borrow(); // 正确,返回Ref<String>
let count = r.len(); // 正确,返回"hello".len()
assert_eq!(count, 5);let mut w = ref_cell.borrow_mut(); // panic:已被借出
w.push_str(" world");
为避免 panic,可以将这两个借用放入不同的块中。这样,在你尝试借用 w 之前,r 已经被丢弃了。这很像普通引用的工作方式。唯一的区别是,通常情况下,当你借用一个变量的引用时,Rust 会在编译期进行检查,以确保你在安全地使用该引用。如果检查失败,则会出现编译错误。RefCell 会使用运行期检查强制执行相同的规则。因此,如果你违反了规则,就会收到 panic(对于 try_borrow 和 try_borrow_mut 则会显示 Err)。现在我们已经准备好把 RefCell 用在 SpiderRobot 类型中了:
pub struct SpiderRobot {...log_file: RefCell<File>,...
}impl SpiderRobot {/// 往日志文件中写一行消息pub fn log(&self, message: &str) {let mut file = self.log_file.borrow_mut();// `writeln!`很像`println!`,但会把输出发送到给定的文件中writeln!(file, "{}", message).unwrap();}
}
变量 file 的类型为 RefMut,我们可以像使用 File 的可变引用一样使用它。有关写入文件的详细信息,请参阅第 18 章。Cell 很容易使用。虽然不得不调用 .get() 和 .set() 或 .borrow() 和 .borrow_mut() 略显尴尬,但这就是我们为违反规则而付出的代价。还有一个缺点虽不太明显但更严重:Cell 以及包含它的任意类型都不是线程安全的。因此 Rust 不允许多个线程同时访问它们。第 19 章会讲解内部可变性的线程安全风格,届时我们会讨论“Mutex”(参见 19.3.2 节)、“原子化类型”(参见 19.3.10 节)和“全局变量”(参见 19.3.11 节)这几项技术。无论一个结构体是具名字段型的还是元组型的,它都是其他值的聚合:如果我有一个 SpiderSenses 结构体,那么就有了指向共享 SpiderRobot 结构体的 Rc 指针、有了眼睛、有了陀螺仪,等等。所以结构体的本质是“和”这个字:我有 X 和 Y。但是如果围绕“或”这个字构建另一种类型呢?也就是说,当你拥有这种类型的值时,你就拥有了 X 或 Y。这种类型也非常有用,在 Rust 中无处不在,它们是第 10 章的主题。
2.枚举与模式
在 Rust 中,它们被称为枚举。你可以使用它们来定义自己的类型,其值是一组命名常量。
例如,你可以定义一个名为 Color 的类型,其值为 Red、Orange、Yellow 等。这种枚举也适用于 Rust,但是 Rust 的枚举远不止于此。Rust 枚举还可以包含数据,甚至是不同类型的数据。例如,Rust 的 Result 类型就是一个枚举,这样的值要么是包含 String 型的 Ok 值,要么是包含 io::Error 的 Err 值。Rust 枚举更像是 C 的联合体,但不同之处在于它是类型安全的。
只要值可能代表多种事物,枚举就很有用。使用枚举的“代价”是你必须通过模式匹配安全地访问数据,这是本章后半部分的主题。
如果你用过 Python 中的解包或 JavaScript 中的解构,那么应该很熟悉“模式”这个词,但 Rust 的模式不止于此。Rust 模式有点儿像针对所有数据的正则表达式。它们用于测试一个值是否具有特定的目标形态,可以一次从结构体或元组中把多个字段提取到局部变量中。
和正则表达式一样,模式很简洁,通常能在一行代码中完成全部工作。
本章从枚举的基础知识讲起,
- 首先展示数据如何关联到枚举的各个变体,以及枚举如何存储在内存中;
- 然后展示 Rust 的模式和 match(匹配)语句如何基于枚举、结构体、数组和切片简洁地表达逻辑。
- 模式中还可以包含引用、移动和 if 条件,来让自己更加强大。
2.1 枚举
Rust 中简单的 C 风格枚举很直观:
enum Ordering {Less,Equal,Greater,
}
这声明了一个具有 3 个可能值的 Ordering 类型,称为变体或构造器:Ordering::Less、Ordering::Equal 和 Ordering::Greater。这个特殊的枚举是标准库的一部分,因此 Rust 代码能够直接导入它:
use std::cmp::Ordering;fn compare(n: i32, m: i32) -> Ordering {if n < m {Ordering::Less} else if n > m {Ordering::Greater} else {Ordering::Equal}
}
要导入当前模块中声明的枚举的构造器,请使用 self:
enum Pet {Orca,Giraffe,
...
