文章目录
- Pre
- 概述
- 源码解析
- 入口索引
- AbstractNioByteChannel.NioByteUnsafe#read
- allocHandle.allocate(allocator)
- 小结
- 传统的零拷贝

Pre
Netty Review - 直接内存的应用及源码分析
概述
Netty 的零拷贝技术是通过优化数据传输过程中的数据复制操作,以降低系统的开销和提高性能。
其原理主要涉及以下几个方面:
-
使用直接内存: Netty 利用 Java NIO 中的 ByteBuffer.allocateDirect() 方法来分配直接内存,直接内存的特点是可以直接被操作系统所管理,不受 Java 堆内存大小的限制,而且可以直接与操作系统进行数据交互,避免了数据在 Java 堆内存和操作系统之间的拷贝。
-
文件传输零拷贝: 在进行文件传输时,Netty 可以通过操作系统提供的零拷贝技术,直接将文件内容从磁盘读取到内核缓冲区,然后通过 DMA(Direct Memory Access)技术将数据直接传输到网络通道,避免了数据在用户空间和内核空间之间的拷贝。
-
内存池: Netty 使用内存池来管理直接内存的分配和释放,避免了频繁地申请和释放内存的开销,提高了内存的重复利用率。
-
CompositeByteBuf: Netty 提供了 CompositeByteBuf 类来实现多个 ByteBuf 的组合,可以将多个缓冲区的内容合并为一个逻辑上的缓冲区,避免了数据在多个缓冲区之间的拷贝。
-
传输过程中的零拷贝: 在网络传输过程中,Netty 利用零拷贝技术将数据从应用程序的缓冲区直接传输到操作系统的网络缓冲区,避免了数据在用户空间和内核空间之间的拷贝,同时可以利用 scatter/gather I/O 操作一次性传输多个缓冲区的数据。
通过以上方式,Netty 实现了数据传输过程中的零拷贝,大大提高了系统的性能和吞吐量,特别是在高并发、大数据量的网络应用场景下,可以显著地降低系统的资源消耗和延迟。

源码解析
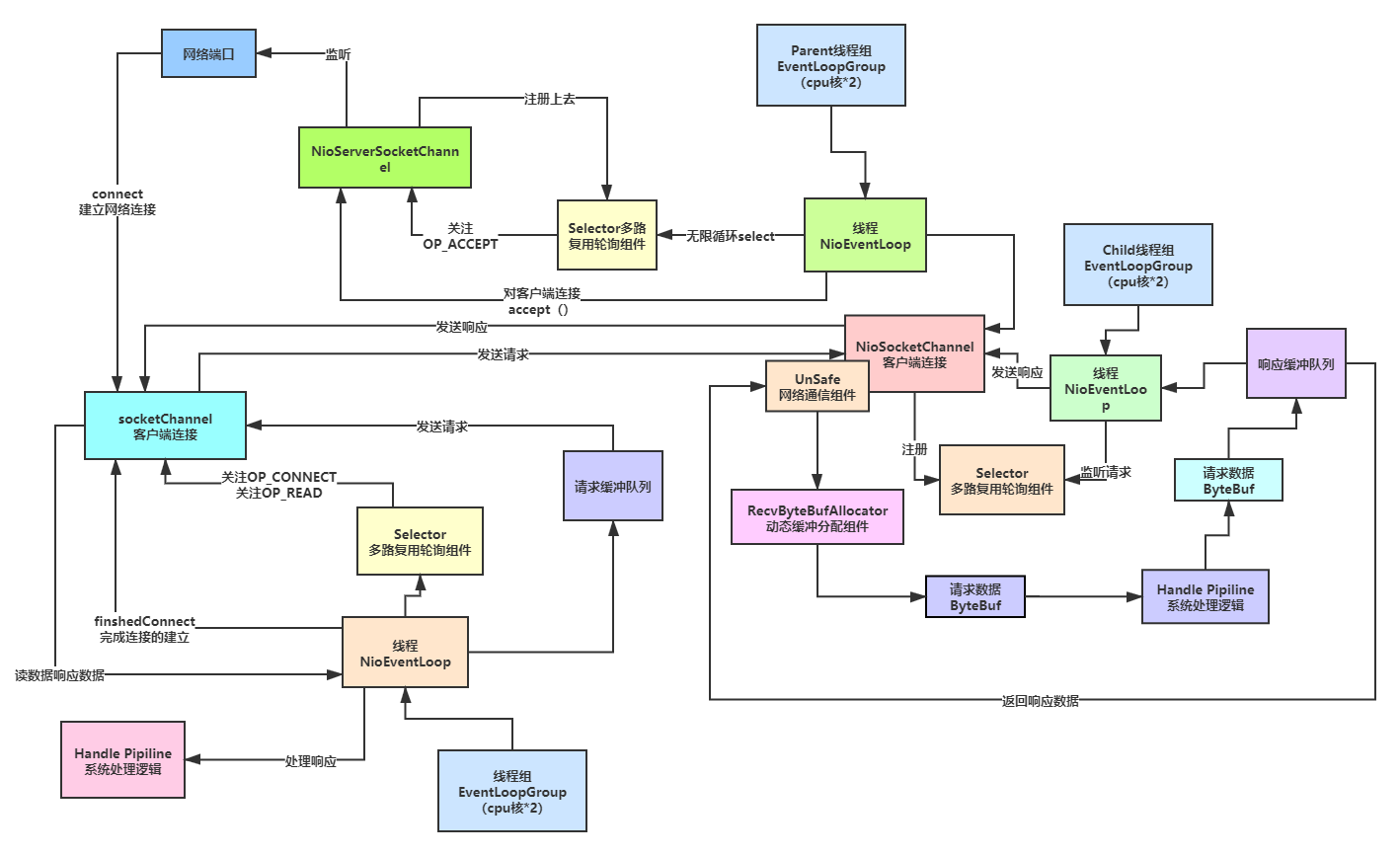
入口索引
结合我们的Netty线程模型源码图 ,找到入口 。
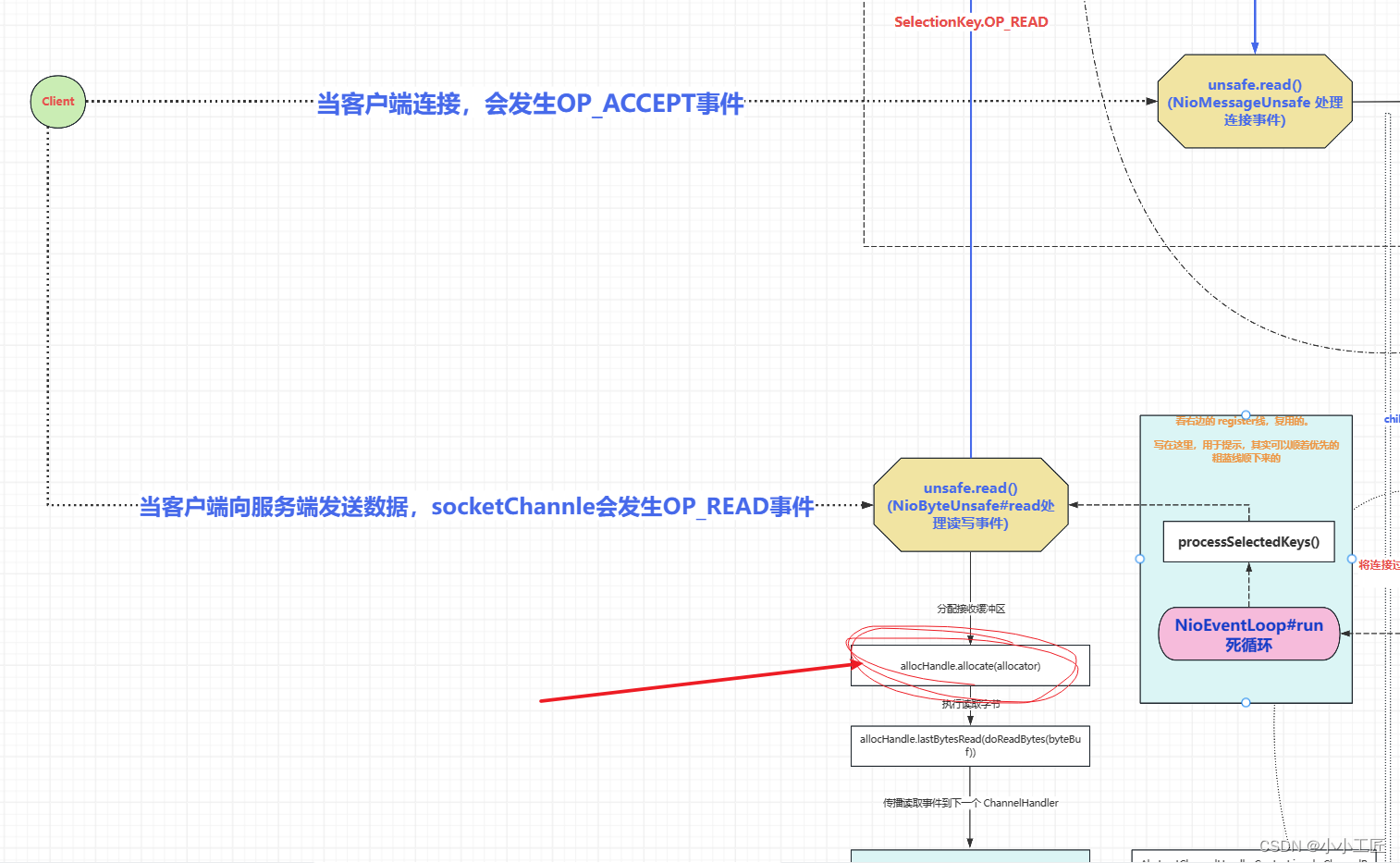
AbstractNioByteChannel.NioByteUnsafe#read
这段代码是 Netty 中的 read() 方法实现,用于从通道中读取数据并触发相应的事件到 ChannelPipeline 中。
@Override
public final void read() {final ChannelConfig config = config(); // 获取通道配置信息if (shouldBreakReadReady(config)) { // 判断是否应该中断读就绪操作clearReadPending(); // 清除读等待标志return;}final ChannelPipeline pipeline = pipeline(); // 获取通道的管道final ByteBufAllocator allocator = config.getAllocator(); // 获取分配器final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle(); // 获取接收字节缓冲区分配句柄allocHandle.reset(config); // 重置分配句柄状态ByteBuf byteBuf = null; // 字节缓冲区boolean close = false; // 是否关闭标志try {do {byteBuf = allocHandle.allocate(allocator); // 分配字节缓冲区allocHandle.lastBytesRead(doReadBytes(byteBuf)); // 读取数据到缓冲区if (allocHandle.lastBytesRead() <= 0) {// 如果没有读取到数据// 