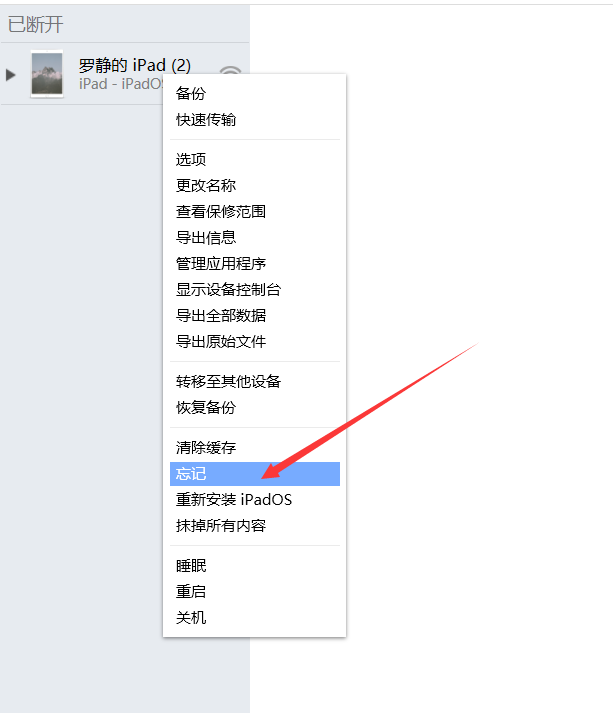
AI视野·今日CS.CV 计算机视觉论文速览
Fri, 26 Jan 2024
Totally 71 papers
👉上期速览✈更多精彩请移步主页

Daily Computer Vision Papers
| Multimodal Pathway: Improve Transformers with Irrelevant Data from Other Modalities Authors Yiyuan Zhang, Xiaohan Ding, Kaixiong Gong, Yixiao Ge, Ying Shan, Xiangyu Yue 我们建议使用来自其他模态的不相关数据来改进特定模态的转换器,例如,使用音频或点云数据集改进 ImageNet 模型。我们想强调的是,目标模态的数据样本与其他模态无关,这将我们的方法与其他利用配对(例如 CLIP 或不同模态的交错数据)的方法区分开来。我们提出了一种名为多模态路径的方法,给定目标模态和为其设计的变压器,我们使用用另一种模态的数据训练的辅助变压器,并构建路径来连接两个模型的组件,以便可以通过以下方式处理目标模态的数据:两种型号。通过这种方式,我们利用从两种模态获得的变压器的通用序列到序列建模能力。作为具体实现,我们像往常一样使用模态特定分词器和任务特定头,但通过提出的名为 Cross Modal Re 参数化的方法利用辅助模型的转换器块,该方法利用辅助权重而无需任何推理成本。在图像、点云、视频和音频识别任务中,我们观察到来自其他模式的不相关数据的显着且一致的性能改进。 |
| Deconstructing Denoising Diffusion Models for Self-Supervised Learning Authors Xinlei Chen, Zhuang Liu, Saining Xie, Kaiming He 在本研究中,我们检查了最初用于图像生成的去噪扩散模型 DDM 的表示学习能力。我们的理念是解构 DDM,逐渐将其转变为经典的去噪自动编码器 DAE。这种解构过程使我们能够探索现代 DDM 的各个组成部分如何影响自监督表示学习。我们观察到,只有极少数现代组件对于学习良好的表示至关重要,而许多其他组件则不是必需的。我们的研究最终得出了一种高度简化的方法,并且在很大程度上类似于经典的 DAE。 |
| Range-Agnostic Multi-View Depth Estimation With Keyframe Selection Authors Andrea Conti, Matteo Poggi, Valerio Cambareri, Stefano Mattoccia 从姿势帧进行 3D 重建的方法需要有关场景度量范围的先验知识,通常是为了恢复沿极线的匹配线索并缩小搜索范围。然而,这种先验可能无法直接获得,或者在实际场景中估计不准确,例如根据视频序列进行室外 3D 重建,因此严重影响性能。在本文中,我们通过提出 RAMDepth 来专注于多视图深度估计,而不需要有关场景度量范围的先验知识,RAMDepth 是一种高效且纯 2D 的框架,可反转深度估计和匹配步骤的顺序。此外,我们还展示了我们的框架能够提供有关用于预测的视图质量的丰富见解的能力。 |
| Rethinking Patch Dependence for Masked Autoencoders Authors Letian Fu, Long Lian, Renhao Wang, Baifeng Shi, Xudong Wang, Adam Yala, Trevor Darrell, Alexei A. Efros, Ken Goldberg 在这项工作中,我们重新检查屏蔽自动编码器 MAE 的解码机制中的补丁间依赖性。我们将 MAE 中掩模补丁重建的解码机制分解为自注意力和交叉注意力。我们的调查表明,掩模补丁之间的自注意力对于学习良好的表示并不是必需的。为此,我们提出了一种新颖的预训练框架 Cross Attention Masked Autoencoders CrossMAE 。 CrossMAE 的解码器仅利用屏蔽标记和可见标记之间的交叉注意力,不会降低下游性能。这种设计还可以仅解码掩码令牌的一小部分,从而提高效率。此外,每个解码器块现在可以利用不同的编码器功能,从而改进表示学习。 CrossMAE 的性能与 MAE 相当,但解码计算量减少了 2.5 至 3.7 倍。在相同计算下,它在 ImageNet 分类和 COCO 实例分割方面也超过了 MAE。 |
| Inconsistency Masks: Removing the Uncertainty from Input-Pseudo-Label Pairs Authors Michael R. H. Vorndran, Bernhard F. Roeck 生成足够的标记数据是有效执行深度学习项目的一个重大障碍,特别是在图像分割的未知领域,与分类任务不同,标记需要大量时间。我们的研究面临着这一挑战,在受硬件资源有限且缺乏广泛数据集或预训练模型限制的环境中运行。我们介绍了 Inconsistency Masks IM 的新颖用途,可以有效过滤图像伪标签对中的不确定性,从而大大提高分割质量,超越传统的半监督学习技术。通过将 IM 与其他方法集成,我们在 ISIC 2018 数据集上展示了出色的二元分割性能,从 10 个标记数据开始。值得注意的是,我们的三个混合模型优于在完全标记数据集上训练的模型。我们的方法在另外三个数据集上始终取得了优异的结果,并且与其他技术相结合时显示出进一步的改进。为了进行全面和稳健的评估,本文对流行的半监督学习策略进行了广泛分析,所有这些策略都在相同的起始条件下进行训练。 |
| UrbanGenAI: Reconstructing Urban Landscapes using Panoptic Segmentation and Diffusion Models Authors Timo Kapsalis 在当代设计实践中,计算机视觉和生成人工智能 genAI 的集成代表了向更具交互性和包容性流程的变革性转变。这些技术提供了图像分析和生成的新维度,这在城市景观重建的背景下尤其重要。本文提出了一种封装在原型应用程序中的新颖工作流程,旨在利用先进图像分割和扩散模型之间的协同作用来实现城市设计的综合方法。我们的方法包括用于详细图像分割的 OneFormer 模型和通过 ControlNet 实现的 Stable Diffusion XL SDXL 扩散模型,用于根据文本描述生成图像。验证结果表明原型应用程序具有很高的性能,在对象检测和文本到图像生成方面都显示出极高的准确性。在对各类城市景观特征的迭代评估中,Intersection 得分优于 Union IoU 和 CLIP 得分就证明了这一点。初步测试包括利用 UrbanGenAI 作为一种教育工具,增强设计教学法的学习体验,并作为一种参与性工具,促进社区驱动的城市规划。早期结果表明,UrbanGenAI 不仅推进了城市景观重建的技术前沿,而且还提供了显着的教学和参与性规划效益。 UrbanGenAI 的持续开发旨在进一步验证其在更广泛的背景下的有效性,并集成实时反馈机制和 3D 建模功能等附加功能。 |
| Learning Robust Generalizable Radiance Field with Visibility and Feature Augmented Point Representation Authors Jiaxu Wang, Ziyi Zhang, Renjing Xu 本文介绍了可泛化神经辐射场 NeRF 的新范例。以前的通用 NeRF 方法将多视图立体技术与基于图像的神经渲染相结合以进行泛化,产生了令人印象深刻的结果,但同时遇到了三个问题。首先,遮挡通常会导致特征匹配不一致。然后,由于采样点和粗糙特征聚合的单独处理,它们会在几何不连续性和局部锐利形状中产生扭曲和伪影。第三,当源视图距离目标视图不够近时,它们基于图像的表示会经历严重的退化。为了应对挑战,我们提出了第一个基于点渲染而不是基于图像渲染构建可泛化神经场的范式,我们将其称为可泛化神经点场 GPF。我们的方法通过几何先验显式地对可见性进行建模,并通过神经特征对其进行增强。我们提出了一种新颖的非均匀对数采样策略来提高渲染速度和重建质量。此外,我们提出了一个可学习的内核,在空间上增强了特征聚合的特征,减轻了几何形状急剧变化的地方的扭曲。此外,我们的表示很容易被操纵。 |
| Progressive Multi-task Anti-Noise Learning and Distilling Frameworks for Fine-grained Vehicle Recognition Authors Dichao Liu 细粒度车辆识别FGVR是智能交通系统必不可少的基础技术,但由于其固有的类内差异而非常困难。以往的FGVR研究大多只关注不同拍摄角度、位置等引起的类内变异,而图像噪声引起的类内变异很少受到关注。本文提出了渐进式多任务抗噪声学习PMAL框架和渐进式多任务蒸馏PMD框架来解决FGVR中由于图像噪声导致的类内变异问题。 PMAL 框架通过将图像去噪视为图像识别中的附加任务并逐步迫使模型学习噪声不变性来实现高识别精度。 PMD 框架将 PMAL 训练模型的知识转移到原始骨干网络中,生成的模型与 PMAL 训练模型的识别精度大致相同,但与原始骨干网络相比没有任何额外开销。结合这两个框架,我们获得的模型在两个广泛使用的标准 FGVR 数据集(即斯坦福汽车和 CompCars)以及三个额外的基于监控图像的车辆类型分类数据集(即北京理工大学BIT车辆、车型图像数据2 VTID2和用于模型识别的车辆图像数据集VIDMMR,无需在原有骨干网络上产生任何额外开销。 |
| Unlocking Past Information: Temporal Embeddings in Cooperative Bird's Eye View Prediction Authors Dominik R le, Jeremias Gerner, Klaus Bogenberger, Daniel Cremers, Stefanie Schmidtner, Torsten Sch n 鸟瞰 BEV 准确、全面的语义分割对于确保自动驾驶中的安全和主动导航至关重要。尽管协作感知已经超过了单代理系统的检测能力,但协作感知中流行的基于相机的算法忽略了从历史观察中得出的有价值的信息。在传感器故障或通信问题期间,随着协作感知恢复为单一代理感知,这种限制变得至关重要,导致性能下降和 BEV 分割图不完整。本文介绍了 TempCoBEV,这是一个时间模块,旨在将历史线索融入当前观测中,从而提高 BEV 地图分割的质量和可靠性。我们提出了一种重要性引导注意力架构来有效地整合时间信息,优先考虑 BEV 地图分割的相关属性。 TempCoBEV 是一个独立的时间模块,可无缝集成到基于最先进相机的协作感知模型中。我们通过对 OPV2V 数据集进行大量实验证明,TempCoBEV 在预测当前和未来 BEV 地图分割方面比非时间模型表现更好,特别是在涉及通信故障的场景中。我们展示了 TempCoBEV 的功效及其将历史线索集成到当前 BEV 地图中的能力,将最佳通信条件下的预测提高了 2 倍,将通信故障情况下的预测提高了 19 倍。 |