}use self::Pet::*;
2.1.1 带数据的枚举
2.1.2 内存中的枚举
2.1.3 用枚举表示富数据结构
2.1.4 泛型枚举
2.2 模式
2.2.1 模式中的字面量、变量和通配符
2.2.2 元组型模式与结构体型模式
2.2.3 数组型模式与切片型模式
2.2.4 引用型模式
2.2.5 匹配守卫
2.2.6 匹配多种可能性
2.2.7 使用@模式绑定
2.2.8 模式能用在哪里
2.2.9 填充二叉树
3.运算符重载
3.1 算术运算符与按位运算符
3.1.1 一元运算符
3.1.2 二元运算符
3.1.3 复合赋值运算符
3.2 相等性比较
3.3 有序比较
3.4 Index与IndexMut
通过实现 std::ops::Index 特型和 std::ops::IndexMut 特型,你可以规定像 a[i] 这样的索引表达式该如何作用于你的类型。数组可以直接支持 [] 运算符,但对其他类型来说,表达式 a[i] 通常是 *a.index(i) 的简写形式,其中 index 是 std::ops::Index 特型的方法。但是,如果表达式被赋值或借用成了可变形式,那么 a[i] 就是对调用 std::ops::IndexMut 特型方法的 *a.index_mut(i) 的简写。
以下是 Index 和 IndexMut 这两个特型的定义:
trait Index<Idx> {type Output: ?Sized;fn index(&self, index: Idx) -> &Self::Output;
}trait IndexMut<Idx>: Index<Idx> {fn index_mut(&mut self, index: Idx) -> &mut Self::Output;
}
请注意,这些特型会以索引表达式的类型作为参数。你可以使用单个 usize 对切片进行索引,以引用单个元素,因为切片实现了 Index。还可以使用像 a[i…j] 这样的表达式来引用子切片,因为切片也实现了 Index<Range>。该表达式是以下内容的简写形式:
*a.index(std::ops::Range { start: i, end: j })
4.迭代器
迭代器是一个值,它可以生成一系列值,通常用来执行循环操作。
迭代器本身也提供了一组丰富的方法,比如映射(map)、过滤(filter)、连接(join)、收集(collect)等。
fn triangle(n: i32) -> i32 {let mut sum = 0;for i in 1..=n {sum += i;}sum
}
表达式 1…=n 是一个 RangeInclusive 型的值。而 RangeInclusive 是一个迭代器,可以生成其起始值到结束值(包括两者)之间的整数,因此你可以将它用作 for 循环的操作数来对从 1 到 n 的值求和。
fn triangle(n: i32) -> i32 {(1..=n).fold(0, |sum, item| sum + item)
}
开始运行时以 0 作为总和,fold 会获取 1…=n 生成的每个值,并以总和(sum)跟当前值(item)为参数调用闭包 |sum, item| sum + item。闭包的返回值会作为新的总和。它返回的最后一个值就是 fold 自身要返回的值——在这个例子中,也就是整个序列的总和。如果你用惯了 for 循环和 while 循环,这种写法可能看起来很奇怪,但一旦习惯了 fold,你就会发现 fold 的表达方式更加清晰和简洁。
这就是函数式编程语言的标准风格,非常注重表达能力。在发行版中,Rust 会理解 fold 的定义并将其内联到 triangle 中。接下来是将闭包 |sum, item| sum + item 内联到 triangle 中。最后,Rust 会检查合并后的代码并意识到有一种更简单的方法可以对从 1 到 n 的数值求和:其总和总会等于 n * (n+1) / 2。于是 Rust 将 triangle 的整个函数体,包括循环、闭包和所有内容,翻译成了单个乘法指令和几个算术运算。
在本章中,我们将解释以下核心知识点。
- Iterator 特型和 IntoIterator 特型,两者是 Rust 迭代器的基础。
- 一个典型的迭代器流水线通常有 3 个阶段:从某种“值源”创建迭代器,通过选择或处理从中流过的值来将一种迭代器适配成另一种迭代器,然后消耗此迭代器生成的值。
- 如何为自己的类型实现迭代器?
