局部变量
写程序时,程序员经常会用到局部变量
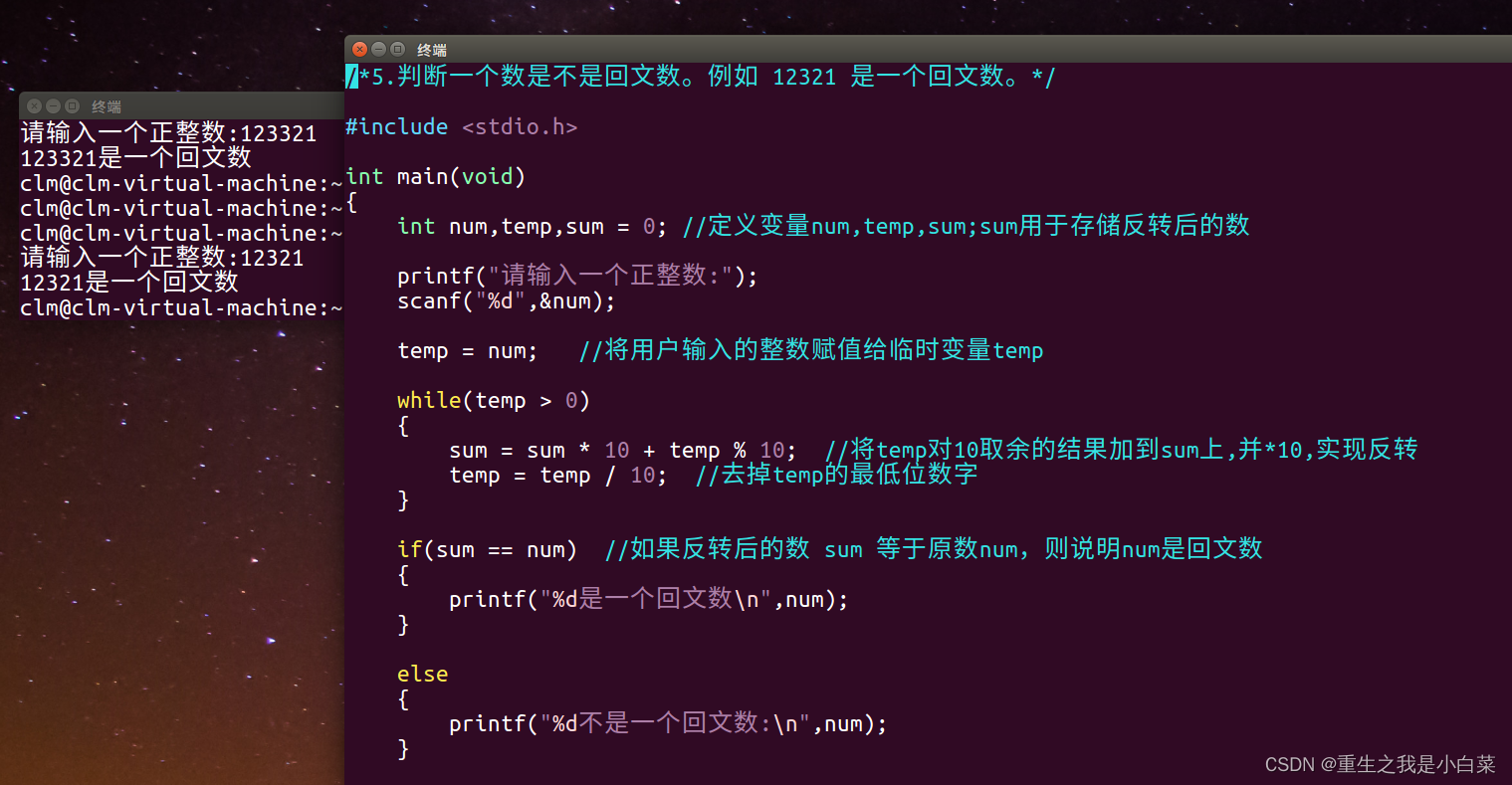
汇编中寄存器、栈,可写区段、堆,函数的局部变量该存在哪里呢?
