Get What You Want, Not What You Don't- Image Content Suppression for Text-to-Image Diffusion Models
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
2. 相关工作
3. 方法
3.1 扩散模型
3.2 [EOT] 嵌入的分析
3.3 基于文本嵌入的语义抑制
3.4 推理时文本嵌入优化
4. 实验
5. 局限性
0. 摘要
最近文本到图像扩散模型的成功很大程度上归因于它们能够受复杂文本提示的引导,这使用户能够精确描述所需内容。然而,这些模型在有效抑制生成非预期内容方面存在困难,这些内容明确在提示中要求从生成的图像中省略。在本文中,我们分析了如何操作文本嵌入并从中去除不需要的内容。我们引入了两个贡献,我们称之为软加权正则化和推理时文本嵌入优化。第一种方法对文本嵌入矩阵进行正则化,有效抑制不需要的内容。第二种方法旨在进一步抑制提示的不需要的内容生成,鼓励生成所需内容。我们在广泛的实验证明了我们方法的定量和定性有效性。此外,我们的方法具有对像素空间扩散模型(即 DeepFloyd-IF)和潜在空间扩散模型(即 Stable Diffusion)的泛化能力。
代码:https://github.com/sen-mao/SuppressEOT
2. 相关工作
基于扩散的语义擦除。目前的方法(Gandikota等人,2023年;Kumari等人,2023年;Zhang等人,2023年)已经注意到擦除的重要性,包括版权、艺术风格、裸露等的擦除。
- ESD(Gandikota等人,2023年)利用负向引导来引导预训练模型的微调,旨在实现一个能够擦除特定风格或对象的模型。
- (Kumari等人,2023年) 使用带有和不带有擦除项的两个提示对模型进行微调,以使模型分布与擦除提示相匹配。
- Inst-Inpaint(Yildirim等人,2023年)是一个新颖的修复框架,它训练一个扩散模型,将源图像映射到包含条件文本提示的目标图像。
然而,这些工作都对 SD 模型进行微调,导致输入提示中意外抑制的灾难性忽略。在本文中,我们的目标是在不进一步训练或微调SD模型的情况下从输出图像中移除不需要的主题。
3. 方法
我们的目标是抑制扩散模型中的负目标(negative target)生成。为实现这一目标,我们着重于操作文本嵌入,这本质上控制了主题的生成。简单地消除目标文本嵌入未能从输出中排除相应的对象(图 2a 的第二列和第三列)。我们进行了全面的分析,表明这种失败是由附加的 [EOT] 嵌入引起的(见第 3.2 节)。我们的方法包括两个主要步骤。
在第一步中,我们提出软加权正则化,大大减少了 [EOT] 嵌入中的负目标文本信息(第 3.3 节)。
在第二步中,我们应用推理时文本嵌入优化,该优化包括相对于两个损失优化整个文本嵌入(在第一步中处理)。