4.1 Iterator 特型与 IntoIterator 特型
迭代器是实现了 std::iter::Iterator 特型的任意值:
trait Iterator {type Item;fn next(&mut self) -> Option<Self::Item>;…… // 很多默认方法
}
只要可以用某种自然的方式来迭代某种类型,该类型就可以实现 std::iter::IntoIterator,其 into_iter 方法会接受一个值并返回一个迭代器:
trait IntoIterator where Self::IntoIter: Iterator<Item=Self::Item> {type Item;type IntoIter: Iterator;fn into_iter(self) -> Self::IntoIter;
}
IntoIter 是迭代器本身的类型,而 Item 是它生成的值的类型。任何实现了 IntoIterator 的类型都称为可迭代者,因为你可以随意迭代它。
Rust 的 for 循环会将所有这些部分很好地结合在一起。要遍历向量的元素,你可以这样写:
println!("There's:");
let v = vec!["antimony", "arsenic", "aluminum", "selenium"];for element in &v {println!("{}", element);
}
下面介绍迭代器的一些术语。
- 迭代器是实现了 Iterator 的任意类型。
- 可迭代者是任何实现了 IntoIterator 的类型:你可以通过调用它的 into_iter 方法来获得一个迭代器。在这里,向量引用 &v 就是可迭代者。
- 迭代器能生成值。
- 迭代器生成的值是条目。在这里,条目是 “antimony”、“arsenic” 等。
- 接收迭代器所生成条目的代码是消费者。在这里,for 循环体就是消费者。
虽然 for 循环总会在其操作数上调用 into_iter,但你也可以直接把迭代器传给 for 循环,比如,在遍历 Range 时就是这样的。所有迭代器都自动实现了 IntoIterator,并带有一个直接返回迭代器的 into_iter 方法。
如果在返回 None 后再次调用迭代器的 next 方法,则 Iterator 特型没有规定它应该做什么。大多数迭代器只会再次返回 None,但也有例外。(如果这个过程中出了问题,可以参考一下 15.3.7 节中介绍的 fuse 适配器。)
4.2 创建迭代器
iter 方法与 iter_mut 方法
大多数集合类型提供了 iter(迭代器)方法和 iter_mut(可变迭代器)方法,它们会返回该类型的自然迭代器,为每个条目生成共享引用或可变引用。像 &[T] 和 &mut [T] 这样的数组切片也有 iter 方法和 iter_mut 方法。如果你不打算让 for 循环替你跟迭代器打交道,iter 方法和 iter_mut 方法就是获取迭代器最常用的方法:
IntoIterator 的实现
如果一个类型实现了 IntoIterator,你也可以自行调用它的 into_iter 方法,就像 for 循环一样:
// 大家通常会使用HashSet,但它的迭代顺序是不确定的,
// 因此在这个示例中用了BTreeSet,它的演示效果更好些
use std::collections::BTreeSet;
let mut favorites = BTreeSet::new();
favorites.insert("Lucy in the Sky With Diamonds".to_string());