注意:局部变量有易失性
一旦函数返回,则所有局部变量会失效。
考虑到这种特性,人们将局部变量存放在栈上,在每次函数被调用时,程序从栈上分配一段空间,作为存储局部变量的区域
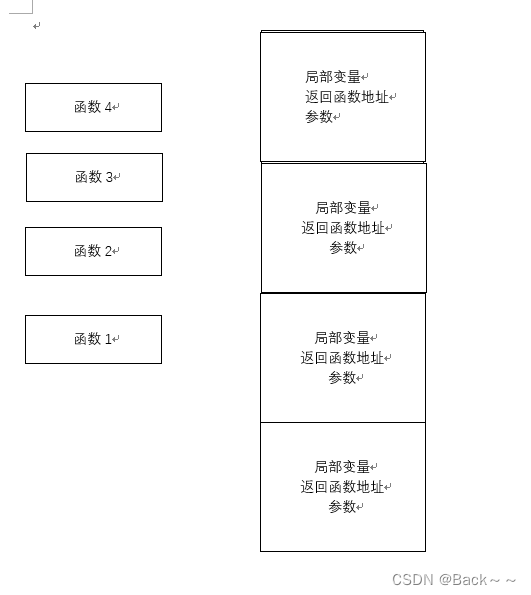
每个函数在被调用时候都会产生这样的局部变量的区域、存储返回地址的区域和参数的区域
程序一层层地深入调用函数,每个函数自己地区域就是一层层地叠在栈上
人们把每个函数自己的这一片区域称位帧,由于这些帧都在栈上,所以又被称为栈帧
栈的内存区域并不一定时固定的,而且随着每次调用的路径不同,栈帧的位置也会不用,那么如何才能正确引用局部变量呢?
虽然栈的内容随着进栈和出栈会一直不断变化,但是一个函数中每个局部变量相对于该函数栈帧的偏移都是固定的
所以可以引入一个寄存器专门来存储当前栈帧的位置,即 ebp称为帧指针
程序在函数初始化阶段赋值ebp位栈帧中间的某个位置,这样可以用ebp引用所有的局部变量
由于上一层的父函数也要使用ebp,因此要在函数开始时先保存ebp,再赋值ebp为自己的栈帧的值,这样的流程在汇编代码中便是经典的组合
push ebp
mov ebp,esp
现在每个函数的栈帧便由局部变量、父栈帧的值,返回地址、参数四部分构成
可以看出ebp在初始化后之际上指向的是父栈帧地址的存储位置
因此,#ebp形成了一个链表,代表一层层的函数调用链