- 第一个损失称为负目标提示抑制损失,旨在减弱负目标的注意力图,以引导整个文本嵌入的更新,从而进一步抑制负目标的主题生成。
- 为了防止不希望的副作用,即输出中来自正目标的意外抑制(见附录D.图13的第三行),我们提出正目标提示保留损失。这加强了正目标的注意力图。
推理时文本嵌入优化在第 3.4 节中介绍。在第 3.1 节中,我们对 SD 模型进行了简要介绍,尽管我们的方法不限于特定的扩散模型。
3.1 扩散模型
3.2 [EOT] 嵌入的分析
文本编码器 Γ 将输入提示 p 映射到文本嵌入 c = Γ(p) ∈ R^(M×N)(即,M = 768,N = 77,在 SD 模型中)。这是通过在输入提示 p 之前添加一个开始文本(Start of Text,[SOT])符号,并在末尾附加 N-|p|-1 个结束文本(End of Text,[EOT])填充符号来实现的,总共得到 N 个符号。我们定义文本嵌入
![]()
下面,我们探讨 [EOT] 嵌入的几个方面。
[EOT] 嵌入包含哪些语义信息?我们观察到 [EOT] 嵌入携带重要的语义信息。例如,在使用提示 “a man without glasses” 请求图像时,SD 合成包括负目标 “glasses” 的主体(图 2a 的第一列)。当从文本嵌入 c 中清零 “glasses” 的标记嵌入时,SD 未能丢弃 “glasses”(图 2a 的第二和第三列)。类似地,将所有 [EOT] 嵌入清零仍会生成 “glasses” 主体(图 2a 的第四和第五列)。最后,当同时将 “glasses” 和 [EOT] 标记嵌入清零时,我们成功地从生成的图像中移除了 “glasses”(图 2a 的第六和第七列)。结果表明 [EOT] 嵌入包含有关输入提示的重要信息。请注意,简单地将它们清零通常会导致意外的变化(图 2a 的第七列)。
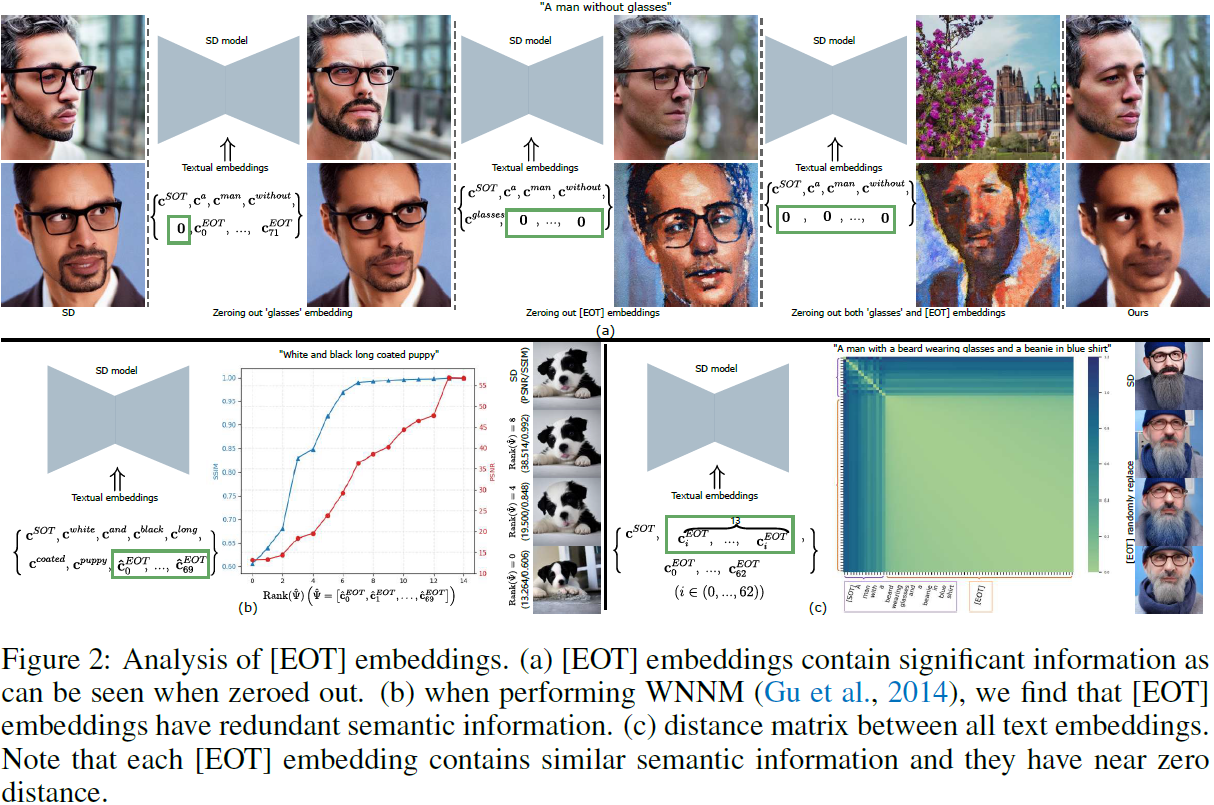
整个 [EOT] 嵌入包含多少信息?我们实验证明 [EOT] 嵌入具有低秩性质,表明它们包含冗余的语义信息(这一观察是基于我们对生成图像进行的统计实验的结果,样本量为100。平均 PSNR 为49.300,SSIM 为 0.992,平均 Rank(ˆΨ)=7.83)。
加权核范数最小化(weighted nuclear norm minimization,WNNM)(Gu等人,2014年)是一种有效的低秩分析方法。我们利用 WNNM 来分析 [EOT] 嵌入。具体而言,我们构建一个 [EOT] 嵌入矩阵
![]()
并执行 WNNM 如下
![]()
其中 Ψ = UΣV^T是 Ψ 的奇异值分解(SVD),Dw(Σ) 是带有加权向量 w 的广义软阈值运算符,即
![]()
奇异值 σ_0 ≥ · · · ≥ σ_(N−|p|−2),权重满足 0 ≤ w_0 ≤ · · · ≤ w_(N−|p|−2)。