| Generalized People Diversity: Learning a Human Perception-Aligned Diversity Representation for People Images Authors Hansa Srinivasan, Candice Schumann, Aradhana Sinha, David Madras, Gbolahan Oluwafemi Olanubi, Alex Beutel, Susanna Ricco, Jilin Chen 捕捉图像中人物的多样性具有挑战性,最近的文献往往侧重于使一两个属性多样化,需要昂贵的属性标签或构建分类器。我们引入了一种多样化的人物图像排名方法,该方法以一种不那么规范、无标签的方式更灵活地符合人类对人物多样性的观念。感知对齐文本派生的人类表示空间路径旨在捕获与人类相关的多样性的所有或许多相关特征,并且当用作标准最大边际相关性 MMR 排名算法中的表示空间时,能够更好地呈现一系列类型的与人相关的多样性,例如残疾,文化服装。 PATHS 分两个阶段创建。首先,使用文本引导方法从预先训练的图像文本模型中提取人物多样性表示。然后,根据人类注释者的感知判断对这种表示进行微调,以便它捕获人类认为最显着的与人相关的相似性方面。 |
| POUR-Net: A Population-Prior-Aided Over-Under-Representation Network for Low-Count PET Attenuation Map Generation Authors Bo Zhou, Jun Hou, Tianqi Chen, Yinchi Zhou, Xiongchao Chen, Huidong Xie, Qiong Liu, Xueqi Guo, Yu Jung Tsai, Vladimir Y. Panin, Takuya Toyonaga, James S. Duncan, Chi Liu 低剂量 PET 提供了一种最大限度减少 PET 成像辐射暴露的宝贵方法。然而,采用额外的 CT 扫描来生成衰减图(用于 PET 衰减校正)的普遍做法会显着提高辐射剂量。为了解决这一问题并进一步减轻低剂量 PET 检查中的辐射暴露,我们提出了 POUR Net,这是一种创新的群体优先辅助代表性网络,旨在从低剂量 PET 生成高质量的衰减图。首先,POUR Net 结合了上下表示网络 OUR Net,以促进高效的特征提取,包括低分辨率抽象特征和精细细节特征,以协助全分辨率级别的深度生成。其次,对 OUR Net 进行补充,这是一种利用综合 CT 导出的 u 地图数据集的人口先验生成机 PPGM,提供了额外的先验信息来帮助 OUR Net 生成。 OUR Net 和 PPGM 在级联框架内的集成可以迭代细化 mu 图生成,从而生成高质量的 mu 图。 |
| Sketch2NeRF: Multi-view Sketch-guided Text-to-3D Generation Authors Minglin Chen, Longguang Wang, Weihao Yuan, Yukun Wang, Zhe Sheng, Yisheng He, Zilong Dong, Liefeng Bo, Yulan Guo 最近,文本转 3D 方法已经使用文本描述实现了高保真 3D 内容生成。然而,生成的对象是随机的并且缺乏细粒度的控制。草图提供了一种廉价的方法来引入这种细粒度的控制。然而,由于这些草图的抽象性和模糊性,实现灵活的控制具有挑战性。在本文中,我们提出了一种多视图草图引导文本到 3D 生成框架,即 Sketch2NeRF,以将草图控制添加到 3D 生成中。具体来说,我们的方法利用预训练的 2D 扩散模型(例如,Stable Diffusion 和 ControlNet)来监督由神经辐射场 NeRF 表示的 3D 场景的优化。我们提出了一种新颖的同步生成和重建方法来有效优化 NeRF。在实验中,我们收集了两种多视图草图数据集来评估所提出的方法。我们证明我们的方法可以通过细粒度草图控制合成 3D 一致的内容,同时对文本提示保持高保真度。 |
| Producing Plankton Classifiers that are Robust to Dataset Shift Authors Cheng Chen, Sreenath Kyathanahally, Marta Reyes, Stefanie Merkli, Ewa Merz, Emanuele Francazi, Marvin Hoege, Francesco Pomati, Marco Baity Jesi 现代浮游生物高通量监测依赖于深度学习分类器来识别水生态系统中的物种。尽管标称性能令人满意,但数据集移位带来了重大挑战,这会导致部署期间性能下降。在我们的研究中,我们将 ZooLake 数据集与 10 个独立部署日的手动注释图像集成在一起,作为测试单元来对数据集外 OOD 性能进行基准测试。我们的分析揭示了分类器最初在数据集中条件下表现良好,但在实际场景中遇到显着失败的情况。例如,标称测试精度为 92 的 MobileNet 显示 OOD 精度为 77。我们系统地调查导致 OOD 性能下降的条件,并提出一种先发制人的评估方法,以识别对新数据进行分类时的潜在陷阱,并查明 OOD 图像中对分类产生不利影响的特征。我们提出了一个三步流程:i 与标称测试性能相比识别 OOD 退化;ii 对退化原因进行诊断分析;iii 提供解决方案。我们发现 BEiT 视觉变换器的集合,具有针对 OOD 鲁棒性的有针对性的增强、几何集成和基于旋转的测试时间增强,构成了最鲁棒的模型,我们将其称为 BEsT 模型。它达到了 83 OOD 准确度,错误集中在容器类上。此外,它对数据集变化的敏感性较低,并且可以很好地再现浮游生物丰度。我们提出的管道适用于通用浮游生物分类器,具体取决于合适的测试单元的可用性。 |
| JUMP: A joint multimodal registration pipeline for neuroimaging with minimal preprocessing Authors Adria Casamitjana, Juan Eugenio Iglesias, Raul Tudela, Aida Ninerola Baizan, Roser Sala Llonch 我们提出了一种以最少的预处理对神经影像模式进行无偏且稳健的多模式注册的管道。虽然典型的多模态研究需要使用多个独立的处理管道,具有多种选项和超参数,但我们提出了一个单一的结构化框架来联合处理不同的图像模态。使用最先进的基于学习的技术可以实现快速推理,这使得所提出的方法适用于每个会话具有多种模式的大规模和/或多队列数据集。该流程目前适用于结构 MRI、静息态 fMRI 和淀粉样蛋白 PET 图像。我们展示了在病例对照研究中使用的衍生生物标志物的预测能力,并研究了不同图像模态之间的跨模态关系。 |
| Exploring the Unexplored: Understanding the Impact of Layer Adjustments on Image Classification Authors Haixia Liu, Tim Brailsford, James Goulding, Gavin Smith, Larry Bull 本文研究了深度学习架构的调整如何影响图像分类中的模型性能。尽管观察到的趋势与整个数据集不一致,但小规模实验产生了初步见解。图像处理管道中的过滤操作至关重要,在预处理之前进行图像过滤可以产生更好的结果。层的选择和顺序以及过滤器的放置会显着影响模型的性能。 |
| AR-GAN: Generative Adversarial Network-Based Defense Method Against Adversarial Attacks on the Traffic Sign Classification System of Autonomous Vehicles Authors M Sabbir Salek, Abdullah Al Mamun, Mashrur Chowdhury 本研究开发了一种基于生成对抗网络 GAN 的防御方法,用于自动驾驶汽车 AV 中的交通标志分类,称为攻击弹性 GAN AR GAN。 AR GAN 的新颖性在于假设对对抗性攻击模型和样本的了解为零,并且在各种对抗性攻击类型下提供一致的高交通标志分类性能。 AR GAN 分类系统由通过重建对图像进行去噪的生成器和对重建图像进行分类的分类器组成。作者在无攻击和各种对抗性攻击下测试了 AR GAN,例如快速梯度符号法 FGSM、DeepFool、Carlini 和 Wagner CW 以及投影梯度下降 PGD。作者考虑了这些攻击的两种形式,即,i 假设攻击者不具备分类器的先验知识的黑盒攻击,以及 ii 假设攻击者完全了解分类器的白盒攻击。 AR GAN 的分类性能与几种基准对抗性防御方法进行了比较。结果表明,AR GAN 和基准防御方法都能抵御黑盒攻击,并且可以实现与未受干扰的图像相似的分类性能。然而,对于本研究中考虑的所有白盒攻击,AR GAN 方法优于基准防御方法。 |
| Vivim: a Video Vision Mamba for Medical Video Object Segmentation Authors Yijun Yang, Zhaohu Xing, Lei Zhu 传统的卷积神经网络的感受野有限,而从计算复杂性的角度来看,基于变压器的网络在构建长期依赖关系方面表现平平。在视频分析任务中处理长视频序列时,这种瓶颈提出了重大挑战。最近,以 Mamba 着称的具有高效硬件感知设计的状态空间模型 SSM 在长序列建模方面取得了令人印象深刻的成就,这促进了深度神经网络在许多视觉任务上的发展。为了更好地捕获视频帧中的可用线索,本文提出了一种基于视频视觉 Mamba 的通用框架,用于医疗视频对象分割任务,名为 Vivim。我们的 Vivim 可以通过我们设计的时空曼巴块有效地将长期时空表示压缩为不同尺度的序列。与现有的基于视频级 Transformer 的方法相比,我们的模型保持了出色的分割结果和更好的速度性能。对美国乳房数据集的广泛实验证明了我们 Vivim 的有效性和效率。 |
| Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks Authors Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, Lei Zhang 我们引入了 Grounded SAM,它使用 Grounding DINO 作为开放集目标检测器,与分段任何模型 SAM 相结合。这种集成能够基于任意文本输入检测和分割任何区域,并为连接各种视觉模型打开了一扇门。如图 1 所示,通过使用多功能的接地 SAM 管道可以实现广泛的视觉任务。例如,仅基于输入图像的自动注释管道可以通过合并 BLIP 和 Recognize Anything 等模型来实现。此外,结合稳定扩散可以实现可控的图像编辑,而 OSX 的集成则有助于快速进行 3D 人体运动分析。 |
| LanDA: Language-Guided Multi-Source Domain Adaptation Authors Zhenbin Wang, Lei Zhang, Lituan Wang, Minjuan Zhu 多源域适应 MSDA 旨在将知识从多个标记源域转移到未标记目标域时减轻数据分布的变化。然而,现有的 MSDA 技术假设目标域图像可用,但却忽略了图像丰富的语义信息。因此,一个悬而未决的问题是,在没有目标域图像的情况下,MSDA 是否可以仅通过文本线索进行指导。通过采用具有联合图像和语言嵌入空间的多模态模型,我们提出了一种基于最优迁移理论的新型语言引导 MSDA 方法,称为 LanDA,它有助于将多个源域迁移到新的目标域,仅需要文本目标域的描述,甚至不需要单个目标域图像,同时保留任务相关信息。 |
| Energy-Based Concept Bottleneck Models: Unifying Prediction, Concept Intervention, and Conditional Interpretations Authors Xinyue Xu, Yi Qin, Lu Mi, Hao Wang, Xiaomeng Li 现有方法(例如概念瓶颈模型 CBM)已成功为黑盒深度学习模型提供基于概念的解释。它们通常通过给定输入预测概念,然后根据预测概念预测最终类别标签来工作。然而, 1 他们经常无法捕捉概念之间的高阶非线性相互作用,例如,纠正预测的概念(例如,黄色乳房)无助于纠正高度相关的概念(例如,黄色腹部),导致最终精度不理想 2 他们无法自然地量化预测概念不同概念和类标签之间的复杂条件依赖关系,例如,对于具有类标签 Kentucky Warbler 和概念 black bill 的图像,模型正确预测另一个概念 black Crown 的概率是多少,因此无法更深入地了解黑色如何盒子模型有效。针对这些限制,我们提出了基于能源的概念瓶颈模型 ECBM。我们的 ECBM 使用一组神经网络来定义候选输入、概念、类元组的联合能量。有了这样一个统一的接口,预测、概念校正和条件依赖量化就可以表示为条件概率,这些概率是通过组合不同的能量函数生成的。我们的 ECBM 解决了现有 CBM 的局限性,提供了更高的准确性和更丰富的概念解释。 |
| Expression-aware video inpainting for HMD removal in XR applications Authors Fatemeh Ghorbani Lohesara, Karen Egiazarian, Sebastian Knorr 头戴式显示器 HMD 是观察扩展现实 XR 环境和虚拟内容不可或缺的设备。然而,头戴式显示器给外部记录技术带来了障碍,因为它们挡住了用户的上脸。这种限制极大地影响了社交 XR 应用程序,特别是电话会议,其中面部特征和眼睛注视信息在创建沉浸式用户体验方面发挥着至关重要的作用。在本研究中,我们提出了一种新的网络,用于基于生成对抗网络 GAN 的用于 HMD 去除 EVI HRnet 的表达感知视频修复。我们的模型有效地填充了有关面部标志和用户的单个无遮挡参考图像的缺失信息。该框架及其组件确保使用参考框架跨框架保存用户的身份。为了进一步提高修复输出的真实感水平,我们引入了一种新颖的面部表情识别 FER 损失函数来保存情感。我们的结果证明了所提出的框架具有从面部视频中去除头戴式显示器的卓越能力,同时保持主体的面部表情和身份。此外,输出沿着修复帧表现出时间一致性。 |
| Enabling Cross-Camera Collaboration for Video Analytics on Distributed Smart Cameras Authors Chulhong Min, Juheon Yi, Utku Gunay Acer, Fahim Kawsar 重叠摄像头提供了从不同角度查看场景的令人兴奋的机会,从而可以进行更高级、更全面和更强大的分析。然而,现有的多摄像机流视觉分析系统大多局限于每个摄像机的处理和聚合以及与工作负载无关的集中处理架构。在本文中,我们介绍了 Argus,这是一种在智能摄像机上具有跨摄像机协作功能的分布式视频分析系统。我们将多摄像机、多目标跟踪确定为多摄像机视频分析的主要任务,并开发了一种新技术,通过利用多个摄像机重叠视场中的对象明智的时空关联,避免冗余、处理繁重的识别任务。我们进一步开发了一套技术,可以在没有云支持的情况下以低延迟跨分布式相机执行这些操作,方法是动态排序相机和对象检查序列,并在智能相机之间灵活分配工作负载,同时考虑网络传输和异构计算能力。使用两个 Nvidia Jetson 设备对三个现实世界重叠相机数据集进行的评估表明,与现有技术相比,Argus 将对象识别数量和端到端延迟分别减少了 7.13 倍、2.19 倍、4.86 倍和 1.60 倍,同时实现了 |
| Incorporating Exemplar Optimization into Training with Dual Networks for Human Mesh Recovery Authors Yongwei Nie, Mingxian Fan, Chengjiang Long, Qing Zhang, Jian Zhu, Xuemiao Xu 我们提出了一种基于优化的新型人体网格从单个图像恢复的方法。给定一个测试样本,以前的方法优化了预训练的回归网络,以最小化 2D 重新投影损失,然而,这会遇到过拟合问题。这是因为测试时的样本优化与预训练过程的关系太弱,并且样本优化损失函数与训练损失函数不同。 1 我们将示例优化纳入训练阶段。在训练过程中,我们的方法首先执行样本优化,然后进行训练时间优化。样本优化可能会走错方向,而后续的训练优化则用于纠正偏差。在训练过程中,样本优化学习使其行为适应训练数据,从而获得测试样本的通用性。 2 我们设计了一种双网络架构来传达新颖的训练范式,它由主回归网络和辅助网络组成,其中我们可以以与训练损失函数相同的形式制定样本优化损失函数。这进一步增强了示例和训练优化之间的兼容性。 |
| MIFI: MultI-camera Feature Integration for Roust 3D Distracted Driver Activity Recognition Authors Jian Kuang, Wenjing Li, Fang Li, Jun Zhang, Zhongcheng Wu 分心驾驶员活动识别在规避风险方面发挥着关键作用,在智能交通系统中尤其有益。然而,大多数现有方法仅使用来自单个视图的视频,并且忽略了难度不一致的问题。与它们不同的是,在这项工作中,我们提出了一种新颖的多摄像头功能集成 MIFI 方法,通过对来自不同摄像头视图的数据进行联合建模,并根据示例的难度来明确重新加权,用于 3D 分心驾驶员活动识别。我们的贡献有两个:1我们提出了一个简单但有效的多相机特征集成框架,并提供了三种类型的特征融合技术。 2 针对分心驾驶员活动识别中难度不一致的问题,提出了一种可联合学习易样本和难样本的周期性学习方法,称为样本重加权。 |
| Scene Graph to Image Synthesis: Integrating CLIP Guidance with Graph Conditioning in Diffusion Models Authors Rameshwar Mishra, A V Subramanyam 生成模型的进步引发了人们对在遵守特定结构准则的同时生成图像的浓厚兴趣。场景图到图像生成就是生成与给定场景图一致的图像的任务之一。然而,视觉场景的复杂性对根据场景图中指定的关系准确对齐对象提出了挑战。现有方法通过首先预测场景布局并使用对抗性训练从这些布局生成图像来完成此任务。在这项工作中,我们引入了一种从场景图生成图像的新颖方法,该方法消除了预测中间布局的需要。我们利用预先训练的文本到图像扩散模型和 CLIP 指导将图形知识转化为图像。为此,我们首先使用基于 GAN 的训练来预训练我们的图形编码器,以将图形特征与相应图像的 CLIP 特征对齐。此外,我们将图特征与给定场景图中存在的对象标签的 CLIP 嵌入相融合,以创建图一致的 CLIP 引导调节信号。在条件输入中,对象嵌入提供图像的粗略结构,图形特征提供基于对象之间关系的结构对齐。最后,我们使用具有重建和 CLIP 对齐损失的图一致条件信号对预训练的扩散模型进行微调。 |
| Double Trouble? Impact and Detection of Duplicates in Face Image Datasets Authors Torsten Schlett, Christian Rathgeb, Juan Tapia, Christoph Busch 用于面部生物识别研究的各种面部图像数据集是通过网络抓取创建的,即互联网上公开提供的图像集合。这项工作提出了一种使用文件和图像哈希来检测完全相同和几乎相同的面部图像副本的方法。该方法通过使用人脸图像预处理进行了扩展。基于人脸识别和人脸图像质量评估模型的附加步骤减少了误报,并促进了对象内和对象间重复集的人脸图像的重复数据删除。所提出的方法应用于五个数据集,即 LFW、TinyFace、Adience、CASIA WebFace 和 C MS Celeb(经过清理的 MS Celeb 1M 变体)。每个数据集中都会检测到重复项,除了 LFW 之外,所有数据集中都有数百到数十万个重复项。人脸识别和质量评估实验表明,重复去除对结果影响较小。 |