释放缓冲区byteBuf.release();byteBuf = null;close = allocHandle.lastBytesRead() < 0; // 是否关闭标志if (close) {// 如果收到 EOF,表示没有数据可读了readPending = false; // 清除读等待标志}break;}allocHandle.incMessagesRead(1); // 增加读取消息数readPending = false; // 清除读等待标志pipeline.fireChannelRead(byteBuf); // 触发通道读事件到管道byteBuf = null;} while (allocHandle.continueReading()); // 继续读取数据,直到不再需要读取为止allocHandle.readComplete(); // 读操作完成pipeline.fireChannelReadComplete(); // 触发通道读完成事件到管道if (close) {closeOnRead(pipeline); // 如果需要关闭通道,执行关闭操作}} catch (Throwable t) {handleReadException(pipeline, byteBuf, t, close, allocHandle); // 处理读取异常} finally {// 检查是否有未处理的读等待操作// 这可能有两个原因:// 1. 用户在 channelRead(...) 方法中调用了 Channel.read() 或 ChannelHandlerContext.read()// 2. 用户在 channelReadComplete(...) 方法中调用了 Channel.read() 或 ChannelHandlerContext.read()// 详见 https://github.com/netty/netty/issues/2254if (!readPending && !config.isAutoRead()) {removeReadOp(); // 移除读操作}}
}
allocHandle.allocate(allocator)
@Override
public ByteBuf allocate(ByteBufAllocator alloc) {return alloc.ioBuffer(guess());
}
在给定的 ByteBufAllocator 上分配一个新的 ByteBuf 实例。
return alloc.ioBuffer(guess()): 使用给定的 ByteBufAllocator 对象调用ioBuffer()方法来分配一个新的 ByteBuf 实例。guess()方法用于估算分配的字节数。
该方法的作用是在给定的 ByteBufAllocator 上分配一个新的 ByteBuf 实例,并返回分配的实例。
alloc.ioBuffer(guess())
@Override
public ByteBuf ioBuffer(int initialCapacity) {if (PlatformDependent.hasUnsafe()) { // 检查当前平台是否支持直接内存return directBuffer(initialCapacity); // 如果支持直接内存,则调用 directBuffer() 方法创建直接内存的 ByteBuf 实例}return heapBuffer(initialCapacity); // 如果不支持直接内存,则调用 heapBuffer() 方法创建堆内存的 ByteBuf 实例
}该方法的作用是根据当前平台是否支持直接内存来选择合适的内存类型(堆内存或直接内存),并根据传入的初始容量参数创建相应类型的 ByteBuf 实例
PlatformDependent.hasUnsafe() ---- true
@Override