favorites.insert("Liebesträume No. 3".to_string());
let mut it = favorites.into_iter();
assert_eq!(it.next(), Some("Liebesträume No. 3".to_string()));
assert_eq!(it.next(), Some("Lucy in the Sky With Diamonds".to_string()));
assert_eq!(it.next(), None);
大多数集合实际上提供了 IntoIterator 的几种实现,用于共享引用(&T)、可变引用(&mut T)和移动(T)。给定一个集合的共享引用,into_iter 会返回一个迭代器,该迭代器会生成对其条目的共享引用。例如,在前面的代码中,(&favorites).into_iter() 会返回一个 Item 类型为 &String 的迭代器。给定对集合的可变引用,into_iter 会返回一个迭代器,该迭代器会生成对其条目的可变引用。如果 vector 是某个 Vec,则调用 (&mut vector).into_iter() 会返回一个 Item 类型为 &mut String 的迭代器。当按值传递集合时,into_iter 会返回一个迭代器,该迭代器会获取集合的所有权并按值返回这些条目,这些条目的所有权会从集合转移给消费者,原始集合在此过程中已被消耗掉了。例如,前面代码中的 favorites.into_iter() 调用返回了一个迭代器,该迭代器会按值生成每个字符串,消费者会获得每个字符串的所有权。当迭代器被丢弃时,BTreeSet 中剩余的所有元素都将被丢弃,并且该集合的空壳也将被丢弃。
from_fn 与 successors
要生成一系列值,有一种简单而通用的方法,那就是提供一个能返回这些值的闭包。
给定返回 Option 的函数,std::iter::from_fn(来自 fn)就会返回一个迭代器,该迭代器会调用 fn 来生成条目。例如:
use rand::random; // 在Cargo.toml中添加dependencies: rand = "0.7"
use std::iter::from_fn;// 产生1000条端点均匀分布在区间[0, 1]上的随机线段的长度(这并不是
// `rand_distr` crate中能找到的分布类型,但你可以轻易实现一个)
let lengths: Vec<f64> =from_fn(|| Some((random::<f64>() - random::<f64>()).abs())).take(1000).collect();
它会调用 from_fn 来让迭代器产生随机数。由于迭代器总是返回 Some,因此序列永不结束,但我们调用 take(1000) 时会将其限制为前 1000 个元素。然后 collect 会从这 1000 次迭代中构建出向量。这是构造已初始化向量的有效方式,我们会在 15.4.13 节中解释原因。
如果每个条目都依赖于其前一个条目,那么 std::iter::successors 函数很实用。只需要提供一个初始条目和一个函数,且该函数能接受一个条目并返回下一个条目的 Option。如果返回 None,则迭代结束。例如,下面是编写第 2 章中的曼德博集绘图器的 escape_time 函数的另一种方式:
use num::Complex;