| ProCNS: Progressive Prototype Calibration and Noise Suppression for Weakly-Supervised Medical Image Segmentation Authors Y. Liu, L. Lin, K. K. Y. Wong, X. Tang 弱监督分割 WSS 已经成为一种解决方案,通过采用稀疏注释格式(例如点、涂鸦、块等)来减轻注释成本和模型性能之间的冲突。典型的方法尝试利用解剖学和拓扑先验将稀疏注释直接扩展为伪标签。然而,由于缺乏对医学图像中模糊边缘的关注以及对稀疏监督的探索不足,现有方法往往会在噪声区域中生成错误且过度自信的伪建议,导致累积模型错误和性能下降。在这项工作中,我们提出了一种新颖的 WSS 方法,名为 ProCNS,包含根据渐进式原型校准和噪声抑制原理设计的两个协同模块。具体来说,我们设计了一个基于原型的区域空间亲和力 PRSA 损失,以最大化空间和语义元素之间的成对亲和力,为我们感兴趣的模型提供更可靠的指导。相似度是从输入图像和原型精炼预测中得出的。同时,我们提出了自适应噪声感知和掩蔽ANPM模块,以获得更丰富和更具代表性的原型表示,它自适应地识别和掩蔽伪提案中的噪声区域,减少原型计算期间潜在的错误干扰。此外,我们为 ANPM 识别的噪声区域生成专门的软伪标签,提供补充监督。 |
| CreativeSynth: Creative Blending and Synthesis of Visual Arts based on Multimodal Diffusion Authors Nisha Huang, Weiming Dong, Yuxin Zhang, Fan Tang, Ronghui Li, Chongyang Ma, Xiu Li, Changsheng Xu 大规模文本到图像生成模型取得了令人印象深刻的进步,展示了它们合成大量高质量图像的能力。然而,将这些模型应用于艺术图像编辑面临着两个重大挑战。首先,用户很难精心制作文本提示来详细说明输入图像的视觉元素。其次,流行的模式在对特定区域进行修改时,经常会破坏整体的艺术风格,使实现有凝聚力和审美统一的艺术品变得复杂化。为了克服这些障碍,我们构建了创新的统一框架 CreativeSynth,它基于扩散模型,能够协调艺术图像生成领域的多模式输入和多任务。通过将多模态特征与定制的注意力机制相结合,CreativeSynth 通过反转和实时风格转换,促进将现实世界的语义内容输入到艺术领域。这允许精确操作图像样式和内容,同时保持原始模型参数的完整性。严格的定性和定量评估强调了 CreativeSynth 在增强艺术图像保真度并保留其固有的审美本质方面表现出色。 |
| Deep Clustering with Diffused Sampling and Hardness-aware Self-distillation Authors Hai Xin Zhang, Dong Huang 深度聚类由于其无需标记数据即可学习聚类友好表示的能力而受到广泛关注。然而,以前的深度聚类方法倾向于平等地对待所有样本,忽略了潜在分布的方差以及对不同样本进行分类或聚类的不同难度。为了解决这个问题,本文提出了一种新颖的端到端深度聚类方法,具有扩散采样和硬度感知自蒸馏 HaDis 。具体来说,我们首先通过扩散采样对齐 DSA 将实例的一个视图与另一个视图对齐,这有助于提高集群内的紧凑性。为了减轻采样偏差,我们提出了硬度感知自蒸馏 HSD 机制来挖掘最难的正样本和负样本,并以自蒸馏方式自适应调整其权重,这能够处理优化过程中样本贡献的潜在不平衡问题。此外,结合了原型对比学习,以同时增强簇间可分离性和簇内紧凑性。五个具有挑战性的图像数据集的实验结果表明,我们的 HaDis 方法比现有技术具有卓越的聚类性能。 |
| Diverse and Lifespan Facial Age Transformation Synthesis with Identity Variation Rationality Metric Authors Jiu Cheng Xie, Jun Yang, Wenqing Wang, Feng Xu, Hao Gao 过去二十年来,面部衰老一直受到研究关注。尽管之前关于这一主题的工作取得了令人印象深刻的成功,但两个长期存在的问题仍未解决: 1 在目标年龄阶段生成多样化且合理的面部衰老模式 2 衡量原始肖像及其随年龄进展或回归的合成之间的身份变化的合理性。在本文中,我们介绍了DLAT,这是第一个可以在人脸上实现多样化和寿命年龄变换的算法,其中多样性共同体现在面部纹理和形状的变换上。除了模型中嵌入的多样性机制之外,还利用多重一致性限制来使其远离反事实的老化合成。此外,我们提出了一种新的指标来评估输入人脸与其一系列年龄转换代之间年龄差距 IDAG 下身份偏差的合理性,该指标基于从大量真实人脸老化数据中总结出的统计规律。 |
| Unsupervised Spatial-Temporal Feature Enrichment and Fidelity Preservation Network for Skeleton based Action Recognition Authors Chuankun Li, Shuai Li, Yanbo Gao, Ping Chen, Jian Li, Wanqing Li 基于无监督骨架的动作识别最近取得了显着的进展。现有的无监督学习方法存在严重的过拟合问题,因此使用小型网络,大大降低了表示能力。为了解决这个问题,首先研究了基于骨架的动作识别的无监督学习背后的过拟合机制。可以看出,骨架已经是一个相对较高层次和低维度的特征,但与动作识别的特征不在同一流形中。简单地应用现有的无监督学习方法可能会产生区分不同样本而不是动作类别的特征,从而导致过拟合问题。为了解决这个问题,本文提出了一种无监督时空特征丰富和保真度保持框架U FEFP,以生成包含骨架序列所有信息的丰富分布式特征。使用时空图卷积网络和图卷积门循环单元网络作为基本特征提取网络,开发了时空特征转换子网络。基于无监督的 Bootstrap Your Own Latent 学习用于生成丰富的分布式特征,基于无监督借口任务的学习用于保留骨架序列的信息。这两种无监督学习方法作为 U FEFP 进行协作,以产生稳健且有区别的表示。在三个广泛使用的基准(即 NTU RGB D 60、NTU RGB D 120 和 PKU MMD 数据集)上的实验结果表明,与最先进的无监督学习方法相比,所提出的 U FEFP 实现了最佳性能。 |
| GauU-Scene: A Scene Reconstruction Benchmark on Large Scale 3D Reconstruction Dataset Using Gaussian Splatting Authors Butian Xiong, Zhuo Li, Zhen Li 我们在庞大的 U 场景数据集上使用新开发的 3D 表示方法 Gaussian Splatting 引入了一种新颖的大规模场景重建基准。 U Scene 占地超过一平方公里,具有全面的 RGB 数据集和 LiDAR 地面实况。在数据采集方面,我们使用了配备高精度Zenmuse L1激光雷达的Matrix 300无人机,实现了精确的屋顶数据采集。该数据集为高级空间分析提供了城市和学术环境的独特融合,面积超过 1.5 km 2 。我们对使用高斯泼溅的 U 场景进行的评估包括对各种新颖观点的详细分析。 |
| PLCNet: Patch-wise Lane Correction Network for Automatic Lane Correction in High-definition Maps Authors Haiyang Peng, Yi Zhan, Benkang Wang, Hongtao Zhang 在高清地图中,车道元素构成了大部分组成部分,需要严格的定位要求以保证车辆导航的安全。使用 LiDAR 位置分配的视觉车道检测是获取高清地图初始车道的常用方法。然而,由于视觉检测不正确和相机激光雷达校准粗糙,初始车道可能会在不确定的范围内偏离其真实位置。为了减轻手动车道校正的需要,我们提出了一种补丁式车道校正网络 PLCNet,用于自动校正从点云转换的本地 LiDAR 图像中初始车道点的位置。 PLCNet 首先提取多尺度图像特征,并裁剪以每个初始车道点为中心的补丁 ROI 特征。通过应用 ROIAlign,固定大小的 ROI 特征被展平为一维特征。然后,设计一维车道注意模块来计算具有自适应权重的实例级车道特征。最后,由多层感知器推断车道校正偏移并用于校正初始车道位置。考虑到实际应用,我们的自动方法支持将局部校正车道合并到全局校正车道中。 |
| Diffusion-based Data Augmentation for Object Counting Problems Authors Zhen Wang, Yuelei Li, Jia Wan, Nuno Vasconcelos 人群计数由于其在图像理解中的广泛应用而成为计算机视觉中的一个重要问题。目前,这个问题通常使用深度学习方法来解决,例如卷积神经网络 CNN 和 Transformer。然而,深度网络是数据驱动的,很容易过度拟合,特别是当可用的标记人群数据集有限时。为了克服这个限制,我们设计了一个利用扩散模型来生成大量训练数据的管道。我们是第一个生成以位置点图为条件的图像的二进制点图,它通过扩散模型指定人头的位置。我们也是第一个使用这些多样化的合成数据来增强人群计数模型的人。我们提出的 ControlNet 平滑密度图输入显着提高了 ControlNet 在正确位置生成人群的性能。此外,我们提出的扩散模型的计数损失有效地最小化了位置点图和生成的人群图像之间的差异。此外,我们的创新引导采样进一步将扩散过程引导至生成的人群图像与位置点图最准确对齐的区域。总的来说,我们增强了 ControlNet 从位置点图生成指定对象的能力,可用于各种计数问题中的数据增强。此外,我们的框架是通用的,可以轻松适应各种计数问题。 |
| Learning to Manipulate Artistic Images Authors Wei Guo, Yuqi Zhang, De Ma, Qian Zheng 计算机视觉的最新进展显着降低了艺术创作的障碍。基于样本的图像翻译方法由于灵活性和可控性而备受关注。然而,这些方法持有关于语义的假设或需要语义信息作为输入,而准确的语义在艺术图像中并不容易获得。此外,这些方法由于训练数据先验而受到跨域伪影的影响,并且由于空间域中的特征压缩而产生不精确的结构。在本文中,我们提出了一种任意风格图像处理网络SIM Net,它利用语义自由信息作为指导,并以自监督的方式使用区域传输策略来生成图像。我们的方法在一定程度上平衡了计算效率和高分辨率。此外,我们的方法有利于零射击风格的图像处理。 |
| BootPIG: Bootstrapping Zero-shot Personalized Image Generation Capabilities in Pretrained Diffusion Models Authors Senthil Purushwalkam, Akash Gokul, Shafiq Joty, Nikhil Naik 最近的文本到图像生成模型在生成忠实遵循输入提示的图像方面取得了令人难以置信的成功。然而,使用文字来描述所需概念的要求提供了对所生成概念的外观的有限控制。在这项工作中,我们通过提出一种在现有文本到图像扩散模型中启用个性化功能的方法来解决这一缺点。 |