为验证 [EOT] 嵌入的低秩特性,WNNM 主要保留 Σ 的前 K 个最大奇异值,将小奇异值清零,最后重构
![]()
![]()
我们使用 Rank( ˆΨ) 表示 ˆΨ 的秩。我们探讨了不同 Rank(ˆΨ) 值对生成的图像的影响。例如,如图 2b 所示,使用提示 “White and black long coated puppy”(此处 |p|=6),我们使用 PSNR 和SSIM 指标评估修改后的图像与 SD 模型的输出。设置 Rank(ˆΨ)=0,清零所有 [EOT] 嵌入,生成的图像保留了与使用所有 [EOT] 嵌入时相似的语义信息。随着 Rank(ˆΨ) 的增加,生成的图像越来越接近 SD 模型的输出。在视觉上,生成的图像看起来与 SD 模型的 Rank( ˆΨ)=4 时的图像相似。在图 2b(中)使用 Rank(ˆΨ)=9 时达到可接受的度量值(PSNR=40.288,SSIM=0.994)。结果表明 [EOT] 嵌入具有低秩特性,并包含冗余的语义信息。
对每个 [EOT] 嵌入的语义对齐。存在总共 76−|p| 个 [EOT] 嵌入。然而,我们发现各种 [EOT] 嵌入之间高度相关,它们通常包含输入提示的语义信息。这一现象在图 2c 中定性和定量地展示。例如,我们输入提示 “戴着眼镜和毛线帽的有胡须的男人穿着蓝色衬衫”。我们随机选择一个 [EOT] 嵌入替换输入文本嵌入(所选择的 [EOT] 嵌入被重复了 |p| 次),如图 2c(左)所示。生成的图像具有相似的语义信息(图 2c(右))。这个结论还可以通过每个 [EOT] 嵌入的距离(图 2c(中))来证明。大多数 [EOT] 嵌入之间的距离很小。总之,我们需要从 76−|p| 个 [EOT] 嵌入中去除负目标信息。
3.3 基于文本嵌入的语义抑制
我们的目标是在图像生成过程中抑制负目标信息。根据前面的分析,我们必须从 [EOT] 嵌入中消除负目标信息。为实现这一目标,我们引入了两种策略,我们称之为软加权正则化和推理时文本嵌入优化。对于前者,我们设计了一个负目标嵌入矩阵,并提出了一种新方法来正则化负目标信息。推理时文本嵌入优化旨在进一步抑制目标提示的负目标生成,并鼓励正目标的生成。我们在图 3 中概述了这两种策略。
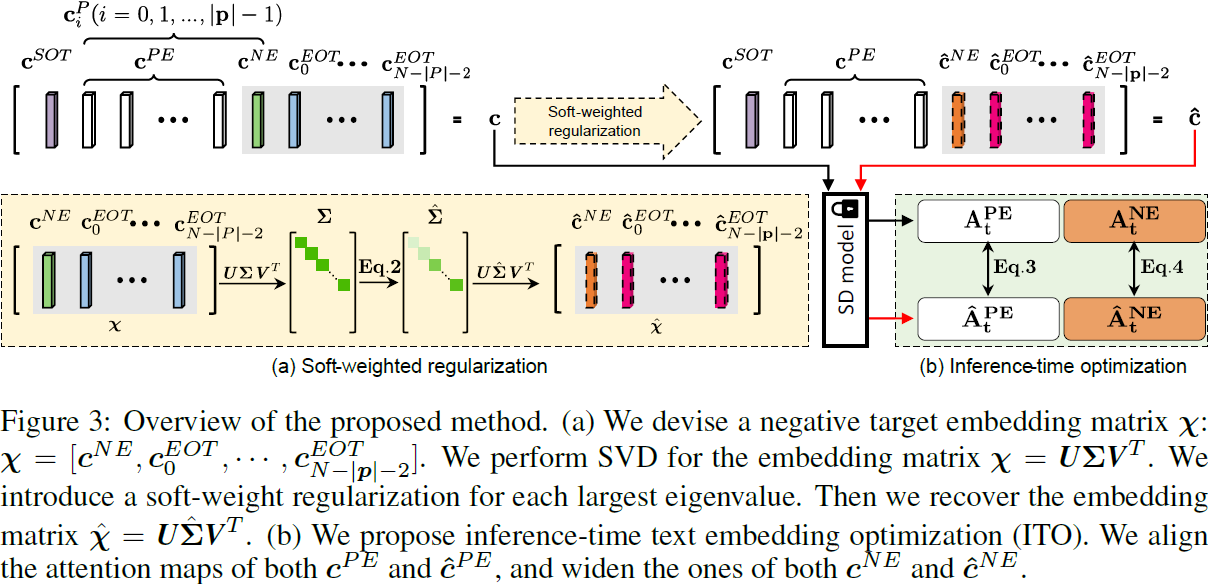
软加权正则化。我们建议使用奇异值分解(SVD)从文本嵌入中提取负目标信息(例如,眼镜)。令 c =
![]()
是来自 CLIP 文本编码器的文本嵌入。如图 3(左)所示,我们将嵌入
![]()
拆分为负目标嵌入集 c^NE 和正目标嵌入集 c^PE。因此,我们有
![]()
我们构建一个负目标嵌入矩阵 χ:
![]()