随着编译技术的发展,编译器也可以通过跟踪计算每个指令执行时栈的位置
从而直接越过ebp,而使用栈指针esp来引用局部变量
这样可以节约每次保存ebp时需要的时间,并增加了一个通用寄存器,从而提高了程序性能
于是现在有两种函数:一是有帧指针的函数,二是经过优化后没有帧指针的函数
现代的分析工具将使用高级的栈指针跟踪方法来针对性地处理这两种函数,从而正确处理局部变量
IDA
1.打开文件
IDA Pro使用的是递归下降反汇编算法
在界面中“New”按钮,并在弹出的对话框中选择要打开的文件,也可以单击“Go”按钮,然后在打开的界面中将文件拖拽进去,或者通过"Previous",按钮、双击列表项等快速打开之前打开过的文件
注意:在打开文件之前需要选择正确的构架版本
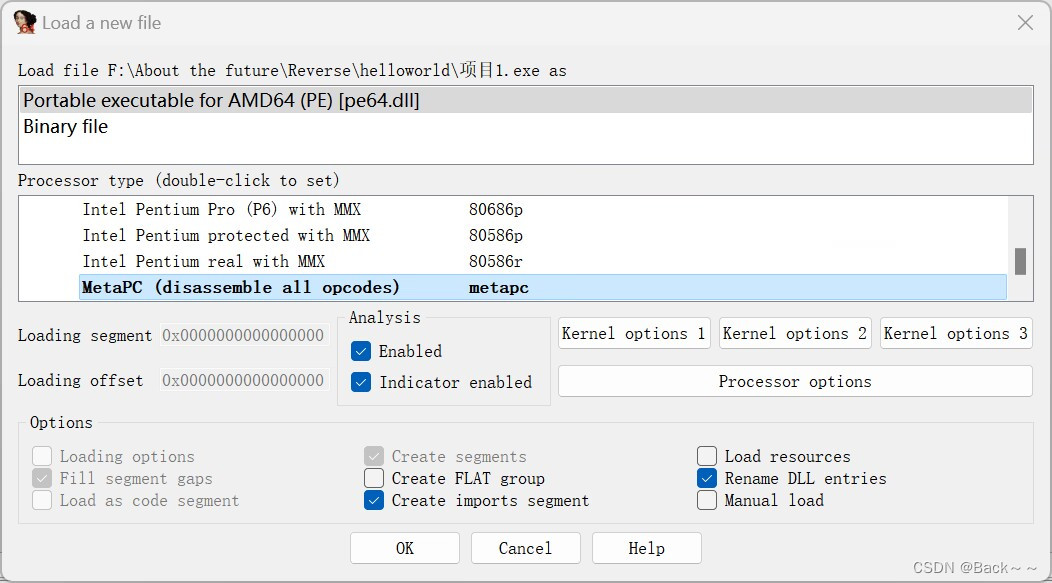
上面IDA显示此文件为AMD64,PE文件,所以用64位打开
2.加载文件
“Load a new file"对话框中的选项主要针对高级用户,初学者可以使用默认设置,不需要改动,单击“OK”按钮,加载文件进去IDA
注意:在初次使用时,IDA可能弹出选择是否使用”Proximity Browser"的对话框,单击NO按钮,进入正常的反汇编界面。
IDA会为文件生成一个数据库(IDB)将,整个文件所需的内容存入其中
以后的分析中,就不再需要访问输入文件了,对数据库中的各种修改也会独立于输入的文件
以下有几个部分