use std::iter::successors;fn escape_time(c: Complex<f64>, limit: usize) -> Option<usize> {let zero = Complex { re: 0.0, im: 0.0 };successors(Some(zero), |&z| { Some(z * z + c) }).take(limit).enumerate().find(|(_i, z)| z.norm_sqr() > 4.0).map(|(i, _z)| i)
}
从零开始,successors(后继者)调用会通过反复对最后一个点求平方再加上参数 c 来生成复平面上的一系列点。在绘制曼德博集时,我们想看看这个序列是永远在原点附近打转还是“飞向”无穷远。调用 take(limit) 确定了我们追踪序列的次数限制,然后 enumerate 对每个点进行编号,将每个点 z 变成元组 (i, z)。我们使用 find 来寻找距离原点足够远的第一个点以判断是否逃逸。find 方法会返回一个 Option:如果这样的点存在就返回 Some((i, z)),否则返回 None。调用 Option::map 会将 Some((i, z)) 变成 Some(i),但不会改变 None,因为这正是我们想要的返回值。
from_fn 和 successors 都接受 FnMut 闭包,因此你的闭包可以捕获和修改周边作用域中的变量。例如,下面的 fibonacci 函数就用 move 闭包来捕获一个变量并将其用作自己的运行状态:
fn fibonacci() -> impl Iterator<Item=usize> {let mut state = (0, 1);std::iter::from_fn(move || {state = (state.1, state.0 + state.1);Some(state.0)})
}assert_eq!(fibonacci().take(8).collect::<Vec<_>>(),vec![1, 1, 2, 3, 5, 8, 13, 21]);
需要注意的是,from_fn 方法和 successors 方法非常灵活,你几乎可以将任何对迭代器的使用改写成对其中之一的调用,通过传递复杂的闭包来得到你想要的行为。但这样做浪费了迭代器提供的机会,即使用常见模式的标准名称来更清晰地表达计算中的数据流。在使用这两个方法之前,请确保你已经熟悉本章中的其他迭代器方法,通常其他迭代器是更好的选择。
drain 方法
有许多集合类型提供了 drain(抽取)方法。drain 会接受一个对集合的可变引用,并返回一个迭代器,该迭代器会将每个元素的所有权传给消费者。然而,与按值获取并消耗掉集合的 into_iter() 方法不同,drain 只会借入对集合的可变引用,当迭代器被丢弃时,它会从集合中移除所有剩余元素以清空集合。
对于可以按范围索引的类型(如 String、向量和 VecDeque),drain 方法可指定要移除的元素范围,而不是“抽干”整个序列:
let mut outer = “Earth”.to_string();
let inner = String::from_iter(outer.drain(1…4));
assert_eq!(outer, “Eh”);
assert_eq!(inner, “art”);
如果确实需要“抽干”整个序列,使用整个范围(…)作为参数即可。
4.4 迭代器适配器
一旦你手头有了迭代器,迭代器的 Iterator 特型就会提供大量适配器方法(也可以简称为适配器)。适配器会消耗某个迭代器并构建一个实现了特定行为的新迭代器。为了阐明适配器的工作原理,我们将从两个最流行的适配器 map 和 filter 开始,然后介绍其他适配器,涵盖了你能想到的从其他序列生成值序列的几乎所有方式:截断、跳过、组合、反转、连接、重复等。