| Improving Pseudo-labelling and Enhancing Robustness for Semi-Supervised Domain Generalization Authors Adnan Khan, Mai A. Shaaban, Muhammad Haris Khan 除了获得领域泛化 DG 之外,视觉识别模型还应该通过利用有限的标签在学习过程中实现数据高效。我们研究半监督域泛化 SSDG 的问题,这对于自动化医疗保健等现实世界的应用至关重要。当给定的训练数据仅部分标记时,SSDG 需要学习跨域可推广模型。实证研究表明,DG 方法在 SSDG 设置中往往表现不佳,可能是因为它们无法利用未标记的数据。与完全监督学习相比,半监督学习 SSL 显示出改进但仍然较差的结果。性能最佳的基于 SSL 的 SSDG 方法面临的一个关键挑战是在多个域转换下选择准确的伪标签,并减少在有限标签下对源域的过度拟合。在这项工作中,我们提出了新的 SSDG 方法,该方法利用一种新颖的不确定性引导伪标记和模型平均 UPLM 。我们的不确定性引导伪标记 UPL 使用模型不确定性来改进伪标记选择,解决多源未标记数据下的不良模型校准问题。 UPL 技术通过我们的新颖模型平均 MA 策略得到增强,可以减轻对标签有限的源域的过度拟合。对关键代表性 DG 数据集的广泛实验表明,我们的方法相对于现有方法表现出有效性。 |
| An Extensible Framework for Open Heterogeneous Collaborative Perception Authors Yifan Lu, Yue Hu, Yiqi Zhong, Dequan Wang, Siheng Chen, Yanfeng Wang 协作感知旨在通过促进多个智能体之间的数据交换来减轻单个智能体感知的局限性,例如遮挡。然而,当前的大多数工作都考虑了一种同质场景,其中所有代理都使用身份传感器和感知模型。实际上,异构代理类型可能会不断出现,并且在与现有代理协作时不可避免地面临领域差距。在本文中,我们引入了一个新的开放异构问题,如何将不断出现的新异构智能体类型容纳到协作感知中,同时确保高感知性能和低集成成本为了解决这个问题,我们提出了 HEterogeneous ALLiance HEAL ,一种新颖的可扩展协作感知框架。 HEAL 首先通过新颖的多尺度前景感知金字塔融合网络与初始代理建立统一的特征空间。当异构新代理以以前未见过的方式或模型出现时,我们通过创新的向后对齐将它们与已建立的统一空间对齐。此步骤只需要对新的Agent类型进行单独训练,因此训练成本极低,可扩展性高。它还可以保护新代理模型的详细信息不被泄露,因为培训可以由代理所有者在本地进行。为了丰富代理数据的异质性,我们带来了 OPV2V H,这是一个具有更多样化传感器类型的新大规模数据集。在 OPV2V H 和 DAIR V2X 数据集上进行的大量实验表明,HEAL 在性能上超越了 SOTA 方法,同时在集成 3 种新代理类型时将训练参数减少了 91.5 个。 |
| TriSAM: Tri-Plane SAM for zero-shot cortical blood vessel segmentation in VEM images Authors Jia Wan, Wanhua Li, Atmadeep Banerjee, Jason Ken Adhinarta, Evelina Sjostedt, Jingpeng Wu, Jeff Lichtman, Hanspeter Pfister, Donglai Wei 在本文中,我们通过引入迄今为止最大的公共基准 BvEM 来解决神经影像领域的重大差距,BvEM 专为体积电子显微镜 VEM 图像中的皮质血管分割而设计。脑血管和神经功能之间的复杂关系强调了血管分析在了解大脑健康方面的重要作用。虽然宏观和中观尺度的成像技术已经获得了大量的关注和资源,但能够揭示复杂血管细节的微尺度 VEM 成像却缺乏必要的基准基础设施。随着研究人员深入研究脑血管系统的微观复杂性,我们的 BvEM 基准代表了揭开神经血管耦合之谜及其对大脑功能和病理学影响的关键一步。 BvEM 数据集基于来自三种哺乳动物物种成年小鼠、猕猴和人类的 VEM 图像卷。我们通过半自动、手动和质量控制流程标准化了分辨率、解决了成像变化并仔细注释了血管,确保了高质量的 3D 分割。此外,我们开发了一种名为 TriSAM 的零样本皮质血管分割方法,该方法利用强大的分割模型 SAM 进行 3D 分割。为了将 SAM 从 2D 分割提升到 3D 体积分割,TriSAM 采用了多种子跟踪框架,利用某些图像平面的可靠性进行跟踪,同时使用其他图像平面来识别潜在的转折点。该方法由三平面选择、基于 SAM 的跟踪和递归重定向组成,可有效实现长期 3D 血管分割,无需模型训练或微调。 |
| A New Image Quality Database for Multiple Industrial Processes Authors Xuanchao Ma, Zehan Wu, Hongyan Liu, Chengxu Zhou, Ke Gu 近年来,图像处理技术在烟雾检测、安全监控、工件检测等多个工业过程中得到了更广泛的应用。图像在采集、压缩、传输、存储、显示等过程中必然会引入不同类型和程度的畸变,这可能会严重降低图像质量,从而严重降低最终的显示效果和清晰度。为了验证现有图像质量评估方法的可靠性,我们建立了一个新的工业过程图像数据库IPID,其中包含通过对50个源图像中的每一个应用不同级别的畸变类型而生成的3000个畸变图像。我们对上述 3000 张图像进行了主观测试,以在非常适合的实验室环境中收集它们的主观质量评级。最后,我们在IPID数据库上进行了对比实验,以研究一些客观图像质量评估算法的性能。 |
| AM-SORT: Adaptable Motion Predictor with Historical Trajectory Embedding for Multi-Object Tracking Authors Vitaliy Kim, Gunho Jung, Seong Whan Lee 许多多目标跟踪 MOT 方法采用卡尔曼滤波器作为运动预测器,假设恒定速度和高斯分布滤波噪声。这些假设使得基于卡尔曼滤波器的跟踪器在线性运动场景中有效。然而,在涉及非线性运动和遮挡的场景中估计未来对象位置时,这些线性假设是一个关键限制。为了解决这个问题,我们提出了一种基于运动的 MOT 方法,该方法具有自适应运动预测器,称为 AM SORT,它适用于估计非线性不确定性。 AM SORT 是 SORT 系列跟踪器的新颖扩展,它以变压器架构取代卡尔曼滤波器作为运动预测器。我们引入了一种历史轨迹嵌入,使转换器能够从一系列边界框中提取时空特征。与 DanceTrack 上最先进的跟踪器相比,AM SORT 的性能具有竞争力(56.3 IDF1 和 55.6 HOTA)。 |
| StyleInject: Parameter Efficient Tuning of Text-to-Image Diffusion Models Authors Yalong Bai, Mohan Zhou, Qing Yang 微调文本到图像生成任务的生成模型的能力至关重要,特别是面对准确解释和可视化文本输入所涉及的复杂性。虽然 LoRA 在语言模型适应方面非常高效,但由于图像生成的复杂要求(例如适应广泛的风格和细微差别),它在文本到图像任务中通常存在不足。为了弥补这一差距,我们引入了 StyleInject,这是一种专门为文本到图像模型量身定制的微调方法。 StyleInject包含多个并行的低秩参数矩阵,保持视觉特征的多样性。它通过根据输入信号的特征调整视觉特征的方差来动态适应不同的风格。这种方法极大地减少了对原始模型文本图像对齐能力的影响,同时巧妙地适应迁移学习中的各种风格。事实证明,StyleInject 在学习和增强一系列先进的社区微调生成模型方面特别有效。 |
| Self-supervised Video Object Segmentation with Distillation Learning of Deformable Attention Authors Quang Trung Truong, Duc Thanh Nguyen, Binh Son Hua, Sai Kit Yeung 视频对象分割是计算机视觉中的一个基本研究问题。最近的技术经常将注意力机制应用于从视频序列中学习对象表示。然而,由于视频数据的时间变化,注意力图可能无法与视频帧中的感兴趣对象很好地对齐,从而导致长期视频处理中累积错误。此外,现有技术利用了复杂的架构,需要高度的计算复杂性,因此限制了将视频对象分割集成到低功率设备中的能力。为了解决这些问题,我们提出了一种基于可变形注意力蒸馏学习的自监督视频对象分割新方法。具体来说,我们设计了一种用于视频对象分割的轻量级架构,可以有效地适应时间变化。这是通过可变形注意力机制实现的,其中捕获注意力模块中视频序列内存的键和值具有跨帧更新的灵活位置。因此,学习到的对象表示适应空间和时间维度。我们通过新的知识蒸馏范式以自我监督的方式训练所提出的架构,其中可变形注意力图被集成到蒸馏损失中。 |
| MambaMorph: a Mamba-based Backbone with Contrastive Feature Learning for Deformable MR-CT Registration Authors Tao Guo, Yinuo Wang, Cai Meng 可变形图像配准是医学图像分析的重要方法。本文介绍了MambaMorph,一种创新的多模态可变形配准网络,专为磁共振MR和计算机断层扫描CT图像对准而设计。 MambaMorph 以其基于 Mamba 的注册模块和对比特征学习方法脱颖而出,解决了多模态注册中普遍存在的挑战。该网络利用 Mamba 模块进行高效的远程建模和高维数据处理,并结合学习细粒度特征以提高配准精度的特征提取器。实验结果展示了 MambaMorph 在 MR CT 配准方面优于现有方法的性能,凸显了其在临床应用中的潜力。这项工作强调了特征学习在多模态注册中的重要性,并将 MambaMorph 定位为该领域的开拓性解决方案。 |