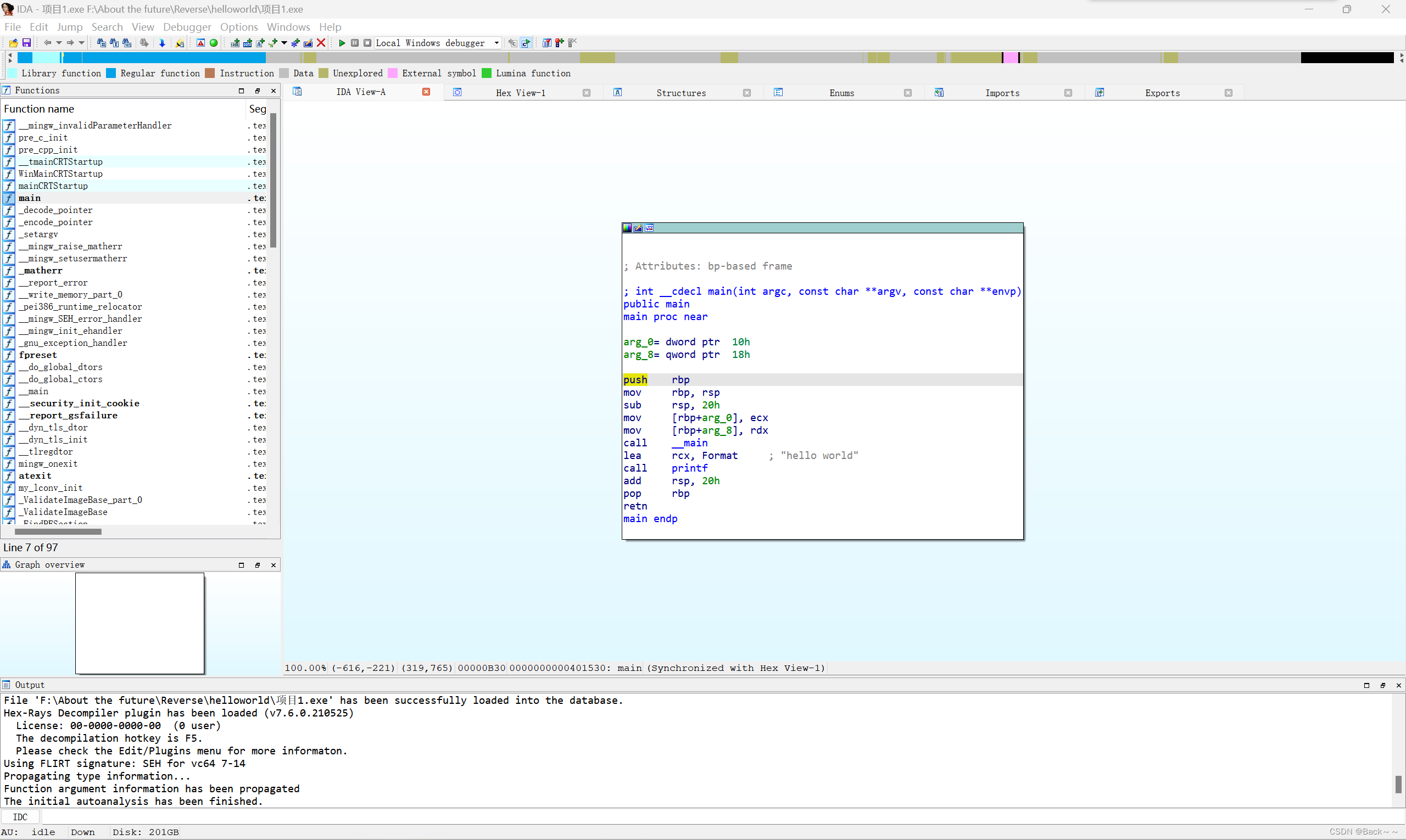
- 导航栏:显示程序的不同类型数据(普通函数、未定义函数的代码、数据、未定义等)的分布情况
- 反汇编的主要窗口:显示反汇编的结果、控制流图等,可以进行拖动、选择等操作
- 函数窗口:显示所有的函数名称和地址(拖动下方滚动条即可查看到),可以通过Ctrl+F组合键进行筛选
- 输出窗口:显示运行过程中IDA的日志,也可以在下方的输入框中输入命令执行
- 状态指示器:显示位“AU:idle”即代表IDA已经完成了对程序的自动化分析
在汇编窗口中,使用右键菜单或者快捷键空格可以在控制流图中和文本界面反汇编键切换
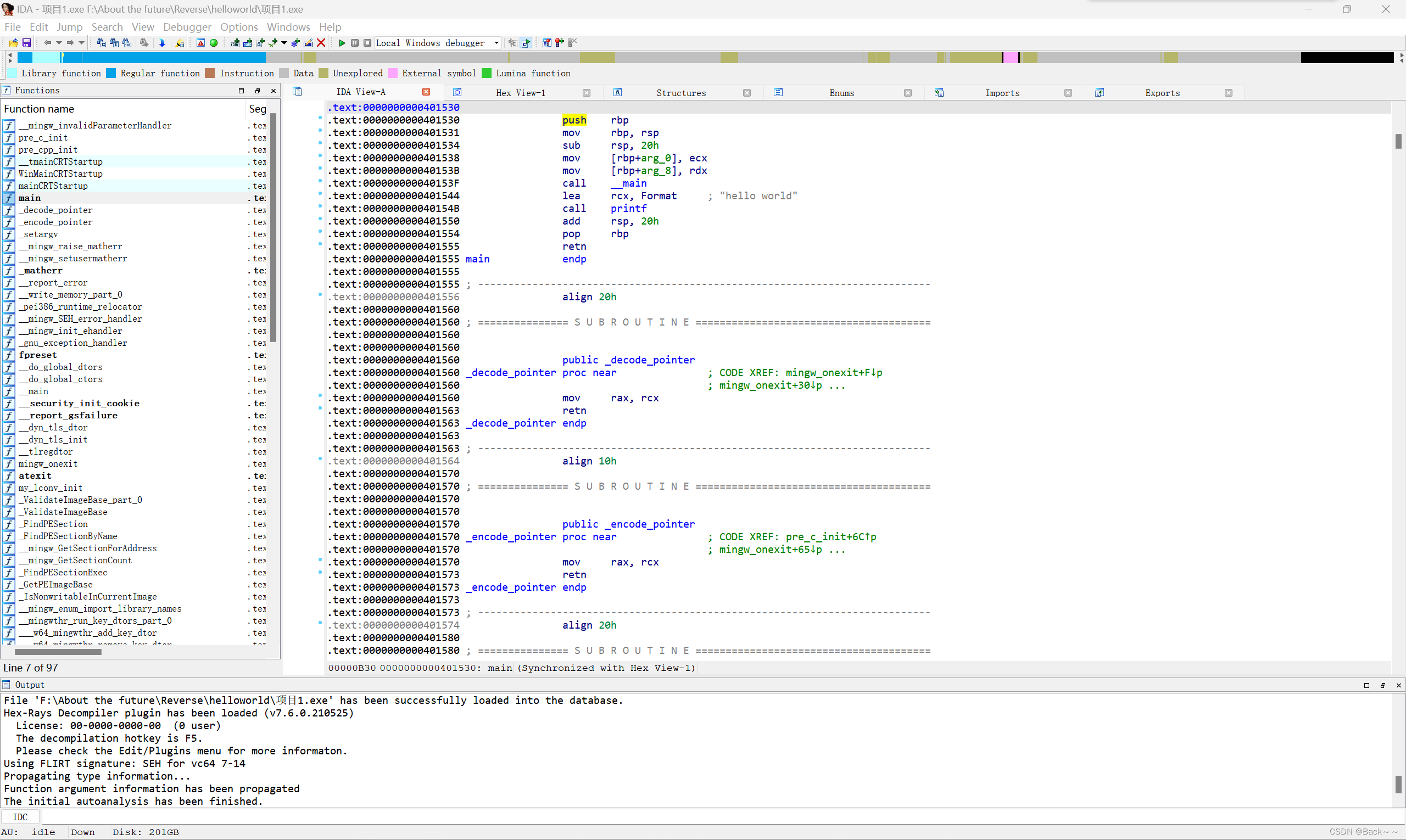
3.数据类型操作
IDA的一大亮点是用户可以通过界面交互来自由控制反汇编的流程
在加载文件的过程中,IDA已经尽其所能,为用户自动定义了大量位置的类型,如IDA将代码段的多数数据正确标注为代码类型,并对其进行反汇编,将特殊段的部分位置标注为8字节类型qword
IDA的能力是有限的,一般情况下并不能正确标出所有的数据类型,而用户可以通过正确的定义1字节或一段区域的类型,纠正IDA出现的问题
低版本的IDA没有撤销功能
用户可以根据地址的颜色来分辨某个位置的数据类型
被标注为代码的位置,将地址将会是黑色显示的;标注为数据的位置,为灰色;未定义数据类型的位置则会使显示位黄色