map 与 filter
Iterator 特型的 map(映射)适配器能针对迭代器的各个条目调用闭包来帮你转换迭代器。filter 适配器能使用闭包来帮你从迭代器中过滤某些条目,由闭包决定保留和丢弃哪些条目。
假设你正在逐行遍历文本并希望去掉每一行的前导空格和尾随空格。标准库的 str::trim 方法能从单个 &str 中丢弃前导空格和尾随空格,返回一个新的、修剪过的 &str 借用。你可以通过 map 适配器将 str::trim 应用于迭代器中的每一行:
let text = " ponies \n giraffes\niguanas \nsquid".to_string();
let v: Vec<&str> = text.lines()
.map(str::trim)
.collect();
assert_eq!(v, [“ponies”, “giraffes”, “iguanas”, “squid”]);
text.lines() 调用会返回一个生成字符串中各行的迭代器。在该迭代器上调用 map 会返回第二个迭代器,第二个迭代器会对每一行调用 str::trim 并将生成的结果作为自己的条目。最后,collect 会将这些条目收集到一个向量中。map 返回的迭代器本身当然也可以进一步适配。如果你想将结果中的 iguanas 排除,可以这样写:
filter_map 与 flat_map
flatten
take 与 take_while
skip 与 skip_while
peekable
fuse
可逆迭代器与 rev
inspect
chain
enumerate
zip
by_ref
cloned 与 copied
cycle
消耗迭代器
简单累加:count、sum 和 product
min 与 max
max_by 与 min_by
max_by_key 与 min_by_key
对条目序列进行比较
any 与 all
position、rposition 和 ExactSizeIterator
fold 与 rfold
try_fold 与 try_rfold
nth 与 nth_back
last
find、rfind 和 find_map
构建集合:collect 与 FromIterator
Extend 特型
partition
for_each 与 try_for_each
实现自己的迭代器
5.集合
首先,移动和借用无处不在。Rust 使用移动来避免对值做深拷贝。这就是 Vec::push(item) 方法会按值而非按引用来获取参数的原因。这样值就会移动到向量中。第 4 章中的示意图展示了这在实践中是如何实现的:将 Rust String 压入 Vec 中会很快,因为 Rust 不必复制字符串的字符数据,并且字符串的所有权始终是明晰的。
其次,Rust 没有失效型错误,也就是当程序仍持有指向集合内部数据的指针时,集合被重新调整大小或发生其他变化而导致的那种悬空指针错误。失效型错误是 C++ 中未定义行为的另一个来源,即使在内存安全的语言中,它们也会偶尔导致 ConcurrentModificationException。Rust 的借用检查器在编译期就可以排除这些错误。
最后,Rust 没有 null,因此在其他语言使用 null 的地方 Rust 会使用 Option。
| 集合 | 描述 | C++ |
|---|---|---|
| Vec< T > | 可增长数组 | vector |
| VecDeque< T > | 双端队列(可增长的环形缓冲区) | deque |