| Knowledge Graph Supported Benchmark and Video Captioning for Basketball Authors Zeyu Xi, Ge Shi, Lifang Wu, Xuefen Li, Junchi Yan, Liang Wang, Zilin Liu 尽管最近出现了视频字幕模型,但如何生成具有特定实体名称和细粒度动作的文本描述还远未解决,但这在篮球直播文本直播等领域有着很大的应用。本文提出了一种新的多模态知识支持的视频字幕篮球基准。具体来说,我们构建了一个多模态篮球比赛知识图谱 MbgKG 以提供视频之外的知识。然后,基于MbgKG构建了包含9种细粒度投篮事件和286名球员知识(即图像和姓名)的多模态篮球比赛视频字幕MbgVC数据集。我们开发了一种编码器解码器形式的新颖框架,名为 Entity Aware Captioner EAC,用于篮球直播文本广播。通过引入双向GRU Bi GRU模块对视频中的时间信息进行编码。利用多头自注意力模块对玩家之间的关系进行建模并选择关键玩家。此外,我们提出了一种新的性能评估指标,名为游戏描述得分 GDS,它不仅衡量语言性能,还衡量名称预测的准确性。 MbgVC 数据集上的大量实验表明,EAC 有效地利用了外部知识,并且优于先进的视频字幕模型。 |
| AscDAMs: Advanced SLAM-based channel detection and mapping system Authors Tengfei Wang, Fucheng Lu, Jintao Qin, Taosheng Huang, Hui Kong, Ping Shen 获得高分辨率、准确的河道地形和沉积条件是渠道化泥石流研究的首要挑战。目前,广泛使用的卫星成像和无人机摄影测量等测绘技术难以精确观测山区长深沟渠的河道内部状况,特别是在汶川地震地区。 SLAM 是一种新兴的 3D 测绘技术,然而,即使对于最先进的 SLAM,长而深的沟壑中极其恶劣的环境也会带来两大挑战 1 非典型特征 2 传感器的剧烈摇摆和振荡。这些问题导致 SLAM 结果存在较大偏差和大量噪声。为了改善此类环境中的 SLAM 映射,我们提出了一种基于 SLAM 的先进通道检测和映射系统,即 AscDAM。它对后处理 SLAM 结果进行了三个主要增强: 1 数字正射影像地图辅助偏差校正算法大大消除了系统误差 2 点云平滑算法大大减少了噪声 3 断面提取算法可以定量评估河道沉积物及其变化。 2023年2月和11月在中国汶川县楚头沟进行了两次野外试验,代表了雨季前后的观测结果。我们展示了 AscDAM 极大改善 SLAM 结果的能力,促进 SLAM 用于绘制特别具有挑战性的环境。该方法弥补了现有技术在检测泥石流河道内部的不足,包括详细的河道形态、侵蚀模式、沉积物区分、体积估计和变化检测。 |
| Appearance Debiased Gaze Estimation via Stochastic Subject-Wise Adversarial Learning Authors Suneung Kim, Woo Jeoung Nam, Seong Whan Lee 最近,基于外观的注视估计已经引起了计算机视觉领域的关注,并且使用各种深度学习技术已经取得了显着的进步。尽管取得了这些进展,但大多数方法的目的是直接从图像中推断注视向量,这会导致对个人特定外观因素的过度拟合。在本文中,我们解决了这些挑战,并提出了一种新颖的框架随机主题明智的对抗性凝视学习 SAZE,它训练一个网络来概括主题的外观。我们使用面部凝视编码器和面部身份分类器以及提出的对抗性损失来设计面部泛化网络 Fgen Net。所提出的损失概括了面部外观因素,以便身份分类器推断出均匀的概率分布。此外,Fgen Net 通过学习机制进行训练,该机制通过在每个训练步骤重新选择主题子集来优化网络,以避免过度拟合。我们的实验结果验证了该方法的稳健性,因为它产生了最先进的性能,在 MPIIGaze 和 EyeDiap 数据集上分别达到 3.89 和 4.42。 |
| LAA-Net: Localized Artifact Attention Network for High-Quality Deepfakes Detection Authors Dat Nguyen, Nesryne Mejri, Inder Pal Singh, Polina Kuleshova, Marcella Astrid, Anis Kacem, Enjie Ghorbel, Djamila Aouada 本文介绍了一种用于高质量深度伪造检测的新方法,称为本地化伪影注意力网络 LAA Net。现有的高质量深度伪造检测方法主要基于监督二元分类器和隐式注意机制。因此,它们不能很好地推广到看不见的操纵。为了解决这个问题,做出了两个主要贡献。首先,提出了多任务学习框架内的显式注意机制。通过结合基于热图和自我一致性注意力策略,LAA Net 被迫专注于一些容易出现伪影的脆弱区域。其次,提出了增强型特征金字塔网络 E FPN 作为一种简单而有效的机制,用于将判别性低级特征传播到最终特征输出中,并具有限制冗余的优点。在多个基准上进行的实验表明,我们的方法在曲线下面积 AUC 和平均精度 AP 方面具有优越性。 |
| Democratizing Fine-grained Visual Recognition with Large Language Models Authors Mingxuan Liu, Subhankar Roy, Wenjing Li, Zhun Zhong, Nicu Sebe, Elisa Ricci 从图像中识别下级类别是计算机视觉领域的一项长期任务,被称为细粒度视觉识别 FGVR。它在现实世界的应用中具有巨大的意义,因为由于物种之间的细微差异,普通外行并不擅长区分鸟类或蘑菇的物种。开发 FGVR 系统的一个主要瓶颈是需要高质量的配对专家注释。为了避免对专家知识的需求,我们提出了细粒度语义类别推理 FineR,它在内部利用大型语言模型 LLM 的世界知识作为代理,以推理细粒度类别名称。具体来说,为了弥合图像和法学硕士之间的模态差距,我们从图像中提取部分级别的视觉属性作为文本,并将该信息提供给法学硕士。基于视觉属性及其内部世界知识,法学硕士对下级类别名称进行推理。 |
| Diffuse to Choose: Enriching Image Conditioned Inpainting in Latent Diffusion Models for Virtual Try-All Authors Mehmet Saygin Seyfioglu, Karim Bouyarmane, Suren Kumar, Amir Tavanaei, Ismail B. Tutar 随着在线购物的增长,买家在其设置中虚拟可视化产品的能力(我们将其定义为“虚拟试穿”)变得至关重要。最近的扩散模型本质上包含一个世界模型,使它们适合在修复上下文中执行此任务。然而,传统的图像条件扩散模型通常无法捕捉产品的细粒度细节。相比之下,个性化驱动的模型(例如 DreamPaint)擅长保留项目的细节,但并未针对实时应用程序进行优化。我们提出了 Diffuse to Choose,一种新颖的基于扩散的图像条件修复模型,它可以有效地平衡快速推理与给定参考项中高保真度细节的保留,同时确保给定场景内容中的准确语义操作。我们的方法基于将参考图像中的细粒度特征直接合并到主扩散模型的潜在特征图中,同时进行感知损失以进一步保留参考项目的细节。 |
| FoVA-Depth: Field-of-View Agnostic Depth Estimation for Cross-Dataset Generalization Authors Daniel Lichy, Hang Su, Abhishek Badki, Jan Kautz, Orazio Gallo 宽视场 FoV 相机可有效捕获大部分场景,这使其在汽车和机器人等多个领域具有吸引力。对于此类应用,从多个图像估计深度是一项关键任务,因此有大量的地面真值 GT 数据可用。不幸的是,大多数 GT 数据都是针对针孔相机的,因此无法正确训练大视场相机的深度估计模型。我们提出了第一种方法,在广泛可用的针孔数据上训练立体深度估计模型,并将其推广到使用更大视场捕获的数据。我们的直觉很简单,我们将训练数据扭曲为规范的大视场表示,并对其进行增强,以允许单个网络推理不同类型的扭曲,否则会妨碍泛化。 |
| S2TPVFormer: Spatio-Temporal Tri-Perspective View for temporally coherent 3D Semantic Occupancy Prediction Authors Sathira Silva, Savindu Bhashitha Wannigama, Roshan Ragel, Gihan Jayatilaka 3D 场景中的整体理解和推理对于自动驾驶系统的成功起着至关重要的作用。与 3D 检测等方法相比,3D 语义占用预测作为自动驾驶和机器人下游任务的预训练任务的演变可以捕获更精细的 3D 细节。现有的方法主要关注空间线索,往往忽视时间线索。基于查询的方法倾向于收敛于计算密集型体素表示以编码 3D 场景信息。本研究介绍了 S2TPVFormer,它是 TPVFormer 的扩展,利用时空转换器架构进行相干 3D 语义占用预测。我们的工作强调了时空线索在 3D 场景感知中的重要性,特别是在 3D 语义占用预测中,探索了较少探索的时间线索领域。利用 Tri Perspective View TPV 表示,我们的时空编码器生成时间上丰富的嵌入,提高预测一致性,同时保持计算效率。为了实现这一目标,我们提出了一种新颖的时空交叉视图混合注意力 TCVHA 机制,促进跨 TPV 视图的有效时空信息交换。 |
| Uncertainty-Guided Alignment for Unsupervised Domain Adaptation in Regression Authors Ismail Nejjar, Gaetan Frusque, Florent Forest, Olga Fink 用于回归的无监督域适应 UDAR 旨在将模型从标记的源域调整为未标记的目标域以执行回归任务。 UDAR 最近的成功工作主要集中在子空间对齐上,涉及整个特征空间内选定子空间的对齐。这与用于分类的特征对齐方法形成对比,后者旨在对齐整个特征空间并已被证明是有效的,但在回归设置中效果较差。具体来说,虽然分类旨在识别整个嵌入维度上的单独簇,但回归会导致数据表示中的结构减少,因此需要额外的指导来实现有效对齐。在本文中,我们通过结合不确定性的指导,提出了一种有效的 UDAR 方法。我们的方法具有双重目的,即提供预测的置信度并充当嵌入空间的正则化。具体来说,我们利用深度证据学习框架,该框架输出每个输入样本的预测和不确定性。我们建议在特征或后验级别使用传统的对齐方法来对齐源域和目标域之间的高阶证据分布的参数。此外,我们建议通过基于标签相似性将源样本与伪标记目标样本混合来增强特征空间表示。这种跨域混合策略产生比随机混合更真实的样本,并引入更高的不确定性,有利于进一步对齐。 |
