目录
五、目标检测问题
5.1 目标检测基础概念
5.1.1 边界框(bounding box)
5.1.2 锚框(Anchor box)
5.1.3 交并比
5.2 单阶段目标检测模型YOLOv3
5.2.1 YOLOv3模型设计思想
5.2.2 YOLOv3模型训练过程
5.2.3 如何建立输出特征图与预测框之间的关联
5.3 代码实践
五、目标检测问题
对计算机而言,能够“看到”的是图像被编码之后的数字,但它很难理解高层语义概念,比如图像或者视频帧中出现的目标是人还是物体,更无法定位目标出现在图像中哪个区域。目标检测的主要目的是让计算机可以自动识别图片或者视频帧中所有目标的类别,并在该目标周围绘制边界框,标示出每个目标的位置。
为了解决这个问题,结合图片分类任务取得的成功经验,我们可以将目标检测任务进行拆分。假设我们现在有某种方式可以在输入图片上生成一系列可能包含物体的区域,这些区域称为候选区域,在一张图上可以生成很多个候选区域。所以问题的关键就是如何产生候选区域?比如我们可以使用穷举法来产生候选区域。然后对每个候选区域,可以把它单独当成一幅图像来看待,使用图像分类模型对它进行分类,看它属于哪个类别或者背景(即不包含任何物体的类别),再预测目标物体位置,这种方法通常被叫做两阶段检测算法。著名的模型包括R-CNN, Fast R-CNN,Faster R-CNN,Mask R-CNN。
R-CNN:2013年,Ross Girshick 等人于首次将CNN的方法应用在目标检测任务上,他们使用传统图像算法Selective Search产生候选区域,取得了极大的成功,这就是对目标检测领域影响深远的区域卷积神经网络(R-CNN)模型。
Fast R-CNN:2015年,Ross Girshick 对此方法进行了改进,提出了Fast R-CNN模型。通过将不同区域的物体共用卷积层的计算,大大缩减了计算量,提高了处理速度,而且还引入了调整目标物体位置的回归方法,进一步提高了位置预测的准确性。
Faster R-CNN: 2015年,Shaoqing Ren 等人提出了Faster R-CNN模型,提出了RPN的方法来产生物体的候选区域,这一方法不再需要使用传统的图像处理算法来产生候选区域,进一步提升了处理速度。
Mask R-CNN:2017年,Kaiming He 等人提出了Mask R-CNN模型,只需要在Faster R-CNN模型上添加比较少的计算量,就可以同时实现目标检测和物体实例分割两个任务。
另外一类算法,如SSD和YOLO算法则只使用一个网络同时产生候选区域并预测出物体的类别和位置,所以它们通常被叫做单阶段检测算法。
5.1 目标检测基础概念
以下是目标检测问题牵涉到几个重要概念:
5.1.1 边界框(bounding box)
边界框是正好能包含物体的矩形框,通常有两种格式来表示边界框的位置:
- xyxy,即(x1,y1,x2,y2),其中(x1,y1)是矩形框左上角的坐标,(x2,y2)是矩形框右下角的坐标。
- xywh,即(x,y,w,h),其中(x,y)是矩形框中心点的坐标,w是矩形框的宽度,h是矩形框的高度。
在检测任务中,训练数据集的标签里会给出目标物体真实边界框所对应的(x1,y1,x2,y2),这样的边界框也被称为真实框(ground truth box)。模型会对目标物体可能出现的位置进行预测,由模型预测出的边界框则称为预测框(prediction box)。
5.1.2 锚框(Anchor box)
锚框(我愿意叫它蒙框),它是通过算法蒙的多个边界框区域,然后判断这些检测区域内是否包含目标物体,如果有预测从锚框到真实边缘的距离,可以用来快速锁定目标区域。
生成锚框的方法,比如可以在每个像素位置处,生成不同比例、不同尺寸的锚框。
5.1.3 交并比