| LinkedList< T > | 双向链表 | list |
| BinaryHeap< T > where T: Ord | 最大堆 | priority_queue |
| HashMap<K,V> where K: Eq + Hash | 键值哈希表 | unordered_map |
| BTreeMap<K,V> where K: Ord | 有序键值表 | map |
| HashSet< T > where T: Eq + Hash | 无序的、基于哈希的集 | unordered_set |
| BTreeSet< T > where T: Ord | 有序集 | set |
Vec< T >、HashMap<K,V> 和 HashSet< T > 是最常用的集合类型。本章会依次讨论每种集合类型。
Vec< T >(普通向量)
可增长的、分配在堆上的 T 类型值数组。本章会用大约一半的篇幅专门介绍 Vec 及其众多实用方法。
HashMap<K, V>(哈希 Map)
由键 - 值对构成的表。通过键查找值很快。其条目会以任意顺序存储。
HashSet< T >(哈希 Set)
由 T 类型的值组成的 Set。它既能很快地添加值和移除值,也能很快地查询给定值是否在此 Set 中。
5.1 Vec< T >
创建向量的最简单方法是使用 vec! 宏:
// 创建一个空向量
let mut numbers: Vec<i32> = vec![];// 使用给定内容创建一个向量
let words = vec!["step", "on", "no", "pets"];
let mut buffer = vec![0u8; 1024]; // 1024个内容为0的字节
向量具有 3 个字段:长度、容量和指向用于存储元素的堆分配内存的指针。图 16-1 展示了前面的向量在内存中的布局方式。空向量 numbers 最初的容量为 0。直到添加第一个元素之前,不会为其分配堆内存。
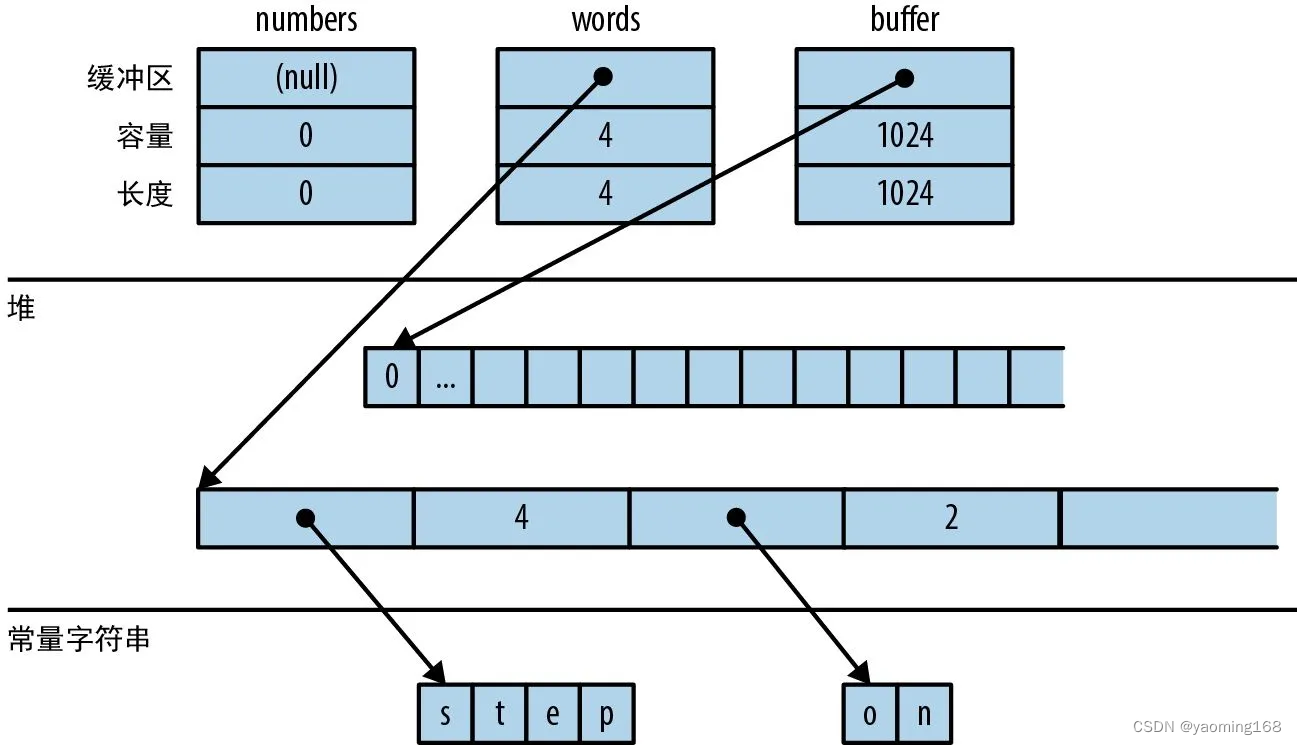
与所有集合一样,Vec 也实现了 std::iter::FromIterator,所以可以使用迭代器的 .collect() 方法从任意迭代器创建向量。
// 把另一个集合转换成向量
let my_vec = my_set.into_iter().collect::<Vec<String>>();
访问元素
通过索引来获取数组、切片或向量的元素非常简单:
// 获取某个元素的引用
let first_line = &lines[0];// 获取某个元素的副本
let fifth_number = numbers[4]; // 要求实现了Copy特型
let second_line = lines[1].clone(); // 要求实现了Clone特型// 获取切片的引用
let my_ref = &buffer[4..12];// 获取切片的副本
let my_copy = buffer[4..12].to_vec(); // 要求实现了Clone特型
如果索引超出了范围,则所有这些形式都会引发 panic。Rust 向量的长度和索引都是 usize 类型。试图用 u32、u64 或 isize 作为向量索引会导致出错。
迭代
向量、数组和切片是可迭代的,要么按值迭代,要么按引用迭代
- 遍历 Vec 或数组 [T; N] 会生成 T 类型的条目。这些元素会逐个从向量或数组中移动出来并被消耗掉。
- 遍历 &[T; N]、&[T] 或 &Vec 类型的值(对数组、切片或向量的引用)会生成 &T 类型的条目,即对单个元素的引用,这些元素不会移动出来。