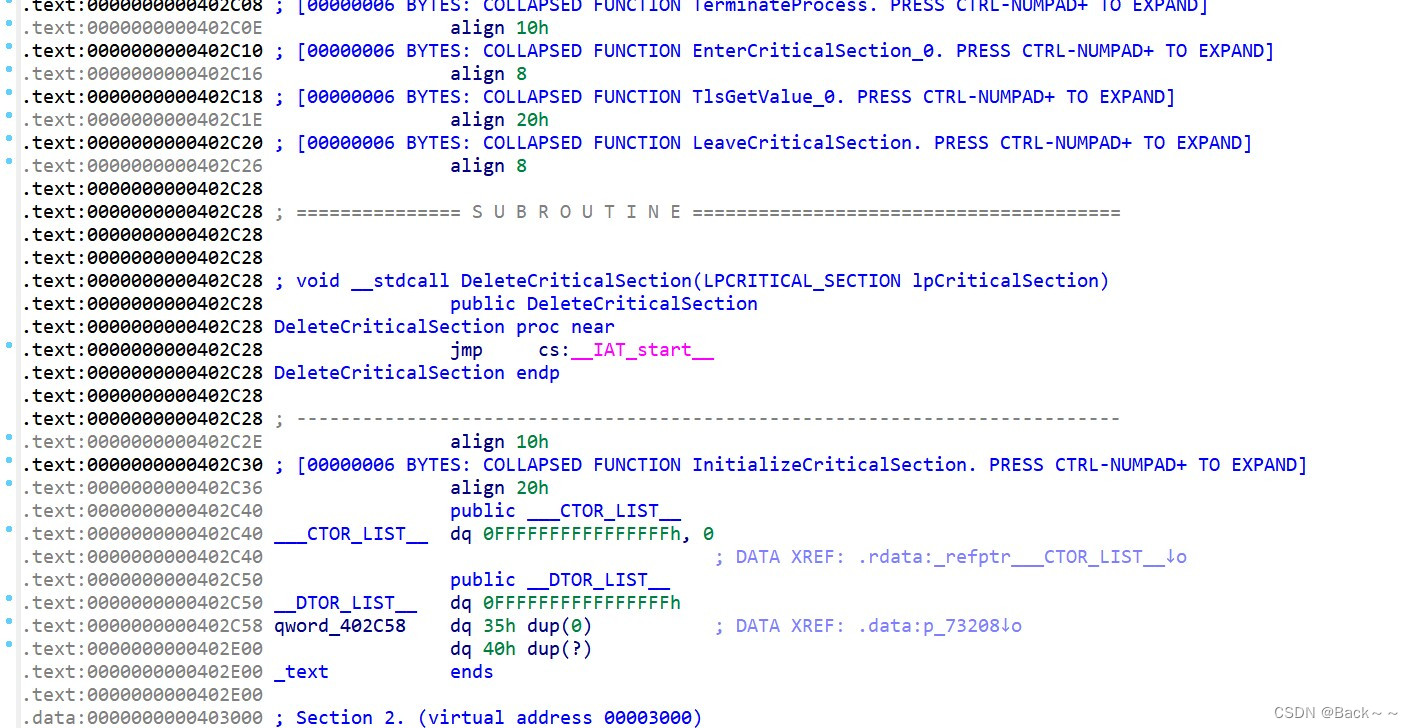
下面介绍快捷键,使用这些快捷键需要光标在对应上才能生效
- U(Undefine)键:即取消一个地方已有的数据类型定义,此时会弹出确认的对话框,单击“Yes”按钮即可
- D(Data)键:即让某一个位置变成数据。一直按D键,这个位置的数据类型将会以1字节(byte/db)、2字节(word/dw)、4字节(dword/dd)、8字节(qword/dq)进行循环。IDA为了防止误操作,如果定义数据的操作会影响到已经有数据类型的位置,IDA会弹出确认的对话框;如果操作的位置及其附近完全是Undefiend,则不会弹出确认对话框
- C(Code)键:即让某一个位置位指令。确认对话框的弹出时机也与D键类似。在定义为指令后,IDA会自动以此为起始位置进行递归下降反汇编
以上是基本的定义数据的快捷键,为了应对日益复杂的数据类型,IDA还内建了各种数额据类型,如数组、字符串等
-
A(ASCII)键:会以该位置为起点定义一个以“\0”结尾的字符串类型,

-
*键:将此处定义为一个数组,此时弹出一个对话框,用来设置数组的属性
-
O(Offset)键:即将此处定义一个地址偏移

4.函数操作
反汇编不是完全连续的,而是由分散的各种函数拼凑而成
每个函数有局部变量、调用约定等信息,控制流图也只能以函数为单位生成和显示,故正确定义函数同样非常重要