public ByteBuf directBuffer(int initialCapacity) {return directBuffer(initialCapacity, DEFAULT_MAX_CAPACITY); // 调用重载方法 directBuffer(int initialCapacity, int maxCapacity),传入默认的最大容量值 DEFAULT_MAX_CAPACITY
}directBuffer(initialCapacity, DEFAULT_MAX_CAPACITY);
@Override
public ByteBuf directBuffer(int initialCapacity, int maxCapacity) {if (initialCapacity == 0 && maxCapacity == 0) { // 如果初始容量和最大容量都为0return emptyBuf; // 返回一个空的 ByteBuf 实例}validate(initialCapacity, maxCapacity); // 验证初始容量和最大容量的合法性return newDirectBuffer(initialCapacity, maxCapacity); // 创建一个新的直接内存的 ByteBuf 实例
}
newDirectBuffer(initialCapacity, maxCapacity)
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {// 获取当前线程的线程缓存PoolThreadCache cache = threadCache.get();// 获取直接内存池PoolArena<ByteBuffer> directArena = cache.directArena;final ByteBuf buf;if (directArena != null) { // 如果直接内存池可用// 从直接内存池中分配内存buf = directArena.allocate(cache, initialCapacity, maxCapacity);} else { // 如果直接内存池不可用// 使用平台相关的方式创建直接内存的 ByteBuf 实例buf = PlatformDependent.hasUnsafe() ?UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);}// 返回一个包装了泄漏感知器的 ByteBuf 实例return toLeakAwareBuffer(buf);
}directArena.allocate(cache, initialCapacity, maxCapacity);
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {// 创建一个新的 PooledByteBuf 实例,其中 maxCapacity 为指定的最大容量PooledByteBuf<T> buf = newByteBuf(maxCapacity);// 使用指定的线程缓存和请求容量来分配内存给 ByteBufallocate(cache, buf, reqCapacity);// 返回分配的 ByteBufreturn buf;
}
这段代码实现了从线程缓存中分配内存给 ByteBuf,并返回分配的 ByteBuf 实例。
allocate(cache, buf, reqCapacity);
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {// 将请求容量规范化为标准容量final int normCapacity = normalizeCapacity(reqCapacity);// 如果容量小于页面大小,则分配小块或微型内存if (isTinyOrSmall(normCapacity)) {int tableIdx;PoolSubpage<T>[] table;boolean tiny = isTiny(normCapacity);if (tiny) { // < 512if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {// 