| Inference Attacks Against Face Recognition Model without Classification Layers Authors Yuanqing Huang, Huilong Chen, Yinggui Wang, Lei Wang 人脸识别FR几乎已经应用到日常生活的方方面面,但它始终伴随着泄露私人信息的潜在风险。目前,几乎所有针对 FR 的攻击模型都严重依赖于分类层的存在。然而,在实践中,FR模型可以通过模型主干获取输入的复杂特征,然后将其与目标进行比较进行推理,这并没有明确涉及采用logit或其他损失的分类层的输出。在这项工作中,我们提倡一种新颖的推理攻击,该攻击由两个阶段组成,适用于没有分类层的实用 FR 模型。第一阶段是成员推理攻击。具体来说,我们分析了中间特征和批量归一化 BN 参数之间的距离。结果表明,该距离是隶属度推断的关键指标。因此,我们设计了一个简单但有效的攻击模型,可以确定人脸图像是否来自训练数据集。第二阶段是模型反转攻击,在第一阶段的攻击模型的指导下,使用预先训练的生成对抗网络 GAN 来重建敏感的私人数据。据我们所知,所提出的攻击模型是针对没有分类层的 FR 模型开发的文献中的第一个。 |
| Value-Driven Mixed-Precision Quantization for Patch-Based Inference on Microcontrollers Authors Wei Tao, Shenglin He, Kai Lu, Xiaoyang Qu, Guokuan Li, Jiguang Wan, Jianzong Wang, Jing Xiao 由于计算和内存资源有限,在微控制器单元 MCU 上部署神经网络面临着巨大的挑战。先前的研究已经探索了基于补丁的推理作为一种在不牺牲模型准确性的情况下节省内存的策略。然而,该技术存在严重的冗余计算开销,导致执行延迟大幅增加。解决这个问题的一个可行的解决方案是混合精度量化,但它面临着精度下降和搜索时间耗时的挑战。在本文中,我们提出了 QuantMCU,这是一种基于补丁的新型推理方法,利用值驱动的混合精度量化来减少冗余计算。我们首先利用价值驱动的补丁分类 VDPC 来保持模型的准确性。 VDPC 根据补丁是否包含异常值将补丁分为两类。对于包含异常值的补丁,我们将 8 位量化应用于后续数据流分支上的特征图。此外,对于没有异常值的补丁,我们在其后续数据流分支的特征图上利用值驱动量化搜索 VDQS 以减少搜索时间。具体来说,VDQS 引入了一种新颖的量化搜索指标,该指标同时考虑了计算量和准确性,并采用熵作为准确性表示以避免额外的训练。 VDQS还采用迭代方法来确定每个特征图的位宽,以进一步加速搜索过程。 |
| Toward Robust Multimodal Learning using Multimodal Foundational Models Authors Xianbing Zhao, Soujanya Poria, Xuejiao Li, Yixin Chen, Buzhou Tang 现有的多模态情感分析任务高度依赖于训练集和测试集是完整的多模态数据的假设,而这种假设很难成立,因为在现实场景中多模态数据通常是不完整的。因此,在模态随机缺失的场景中,鲁棒的多模态模型是首选。最近,基于 CLIP 的多模态基础模型通过学习图像和文本对的对齐跨模态语义,在众多多模态任务中表现出了令人印象深刻的性能,但多模态基础模型也无法直接解决涉及模态缺失的场景。为了缓解这个问题,我们提出了一个简单而有效的框架,即 TRML,使用多模态基础模型实现稳健的多模态学习。 TRML 使用生成的虚拟模态来替换缺失的模态,并对齐生成的模态和缺失的模态之间的语义空间。具体来说,我们设计了一个缺失的模态推理模块来生成虚拟模态并替换缺失的模态。我们还设计了一个语义匹配学习模块来对齐生成的语义空间和缺失的模态。在完整模态的提示下,我们的模型通过利用对齐的跨模态语义空间来捕获缺失模态的语义。 |
| Adaptive Mobile Manipulation for Articulated Objects In the Open World Authors Haoyu Xiong, Russell Mendonca, Kenneth Shaw, Deepak Pathak 在家庭等开放式非结构化环境中部署机器人一直是一个长期存在的研究问题。然而,机器人通常仅在封闭的实验室环境中进行研究,并且先前的移动操纵工作仅限于拾取移动位置,这可以说只是该领域的冰山一角。在本文中,我们介绍了开放世界移动操纵系统,这是一种解决现实铰接对象操作的全栈方法,例如,现实世界中开放式非结构化环境中的门、橱柜、抽屉和冰箱。该机器人利用自适应学习框架,首先通过行为克隆从一小组数据中学习,然后从训练分布之外的新物体的在线实践中学习。我们还开发了一个低成本的移动操纵硬件平台,能够在非结构化环境中安全、自主地在线适应,成本约为 20,000 美元。在我们的实验中,我们在 CMU 校园的 4 栋建筑中使用了 20 个铰接物体。每个对象的在线学习时间不到一个小时,系统能够利用在线适应将 BC 预训练的成功率从 50 提高到 95。 |
| Learning to navigate efficiently and precisely in real environments Authors Guillaume Bono, Herv Poirier, Leonid Antsfeld, Gianluca Monaci, Boris Chidlovskii, Christian Wolf 在陆地机器人自主导航的背景下,创建代理动力学和传感的真实模型是机器人文献和商业应用中的普遍习惯,它们用于基于模型的控制和/或定位和绘图。另一方面,最近的 Embodied AI 文献侧重于在 Habitat 或 AI Thor 等模拟器中训练的模块化或端到端代理,其中重点放在照片真实感渲染和场景多样性上,但高保真机器人运动被分配了特权较低的角色。由此产生的 sim2real 差距极大地影响了训练模型到真实机器人平台的转移。在这项工作中,我们探索在模拟环境中对代理进行端到端训练,以最大限度地减少传感和驱动方面的 sim2real 差距。我们的代理直接预测离散速度命令,这些命令通过真实机器人中的闭环控制来维护。真实机器人的行为(包括底层低级控制器)在改进的栖息地模拟器中进行识别和模拟。用于里程计和定位的噪声模型进一步有助于降低 sim2real 差距。 |
| On generalisability of segment anything model for nuclear instance segmentation in histology images Authors Kesi Xu, Lea Goetz, Nasir Rajpoot 分段任何模型 SAM 在大型且多样化的数据集上进行了预先训练,是计算机视觉中第一个针对对象分割任务的可提示基础模型。在这项工作中,我们通过零样本学习和微调来评估 SAM 在核实例分割任务中的性能。我们将 SAM 与核实例分割中的其他代表性方法进行比较,特别是在模型通用性方面。 |
| Clinical Melanoma Diagnosis with Artificial Intelligence: Insights from a Prospective Multicenter Study Authors Lukas Heinlein, Roman C. Maron, Achim Hekler, Sarah Haggenm ller, Christoph Wies, Jochen S. Utikal, Friedegund Meier, Sarah Hobelsberger, Frank F. Gellrich, Mildred Sergon, Axel Hauschild, Lars E. French, Lucie Heinzerling, Justin G. Schlager, Kamran Ghoreschi, Max Schlaak, Franz J. Hilke, Gabriela Poch, S ren Korsing, Carola Berking, Markus V. Heppt, Michael Erdmann, Sebastian Haferkamp, Konstantin Drexler, Dirk Schadendorf, Wiebke Sondermann, Matthias Goebeler, Bastian Schilling, Eva Krieghoff Henning, Titus J. Brinker 黑色素瘤是一种潜在致命的皮肤癌,在全球范围内发病率很高,早期发现可以改善患者的预后。回顾性研究表明,人工智能AI已被证明有助于增强黑色素瘤检测。然而,很少有前瞻性研究证实这些有希望的结果。现有的研究受到样本量小、数据集过于同质或缺乏罕见黑色素瘤亚型的限制,阻碍了对人工智能及其普遍性的公平和彻底的评估,而这是人工智能在临床环境中应用的一个关键方面。因此,我们评估了 All Data are Ext ADAE ,这是一种用于检测黑色素瘤的已建立的开源集成算法,通过将其诊断准确性与皮肤科医生在前瞻性收集的外部异构测试集上的诊断准确性进行比较,该测试集包括八家不同的医院、四种不同的相机设置、罕见的黑色素瘤亚型和特殊解剖部位。我们通过实时测试时间增强 R TTA 改进了该算法,即提供从多个角度拍摄的病变的真实照片并对预测进行平均,并评估其泛化能力。总体而言,AI 显示出比皮肤科医生更高的平衡准确度 0.798, 95 CI 0.779 0.814 对比 0.781, 95 CI 0.760 0.802 p 0.001,获得更高的灵敏度 0.921, 95 CI 0.900 0.942 对比 0.734, 95 CI 0.701 0.770 p 0.001 在较低特异性的成本 0.673, 95 CI 0.641 0.702 vs. 0.828, 95 CI 0.804 0.852 p 0.001。 |
| Attention-based Efficient Classification for 3D MRI Image of Alzheimer's Disease Authors Yihao Lin, Ximeng Li, Yan Zhang, Jinshan Tang 由于其临床症状微妙而复杂,阿尔茨海默病诊断 AD 的早期诊断是一项具有挑战性的任务。利用图像识别技术的深度学习辅助医学诊断已成为该领域的重要研究课题。这些特征必须准确捕捉大脑解剖结构的主要变化。然而,通过深度学习训练进行特征提取非常耗时且昂贵。本研究提出了一种基于卷积神经网络的新型阿尔茨海默病检测模型。该模型利用预先训练的 ResNet 网络作为主干,结合了 3D 医学图像的后融合算法和注意力机制。实验结果表明,所采用的二维融合算法有效地提高了模型的训练开销。 |