IDA处理函数的操作:
- 删除函数:在函数窗口中选中函数后,Delete键
- 定义函数:在反汇编窗口中选中对应后,按P键
- 修改函数参数:在函数窗口中并按Ctrl+E组合键,或反汇编窗口的函数内部按Alt+P组合键
在定义函数后,IDA即可进行很多函数层面的分析,如调用约定分析、栈变量分析、函数调用参数分析等
这些分析对于还原反汇编的高层语义都有着直接和巨大的帮助
5.导航作用
虽然可以通过鼠标点击在不同的函数之间切换,但是随着程序规模的增大,使用这种方式来定位显得不太现实
IDA有导航历史的功能,类似资源管理器和浏览器的历史纪录,可以后退或者前进到某次浏览的地方
6.类型操作
IDA开发了一套类型分析系统,用来处理C/C++语言的各种数据类型(函数声明、变量声明、结构体声明等),并且允许用户自由指定。这无疑让反汇编的还原变得更加准确。选中变量、函数后按Y键,弹出“Please enter the type declaration”对话框,从中输入正确的C语言类型,IDA就可以解析出并自动应用这个类型
7.IDA操作的操作模式
- IDA的反汇编窗口中的各种操作在选中时和未选中时会是有不同的功能 Ag:快捷键C对应的操作在选中反汇编窗口时,能指定递归下降反汇编的扫描区域
- IDA的反汇编窗口中的部分快捷键在多次使用的时候会有不同功能,如快捷键O在对着同一个位置第二次使用时会恢复第一次的操作