- 遍历 &mut [T; N]、&mut [T] 或 &mut Vec 类型的值会生成 &mut T 类型的条目。
数组、切片和向量也有 .iter() 方法和 .iter_mut() 方法,以用于创建一个会生成对其元素的引用的迭代器。
HashMap<K, V>
Map 是键 - 值对[称为条目(entry)]的集合。任何两个条目都不会有相同的键,并且这些条目会始终按某种数据结构进行组织,从而使你可以通过键在 Map 中高效地查找对应的值。简而言之,Map 就是一个查找表。
Rust 提供了两种 Map 类型:HashMap<K, V> 和 BTreeMap<K, V>。这两种类型共享许多相同的方法,区别在于它们如何组织条目以便进行快速查找。
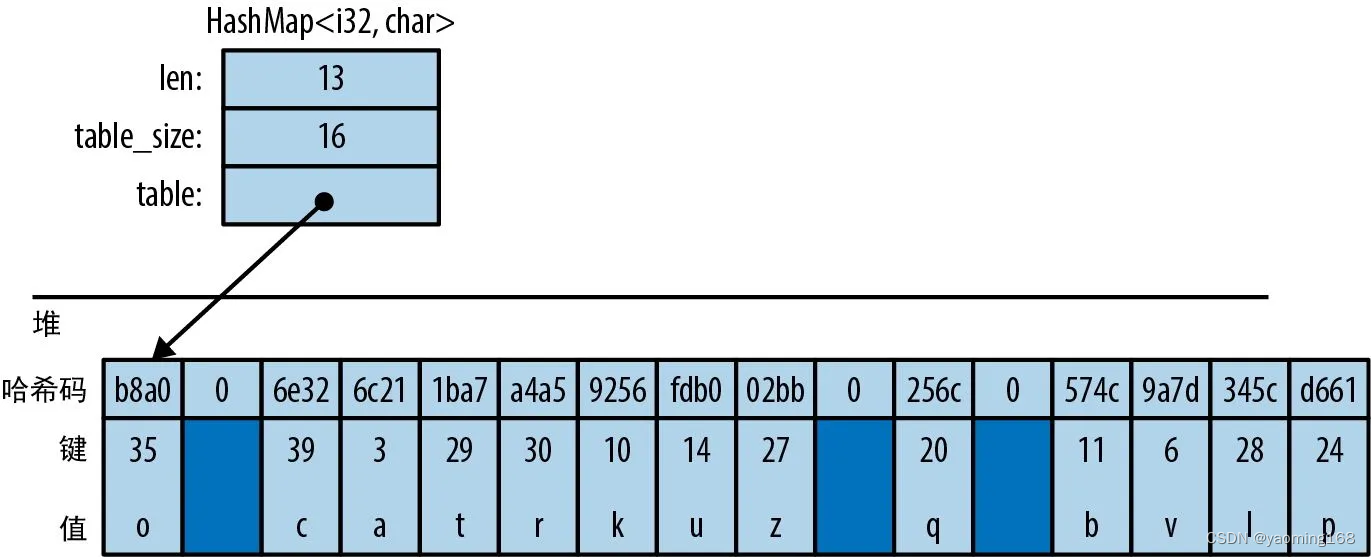
HashMap 会将键和值存储在哈希表中,因此它需要一个实现了 Hash 和 Eq 的键类型 K,即用来求哈希与判断相等性的标准库特型。
HashMap 在内存中的排列方式。深灰色区域表示未使用。所有键、值和缓存的哈希码都存储在一个分配在堆上的表中。添加条目最终会迫使 HashMap 分配一个更大的表并将所有数据移入其中。
下面是创建 Map 的几种方法。
HashMap::new()(新建)
创建新的空 Map。
iter.collect()(收集)
可用于从键 - 值对创建和填充新的 HashMap。iter 必须是 Iterator 类型的。
HashMap::with_capacity(n)(自带容量)
创建一个新的空 HashMap,其中至少有 n 个条目的空间。与向量一样,HashMap 会将数据存储在分配在堆上的单块内存中,因此它们有容量及其相关方法
hash_map.capacity()
hash_map.reserve(additional)
hash_map.shrink_to_fit()
条目
HashMap 和 BTreeMap 都有其对应的 Entry(条目)类型。条目的作用旨在消除冗余的 Map 查找。
对 Map 进行迭代
以下几个方法可以对 Map 进行迭代。
- 按值迭代(for (k, v) in map)以生成 (K, V) 对。这会消耗 Map。
- 按共享引用迭代(for (k, v) in &map)以生成 (&K, &V) 对。
- 按可变引用迭代(for (k, v) in &mut map)以生成 (&K, &mut V) 对。(同样,无法对存储在 Map 中的键进行可变访问,因为这些条目是通过它们的键进行组织的。)
与向量类似,Map 也有 .iter() 方法和 .iter_mut() 方法,它们会返回针对“条目引用”的迭代器,可用来迭代 &map 或 &mut map。
HashSet
Set 是用于快速进行元素存在性测试的集合:
let b1 = large_vector.contains(&"needle"); // 慢,会检查每一个元素
let b2 = large_hash_set.contains(&"needle"); // 快,会按哈希查找
针对整个Set的运算
哈希
std:#️⃣:Hash 是可哈希类型的标准库特型。HashMap 的键和 HashSet 的元素都必须实现 Hash 和 Eq。
![洛谷_P1059 [NOIP2006 普及组] 明明的随机数_python写法](https://img-blog.csdnimg.cn/direct/f4b057db50a34eaeb4658ea8eb05ad1c.png)