从缓存中成功分配,则直接返回return;}tableIdx = tinyIdx(normCapacity);table = tinySubpagePools;} else {if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {// 从缓存中成功分配,则直接返回return;}tableIdx = smallIdx(normCapacity);table = smallSubpagePools;}final PoolSubpage<T> head = table[tableIdx];// 同步处理双向链表的头部synchronized (head) {final PoolSubpage<T> s = head.next;if (s != head) {// 分配内存assert s.doNotDestroy && s.elemSize == normCapacity;long handle = s.allocate();assert handle >= 0;s.chunk.initBufWithSubpage(buf, null, handle, reqCapacity);incTinySmallAllocation(tiny);return;}}// 没有可用的内存块,则进入分配普通内存块的逻辑synchronized (this) {allocateNormal(buf, reqCapacity, normCapacity);}incTinySmallAllocation(tiny);return;}// 大于页面大小的内存分配if (normCapacity <= chunkSize) {if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {// 从缓存中成功分配,则直接返回return;}synchronized (this) {allocateNormal(buf, reqCapacity, normCapacity);++allocationsNormal;}} else {// 大块内存分配allocateHuge(buf, reqCapacity);}
}
这段代码实现了根据请求的容量大小来分配不同大小的内存块,优先从缓存中分配,如果缓存中没有可用内存,则根据请求的大小分配不同大小的内存块。
小结
Netty的接收和发送ByteBuf采用DIRECT BUFFERS,使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。
如果使用传统的JVM堆内存(HEAP BUFFERS)进行Socket读写,JVM会将堆内存Buffer拷贝一份到直接内存中,然后才能写入Socket中。
JVM堆内存的数据是不能直接写入Socket中的。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。

在传统的Java IO中,使用堆内存(Heap Buffers)进行Socket读写时,数据需要先从堆内存中复制到直接内存(Direct Buffers),然后才能写入Socket。这样就导致了一次缓冲区的内存拷贝。
而在Netty中,采用堆外直接内存(Direct Buffers)进行Socket读写。这样,在数据传输过程中,就不需要进行额外的内存拷贝操作。消息可以直接从直接内存写入Socket中,从而避免了堆内存到直接内存的二次拷贝,提高了数据传输的效率。
使用堆外直接内存的优点包括:
- 减少了内存拷贝次数:消息可以直接从直接内存写入Socket中,避免了额外的内存拷贝操作,提高了数据传输的效率。
- 提高了IO性能:由于减少了内存拷贝操作,可以降低CPU的开销,提高IO性能。
- 更好地利用操作系统资源:堆外直接内存是由操作系统直接管理的,不受Java堆大小的限制,可以更好地利用操作系统的资源。
总的来说,Netty使用堆外直接内存进行Socket读写可以提高IO性能,并降低系统资源的开销,是一种更高效的IO模型。
传统的零拷贝

戳这里