- IDA的右键快捷菜单中会标注各种快捷键
- IDA的对话框的按钮可以通过其首字母的来取代鼠标点击(“Yes”,按钮Y就行)
8.IDAPython
IDAPython时IDA内建的Python环境,可以通过接口进行数据库的各种操作,目前它及已经可以执行绝大多数IDA SDK中的C++函数和IDC函数,可以说是同时有着IDC的便捷和C++SDK的强大
Alt+F7组合键或者"File->Script file‘菜单命令
执行Python脚本文件
输出窗口中也有一个Python的Console框
执行Python语句
按Shift+F2组合键,或者”File->Script command“菜单命令,可以打开脚本面板,将”Scripting language"改为Python即可获得一个简易的编译器
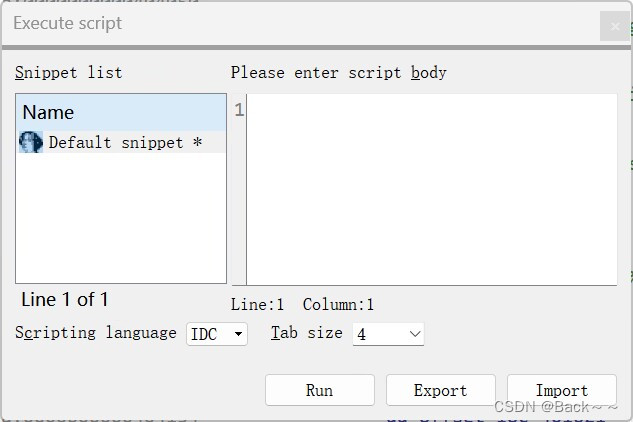
我这里版本可能低了,没有python
9.IDA其他功能
IDA的菜单栏“View——>Open subviews”下可以看见各种类型的窗口
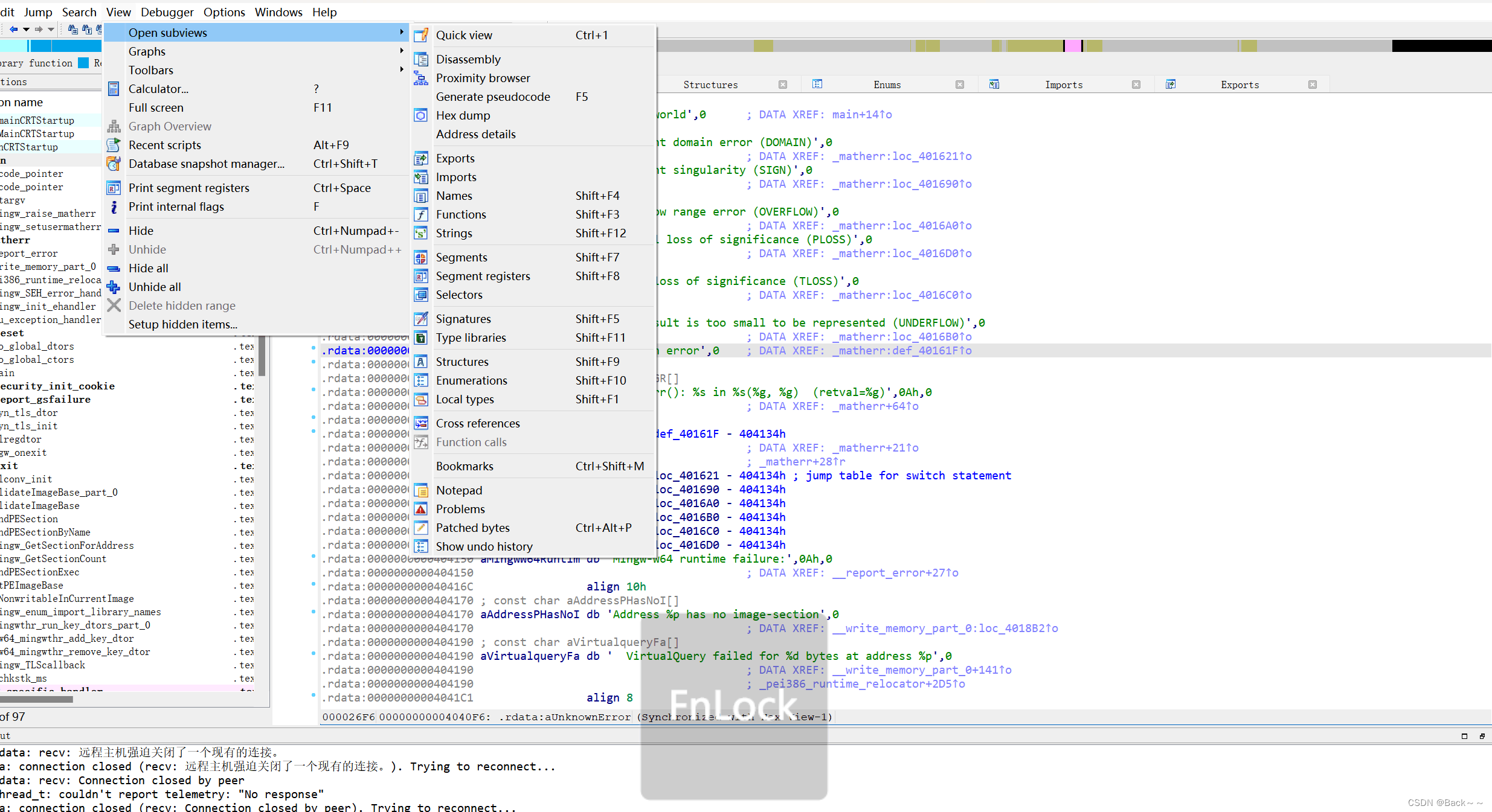
String窗口:按Shift+F12组合键即可以打开,可以识别程序中的字符串,双击即可在反汇编窗口中定位到目标字符串
十六进制窗口:默认打开,可以按F2键对数据库中的数据进行修改,修改后再次按F2键即可应用修改
递归下降反汇编算法