| A real-time rendering method for high albedo anisotropic materials with multiple scattering Authors Shun Fang, Xing Feng, Ming Cui 我们提出了一种基于神经网络的实时体积渲染方法,用于逼真且高效地渲染体积媒体。传统的体绘制方法采用路径追踪来求解辐射传递方程,计算量巨大且无法实现实时绘制。因此,本文利用神经网络来模拟求解辐射传递方程的迭代积分过程,以加速体媒体的体渲染。具体来说,论文首先对体介质进行数据处理,生成多种采样特征,包括密度特征、透过率特征和相位特征。分层透射率场被输入 3D CNN 网络以计算更重要的透射率特征。其次,利用漫反射采样模板和高光采样模板将三类采样特征分层到网络中。该方法可以更多地关注光散射、高光和阴影,然后通过注意力模块选择重要的通道特征。最后,通过主干神经网络预测所有采样模板中心点的散射分布。该方法可以实现逼真的体媒体渲染效果,在保持渲染质量的同时大幅提高渲染速度,对于实时渲染应用具有重要意义。 |
| Sparse and Transferable Universal Singular Vectors Attack Authors Kseniia Kuvshinova, Olga Tsymboi, Ivan Oseledets 对抗性攻击和模型漏洞领域的研究是现代机器学习的基本方向之一。最近的研究揭示了脆弱性现象,了解其背后的机制对于改善神经网络特性和可解释性至关重要。在本文中,我们提出了一种新颖的稀疏通用白盒对抗攻击。我们的方法基于截断幂迭代,为雅可比矩阵隐藏层的 p,q 奇异向量提供稀疏性。使用 ImageNet 基准验证子集,我们在各种设置下分析了所提出的方法,获得了与愚弄率超过 50 的密集基线相当的结果,同时仅损坏 5 个像素,并利用 256 个样本进行扰动拟合。我们还表明,我们的算法允许更高的攻击强度,而不影响人类解决任务的能力。此外,我们研究发现,所构建的扰动在不同模型之间具有高度可转移性,而不会显着降低愚弄率。 |
| Semantic Ensemble Loss and Latent Refinement for High-Fidelity Neural Image Compression Authors Daxin Li, Yuanchao Bai, Kai Wang, Junjun Jiang, Xianming Liu 神经压缩领域的最新进展在 PSNR 和 MS SSIM 测量方面已经超越了传统编解码器。然而,在低比特率下,这些方法可能会引入视觉上令人不快的伪像,例如模糊、色偏和纹理丢失,从而损害图像的感知质量。为了解决这些问题,本研究提出了一种增强的神经压缩方法,旨在实现最佳视觉保真度。我们使用复杂的语义集成损失来训练我们的模型,整合 Charbonnier 损失、感知损失、风格损失和非二元对抗性损失,以提高图像重建的感知质量。此外,我们还实施了一个潜在的细化过程来生成内容感知的潜在代码。这些代码遵守比特率限制,平衡失真和保真度之间的权衡,并将比特分配优先到更重要的区域。我们的实证研究结果表明,这种方法显着提高了神经图像压缩的统计保真度。 |
| WAL-Net: Weakly supervised auxiliary task learning network for carotid plaques classification Authors Haitao Gan, Lingchao Fu, Ran Zhou, Weiyan Gan, Furong Wang, Xiaoyan Wu, Zhi Yang, Zhongwei Huang 颈动脉超声图像的分类是诊断颈动脉斑块的重要手段,对于预测中风风险具有重要的临床意义。最近的研究表明,利用斑块分割作为分类的辅助任务可以通过利用分割和分类任务之间的相关性来提高性能。然而,这种方法依赖于获得大量的挑战来获取分割注释。本文提出了一种新颖的弱监督辅助任务学习网络模型WAL Net,以探索颈动脉斑块分类和分割任务之间的相互依赖关系。斑块分类任务是主要任务,而斑块分割任务作为辅助任务,为提高主要任务的性能提供有价值的信息。辅助任务中采用弱监督学习,彻底摆脱对分割标注的依赖。在武汉大学中南医院包含 1270 张颈动脉斑块超声图像的数据集上进行实验和评估。结果表明,与基线网络相比,所提出的方法在颈动脉斑块分类准确性方面实现了约 1.3 的提高。 |
| Deep Learning Innovations in Diagnosing Diabetic Retinopathy: The Potential of Transfer Learning and the DiaCNN Model Authors Mohamed R. Shoaib, Heba M. Emara, Jun Zhao, Walid El Shafai, Naglaa F. Soliman, Ahmed S. Mubarak, Osama A. Omer, Fathi E. Abd El Samie, Hamada Esmaiel 糖尿病视网膜病变 DR 是视力损害的一个重要原因,强调早期发现和及时干预以避免视力恶化的迫切需要。诊断 DR 本质上是复杂的,因为它需要经验丰富的专家对复杂的视网膜图像进行细致的检查。这使得 DR 的早期诊断对于有效治疗和预防最终失明至关重要。传统的诊断方法依赖于人类对这些医学图像的解释,在准确性和效率方面面临挑战。在本研究中,我们引入了一种新方法,通过采用先进的深度学习技术,与这些传统方法相比,该方法在 DR 诊断中提供了更高的精度。这种方法的核心是迁移学习的概念。这需要使用预先存在的、完善的模型,特别是 InceptionResNetv2 和 Inceptionv3,来提取特征并微调选择的层,以满足此特定诊断任务的独特要求。同时,我们还提出了一个新设计的模型DiaCNN,它是为眼部疾病的分类量身定制的。为了验证所提出方法的有效性,我们利用了眼部疾病智能识别 ODIR 数据集,该数据集包含八种不同的眼部疾病类别。结果是有希望的。结合了迁移学习的 InceptionResNetv2 模型在训练和测试阶段均达到了令人印象深刻的 97.5 准确率。其对应的 Inceptionv3 模型在训练期间达到了更值得称赞的 99.7 准确率,在测试期间达到了 97.5 的准确率。 |
| Conditional Neural Video Coding with Spatial-Temporal Super-Resolution Authors Henan Wang, Xiaohan Pan, Runsen Feng, Zongyu Guo, Zhibo Chen 本文档是最初在 2024 年数据压缩会议上提出的一页摘要的扩展版本。它描述了我们为学习图像压缩 CLIC 2024 挑战赛的视频轨道提出的方法。我们的方案遵循典型的混合编码框架和一些新技术。首先,我们采用Spynet网络来产生精确的运动矢量用于运动估计。其次,我们引入了带有条件帧编码的上下文挖掘方案,以充分利用时空信息。针对CLIC给出的低目标码率,我们集成了时空超分辨率模块来提高码率失真性能。 |
| Dataset and Benchmark: Novel Sensors for Autonomous Vehicle Perception Authors Spencer Carmichael, Austin Buchan, Mani Ramanagopal, Radhika Ravi, Ram Vasudevan, Katherine A. Skinner 自动驾驶汽车视音频系统中采用的传统摄像头支持许多感知任务,但面临低光或高动态范围场景、恶劣天气和快速运动的挑战。事件相机和热感相机等新型传感器提供了解决这些场景的潜力,但它们仍有待充分利用。本文介绍了用于自动驾驶车辆感知的新型传感器 NSAVP 数据集,以促进该主题的未来研究。该数据集是通过一个平台捕获的,该平台包括立体事件、热成像、单色和 RGB 相机以及提供地面真实姿势的高精度导航系统。这些数据是通过重复驾驶两条 8 公里路线收集的,包括不同的照明条件和相反的视角。我们提供关于地点识别任务的基准测试实验,以展示新型传感器在增强关键 AV 感知任务方面的挑战和机遇。据我们所知,NSAVP 数据集是第一个包含立体热像仪以及立体事件和单色相机的数据集。 |
| Tweets to Citations: Unveiling the Impact of Social Media Influencers on AI Research Visibility Authors Iain Xie Weissburg, Mehir Arora, Liangming Pan, William Yang Wang 随着人工智能和机器学习会议上接受的论文数量达到数千篇,研究人员如何获取和阅读研究出版物已经变得不清楚。在本文中,我们研究了社交媒体影响者在提高机器学习研究的知名度方面的作用,特别是他们分享的论文的引用次数。我们编制了包含 8,000 多篇论文的综合数据集,涵盖 2018 年 12 月至 2023 年 10 月的推文,以及基于出版年份、地点和摘要主题的 1 1 匹配对照。我们的分析显示,这些影响者认可的论文的引用显着增加,引用次数中位数比对照组高 2-3 倍。此外,该研究还深入研究了重点作者的地理、性别和机构多样性。 |
| A Systematic Approach to Robustness Modelling for Deep Convolutional Neural Networks Authors Charles Meyers, Mohammad Reza Saleh Sedghpour, Tommy L fstedt, Erik Elmroth 当有大量标记数据可用时,卷积神经网络已被证明可以广泛适用于大量领域。最近的趋势是使用具有越来越大的可调参数集的模型来提高模型精度、减少模型损失或创建更具对抗性的鲁棒模型目标,而这些目标通常彼此不一致。特别是,最近的理论工作提出了关于更大的模型泛化到受控训练和测试集之外的数据的能力的问题。因此,我们研究了 ResNet 模型中隐藏层数量的作用,并在 MNIST、CIFAR10、CIFAR100 数据集上进行了演示。我们测试了各种参数,包括模型的大小、浮点精度以及训练数据和模型输出的噪声水平。为了封装模型的预测能力和计算成本,我们提供了一种方法,该方法使用诱发故障来对作为时间函数的故障概率进行建模,并将其与一个新的指标相关联,该指标使我们能够快速确定训练成本是否模型的价值超过了攻击它的成本。使用这种方法,我们能够使用少量特制样本而不是越来越大的基准数据集来近似预期故障率。我们使用 8、16、32 和 64 位浮点数、各种数据预处理技术以及对 ResNet 模型的五种配置的几种攻击,在 MNIST 和 CIFAR10 数据集上展示了该技术的功效。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com