交并比用来判断锚框和真实框的重合度。这一概念来源于数学中的集合,用来描述两个集合A和B之间的关系,它等于两个集合的交集里面所包含的元素个数,除以它们的并集里面所包含的元素个数。
5.2 单阶段目标检测模型YOLOv3
YOLOv3使用单个网络结构,在产生候选区域的同时即可预测出物体类别和位置,不需要分成两阶段来完成检测任务。另外,YOLOv3算法产生的预测框数目比Faster R-CNN少很多。Faster R-CNN中每个真实框可能对应多个标签为正的候选区域,而YOLOv3里面每个真实框只对应一个正的候选区域。这些特性使得YOLOv3算法具有更快的速度,能到达实时响应的水平。
5.2.1 YOLOv3模型设计思想
YOLOv3算法的基本思想可以分成两部分:
- 按一定规则在图片上产生一系列的候选区域,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。而其余的锚框,objectness将被标注为0,无需标注出位置和类别的标签跟真实框足够接近的那些候选区域会被标注为正样本。这样,对于每个真实框,选出了与它形状最匹配的锚框,将其objectness标注为1,真实框包含的物体类别作为锚框的类别,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。
- 使用卷积神经网络提取图片特征并对候选区域的位置和类别进行预测。这样每个预测框就可以看成是一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数。
5.2.2 YOLOv3模型训练过程
YOLOv3算法训练过程的流程图如下图所示:

- 上图左边是输入图片,上半部分所示的过程是使用卷积神经网络对图片提取特征,随着网络不断向前传播,特征图的尺寸越来越小,每个像素点会代表更加抽象的特征模式,直到输出特征图,其尺寸减小为原图的1/32。
- 下半部分描述了生成候选区域的过程,首先将原图划分成多个小方块,每个小方块的大小是32×32,然后以每个小方块为中心分别生成一系列锚框,整张图片都会被锚框覆盖到。在每个锚框的基础上产生一个与之对应的预测框,根据锚框和预测框与图片上物体真实框之间的位置关系,对这些预测框进行标注。
- 将上方支路中输出的特征图与下方支路中产生的预测框标签建立关联,创建损失函数,开启端到端的训练过程。
5.2.3 如何建立输出特征图与预测框之间的关联
对于一个预测框,网络需要输出(5+C)个实数来表征它是否包含物体、位置和形状尺寸以及属于每个类别的概率,分别是:
objectness:1包含目标物体,0不包含
x, y, w, h:偏移位置信息,使得预测框可以和真实框重合
C:类别概率,c1, c2, c3...,有几个类别就有几个数
由于我们在每个小方块区域都生成了K个预测框,则所有预测框一共需要网络输出的预测值数目是:[K(5+C)]×m×n
还有更重要的一点是网络输出必须要能区分出小方块区域的位置来,不能直接将特征图连接一个输出大小为[K(5+C)]×m×n的全连接层。因此要对特征图进行多次卷积,并将最终的输出通道数设置为K(5+C),即可将生成的特征图与每个预测框所需要的预测值巧妙的对应起来。
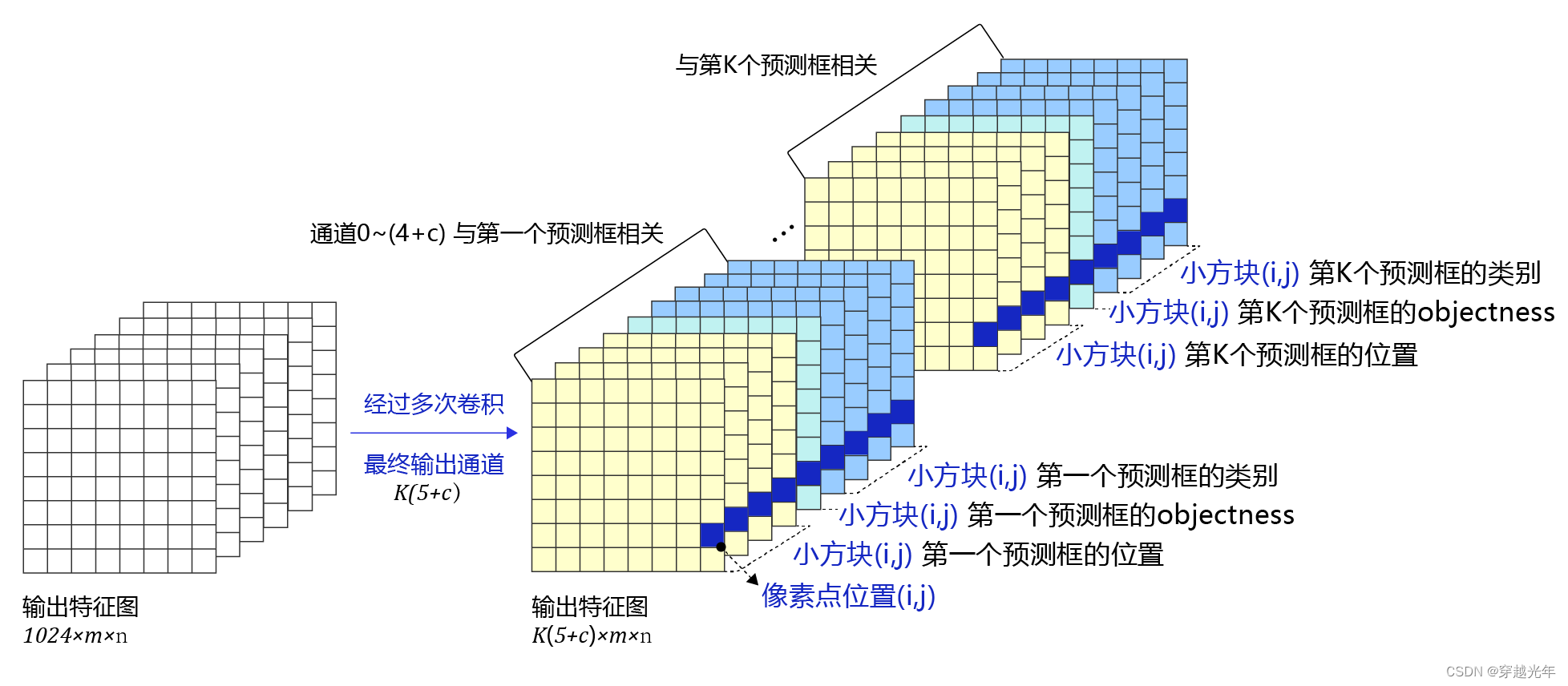
总结:其本质就是将图像通过卷积,计算出分块特征值(每个分块是锚框的中心),该分块特征值对应该分块唯一正样本锚框的预测标签(预测标签值包括:objectness,x, y, w, h, c0, c1, c2...),将该预测标签与基于真实数据产生的正确预测框的标签进行对比,形成损失函数。
5.3 代码实践
from paddle.nn import Conv2D# 计算出锚框对应的标签:图像分块对应的正样本锚框的标签