递归下降反汇编算法是一种反汇编算法,它使用递归来分析指令流。它与线性扫描反汇编算法不同,后者逐个分析指令。
递归下降反汇编算法的工作原理如下:
- 从起始地址开始。
- 识别当前指令的类型。
- 根据指令类型,执行相应的操作。
- 如果指令是跳转指令,则将跳转目标地址添加到要反汇编的地址列表中。
- 递归地反汇编地址列表中的地址。
递归下降反汇编算法的优点是:
- 可以轻松处理跳转指令。
- 可以生成更准确的反汇编代码。
递归下降反汇编算法的缺点是:
- 可能存在递归调用过多导致栈溢出的问题。
- 难以处理循环指令。
以下是一些递归下降反汇编算法的示例:
// 识别 add 指令
if (opcode == 0x01) {// 解析第一个操作数operand1 = parse_operand();// 解析第二个操作数operand2 = parse_operand();// 生成汇编代码emit("add %s, %s", operand1, operand2);
}// 识别 jmp 指令
if (opcode == 0x02) {// 解析跳转目标地址target_address = parse_address();// 将跳转目标地址添加到要反汇编的地址列表中addresses.push_back(target_address);
}
在实际应用中,递归下降反汇编算法通常与其他反汇编技术结合使用,以提高反汇编的准确性和效率。