我们执行 SVD:χ = UΣV^T,其中 Σ = diag(σ0, σ1,· · ·,σ_n0),奇异值σ1 ≥ · · ·≥ σ_n0,n0=min(M,N−|p|−1)。直观地,负目标嵌入矩阵 χ 主要包含了期望被抑制的信息。执行 SVD 后,我们假设主奇异值对应于被抑制的信息(负目标)。然后,为了抑制负目标信息,我们为每个奇异值引入软加权正则化(启示细节解释见附录 B):
![]()
然后,我们恢复嵌入矩阵 ˆχ = UˆΣV^T,其中,
![]()
![]()
![]()
![]()
我们考虑一种特殊情况,即将前 K 或后 K 个奇异值置为 0。如图 4 所示,当将前 K(这里 K=2)个奇异值设置为 0 时,我们能够移除负目标提示(例如,眼镜或胡须)。当将后 K 个奇异值设置为 0 时(这里 K=70),负目标提示信息被保留。这支持我们的假设,即 χ 的主奇异值对应于负目标信息。

3.4 推理时文本嵌入优化
如图 3(右)所示,对于特定的时间步 t,在扩散过程 T → 1 期间,我们得到扩散网络的输出:ϵθ(~zt, t, c),以及相应的注意力图:
![]()
![]()
A^PE_t 对应于 c^PE,而 A^NE_t 对应于我们希望抑制的 c^NE。经过软加权正则化后,我们得到新的文本嵌入和注意力图
![]()
![]()
在这里,我们旨在进一步抑制负目标的生成,并鼓励正目标的信息。我们提出了两个注意力损失来规范注意力图,并修改文本嵌入 ˆc 以引导注意力图集中在与正目标提示对应的特定区域。我们引入了正目标提示保持损失:
![]()
也就是说,该损失试图在时间步 t 加强正目标提示的注意力图。为了进一步抑制负目标提示的生成,我们提出了负目标提示抑制损失:
![]()
完整目标。我们模型的完整目标函数是:
![]()
其中 λ_pl=1,λ_nl=0.5用于平衡保持和抑制的效果。我们使用这个损失来更新文本嵌入 ˆc。
对于真实图像编辑,我们首先利用文本嵌入 c 应用 Null-Text(Mokady等人,2022)将给定的真实图像反演为潜在表示。然后,我们使用所提出的软加权正则化来从 c 中抑制负目标信息,得到 ˆc。接下来,我们在推理过程中应用推理时文本嵌入优化来更新 ˆct,得到最终编辑后的图像。我们的完整算法在算法 1 中呈现。有关 SD 模型在没有参考真实图像的情况下生成负目标的更多详细信息,请参见附录 C。

4. 实验

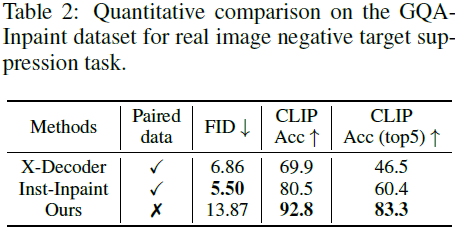
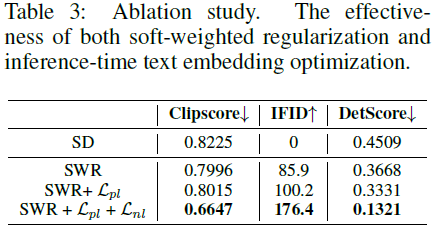



5. 局限性
目前,测试时优化大约需要半分钟,使得提出的方法不适用于需要快速结果的应用程序。但是,我们相信通过专门的工程努力可以显著减少这个时间。





![[嵌入式系统-14]:常见实时嵌入式操作系统比较:RT-Thread、uC/OS-II和FreeRTOS、Linux](https://img-blog.csdnimg.cn/direct/ddf27450e1d9420bb8f56efb77854562.png)