label_objectness, label_location, label_classification, scale_location = get_objectness_label(img, #输入的图像数据,形状是[N, C, H, W]gt_boxes, #真实框,维度是[N, 50, 4],其中50是真实框数目的上限gt_labels, #真实框所属类别,维度是[N, 50]iou_threshold = 0.7, #当预测框与真实框的iou大于iou_threshold时不将其看作是负样本anchors = [116, 90, 156, 198, 373, 326], #锚框长宽,6个数字,对应3个大小的锚框num_classes=7, #图像中物体的类别数量 downsample=32 #特征图相对于输入网络的图片尺寸变化的比例
) #每个分块的锚框数量
NUM_ANCHORS = 3
#类别数量
NUM_CLASSES = 7
#表达每个分块唯一正样本锚框标签需要的数据量
num_filters=NUM_ANCHORS * (NUM_CLASSES + 5)backbone = DarkNet53_conv_body()
detection = YoloDetectionBlock(ch_in=1024, ch_out=512)
conv2d_pred = Conv2D(in_channels=1024, out_channels=num_filters, kernel_size=1)#生成PO特征图,即预测框标签
x = paddle.to_tensor(img)
C0, C1, C2 = backbone(x)
route, tip = detection(C0)
P0 = conv2d_pred(tip)# anchors包含了预先设定好的锚框尺寸
anchors = [116, 90, 156, 198, 373, 326]
# downsample是特征图P0的步幅
pred_boxes = get_yolo_box_xxyy(P0.numpy(), anchors, num_classes=7, downsample=32)
iou_above_thresh_indices = get_iou_above_thresh_inds(pred_boxes, gt_boxes, iou_threshold=0.7)
label_objectness = label_objectness_ignore(label_objectness, iou_above_thresh_indices)label_objectness = paddle.to_tensor(label_objectness)
label_location = paddle.to_tensor(label_location)
label_classification = paddle.to_tensor(label_classification)
scales = paddle.to_tensor(scale_location)
label_objectness.stop_gradient=True
label_location.stop_gradient=True
label_classification.stop_gradient=True
scales.stop_gradient=True#将P0预测框标签和正样本锚框标签进行计算
total_loss = get_loss(P0, label_objectness, label_location, label_classification, scales,num_anchors=NUM_ANCHORS, num_classes=NUM_CLASSES)
total_loss_data = total_loss.numpy()
print(total_loss_data)详细过程可参考:飞桨AI Studio星河社区-人工智能学习与实训社区